
DANs(Dual Attention Networks for Multimodal Reasoning and Matching, DANs 논문 설명)
17 Apr 2019 | Attention Mechanism Paper_Review VQA목차
- DANs(Dual Attention Networks for Multimodal Reasoning and Matching)
이 글에서는 네이버랩스(Naver Corp.)에서 2017년 발표한 논문인 Dual Attention Networks for Multimodal Reasoning and Matching에 대해 알아보고자 한다.
네이버랩스는 인공지능 국제대회 ‘CVPR 2016: VQA Challenge’에서 2위를 차지하였고, 해당 챌린지에서 DAN(Dual Attention Networks)라는 알고리즘을 개발하였다. 이어 이 알고리즘을 조금 더 일반화하여 2017년 발표한 논문이 이 논문이다.
VQA가 무엇인지는 여기를 참조하면 된다.
간단히, DANs은 따로 존재하던 Visual 모델과 Textual 모델을 잘 합쳐 하나의 framework로 만든 모델이라고 할 수 있겠다.
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
DANs(Dual Attention Networks for Multimodal Reasoning and Matching)
논문 링크: DANs(Dual Attention Networks for Multimodal Reasoning and Matching)
초록(Abstract)
vision과 language 사이의 세밀한 상호작용을 포착하기 위해 우리는 visual 및 textual attention을 잘 조정한 Dual Attention Networks(DANs)를 제안하고자 한다. DANs는 이미지와 텍스트 모두로부터 각각의 중요한 부분에 여러 단계에 걸쳐 집중(attend / attention)하고 중요한 정보를 모아 이미지/텍스트의 특정 부분에만 집중하고자 한다. 이 framework에 기반해서, 우리는 multimodal reasoning(추론)과 matching(매칭)을 위한 두 종류의 DANs를 소개한다. 각각의 모델은 VQA(Visual Question Answering), 이미지-텍스트 매칭에 특화된 것이고 state-of-the-art 성능을 얻을 수 있었다.
서론(Introduction)
Vision과 language는 실제 세계를 이해하기 위한 인간 지능의 중요한 두 부분이다. 이는 AI에도 마찬가지이며, 최근 딥러닝의 발전으로 인해 이 두 분야의 경계조차 허물어지고 있다. VQA, Image Captioning, image-text matching, visual grounding 등등.
최근 기술 발전 중 하나는 attention mechanism인데, 이는 이미지 등 전체 데이터 중에서 중요한 부분에만 ‘집중’한다는 것을 구현한 것으로 많은 신경망의 성능을 향상시키는 데 기여했다.
시각 데이터와 텍스트 데이터 각각에서는 attention이 많은 발전을 가져다 주었지만, 이 두 모델을 결합시키는 것은 연구가 별로 진행되지 못했다.
VQA같은 경우 “(이미지 속) 저 우산의 색깔은 무엇인가?” 와 같은 질문에 대한 답은 ‘우산’과 ‘색깔’에 집중함으로써 얻을 수 있고, 이미지와 텍스트를 매칭하는 task에서는 이미지 속 ‘girl’과 ‘pool’에 집중함으로써 해답을 얻을 수 있다.
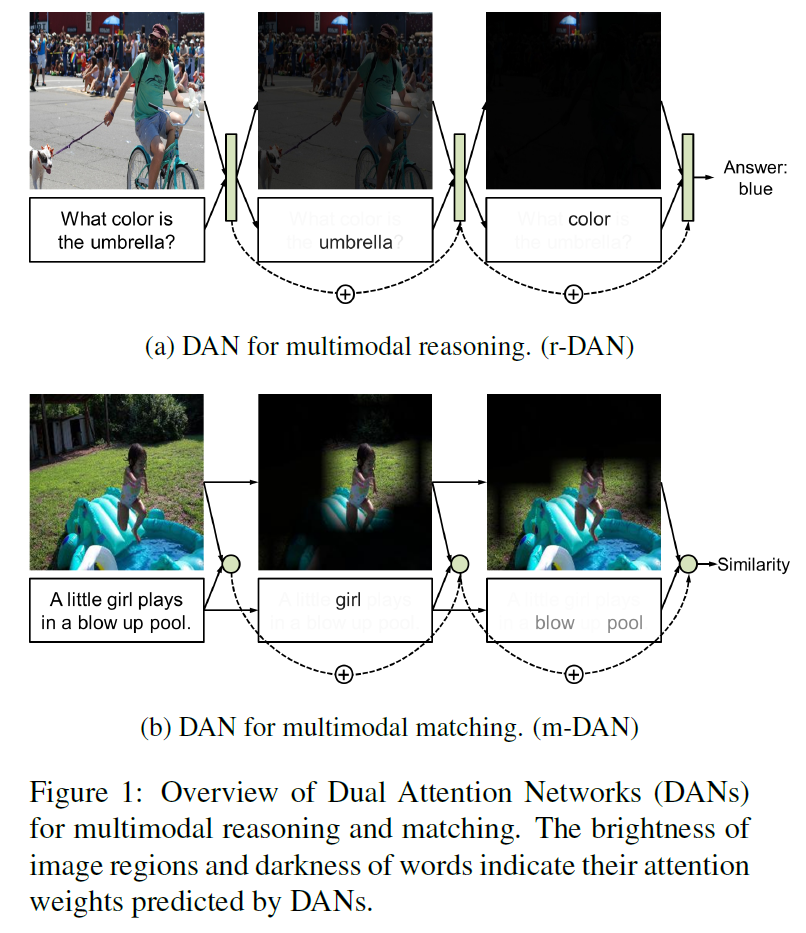
이 논문에서 우리는 vision과 language의 fine-grained 상호작용을 위한 visual 모델과 textual 모델 두 가지를 잘 결합한 Dual Attention Networks(DANs)를 소개한다. DANs의 두 가지 변형 버전이 있는데, reasoning-DAN(r-DAN, 추론용 모델)과 matching-DAN(m-DAN, 매칭용 모델)이다.
