
KnowIT VQA - Answering Knowledge-Based Questions about Videos(KnowIT VQA 논문 설명)
24 Nov 2020 | Paper_Review VQA Task_Proposal AAAI2020목차
- KnowIT VQA: Answering Knowledge-Based Questions about Videos
이 글에서는 KnowIT VQA: Answering Knowledge-Based Questions about Videos에 대해 알아보고자 한다.
VQA task는 이미지(Visual, 영상으로도 확장 가능)와 그 이미지에 대한 질문(Question)이 주어졌을 때, 해당 질문에 맞는 올바른 답변(Answer)을 만들어내는 task이다.
KnowIT VQA는 VQA 중에서도 Video를 다루는 QA이며, 전통적인 VQA와는 달리 이미지 등 시각자료에서 주어지는 정보뿐만 아니라 외부 지식(상식 베이스, Knowledge Base)이 있어야만 문제를 풀 수 있는 질의들로 이루어진 새로운 task이다.
KnowIT VQA 홈페이지는 https://knowit-vqa.github.io/ 이다.
데이터셋 중 Annotation도 같은 링크에서 다운받을 수 있다.
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
KnowIT VQA: Answering Knowledge-Based Questions about Videos
논문 링크: KnowIT VQA: Answering Knowledge-Based Questions about Videos
초록(Abstract)
지식기반 그리고 Video QA를 결합한 새로운 영상이해(video understanding) task를 제안한다. 먼저, 유명한 시트콤(참고: 빅뱅이론이다)에 대해 24,282개의 사람이 만든 질답 쌍을 포함하는 video dataset인 KnowIT VQA를 소개한다. 데이터셋은 시각적, 텍스트, 시간적 일관성 추론을 지식기반 질문과 결합하여 이는 시리즈를 봄으로써 얻을 수 있는 경험을 필요로 한다. 그리고 시트콤에 대한 세부적인 지식과 함께 시각적, 텍스트 비디오 자료를 모두 사용하는 영상이해 모델을 제안한다. 이 논문의 주된 결과는 1) (외부) 지식의 결합이 Video QA에 대한 성능을 크게 높여주는 것과 2) KnowIT VQA에 대한 성능은 사람의 정확도에 비해 많이 낮다는 것(현 video 모델링의 한계에 대한 연구의 유용성을 내포함)이다.
서론(Introduction)
VQA는 자연어와 이미지 이해를 함께 평가하는 중요한 task로 지난 몇 년간 많은 종류의 VQA가 제안되고 연구되어왔다. 특히 초기 연구와 그 모델들은 주로 이미지의 내용에만 집중하는 형태를 보여 왔다(질문의 예: 안경을 쓴 사람이 몇 명이나 있는가?).
단지 이미지-이미지에 대한 질문을 묻는 것은 한계가 명확했다.
- 이미지의 features는 오직 이미지의 정적인 정보만을 잡아낼 뿐 video에 대한 시간적인 일관성이나 연관성은 전혀 고려하지 않았다(예: 그들은 어떻게 대화를 끝내는가?).
- 시각 자료(이미지나 영상)는 그 자체로는 외부 지식을 필요로 하는 질문에 대답하는 충분한 정보를 포함하지 않는다.
이러한 한계를 해결하기 위해 단순 이미지와 질문만을 사용하는 Visual QA에서 1) 영상을 사용하는 VideoQA, 2) 외부 지식을 활용하는 KBVQA 등이 등장하였다. 하지만, 여러 종류의 질문을 다루는 일반적인 framework는 여전히 나오지 않았다.
이 논문의 기여하는 바는 여기서부터 출발한다. 영상에 대한 이해와, 외부 지식에 기반한 추론을 모두 활용하는 방법을 제안한다.
- 영상을 활용하기 위해 유명 시트콤인 빅뱅이론에다 annotation을 더하여 KnowIT VQA dataset을 만들었다. 질문들은 시트콤에 익숙한 사람만이 대답할 수 있는 수준으로 만들어졌다.
- 특정 지식을 continuous representation으로 연결하여 각 질문에 내재된 의도를 추론하는 모듈과 얻어진 지식을 영상 및 텍스트 내용과 결합하여 추론하는 multi-modal 모델을 제안한다.

관련 연구(Related Work)
- Video Question Answering은 행동인식, 줄거리 이해, 시간적 연관성을 추론하는 등의 시간적 정보를 해석하는 문제들을 다뤄 왔다. 영상의 출처에 따라 시각자료는 자막이나 대본 등 텍스트 자료와 연관되어 해석을 위한 추가 수준의 문맥을 제공한다. 대부분의 연구는 영상이나 텍스트 자체의 정보를 추출할 뿐 두 modality의 결합은 제대로 활용하지 않았다. MovieFIB, TGIF-QA, MarioVQA는 행동인식, Video Context QA는 시간적 일관성을 다룬다.
- 오직 몇 개의 데이터셋, PororoQA와 TVQA만이 multi-model video representation을 함께 해석하는 benchmark를 제안하였다. 하지만 영상자료를 넘어서는 추가 지식에 대한 고려는 이루어지지 않았다.
- Knowledge-Based Visual Question Answering: 시각자료와 텍스트만 가지고서는 그 자체에 내재된 정보 외에 추가 지식은 전혀 쓸 수가 없다. 그래서 외부 지식을 포함하는 VQA가 여럿 제안되었다. KBVQA(Knowledge-based VQA)는 외부 지식을 활용하는 대표 VQA 중 하나이다. 이는 지식을 포함하는 데이터셋이지만 초기 단계에 머물러 있다.
- 그 중 일부 dataset은 질문의 형태가 단순하거나 외부 지식이 정해진 형태로만 제공되었다. KB-VQA는 template에서 만들어진 질문-이미지 쌍을 활용했으며, R-VQA는 각 질문에 대한 relational facts만을 사용했다. FVQA는 entity 식별, OK-VQA는 자유형식의 질문을 사용하였으나 지식에 대한 annotation이 없었다.
- KnowIT-VQA는 영상을 활용하며, 지식을 특정 데이터에서 직접 추출한 것이 아닌 일반지식을 가져왔기에 이러한 단점들을 해결하였다고 한다.
KnowIT VQA 데이터셋(KnowIT VQA Dataset)
TV Show는 인물, 장면, 줄거리의 일반적인 내용들을 사전에 알 수 있기에 영상이해 task에서 현실 시나리오를 모델링하는 좋은 과제로 여겨진다. 그래서 이 논문에서는 유명 시트콤인 빅뱅이론을 선정하여 KnowIT VQA dataset으로 만들었고, 이는 영상과 show에 대한 지식기반 질답을 포함한다.
Video Collection
영상은 빅뱅이론 TV show에서 가져왔으며, 이는 각 20분 정도의 207개의 episode들로 구성된다. 텍스트 데이터는 DVD에 있는 자막(대본)을 그대로 가져왔다. 각각의 대사는 시간과 화자(speaker)의 순서에 맞게 주석을 달았다. 영상은 scene으로 나누어지며 이는 또 20초 정도의 clip으로 분리되어, 총 12,264개의 clip이 있다.
