
Contextual Bandit and Tree Heuristic
18 Sep 2019 | Machine Learning Paper_Review Contextual Bandit목차
1. Contextual Bandit의 개념
Contextual Bandit 문제를 알기 위해선 Multi-Armed Bandit 문제의 개념에 대해 숙지하고 있어야 한다.
위 개념에 대해 알기를 원한다면 여기를 참고하기 바란다.
Multi-Armed Bandit 문제에서 Context 개념이 추가된 Contextual Bandit 문제는 대표적으로 추천 시스템에서 활용될 수 있다. 단 전통적인 추천 시스템을 구축할 때는 Ground Truth y 값, 즉 실제로 고객이 어떠한 상품을 좋아하는지에 대한 해답을 안고 시작하지만, Contextual Bandit과 관련된 상황에서는 그러한 이점이 주어지지 않는다.
그림을 통해 파악해보자.
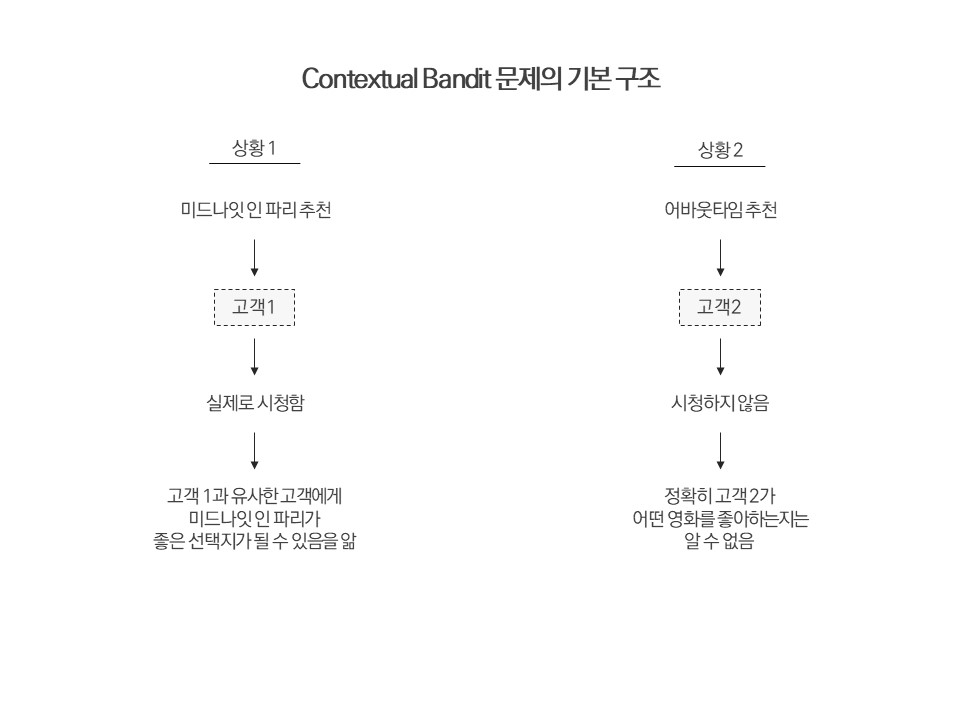
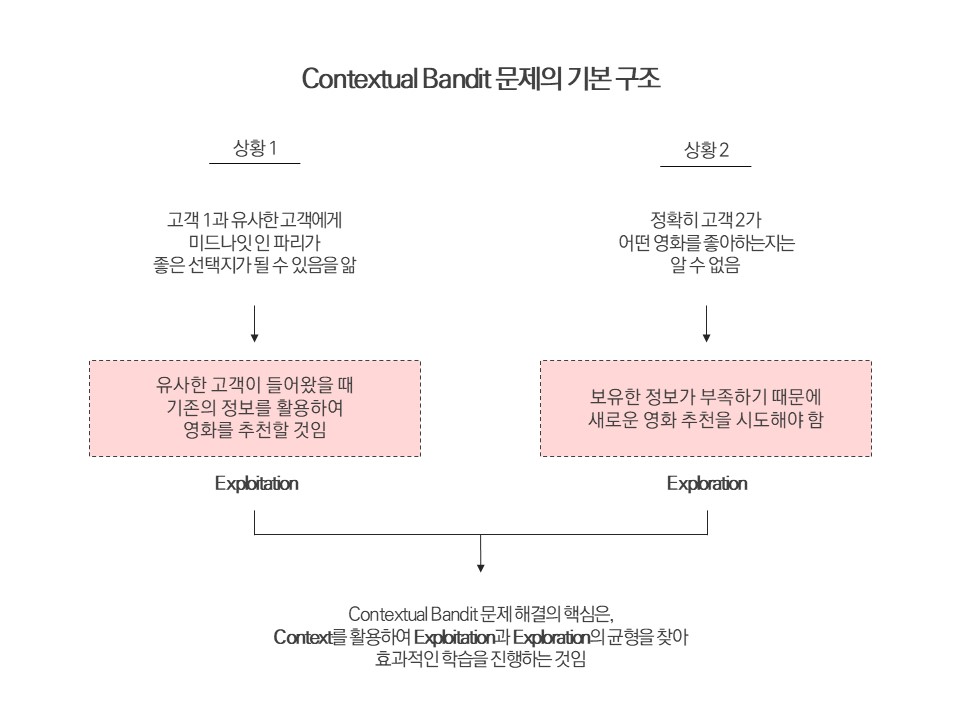
첫 번째 그림은 전통적인 추천시스템에 관한 것이고, 두 번째 그림은 Contextual Bandit 문제와 관련된 것이다.
온라인 상황에서 우리가 고객에게 어떠한 상품을 제시하였을 때, 고객이 그 상품을 원하지 않는다면 우리는 새로운 시도를 통해 고객이 어떠한 상품을 좋아할지 파악하도록 노력해야 한다. 이것이 바로 Exploration이다.
