
CNN 기본 모델(ImageNet Challenge - AlexNet, ZFNet, VGG, GoogLeNet, ResNet, InceptionNet)
24 Oct 2021 | CNN Paper_Review ImageNet목차
이 글에서는 ImageNet Challenge에서 2012~2015년까지 좋은 성능을 낸 대표적인 모델인 AlexNet, ZFNet, VGG, GoogLeNet(InceptionNet), ResNet을 살펴본다.
ImageNet에서 사람의 오류율(이미지 class를 잘못 분류한 비율)은 5.1%로 나와 있음을 참고한다.
각각에 대해 간단히 설명하면,
- AlexNet: ImageNet Challenge에서 사실상 최초로 만든 Deep Neural Network 모델이다(이전에는 Shallow model이 대세였다). 2012년, 8 layers, 오류율 16.4%.
- ZFNet: AlexNet을 최적화한 모델이다. 2013년, 8 layers, 오류율 11.7%.
- VGGNet: Filter의 size를 크게 줄이고 대신 더 깊게 layer를 쌓아 만든 모델이다. 2014년, 19 layers, 오류율 7.3%.
- GoogLeNet: InceptionNet 으로도 부른다. 이름답게 Google에서 만들었으며 한 layer에서 여러 크기의 Conv filter를 사용하여 성능을 높였다. 2014년, 19 layers, 오류율 6.7%.
- ResNet: Residual Network를 개발한 논문으로 identity mapping을 추가하는 기술을 통해 깊이가 매우 깊어진 모델의 학습을 가능하게 하였다. 2015년, 152 layers, 오류율 3.6%. 이때부터 사람의 정확도를 능가하였다고 평가받는다.
- Inception v2,3, v4: GoogleNet(Inception)을 개량한 버전으로 ResNet보다 더 높은 성능을 보여준다. 2016년.
AlexNet
논문 링크: AlexNet
2012 NIPS에서 발표된 ImageNet Challenge에서의 (사실상) 최초의 Deep Neural Network이다.
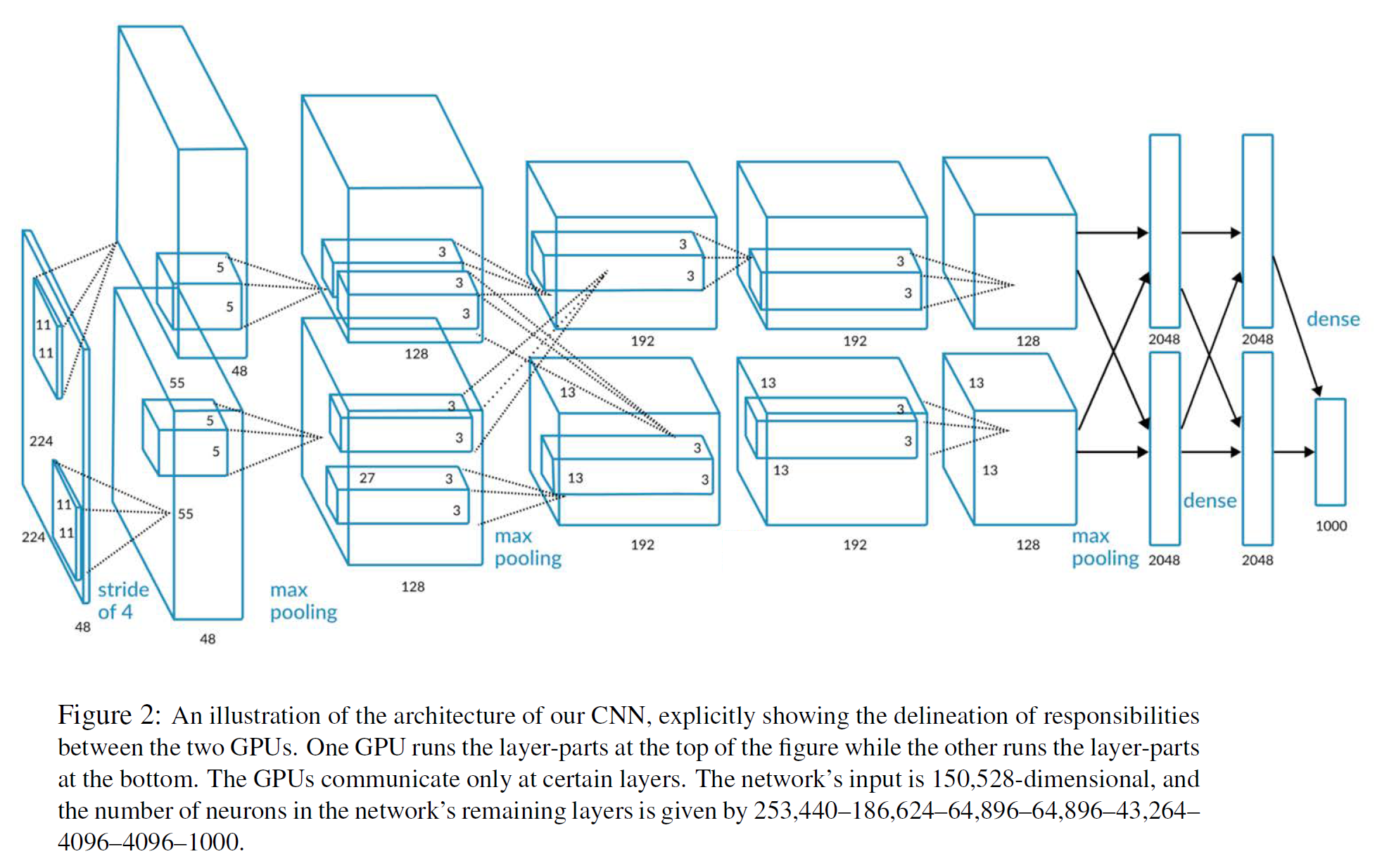
8개의 layers를 쌓은 지금으로서는 상당히 간단한 모델이지만 당시에는 꽤 복잡한 모델이었다.