QA Collection
Amazon Mechanical Turk (AMT)를 사용하였으며 빅뱅이론에 대해 깊은 이해도를 갖는 사람들로 하여금 질답을 생성하도록 했다. 목표는 show에 친숙한 사람들만이 질문에 대답할 수 있도록 하는 질문(그리고 답)을 만드는 것이었다. 각 clip에 대해, 영상과 자막을 각 episode의 대본과 요약과 연결시키도록 했다. 각 clip은 질문, 정답, 3개의 오답과 연관된다.
Knowledge Annotations
여기서 “knowledge”(지식)이란 주어진 영상 clip에 직접 포함되지 않는 정보를 가리킨다. 질답 쌍은 추가 정보로 annotated되어:
- Knowledge: 짧은 문장으로 표현되는 질문에 대답하기 위해 필요한 정보.
- 질문: 왜 Leonard는 Penny를 점심에 초대했는가?
- Knowledge: Penny는 이제 막 이사를 왔다.
- 정답: 그는 Penny가 빌딩에서 환영받는다고 느끼기를 원했다.
- Knowledge Type: Knowledge가 특정 episode에서 왔는지, 아니면 show의 많은 부분에서 반복되는지(recurrent)를 말한다. 6.08%의 Knowledge만이 반복되며 나머지 9개의 season에 속하는 Knowledge는 거의 균등하다. 분포와 Knowledge의 예시를 아래 그림에서 볼 수 있다.
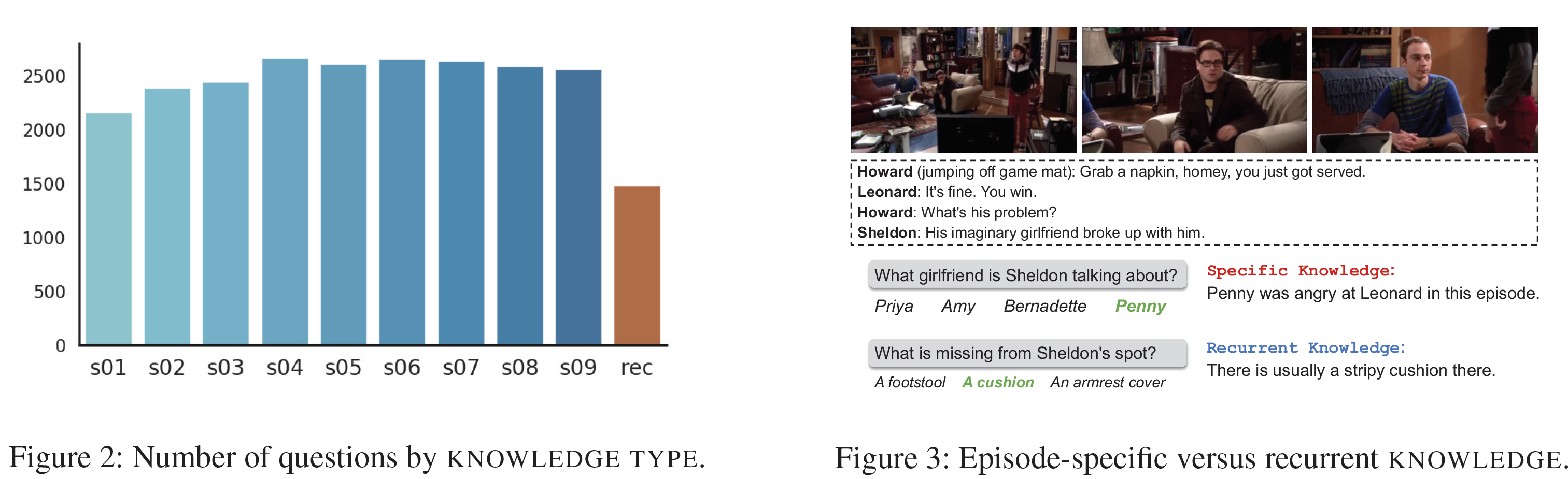
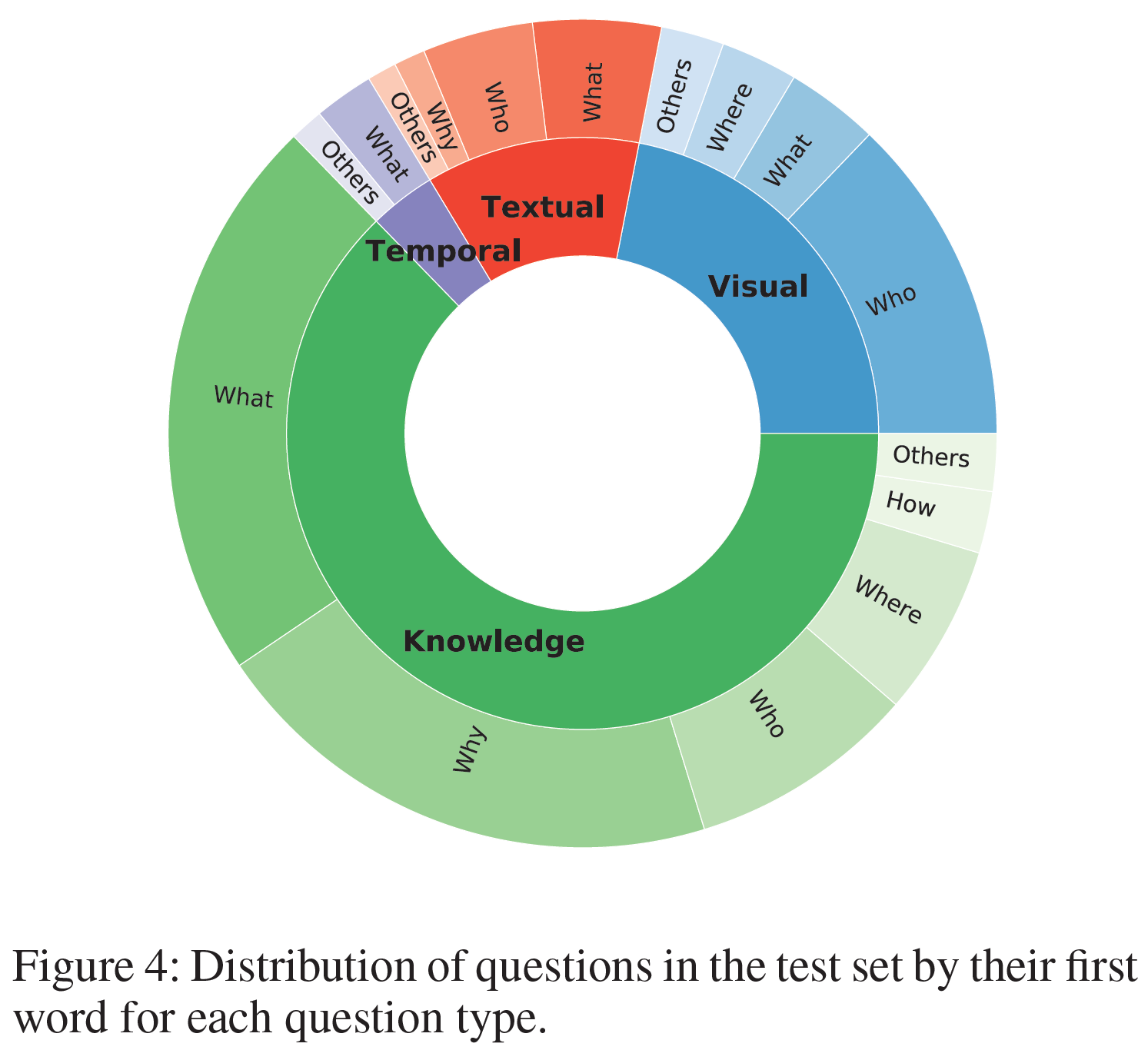
- Question Type: 범용 모델의 개발을 장려하기 위해 test set에서만 제공되며, 4가지 종류로 구분된다:
- visual-based(22%): video frame 안에서 답을 찾을 수 있다.
