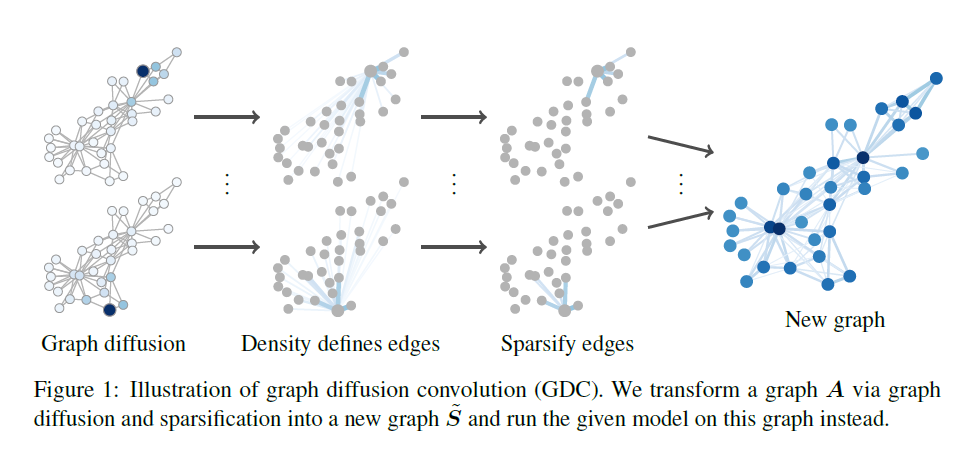
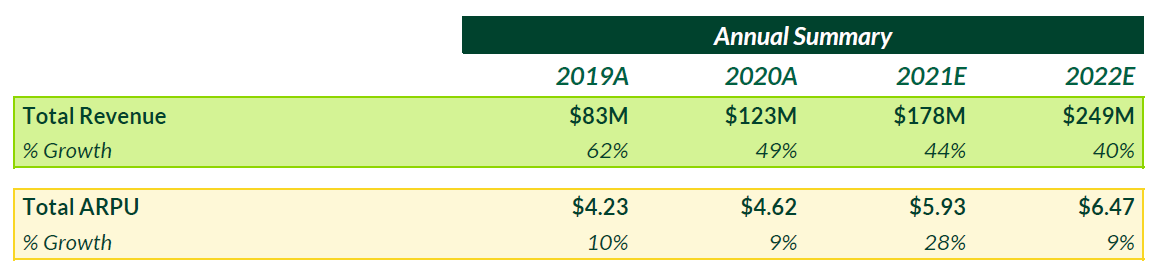
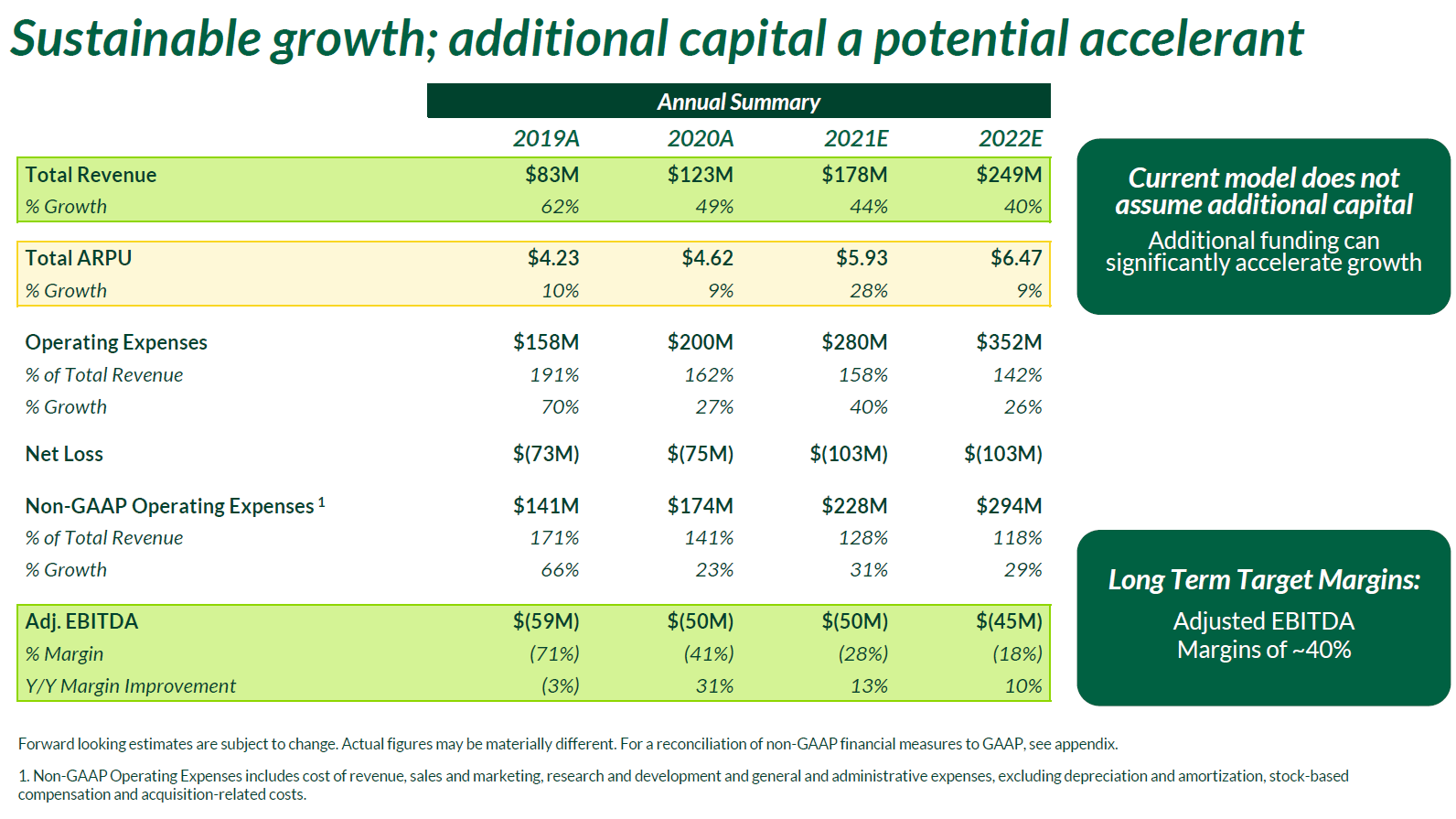
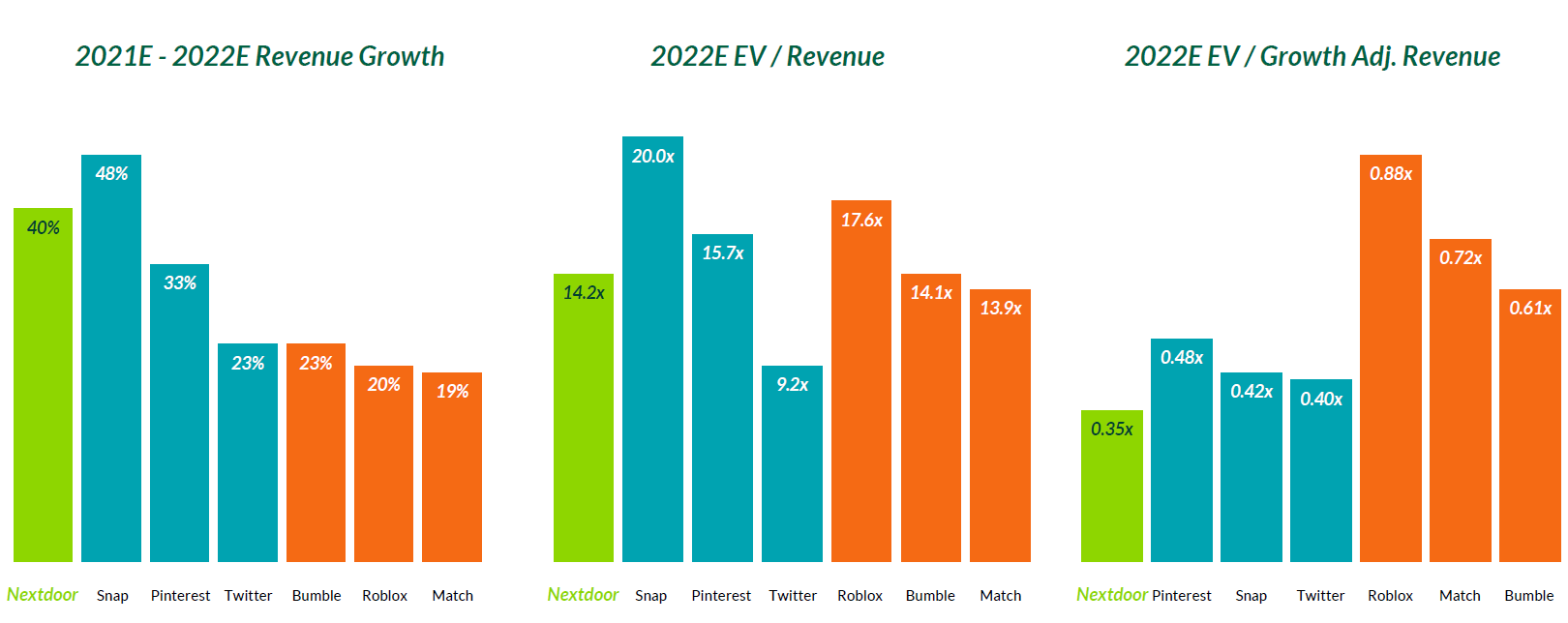
Graph Fourier Transform 설명
14 Aug 2021 | Machine_Learning본 글에서는 Graph Neural Networks 이론의 근간 중 하나라고 할 수 있는 Graph Fourier Transform에 대해 설명할 것이다.
Notation의 경우 최대한 가장 자주 쓰이는 형태를 고려하여 작성하였고, 글로써 완전히 전달하는 것이 어렵기 때문에 여러 자료들을 함께 참고하길 바라며, 관련 강의를 들을 수 있다면 더욱 좋을 것이다.
