
KVQA - Knowledge-Aware Visual Question Answering(KVQA 논문 설명)
17 Nov 2020 | Paper_Review VQA Task_Proposal목차
이 글에서는 KVQA: Knowledge-Aware Visual Question Answering에 대해 알아보고자 한다.
VQA task는 이미지(Visual, 영상으로도 확장 가능)와 그 이미지에 대한 질문(Question)이 주어졌을 때, 해당 질문에 맞는 올바른 답변(Answer)을 만들어내는 task이다.
KVQA는 VQA의 일종이지만, 전통적인 VQA와는 달리 이미지 등 시각자료에서 주어지는 정보뿐만 아니라 외부 지식(상식 베이스, Knowledge Base)이 있어야만 문제를 풀 수 있는 질의들로 이루어진 새로운 task이다.
KVQA 홈페이지는 http://malllabiisc.github.io/resources/kvqa/ 이다.
데이터셋도 같은 링크에서 다운받을 수 있다(총 90G 상당).
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
KVQA: Knowledge-Aware Visual Question Answering
논문 링크: KVQA: Knowledge-Aware Visual Question Answering
초록(Abstract)
Visual Question Answering(VQA)는 CV, NLP, AI에서 중요한 문제로 떠오르고 있다. 전통적인 VQA에서는, 이미지에 대한 질문이 주어지는데 이는 이미지에 있는 정보만으로도 답변할 수 있다: 예를 들어, 사람들이 있는 이미지가 주어지면, 이미지 안에 사람이 몇 명이나 있는지를 묻는 것과 같은 식이다.
좀 더 최근에는 고양이/개 등 일반명사를 포함하는 일반상식(commonsense knowledge)을 요구하는 질문에 답변하는 것이 주목받고 있다. 이러한 흐름에도 버락 오바마 등 고유명사에 대한 세계 지식(world knowledge)를 요하는 질문에 답변하는 것은 다뤄진 적이 없었다. 그래서 이러한 부분을 이 논문에서 다루며, (세계) 지식을 알아햐 하는 VQA인 KVQA를 제안한다.
이 데이터셋은 18K개의 고유명사와 24K개의 이미지를 포함하는 183K개의 질답 쌍으로 이루어져 있다. 데이터셋의 질문들은 여러 객체와 다중 관계, 큰 Knowledge Graphs(KG) 상에서 다중도약 추론을 요구한다. 이러한 점에서 KVQA는 KG를 갖는 VQA에서 가장 큰 데이터셋이다. 또한, KVQA에 SOTA 방법을 사용한 결과도 보인다.