- textual-based(12%): 자막에서 답을 찾을 수 있다.
- temporal-based(4%): 현재 video clip의 특정 시간에서 답을 예측 가능하다.
- knowledge-based(62%): clip만으로는 답을 찾을 수 없다(외부 지식이 필요하다).
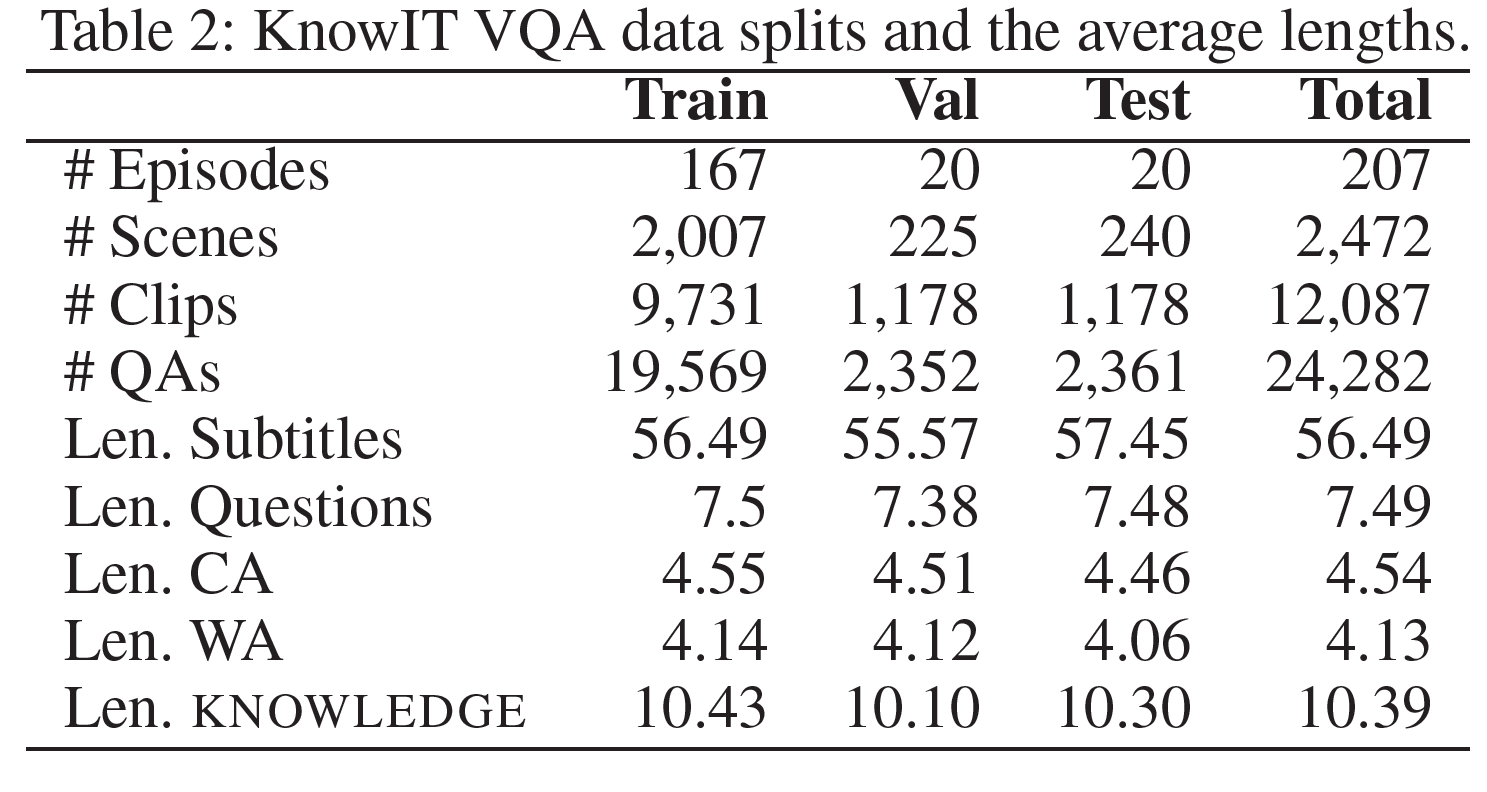
Data Splits
12,087개의 video clip으로부터 24,282개의 sample을 추출하였으며 train/val/test set으로 구분되었다. 일반적인 QA dataset처럼 정답은 오답보다 살짝 더 길이가 긴 편향이 존재한다.
Dataset Comparison
KnowIT VQA 데이터셋과 다른 데이터셋을 비교한 표를 아래에서 볼 수 있다:
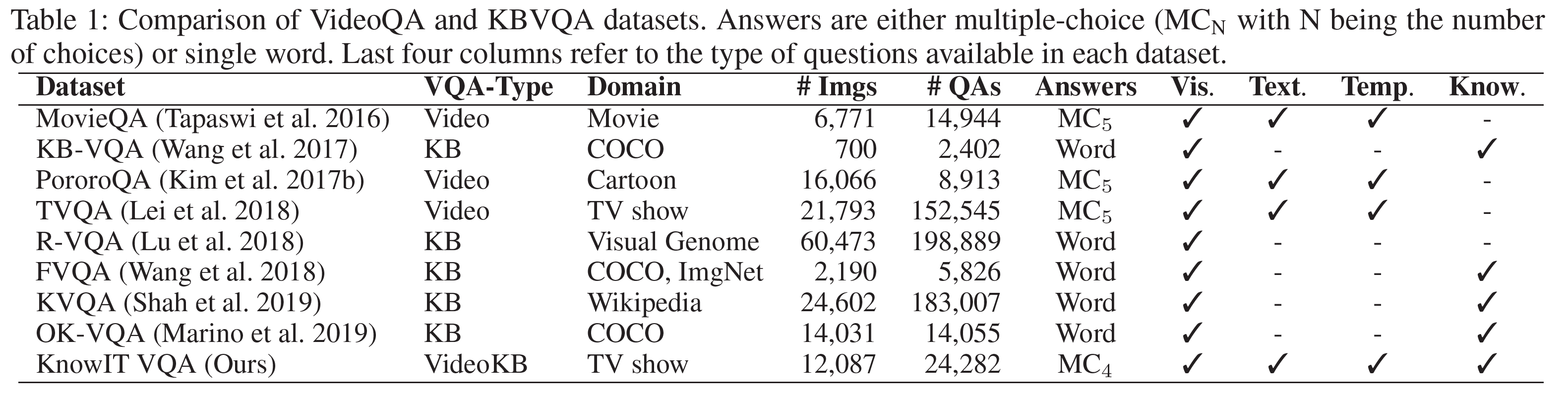
- QA 생성이 더 까다롭기 때문에 KBVQA의 크기가 작다.