r-DAN은 이전 attention 결과와 다음 attention을 모은 결합 메모리를 사용하여 시각적 그리고 언어적 attention을 협동 수행한다. 이는 VQA같은 multimodal 추론에 적합하다.
m-DAN은 시각 집중 모델과 언어 집중 모델을 분리하여 각각 다른 메모리에 넣지만 이미지와 문장 사이의 의미를 찾기 위해 학습은 동시에 진행하는 모델이다. 이 접근법은 최종적으로 효율적인 cross-modal 매칭을 용이하게 해 준다.
두 알고리즘 모두 시각적 그리고 언어적(문자적, textual) 집중 mechanism을 하나의 framework 안에 긴밀히 연결한 것이다.
이제 우리가 기여한 바는 다음과 같다:
- 시각적 그리고 언어적 attention을 위한 통합된 framework를 제안하였다. 이미지 내 중요한 부분과 단어들은 여러 단계에서 합쳐진 곳에 위치한다.
- 이 framework의 변형 버전 두 가지는 실제로 추론 및 매칭을 위한 모델로 구현되어 VQA와 image-text 매칭에 적용되었다.
- attention 결과의 상세한 시각화는 우리의 모델이 task에 핵심적인 이미지 및 문장 부분에 잘 집중하고 있음을 보여주는 것을 가능하게 한다.
- 이 framework는 VQA와 Flickr30K 데이터셋에서 SOTA(state-of-the-art) 결과를 보여주었다.
관련 연구(Related Works)
- Attention Mechanisms: 간단히 말해 시각적 또는 언어적 입력에서 task를 해결하는 데 중요한 일부분에만 집중하도록 해 문제를 잘 풀 수 있게 하는 방법이다.
- Visual Question Answering(VQA): 이미지와 그 이미지와 연관된 질문이 주어지면 적절한 답을 찾는 task이다. 자세한 내용은 여기를 참조하라.
- Image-Text Matching: 시각자료(이미지)와 글자자료(=문장, 언어적 부분) 사이의 의미적 유사도를 찾는 것이 가장 중요하다. 많은 경우 이미지 특징벡터(feature vector)와 문장 특징벡터를 직접 비교할 수 있도록 변형해 비교하는 방법이 자주 쓰인다. 이 비교방법은 양방향 손실함수 또는 CNN으로 결합하는 방법 등이 쓰인다. 그러나 multimodal attention 모델을 개발하려는 시도는 없었다.
Dual Attention Networks(DANs)
Input Representation
Image representation
- 이미지 특징은 19-layer VGGNet 또는 152-layer ResNet으로 추출했다.
- 448 $\times$ 448 으로 바꿔 CNN에 집어넣는다.
- 다른 ‘지역’(region)으로부터 특징벡터를 얻기 위해 VGGNet 및 ResNet의 마지막 pooling layer를 취했다.
- 이제 이미지는 ${v_1, …, v_N}$으로 표현된다. $N$은 이미지 지역의 개수, $v_n$은 512(VGGNet) 또는 2048(ResNet)이다.
Text representation
one-hot 인코딩으로 주어진 $T$개의 입력 단어들 ${w_1, …, w_T}$을 임베딩시킨 후 양방향 LSTM에 집어넣는다.
