
Factorization Machines (FM) 설명 및 Tensorflow 구현
21 Dec 2019 | Machine_Learning Recommendation System Factorization Machines목차
본 글의 전반부에서는 먼저 Factorization Machines 논문을 리뷰하면서 본 모델에 대해 설명할 것이다. 후반부에서는 텐서플로를 활용하여 FM 모델을 구현해 볼 것이다. 논문의 전문은 이곳에서 확인할 수 있다.
1. Factorization Machines 논문 리뷰
1.0. Abstract
본 논문에서는 SVM과 Factorization model들의 장점을 결합한 FM이라는 새로운 모델을 소개한다. SVM과 마찬가지로 FM은 그 어떤 실수 값의 피쳐 벡터를 Input으로 받아도 잘 작동하는 일반적인 예측기이다. 그러나 SVM과 다르게 이 모델은 Factorized Parameter를 이용하여 모든 Interaction을 모델화하여 아주 희소한 상황에서도 Interaction들을 예측할 수 있다는 장점을 갖고 있다.
본 논문에서는 FM의 모델 방정식이 선형시간 내에서 계산되어 바로 최적화될 수 있음을 증명한다. 따라서 SVM과 달리 dual form에서의 변환(transformation)은 필요하지 않아 본 모델의 파라미터들은 해를 구할 때 Support 벡터의 도움 없이 바로 예측될 수 있다.
Matrix Factorization, SVD++, PITF, FPMC 등 다양한 모델들이 존재하는데, 이들은 오직 특정한 Input 데이터에서만 잘 작동한다는 한계를 지닌다. 반면 FM은 Input 데이터를 지정하여 이러한 모델을 따라할 수 있다. 따라서 Factorization 모델에 대한 전문적인 지식이 없더라도 FM은 사용하기에 있어 굉장히 쉽다.
1.1. Introduction
SVM은 유명한 예측 알고리즘이지만 협업 필터링과 같은 환경에서 SVM은 그리 중요한 역할을 하지 못한다. 본 논문에서는 SVM이 굉장히 희소한 데이터의 비선형적(complex) 커널 공간에서 reliable parameter(hyperplane: 초평면)를 학습할 수 없기 때문에 이러한 task에서 효과적이지 못함을 보여줄 것이다. 반면에 Tensor Factorization Model은 일반적인 예측 데이터에 대해서 그리 유용하지 않다는 단점을 가진다.
본 논문에서는 새로운 예측기인 FM을 소개할 것인데, 본 모델은 범용적인 예측 모델이지만 또한 매우 희소한 데이터 환경 속에서도 reliable parameter를 추정할 수 있다. FM은 모든 nested된 변수 간 상호작용을 모델화하지만 SVM이 Dense Parametrization을 사용하는 것과 달리 factorized parametrization을 사용한다.
FM의 모형식은 선형 시간으로 학습될 수 있으므로 파라미터들의 숫자에 따라 학습시간이 결정된다. 이는 SVM처럼 학습 데이터를 저장할 필요 없이 직접적인 최적화화 모델 파라미터의 저장을 가능하게 한다.
요약하자면 FM의 장점은 아래와 같다. 1) 굉장히 희소한 데이터에서도 파라미터 추정을 가능하게 한다. 2) 선형 complexity를 갖고 있기 때문에 primal하게 최적화될 수 있다. 3) 어떤 실수 피쳐 벡터를 Input으로 받아도 잘 작동한다.
1.2. Prediction under Sparsity
가장 일반적인 예측 문제는 실수 피쳐 벡터 x에서 Target domain T (1 또는 0)로 매핑하는 함수를 추정하는 것이다. 지도학습에서는 (x, y) 튜플이 stacked된 D라는 학습데이터셋이 존재한다고 가정된다. 우리는 또한 랭킹 문제에 대해 논의해볼 수 있는데, 이 때 함수 y는 피쳐 벡터 x에 점수를 매기고 이를 정렬하는데 사용된다. Scoring 함수는 pairwise한 학습 데이터로부터 학습될 수 있는데, 이 때 피쳐 튜플인 $ (x^(A), x^(B)) $는 $ x^(A) $가 $ x^(B) $보다 높은 순위를 지닌다는 것을 의미한다. pairwise 랭킹 관계가 비대칭적이기 때문에, 오직 positive 학습 instance만을 사용해도 충분하다.
본 논문에서 우리는 x가 매우 희소한 상황을 다룬다. 범주형 변수가 많을수록 더욱 데이터는 희소해지기 마련이다.