- KnowIT VQA는 질문의 수가 24k개로 2.4k의 KB-VQA, 5.8k의 FVQA, 14k의 OK-VQA에 비해 훨씬 많다.
- TVQA와 영상이 일부 겹치지만 KnowIT VQA는 더 많은 clip을 사용하였다.
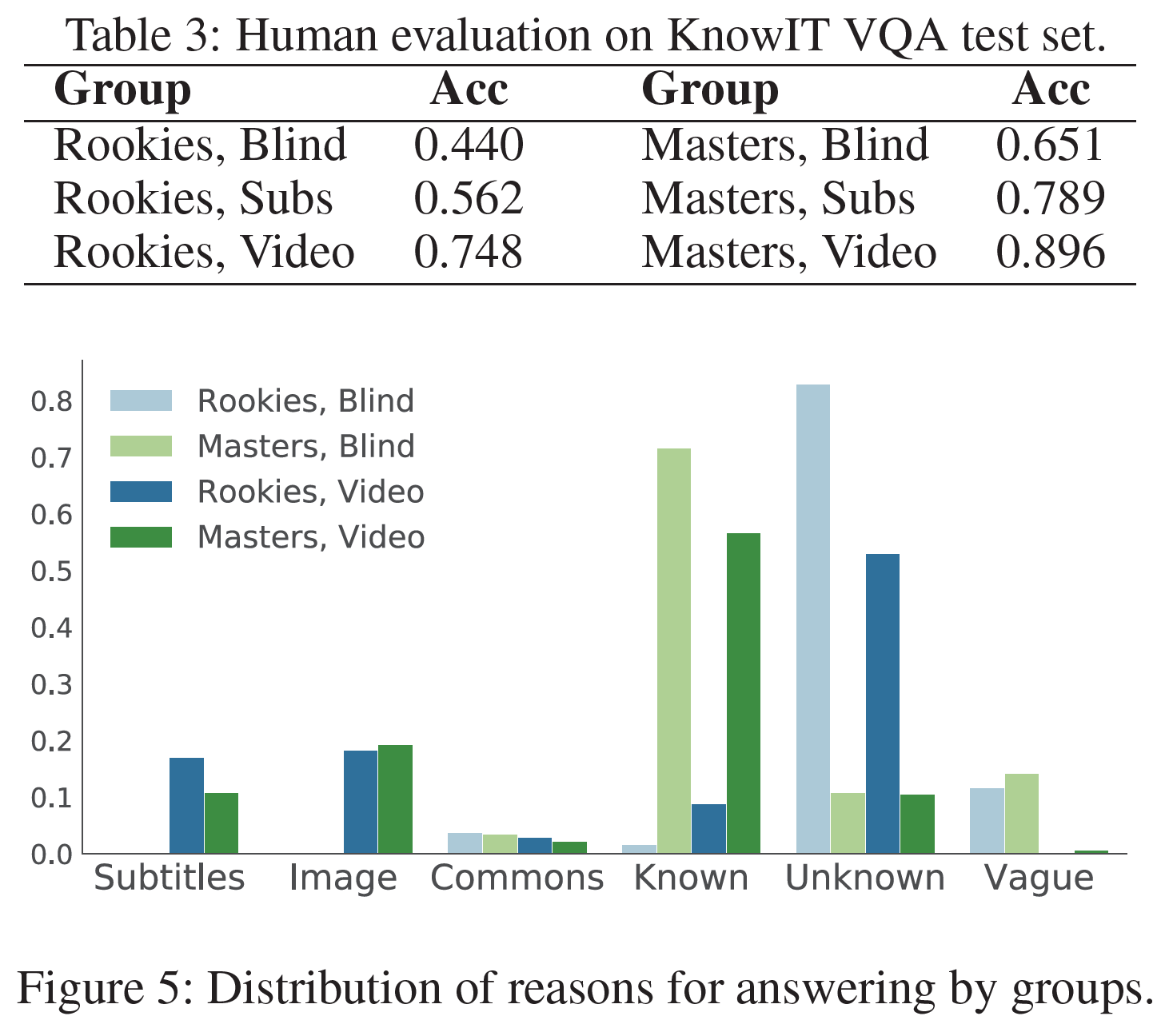
인간 평가(Human Evaluation)
다음의 목적에 따라 평가를 진행하였다:
- video clip이 질문에 답하는 것과 연관이 있는지
- 질문이 답변하는데 Knowledge를 실제로 필요로 하는지
- Knowledge가 답변하는 데 정말로 도움이 되는지
- 모델 비교를 위한 human performance baseline을 설정하기 위해
Evaluation Design
AMT를 사용하였고, worker를 1) 9개의 시즌 전부를 적어도 한 번은 본 masters 그룹과 2) 빅뱅이론을 조금도 본 적 없는 rookies로 구분하였다. 질문에 대한 평가와 knowledge에 대한 평가를 중심으로 진행하였다.
Evaluation on the questions
위의 두 그룹은 각각 Blind(질답만 제공), Subs(질답과 자막 제공), Video(질답, 자막, 영상 clip 제공)으로 구분되었다. worker들은 4지선다형 중 맞는 답과 그 답을 선택한 이유를 6지선다형으로 풀게 하였다.
- Subs와 Video 그룹의 차이는 video의 영향을 보여준다.
- masters와 rookies 그룹의 차이는 knowledge의 중요성을 보여주며 KnowIT VQA는 show를 보지 않았을 때 굉장히 어려운 task임을 보여준다.
Evaluation on the knowledge
모아진 Knowledge의 품질과 질문 간 연관성을 분석하였다. rookies들에게 test set의 질문에 대답하도록 하였다. 각 질문과 선택지에 대해 자막과 video clip이 제공되었다. 답을 한 후에는 연관된 Knowledge를 보여주고 다시 답변하도록 하였다. 결과적으로 Knowledge가 주어지기 전후로 정확도는 0.683에서 0.823으로 증가하였다. 이는 답변을 하는 데 있어 Knowledge의 연관성(그리고 그 중요성)을 보여 준다.
ROCK Model
ROCK (Retrieval Over Collected Knowledge) 모델의 구조는 다음과 같다.
