
MovieQA(Movie Question Answering, MovieQA 논문 설명)
29 May 2019 | Paper_Review VQA Task_Proposal목차
이 글에서는 MovieQA: Understanding Stories in Movies through Question-Answering에 대해 알아보고자 한다.
VQA task는 이미지(Visual, 영상으로도 확장 가능)와 그 이미지에 대한 질문(Question)이 주어졌을 때, 해당 질문에 맞는 올바른 답변(Answer)을 만들어내는 task이다.
MovieQA는 Vision QA의 확장판과 비슷한 것이라고 보면 된다. 그러나 크게 다른 점은 사진 한 장과 QA셋이 아닌 Movie Clip과 QA셋으로 학습 및 테스트를 진행한다는 것이다. 사진이 영상으로 바뀐 만큼 당연히 난이도 역시 증가하였다.
MovieQA 홈페이지는 http://movieqa.cs.toronto.edu/home/ 이다.
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
MovieQA: Understanding Stories in Movies through Question-Answering
논문 링크: MovieQA: Understanding Stories in Movies through Question-Answering
초록(Abstract)
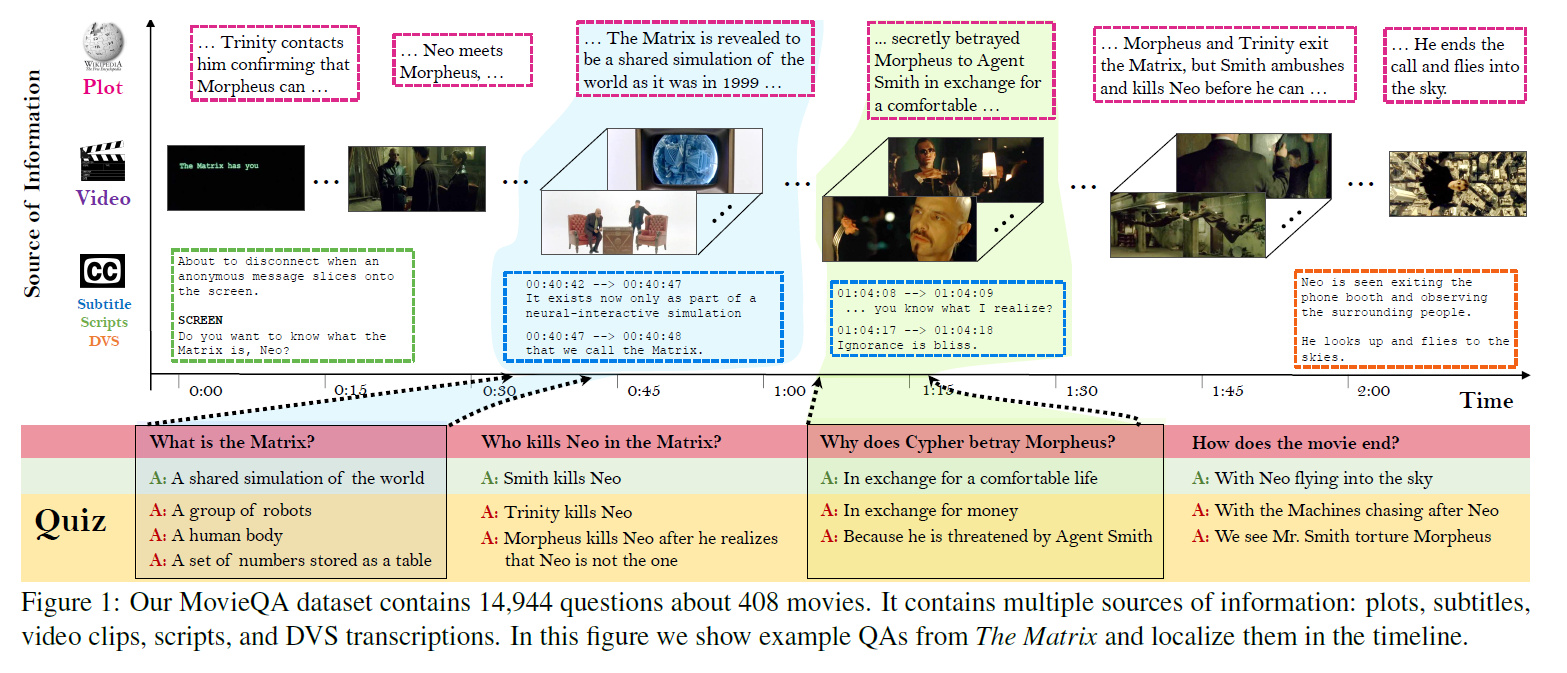
우리는 video와 text 모두를 통해 자동적 스토리 이해를 평하가는 MovieQA 데이터셋을 소개할 것이다. 이 데이터셋은 408개의 영화(movie)에 대한 아주 다양한 의미의 14,944개의 질문으로 이루어져 있다. 이 질문들은 ‘누가’ ‘누구에게’ ‘무엇을’ ‘어떻게’ ‘왜’ 했는지까지의 범위를 포함한다. 각 질문에는 5개의 답이 있는데 1개만 맞는 답이며 4개는 사람이 직접 만든 가짜 답이다. 