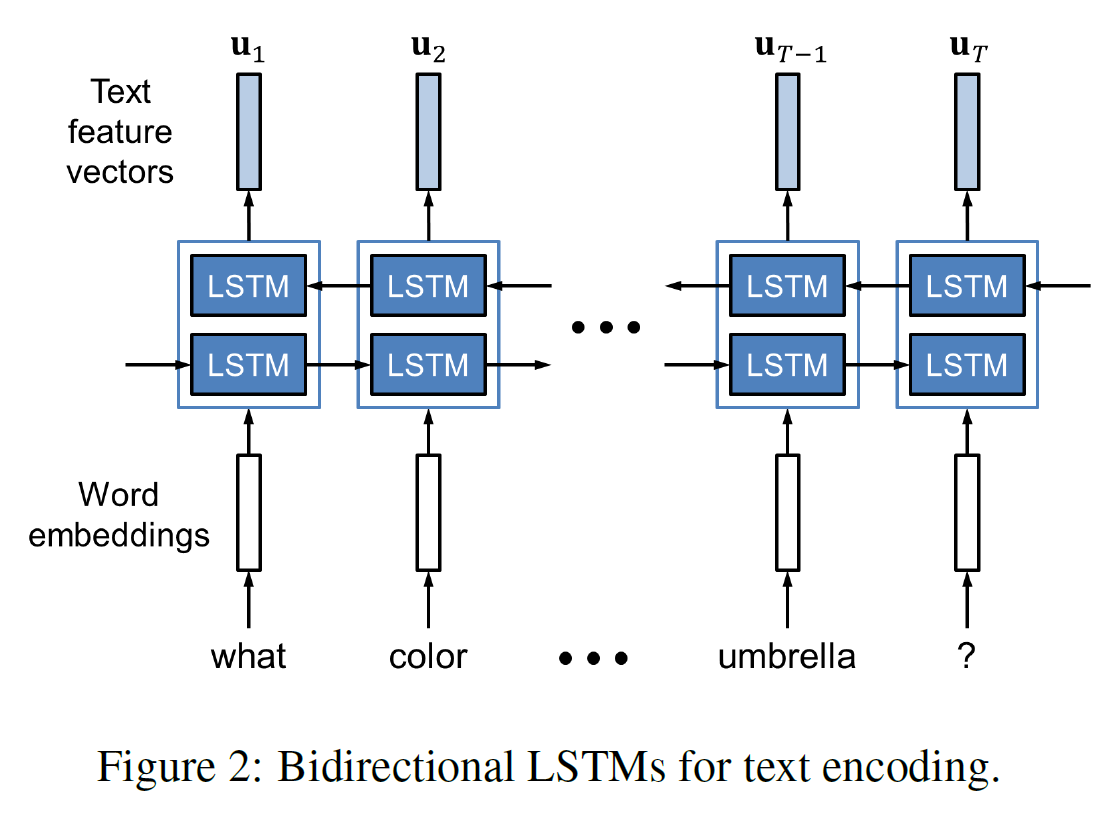
임베딩 행렬(embedding matrix)와 LSTM은 end-to-end로 학습된다.
Attention Mechanisms
bias $b$는 생략되어 있다.
Visual Attention
이미지의 특정 부분에 집중하게 하는 context vector를 생성하는 것을 주목적으로 한다.
step $k$에서, 시각문맥벡터(visual context vector) $v^{(k)}$는
\[v^{(k)} = \text{V\_Att} (\{v_n\}^N_{n=1}, \ m_v^{(k-1)}\]$m_v^{(k-1)}$는 step $k-1$까지 집중했었던 정보를 인코딩하는 메모리 벡터이다.
여기에다가 soft attention mechanism을 적용하게 된다.
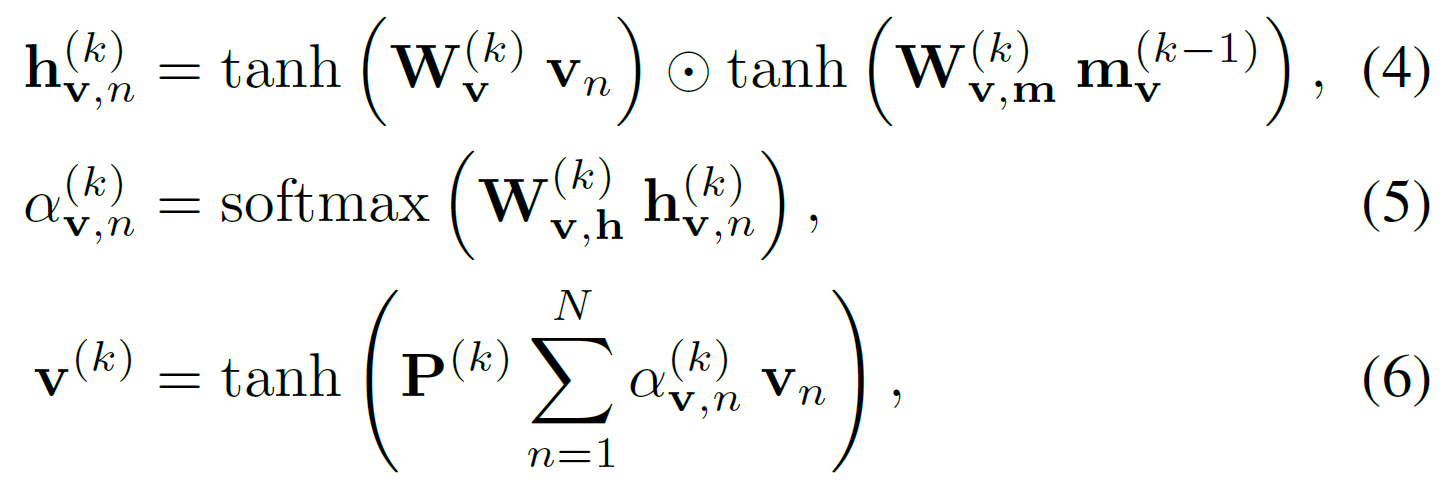
attention weights $\alpha$는 2-layer FNN과 softmax로 구해진다. $W$들은 네트워크 parameter이다.
