
HERO 논문 설명(HERO - Hierarchical Encoder for Video+Language Omni-representation Pre-training)
15 Aug 2021 | Paper_Review Multimodal Transformer Microsoft AI Research목차
- HERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training
이 글에서는 2020년 EMNLP에 게재된 HERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training 논문을 살펴보고자 한다.
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
HERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training
논문 링크: HERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training
초록(Abstract)
대규모 Video + Language omni-representation(전체표현) 학습을 위한 새로운 framework, HERO를 제시한다. HERO는 계층적 구조에서 multimodal 입력을 인코딩한다. Video frame의 local 문맥은 multimodal fusion에 의해 Cross-modal Transformer로 잡아내고, global video 문맥은 Temporal Transformer에 의해 추출된다. Masked Language Modeling(MLM)과 Masked Frame Modeling(MFM)에 더해 새로운 사전학습 task를 제시한다.
- Video-Subtitle Matching(VSM): 모델이 global/local temporal alignment를 예측함.
- Frame Order Modeling(FOM): 모델이 순서를 섞인 video frame의 올바른 순서를 예측함.
HERO는 HowTo100M과 대규모 TV 데이터셋으로 학습하여 multi-character 상호작용과 복잡한 사회적 dynamics에 대한 깊은 이해를 얻을 수 있게 한다. 종합적인 실험은 HERO가 Video Retreival, VQA, Video Captioning 등의 task에서 새로운 SOTA를 달성하였음을 보인다. 또한 How2QA와 How2R이라는 Video QA and Retrieval benchmark를 제안한다.
1. 서론(Introduction)
시각+언어 multimodal 연구에서 BERT, ViLBERT, LXMERT, UNITER, VL-BERT, Unicoder-VL 등 대규모 사전학습 방식 모델이 여럿 발표되었다. 그러나 이러한 모델은 정적인 이미지에 맞춰져 있을 뿐 동적인 영상에는 적합하지 않다. VideoBERT가 영상-텍스트 쌍에 대한 결합표현을 학습하는 첫 시도이기는 했으나 이산적인 token만 사용되었으며 전체 frame feature가 사용되지 않았다. 이후 CBT, UniViML 등이 이를 해결하기 위한 시도를 하였다.
여러 시도가 있었으나 한계가 있었는데,
- BERT 기반으로 구성되었다. 이는 텍스트와 영상 정보를 단순히 이어붙인 형태로 사용하여 두 modality가 같은 시간에 있었다는 정보를 사용하지 않는다.
- 사전학습 task는 이미지+텍스트 task에서 가져온 것으로 영상의 특성을 활용하지 못한다.
- 영상 데이터셋은 요리나 일부 형식의 영상만 존재하여 한계가 있다.
이를 해결하기 위해 HERO: Hierarchical Encoder for Video+Language Omni-representation Pre-training를 제안한다.
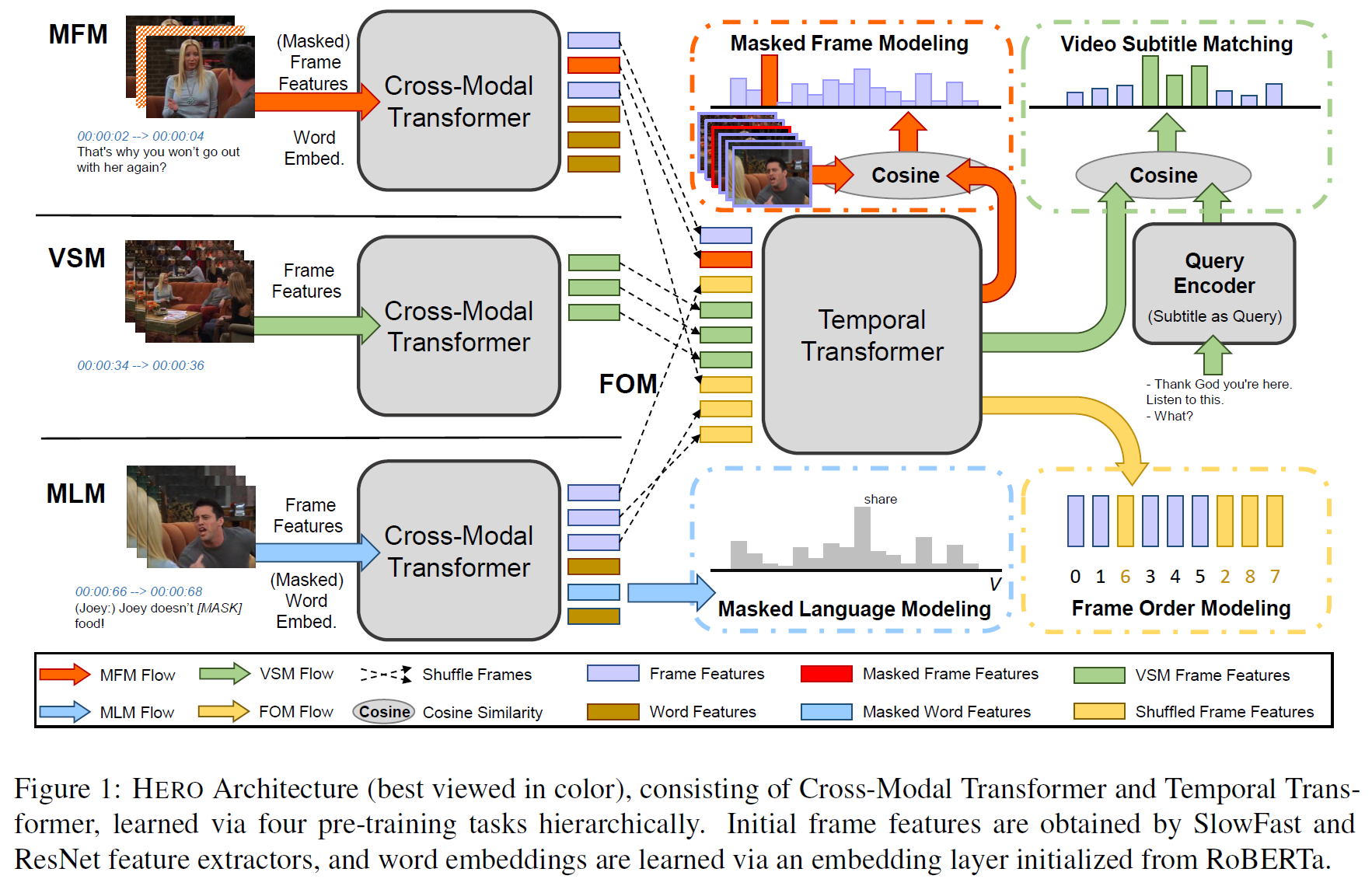
