VideoBERT - A Joint Model for Video and Language Representation Learning, CBT(Learning Video Representations using Contrastive Bidirectional Transformer) 논문 설명
13 Dec 2021 | Transformer BERT Google Research목차
- VideoBERT: A Joint Model for Video and Language Representation Learning
- CBT(Learning Video Representations using Contrastive Bidirectional Transformer)
이 글에서는 Google Research에서 발표한 VideoBERT(와 CBT) 논문을 간략하게 정리한다.
VideoBERT: A Joint Model for Video and Language Representation Learning
논문 링크: VideoBERT: A Joint Model for Video and Language Representation Learning
Github: maybe, https://github.com/ammesatyajit/VideoBERT
- 2019년 9월(Arxiv), ICCV 2019
- Google Research
- Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmid
Video에다가 BERT를 적용한 논문이다. Visual info는 Video의 frame를 1.5초마다 하나씩 뽑아 S3D embedding을 만들고, Audio는 ASR을 사용하여 텍스트로 변환하여 사용했다.
VL-BERT나 ViLBERT와는 달리 detection model이 없으므로, 그냥 S3D embedding을 갖고 clustering을 수행한다.그러면 어떤 frame이 어느 cluster에 속하는지 알기 때문에 대략적인 classification을 수행할 수 있게 된다.
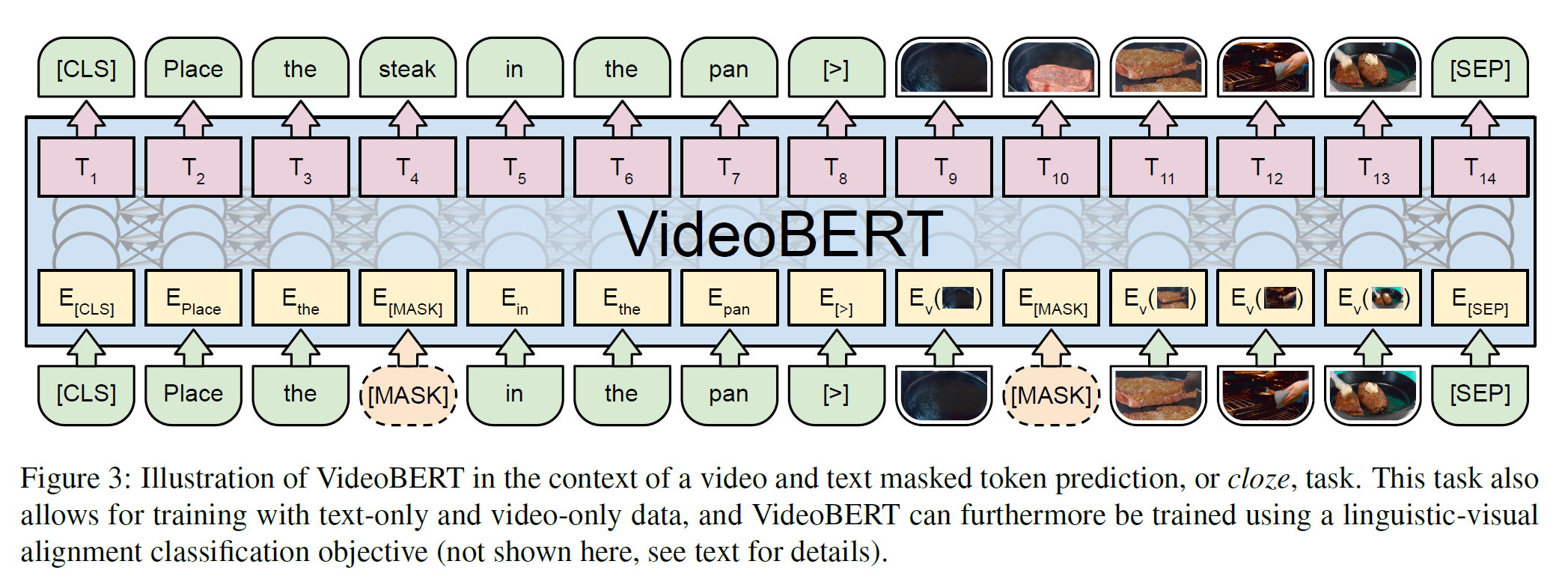
학습은 3가지 task를 사용한다.
- Linguistic-visual alignment: 텍스트가 video frame의 장면과 일치하는지를 판별한다.
- Masked Language Modeling(MLM): BERT의 것과 같다.
- Masked Frame Modeling(MFM): MLM과 비슷한데, word token을 복구하는 대신 masked frame의 cluster class를 예측한다.