Textual Attention
마찬가지로 문장의 특정 부분에 집중할 수 있도록 문맥벡터 $u^{(k)}$를 매 step마다 생성하는 것이다.
\[u^{(k)} = \text{T\_Att} (\{u_t\}^T_{t=1}, \ m_u^{(k-1)}\]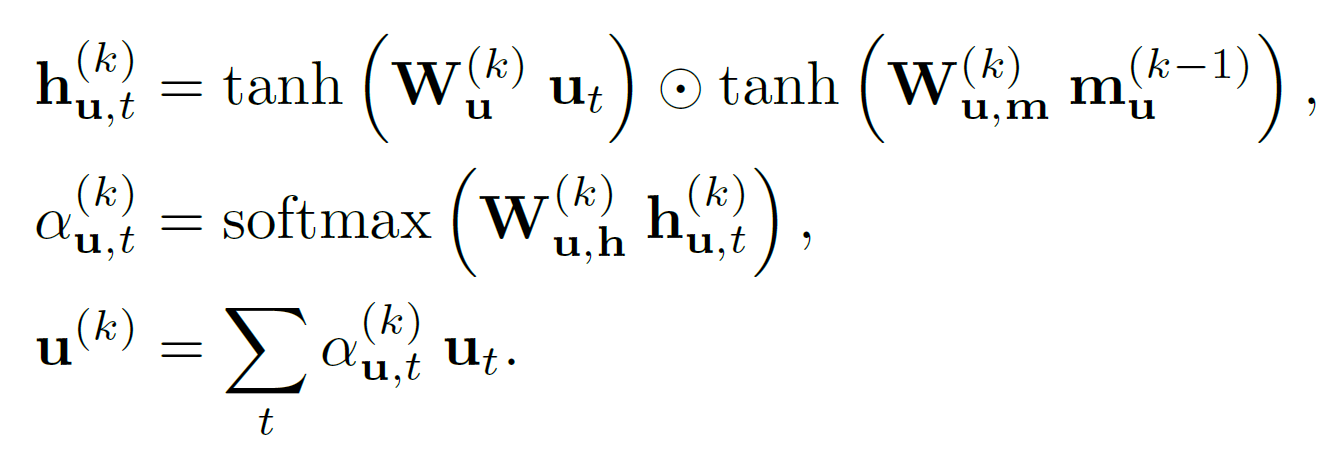
r-DAN for Visual Question Answering
VQA는 multimodal 데이터를 결합 추론하는 것을 필요로 하는 문제이다. 이를 위해 r-DAN은 step $k$에서 시각 및 언어적 정보를 축적하는 메모리 벡터 $m^{(k)}$를 유지한다. 이는 재귀적으로 다음 식을 통해 업데이트된다.
