
Resnet 계열 image classification 모델 설명
26 Jun 2022 | Computer Vision목차
이번 글에서는 Resnet을 기반으로 한 여러 image classification 네트워크 들에 대해 정리해보겠습니다.
그 대상은 아래와 같습니다.
- ResNeXt(2017)-Aggregated Residual Transformations for Deep Neural Networks
- ResNeSt(2020)-Split-Attention Networks
- Res2Net(2021)-A New Multi-scale Backbone Architecture
- ReXNet(2021)-Rethinking Channel Dimensions for Efficient Model Design
본 글에서는 핵심적인 부분에 대해서만 살펴보겠습니다.
ResNeXt 설명
ResNext에서는 cardinality라고 하는 개념이 등장합니다. transformation 작업의 크기 혹은 종류라고 생각하면 되는데, 이 hyper-parameter만 잘 조절해도 depth나 channel을 크게 증가시키지 않으면서도 성능 향상을 이끌어 낸다고 합니다.
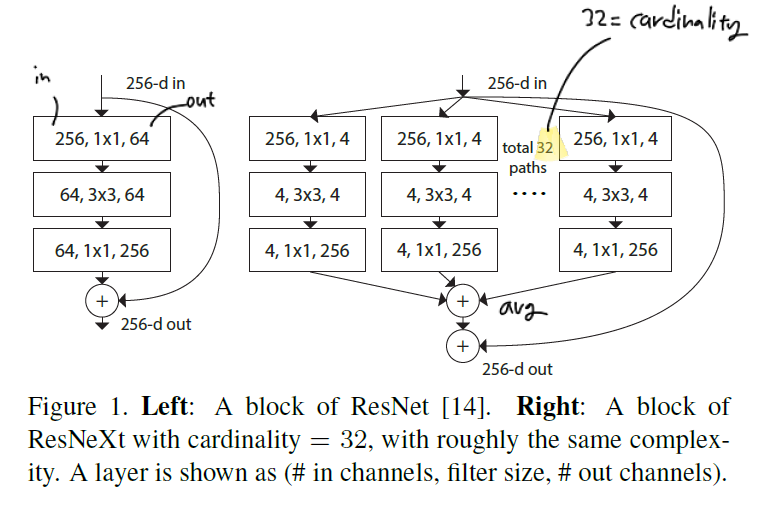
왼쪽은 ResNet에 등장했던 bottleneck layer의 구조입니다. 오른쪽은 ResNeXt에서 제안된 구조인데, cardinality를 32개로 설정, 즉 path를 32개로 만든 뒤, 이를 average 하여 병합하는 것을 알 수 있습니다. shortcut 구조는 동일합니다.
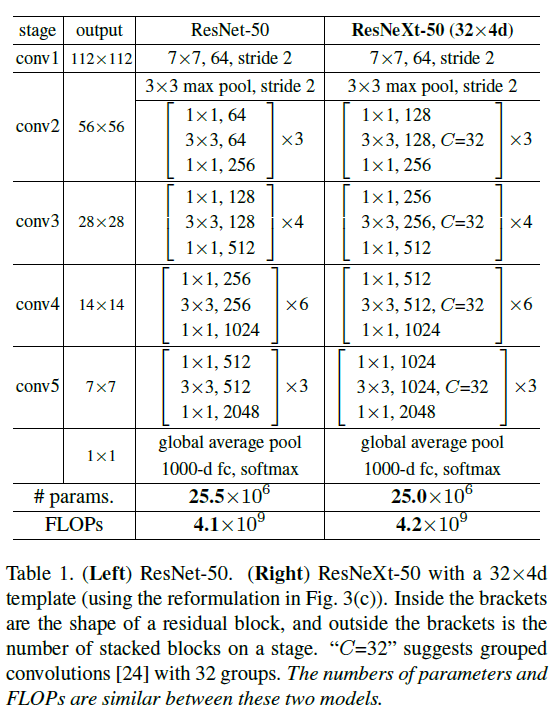
ResNet-50과 ResNeXt-50 with 32x4d 구조를 보면, parameter 수나 FLOPs의 경우 유사함을 알 수 있습니다.