만약 고객이 그 상품에 호의적인 반응을 보였다면, 이 또한 중요한 데이터로 적재되어 이후에 동일 혹은 유사한 고객에게 상품을 추천해 주는 데에 있어 이용될 것이다. 이 것이 Exploitation이다.
위 그림에 나와 있듯이, Contextual Bandit 문제 해결의 핵심은, Context(고객의 정보)를 활용하여 Exploitation과 Exploration의 균형을 찾아 어떤 Action을 취할 것인가에 대한 효과적인 학습을 진행하는 것이다.
2. Lin UCB
Lin UCB는 A contextual-bandit approach to personalized news article recommendation논문에 처음 소개된 알고리즘으로, Thompson Sampling과 더불어 Contextual Bandit 문제를 푸는 가장 대표적이고 기본적인 알고리즘으로 소개되어 있다.
이 알고리즘의 기본 개념은 아래와 같다.
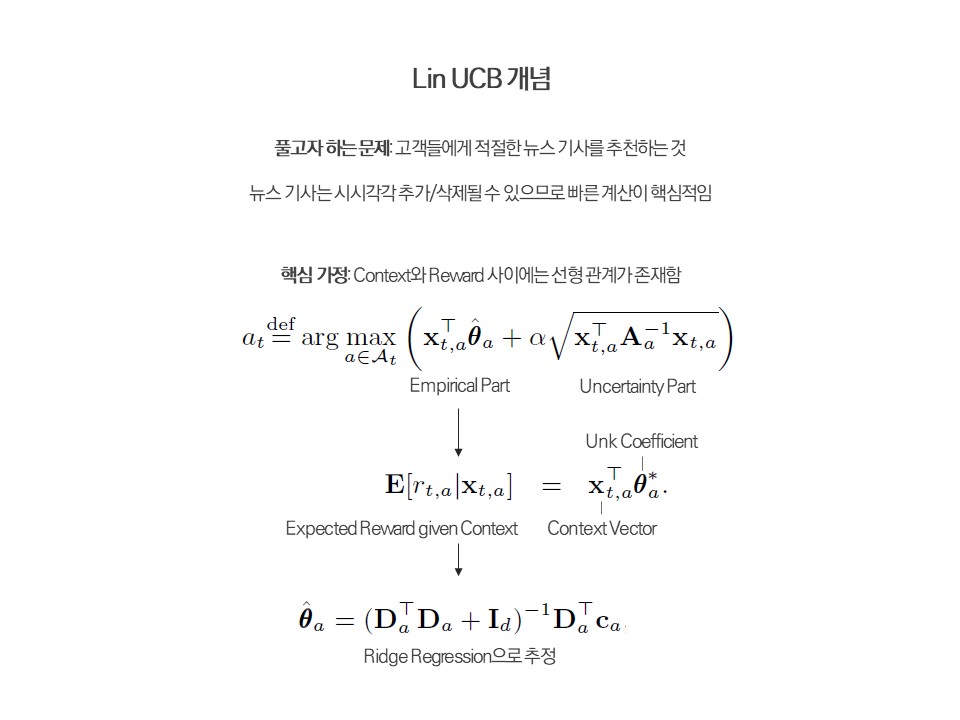
Context Vector를 어떻게 구성할 것인가에 따라 Linear Disjoint Model과 Linear Hybrid Model로 구분된다. Hyperparameter인 Alpha가 커질 수록 Exploration에 더욱 가중치를 두게 되며, 결과는 이 Alpha에 다소 영향을 받는 편이다.