8개의 layers라는 말은 학습가능한 parameter가 있는 layer의 개수를 의미하며 learnable parameters가 없는 pooling layer 등은 제외한다.
입력 이미지 크기는 [224, 224, 3]이며 이 이미지는
conv - pooling - layer norm을 총 2번 거친 다음convlayer를 3번 연속 통과하고poolinglayer를 1번 통과한 뒤fully connectedlayer를 3번 통과하여 최종적으로 1000개의 class일 확률을 예측하는[1000, 1]벡터를 출력한다.
첫 2개의 conv layer에서는 각각 크기가 11, 5인 filter를 사용하는데, 이는 지금 기준으로 매우 큰 크기이다. 이는 이후 모델이 발전하면서 작아지는 쪽으로 바뀌게 된다.
전체 구조를 정리하면 다음과 같다.
| Layer | Input size | Filters | Output size |
|---|---|---|---|
| Conv 1 | [224, 224, 3] | 96 [11 x 11] filters, stride=4, pad=1.5 | [55, 55, 96] |
| Pool 1 | [55, 55, 96] | [3 x 3] filters, stride=2] | [27, 27, 96] |
| Norm 1 | [27, 27, 96] | Layer Norm(not Batch Norm) | [27, 27, 96] |
| Conv 2 | [27, 27, 96] | 256 [5 x 5] filters, stride=1, pad=2 | [27, 27, 256] |
| Pool 2 | [27, 27, 256] | [3 x 3] filters, stride=2] | [13, 13, 256] |
| Norm 2 | [13, 13, 256] | Layer Norm(not Batch Norm) | [13, 13, 256] |
| Conv 3 | [13, 13, 256] | 384 [3 x 3] filters, stride=1, pad=1 | [13, 13, 384] |
| Conv 4 | [13, 13, 384] | 384 [3 x 3] filters, stride=1, pad=1 | [13, 13, 384] |
| Conv 5 | [13, 13, 384] | 256 [3 x 3] filters, stride=1, pad=1 | [13, 13, 256] |
| Pool 3 | [13, 13, 384] | [3 x 3] filters, stride=2] | [6, 6, 256] |
| FC 6 | [6, 6, 256] | Fully-connected | [4096] |
| FC 7 | [4096] | Fully-connected | [4096] |
| FC 8 | [4096] | Fully-connected | [1000] |
살펴볼만한 특징은,
- 이 논문은 최초의 CNN 기반 모델로 ReLU를 처음 사용하였다.
- Normalization Layer를 사용하였는데, 참고로 최근에는 거의 쓰이지 않는다.
- Data Augmentation을 상당히 많이 사용하였다.
- Dropout 0.5, Batch size 128, SGD(Momemtum 0.9)
- Learning rate는 0.01 이후 성능이 정체되면 1/10으로 줄인다.
- L2 weight decay(5e-4)를 hyperparameter로 사용하였다.
ZFNet
논문 링크: ZFNet
AlexNet을 최적화하여 다음 연도(2013년)에 발표된 논문으로, 모델의 구조는 딱히 다를 것이 없으나 filter size 등 여러 hyperparameter를 최적화하여 성능을 상당히 높인 모델이다.