\[m^{(k)} = m^{(k-1)} + v^{(k)} \ (\cdot) \ u^{(k)}\]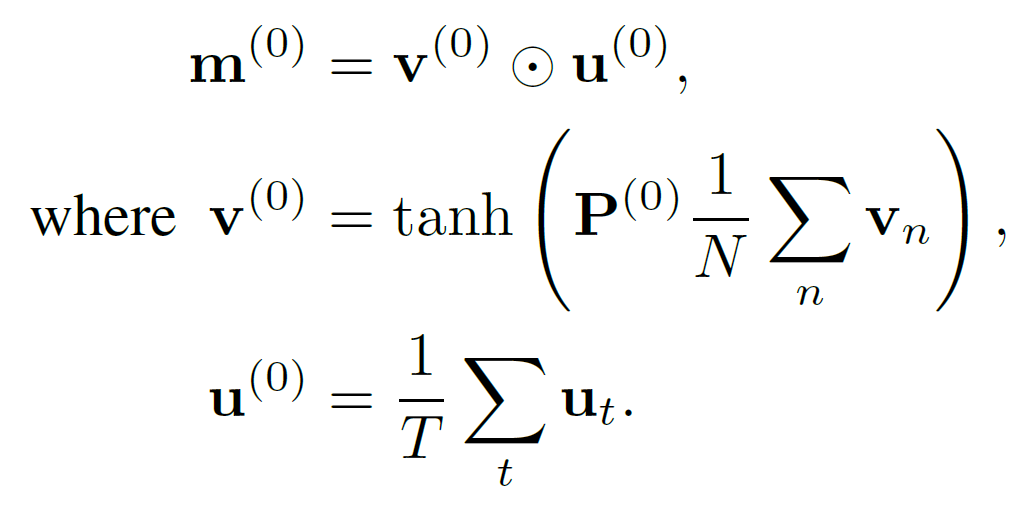
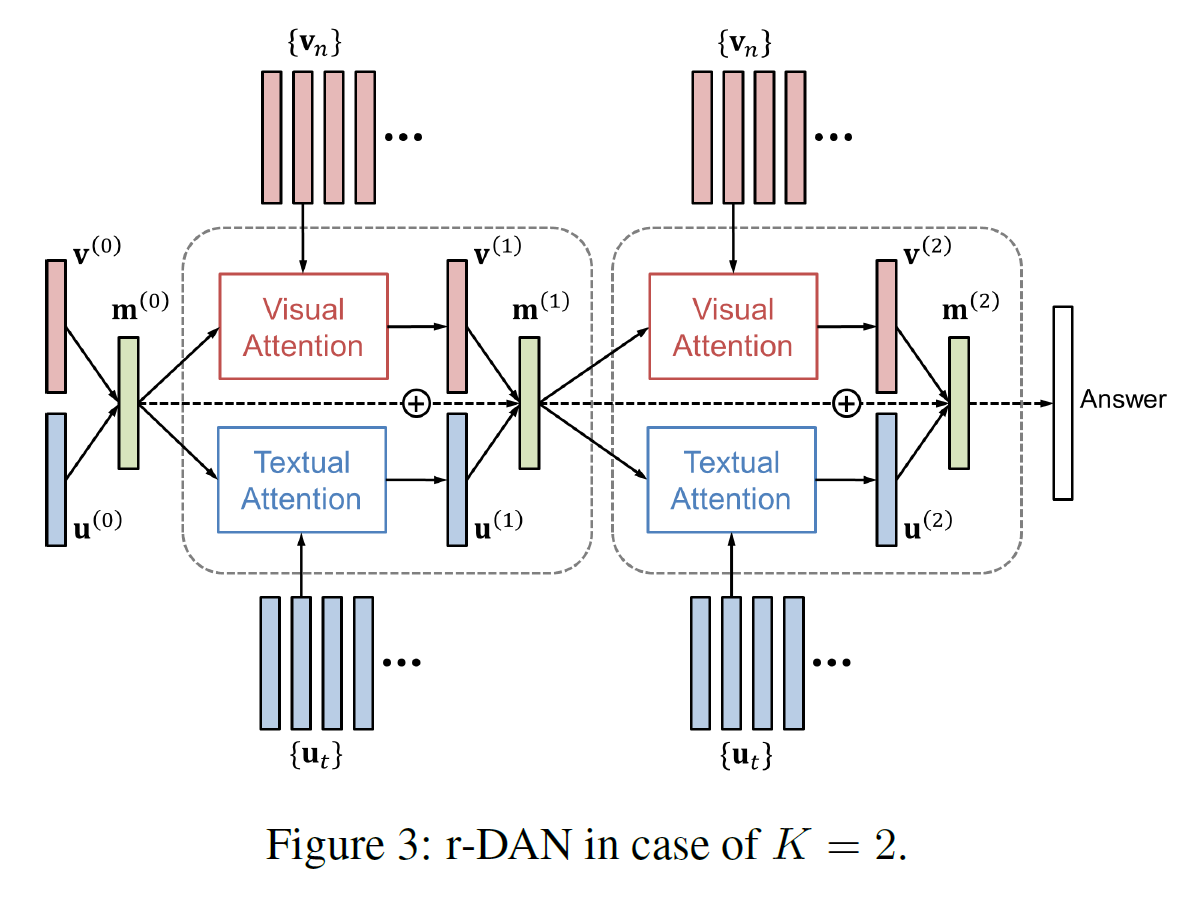
최종 답은 다음과 같이 계산된다. $ \text{p}_{\text{ans}}$는 정답 후보들의 확률을 나타낸다.
\[\bold{\text{p}}_{\text{ans}} = \text{softmax} \bigr( W_{\text{ans}} \ m^{(K)} \bigl)\]m-DAN for Image-Text Matching
수식의 형태는 꽤 비슷하다.
