
STAR benchmark 논문 설명(STAR - A Benchmark for Situated Reasoning in Real-World Videos)
07 Jun 2022 | Benchmark Video목차
이 글에서는 MIT 등 연구자들이 STAR benchmark 논문을 간략하게 정리한다.
STAR: A Benchmark for Situated Reasoning in Real-World Videos
논문 링크: STAR: A Benchmark for Situated Reasoning in Real-World Videos
Repo: http://star.csail.mit.edu/#repo
Github: https://github.com/csbobby/STAR_Benchmark
- NIPS 2021
- Bo Wu(MIT-IBM) et al.
Abstract
- 주변의 상황으로부터 지식을 얻고 그에 따라 추론하는 것은 매우 중요하고 또한 도전적인 과제이다.
- 이 논문에서는 실세계 영상에 대해 situation abstraction, logic-grounded 질답을 통해 situated 추론 능력을 평가하는 새로운 benchmark를 제시한다.
- STAR(Situated Reasoning in Real-World Videos)
- 이는 사람의 행동, 상호작용 등과 연관된 실세계 영상에 기반하여 만들어진 것으로 naturally dynamic, compositional, logical한 특성을 가진다.
- 4가지 형태의 질문(interaction, sequence, prediction, and feasibility)을 포함한다.
- 이 실세계 영상의 situations은 추출한 단위 entity와 relation을 연결한 hyper-graph로 구성된다.
- 질문과 답변은 절차적으로 생성되었다.
- 여러 영상 추론 모델을 이 데이터셋에 적용하여 보았을 때 상황 추론 task에서 어려움을 겪는 것을 발견하였다.
- Diagnostic neuro-symbolic 모델을 제시하며, 이 benchmark의 challenge를 이해하기 위한 이 모델은 visual perception, situation abstraction, language understanding, and functional reasoning을 disentangle할 수 있다.
1. Introduction
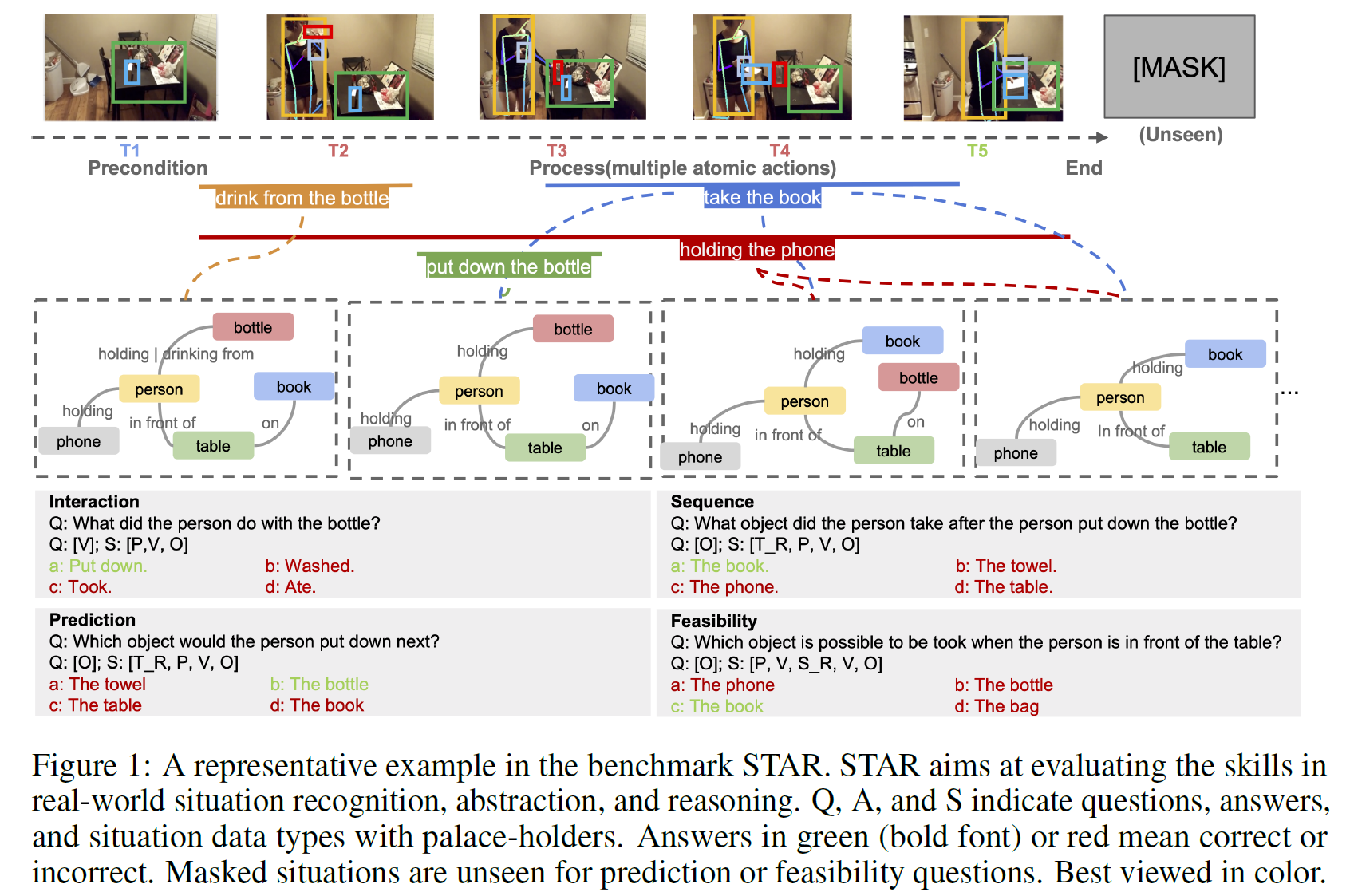