서론(Introduction)
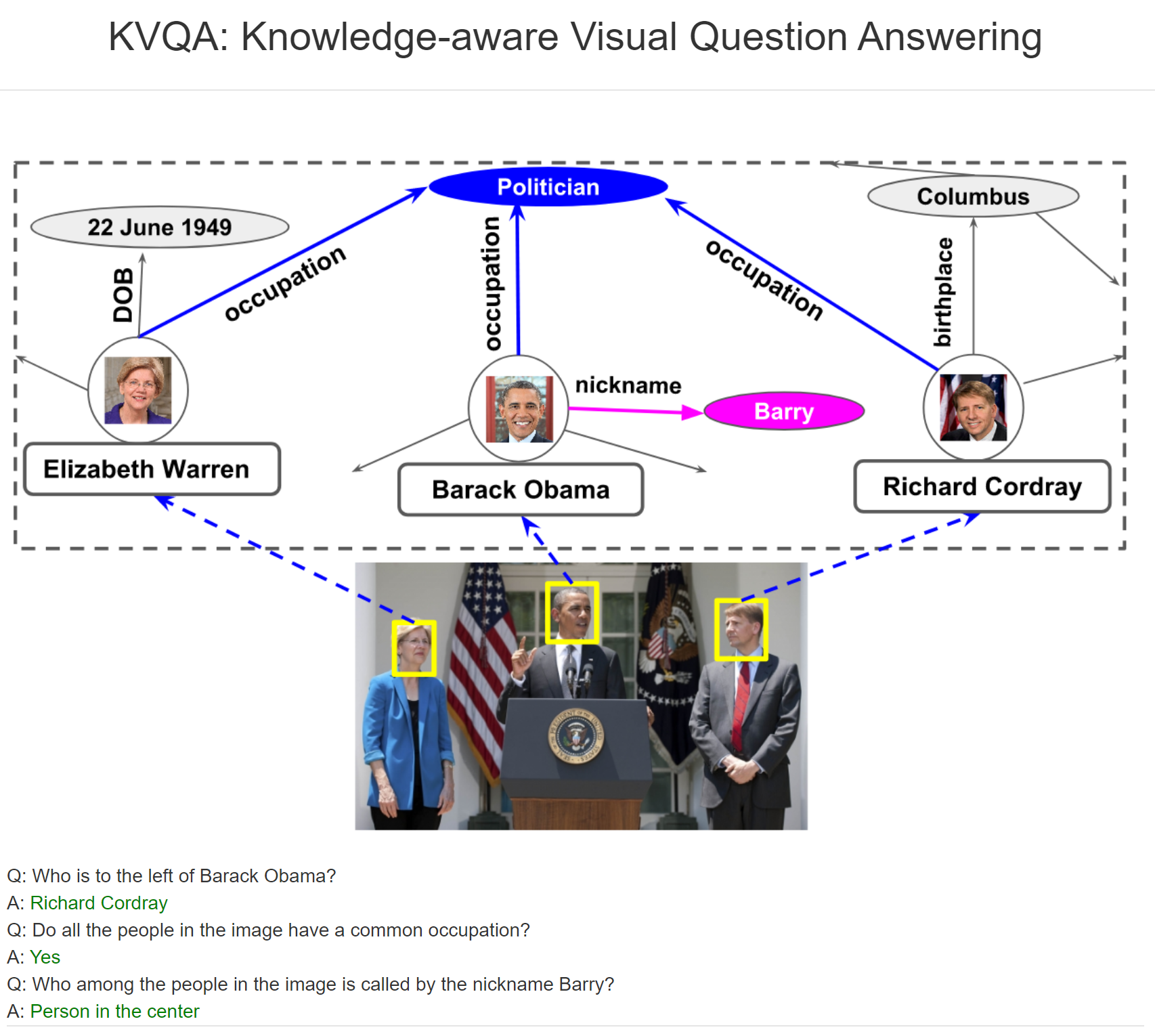
VQA는 AI와 소통하는 데 있어 아주 훌륭한 도구로 자리잡았다. 지난 몇 년간 많은 발전이 있었는데, 우선은 VQA의 시초가 되는 VQA 논문가 있다. 전통적인 VQA는 이미지 등의 시각자료가 주어지면, 이미지에 관련한 질문을 묻고, 이미지에서 얻은 정보를 바탕으로 답변을 하는 방식이다.
위 그림이 주어졌을 때, 전통적인 VQA 질문의 예시는 다음과 같다.
- Q: 이미지에 몇 명의 사람이 있는가?
- A: 3
최근에는 Commonsense Knowledge를 사용해야만 문제를 풀 수 있는 VQA가 더 관심을 받고 있다. 이러한 일반상식의 예시는 다음과 같다.
- Microphone은 소리를 증폭시키는 데 쓴다.
- Microphone은 일반명사이다.
일반상식을 필요로 하는 질문은 다음과 같다.
- Q: 이미지에 있는 것 중 무엇이 소리를 증폭시키는 데 쓰이는가?
- A: Microphone
그러나 실생활에서 문제는 이렇게 간단하지 않고 이미지에 존재하는 고유명사(named entities)에 대한 정보를 필요로 하는 경우가 많다. 예를 들면,
- Q: 버락 오바마의 왼쪽에 있는 사람은 누구인가?
-
A: Richard Cordray
- Q: 이미지에 있는 사람들은 공통 직업을 가지는가?
- A: Yes
그래서 이러한 경우를 다루기 위해 논문에서 KVQA(Knowledge-aware VQA)를 제안한다. 이러한 방향의 연구는 별로 다뤄지지 않았고 또한 필요할 것이라 생각된다.
Wikidata(Vrandecic and Kr¨otzsch 2014)는 대규모 KG로서 사람들, 생물 분류, 행정상 영토, 건축구조, 화합물, 영화 등 5천만 개의 객체를 포함하는 KG이다. 여기서 필요한 것을 추출하는 것은 어렵기 때문에, 논문에선 생략되었다. 대신 이에 대한 배경지식과 관련한 사람들과 수동으로 검증된 질답 쌍을 포함하는 KVQA 데이터셋을 제안한다.
KVQA 데이터셋에서는 visual 고유명사와 Wikidata의 객체를 연결하기 위해 Wikidata에서 69K 명의 사람들 이미지를 포함하도록 했다.
이 논문이 기여한 바는:
- 이미지의 고유명사를 다로는 VQA를 처음으로 다룬다.
- Knowledge-aware VQA인 KVQA 데이터셋을 제안하며 이는 일반상식을 요구하는 기존 데이터셋보다 12배 크며 고유명사를 다룬 것으로는 유일하다.
- KVQA에 SOTA 방법을 적용하여 그 성능을 제시하였다.