Downstream task로
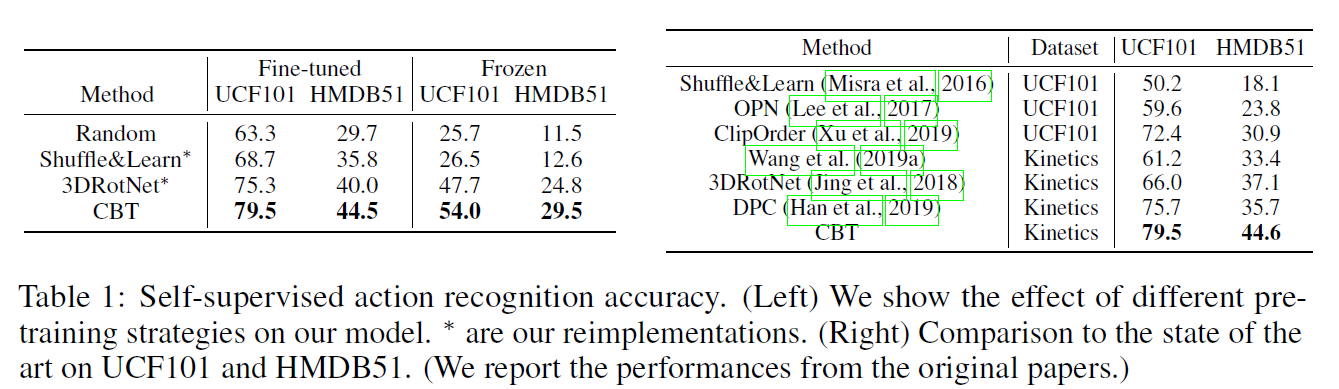
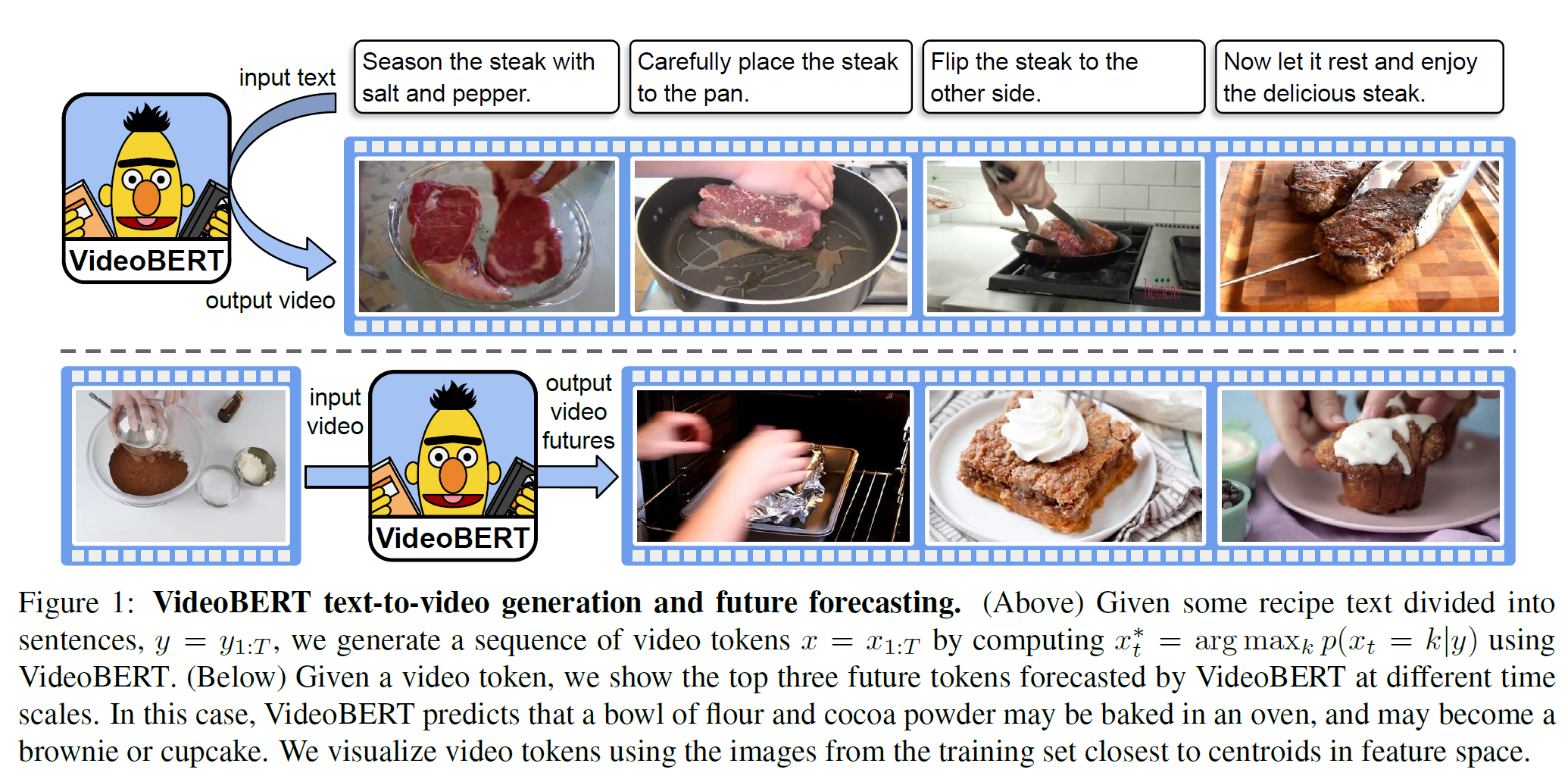
- Recipe Illustration(입력 문장이 들어오면 그에 맞는 video token을 생성한다)
- Future frame prediction(다음 frame 예측)
- Zero-shot action classification(비디오와