그림 1과 같은 (실세계) 상황에서 우리(사람)는 어떻게 행동할지, 현실적인 결정을 무의식적으로 내릴 수 있다. 그러나 기계한테는 주어진 문맥과 상황을 모두 고려하여 결정을 내린다는 것은 꽤 어려운 문제이다.
- 상황을 formulae의 집합으로 두고 가능한 logic 규칙을 만들어 이해하려는 시도가 있었으나 모든 가능한 logic rule을 만드는 것은 불가능하며 현실성이 떨어진다.
현존하는 비디오 이해 모델들을 도전적인 task에서 테스트한 결과 성능이 매우 낮아짐을 확인하였다. 이 모델들은 추론 자체보다는 시각적인 내용과 질답 간 연관성을 leverage하는 데에 집중하고 있었다.
이 논문에서는 STAR benchmark를 제안한다.
- 4종류의 질문을 포함한다: interaction question, sequence question, prediction question, and feasibility question.
- 각 질문은 다양한 장면과 장소에서 얻어진 action 중심 situation과 연관되어 있으며 각 situation은 여러 action과 연관되어 있다.
- 현존하는 지식과 상황에 따라 유동적으로 변화하는 지식을 표현하기 위해 entity와 relation으로 구조화된 표현으로 추상화하였다(situation hypergraphs).
- 시각적 추론 능력에 집중하기 위해 (자연어) 질문은 간결한 형태의 template에 맞춰 생성되었다.
- 보조 용도로, (더욱 어려운) 사람이 만든 질문을 포함하는 STAR-Humans도 같이 제공한다.
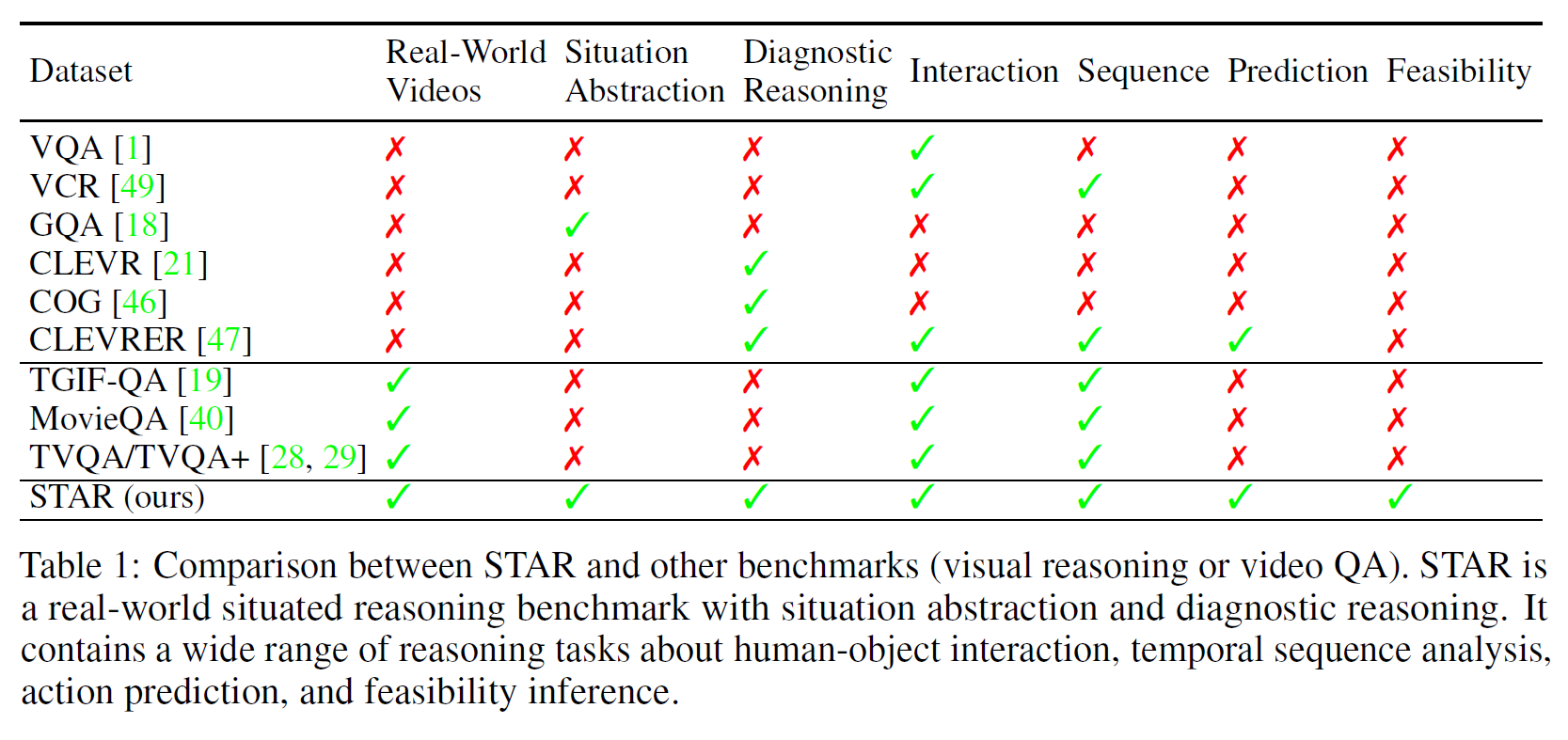
- 다른 데이터셋과 비교한 결과는 Table 1에 있다.
또한, Neuro-Symbolic Situated Reasoning (NS-SR)라는, 실세계 situated 추론을 위한 neural-symbolic 구조를 갖는 diagnostic model을 제안한다. 이는 질문에 답변하기 위해 구조화된 situation graph와 situation으로부터 얻은 dynamic clues를 활용한다.
이 논문이 기여한 바는,
- interaction, sequence, prediction, and feasibility questions에 집중하여, 실세계 영상에서 situated reasoning 문제를 형식화했다.
- situated reasoning을 위해 잘 설계된 benchmark인 STAR을 구성하였다.
- 3가지 측면(visual perception, situation abstraction and logic reasoning)에서 annotation이 설계되었다.