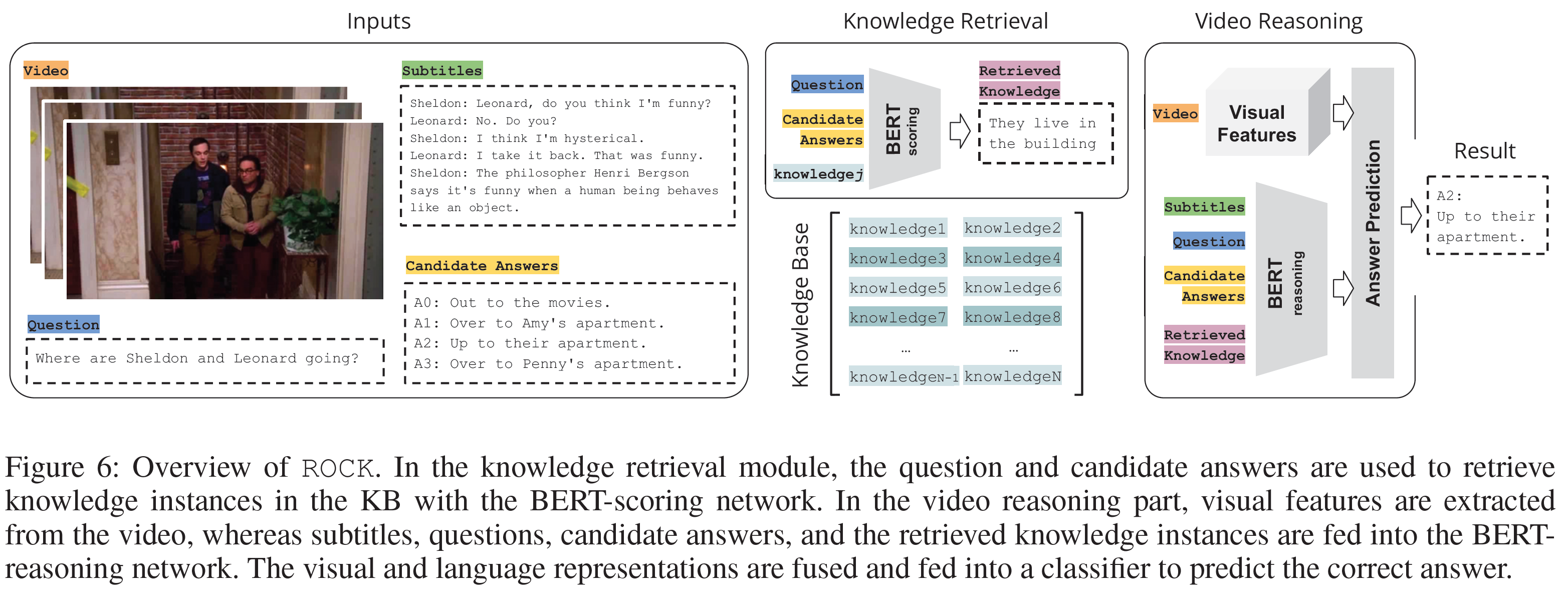
- Knowledge Base(KB)에 있는 show 정보를 표현하는 언어 instance에 기초한다.
- 언어와 시공간적 영상 표현을 합하여 질문에 대해 추론하고 답을 예측한다.
Knowledge Base
시청자가 시리즈를 볼 때 정보를 습득하는 것을 모방한다. show에 대해 특정 정보에 접근해야 하기 때문에, Knowledge의 AMT worker 주석에 의존한다.
모아진 Knowledge는 자연어 문장의 형태로 주어진다. ‘Raj가 Penny 집에서 한 것은 무엇인가?’라는 질문에서 주석 Knowledge는 다음과 같다:
Raj는 Missy에게 데이트하자고 요청하길 원했는데, Howard와 Leonard는 이미 그녀에게 물어봤지만 실패했기 때문이지만, (그가 먹었던) 약효가 사라졌고 그는 그럴(요청할) 수 없었다.
Knowledge Graphs와 같은 복잡한 구조에서 어떻게 정보를 가져오는지 불분명하기에, knowledge instance $w$는 자연어 문장으로 표현된다. 거의 중복되는 instance를 제거하였고, $N$은 24,282에서 19,821로 줄어들었다.
Knowledge base $K$는 다음과 같다.
\[K = \lbrace w_j \vert j=1, ..., N \rbrace\]Knowledge Base Cleaning
거의 중복되는 문장을 제거하기 위해 Knowledge instance 사이의 유사도를 측정하였다. 각 $w_j \in K$에 대해 다음과 같은 입력 문장을 만들었다:
\[w_j^{'} = [\text{CLS}] + w_j + [\text{SEP}]\][CLS]는 문장의 시작을, [SEP]은 끝을 나타내는 token이다. 이를 60개의 token으로 나눈 뒤 BERT를 통과시켜 고차원의 projection을 얻었다.
\[\mathbf{p}_j = \text{BERT}_{\mathbf{p}}(\tau_j)\]두 문장의 유사도는 cosine 유사도를 사용하였으며 다음과 같이 구해진다.
\[\beta_{i, j} = sim(\mathbf{p}_i, \mathbf{p}_j)\]그리고 무향 그래프 $V$를 만들고 유사도 $\beta$가 0.998 초과인 경우에만 edge를 만들었다. 해당 그래프에서 크기 $L$ 이상의 clique를 찾아 임의로 1개만 남기고 나머지는 삭제하였다.
\[V = \lbrace w_j \vert j=1, ..., N\rbrace\]Knowledge Retrieval Module
전체 과정은 다음과 같다.
질문과 답안 선택지 $q_i, a_i^c, \quad c \in \lbrace 0, 1, 2, 3\rbrace$를 사용하여 Knowledge base $K$에 질의를 한다.
그리고 연관도 점수 $s_{ij}$에 따라 $w_j \in K$의 순위를 매긴다.
먼저 입력이 될 표현 $x_{ij}$를 다음과 같이 문자열들을 이어 붙여 구한다.
\[x_{ij} = [\text{CLS}] + q_i + \sum_{k=0}^3 a_i^{\alpha_k} + [\text{SEP}] + w_j + [\text{SEP}]\]이전 연구들은 $a_i^c$의 순서는 별다른 영향이 없다고 하였지만, 불변성을 확보하기 위해 연관도가 높은 순($a_i^0 \rightarrow a_i^3$)으로 정렬하였다.
- 그리고 입력 표현을 $n$개의 단어로 이루어진 sequence $\textbf{x}_{ij}^{10}$으로 토큰화하고 BERT에 입력으로 준다.
- 점수를 매기기(scoring) 때문에 $\text{BERT}^{\text{S}}(\textbf{x}_{ij})$로 표기한다.
- $s_{ij}$를 계산하기 위해 fully connected layer를 사용하고 sigmoid를 붙인다.
- $\textbf{w}, b$를 각각 FC Layer의 weight와 bias라 할 때
$\text{BERT}^{\text{S}}, \textbf{w}, b$는 매칭되거나 되지 않는 QA-knowledge 쌍과 다음의 Loss로 미세조정(fine-tuned)된다:
\[\mathcal{L} = -\sum_{i=j} \log(s_{ij}) -\sum_{i\neq j} \log(1 - s_{ij})\]각 $q_i$에 대해 $K$ 안의 모든 $w_j$는 $s_{ij}$에 의해 순위가 매겨진다. 이중 상위 $k$개가 질의로 주어진 질문과 가장 연관 있는 것으로써 이것들이 얻어진다.
Prior Score Computation
모델이 다른 답변 후보에 대해 다른 출력을 내는 것을 막기 위해 답안들을 정렬함으로써 순서에 불변적인 모델을 만들었다. prior score $\xi^c$에 따라
\[a^c, \quad c \in \lbrace 0, 1, 2, 3\rbrace\]질문 $q$가 주어지면, $\xi^c$는 정답에 대한 $a^c$의 점수를 예측함으로써 얻어진다. 먼저 입력문장 $e^c$를 문자열을 이어 붙여 얻는다:
\[e^c = [\text{CLS}] + q + [\text{SEP}] + a^c + [\text{SEP}]\]그리고 $e^c$를 120개의 토큰 $\mathbf{e}^c$로 토큰화한다. $\text{BERT}_{\text{E}}(\cdot)$를 output이 [CLS]인 BERT 네트워크라 한다면,
\[\xi^c = \textbf{w}_{\text{E}}^{\top} \text{BERT}_{\text{E}}(\mathbf{e}^c) + b_E\]이제 모든 $\xi^c$를 내림차순으로 정렬한 후 이에 맞춰 답변 후보 $\alpha_c$를 재배열한다.