\[m_v^{(k)} = m_v^{(k-1)} + v^{(k)}\] \[m_u^{(k)} = m_u^{(k-1)} + u^{(k)}\]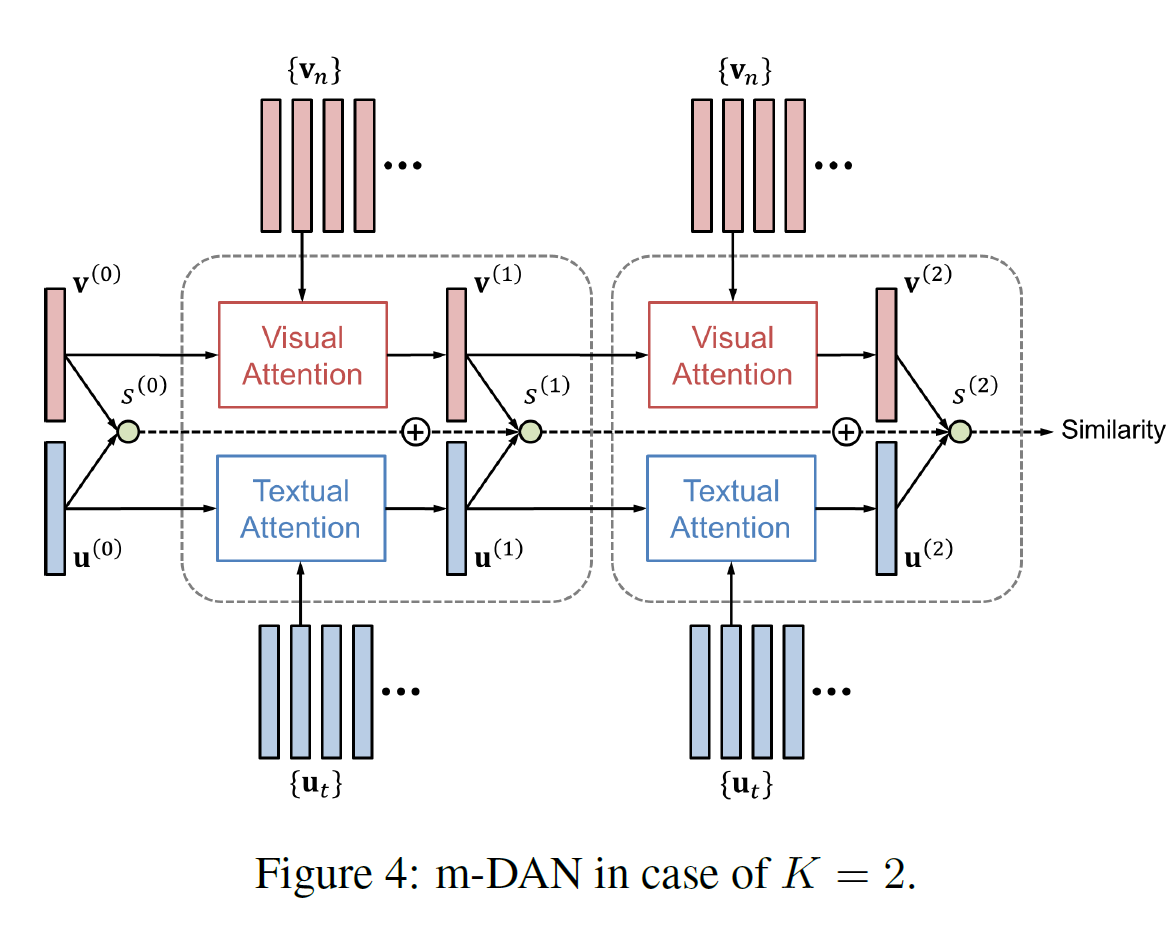
\(s^{(k)} = v^{(k)} \cdot u^{(k)}, \ S = \sum_{k=0}^K s^{(k)}\) Loss function은 다음과 같이 정의된다.
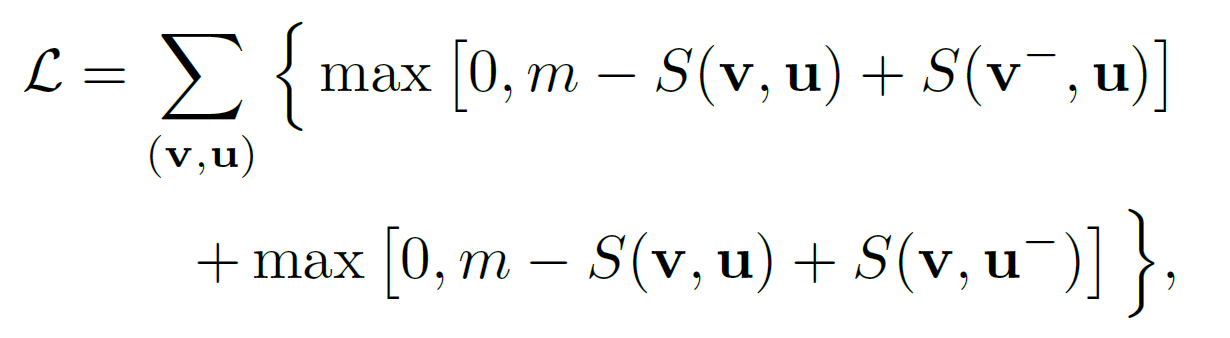
추론할 시점에는 어떤 이미지나 문장이든 결합공간 안에 임베딩된다.