본 알고리즘은 이후 Tree Heuristic과의 비교를 위해 테스트 용으로 사용될 예정이다.
3. Tree Heuristic
3.1 Tree Boost
Tree Heuristic에 접근하기 위해서는 먼저 그 전신이라고 할 수 있는 Tree Boost 알고리즘에 대해 알아야 한다. 본 알고리즘은 A practical method for solving contextual bandit problems using decision trees 논문에서 소개되었다.
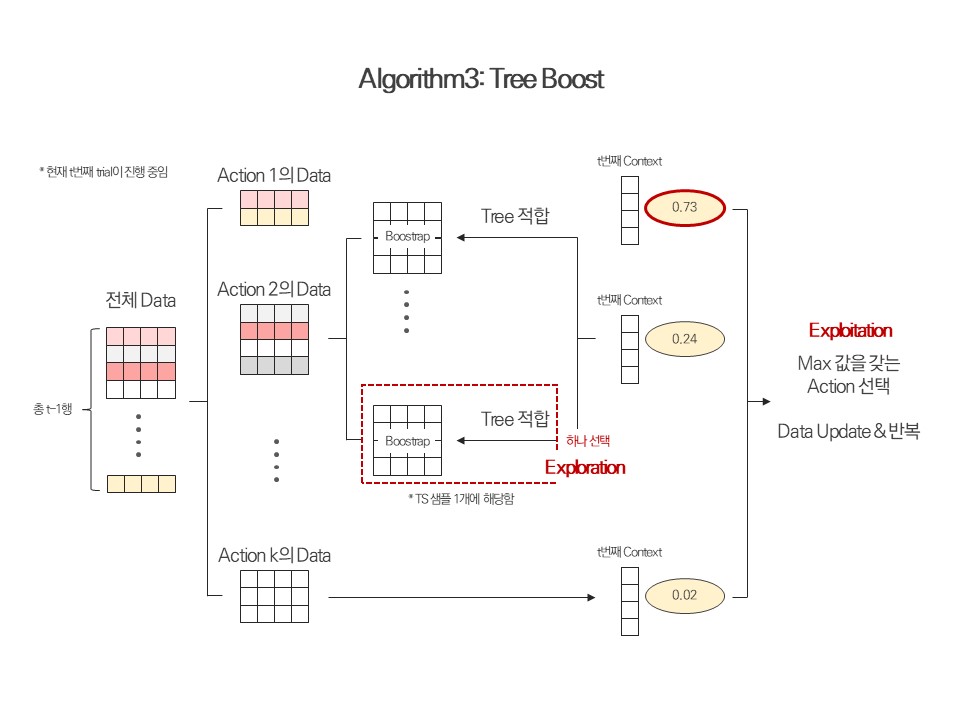
Tree Boost는 Thompson Sampling의 개념을 차용하여 설계된 알고리즘이다. 위의 Lin UCB가 Context와 Reward 사이의 관계를 선형적으로 정의하였다면, 본 알고리즘은 Tree 계열의 모델로써 이 관계를 정의한다.