- 각 영상은 situation hyper-graph로 grounded되어 있으며 각 질문은 functional program으로 연관되어 있다.
- 여러 SOTA 방법을 STAR로 테스트해 보았고 ‘사람에게는 자명한 상황’에서 모델은 실수가 많음을 보였다.
- Diagnostic neuro-symbolic framework을 설계하였고 더욱 강력한 추론 모델을 위한 연구 방향을 제시하였다.
2. Related Work
- Visual Question Answering
- Visual Reasoning
모델의 추론 능력을 진단하기 위한 여러 데이터셋이 있다: CLEVR, GQA, MarioQA, COG, CATER, CLEVRER, etc.
- Situation Formalism
3. Situated Reasoning Benchmark
situations abstraction과 logical reasoning을 결합하였고, 아래 3가지 가이드라인을 따라 benchmark를 구축했다.
- 추상화를 위한 bottom-up anotations에 기반한 계층적 graph로 표현되는 situations
- situated reasoning을 위한 질문과 선택지 생성은 정형화된 질문, functional programs, 공통 situation data types에 grouded됨
- situated reasoning이 situation graphs에 대해 반복적으로 수행할 수 있음
만들어진 데이터셋의 metadata는 다음과 같다.
- 60K개의 situated reasoning 질의
- 240K개의 선택지
- 22K개의 trimmed situation video clip으로 구성된다.
- 144K개의 situation hypergraph(structured situation abstraction)
- 111 action predicates
- 28 objects
- 24 relationships
- train/val/test = 6:1:1
- 더 자세한 내용은 부록 2, 3 참조
3.1. Situation Abstraction
Situations
Situation은 STAR의 핵심 컨셉으로 entity, event, moment, environment를 기술한다. Charades dataset으로부터 얻은 action annotation과 9K개의 영상으로 situation을 만들었다. 영상들은 주방, 거실, 침실과 같은 11종류의 실내환경에서의 일상생활이나 활동을 묘사한다. 각 action별로 영상을 나눌 수 있으며 영상 역시 이에 맞춰서 나눌 수 있다.