관련 연구(Related Works)
- VQA는 2015년 제시된 이후 계속해서 발전하여 2017년 v2.0 데이터셋 발표, (2020년까지) 챌린지를 매년 열고 있다. 비슷한 연구가 많이 발표되었지만 문제가 단순하다는 점에서 한계점이 명확하다.
- 이후에는 일반상식을 필요로 하는 VQA가 많이 연구되어 왔다.
- Computer Vision and Knowledge Graph: 컴퓨터비전과 KG를 연결하려는 데 관심이 늘고 있다. 이는 단지 VQA의 활용에만 그치는 것이 아니라 이미지 분류 등의 전통적인 CV 문제에서도 사용된다. 하지만, 대부분은 이미지와 일반상식 그래프를 연결짓는 데에 치중하고 있다.
- Other Datasets: CV에서 사람을 인식하고 판별하는 것은 주류 연구 분유 중 하나이다. 유명인사나 사람의 자세 추정, 장소 추정 등이 있다.
- Face identification and context: 이미지에 나타나는 고유명사와 KG를 연결하는 것은 web scale에서 얼굴식별의 필요로 이어진다. 얼굴식별은 연구가 많이 이루어졌지만 대부분 작은 규모에서 이루어지고 있다. KVQA이 더 규모가 크기 때문에 좋다는 뜻이다.
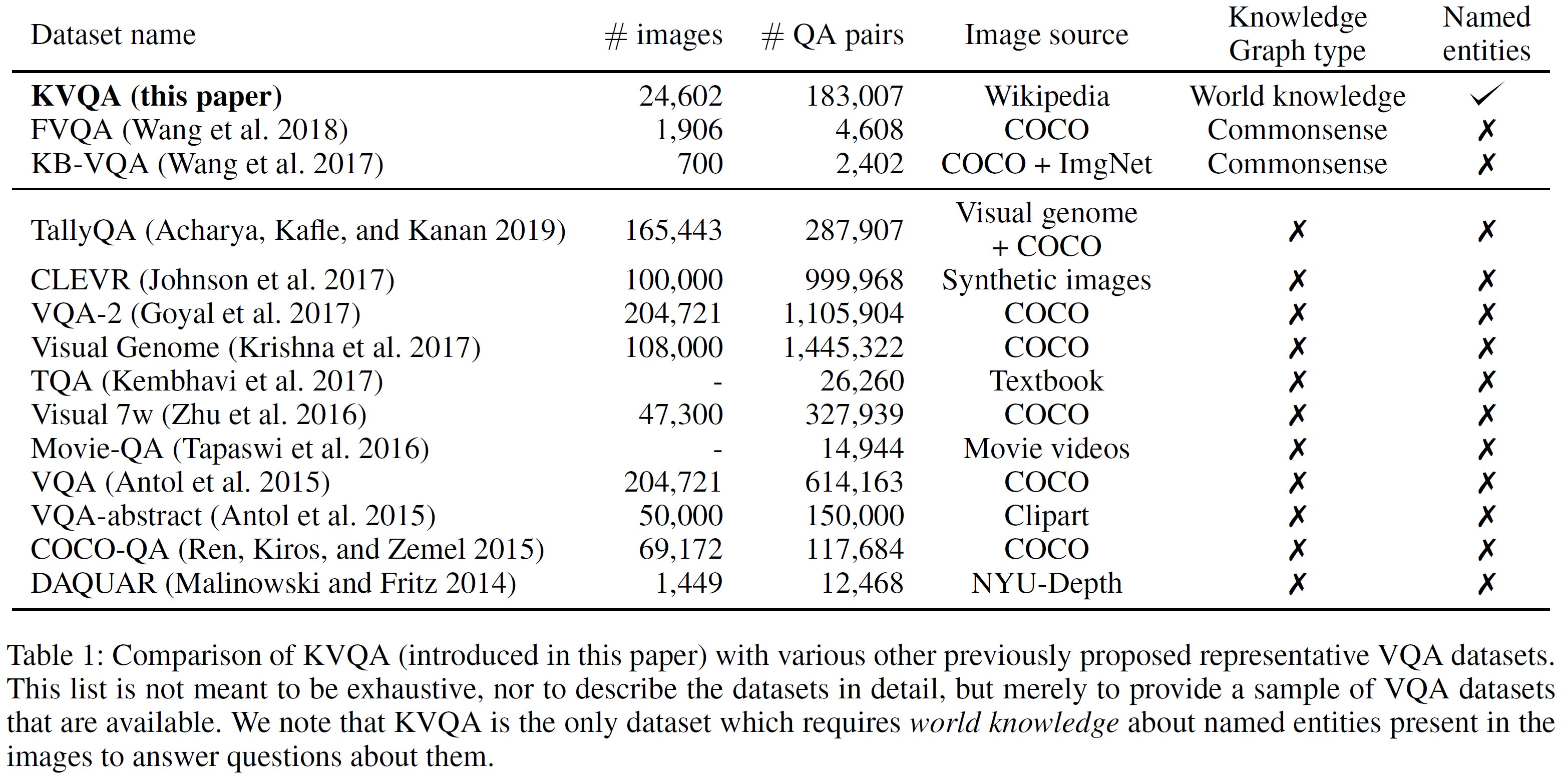
KVQA 데이터셋과 다른 데이터셋을 비교한 표를 아래에서 볼 수 있다:
KVQA 데이터셋(KVQA)
간략한 통계는 아래 표와 같다. 이미지와 질문의 수 등을 볼 수 있고, train/val/test set이 구분되어 있다.