우리의 데이터셋은 영상클립, 줄거리, 제목, 자막, DVS 등 많은 소스들을 포함한다는 점에서 유일하다. 우리는 이 데이터셋을 다양한 통계적 방법으로 분석했으며 존재하는 QA 기술들을 확장하여 열린 의미의 QA로 하는 것은 어렵다는 것을 보일 것이다. 우리는 이 데이터셋을 평가방법과 함께 일반에 공개하여 도전을 장려할 것이다.
서론(Introduction)
이미지 태깅, 물체인식 및 분할, 액션 인식, 이미지/비디오 캡셔닝 등 많은 시각적 task에서 레이블링된 많은 양의 데이터가 사용 가능해진 것과 함께 딥러닝에서 빠른 발전이 있었다. 우리는 시각장애가 있는 사람들을 위한 보조적인 해결책이나, 일반적인 framework에서 이런 모든 task들을 추론에 의해 실제 세계를 전체적으로 인식하는 인지로봇과 같은 application에 한 걸음 더 다가갔다. 그러나 정말 ‘지능적인’ 기계는 동기, 의도, 감정, 의사소통 등 높은 수준의 것을 포함한다. 이러한 주제들은 문학에서나 겨우 탐험이 시작되었다.
(눈에 보이는) 장면을 이해하는 것을 보여주는 훌륭한 방법은 그것에 대한 질문-답변을 하는 것이다. 이러한 생각은 각 이미지에 대해 여러 질문들과 다지선다형 답변을 포함한 질문-답변 데이터셋을 만드는 것으로 이어졌다.
이러한 데이터셋은 RGB-D 이미지 또는 Microsoft COCO와 같은 정지 이미지의 거대한 모음집에 기반한다. 전형적인 질문으로는 ‘무엇이(what)’ 거기에 있고 ‘어디에(where)’ 그것이 있는지와 같은 것, 물체가 어떤 성질을 갖는지, 얼마나 많은 ‘특정 종류의 물건’이 있는지 등이 있다.
이러한 질문들은 전체적인 자연에 대한 우리의 시각적 알고리즘을 확인시켜주기는 하지만, 정지 이미지에 대해 물어볼 수 있는 태생적인 한계가 존재한다. 행동과 그 의도에 대한 높은 수준의 의미 이해는 오직 순간적, 또는 일생에 걸친 시각적 관찰에 의한 추론에 의해서만 가능하다.