Tree Boost의 작동 원리를 알아 보자. 한 고객의 정보가 입수되었다. 이 정보는 1개의 Context Vector라고 할 수 있다. 우리가 취할 수 있는 Action이 총 k개 있다고 가정하면, 각각의 Action과 연결된 Tree 모델에 방금 입수한 Context Vector를 투입하고 Reward가 1이 될 확률(Score)값을 얻는다. 가장 높은 값을 갖는 Action을 선택하여 고객에게 제시한다.
제시가 끝난 후에 고객의 반응(Reward가 1인지, 0인지)이 확인되었다면, 이를 제시하였던 Action의 Sub-data에 적재한다. 즉, 각 데이터(Design Matrix)는 제시한 Action의 Sub-data에 소속되는 것이다. 이 Sub-data들을 모두 모으면 전체 데이터가 구성된다.
Sub-data 내에서 부트스트랩을 여러 번 진행하고 그 중 하나를 선택하여 Tree 모델에 적합시키는데, 이 과정이 Exploration 과정에 해당하며, 선택된 데이터셋과 Tree 모델은 Thompson Sampling에서 사용되는 샘플 1개에 해당한다.
이후에 설명하겠지만, Tree Boost의 성능은 뛰어난 편이다. 그러나 이 모든 과정을 거치기에는 굉장히 많은 시간이 소요되며, 신속성이 중요한 평가 포인트라고 할 수 있는 Contextual Bandit 알고리즘들 사이에서 현실적으로 우위를 보이기는 어려운 것이 사실이다. 따라서 아래에 있는 Tree Heuristic이라는 알고리즘이 제시되었다고 볼 수 있다.
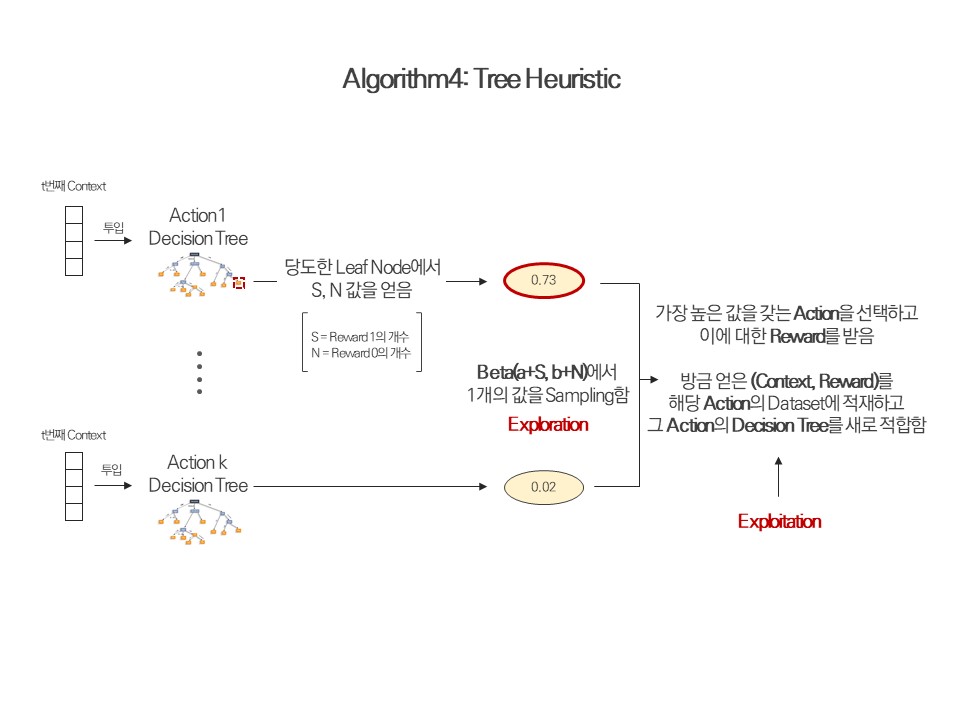
3.2 Tree Heuristic
Tree Boost와의 가장 큰 차이점은 바로, 한 Trial에 한 번만 적합을 진행하여 속도를 향상시켰다는 점이다. Tree Boost의 경우 각 Action 마다 부트스트랩 과정을 여러 번 시키고, 또 선택된 데이터에 Action 수 만큼 모델을 적합해야 했기 때문에 굉장히 오랜 시간이 소요되었는데 Tree Heuristic은 그러한 과정을 겪을 필요가 없는 것이다.