그림 1에서와 같이, video clip frame과 대응되는 자막 문장을 입력으로 받는다. BERT의 encoder와 같은 것이 아닌, HERO는 multimodal 입력을 구조적인 형태로 받는데,
- Cross-modal Transformer는 자막 문장과 해당하는 local video frame을 결합하고,
- 그 다음에 Temporal Transformer가 각 frame마다 주변의 frame을 전역 문맥으로 사용하여 연속적으로 contextualized embedding을 얻는다.
제안하는 계층적 모델은 frame 수준에서 먼저 visual/textual 지역 문맥을 얻어 전역 영상수준 시간적 문맥으로 변환한다.
실험은 이러한 구조가 BERT와 같은 구조의 모델보다 성능이 좋음을 보여준다.
사전학습 task는 다음 4가지이다.
- Masked Language Modeling(MLM)
- Masked Frame Modeling(MFM)
- Video-Subtitle Matching(VSM)
- Frame Order Modeling(FOM)
VSM과 FOM은 연속적 영상입력 전체에서 modality 간 시간적 일치 정보를 활용하는 것이 핵심이다.
YouCook2나 MSR-VTT와 같은 교육용(instructional) 영상만을 쓰는 한계를 벗어나기 위해 데이터셋은 HowTo100M과 대규모 TV 데이터셋을 사용하였다. 또한 요리에만 국한되거나(YouCook2) 매우 간단한(MSR-VTT) 데이터셋의 문제를 해결하기 위해서 새로운 task인 How2R과 How2QA를 제안한다.
그래서 본 논문의 기여한 바는,
- 시각+언어 표현 학습을 위한 Transformer 기반 계층적 모델 HERO를 제안한다.
- Modality 간 alignemnts를 더 잘 학습할 수 있도록 하는 사전학습 task VSM과 FOM을 제시한다.
- 단순한 데이터셋을 넘어 HowTo100M과 대규모 TV 데이터셋을 사용하여 모델이 더욱 풍부한 표현을 학습할 수 있게 하였다.
- HowTo100M, video-moment retrieval/QA에서 데이터셋을 모아 새로운 benchmark로 How2R과 How2QA를 제안한다.
2. 관련 연구(Related Work)
- BERT이후 BERT-like한 많은 모델이 발표되었다. 이후 모델 압축이나 생성 task로 발전이 있었다.
- 텍스트만 다루는 것을 넘어 시각적 정보까지 사용하는 모델이 등장하였다(ViLBERT, LXMERT, VL-BERT, Unicoder-VL 등).
- 대개 텍스트에 이미지를 사용하는 것이 많았는데, 이후 영상을 다루는 모델(VideoBERT, CBT, MIL-NCE, Act-BERT, UniViLM)이 제안되었다.
본 논문에서는 시각+언어 전체표현(omni-representation)을 4가지 차원에서 학습하는 모델을 개발하는 것을 목표로 하였다.
- 더 나은 모델구조
- 더 나은 사전학습 task 설계
- 학습 말뭉치의 다양화
- 후속 평가를 위한 새로운 고품질의 benchmark
3. 계층적 시각+언어 인코더(Hierarchical Video+Language Encoder)
3.1 Model Architecture
그림 1에서 전체 구조를 볼 수 있다.
- 입력은 video clip과 자막(일련의 token으로 된 문장)이다.
- 이들 입력은 Video Embedder과 Text Embedder를 통과하여 초기 표현을 뽑는다.
- HERO는 계층적 과정으로 영상표현을 추출하는데,
- 각 video frame의 local textual context는 Cross-modal Transformer에 의해 만들어진다. 자막 문장과 연관된 video frame의 contextualized multi-modal 임베딩을 계산하여 얻는다.