How to <mask> the <mask>와 갈은 템플릿 문장을 주면 문장을 완성하면서 어떤 action을 수행하는지를 맞추는 task) - Video captioning(Video에 맞는 caption 생성)
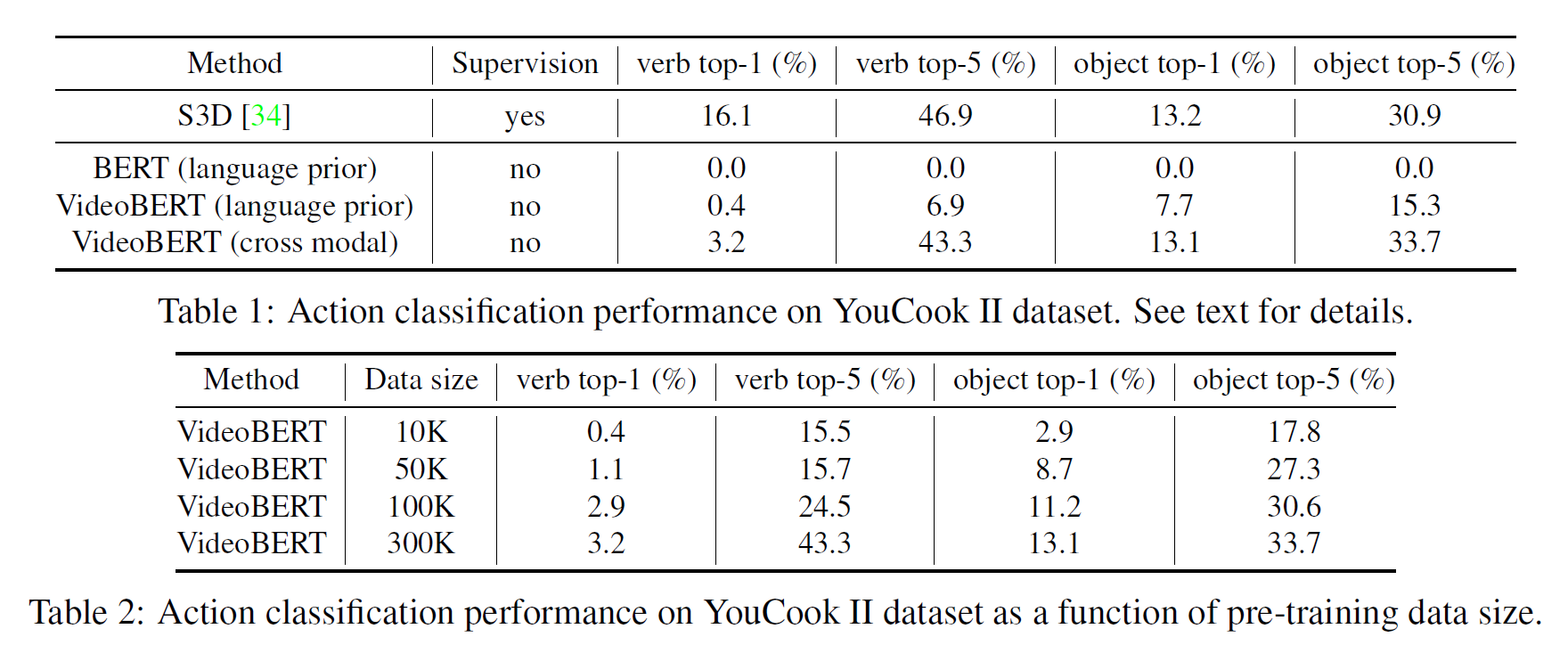
등을 수행하여 좋은 결과를 얻었다. 일부 결과를 아래에서 볼 수 있다.