Video Reasoning Module
이 모듈에서는 얻어진 knowledge들이 영상 내용으로부터 얻은 multi-modal 표현과 함께 처리되어 정답을 예측한다. 이 과정은 다음 3가지 과정을 포함한다.
- Visual Representation
- Language Representation
- Answer Prediction
Visual Representation
각 video clip으로부터 $n_f$개의 프레임을 뽑아 영상 내용을 설명하기 위해 아래 4가지의 다른 과정을 거친다:
- Image features: 각 frame은 마지막 FC Layer가 없는 Resnet50에 들어가 2048차원의 벡터로 변환된다. 모든 frame에서 나온 벡터를 모아 새로운 FC Layer를 통과시켜 512차원으로 만든다.
- Concepts features: 주어진 frame에 대해, bottom-up object detector를 사용하여 object과 특성들의 리스트를 얻는다. 이를 전부 인코딩하여 $C$차원의 bag-of-concept 표현으로 만들고, FC Layer를 통해 512차원으로 변환된다. $C$는 가능한 모든 object와 특성들의 전체 수이다.
- Facial features: 주요 인물의 사진 3~18개를 사용하여 최신 얼굴인식 네트워크를 학습시켰다. 각 clip에 대해 $F$차원의 bag-of-faces 표현으로 인코딩하여, FC Layer를 통과시켜 512차원으로 만든다. $F$는 네트워크에서 학습되는 모든 사람의 수이다.
- Caption features: 각 frame에 대해 영상 내용을 설명하는 캡션을 Xu et al. 2015으로 만들었다. 각 clip으로부터 얻은 $n_f$개의 캡션은 언어표현 모델의 입력으로 사용된다.
Language Representation
텍스트는 미세조정된 BERT-reasoning을 통과한다. 언어입력은 다음과 같이 구해진다.
\[y^c = [\text{CLS}] + caps + subs + q + [\text{SEP}] + a^c + w + [\text{SEP}]\]$caps$는 $n_f$개의 캡션을 시간순으로 이어 붙인 것이고 $subs$는 자막, $w$는 $k$개의 knowledge instance를 합친 것이다.
각 질문 $q$에 대해, 답변 후보 $a^c, \ c = \lbrace 0, 1, 2, 3\rbrace$ 하나당 하나씩 총 4개가 생성된다.
$m$개의 단어로 이루어진 $\mathbf{y}^c$로 토큰화하고 언어표현 $\mathbf{u}^c = \text{BERT}_{\text{R}}(\mathbf{y}^c)$를 얻는다. (R은 reasoning)
Answer Prediction
정답을 예측하기 위해, 시각표현 $\textbf{v}$(images, concepts, facial features)를 언어표현 $\mathbf{u}^c$를 이어 붙인다:
\[\textbf{z}^c = [\mathbf{v}, \mathbf{u}^c]\]$ \textbf{z}^c$는 scalar로 사영된다.
\[o^c = \textbf{w}_{\text{R}}^{\top}\textbf{z}^c + b_R\]예측된 답안 $\hat{a} = a^{\text{argmax}_c\textbf{o}}$는 $\textbf{o} = (o^0, o^1, o^2, o^3)^\top$ 중 최댓값의 index로 구해진다. $c^*$를 정답이라고 하면 multi-class cross-entropy loss를 써서 미세조정한다:
\[\mathcal{L}(\mathbf{o}, c^*) = - \log \frac{\exp(o^{c^*})}{\Sigma_c \exp{(o^c)}} \qquad \text{for} \ \text{BERT}_{\text{R}}, \textbf{w}_{\text{R}}, b_{\text{R}}\]실험 결과(Experimental Results)
ROCK 모델을 여러 기준 모델과 비교하여 아래에 정리하였다. SGD를 사용하여 momentum 0.9, learning rate는 0.001을 사용하였으며 BERT는 사전학습된 초기값을 사용한 uncased based 모델을 사용하였다.
Answers
데이터셋에 존재할 수 있는 잠재적 편향을 찾기 위해서 단지 답변 자체만을 고려하여 정답을 예측하는 평가를 진행하였다:
- Longest / Shortest: 예측 답변이 가장 많거나 적은 단어를 포함하는 답을 선택한다.
- word2vec / BERT sim: word2vec은 300차원의 사전학습된 벡터를 사용하였다. BERT에서는 3번째~마지막 layer의 출력을 사용하였다. 답변은 word representation의 평균으로 인코딩되었다. 예측은 가장 높은 코사인 유사도를 갖는 것을 선택한다.
전체적으로, baseline은 매우 낮은 성능을 보였으며, Longest만이 찍는 것보다 간신히 나은 성능을 보였다. 정답이 긴 경우가 조금 많은 것을 제외하면 데이터셋에서는 특별한 편향은 발견되지 않았다.
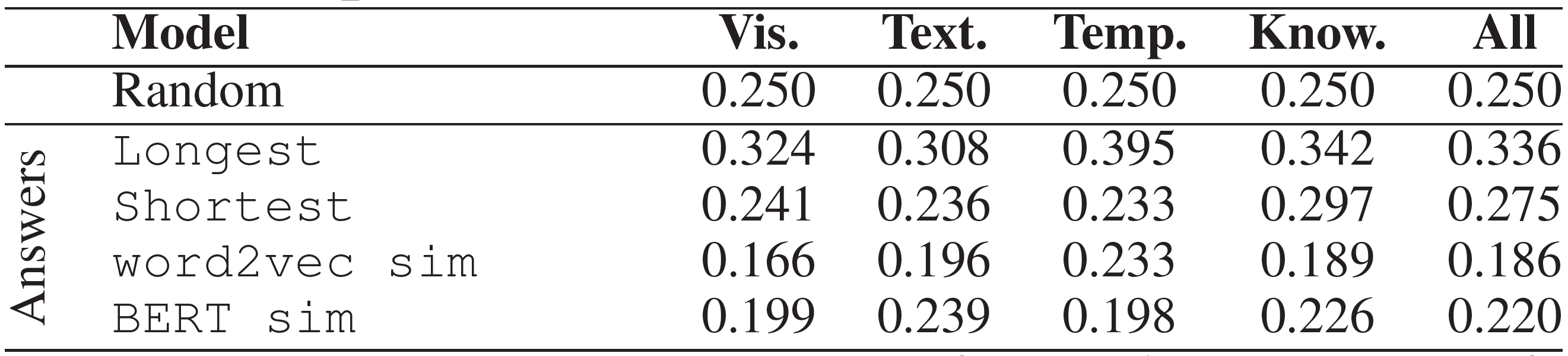
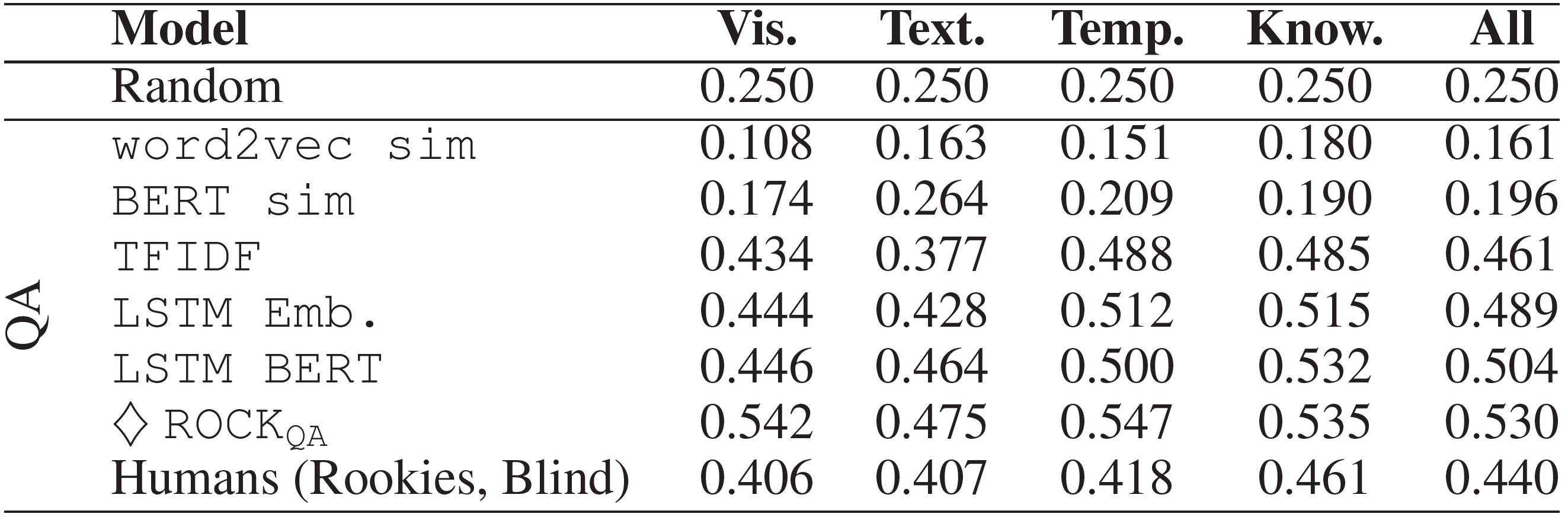
QA
오직 질문과 답변만을 고려하여 여러 baseline에 대해 실험을 진행하였다.