- 전체 영상의 frame 임베딩은 이후 Temporal Transformer에 집어넣어 global video context와 최종 contextualized video 임베딩을 얻는다.
Input Embedder
Notation:
\[\text{video clip} \ v=\lbrace v_i\rbrace^{N_v}_{i=1}, \quad \text{subtitle} \ s=\lbrace s_i\rbrace^{N_s}_{i=1}\]Text Embedder에서, WordPieces를 사용하여 자막 문장 $s_i$를 토큰화하고 각 sub-word token에 대한 최종표현은 token/position embedding을 합한 후 layer normalization(LN)을 통과시켜 얻는다.
Video Embedder에서, ImageNet에서 사전학습한 ResNet과 Kinetics에서 사전학습한 Slow-Fast를 사용, 각 video frame에 대한 2D/3D visual feature를 얻는다. 이들을 이어붙인 뒤 FC layer에 통과시켜 낮은 차원의 공간으로 전사, token embedding으로 사용한다.
Video frame은 연속적이기 때문에 position embedding은 Text Embedder에서와 같은 방법으로 계산된다. Frame에 대한 최종 표현은 FC 출력과 position embedding을 합하여 LN layer를 통과시켜 얻는다.
Input Embedder 이후 $w_{s_i}, v_{s_i}$에 대한 token과 frame embedding은 각각 다음과 같이 표시된다. $d$는 hidden size이다.
Cross-modal Transformer
자막과 video frame 간 alignments를 활용하기 위해 각 자막 문장 $s_i$에 대해 대응되는 token $w_{s_i}$와 연관된 visual frames $v_{s_i}$ 사이의 contextualized embedding을 cross-modal attention을 통해 학습한다. 이를 위해 multi-layer Transformer를 사용한다.
Cross-modal Transformer의 출력은 각 자막과 frame에 대한 일련의 contextualized embedding이며 다음과 같이 표시한다.
$f_{cross}$는 Cross-modal Transformer이다.
Temporal Transformer
Cross-modal Transformer의 출력으로부터 모든 visual frame embedding을 모은 후 video clip의 global context를 학습하기 위해 다른 Transformer를 temporal attention으로 사용한다.
\[\mathbf{V}^{cross} = \lbrace \textbf{V}_{s_i}^{cross}\rbrace^{N_s}_{i=1} \in \mathbb{R}^{N_v \times d}\]위치정보의 손실을 막기 위해 residual connection을 $\textbf{V}^{emb} \in \mathbb{R}^{N_v \times d}$의 뒤에 추가한다. 최종 contextualized video embedding은
\[\mathbf{V}^{temp} = f_{temp}(\mathbf{V}^{emb} + \mathbf{V}^{cross}), \quad \mathbf{V}^{temp} \in \mathbb{R}^{N_v \times d}\]$f_{temp}$는 Temporal Transformer이다.
모든 textual/visual feature를 그냥 이어 붙이는(concat) BERT류와 달리 본 논문의 모델은 좀 더 세밀하게 시간적 일치정보를 활용한다. 실험에서 이 방식이 더 나음을 증명한다.
3.2 Pre-training Tasks
MFM과 MLM은 BERT의 것과 비슷하다. VSM은 local & global alignment를 학습하기 위한 것이며, FOM은 영상의 연속적 특성을 모델링하기 위한 task이다.
3.2.1 Masked Language Modeling
입력은 다음과 같다.
- $i$번째 자막 문장 $\mathbf{w}_{s_i}$
- 이와 연관된 visual frames $\mathbf{v}_{s_i}$
- mask index $\mathbf{m} \in \mathbb{N}^M$
15%의 확률로 임의의 word를 [MASK]로 치환하고 이를 맞추는 task이다. 다음 음의 우도를 최소화한다.
$\theta$는 학습 가능한 parameter이며 각 $\mathbf{w}, \mathbf{v}$는 $D$로부터 샘플링된다.
3.2.2 Masked Frame Modeling
MLM과 비슷하지만, MLM은 local context에서 진행되는 데 비해 MFM은 global context에서 수행된다. 목적은 word 대신 masking된 frame $\mathbf{v}_{\mathbf{m}}$을 복구하는 것이다.
Masked frame의 visual feature는 0으로 대체된 상태에서 나머지 frame $\mathbf{v}_{\backslash \mathbf{m}}$과 자막 문장 $\mathbf{s}$을 갖고 복원을 하게 된다. 이산값인 텍스트와는 달리 visual feature는 class 우도로 학습할 수 없고 따라서 다른 목적함수를 도입한다.
\[\mathcal{L}_{MFM}(\theta) = \mathbb{E}_D f_{\theta}(\mathbf{v}_{\mathbf{m}} | \mathbf{v}_{\backslash \mathbf{m}}, \mathbf{s})\]Masked Frame Feature Regression (MFFR)
MFFR은 각 masked frame $\mathbf{v}_{\mathbf{m}}^{(i)}$를 visual feature로 회귀시키는 task이다.
출력 frame 표현을 FC layer에 통과시켜 입력 visual feature와 같은 차원인 벡터 $h_{\theta}(\mathbf{v}_{\mathbf{m}}^{(i)})$로 변환한다.