$m(x)$: 피쳐 벡터 x에서 0이 아닌 원소의 개수
$\overline{m}_D$: 학습 데이터셋 D에 속하는 모든 x에 대해 $m(x)$의 평균
Example 1
영화 평점 데이터를 갖고 있다고 하자. User $u \in U$가 영화(Item) $i \in I$를 특정 시점 $t \in \R$에 $r \in {1, 2, 3, 4, 5}$의 점수로 평점을 주었을 때 데이터는 아래와 같은 형상을 취할 것이다.
data S = {(Alice, Titanic, 2010-1, 5), (Bob, Star Wars, 2010-2, 3) … }
아래 그림은 이 문제 상황에서 S라는 데이터셋에서 어떻게 피쳐 벡터가 생성되는지를 보여준다.
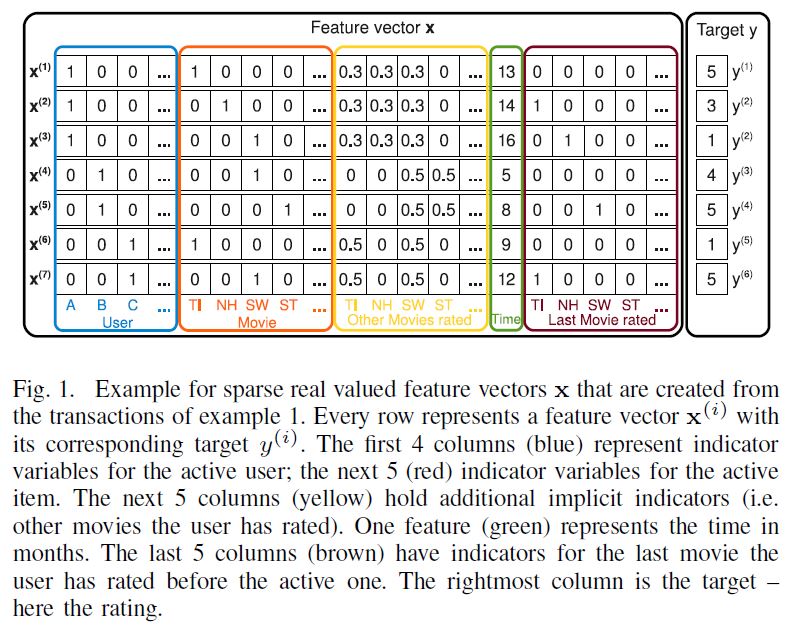
한 행에는 하나의 User, 하나의 Item이 들어가는 것을 확인할 수 있다. 모든 영화에 대한 평점 Matrix는 행의 합이 1이 되도록 Normalized되었다. 마지막 갈색 행렬은 주황색 행렬에서 확인한 active(가장 최근에 평점을 매긴)item 바로 이전에 평점을 매긴 Item이 무엇인지 알려주고 있다.
1.3. Factorizaion Machines 본문
A. Factorization Machine Model
2차 모델 방정식은 아래와 같다.

$V$ 내부의 행 $v_i$는 k개의 factor를 지닌 i번째 변수를 설명한다. k는 0을 포함한 자연수이며, factorization의 차원을 정의하는 하이퍼 파라미터이다. 2-way FM(2차수)은 변수간의 단일 예측변수와 결과변수 간의 상호작용 뿐 아니라 pairwise한(한 쌍의) 예측변수 조합과 결과변수 사이의 상호작용도 잡아낸다.
부가적으로 설명을 하면,
- $x_i$: X 데이터 셋의 하나의 행 벡터(feature vector)
- $w_0$: global bias
- $w_i$: i번째 변수의 영향력을 모델화 함
- $\hat{w}_{i, j}$ = $<v_i, v_j>$: i, j번째 변수간의 상호작용을 모델화 함
- $v$ 벡터: factor vector
FM 모델은 각 상호작용에 대해 $w_{i, j}$라는 모델 파라미터를 그대로 사용하는 것이 아니라, 이를 factorize하여 사용한다. 나중에 확인하겠지만, 이 부분이 희소한 데이터임에도 불구하고 고차원의 상호작용에 대한 훌륭한 파라미터 추정치를 산출할 수 있는 중요한 역할을 하게 된다.
k가 충분히 크면 positive definite 행렬 W에 대하여 $W = V \bullet V^t$을 만족시키는 행렬 $V$는 반드시 존재한다. 이는 FM모델이 k가 충분히 크면 어떠한 상호작용 행렬 $W$도 표현할 수 있음을 나타낸다. 그러나 sparse한 데이터 환경에서는, 복잡한 상호작용 W를 추정하기 위한 충분한 데이터가 없기에 작은 k를 선택할 수 밖에 없는 경우가 많다.