데이터는 다음 과정을 통해 모았다:
- Image Collection: Wikidata로부터 운동선수, 정치인, 배우 등의 사람들의 리스트를 가져와 Wikipedia에서 사람(30K)의 이미지(70K)와 설명을 가져왔다.
- Counting, identifying and ordering persons in image: 이미지의 사람 수를 세고, 사람 수에 따라 human annotator를 부여하였다. 사람이 없거나 너무 많은 경우 등은 제외하고 중복 제거 등을 수행하였다. 그리고 왼쪽부터 오른쪽으로 맞는 human annotator를 부여하였다.
- Obtaining ground-truth answers: 이제 고유명사(사람)와 이미지 안의 관계(왼쪽/오른쪽 등)를 파악하였으니 이미지에 있는 사람에 어떤 질문을 할 수 있는지를 정하여 질문 템플릿을 정하고 SPARQL는 오직 ground truth를 얻기 위해 사용되었다.
- Training, Validation, and testing: train/val/test set을 70/20/10%의 비율로 다른 VQA와 동일하게 구분하였다.
- Paraphrasing questions: task의 복잡도를 늘리고 실세계와 유사하게 만들기 위해 test set의 질문을 다른 표현으로 바꿔서(https://paraphrasing-tool.com/) 이를 수동으로 검증하여 일부를 사용하였다. 예시는:
- 원래 질문: 이미지에 있는 사람들 중 Paula Ben-Gurion와 결혼했던 사람은 누구인가?
- 바뀐 질문: Paula Ben-Gurion과 어떤 시점에선 결혼한 적 있는 사람은 누구인가?

KVQA 데이터셋 분석(Analysis of KVQA)
KVQA는 자세나 인종 등 광범위한 사람들을 다루거나 KG에서 다중도약 추론을 해야 하는 challenge를 포함한다. 질문은 총 10가지 분류로 나뉜다:
spatial, 1-hope, multi-hop, Boolean, intersection, subtraction, comparison, counting, multi-entity, multi-relation