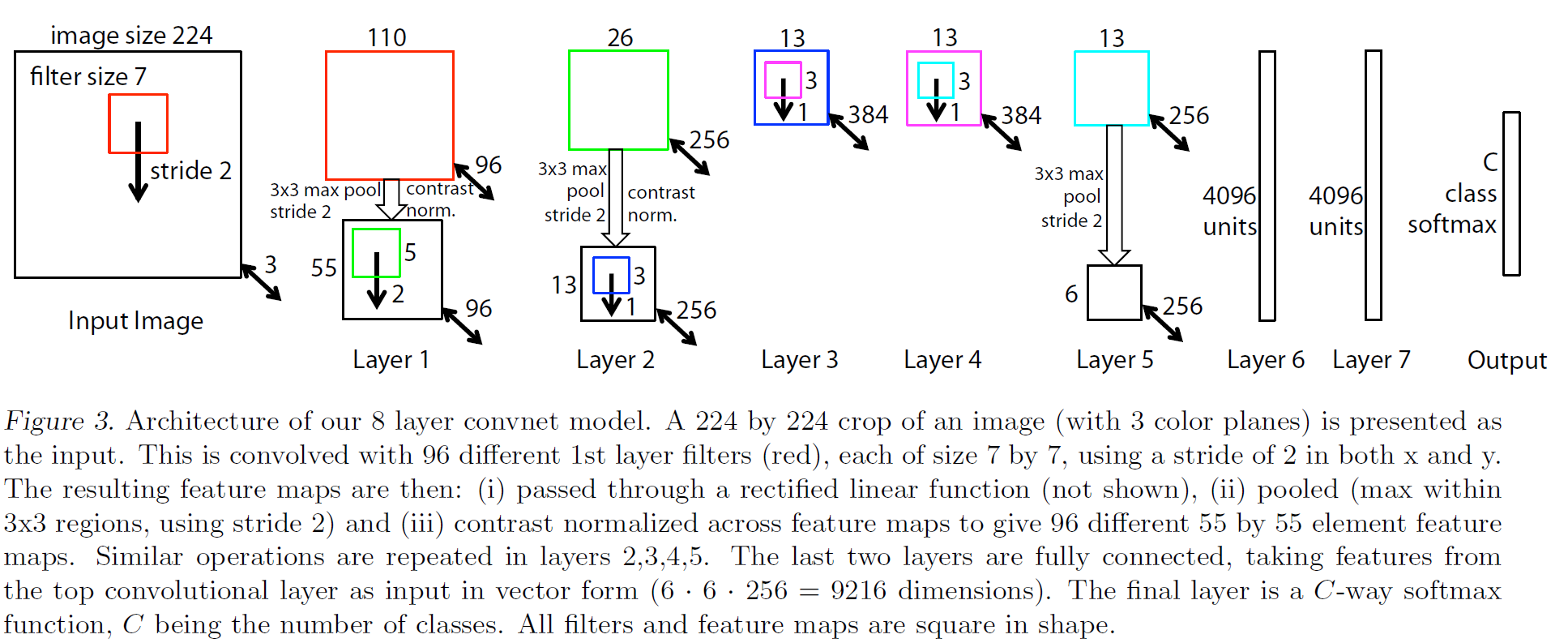
VGGNet
논문 링크: VGGNet
AlexNet의 필터 크기는 11, 5로 상당히 크다. 이는 parameter의 수와 계산량을 크게 증가시키는데, 2014년 발표된 VGGNet에서는 filter 크기를 3인 것만 사용하고, 대신 모델의 깊이를 더 깊게 쌓아서 더 좋은 성능을 얻는 데 성공한다.
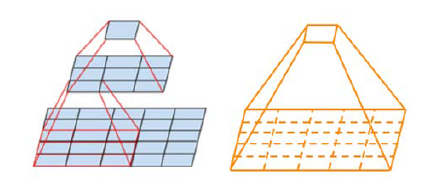
예로 [5 x 5] filter 1개를 사용하는 경우와 2개의 [3 x 3] filter를 사용하는 경우를 비교하면, 둘 다 [5 x 5] 범위를 살펴볼 수 있다. 그러나,
- 1개의 [5 x 5] filter는 총 $1 \times (5 \times 5) \times C^2 = 25C^2$개의 parameter를 사용한다.
- 2개의 [3 x 3] filter는 총 $2 \times (3 \times 3) \times C^2 = 18C^2$개의 parameter를 사용한다.
즉 갈은 범위를 처리할 수 있으면서도 필요한 parameter 수는 크게 줄어든다. [11 x 11]의 경우는 차이가 훨씬 크게 나게 된다.
VGGNet의 경우 버전이 여러 개 있는데, 보통 각각 16, 19개의 layer를 사용한 VGG16과 VGG19가 현재까지도 곧잘 사용된다. filter size와 layer의 수를 제외하면 큰 구조는 AlexNet과 꽤 비슷하다.
오류율이 7.3%로 줄어들어 사람의 성능(?)과 매우 근접한 수준까지 온 모델이다. VGGNet의 상세한 사항은 AlexNet과 비슷하지만, AlexNet에서는 사용한 local-response Normalization(LRN) layer를 사용하지 않았다. Batch size는 256으로 증가되었다.
GoogLeNet
논문 링크: GoogLeNet
역시 2014년 발표된 논문이다. 모델이 점점 더 깊어진다는 뜻에서 inception module이라는 것을 사용한다(영화 인셉션을 생각하라..).