참고로 visual feature는 $r(\mathbf{v}_{\mathbf{m}}^{(i)})$이며, 변환 이후 L2 regression을 적용한다.
\[f_{\theta}(\mathbf{v}_{\mathbf{m}} | \mathbf{v}_{\backslash \mathbf{m}}, \mathbf{s}) = \sum^M_{i=1} \Vert h_{\theta}(\mathbf{v}_{\mathbf{m}}^{(i)}) - r(\mathbf{v}_{\mathbf{m}}^{(i)}) \Vert_2^2\]Masked Frame Modeling with Noise Contrastive Estimation (MNCE)
Masked visual feature로 바로 회귀시키는 대신 자기지도 표현학습에서 널리 쓰이는 Noise Contrastive Estimation(NCE) loss를 사용한다. NCE loss는 모델이 올바른 frame을 판별할 수 있게 한다.
MFFR과 비슷하게 masked frame $\mathbf{v}_{\mathbf{m}}^{(i)}$을 FC layer에 통과시켜 다음 벡터로 전사한다.
\[g_{\theta}(\mathbf{v}_{\mathbf{m}}^{(i)})\]이후 부정 선택지에도 같은 과정을 적용한다.
\[\mathbf{v}_{\mathbf{neg}} = \lbrace \mathbf{v}_{\mathbf{neg}}^{(j)} | \mathbf{v}_{\mathbf{neg}}^{(j)} \in \mathbf{v}_{\backslash \mathbf{m}} \rbrace\]최종 목적함수는 다음과 같다.
\[f_{\theta}(\mathbf{v}_{\mathbf{m}} | \mathbf{v}_{\backslash \mathbf{m}}, \mathbf{s}) = \sum^M_{i=1} \log \text{NCE}(g_{\theta}(\mathbf{v}_{\mathbf{m}}^{(i)}) - g_{\theta}(\mathbf{v}_{\mathbf{neg}}))\]3.2.3 Video-Subtitle Matching
VSM의 입력은 아래와 같다.
- 모든 자막 문장에서 얻은 query $s_q$
- 전체 video clip $\mathbf{v}$
- video clip에 대한 나머지 자막 문장 $\mathbf{s}_{\backslash q}$
모델은 두 가지를 학습해야 한다.
- local alignment - query와 연관된 frame의 시작과 끝 = $y_{st}, y_{ed} \in \lbrace 1, …, N_v \rbrace $
- global alignment - query와 match되는 video
학습 방식은 XML 모델을 따라간다. Temporal Transformer의 출력을 최종 frame 표현 $\mathbf{V}^{temp} \in \mathbb{R}^{N_v \times d}$으로 추출한다.
Query는 Cross-modal Transformer에 넣어 다음 textual 표현을 얻는다.
이에 기반하여 self-attention layer로 구성된 query encoder, 2개의 선형 layer, LN layer을 사용하여 $ \mathbf{W}_{s_q}^{cross}$로부터 최종 query 벡터 $\mathbf{q} \in \mathbb{R}^d$를 얻는다.
Local Alignment
Local query-video matching 점수는 내적을 사용한다.
\[S_{local}(s_q, \mathbf{v}) = \mathbf{V}^{temp} \mathbf{q} \in \mathbb{R}^{N_v}\]2개의 학습가능한 1D convolution filter가 이 점수에 적용되고 softmax를 통과하면 다음 확률벡터를 얻는다. 이는 ground-truth span의 시작과 끝을 나타낸다.
\[\mathbf{p}_{st}, \mathbf{p}_{ed} \in \mathbb{R}^{N_v}\]학습 동안 15%의 자막을 선택하여 cross-entropy loss를 사용한다.
\[\mathcal{L}_{local} = -\mathbb{E}_D \log (\mathbf{p}_{st}[y_{st}]) + \log (\mathbf{p}_{ed}[y_{ed}])\]$\mathbf{p}[y]$는 벡터 $\mathbf{p}$의 $y$번째 원소이다.
XML에서는 각 modality에 대해 독립적으로 점수를 계산하며 최종점수는 2개의 점수를 합친 것이다.
HERO에서는 multimodal fusion이 그 이전에 행해진다.
Global Alignment
Frame과 query 간 cosine 유사도를 계산하여 matching score를 얻는다.
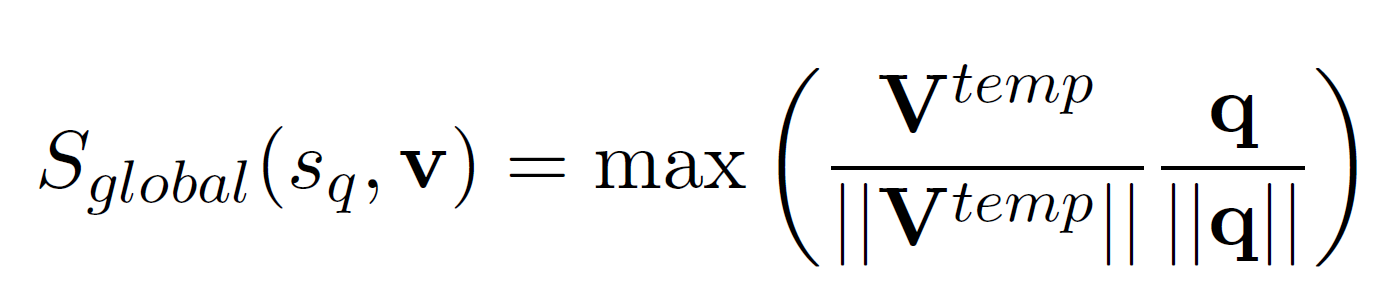
Positive/Negative query-video 쌍에 대해 결합 hinge loss $\mathcal{L}_h$를 사용한다. Positive 쌍에 대해서 각 원소를 같은 mini-batch 안에 있는 다른 sample로 대체하여 총 2개의 negative sample을 만든다.