영화(Movies)는 사람들의 삶과 이야기, 성격에 대한 높은 수준의 이해, 행동과 그 이면에 숨겨진 동기와 같은 것들을 이해할 수 있도록 하는 짤막한 정보를 우리에게 제공한다. 우리의 목표는 ‘복잡한 영상과 그에 맞는 텍스트(자막) 모두를 포함한 것을 이해하는 기계’를 측정하는 질문-답변 데이터셋을 만드는 것이다. 우리는 이 데이터셋이 다음 수준의 자동적인 ‘정말로’ 이해를 하는 기계를 만드는 것을 촉진하는 것이 되었으면 한다.
이 논문은 영화에 대한 거대한 질문-답변 데이터셋, MovieQA를 소개한다. 이는 408개의 영화와 14,944개의 5지선다형 질문을 포함한다. 이 중 140개의 영화(6,462개의 질답)에는 영화의 질문-답변 부분에 해당하는 time stamp가 붙어 있다.
이 질문들은 ‘누가’ ‘무엇을’ ‘누구에게’ 같이 시각적으로만 풀 수 있는 것과 ‘왜’ ‘어떻게’ 무슨 일이 일어났냐는 시각정보와 대사(텍스트)를 모두 사용해야만 답을 추론할 수 있는 질문들을 포함한다.