각 conv layer에서, filter size를 1,3,5로 다양하게 사용하여 여러 receptive field size를 취하고 channel별로 concat하여 사용한다. 이를 통해 좀 더 다양한 정보를 학습할 수 있다.
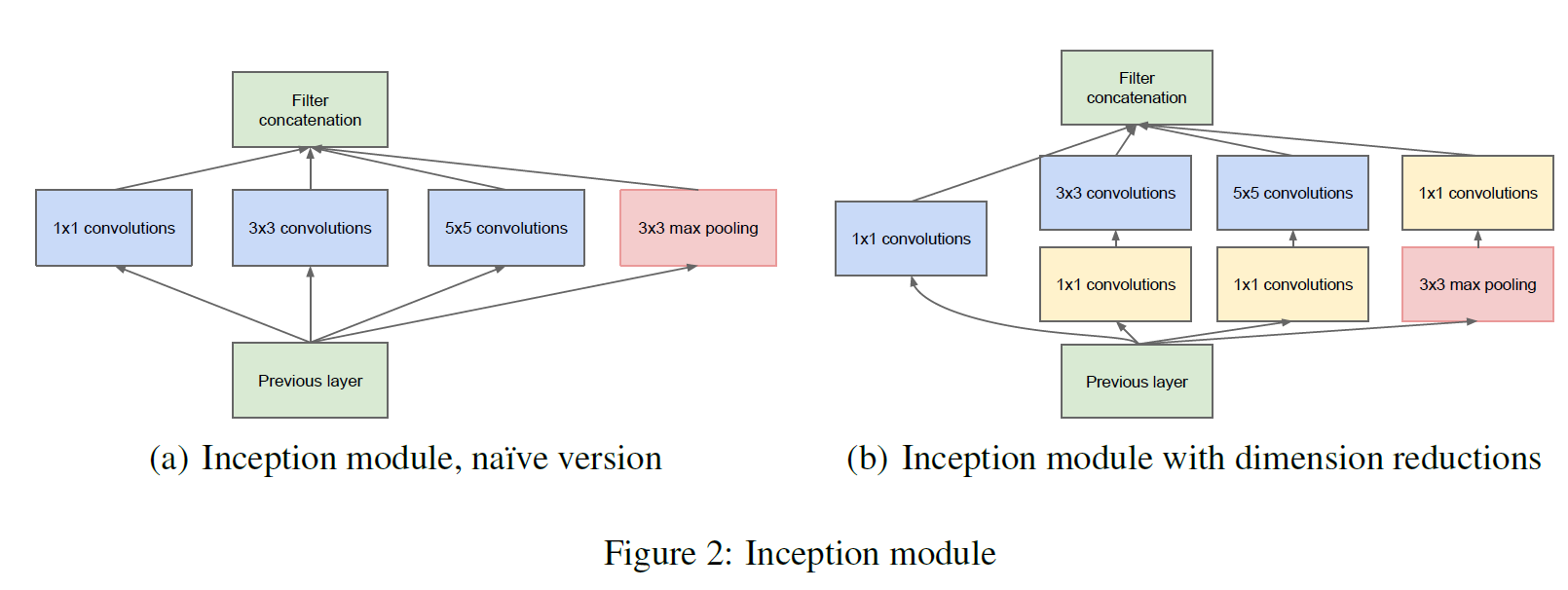
왼쪽이 Inception Module의 구상이고, 오른쪽은 계산량을 줄이기 위해 [1 x 1] conv를 앞에다 붙여서 사용한 것을 나타낸다. 각 layer마다 사용하는 filter가 3개씩(+pooling) 있기 때문에 계산량이 매우 많아지는데, 계산량이 많을 수밖에 없는 [3 x 3]과 [5 x 5] 필터를 사용하기 전 [1 x 1] filter를 적용하여 채널 수를 줄인 다음 계산하면 계산량이 3~4배 줄어들게 된다.
전체 구조는 다음과 같다. 각 layer마다 inception module이 들어가기 때문에 매우 복잡해 보이지만, 총 깊이는 22 layer이다.