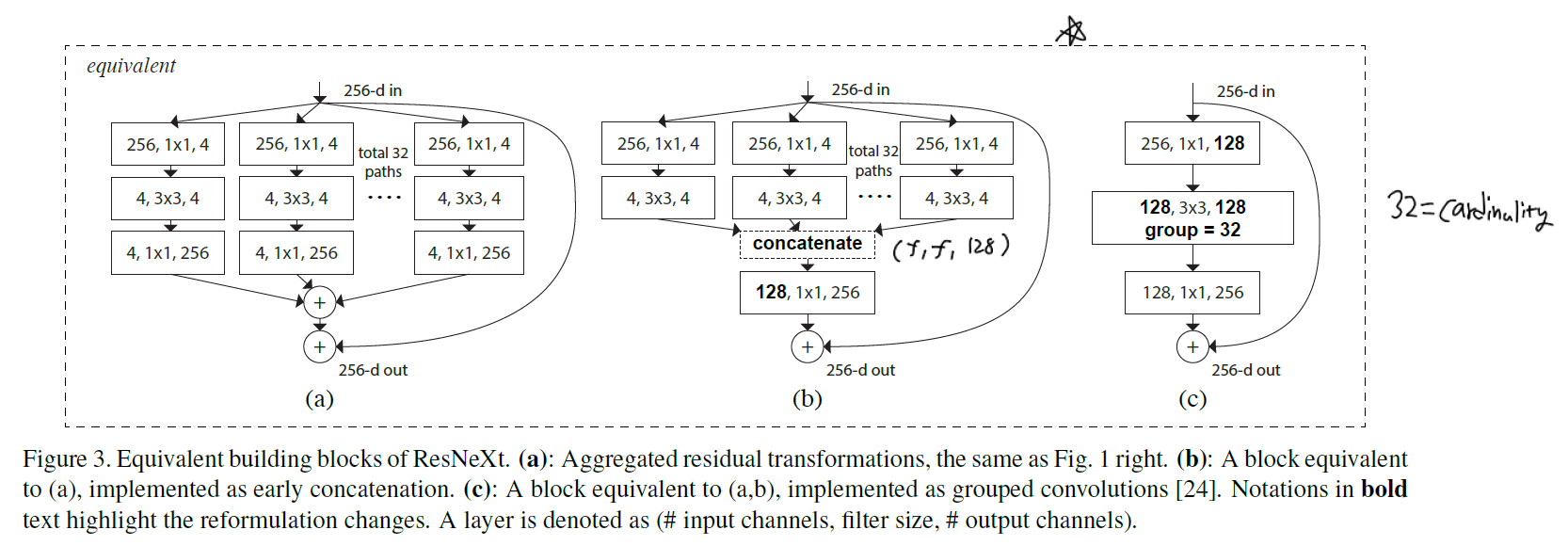
실제로 같은 연산이지만 표현 방식은 아래와 같이 다양합니다.
ResNeSt 설명
1. 핵심 내용
feature map attention과 multi-path representation이 visual recognition에서 중요하다는 사실은 잘 알려진 사실입니다. ResNeXt에서는 다른 network branch에 대하여 channel-wise attention을 적용함으로써 cross-feature interaction을 포착하고 다양한 representation을 학습하는 데에 있어 효과적인 방법론을 제시합니다.
위에서 소개하였던 ResNeXt에서 cardinality (K) hyperparameter를 이야기 하였는데요, 이 값은 곧 featuremap group의 수를 의미합니다. 본 논문에서는 이 featuremap group을 cardinal group이라고 부릅니다. 그리고 이 cardinal group을 또 나눈 (split) 수를 의미하는 $R$ = radix hyper-parameter 라는 개념을 추가합니다. 즉 모든 feature group의 수는 아래와 같이 표현할 수 있습니다.