위 그림을 보면 알 수 있듯이, x벡터 하나당 1개의 예측 값을 산출하게 된다.
참고로, 본 논문에서는 위 그림의 p 대신 n이라고 적혀있는데, 이 p는 예측 변수의 수를 의미하기 때문에, 관례적으로 더 많이 쓰이는 p로 표기한 것이니 착오 없길 바란다.
Sparse한 환경에서, 일반적으로 변수들 간의 상호작용을 직접적이고 독립적으로 추정하기 위한 충분한 데이터가 없는 경우가 많다. FM은 이러한 환경에서도 상호작용들을 추정할 수 있는데, 이는 왜냐하면 이 모델은 상호작용 파라미터들을 factorize하여 상호작용 파라미터들 사이의 독립성을 깰 수 있기 때문이다.
일반적으로 이것은 하나의 상호작용을 위한 데이터가 다른 관계된 상호작용들의 파라미터들을 추정하는 데 도움을 준다는 것읠 의미한다.
앞서 언급했던 예를 들어보자,
Alice와 Star Trek 사이의 상호작용을 추정하여 영화평점(Target y)을 예측하고 싶다고 하자. 당연하게도 학습데이터에는 두 변수 $x_a$와 $x_{ST}$가 모두 0이 아닌 경우는 존재하지 않으므로, direct estimate $w_{A, ST}$는 0이 될 것이다.
그러나 factorized 상호작용 파라미터인 $<V_{A}, V_{ST}>$를 통해 우리는 상호작용을 측정할 수 있다. Bob과 Charlie는 모두 유사한 factor vector $V_B$, $V_C$를 가질 것인데, 이는 두 사람 모두 Star Wars ($V_{SW}$)와 관련하여 유사한 상호작용을 갖고 있기 때문이다. (취향이 비슷하다.) 즉, $<V_{B}, V_{SW}>$과 $<V_{C}, V_{SW}>$가 유사하다는 뜻이다.
Alice($V_A$)는 평점 예측에 있어서 Titanic과 Star Wars 두 factor와 상호작용이 다르기 때문에 Charlie와는 다른 factor vector를 가질 것이다. Bob은 Star Wars와 Star Trek에 대해 유사한 상호작용을 가졌기 때문에 Star Trek과 Star Wars의 factor vector는 유사할 가능성이 높다. 즉, Alice와 Star Treck의 factor vector의 내적은 Alice와 Star Wars의 factor vector의 내적 값과 매우 유사할 것이다. (직관적으로 말이 된다.)
이제 계산적 측면에서 모델을 바라볼 것이다. 앞서 확인한 방정식의 계산 복잡성은 $O(kp^2)$이지만, 이를 다시 변형하여 선형적으로 계산 시간을 줄일 수 있다. pairwise 상호작용 부분은 아래와 같이 재표현할 수 있다.
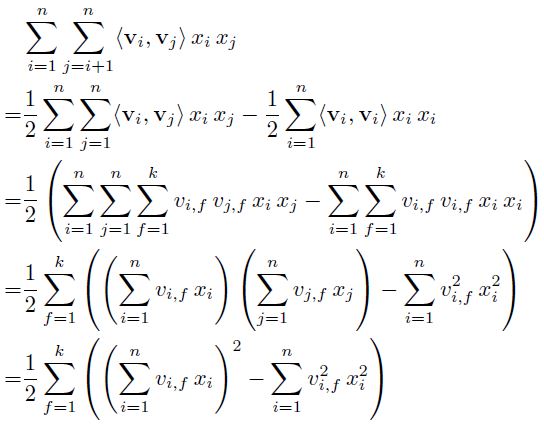
이 부분이 굉장히 중요한데, 실제로 코드로 구현할 때 이와 같은 재표현 방식이 없다면 굉장히 난감한 상황에 맞닥드리게 될 것이다.
또한 x의 대부분의 원소가 0이므로 실제로는 0이 아닌 원소들에 대해서만 계산이 수행된다.