Graph Laplacian
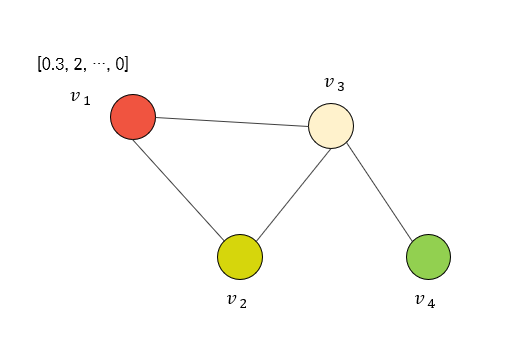
위와 같은 Graph $\mathcal{G}$ 가 존재한다고 할 때, 각 node $v$ 는 feature를 갖고 있다.
각각의 node가 갖고 있는 feature를 그 node의 signal이라고 설정해 볼 때, node $v_1$ 의 signal은 $f_1$ 이라는 함수에 의해 정의된다.
node의 집합 $\mathcal{V}=[v_1, v_2, v_3, v_4]$ 에 대한 node feature matrix는 $(4, d)$ 형태의 2차원 행렬일 것인데,
이 행렬의 각 행이 한 node에 대한 signal이라고 생각해보면 아래와 같이 표현할 수 있다.
[\mathcal{V} \rightarrow \left[\begin{matrix} f_1\f_2\f_3\f_4\ \end{matrix} \right] = \mathbf{f}]
이 Graph의 인접 행렬(Adjacency Matrix)를 표현하면 아래와 같다.
[A = \left[
\begin{matrix}
0 & 1 & 1 & 0
1 & 0 & 1 & 0
0 & 1 & 1 & 1
0 & 0 & 1 & 0
\end{matrix}
\right]]
그리고 Graph의 Degree Matrix는 $D$ 이며 이 두 행렬을 이용하여 Laplacian Matrix를 정의한다.
[\mathbf{L} = \mathbf{D} - \mathbf{A}]
Laplacian Matrix를 difference operator로 활용해보자.

위 예시를 적용해보면 아래와 같이 쓸 수 있다.
[h_2 = 2 f_2 - f_1 - f_3]
이를 일반화하여 적어보면 다음과 같다.