우리의 데이터셋은 영상클립, 제목, 자막, 줄거리, DVS를 포함하는 다양한 출처의 정보를 포함하는 유일한 데이터셋이다. 우리는 이를 통계적으로 분석할 것이며 또한 존재하는 질답 기술을 우리의 데이터에 적용하고 이러한 open-ended 질답이 어려운 것을 보일 것이다.
우리는 leaderboard를 포함한 온라인 벤치마크 사이트를 만들어 두었다.
관련 연구(Related Works)
- Video understanding via language: 영상 범위에서 시각 및 언어정보를 통합시킨 연구는 더 적은 연구만이 존재한다. LSTM을 사용한 영상클립에 캡션을 다는 것 등이 있었다.
- Question-answering: 자연언어처리에서 인기 있는 task이다. Memory network나 deep LSTM, Bayesian approach 등이 사용되고 있다.
- QA Datasets: NYUv2 RGB-D와 같은 데이터셋이나, 100만 단위의 MS-COCO 데이터셋 등이 있다.
MovieQA 데이터셋(MovieQA Dataset)
앞서 언급했듯이 408개의 영화와, 위키피디아에서 가져온 줄거리(시놉시스)를 포함한다. 또한 영상, 제목, DVS, 대사 스크립트를 포함한다.
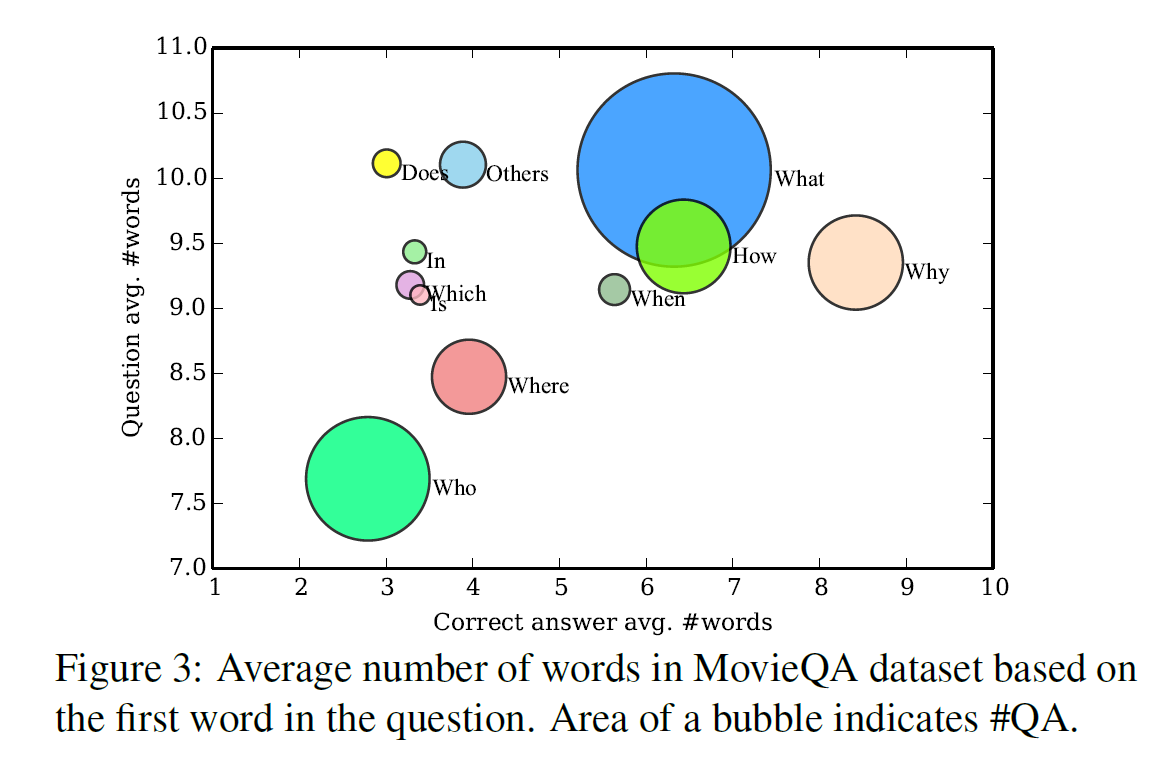
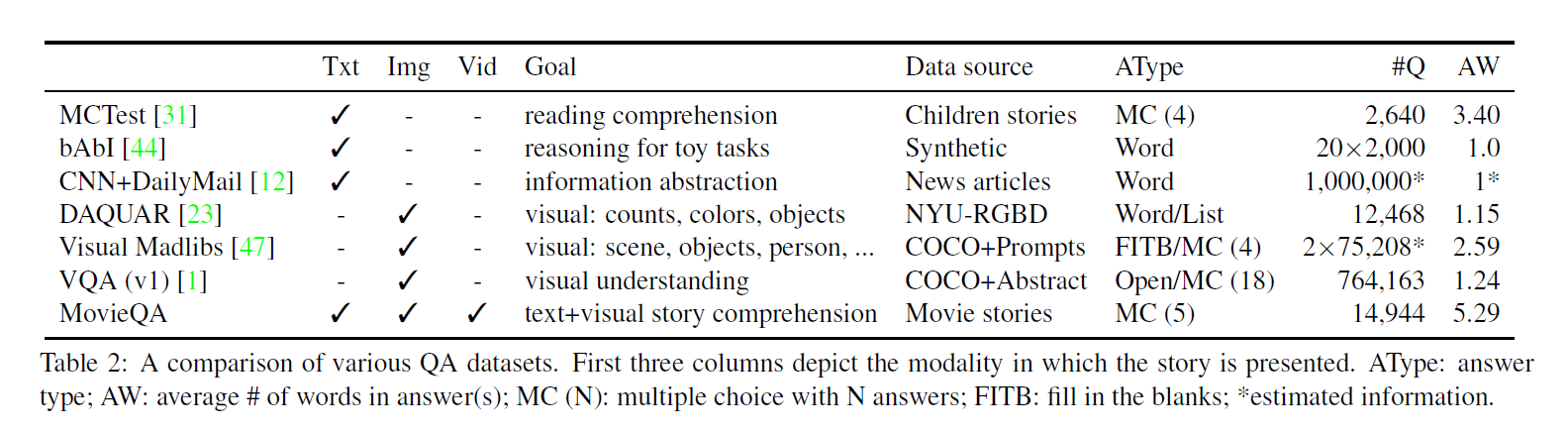
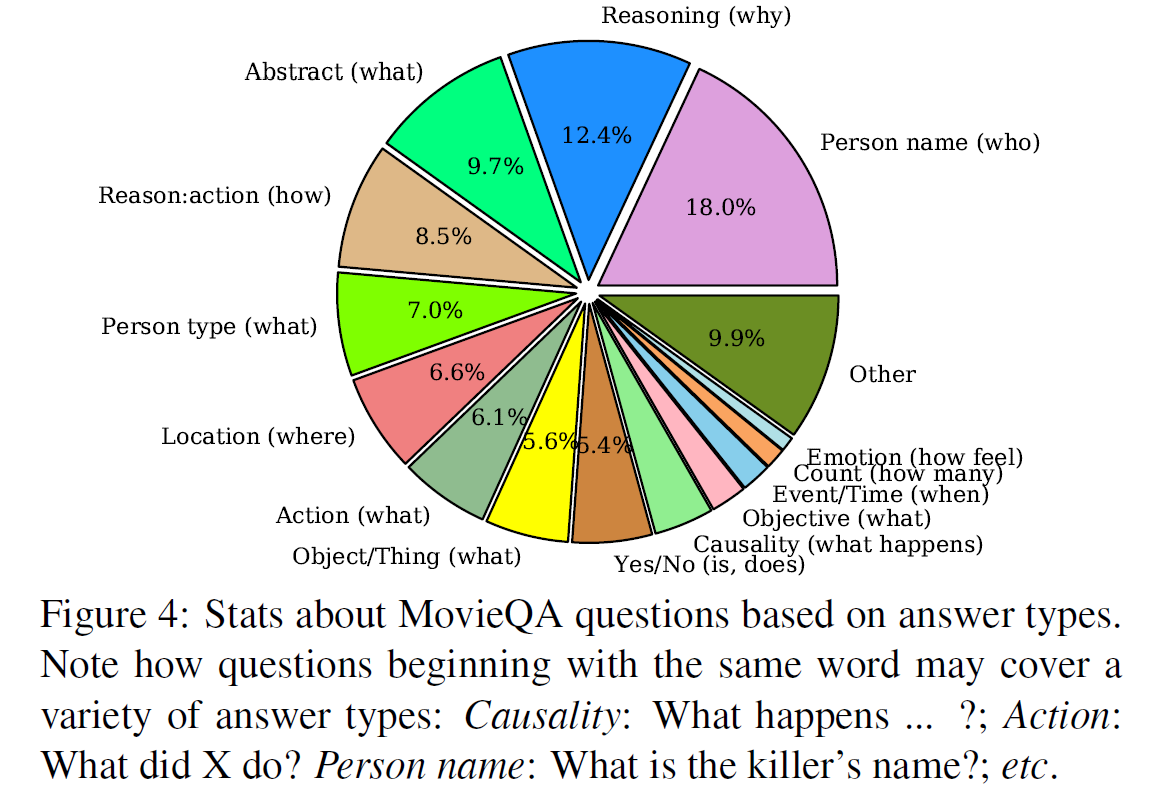
이 부분의 주된 내용은 영화, 질문, 답변에는 어떤 종류가 있고, 어느 비율만큼 어떤 것이 있는지에 대한 통계 자료들이다. 자세한 내용은 궁금하면 논문을 직접 읽어보는 것이 빠르다.
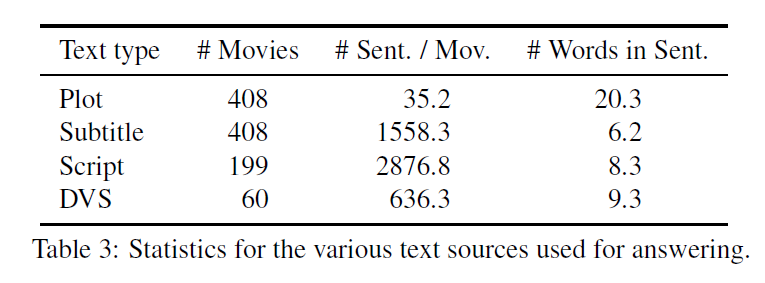
다지선다형 질문-답변(Multi-choice Question-Answering)
여기서는 질답을 위한 여러 지능적인 기준선(intelligent baselines)를 조사하려 한다.