- $G$ = feature group 총 수
- $K$ = # cardinality
- $R$ = # splits within cardinal group
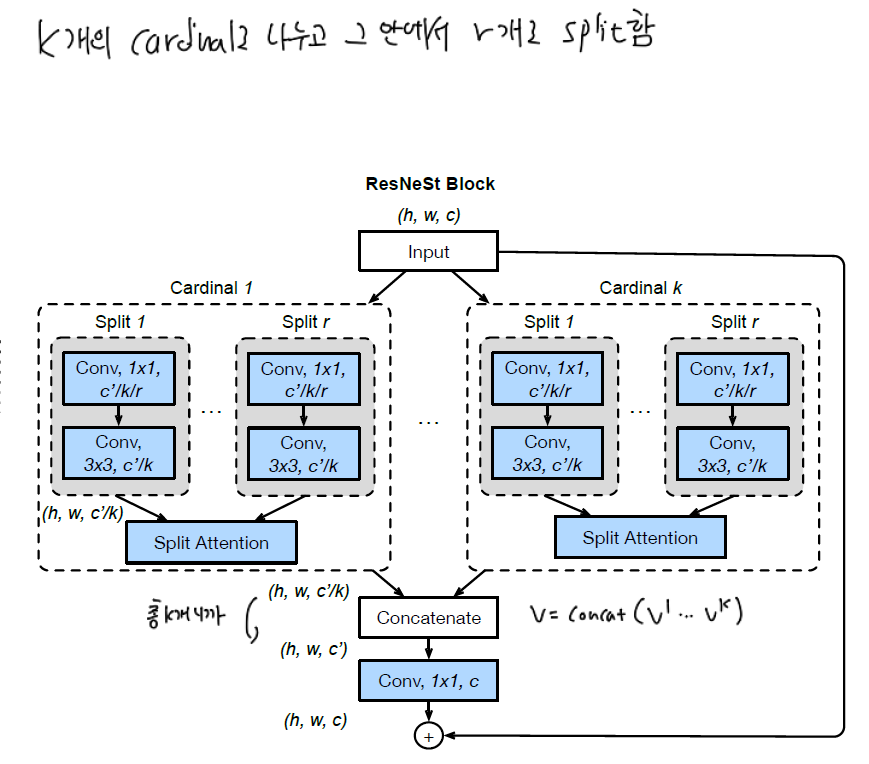
즉, input feature의 채널이 $C$ 개 있다고 할 때 이를 $K$ 개의 cardinality group으로 나누고, 이를 다시 $R$ 개로 split 하는 것입니다.
$k$ 번째 cardinality group의 representation은 아래와 같이 표현됩니다.
\[\hat{U}^k = \Sigma_{j = R(k-1) + 1}^{RK} U_j\] \[k \in 1, 2, .,,, K\] \[\hat{U}^k \in \mathbb{R}^{H, W, C/K}\]k=1 일 때, j=1~R
k=2 일 때, j=R+1 ~ 2R 이 됩니다.
위 그림의 split-attention 과정까지 합쳐서 shape이 변화하는 과정을 나타내면 아래와 같습니다.
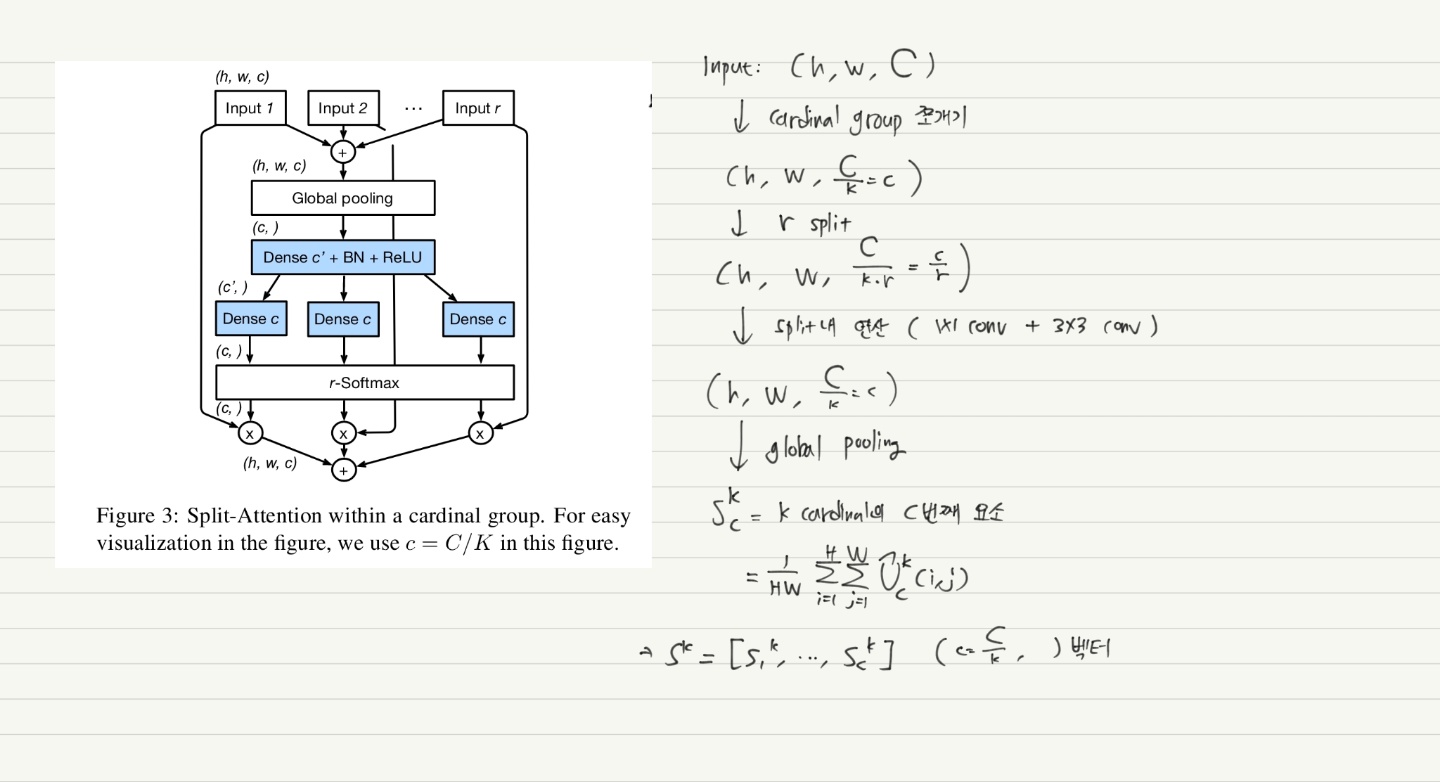