각 action은 (1) action precondition과 (2) effect로 나눌 수 있다.
- action precondition은 환경의 초기 static scene을 보여주기 위한 첫 frame이다.
- action effect는 하나 또는 여러 개의 action의 process를 기술한다.
질문의 종류에 따라서는:
- interaction, sequence 타입의 question은 완전한 action segment를 포함한다.
- prediction, feasibility 타입의 question은 불완전한 action segment를 포함하거나 아예 포함하지 않는다.
Situation Hypergraph
Situation video를 잘 표현하기 위해, situation의 추상적인 표현을 얻기 위해 hypergraph 형태의 실세계 situation에서의 dynamic process를 기술한다. hypergraph는 action과 그 관계, 계층적 구조를 포함한다. 그림 1에서와 같이 각 situation video는 person 및 object node와, 한 frame 내의 person-object 또는 object-object 관계를 표현하는 edge를 포함하는 subgraph 여러 개로 구성된다. 한편 각 actino hyperedge는 여러 subgraph를 연결한다. 몇몇 경우에 여서 action이 겹치며 subgraph 안의 node들이 서로 공유된다.
수식으로 나타내면, $H = (X, E)$ : situation hypergraph $H$는 situation frame에 나타나는 person 또는 object를 나타내는 node들의 집합 $X$와 action들에 대한 subgraphs $S_i$의 hyperedge들의 공집합이 아닌 집합 $E$로 구성된다.
다른 spatio-temporal graph와 달리 action을 frame 수준 subgraph 대신 hyperedge로 나타낸다.
situation hypergraph의 annotation 작업은 다음과 같다:
- action temporal duration과 나타난 object들에 대한 annotation에 기반하여 one-to-many connection을 action hyperedge로 생성한다.
- action annotation은 Charades에서 얻었으며 person-object relationships(Rel1), objects/persons annotation은 ActionGenome에서 얻었다.
- object-object relationships(Rel2)는 detector VCTree(with TDE)를 사용하여 추출하였다.
- Rel1과 Rel2에 더하여 person-object relations(Rel3)을 추가하였다.
- 예를 들어
<person, on, chair>과<chair, on the left of, table>이라는 관계가 존재하면,<person, on the left of, table>또한 존재한다.
- 예를 들어
- 모든 모델은 video를 입력으로 사용하지만, hypergraph annotation(entities, relationships, actions, or entire graphs)는 더 나은 visual perception이나 structured abstraction을 학습하는데 사용될 수 있다.
3.2. Questions and Answers Designing
QA 엔진은 모든 질문, 답변, 옵션들을 situation hypergraph에 기반하여 생성한다.
Question Generation
situation reasoning에서 여러 난이도를 다루고 각각 다른 목적을 가지는 여러 타입의 질문을 설계하였다.
- Interaction Question (What did a person do …): 주어진 상황에서 사람과 물체 간 상호작용을 이해하는 기본 테스트이다.
- Sequence Question (What did the person do before/after …): dynamic situation에서 연속적인 action이 있을 때 시간적 관계를 추론하는 능력을 측정한다.
- Prediction Question ( What will the person do next with…): 현 상황에서 다음 행동으로 타당한 것을 예측하는 능력을 측정한다. 주어진 상황은 action의 첫 1/4만큼만 보여지며 질문은 나머지 action이나 결과에 대한 것이다.
- Feasibility Question (What is the person able to do/Which object is possible to be …): 특정 상황 조건에서 실현 가능한 action을 추론하는 능력을 평가한다. 상황 통제를 위해 spatial/temporal prompt를 사용한다.
일관성을 위해 모든 질문은 잘 설계된 template과 hypergraph의 data로부터 생성되었다. [P], [O], [V], [R]로 각각 person, objects, action verbs, relationships을 나타내고 생성 과정은 다음과 같다:
- situation annotations과 hypergraphs로부터 데이터를 추출한다.
- 추출한 데이터로 question template을 채운다.
- 어구 조합(phrase collocation)이나 형태론(morphology) 등으로 확장한다.
Answer Generation
STAR hypergraph에 기반한 functional program으로 정확한 답을 자동으로 만든다. Suppl. figure 5에서 자세한 과정을 볼 수 있다.