위 분류는 상호 배제적인 것은 아니다. 위 그림의 (c)에서, 추론은 다음과 같이 여러 단계를 거쳐야 한다:
- 왼쪽부터 2번째 사람을 찾고
- Narendra Modi는 BJP의 일원이며
- BJP는 Syama Prasad Mookerjee에 의해 설립되었다.
질문의 종류와 답변의 간략한 분포는 아래와 같이 확인할 수 있다.
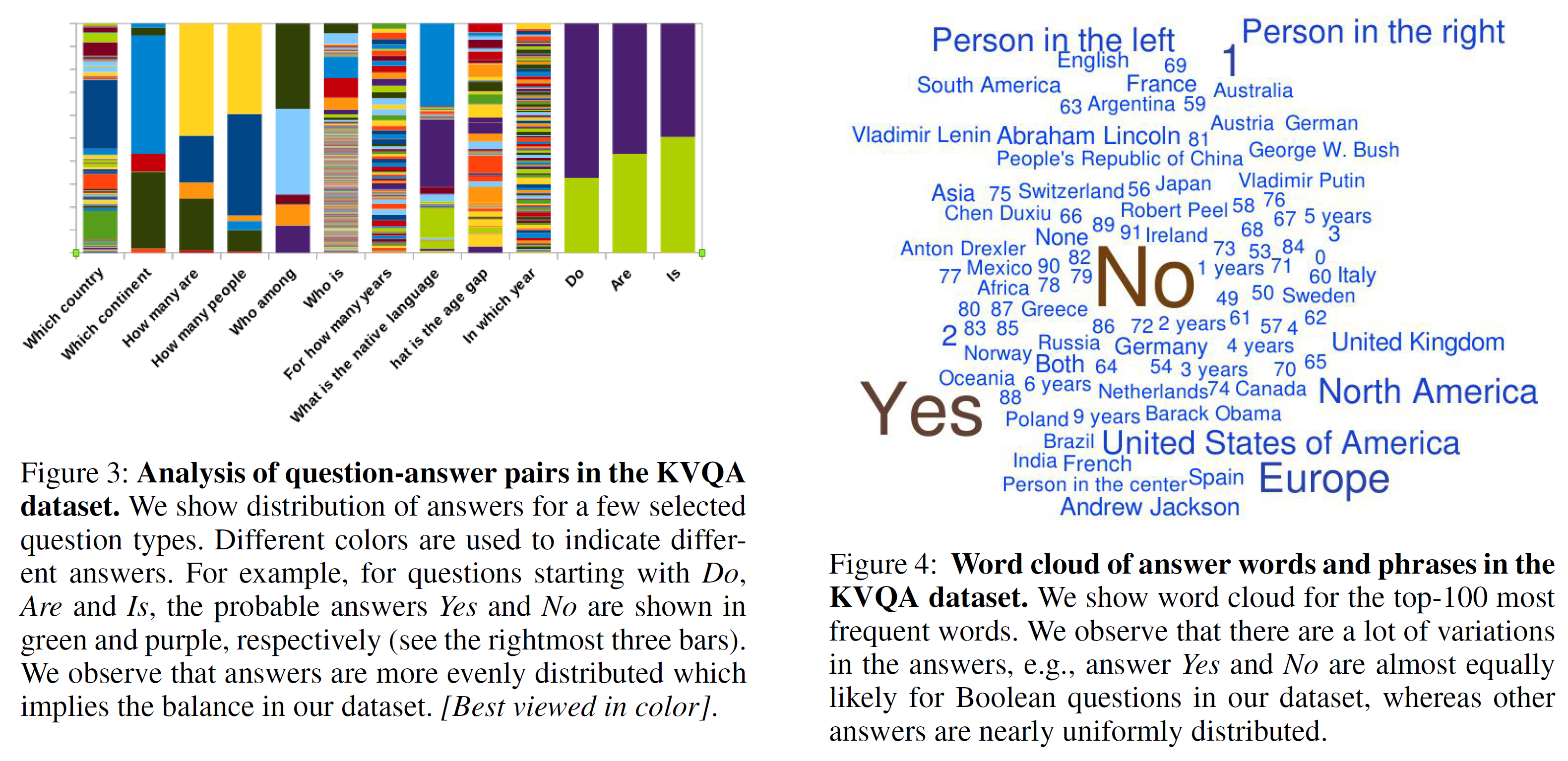
일반적인 VQA에서는 ‘어떤 스포츠인가’라는 질문에는 높은 확률로 ‘테니스’가 정답이고, Yes/no 질문에서는 ‘Yes’가 87%으로 꽤 편향된 것을 볼 수 있다.
단 KVQA는 꽤 균등한 분포를 보이는데, 이는 질문을 다양하게 바꿈으로써 해결한 것이라 한다.
Knowledge Graph(KG)
논문 발표 시점 최신인 2018-05-05 버전의 Wikidata를 KG로 사용하였다. 이는 ‘주어-관계-목적어’의 triplet 형태를 가지고 각 객체와 관계는 고유한 Qid와 Pid로 표현된다(예. Barack Obama는 Q76, has-nickname은 P1449). 이 KG는 5200개의 관계, 1280만개의 객체와 5230만 개의 지식을 포함한다. 이럴 114명K의 사람에 대한 것을 고려하여 Wikidata에서 사람들의 이미지를 가져왔다. 단 데이터가 불완전하여 69K명의 것만 가져왔다. 이 이미지는 visual entity를 연결하는 데 사용된다.
Baseline을 평가하는 두 세팅은 다음과 같다:
- Closed-world setting: 18K의 객체와 3단계 추론을 사용한다. 사실(Facts)은 18종류의 관계만을 포함한다(직업, 시민권 국적, 출생지 등).
- Open-world setting: 훨씬 open된 3단계 추론 실험적 세팅이다. 69K의 객체와 상위 200개의 관계를 포함한다.
접근법(Approach)
Visual Entity Linking
Visual entity linking은 visual entity를 KG에 연결하는 것인데, KVQA에서 visual entity는 사람이다. 그래서 visual entity linking은 안면 식별이 되는데, 사람의 수가 매우 많으므로 그 규모가 매우 크다.