알고리즘의 실질적인 작동원리는 아래 그림과 코드를 보면 상세히 설명되어 있다.
"""
Tree Heuristic Implementation with Striatum Module
본 알고리즘은 Striatum Module의 가장 기본적인 class들을 활용하였음
"""
import time
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from striatum.bandit.bandit import BaseBandit
from striatum.storage import history, action, model
from sklearn.externals.joblib import Parallel, delayed
from sklearn.multiclass import _fit_binary, OneVsRestClassifier
from sklearn.preprocessing import LabelBinarizer
from sklearn.tree import DecisionTreeClassifier
# 터미널을 클린하게 해야 함
warnings.simplefilter(action='ignore', category=FutureWarning)
warnings.simplefilter(action='ignore', category=UserWarning)
class CustomOneVsRestClassifier(OneVsRestClassifier):
"""
현재 scikit-learn의 OneVsRestClassifier class 의 경우,
내부에 있는 Classifier 객체들이 독립적이지 않아 개별 접근이 불가능함
따라서 개별 접근이 가능하게 (각 Action 별로 다른 모델이 필요하므로)
본 클래스를 수정해주어야 함
참조: https://www.oipapio.com/question-3339267
"""
def __init__(self, estimators, n_jobs=1):
super(CustomOneVsRestClassifier, self).__init__(estimators, n_jobs)
self.estimators = estimators
self.n_jobs = n_jobs
def fit(self, X, y):
self.label_binarizer_ = LabelBinarizer(sparse_output=True)
Y = self.label_binarizer_.fit_transform(y)
Y = Y.tocsc()
self.classes_ = self.label_binarizer_.classes_
columns = (col.toarray().ravel() for col in Y.T)
# This is where we change the training method
self.estimators_ = Parallel(n_jobs=self.n_jobs)(delayed(_fit_binary)(
estimator, X, column, classes=[
"not %s" % self.label_binarizer_.classes_[i],
self.label_binarizer_.classes_[i]])
for i, (column, estimator) in enumerate(zip(columns, self.estimators)))
return self
class RecommendationCls(object):
"""
우리가 추천한 Action 의 정보들을 저장할 클래스
"""
def __init__(self, action, score, reward=None):
self.action = action
self.score = score
self.reward = reward
class TreeHeuristic(BaseBandit):
"""
Tree Heuristic Algorithm:
Context 와 Reward 의 관계를 Tree Model 로서 정의내리고,
Decision Tree 의 학습결과에 기반하여 Beta 분포 Sampling 을 진행하여 Action 을 선택하는 알고리즘임
"""
def __init__(self,
history_storage,
model_storage,
action_storage,
n_actions,
):
super(TreeHeuristic, self).__init__(history_storage, model_storage, action_storage,
recommendation_cls=RecommendationCls)
# 1) history_storage 에는 매 trial 에서 진행되었던 기본적인 record 가 담겨 있음
# 2) model_storage 는 Lin UCB 에서는 model parameter 가 저장되는 공간인데, 본 알고리즘에선 사실 쓰임새는 없음
# 3) action_storage 에는 선택된 Action 의 ID 와 Score 가 저장됨
# oracle: Action 수 만큼의 Decision Tree 를 담고 있음
# n_actions: Action 수
# n_features: Feature 수
# D: Action 별로 적재한 데이터, 딕셔너리구조이며 value 자리에는 각 Action 에 맞는 np.array 가 적재됨
# first_context = 첫 손님, 처음 Input 으로 주어지는 Context
# -> 얘를 저장하여 가짜 데이터를 만듦, build 메서드를 참고
self.oracles = CustomOneVsRestClassifier([DecisionTreeClassifier() for i in range(n_actions)])
self.n_actions = n_actions
self.n_features = None
self.D = None
self.first_context = None
def build(self, first_context, actions):
"""
1) first_context 저장 및 n_features 저장