Distractor Generation
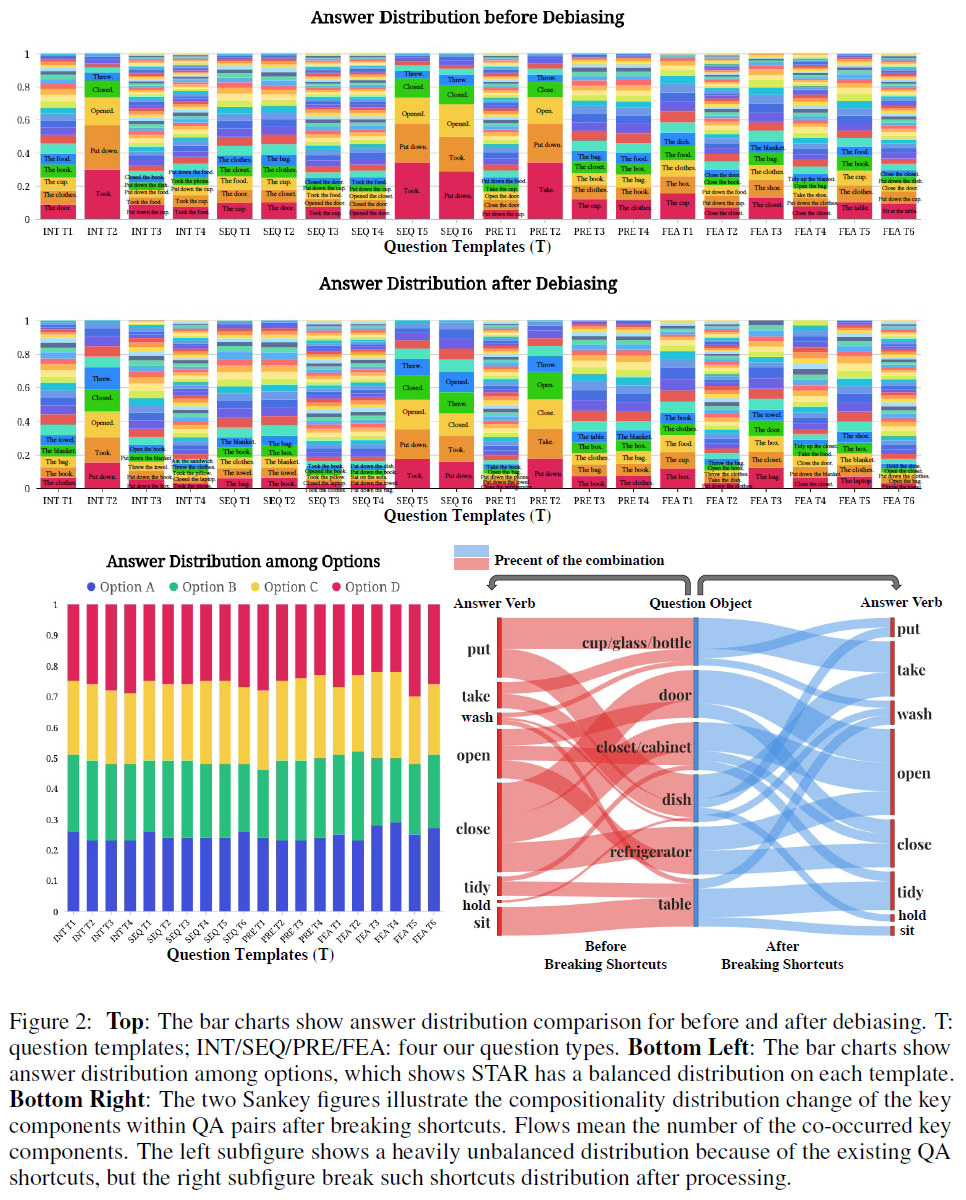
정말 추론을 잘하는지 아니면 단순 확률만 추정하는 건지 확인하기 위한 작업으로 다음 3가지 distractor 전략을 설계했다.
- Compositional Option: 주어진 상황과 반대되는 옵션을 주는 가장 어려운 옵션이다. 또한 잘 어울리는 verb-object이며(합성성compositionality를 만족) 같은 상황에서 일어나는 사실을 기반으로 만든다.
- Random Option: 이 옵션 역시 합성성을 만족하지만 다른 임의의 situation hypergraph에서 선택된다.
- Frequent Option: 모델을 확률로 속이는 옵션인데 각 질문 그룹에서 가장 자주 일어나는 옵션을 고른다.
모든 옵션은 각 질문에 대해 랜덤 순서로 배치된다.
Debiasing and Balancing Strategies
옷을 입는다나 문손잡이를 잡는다같이 자주 나타나는 단어쌍 등이 있는데 모델은 이를 통해 영상을 보지도 않고 답을 맞출 수도 있다. 이런 것을 막기 위해 다른 여러 단어들과 좋바될 수 있는 동사나 명사를 선택하여 남겨두었다. 즉 편향 제거 작업이다.
Grammar Correctness and Correlation
문법 체크기를 사용해서 정확성을 87%에서 98%로 올렸다.
Rationality and Consistency
생성된 situation video, 질문, 선택지의 품질과 상관성을 확보하기 위해 AMT를 사용, rationality와 consistency를 확보한 데이터만 남겼다.