[h_i = \Sigma_{j \in N_i} (f_i - f_j)]
이어서 이를 Quadratic Form으로 재표현한 과정은 아래와 같다.

마지막 줄을 보면, 결국 위 식에서 남는 것은 node $i$ 와 $j$ 사이의 연결이 존재할 때, $f_i - f_j$ 의 값이 작으면 연결된 node의 signal이 유사하다는 의미로 생각할 수 있다.
참고로 $\mathbf{D}^{-1} \mathbf{A}$ 혹은 $\mathbf{D}^{-\frac{1}{2}} \mathbf{A} \mathbf{D}^{-\frac{1}{2}}$ 같은 경우는 Transition Matrix라고도 부른다.
Eigen-decomposition of Laplacian Matrix
지난 Chapter에서 정의했던 Laplacian Matrix $\mathbf{L} = \mathbf{D} - \mathbf{A}$ 에 고유값 분해를 적용해보자.

하나의 eigen value에 대해서 다시 살펴보면 아래와 같고, 이 때 $\lambda_i$ 가 클수록 signal $u_i$ 의 frequency가 크다고 해석할 수 있다.
[\mathbf{u}_i^T \mathbf{L} \mathbf{u}_i = \mathbf{u}_i^T \lambda_i \mathbf{u}_i = \lambda_i]
Graph Fourier Transform
푸리에 변환은 다양한 분야에서 활용되는 굉장히 중요한 개념인데, Graph 이론에서도 변형되어 사용된다.
푸리에 변환의 개념을 간단히만 설명하자면, 어떤 입력 signal을 여러 종류의 frequency를 갖는 함수들의 합으로 표현하는 것이라고 볼 수 있다.
자세한 설명은 이 곳을 참조할 것을 권한다.
그러니까 우리는 Graph를 표현하는 어떤 signal이 존재할 때, 이를 우리가 표현할 수 있는 어떤 함수들의 합으로 의미있게 표현하고 싶은 것이다.
핵심부터 말하자면, $\mathbf{L}$ 의 eigen space $\mathcal{F}$ 에 속해있는 $\mathbf{f} \in \mathcal{F}$ 이 존재할 때, 이를 $\hat{\mathbf{f}}$로 변환하는 것을 Graph Fourier Transform라고 한다.
Graph Fourier Mode 혹은 Basis Graph로 $\mathbf{u_i}$ 를 설정하자, 이 벡터는 사실 Graph Laplacian Matrix에서의 orthogonal eigen vector이다.
참고로 $\lambda_i$ 는 frequency, $\hat{f_i}$ 를 Graph Fourier 계수를 의미한다.
Graph Fourier Transform은 아래와 같이 정의한다.
[\hat{\mathbf{f}} = \mathbf{U}^T \mathbf{f} = \Sigma_i f_i \mathbf{u_i}]
[\hat{f_i} = \mathbf{u_i}^T \mathbf{f}]
이 과정은 $\mathbf{f}$ 를 $\mathcal{F}$ 로 projection하는 것을 의미한다. 즉 기존에 존재하던 Graph Signal을 Graph Laplacian Matrix를 통해 새롭게 정의한 eigen space로 투사하는 것이다. 이 과정은 또한 signal을
앞서 설명하였듯이 $\hat{\mathbf{f_i}}$ 는 Graph Fourier Transform의 결과물인 Graph Fourier 계수 벡터인데, Graph Fourier Transform의 반대 방향 진행은 Inverse Graph Fourier Transform라고 부르며, 다음과 같이 정의한다.
[\mathbf{f} = \mathbf{U}^T \hat{\mathbf{f}} = \Sigma_i \hat{f_i} \mathbf{u_i}]
Spectral Graph Filtering
본 Chapter의 내용은 이후에 GFT를 어떻게 적용하느냐에 관한 내용인데, 간단하게만 짚고 넘어가겠다. 추후 다른 글에서 자세히 다루도록 할 것이다.
GFT를 통해 우리가 얻고자 하는 것은, Graph 내에 있는 어떠한 중요한 특성을 포착하는 것이다. 그리고 이 목적은 Graph Filtering이라는 과정을 통해 구체화할 수 있다.