B. Factorizaion Machine as Predictors
FM은 회귀, 이항 분류, 랭킹 문제를 풀기 위해 활용될 수 있다. 그리고 이 모든 문제에서 L2 정규화 항은 과대적합을 막기 위해 추가된다.
C. Learning Factorizatino Machines
앞서 확인한 것처럼, FM은 선형적으로 계산되는 모델 방정식을 지니고 있다. 따라서 $w_0, w, V$와 같은 모델 파라미터들은 Gradient Descent 방법을 통해 효과적으로 학습될 수 있다. FM 모델의 Gradient는 아래와 같이 표현될 수 있다.
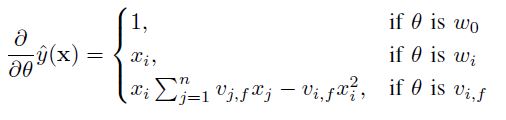
$\sum_{j=1}^n v_{j, f} x_j$는 i에 대해 독립적이기 때문에 우선적으로 미리 계산될 수 있다. 일반적으로 각각의 Gradient는 상수적 시간 O(1)만에 계산될 수 있다. 그리고 (x, y)를 위한 모든 파라미터 업데이터는 희소한 환경에서 $O(kp)$ 안에 이루어질 수 있다.
우리는 element-wise하거나 pairwise한 Loss를 계산하기 위해 SGD를 사용하는 일반적인 implementation인 LIBFM2를 제공한다.
D. d-way Factorizatino Machine
2-way FM은 쉽게 d-way FM으로 확장할 수 있다.
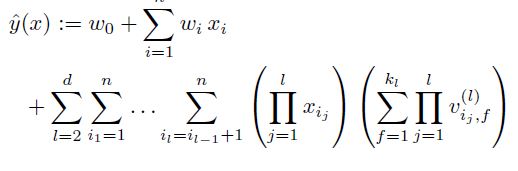
E. Summary
FM 모델은 모든 상호작용을 있는 그대로 사용하는 것이 아니라 factorized 상호작용을 이용하여 피쳐 벡터 x의 값 사이에 있는 가능한 상호작용들을 모델화한다. 이러한 방식은 2가지 장점을 지닌다.
1) 아무리 희소한 환경에서도 값들 사이의 상호작용을 추정할 수 있다. 또한 이는 관측되지 않은 상호작용을 일반화하는 것도 가능하게 한다.
2) 학습 및 예측에 소요되는 시간이 선형적이고, 이에 따라 파라미터의 수도 선형적이다. 이는 SGD를 이용하여 다양한 Loss Function들을 최적화하는 것을 가능하게 한다.
(후략)
2. Tensorflow를 활용한 구현
2.1. 준비
# FM
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.metrics import BinaryAccuracy
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
# GPU 확인
tf.config.list_physical_devices('GPU')
# 자료형 선언
tf.keras.backend.set_floatx('float32')
# 데이터 로드
scaler = MinMaxScaler()
file = load_breast_cancer()
X, Y = file['data'], file['target']
X = scaler.fit_transform(X)
n = X.shape[0]
p = X.shape[1]
k = 10
batch_size = 8
epochs = 10
데이터는 sklearn에 내장되어 있는 breast_cancer 데이터를 사용하였다. 30개의 변수를 바탕으로 암 발생 여부를 예측하는 데이터이다. p는 예측 변수의 개수이고, k는 잠재 변수의 개수이다.
2.2. FM 모델 선언
class FM(tf.keras.Model):
def __init__(self):
super(FM, self).__init__()
# 모델의 파라미터 정의
self.w_0 = tf.Variable([0.0])
self.w = tf.Variable(tf.zeros([p]))
self.V = tf.Variable(tf.random.normal(shape=(p, k)))
def call(self, inputs):
linear_terms = tf.reduce_sum(tf.math.multiply(self.w, inputs), axis=1)
interactions = 0.5 * tf.reduce_sum(
tf.math.pow(tf.matmul(inputs, self.V), 2)
- tf.matmul(tf.math.pow(inputs, 2), tf.math.pow(self.V, 2)),
1,
keepdims=False
)
y_hat = tf.math.sigmoid(self.w_0 + linear_terms + interactions)
return y_hat
모델 자체는 아주 복잡할 것은 없다. linear terms와 interactions라고 정의한 부분이 아래 수식의 밑줄 친 부분에 해당한다.