Face identification at scale
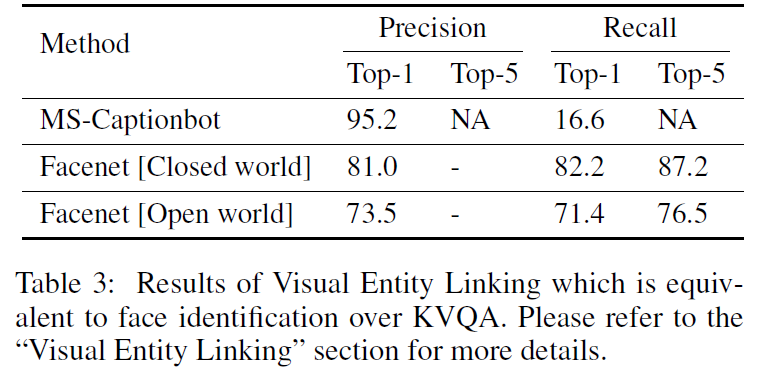
Face Localization은 KVQA에서 안면 식별의 선구자격 역할을 한다. 그래서 두 가지 방법(Zhang et al. 2016; Hu and Ramanan 2017)을 사용해보고 더 좋은 방법(Zhang)을 써서 face localization을 수행한다. 이후 얼굴 식별(face identificatino)을 수행하는데, Baseline으로 Facenet을 선정하여 사용하였다.
그래서 참고 이미지의 face representation을 얻고 1-최근접 이웃을 18K/69K명의 고유명사 이미지에 대해 찾았다. 결과는 아래에서 볼 수 있다.
VQA over KG
일단 Visual Entity를 KG에 열결하면, VQA 문제는 KG로부터 (질문과) 관련 있는 fact를 찾아 추론한 뒤 답변하는 것을 학습하는 것과 같아진다. 이 논문에서는 visual entity linking과 QA를 두 개의 분리된 모듈로 다룬다(end-to-end를 쓰지 않음).
KVQA의 baseline으로 memNet(memory network, Weston at al., 2014)을 썼는데 이 모델은 외부 지식으로부터 학습하는 일반적인 구조를 제공한다(memNet은 상식 요구 VQA에서 SOTA 성능을 보임). 이 논문에서 사용한 모델의 구조는 다음과 같다:
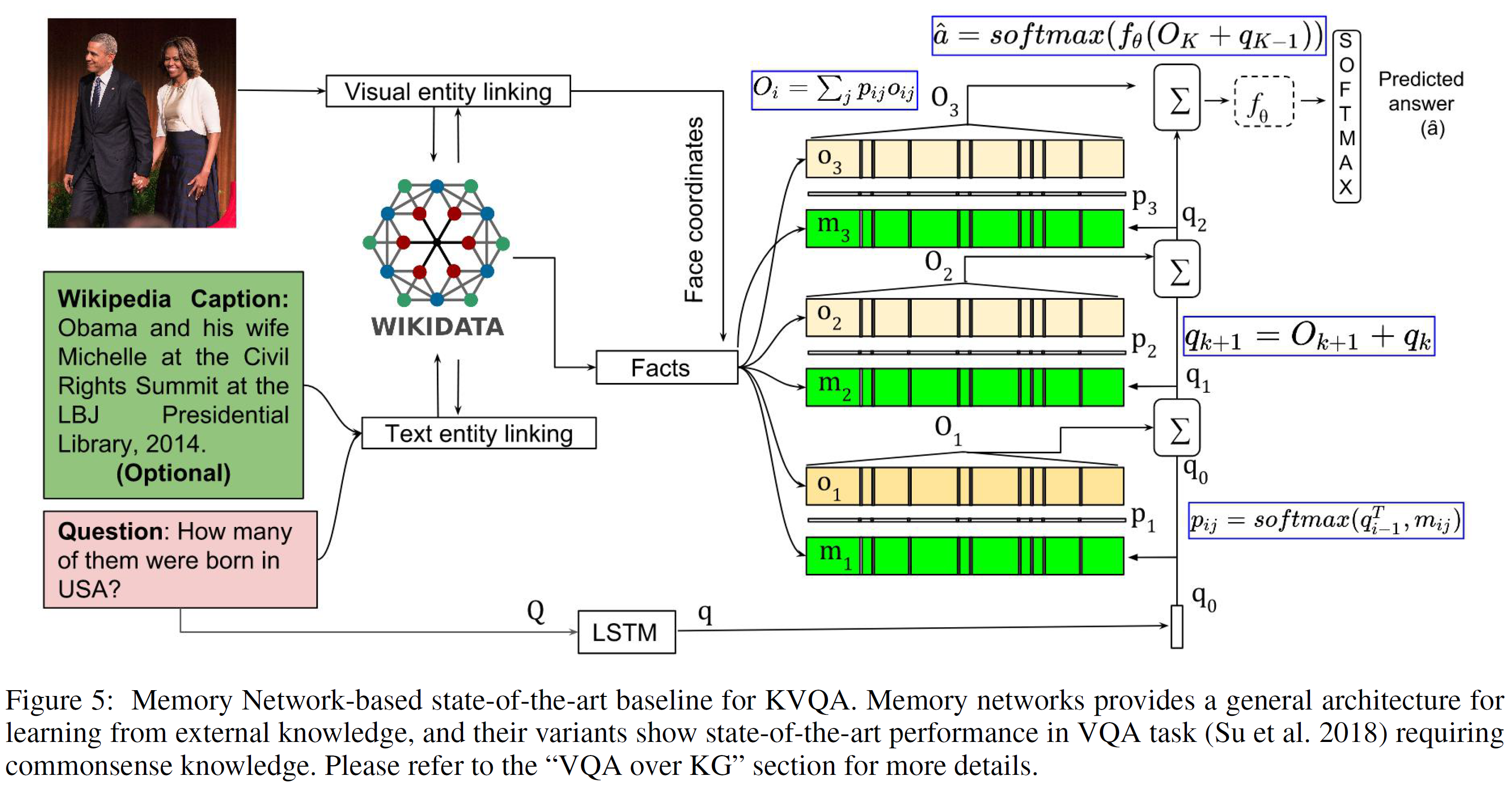
1. Entity Linking
이미지, Wikipedia 캡션(선택적 요소), 질문이 주어지면 이미지와 질문에 있는 entity(visual entities: 사람)를 찾는 것이다. Wikidata에서 가져온 참고 이미지를 활용하며, 텍스트(캡션과 질문)에 있는 entity를 찾기 위해 Dexter 라고 하는 오픈소스 entity recognizer를 사용한다. Visual entity linking과 Text entity linking은 위 그림에서 보듯이 따로 이루어진다.
이 부분에서 entity를 모두 찾고 또한 추가적으로 이미지 상의 entity들의 위치(상대적 위치나 얼굴의 좌표 등)를 얻는다.
2. Fetching facts from KG
이제 entity와 연관 있는 정보를 KG에서 찾는다. 여기서는 3단계(3-hop)만 거치도록 제한하였다. 이러한 knowledge fact들을 공간적 fact(ex. Barack Obama(의 얼굴의 중심)는 (x1, y1) 좌표에 있다)와 함께 보강한다.