Graph Filtering은 크게 Spectral Filtering과 Spatial Filtering으로 구분할 수 있으며, spectral이란 단어는 Graph 인접 행렬의 eigenvalue와 eigenvector를 구한다는 뜻을 내포한다.
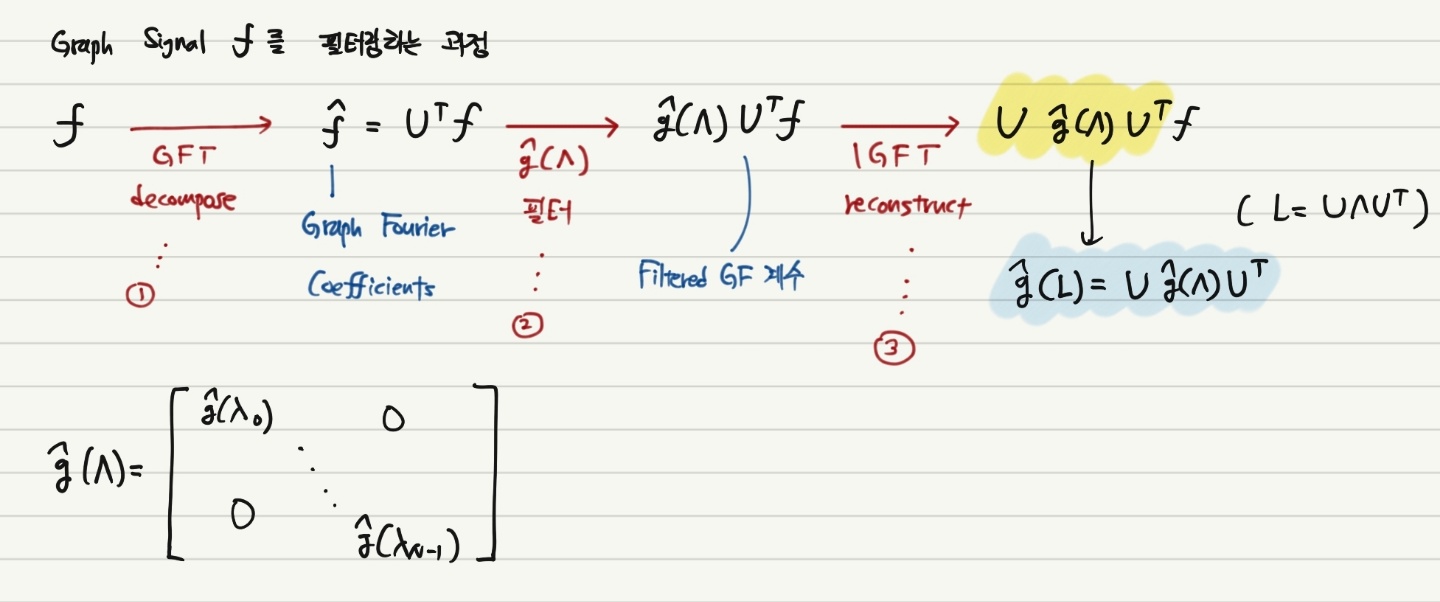
1번 과정에서 GFT를 적용하여 Signal을 변환하여 Graph Fourier 계수를 얻었다. 이후 2번 과정에서 $\hat{g(\Lambda)}$ 으로 정의되는 필터를 곱한 후 IGFT 과정을 통해 최종 결과물을 얻는다.
위 과정은 앞서 기술하였듯이 Input Signal $\mathbf{f}$ 혹은 Input Data $\mathbf{X}$ 가 주어졌을 때, 특정한 필터를 선택하여 곱합으로써 이 Input에서 중요한 특성을 추출하는 의미를 갖는다.
이를 다시 표현하면,
[g_{\theta} * x = \mathbf{U} g_{\theta} \mathbf{U}^T x]
여기서 $\theta$ 는 파라미터를 의미하는데, 이 파라미터의 학습 가능 여부에 따라 다른 방식으로 문제를 풀어나갈 수 있다.
이후 위 식을 통해서 Graph Convolution을 정의하는 과정으로 내용이 이어지게 된다.
References
- GCN 논문
- CS224W Spectral Clustering 강의
- 푸리에 변환 설명 블로그 글