\[z_v = [v^{(0)}; ... ; v^{(K)}],\] \[z_u = [u^{(0)}; ... ; u^{(K)}],\]실험(Experiments)
Experimental Setup
r-DAN과 m-DAN 모두에 대해 모든 hyper-parameters들은 전부 고정되었다.
$K$=2, LSTM을 포함한 모든 네트워크의 hidden layer의 dimension=512,
lr=0.1, momentum=0.9, weight decay=0.0005, dropout rate=0.5, gradient clipping=0.1,
epochs=60, 30epoch 이후 lr=0.01,
minibatch=128 $\times$ 128 quadruplets(긍정 이미지, 긍정 문장, 부정 이미지, 부정 문장),
가능한 답변의 수 C=2000, margin $m$=100이다.
Evaluation on Visual Question Answering
Dataset and Evaluation Metric
VQA 데이터셋을 사용하였고, train(이미지 8만 장), val(이미지 4만 장), test-dev(이미지 2만 장), test-std(이미지 2만 장)이다. 측정방법은

$\hat{a}$는 예측된 답이다.
Results and Analysis
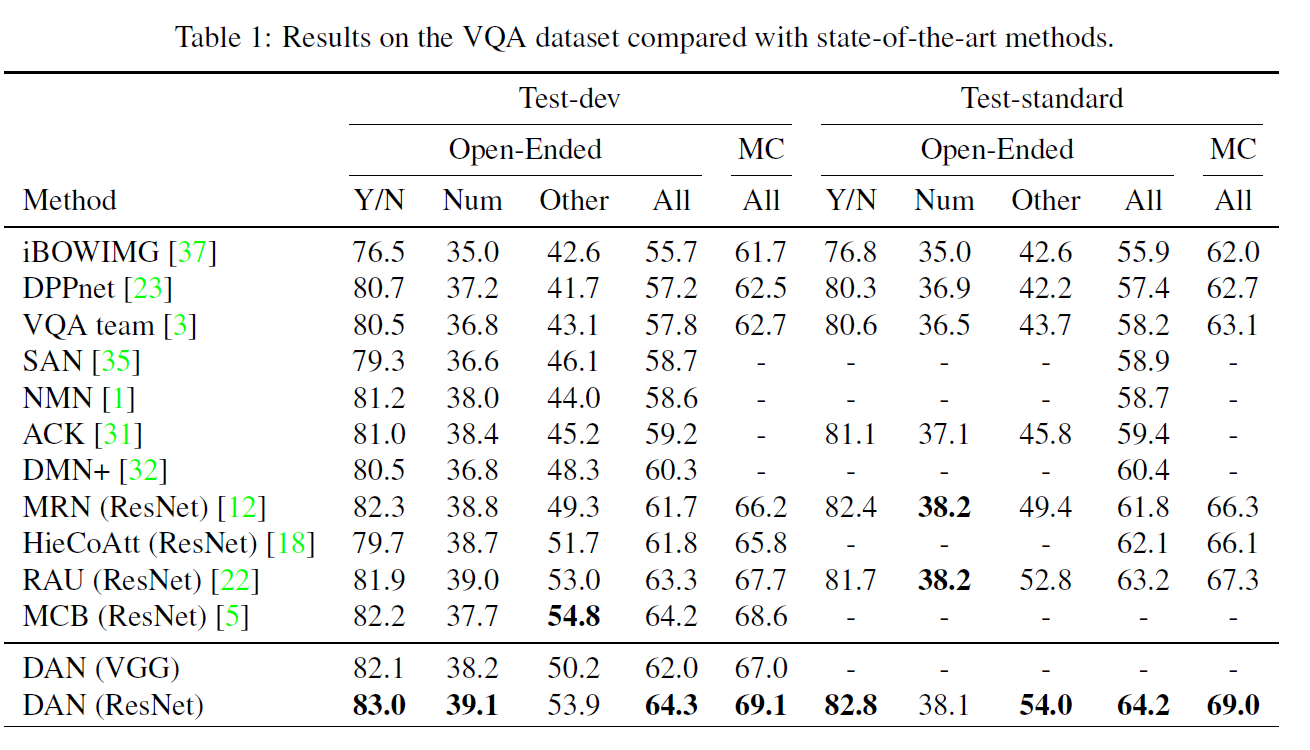

결과를 보면 대부분의 상황에서 SOTA 결과를 얻었으며, 이미지와 문장에서 집중해야 할 부분을 잘 찾았음을 확인할 수 있다.