4. Baseline Evaluation
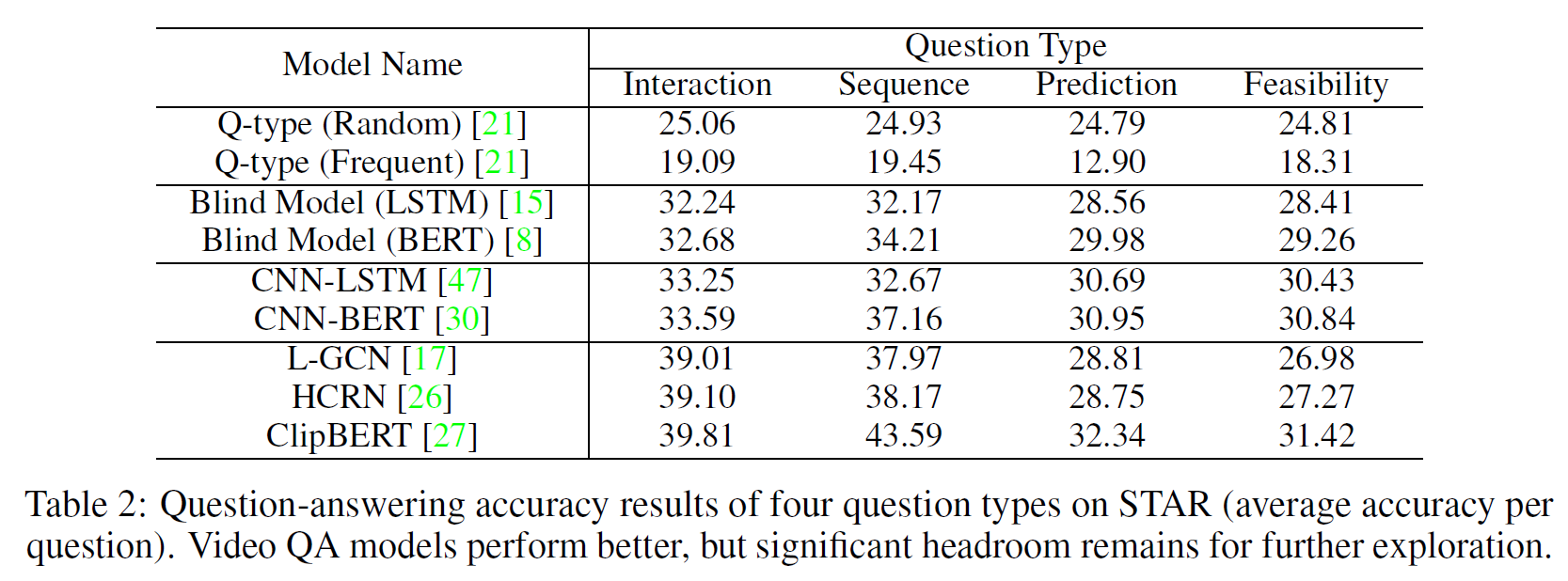
4지선다형 문제에 정답을 맞추는 비율로 여러 모델을 테스트했다.
사용한 모델들은 아래 표와 같다. Q-type random과 frequent는 각각 완전 임의선택, 가장 자주 나타나는 답만 선택하는 모델이다.
Blind Model은 언어 정보만 가지고 추론하는 모델이다.
4.1. Comparison Analysis
위 표 결과에서 보듯이 STAR는 질문이 여러 타입을 가져 꽤 어려운 문제임을 알 수 있다. object 상호작용이나(LGCN) 더 나은 visual representation을 얻을 수 있는 HCRN, ClipBERT 등의 모델이 성능이 좀 낫다.
5. Diagnostic Model Evaluation
neuro-symbolic framework인 Neuro-Symbolic Situated Reasoning(NS-SR)을 diagnostic model로 제안한다.