목적함수는 다음과 같다.
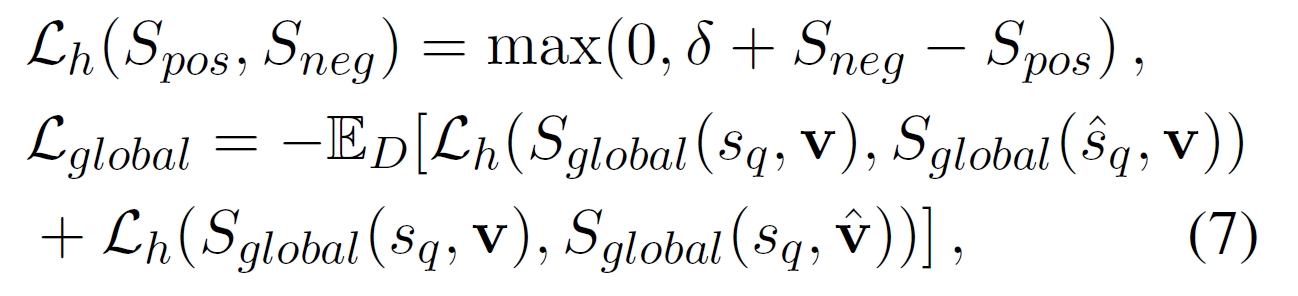
$\delta$는 margin hyper-parameter이다. 최종 손실함수는 다음과 같다.
\[\mathcal{L}_{VSM} = \lambda_1 \mathcal{L}_{local} + \lambda_2 \mathcal{L}_{global}\]3.2.4 Frame Order Modeling
입력은 다음과 같다.
- 모든 자막 문장 $\mathbf{s}$
- visual frames $\mathbf{v}$
- 재배치 순서 $\mathbf{r} = \lbrace r_i \rbrace^R_{i=1} \in \mathbb{N}^R$
15%의 frame을 순서를 섞으면 모델은 원래 시간순서(timestamp) $ \mathbf{t} = \lbrace t_i \rbrace^R_{i=1}, \ t_i \in \lbrace 1, …, N_v \rbrace$ 를 알아내야 한다.
본 논문에서, FOM은 분류 문제로 형식화하고, $\mathbf{t}$는 재배치 순서의 ground-truth label이다.
재배치는 자막과 frame의 fusion 이후 행해진다. 재배치된 feature는 Temporal Transformer에 넣어 재배치된 visual frame embedding $\mathbf{V}_r^{temp}$를 얻는다.
이 embedding은 FC layer, softmax layer를 통과하여 확률행렬 $\mathbf{P} \in \mathbb{R}^{N_v \times N_v}$를 얻는다. 여기서 각 열 $\mathbf{p}_i \in \mathbb{R}^{N_v}$는 $i$번째 timestamp가 속할 $N_v$개의 timestamp class의 점수를 나타낸다.
FOM에서, 다음 손실함수를 최소화해야 한다.
\[\mathcal{L}_{FOM} = -\mathbb{E}_D \sum^R_{i=1} \log \mathbf{P}[r_i, t_i]\]4. 실험(Experiments)
Text-based Video, Video-moment Retreival, VQA, Video-and-Language Inference, Video Captioning 분야에서 평가한다.
6개의 benchmark(TVR, TVQA, VIOLIN, TVC, DiDeMo, MSR-VTT)을 사용하였다.
4.1 Pre-training Datasets
7.6M개의 video clip을 포함하며 downstream task에 등장하는 모든 영상은 사전학습 데이터셋에서 제거하였다.
TV Dataset
의학 드라마, 시트콤, crime show의 세 장르에서 6개의 TV show를 포함한다. 총 21,793개의 video clip이며 각 clip은 대략 60-90초 사이이다. 인물 간 상호작용과 사회적/전문적 활동 등을 포함하며 대화 목록이 제공된다.
HowTo100M Dataset
YouTube에서 모은 대부분 교육용(instructional) video인 12개의 분류, 1.22M개의 영상을 포함한다. (Food & Entertaining, Home & Garden, 등)
각 영상은 설명(narration)을 자막으로 포함하며 이는 수동으로 혹은 ASR로 얻어졌다. 평균 길이는 6.5분이지만 TV dataset과 비슷하게 맞추기 위해 1분 단위로 잘라 총 7.56M개의 clip을 만들었다.
4.2 New Benchmarks
다양한 내용을 학습하기 위해 text based video-moment retrieval를 위한 How2R, VQA를 위한 How2QA를 제안한다.