- word2vec / BERT sim: 위의 Answers와 비슷하게 진행되었으며 질문이 고려 대상에 추가되었다.
- TF IDF: tf-idf에 의한 단어벡터 가중으로 질문과 답변을 표현한 후 512차원으로 만들었다. 질문과 4개의 답변을 이어 붙여 4-class 분류기에 집어넣었다.
- LSTM Emb. / BERT: 질문과 답변들의 단어를 사전학습된 BERT와 LSTM에 통과시킨다. LSTM의 마지막 layer는 512차원의 문장표현으로 사앵되었다. 역시 각각을 이어 붙여 4-class 분류기에 넣었다.
- ROCK_QA: $m = 120$ token을 사용하는 ROCK 모델을 질문과 답변만으로 학습시켰다.
유사도에 기반한 방법을 찍는 것보다 형편없지만, 분류기를 사용한 경우는 훨씬 더 나은 결과를 보이며, 사람보다 더 잘하기도 했다.
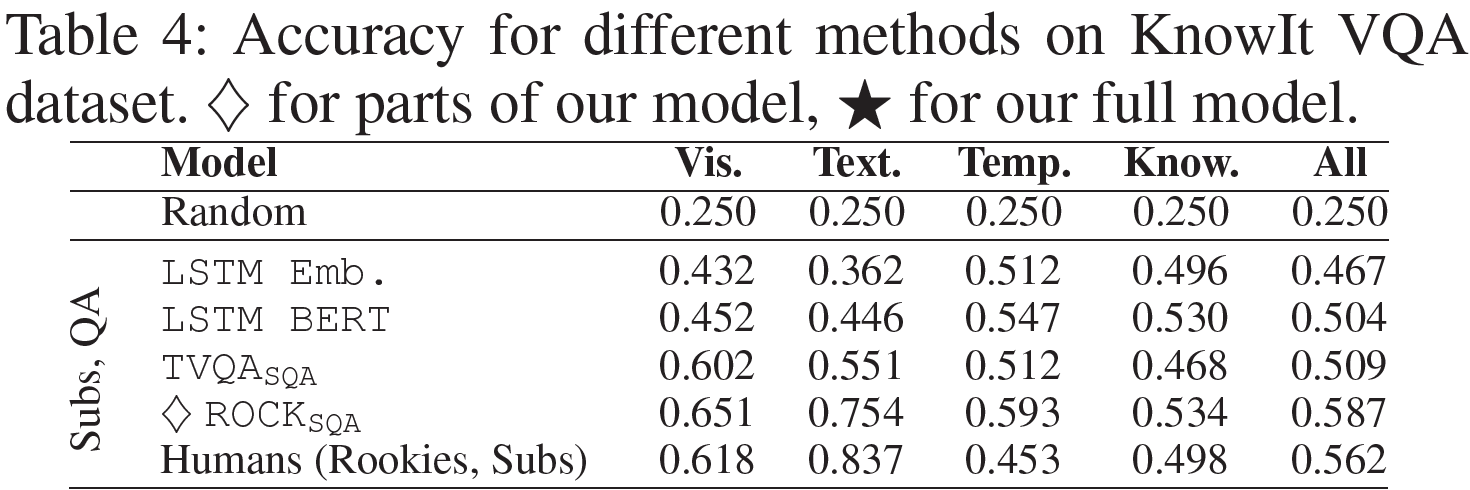
Subs, QA
자막, 질문, 답변을 사용한다.
- LSTM Emb. / BERT: 자막은 LSTM에 의해 인코딩된 후 자막-질문-답변으로 이어 붙여 4-class 분류기에 넣는다.
- TVQA_SQA: 언어는 LSTM layer에 의해 인코딩되며 다른 시각정보는 쓰지 않았다.
- ROCK_SQA: $m = 120$ token을 사용하는 ROCK 모델을 자막, 질문, 답변만으로 학습시켰다.
LSTM BERT와 ROCK_SQA는 질문과 답변만을 사용할 때보다 성능이 5.7% 향상되었다. LSTM Emb.는 전혀 향상되지 않았으며 자막의 긴 문장을 인코딩하는 데 한계가 있었기 때문이라 생각된다.