그림에서 Facts + Face coornidates라 표시된 부분이다.
3. Memory and question representation
각 knowledge와 공간적 fact는 연관된 memory embedding $m_i$를 얻기 위해 BLSTM에 입력으로 주어진다. 질문 $Q$에 대한 embedding ($q$) 또한 비슷하게 얻어진다.
그리고 $q$와 $m_{ij}$ 사이의 매치되는 정도를 구하기 위해 내적과 softmax를 거친다:
\[p_{ij} = \text{softmax}(q^Tm_{ij})\]여기서 $p_{ij}$는 knowledge fact들과 $Q$ 사이의 soft attention과 같은 역할을 한다. 이를 얻으면 모든 fact에 대한 출력 representation을 선형결합하여 출력 representation을 구한다:
\[O = \sum_j p_{ij}o_{ij}\]$o_{ij}$는 fact $j$에 대한 representation이다.
4. Question answering module
출력 representation $O$와 $q$의 합은 MLP $f_\theta$에 입력으로 들어간다($\theta$는 학습가능한 parameter). 그리고 정답 $\hat{a}$를 구하기 위해 softmax를 적용한다:
\[\hat{a} = \text{softmax}(f_\theta(O+q))\]학습하는 동안, memory/question representation과 QA 모듈을 함께 학습한다. 손실함수는 cross-entropy loss를 사용하였으며 SGD로 최소화한다.
다중도약(multi-hop) facts 탐색을 효율적으로 하기 위해 memory layer를 쌓고 질문 representation을 다음과 같이 구한다:
\[q_{k+1} = O_{k+1} + q_k\]첫 번째 레이어의 질문 representation은 BLSTM으로부터 구해진다. 최상층 레이어(layer K)에서 질문에 대한 답은 다음과 같이 구해진다.
\[\hat{a} = \text{softmax}(f_{\theta}(O_K+q_{K-1}))\]이 논문에서는 3-hop을 사용하므로 $K=3$이다.
Memory Network의 대안은 knowledge facts를 표현하기 위해 BLSTMs를 사용하는 것이다. 이는 baseline의 하나로 사용되었다.
KVQA의 양적평가(quantitative results)는 아래 표의 왼쪽 부분과 같다.