2) Action objects 를 self._action_storage 에 저장함
3) 가짜 데이터를 집어 넣어 D 를 만듦
4) 초기 fitting 을 진행 함
:param first_context: np.array (n_features, ) 첫 번째 context
:param actions: list of action objects(Striatum 모듈 기본 class), action 의 종류를 담고 있음
"""
self.first_context = first_context
self.n_features = first_context.shape[0]
self._action_storage.add(actions)
# Add Fabricated Data
# 적합을 진행하려고 하는데 만약 Label 이 오직 0만 존재한다거나 하는 상황이 오면
# Classifier 를 그 데이터에 적합시키는 것은 불가능함
# 가짜 데이터를 D 에 미리 적재함으로써 이 문제를 해결함 (논문 참조)
# 데이터의 개수가 늘어날 수록 이 가짜 데이터의 영향력은 약화됨
# D 에서 각 Action 에 맞는 np.array 의 마지막 열은 실제 Reward 값이며, 그 외의 열에는 Feature 값이 들어감
x1, x2 = np.append(first_context, 0), np.append(first_context, 1)
X = np.array([x1, x2])
D = {action_id: X for action_id in self._action_storage.iterids()}
oracles = self.oracles
# 위에서 만든 가짜 데이터를 적합함
for index, action_id in enumerate(list(self._action_storage.iterids())):
oracle = oracles.estimators[index]
oracle.fit(D[action_id][:, :-1], D[action_id][:, -1])
self.D = D
self.oracles = oracles
def sample_from_beta(self, context):
"""
:param context: np.array (n_features, ), 고객 1명의 context 임
:return: history_id -- 저장 기록 index
recommendations -- 수행한 action 과 그 action 의 score 를 저장하는 class,
위에서 만든 RecommendationCls class 의 Instance 임
아래 loop 내의 코드는 Decision Tree 내부에 접근하는 과정을 다루고 있음
접근 방법 참고:
https://lovit.github.io/machine%20learning/2018/04/30/get_rules_from_trained_decision_tree/
"""
oracles = self.oracles
samples = []
# Prediction 을 위해 reshaping 을 해줌
context_vector = context.reshape(1, -1)
for i, action_id in enumerate(list(self._action_storage.iterids())):
oracle = oracles.estimators[i]
# 각 DT 모델에 context 를 투입하여 당도한 leaf node 의 index 를 얻음
leaf_index = oracle.apply(context_vector)[0]
# 해당 leaf node 의 n0, n1 값을 얻음
# n0: number of failure in the leaf node selected
# n1: number of success in the leaf node selected
n0 = oracle.tree_.value[leaf_index][0][0]
n1 = oracle.tree_.value[leaf_index][0][1]
# 이를 베타분포에 반영해주고, 여기서 sampling 을 진행함
sample = np.random.beta(a=1 + n1, b=1 + n0, size=1)
samples.append(sample)
# Sample 값 중 가장 높은 값을 갖는 Action 을 선택함
target = np.argmax(samples)
recommendation_id = list(self._action_storage.iterids())[target]
recommendations = self._recommendation_cls(
action=self._action_storage.get(recommendation_id),
score=np.max(samples)
)
history_id = self._history_storage.add_history(context, recommendations)
return history_id, recommendations
def update_D(self, action_id, context, reward):
"""
추천한 Action 의 결과로 받은 Reward 와 Context 를 결합하여 데이터 딕셔너리 D 업데이트를 진행 함
:param action_id: integer, D 에서 어떤 데이터를 업데이트할지 결정함
:param context: np.array (n_samples, ), 고객 1명의 context 임
:param reward: 실제 Reward -- 0 또는 1
"""
D = self.D
# new_data: context 와 reward 를 붙인 np.array
new_data = np.append(context, reward).reshape(1, -1)
# 해당 Action 의 데이터에 적재함
D[action_id] = np.append(D[action_id], new_data, axis=0)
self.D = D
def update_tree(self, action_id):
"""
해당 Action 에 소속된 Decision Tree 를 적합하여 업그레이드 함