5.1. Model Design
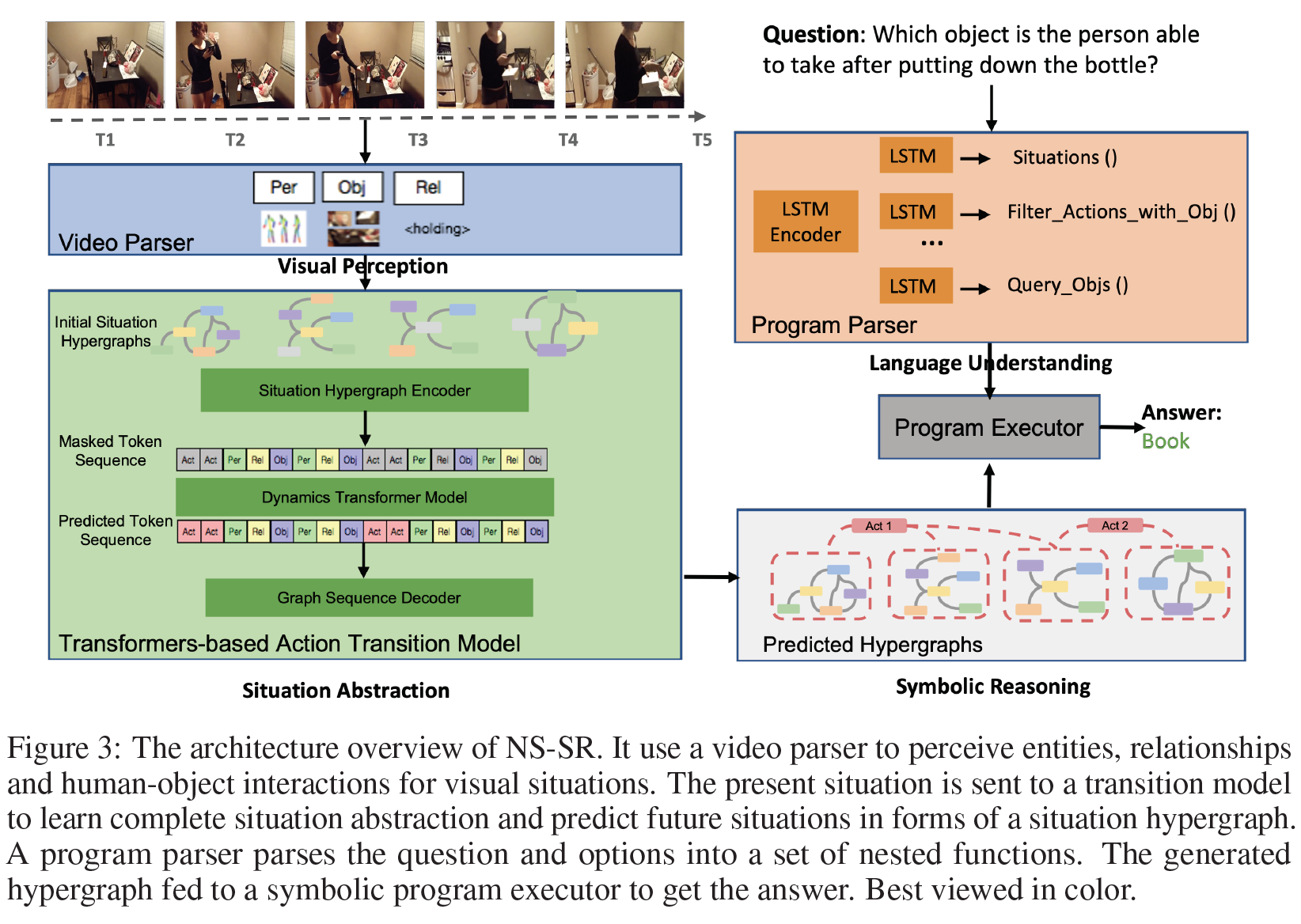
Video Parser
사람 또는 물체 중심 상호작용 정보를 얻는 detector로 구성된다.
- object는 Faster R-CNN, X101-FPN
- relationships는 VCTree with TDE-sum, GloVe
- pose는 AlphaPose
- action은 MoViNets
를 사용했다.
Transformers-based Action Transition Model
- Situation Hypergraph Encoder: 추출한 entity나 relation을 연결하여 “초기” situation hypergraph를 생성한다.
- Dynamics Transformer Model: dynamic하게 action state나 relationship을 예측하도록 설계되었다. transformer block은 VisualBERT로 구현하였다.
- Graph Sequence Decoder
Language Parser
attention 기반 Seq2Seq 모델로 질문을 대응되는 program으로 parsing한다. 데이터셋의 질문이 single-select이므로 질문 및 선택지를 각각 parsing하는 2개의 모델을 사용했다. 각각 bidirectional LSTM encoder와 LSTM decoder로 구성된다.
Program Executor
hypergraph 위에서 program을 실행하는 Program Executor를 설계했다. 질문을 parsing한 program을 그대로 hypergraph 위에서 따라가며 추론하는 방식이라고 생각하면 된다.