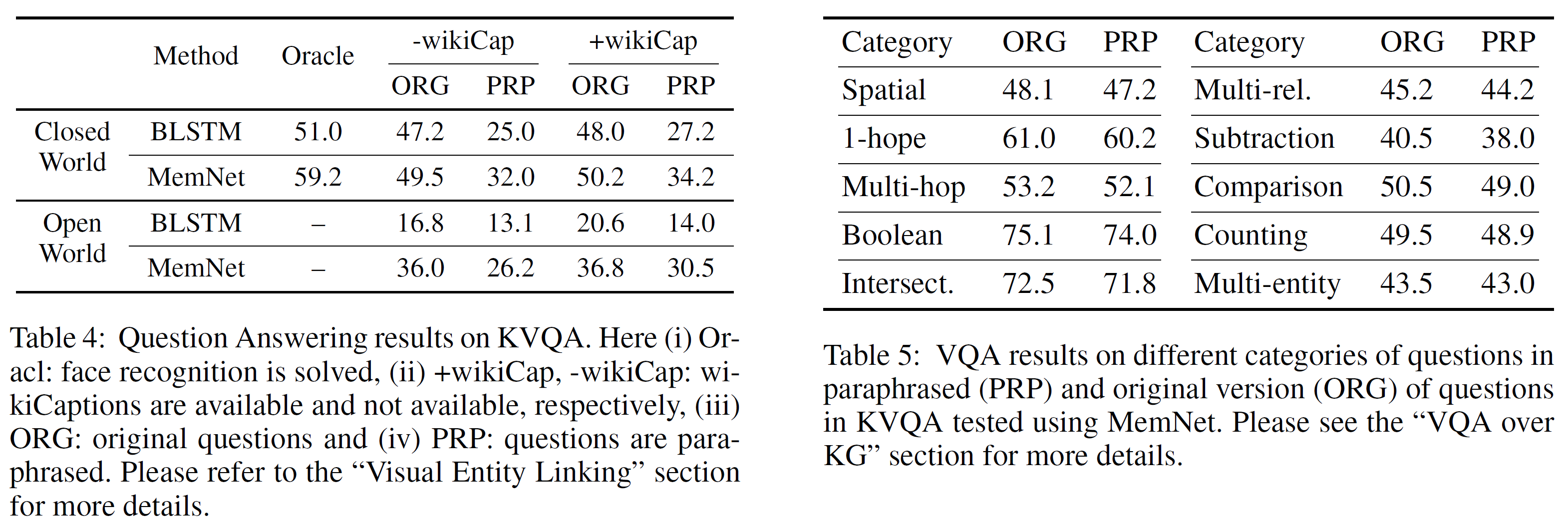
Closed/Open World 각각에 대해 평가하였으며, Wikipedia Caption을 사용했으면 +wikiCap, 아니면 -wikiCap으로 표시되어 있다. 질문을 paraphrase했으면 PRP, 아니면 ORG(original)이다.
모든 평가에서는 고정된 크기의 사전을 사용하였으며 질문에서 각 token, Wikipedia caption, visual entity들은 1-hot 벡터로 표현하였다.
결과를 보면,
- BLSTMs는 fact의 수가 증가할수록 비효율적이었으며 memNet이 이를 압도한다.
- visual entity linking은 많은 수의 다른 요인에 의해 open world에서 실수가 많았으며
- 수많은 fact에서 질문과 관련된 fact를 찾는 것이 어려워지기 때문이다.
- Ablation study에서(위 표에서 오른쪽 부분)는
- KG에서 논리적 추론만에 의한 부분을 연구하기 위한 세팅을 oracle setting이라 한다.
- 이 oracle setting은 각 사람과 이미지 내에서 사람의 순서는 알려져 있다고 가정한다.
- memNet은 공간적, 다중도약, 다중관계, subtraction 등에서 부적합했지만 1-hop, 이지선다 및 교차질문에서는 괜찮은 성능을 보였다.
- 이것은 질문의 종류에 따라 어떤 가이드가 필요하다는 것을 뜻할 수 있다. 이는 추후 연구로 남겨둔다.
논의 및 요약(Discussion and Summary)
얼굴 식별과 VQA에서의 진전에도 불구하고 Knowledge-aware VQA에서 더 많은 연구가 필요함을 보였다. 기존의 Facenet이나 memory network는 수많은 distractor가 존재하거나 규모가 커진 경우에는 제대로 성능을 내지 못하였다.
이 논문에서는 Knowledge-aware VQA인 KVQA를 제안하였고 평가방법과 baseline을 제시하였다. KVQA의 현재 버전은 KG의 중요 entity인 사람에만 국한되어 있다. 하지만 Wikidata와 같은 KG는 기념물이나 사건 등 여러 흥미로운 entity에 대한 정보도 갖고 있기 때문에 추후 확장할 수 있다. 이 분야에 많은 연구가 이루어지길 희망한다.
Acknowledgements
MHRD와 인도 정부, Intel이 지원하였다고 한다..
참고문헌(References)
논문 참조!