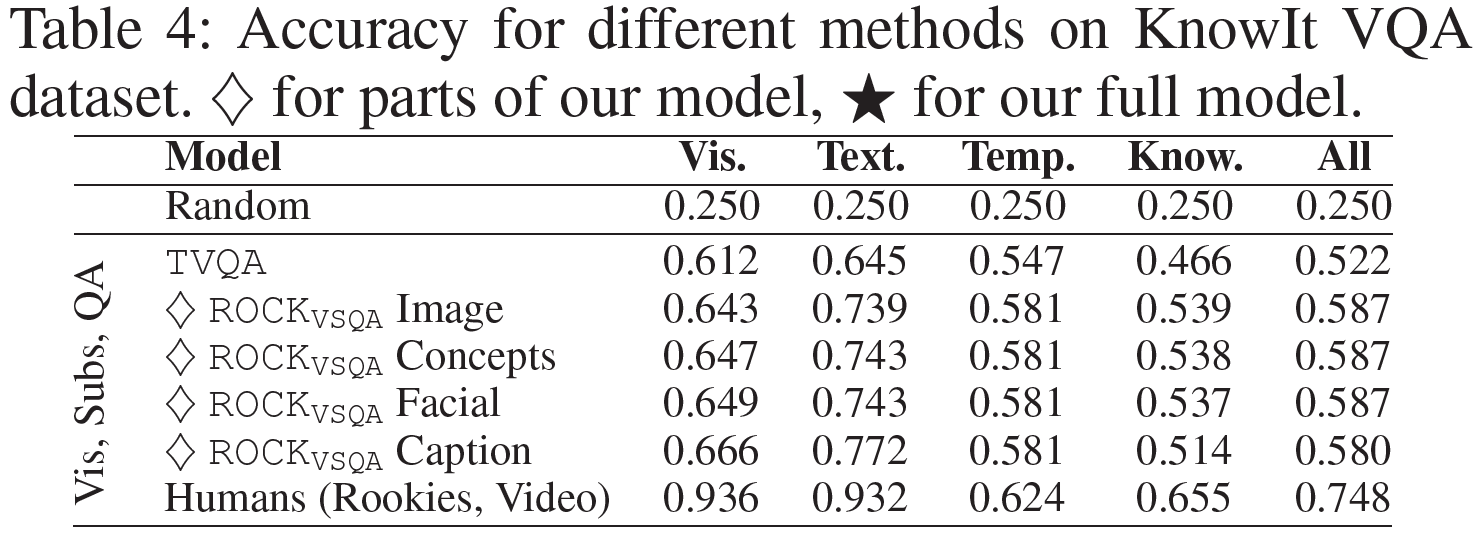
Vis, Sub, QA
이제 언어와 시각 정보 둘 다에 기반한 Video QA 모델이다.
- TVQA: SOTA VideoQA 방법이다. 언어는 LSTM layer로, 시각 데이터는 visual concepts으로 인코딩된다.
- ROCK_VSQA: $m = 120$ token과 $n_f=5$ frame을 사용하는 ROCK 모델을 질문과 답변만으로 학습시켰다. 4개의 다른 시각표현이 사용되었다.
ROCK_VSQA는 TVQA를 6.6%만큼 앞질렀다. 그러나, 어떤 visual 모델이든지 ROCK_SQA를 능가하는데 이는 현 영상모델링 기법의 큰 한계를 암시한다.
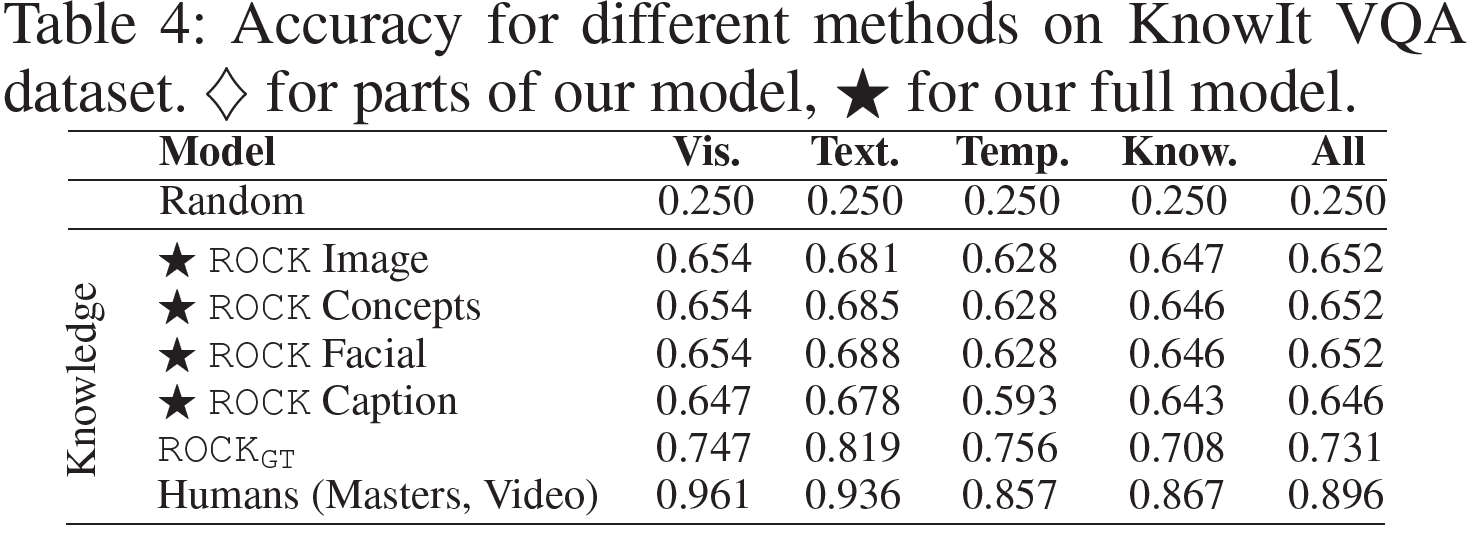
Knowledge
모델이 이제 Knowledge를 정답을 예측하는 데 사용한다. 전체 버전의 ROCK 모델은 $n=128, k=5$의 지식검색 모듈과 $m=512$의 영상추론 모듈을 사용한다.
non-knowledge 모델과 비교하여, 지식검색 모듈을 포함함으로써 6.5%의 성능 향상이 있으며, 지식기반 접근법의 상당한 잠재력을 보인다(시각표현인 Image, Concepts, Facial과 같이). 그러나, 전문가인 사람과 비교하여, ROCK은 여전히 뒤처지며, 이는 향상시킬 여지가 충분하다는 것을 뜻한다. 지식검색 대신 딱 맞는 지식을 그대로 갖고 오는 모델(ROCK_GT)를 사용하면 정확도는 0.731까지 오르며, 지식검색 모듈도 개선할 여지가 있음을 보여준다.
마지막으로 아래 그림에서 질적 평가 결과를 볼 수 있다.

Knowledge Retrieval Results
지식검색 모듈에 대한 결과로, recall at K와 median rank(MR)에 대한 결과를 아래 표에서 볼 수 있다.
- 질문만 있는 경우
- QA parameter sharing: 같은 parameter가 4개의 후보 답변에 사용됨
- QA prior score: prior score에 따라 순서를 배열하는 방법

질문만 사용하는 경우와 다른 두 경우에 큰 차이가 있는데 이는 후보 답변에 올바른 지식을 가져오는 데 필요한 정보가 포함되어 있음을 나타낸다. 가장 좋은 결과는 prior score에 따라 순서를 정한 것인데, 이는 모든 후보 답변을 전부 사용하는 것이 더 정확한 정보를 얻는 데 도움이 된다는 뜻이다.
결론(Conclusion)
새로운 지식 필요 영상 VQA를 제시하였고 multi-modal 영상정보와 지식을 결합하여 사용하는 영상추론 모델을 제시하였다. 진행된 실험은 영상이해 문제에서 지식기반 접근법의 상당한 잠재력을 보였다. 그러나, 사람의 능력에 비하면 크게 뒤처지며, 이 데이터셋을 통해 더 강력한 모델의 개발을 장려하며 이를 바라는 바이다.
Acknowledgements
New Energy and Industrial Technology Development Organization
참고문헌(References)
논문 참조!