CBT(Learning Video Representations using Contrastive Bidirectional Transformer)
논문 링크: Learning Video Representations using Contrastive Bidirectional Transformer
- 2019년 9월
- Google Research
- Chen Sun1 Fabien Baradel1;2 Kevin Murphy1 Cordelia Schmid1
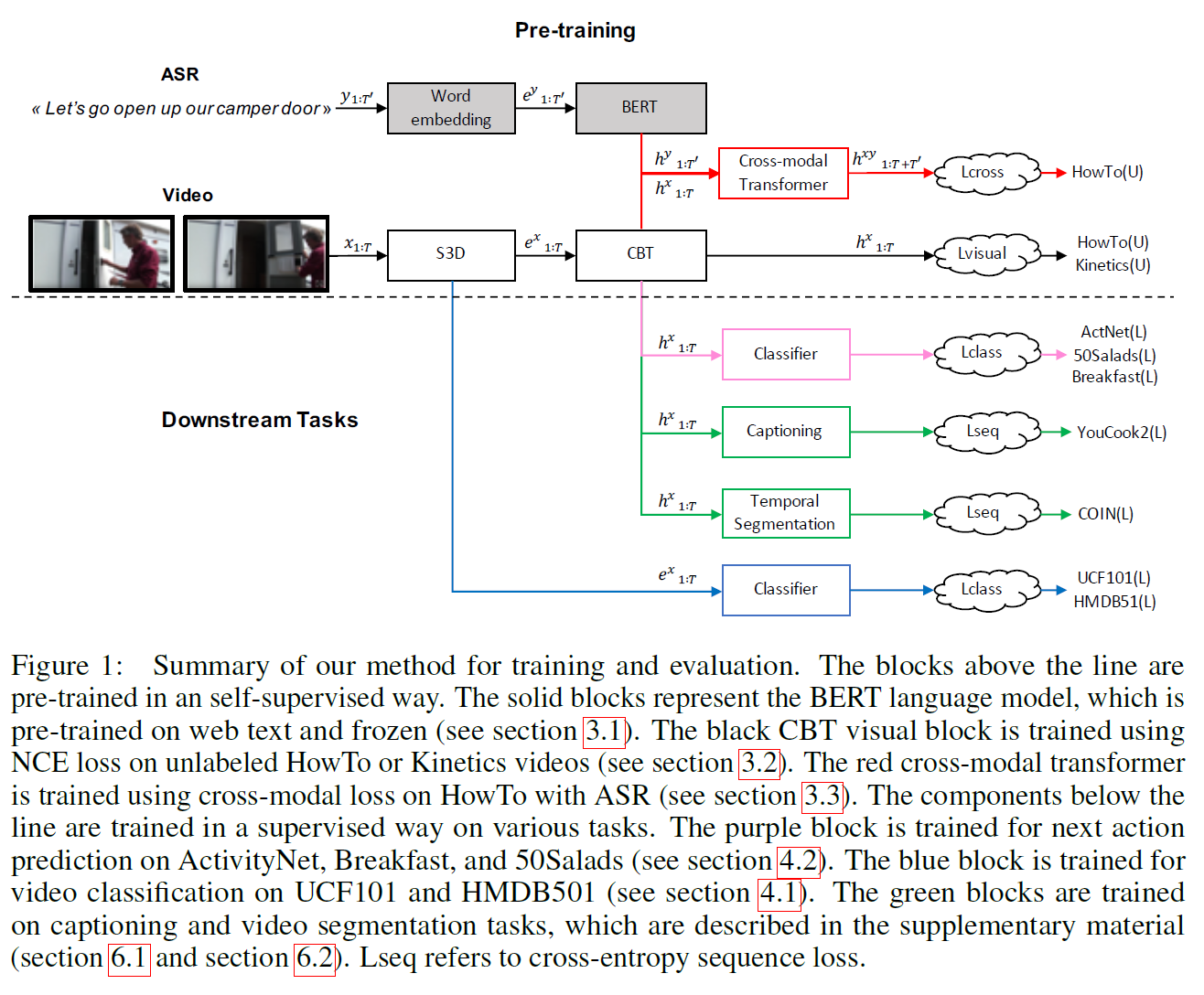
(거의) 갈은 저자들이 위의 VideoBERT 논문에서 end-to-end 학습을 막는 Clustering을 대체하는 방법을 제안한 논문이다.