이렇게 구해진 $s_c^k$ 는 일종의 attention score의 역할을 수행하게 되고, 최종적으로 cardinal group representation의 가중 결합은 channel-wise soft attention을 통해 이루어지게 됩니다.
지금까지 설명한 것은 사실 cardinality-major 구현 방식인데, 실제로 이 방식으로 표준 CNN을 구성하는 것은 기술적으로 어렵습니다. 따라서 실제 코드로 구현해서 사용할 때는 radix-major 구현 방식을 이용한다고 합니다.
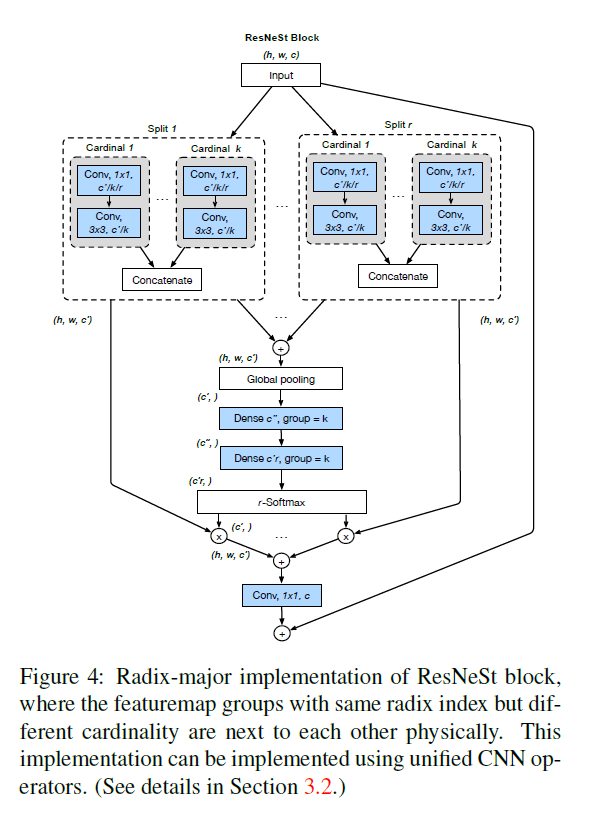
자세한 학습 방식과 실험 결과는 논문을 참조하길 바랍니다. 몇 가지만 메모를 하자면,
- 네트워크의 마지막 2단계에서 DropBlock layer를 사용했습니다.
- conv, fc layer에만 weight decay를 적용하였습니다.
- 본 네트워크는 ResNet-D에 기반하였는데, 몇 가지 layer 구성 방식이 다릅니다. 자세한 사항은 논문 5페이지를 참조하면 됩니다.
- auto augmentation, mixup, large crop 등의 기법을 통해 성능을 향상시켰습니다.