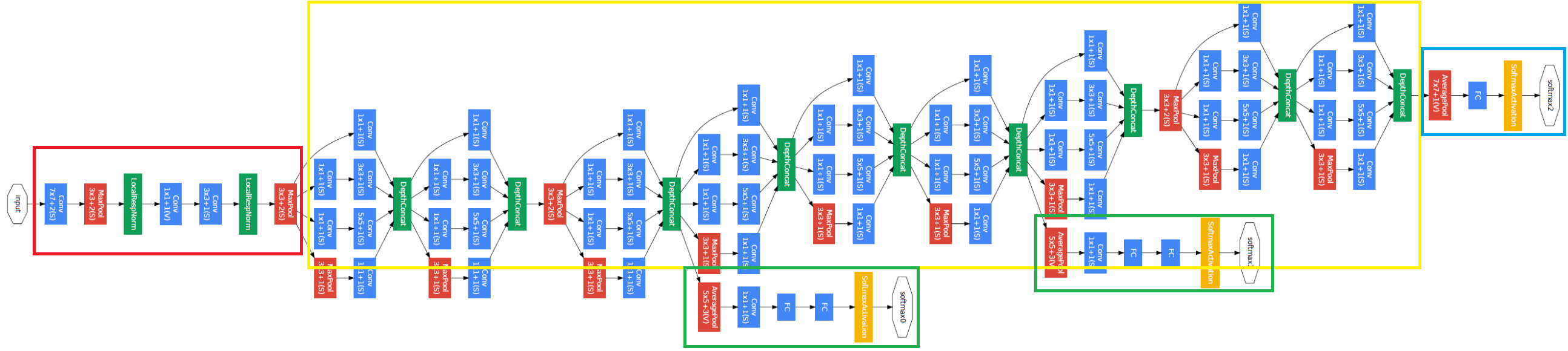
크게 4부분을 떼어 놓고 볼 수 있다.
- 맨 앞부분(빨간색 박스)은 input image를 받는 부분인데, Stem Network라 부른다. 이전 모델인 AlexNet과 VGGNet과 비슷하게, Conv-Pool-Norm-Conv-Conv-Norm-Pool Layer로 구성되어 있다.
- 중간 부분(노란색 박스)은 inception module를 쌓아 만든 부분이다.
- 마지막 부분(파란색 박스)은 앞에서 얻은 feature를 가지고 class를 분류하는 부분으로 Classifier output을 최종적으로 내보낸다.
- 아래쪽에 달려 있는 초록색 박스로 표시한 두 부분이 있는데, 이는 Auxilizary Classification loss를 사용하는 부분이다. GoogLeNet이 꽤 깊기 때문에 loss가 앞 layer까지 backprop이 잘 일어나지 않는다. 따라서 중간에 auxiliary classification loss를 추가하여 앞 부분에도 잘 전파될 수 있도록 하는 부분이다.
기타 살펴볼 특징은 다음과 같다.
- 22층의 layer를 사용하였다.
- AlexNet보다 12배, VGG16보다 27배 더 적은 parameter를 사용하면서도 성능이 더 좋다.
- Learning rate는 매 8 epoch 마다 4%씩 감소시킨다.
ResNet
논문 링크: ResNet
Microsoft에서 개발한 모델로 2015년 발표되었고, 최초로 사람의 분류 성능을 뛰어넘은 모델로 평가된다.
매우 깊은 모델(152층)이며, 이 이후부터는 매우 깊고 큰 모델을 사용하게 된다.