텍스트에서 loss를 구할 때는 BERT에서와 같이 cross-entropy를 모든 단어에 대해서 확률을 계산하여 얻는다. 식으로 나타내면 다음과 같다.
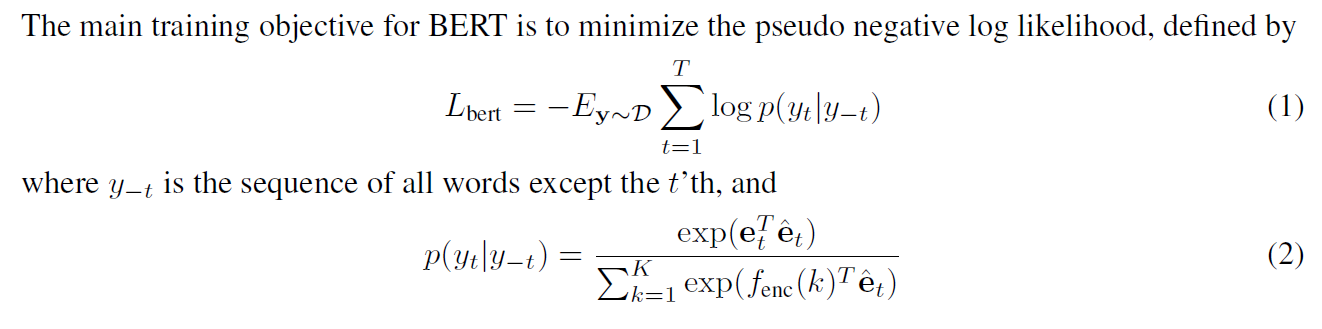
그러나 Video에서는 모든 video에 대해 계산을 할 수가 없다(Video frame의 차원이 너무 높음). 따라서 모든 경우에 대해 하는 대신 negative sampling을 통해 일부만 뽑아서 계산을 수행하게 된다. 식으로 나타내면 다음과 같다.

위와 같이 NCE loss를 사용하여 Clustering을 없애면 end-to-end 학습이 가능하게 된다.
요약하면,
- frame $\mathbf{x} = \lbrace x_1, …, x_m \rbrace $과 ASR token $\mathbf{y} = \lbrace y_1, …, y_n \rbrace $이 주어지면 모델은 그 correspondence/alignment를 학습한다.
- $\mathbf{x, y}$를 concat하여 cross-modal Transformer(VideoBERT 등)에 집어넣으면 embedding sequence $\mathbf{h} = \lbrace h_1, …, h_{m+n} \rbrace$를 얻을 수 있다.
- 전체 모델은 BERT, CBT, Cross-modal loss를 가중합하여 loss function으로 사용한다.
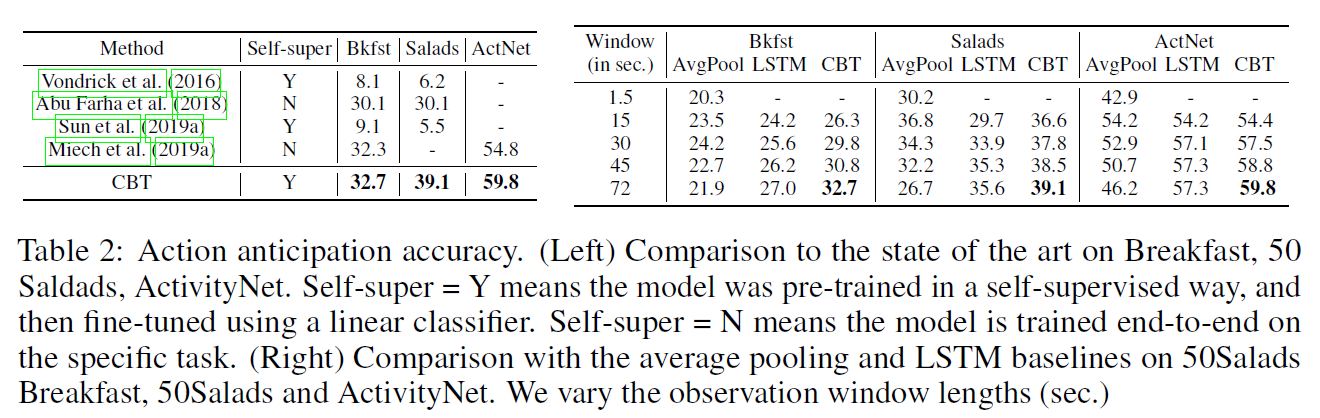
결과는 대략 아래와 같다.