- $S$를 이야기(줄거리, 제목, 비디오 샷을 포함한 어떤 정보든 포함)라 한다.
- $q^S$는 하나의 질문이다.
- ${a^S_j}^M_{j=1}$은 질문 $q^S$에 대한 여러 답변이다. 여기서 $M=5$이다(5지선다형이므로).
- 그러면 다지선다형 질답의 일반적인 문제느 3방향 득점 점수 $f(S, q^S, a^S)$로 나타낼 수 있다.
- 이 함수는 이야기와 질문이 주어졌을 때 답변의 “Quality”를 평가한다.
- 우리의 목표는 이제 $f$를 최대화하는 질문 $q^S$에 대한 답변 $a^S$를 선택하는 것이다:
아래는 모델의 한 예시이다.
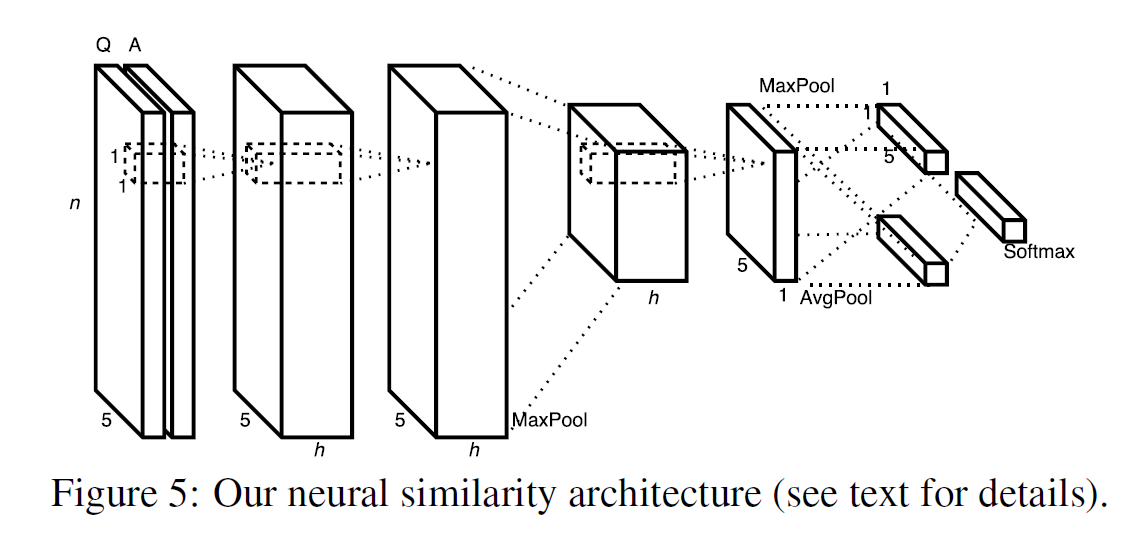
모델은 ‘The Hasty Student’, ‘Searching Student’, ‘Memory Network’, ‘Video baselines’ 등을 포함한다.
결론(Conclusion)
이 논문에서는 영상과 텍스트 모두를 아우르는 자동적 이야기 이해 평가를 목표로 하는 MovieQA 데이터셋을 소개하였다. 우리의 데이터셋은 영상클립, 제목, 대사 스크립트, 줄거리, DVS 등 다양한 출처의 정보를 포함한다는 점에서 유일하다. 우리는 여러 지능적인 기준선과 우리의 task의 난이도를 분석하는 원래 존재하던 질답 기술을 연장시키기도 했다. 평가 서버를 포함한 우리의 벤치마크는 온라인에서 확인할 수 있다.
참고문헌(References)
논문 참조!
모델들에 대한 자세한 설명들은 생략하였다. Student 모델같은 경우에는 이름부터 꽤 흥미롭기 때문에 한번쯤 찾아보는 것을 추천한다.