ResNet의 출발점은 다음과 같다. 어떤 shallow 모델이 있고, 여기에 더해 Layer를 몇층 더 쌓은 deep 모델이 있다. 그러면 deep model은, shallow 모델을 포함하니까 적어도 shallow 모델만큼은 성능이 나와 주어야 하는데(추가한 layer는 identity mapping을 한다고 하면 명백하다), 실제로 실험을 해보면 그렇지 않은 결과가 나온다. 이는 깊은 모델일수록 학습이 잘 이루어지지 않기 때문이다.
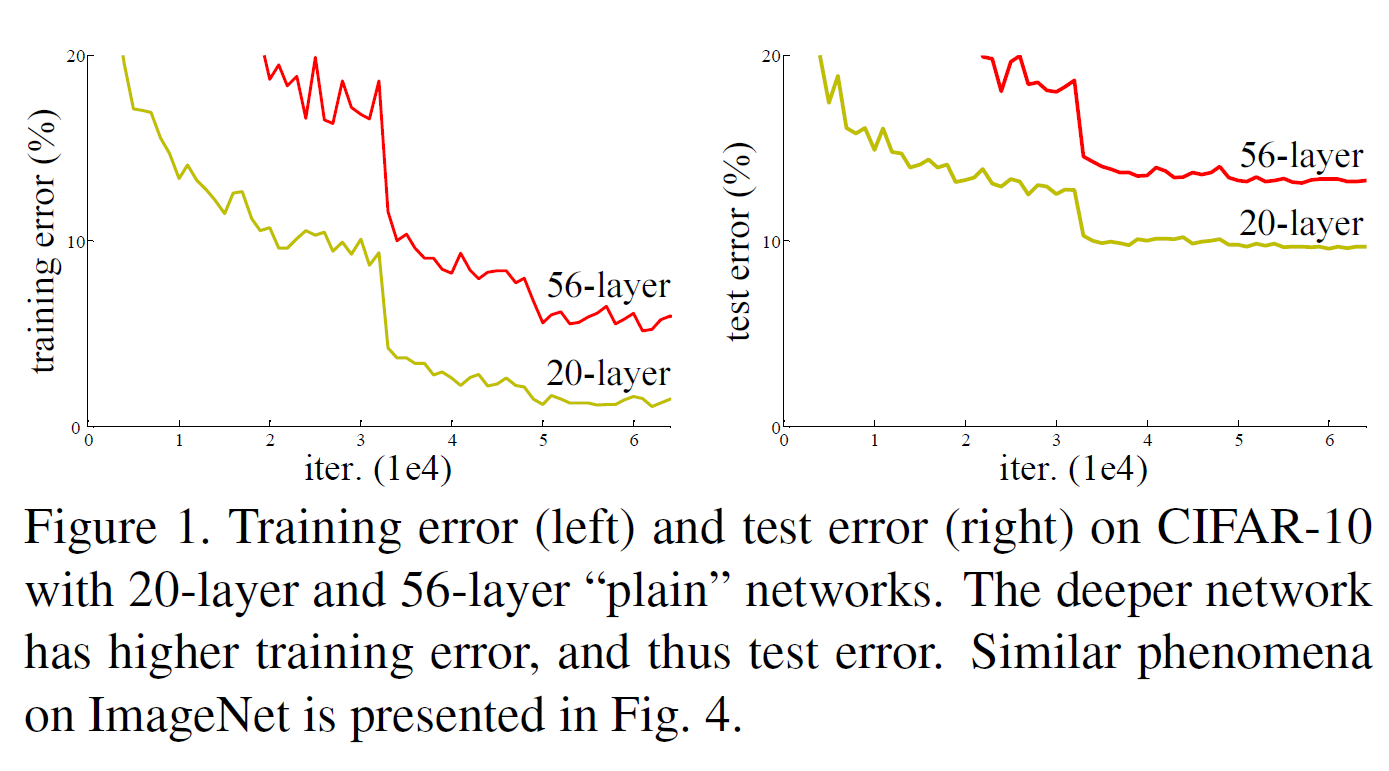
어쨌든 deep 모델이 shallow 모델만큼의 성능을 확보하려면, 강제적으로 이미 학습한 부분을 identity mapping으로 다음 layer에 전달하면 최소한 shallow 모델만큼은 성능이 확보될 것이다. 이 내용이 ResNet의 motivation이다.
그래서 그냥 identity mapping(혹은 Shortcut Connection이라고도 함)을 layer의 끝에다 그냥 더해버린다.
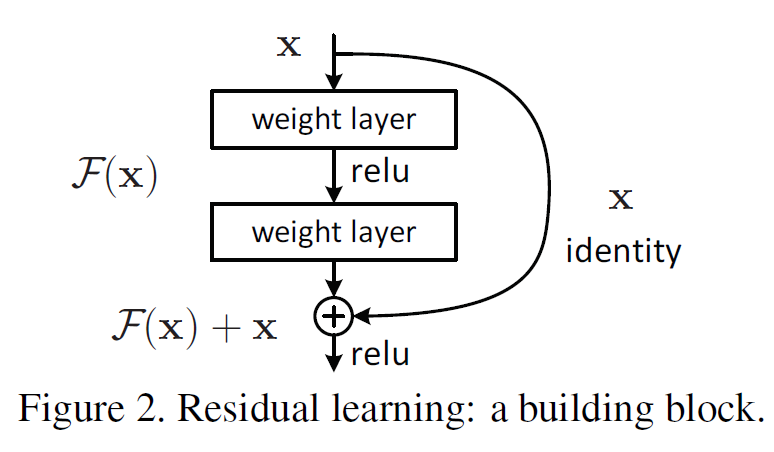
이러한 residual block을 152개까지 쌓는다. GoogLeNet과 비슷하게 Stem network가 처음에 있으며, 추가 FC layer는 사용하지 않는다.
각 block 내에는 각각 크기 1, 3, 1인 conv filter를 사용한다. ResNet도 여러 버전이 있는데(18, 34, 50, 101, 152 layers) 50 이후로는 사용하는 메모리에 비해 성능이 그닥 크게 증가하지는 않는다.
버전별 ResNet 구조는 다음과 같다.