Evaluation on Image-Text Matching
분석결과는 비슷하므로 생략한다.
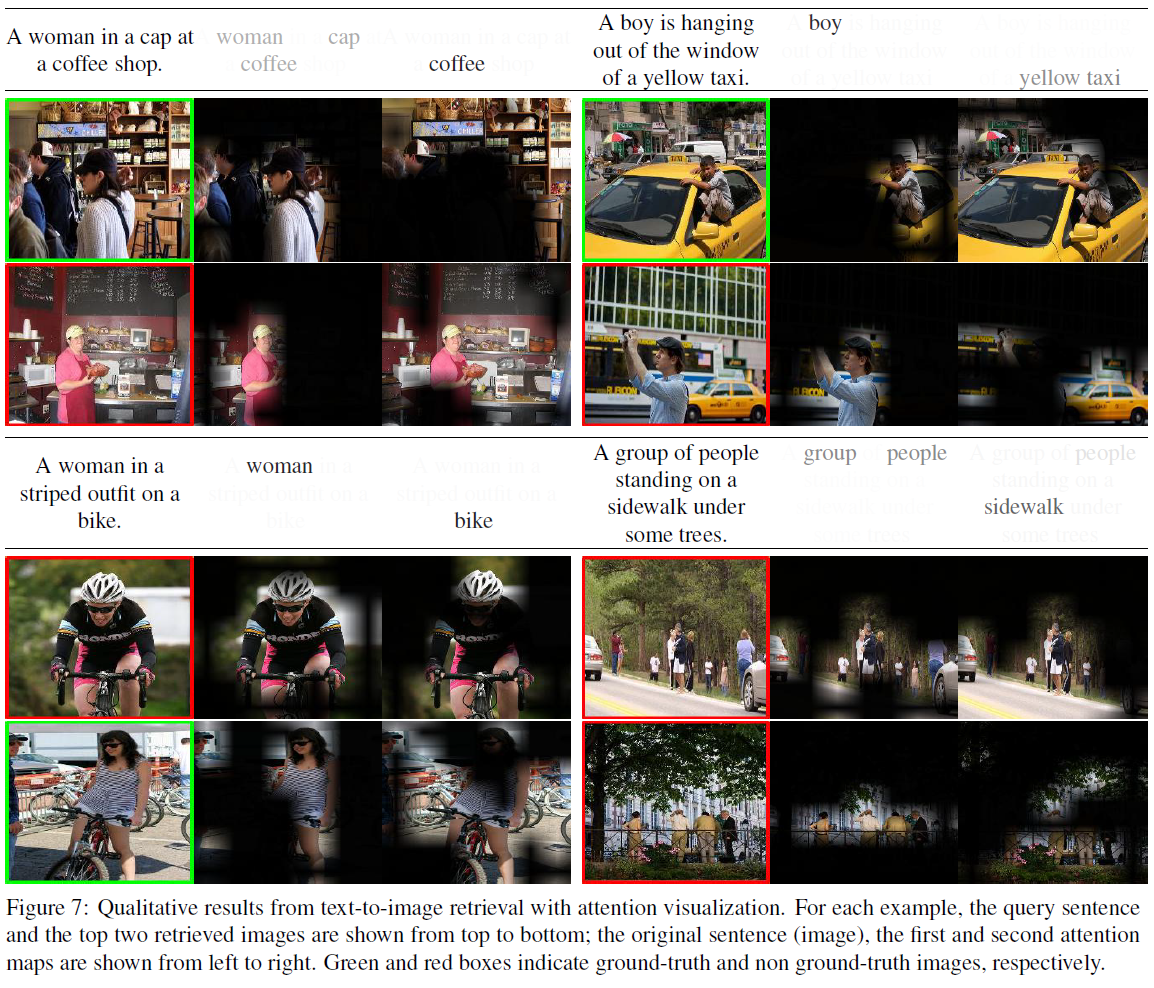
결론(Conclusion)
우리는 시각 및 언어적 attention mechanism을 연결하기 위한 Dual Attention Networks (DANs)를 제안하였다. 추론과 매칭을 위한 모델을 하나씩 만들었고, 각각의 모델은 이미지와 문장으로부터 공통 의미를 찾아낸다.
이 모델들은 VQA와 image-text 매칭 task에서 SOTA 결과를 얻어냄으로써 DANs의 효과를 입증하였다. 제안된 이 framework는 image captioning, visual grounding, video question answering 등등 많은 시각 및 언어 task들로 확장될 수 있다.
참고문헌(References)
논문 참조! 부록은 없다. 읽기 편하다