How2R
HowTo100M 영상에 대한 annotation을 얻기 위해 AMT를 이용하였다. 영상 자체에 집중하기 위해 narration은 미제공 상태로 이루어졌다.
- 하나의 self-contained scene을 포함하는 영상의 일부분을 구분하는 것
- 분절된 각 영상에 대해 설명을 쓰는 것
최종 분절영상은 10-20초 정도이며 query의 길이는 8-20단어이다.
51390개의 Query, 9371개의 영상을 얻고 각 clip당 2-3개의 query를 포함한다. 데이터셋은 train/val/test가 각 80/10/10%으로 구분된다.
How2QA
역시 AMT를 이용, 분절영상에 대해 1개의 질문과 4개의 선택지를 만들게 하였다.
만들어진 QA 중 매우 편향되게 작성된 것이 많은 관계로(모델이 영상이나 자막으로부터 어떤 정보도 얻지 않고도 답을 맞힐 수 있음) 이를 완화하기 위해 adversarial matching(3개의 오답을 다른 질문의 정답으로 대체)을 사용하였다.
TVQA와 비슷하게 각 질문과 연관된 영상의 시작/끝 부분을 제공하였다. 저품질 annotation을 제거하고 22k개의 60초 clip, 44007개의 QA 쌍을 얻었다. 비슷하게 80/10/10 비율로 나눈다.
4.3 Ablation Study
Optimal Setting of Pre-training Tasks
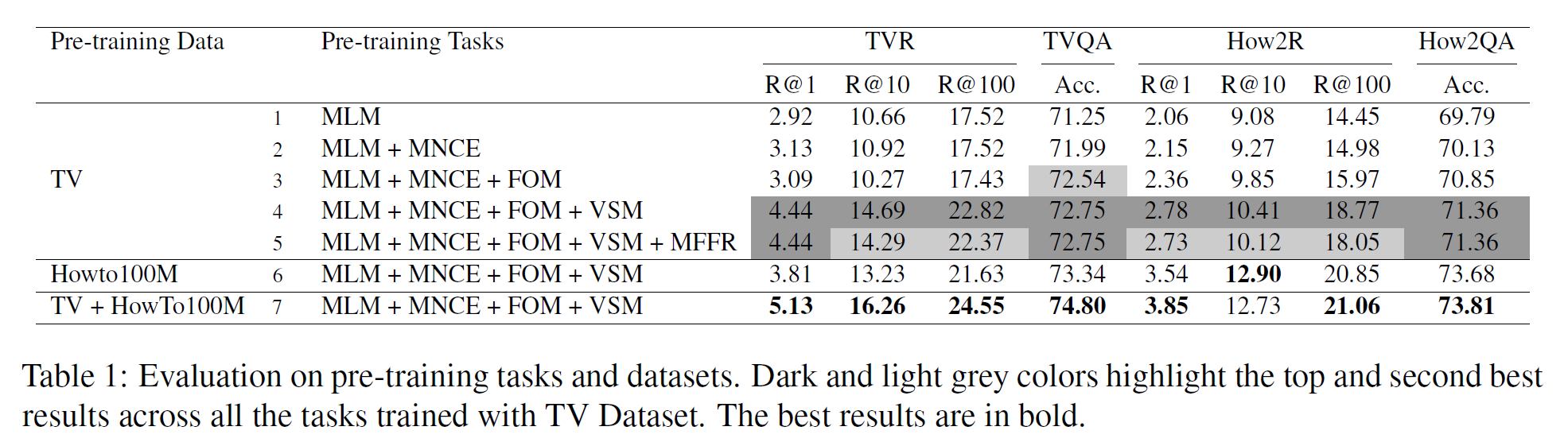
각 데이터셋별로 다른 사전학습 세팅을 적용하여 실험하였다.
- TV dataset에서 학습된 모델만이 계산량에서 이점을 가진다.
- MLM과 비교하여 MNCE를 추가하는 것은 모든 데이터셋에서 효과가 있다.
- 제일 좋은 조합은 MLM + MNCE + FOM + VSM이다.
Effect of FOM and VSM
- MLM, MNCE, FOM이 같이 학습되면 TVQA에서 큰 향상이 있고, How2R과 How2QA에서도 마찬가지이다.
- 이는 FOM이 QA task와 같이 temporal reasoning에 의존하는 downstream task에 효과적임을 뜻한다.
- VSM에서 상당한 성과가 있었는데 특히 local/global alignments를 학습함으로써 TVR과 How2R에서 특히 효과적이다.
- 추가적인 MFFR을 더하는 것은 좋지 않았다.
- MFFR은 사전학습 동안 MNCE와 비등하지만 나머지의 경우는 무시할 만한 수준이다.
Effect of Pre-training Datasets
- HowTo100M에서만 사전학습한 모델은 TV dataset에서만 사전학습한 모델보다 TVR에서는 성능이 낮고, 나머지 TVQA, How2R, How2QA에서는 더 좋은 결과를 얻었다.
- 하나의 가정은 text-based video-moment retreival이 video domain에 더 민감하다는 것이다.
- HowTo100M이 더 많은 수의 영상을 포함하지만 TV 영상에 대해서는 TV로 학습한 것이 더 낫다.