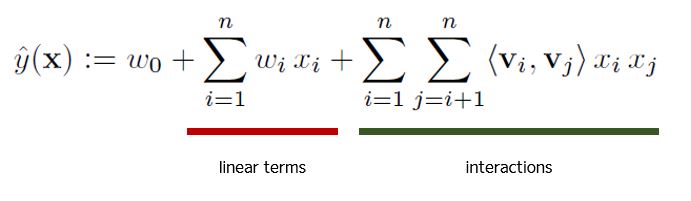
interactions 부분이 아주 중요한데, 이 부분을 어떻게 구현하느냐가 속도의 차이를 만들어 낼 수 있기 때문이다. 논문에서는 아래와 같이 이 상호작용 항을 재표현할 수 있다고 하였다.
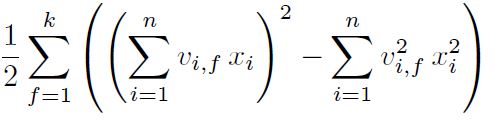
위 interactions 부분은 위 식을 코드로 표현한 것인데, $\sum$ 항을 벡터화 하여 구현하였다.
설명을 위해, (k=2, p=3) shape을 가진 $V$ 행렬과 (p=3, 1)의 shape을 가진 $x$ 벡터가 있다고 하자. 사실 $(\sum_{i=1}^n v_{i,f } x_i)^2$ 부분을 계산하면 $V^T x$의 모든 원소를 더한 것과 동일하다.
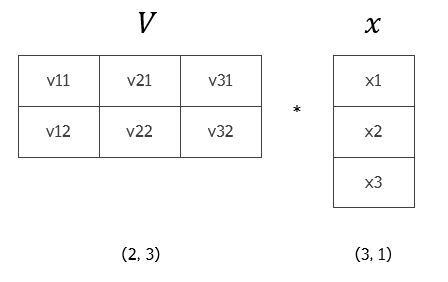
위 그림의 결과는 $(v_{11}x_1 + v_{21}x_2 + v_{31}x_3)^2 + (v_{12}x_1 + v_{22}x_2 + v_{32}x_3)^2$와 동일할 것이다. 식의 나머지 부분도 같은 방법으로 생각하면 위와 같은 코드로 표현할 수 있을 것이다.
2.1.3. 학습 코드
# Forward
def train_on_batch(model, optimizer, accuracy, inputs, targets):
with tf.GradientTape() as tape:
y_pred = model(inputs)
loss = tf.keras.losses.binary_crossentropy(from_logits=False,
y_true=targets,
y_pred=y_pred)
# loss를 모델의 파라미터로 편미분하여 gradients를 구한다.
grads = tape.gradient(target=loss, sources=model.trainable_variables)
# apply_gradients()를 통해 processed gradients를 적용한다.
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# accuracy: update할 때마다 정확도는 누적되어 계산된다.
accuracy.update_state(targets, y_pred)
return loss
# 반복 학습 함수
def train(epochs):
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, stratify=Y)
train_ds = tf.data.Dataset.from_tensor_slices(
(tf.cast(X_train, tf.float32), tf.cast(Y_train, tf.float32))).shuffle(500).batch(8)
test_ds = tf.data.Dataset.from_tensor_slices(
(tf.cast(X_test, tf.float32), tf.cast(Y_test, tf.float32))).shuffle(200).batch(8)
model = FM()
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
accuracy = BinaryAccuracy(threshold=0.5)
loss_history = []
for i in range(epochs):
for x, y in train_ds:
loss = train_on_batch(model, optimizer, accuracy, x, y)
loss_history.append(loss)
if i % 2== 0:
print("스텝 {:03d}에서 누적 평균 손실: {:.4f}".format(i, np.mean(loss_history)))
print("스텝 {:03d}에서 누적 정확도: {:.4f}".format(i, accuracy.result().numpy()))
test_accuracy = BinaryAccuracy(threshold=0.5)
for x, y in test_ds:
y_pred = model(x)
test_accuracy.update_state(y, y_pred)
print("테스트 정확도: {:.4f}".format(test_accuracy.result().numpy()))
epochs = 50으로 실행한 결과는 아래와 같다.
스텝 000에서 누적 평균 손실: 1.2317
스텝 000에서 누적 train 정확도: 0.5692
스텝 002에서 누적 평균 손실: 0.9909
스텝 002에서 누적 train 정확도: 0.6271
...
스텝 048에서 누적 평균 손실: 0.2996
스텝 048에서 누적 train 정확도: 0.8996
테스트 정확도: 0.9500
Reference
http://nowave.it/factorization-machines-with-tensorflow.html