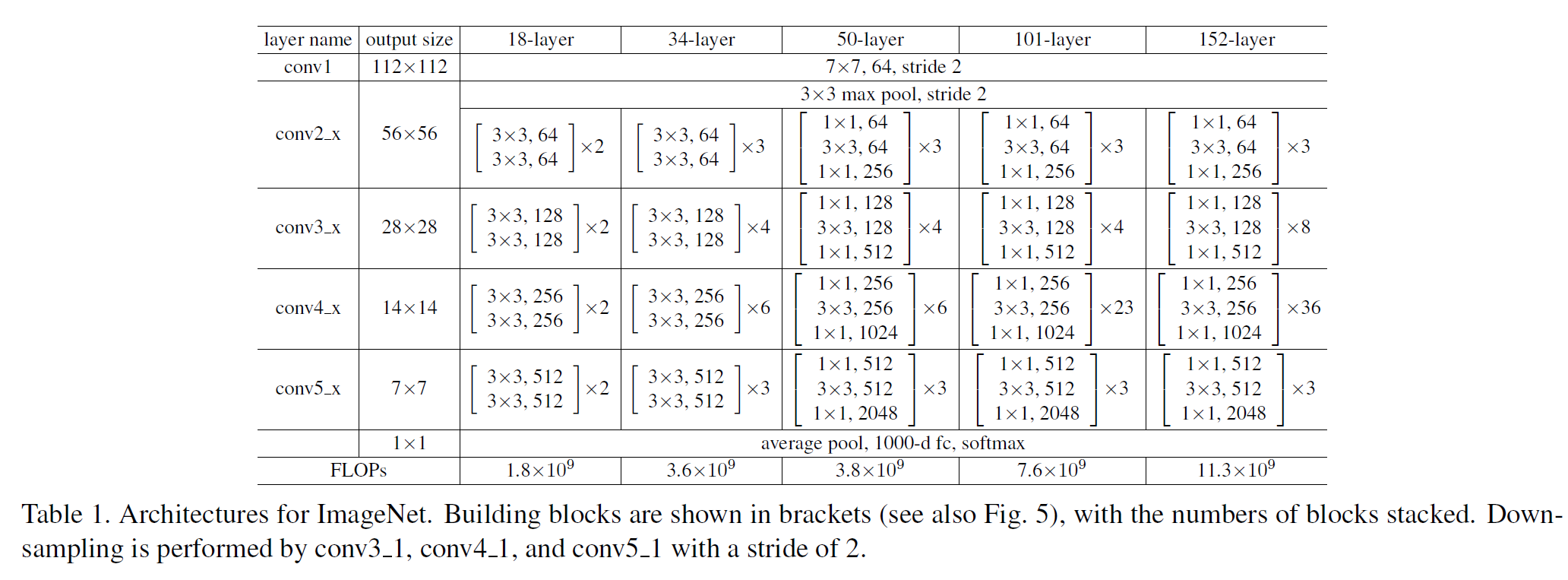
- Xavier Initialization을 사용하였다.
- 모든 conv layer 이후 batch norm이 사용되었다.
- Dropout은 사용하지 않는다.
InceptionNet v2,3, v4
논문 링크: Inception v2, 3, Inception v4
기존의 InceptionNet(GoogLeNet)을 발전시킨 모델이다.
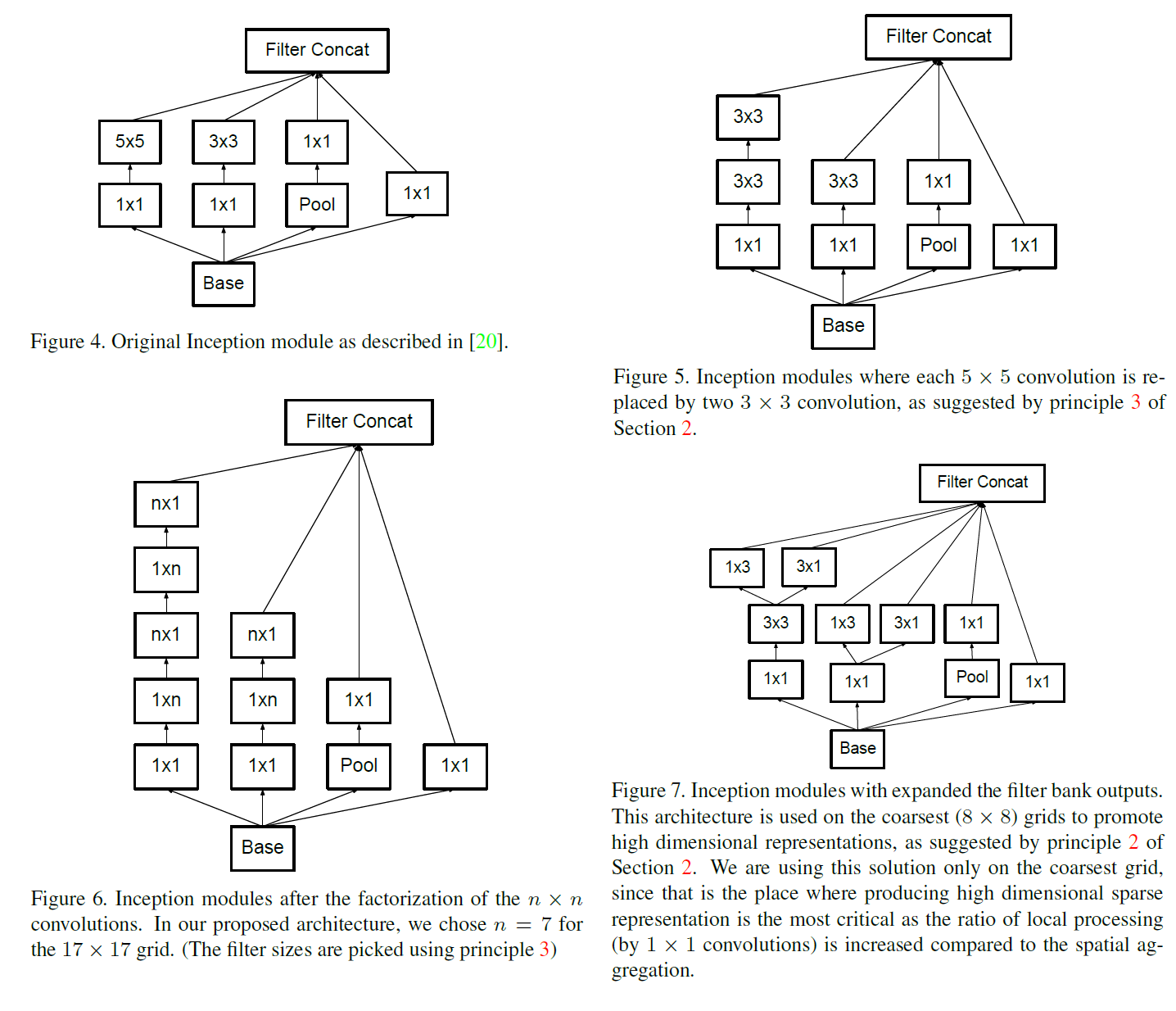
v2, 3에서는 Conv Filter Factorization과 Grid Size Reduction을 통해 기존 모델을 발전시켰다.