5.2. Result Analysis
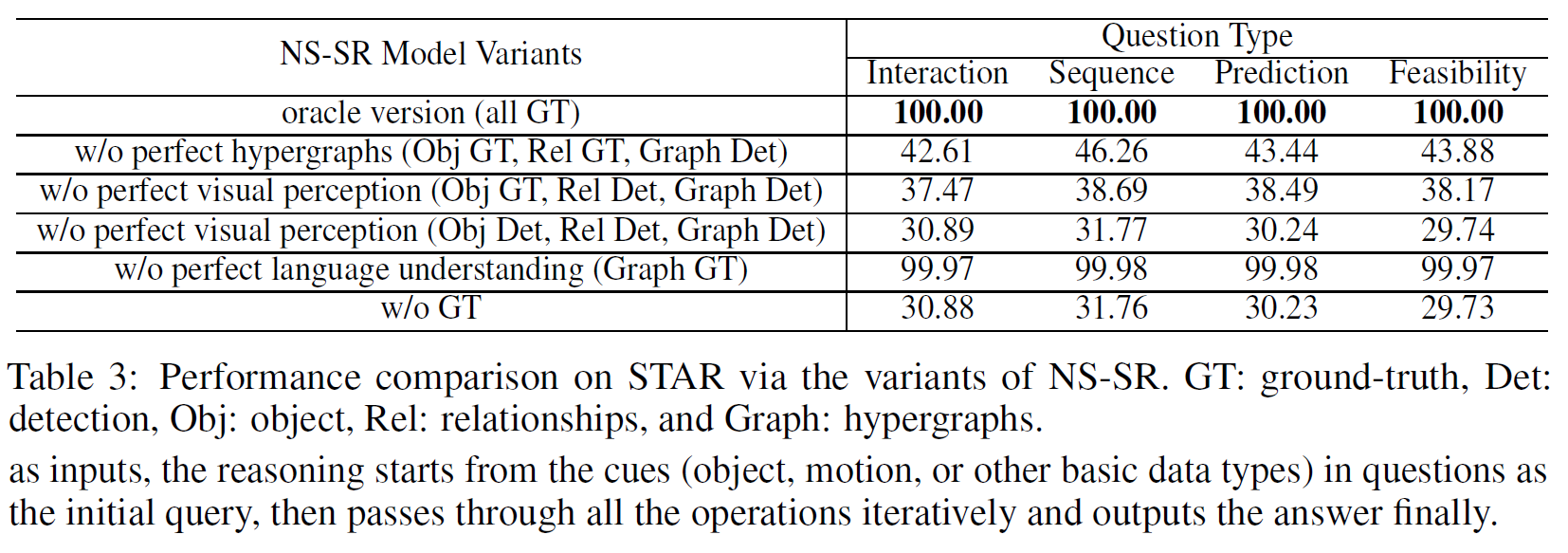
완벽한 GT를 가지고 program을 수행하면 당연하게도 100% 정답률을 보인다. (데이터셋이 그렇게 만들어졌으므로)
아래는 각 요소가 없는 경우를 분석한 것이다.
Situation Abstraction: 완벽한 시각적 인식과 추론 논리를 가지지만 완벽한 구조화된 상황 추상화 능력이 없어 성능이 많이 떨어진다. Visual Perception: 시각적 정보를 처리하는 것이 중요함을 나타낸다. 성능이 더 떨어졌다. Language Understanding: 완벽한 프로그램을 사용하지 않는 경우 성능은 1% 이내로 약간 감소한다. 이는 STAR의 언어 인식이 어렵지 않다는 것을 의미한다. Without Ground-Truths: 이 결과는 그리 좋지 못한데 추가 연구가 많이 이루어질 수 있다. visual perception과 situation abstraction을 개선하는 데 초점을 맞춰야 한다.
6. Conclusion
- 실제 상황에서의 추론을 위해 새로운 벤치마크 STAR를 도입하여 그에 맞는 추론 방법을 모색하였다.
- 지각 외에도 상향식 상황 추상화와 논리적 추론을 통합합니다.
- 상황 추상화는 동적 상황에 대한 통합적이고 구조화된 추상화를 제공하며, 논리적 추론은 정렬된 질문, 프로그램 및 데이터 유형을 채택합니다.
- 시스템이 동적 상황에서 학습하고 특정 상황에서 네 가지 유형의 질문(상호작용, 순서, 예측, 실현 가능성)에 대한 합리적인 답을 찾아야 하는 상황 추론 과제를 설계하였다.
- 실험을 통해 상황적 추론이 최첨단 방법으로는 여전히 어려운 과제임을 입증하였다.
- 또한 neuro-symbolic architecture로 새로운 진단 모델을 설계하여 상황적 추론을 탐구하였다.
- 상황 추론 메커니즘이 완전히 개발되지는 않았지만, 이 결과는 벤치마크의 도전과제를 보여주고 향후 유망한 방향을 제시하였다.
- STAR 벤치마크가 실제 상황 추론에 대한 새로운 기회를 열어줄 것으로 믿는다고 한다.