:param action_id: integer
"""
D = self.D
oracles = self.oracles
action_index = list(self._action_storage.iterids()).index(action_id)
oracle = oracles.estimators[action_index]
oracle.fit(D[action_id][:, :-1], D[action_id][:, -1])
self.oracles = oracles
def reward(self, history_id, rewards):
"""
self._history_storage.unrewarded_histories 에 있는,
아직 Reward 를 받지 못한 기록들을 제거함
:param history_id: Integer, sample_from_beta 메서드의 output
:param rewards: Dictionary, {action_id : 0 or 1}
"""
self._history_storage.add_reward(history_id, rewards)
def add_action(self, actions):
"""
새로운 Action 이 추가되었을 때,
1) action_storage 를 업데이트하고
2) D 에 새로운 가짜 데이터를 적재하며
3) oracle 에 새로 추가된 Action 의 개수만큼 Decision Tree 를 추가하여
4) 앞서 만든 가짜 데이터에 적합함
:param actions: set of actions
"""
oracles = self.oracles
x = self.first_context
D = self.D
self._action_storage.add(actions)
num_new_actions = len(actions)
# 새롭게 정의된 Decision Tree 에 적합을 시작할 수 있게 기본 (가짜) 데이터셋을 넣어줌
# 이어서 새롭게 Decision Tree 들을 추가된 Action 의 개수 만큼 만들어준 이후
# 각 Action 에 매칭되는 Decision Tree 에 적합함
x1, x2 = np.append(x, 0), np.append(x, 1)
X = np.array([x1, x2])
new_trees = [DecisionTreeClassifier() for j in range(num_new_actions)]
for new_action_obj, new_tree in zip(actions, new_trees):
# 여기서 new_action_obj 는 Striatum 패키지의 기본 class 로 짜여 있어
# 그 class 의 attribute 인 id 를 불러와야 integer 인 action_id 를 쓸 수 있음
new_action_id = new_action_obj.id
D[new_action_id] = X
new_tree.fit(D[new_action_id][:, :-1], D[new_action_id][:, -1])
# 새로 적합한 Decision Tree 를 추가해 줌
oracles.estimators.append(new_tree)
self.oracles = oracles
self.D = D
def remove_action(self, action_id):
"""
이제는 필요 없어진 Action을 제거한다.
:param action_id: integer
"""
D = self.D
self._action_storage.remove(action_id)
del D[action_id]
self.D = D
# Preparation
def make_arm(arm_ids):
"""
선택할 수 있는 Action 의 리스트를 받아
Striatum 모듈의 Action Object 로 변환함
이 작업을 거쳐야 위 Action Object 들을 Tree Heuristic 과 같은 Contextual Bandit class 의
내부 Attribute 인 _action_storage 에 저장할 수 있음
:param arm_ids: list,
:return:
"""
arms = []
for arm_id in arm_ids:
arm = action.Action(arm_id)
arms.append(arm)
return arms
# Training: Movie Lens Data
def train_movielens(max_iter=163683, batch_size=100):
# 데이터 전처리 방법에 대해 알고자 한다면...
# 참고: https://striatum.readthedocs.io/en/latest/auto_examples/index.html#general-examples
streaming_batch = pd.read_csv('streaming_batch.csv', sep='\t', names=['user_id'], engine='c')
user_feature = pd.read_csv('user_feature.csv', sep='\t', header=0, index_col=0, engine='c')
arm_ids = list(pd.read_csv('actions.csv', sep='\t', header=0, engine='c')['movie_id'])
reward_list = pd.read_csv('reward_list.csv', sep='\t', header=0, engine='c')
streaming_batch = streaming_batch.iloc[0:max_iter]
# 아래 n_actions 인자에서 처음 시점에서의 Action 의 개수를 정의 함
th = TreeHeuristic(history.MemoryHistoryStorage(), model.MemoryModelStorage(),
action.MemoryActionStorage(), n_actions=50)
actions = make_arm(arm_ids=arm_ids)
reward_sum = 0
y = []
print("Starting Now...")