Conv Filter Factorization은 [n x n] filter를 [1 x n], [n x 1] 2개로 나누어 계산하는 방법으로 $n \times n$ 범위를 처리할 수 있으면서 계산량을 줄일 수 있는 방법이다.
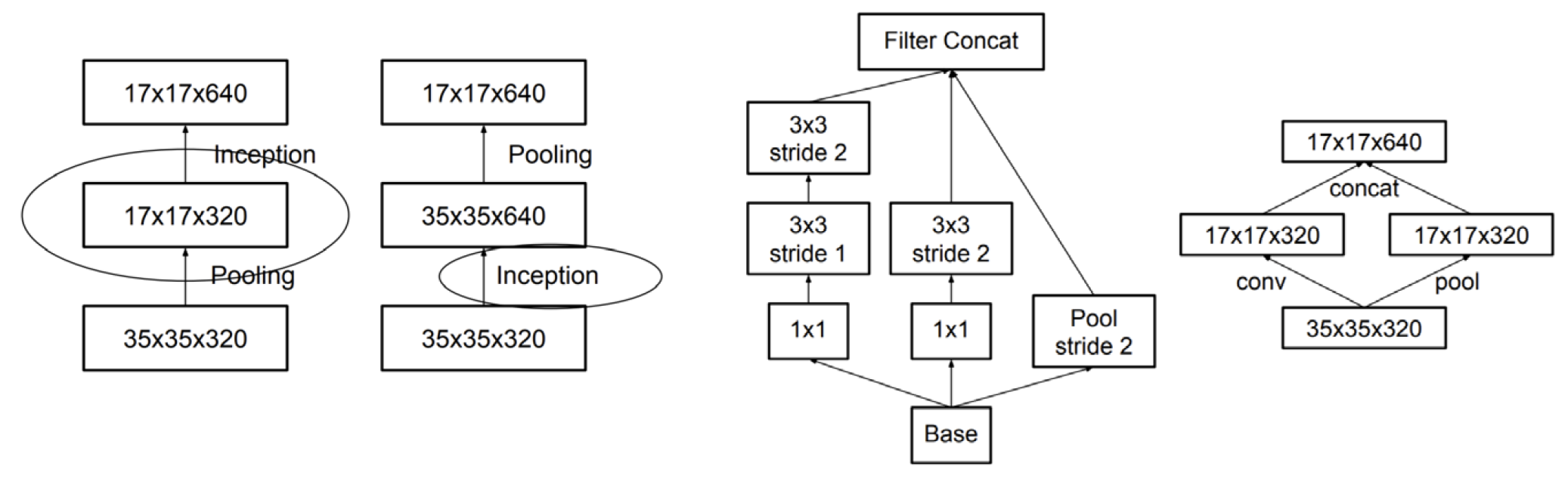
Grid size Reduction은 Pooling-Inception 순서로 할 경우 계산은 빠르지만 spatial 정보 손실이 일어나는 점, Inception-Pooling 순서의 경우 정보는 보존되지만 계산량이 많다는 점을 착안해, 이 두가지 방식을 적절히 섞어서(즉, 크기를 줄인 채 두 방법 모두를 사용하여) 2가지 장점을 모두 가지려 한 방법이라 생각하면 된다.
Inception v4는 ResNet 이후에 나온 모델이다. 그래서 Inception v3에다가 Residual 기법을 사용한 모델로, ResNet152보다 Inception v4의 성능이 더 좋다.
이후 모델은 ResNeXt, DenseNet, MobileNets 등이 있다.