Hierarchical Design vs. Flat Architecture
HERO의 계층적 구조가 좋은 것인지 확인하기 위해 다른 기준모델 2개와 비교하였다.
- Hierarchical Transformer(H-TRM). Cross-modal Transformer을 RoBERTa 모델로 대체한 것
- Flat BERT-like encoder(F-TRM)
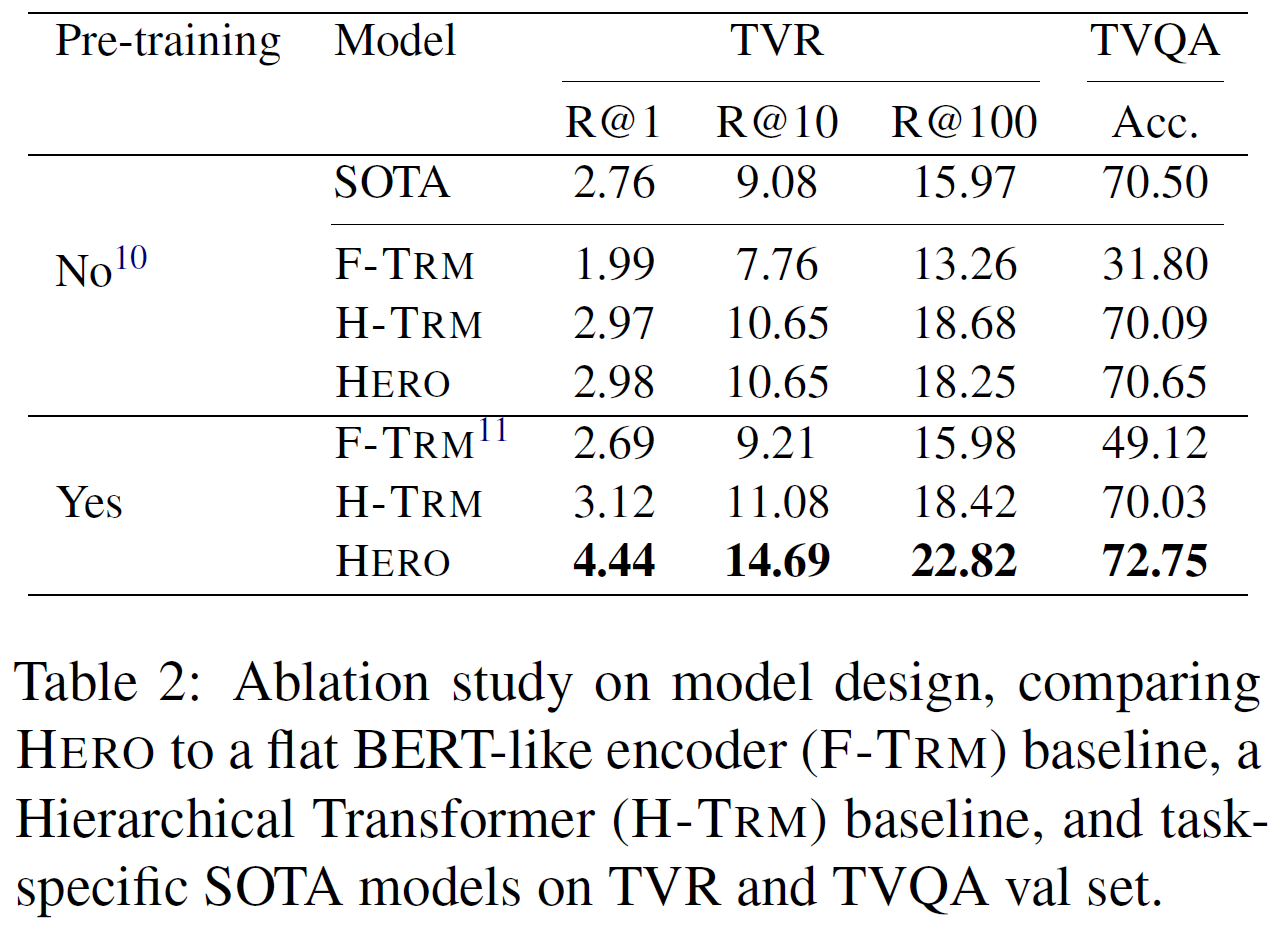
- 사전학습 없이 실험한 경우, F-TRM은 HERO에 비해 좋지 않다. 이는 HERO의 영상의 두 modality 간 temporal alignment의 탐색 효과 때문으로 보인다.
- 사전학습한 경우 차이는 더 큰데, 이는 cross-modal 상호작용과 temporal alignments가 downstream task에 대해 더 나은 표현을 제공함을 뜻한다.
HERO vs. SOTA with and w/o Pre-training
표 2에서 보듯이 사전학습이 있든 없든 HERO가 더 좋은 성능을 보인다.
Key Conclusions
- 최적의 사전학습 세팅은 MLM + MNCE + FOM + VSM이며 HowTo100M과 TV dataset을 모두 사용한다.
- FOM은 특히 시간적 추론을 요하는 task에서 효과적이다.
- VSM은 frame-subtitle 일치정보를 학습하게 하여 특히 video-moment retreival task에서 효과적이다.