start = time.time()
for i in range(max_iter):
context = np.array(user_feature[user_feature.index == streaming_batch.iloc[i, 0]])[0]
if i == 0:
th.build(first_context=context, actions=actions)
history_id, recommendations = th.sample_from_beta(context=context)
watched_list = reward_list[reward_list['user_id'] == streaming_batch.iloc[i, 0]]
if recommendations.action.id not in list(watched_list['movie_id']):
# 잘 못 맞췄으면 0점을 얻음
th.reward(history_id, {recommendations.action.id: 0.0})
th.update_D(context=context, action_id=recommendations.action.id, reward=0.0)
else:
# 잘 맞춨으면 1점을 얻음
th.reward(history_id, {recommendations.action.id: 1.0})
th.update_D(context=context, action_id=recommendations.action.id, reward=1.0)
reward_sum += 1
if i % batch_size == 0 and i != 0:
for action_chosen in th._action_storage.iterids():
th.update_tree(action_id=action_chosen)
if i % 100 == 0:
print("Step: {} -- Average Reward: {}".format(i, np.round(reward_sum / (i+1), 4)))
y.append(reward_sum / (i + 1))
print("Time: {}".format(time.time() - start))
x = list(range(max_iter))
plt.figure()
plt.plot(x, y, c='r')
plt.title("Cumulative Average Reward of \n Tree Heuristic: Movie Lens Data")
plt.show()
# Training: Cover Type Data
def train_covtype(n_samples=581000, batch_size=3000):
file = pd.read_csv("covtype.data", header=None)
data = file.values
np.random.shuffle(data)
X, temp = data[:, 0:54], data[:, 54]
Y = pd.get_dummies(temp).values
actions = make_arm(list(range(7)))
th = TreeHeuristic(history.MemoryHistoryStorage(), model.MemoryModelStorage(),
action.MemoryActionStorage(), n_actions=7)
th.build(first_context=X[0], actions=actions)
reward_sum = 0
y = []
print("Starting Now...")
start = time.time()
for i in range(n_samples):
context = X[i]
history_id, recommendations = th.sample_from_beta(context=context)
# 실제 Reward 를 받고 이를 누적함
actual_reward = Y[i, recommendations.action.id]
reward_sum += actual_reward
th.reward(history_id, {recommendations.action.id: actual_reward})
# D는 매 trial 마다 업데이트해 주어야 함
th.update_D(context=context, action_id=recommendations.action.id, reward=actual_reward)
# batch size 만큼을 모아서 적합해줌
if i % batch_size == 0 and i != 0:
for action_chosen in th._action_storage.iterids():
th.update_tree(action_id=action_chosen)
# 로그는 100개 마다 찍음
if i % 100 == 0:
print("Step: {} -- Average Reward: {}".format(i, np.round(reward_sum / (i+1), 4)))
y.append(reward_sum/(i+1))
print("Time: {}".format(time.time() - start))
x = list(range(n_samples))
y[0] = 0
plt.figure()
plt.plot(x, y, c='r')
plt.title("Cumulative Average Reward Flow of \n Tree Heuristic: Cover type Data")
plt.show()
Test는 전통적으로 자주 애용되었던 Movielens 데이터와 Covtype 데이터로 진행할 수 있다. 아래 속도와 관련된 지표는 GPU가 없는 Laptop에 의한 것임을 밝혀둔다.
위 두 데이터의 경우, Tree Heuristic 알고리즘이 Lin UCB보다 우수한 성능을 보이는 것으로 확인되었다. 비록 Lin UCB보다는 속도 면에서 열위를 보이기는 하지만, Tree 구조에 기반한 모델이므로 해석에 있어 강점을 보일 수 있다는 점과 우수한 성능 때문에 충분히 기능할 수 있는 알고리즘으로 판단된다.
Test1: Covtype Data
| 알고리즘 | 10% Dataset (58,100) |
20% Dataset (116,200) |
50% Dataset (290,500) |
100% Dataset (581,000) |
비고 |
|---|---|---|---|---|---|
| Lin UCB | 0.7086 (23.66초) |
0.7126 (49.39초) |
0.7165 (137.19초) |
0.7180 (5분 39초) |
alpha=0.2 |
| Tree Heuristic | 0.7154 (100.65초) |
0.7688 (6분 48초) |
0.8261 (2463.70초) |
0.8626 (2시간 37분) |
3000 trial이 지날 때 마다 적합 |
Test2: Movielens Data
| 알고리즘 | 10% Dataset (16,400) |
20% Dataset (32,700) |
50% Dataset (81,800) |
100% Dataset (163,600) |
비고 |
|---|---|---|---|---|---|
| Lin UCB | 0.7521 | 0.7668 | 0.7746 | 0.7567 (6분 14초) |
alpha=0.2 |
| Tree Heuristic | 0.7683 | 0.8017 | 0.8183 | 0.8346 (33분 16초) |
100 trial이 지날 때 마다 적합 |