- HERO의 계층적 구조는 명시적으로 subtitle과 frame 간 일치 정보를 학습하기 한다.
- HERO는 사전학습이 있든 없든 SOTA를 일관되게 앞선다.
4.4 Results on Downstream Tasks
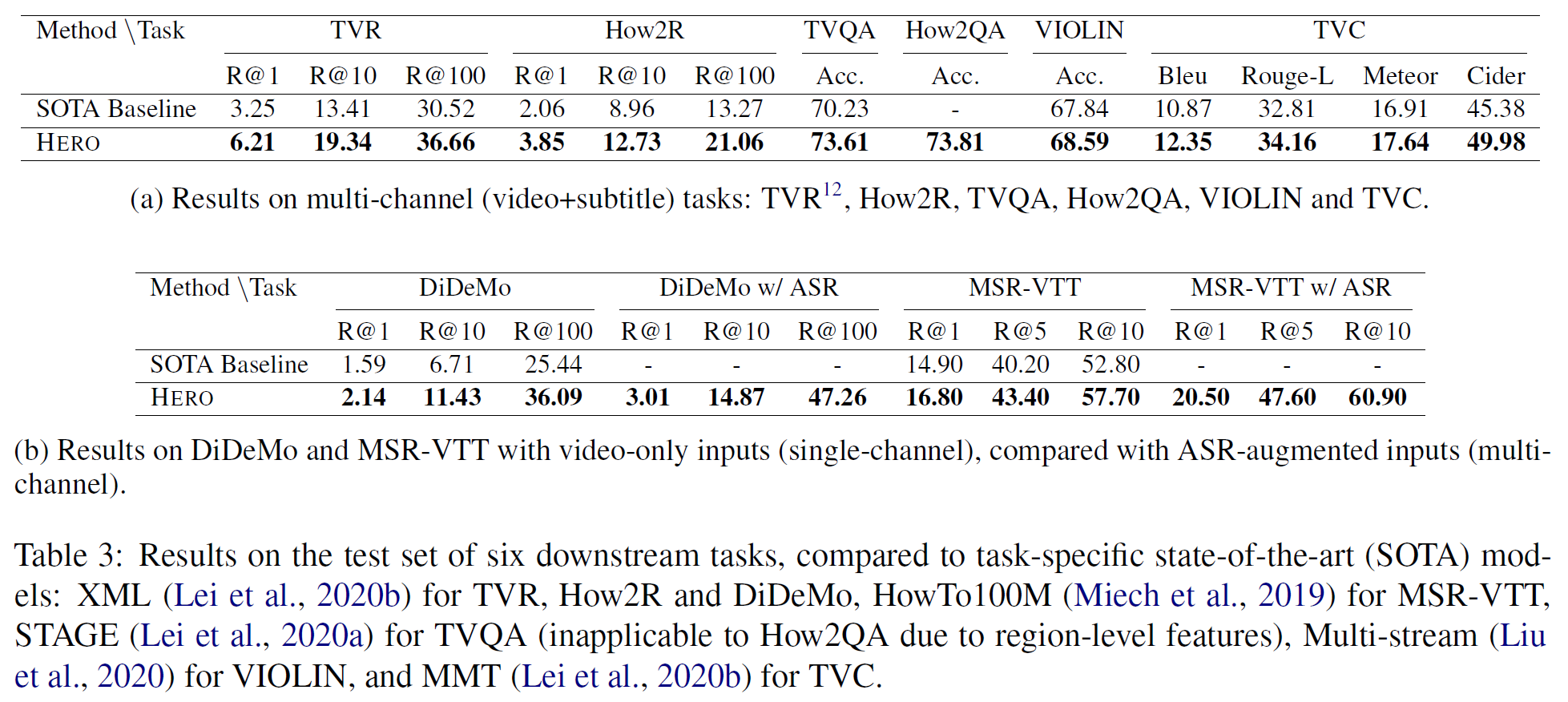
HERO는 위에서 언급한 최적의 사전학습 세팅을 사용하였다. XML, STAGE, Multi-stream, MMT 등을 능가하는 결과를 볼 수 있다.
Results on Multi-channel Tasks
표 3a에서 다채널 영상에 대한 결과를 볼 수 있다. TVR R@1에서는 XML의 거의 두 배를 기록하는 등 꽤 좋은 성능을 보인다.
Results on Single-channel Tasks
표 3b는 단채널 영상에 대한 결과이다. 역시 DiDeMo, MSR-VTT에 비해 일관되게 좋은 성능이다. 더 자세한 내용은 부록 A.1에 있다.
5. 결론(Conclusion)
Video+Language omni-representation 사전학습을 위한 계층적 encoder를 제안하였다. HERO 모델은 Cross-modal & Temporal Transformer를 사용한 계층적 구조로 새로운 사전학습 task들이 지역적으로 그리고 전역적으로 temporal alignment 정보를 학습하기 위해 제안되었다. HERO는 다수의 vision-language task에서 SOTA를 달성하였고 downstream task에 대한 추가적인 평가방법으로 2개의 새로운 데이터셋(task) How2R과 How2QA를 제시하였다. 추후 연구로는 모델의 확장 버전을 검토하고 더 나은 사전학습 task를 고안할 예정이다.
참고문헌(References)
논문 참조!