
Field-aware Factorization Machines (FFM) 설명 및 xlearn 실습
05 Apr 2020 | Machine_Learning Recommendation System Field-aware Factorization Machines목차
본 글의 전반부에서는 먼저 Field-aware Factorization Machines for CTR prediction 논문을 리뷰하면서 본 모델에 대해 설명할 것이다. 후반부에서는 간단한 xlearn코드 역시 소개할 예정이다. 논문의 전문은 이곳에서 확인할 수 있다.
1. Field-aware Factorization Machines for CTR prediction 논문 리뷰
1.0.Abstract
CTR 예측과 같은 크고 희소한 데이터셋에 대해 FFM은 효과적인 방법이다. 본 논문에서는 우리는 FFM을 학습시키는 효과적인 구현 방법을 제시할 것이다. 그리고 우리는 이 모델을 전체적으로 분석한 뒤 다른 경쟁 모델과 비교를 진행할 것이다. 실험에 따르면 FFM이 특정 분류 모델에 있어서 굉장히 뛰어난 접근 방법이라는 것을 알려준다. 마지막으로, 우리는 FFM 패키지를 공개한다.
1.1. Introduction
CTR 예측에 있어서 굉장히 중요한 것은, feature 간의 conjunction(결합, 연결)을 이해하는 것이다. Simple Logistic Regression과 같은 간단한 모델은 이러한 결합을 잘 이해하지 못한다. FM 모델은 2개의 Latent Vector의 곱으로 factorize하여 feature conjunction을 이해하게 된다.
개인화된 태그 추천을 위해 pairwise interaction tensor factorization (PITF)라는 FM의 변형 모델이 제안되었다. 이후 KDD Cup 2020에서, Team Opera Solutions라는 팀이 이 모델의 일반화된 버전을 제안하였다. 그러나 이 용어는 다소 일반적이고 혼동을 줄 수 있는 이름이므로, 본 논문에서는 이를 FFM이라고 부르도록 하겠다.
FFM의 중요 특징은 아래와 같다.
- 최적화 문제를 해결하기 위해 Stochastic Gradient를 사용한다. 과적합을 막기 위해 오직 1 epoch만 학습한다.
- FFM은 위 팀에서 비교한 모델 6개 중 가장 뛰어난 성적을 보여주었다.
1.2. POLY2 and FM
(중략)
1.3. FFM
FFM의 중요한 아이디어는 PITF로 부터 파생되었는데, 이는 바로 개인화된 태그에 관한 것이다. PIFT에서 그들은 User, Item, Tag를 포함한 3개의 가용 필드를 가정했고, 이를 분리된 latent space에서 (User, Item), (User, Tag), (Item,Tag)로 factorize하였다. 이러한 정의는 추천 시스템에 적합한 정의이고 CTR 예측에 있어서는 자세한 설명이 부족한 편이므로, 좀 더 포괄적인 논의를 진행해보도록 하겠다.
아래와 같은 데이터 테이블이 있을 때, features는 fields로 그룹화할 수 있다.
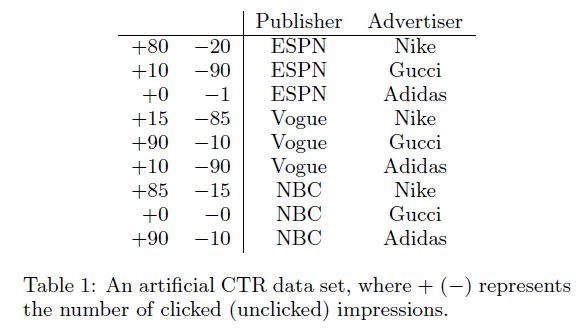
예를 들어, Espn, Vogue, NBC는 Publisher라는 field에 속할 수 있겠다. FFM은 이러한 정보를 활용하는 FM의 변형된 버전이다. FFM의 원리를 설명하기 위해, 다음 새로운 예시에 대해 생각해보자.
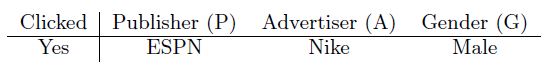
FM의 상호작용 항인 $\phi_{FM}(w, x)$는 아래와 같이 표현될 수 있다.
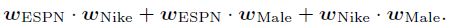
FM에서는 다른 feature들과의 latent effect를 학습하기 위해 모든 feature는 오직 하나의 latent vector를 가진다. Espn을 예로 들어보면, $w_{Espn}$은 Nike와 Male과의 latent effect를 학습하기 위해 이용되었다. 그러나 Nike와 Male은 다른 Field에 속하기 때문에 사실 (Espn, Nike)의 관계와 (Espn, Male)의 관계에서 사용되었던 $w_{Espn}$의 값은 다를 가능성이 높다. 즉, 하나의 벡터로 2개의 관계를 모두 표현하기에는 무리가 있다는 점이다.
FFM에서는 각각의 feature는 여러 latent vector를 갖게 된다. FFM의 상호작용 항인 $\phi_{FFM}(w, x)$은 아래와 같이 표현된다.
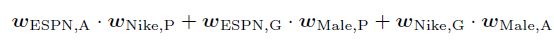
수학적으로 재표현하면 아래와 같이 표현할 수 있겠다.
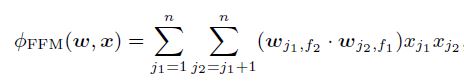
여기서 $f_1$과 $f_2$는 $j_1$과 $j_2$의 field를 의미한다. $j$들은 Espn, Nike 등을 의미한다. $f$를 field의 개수라고 할 때, FFM의 변수의 개수는 $nfk$이며, FFM의 계산 복잡성은 $O(\overline{n}^2 k)$이다.
여기서 n, f, k는 각각 feature의 개수(often called p), field의 개수, latent 변수의 개수를 의미한다.
FFM의 경우 각각의 latent vector아 오직 특정 field와 관련한 효과에 대해서는 학습을 진행하기 때문에 잠재 변수의 수은 $k$는 FM의 경우보다 작은 경우가 많다.
\[k_{FFM} < k_{FM}\]1.3.1. Solving the Optimization Problem
사실 FFM의 최적화 문제를 푸는 것은 Simple Logistic Regression의 최적화 문제를 푸는 식에서 $\phi_{LM}(w, x)$를 $\phi_{FFM}(w, x)$로 바꾸는 것을 제외하면 동일하다.
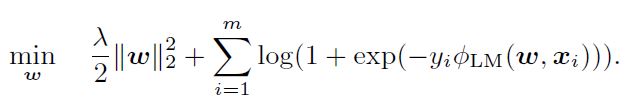
실험 결과에 그 이유가 나오지만, Stochastic Gradient 알고리즘으로 행렬 분해에 있어 효과적인 AdaGrad를 적용하였다. 각 SG 스텝마다 data point $(y, x)$는 $\phi_{FFM}(w, x)$ 식에서 $w_{j1, f2}, w_{j2f1}$를 업데이트하기 위해 추출된다. CTR prediction과 같은 문제를 푸는 데에 있어 $x$는 굉장히 희소한 벡터임을 기억하자. 따라서 실제로는 0이 아닌 값들에 대해서만 업데이트가 진행될 것이다.
sub-gradient는 아래와 같다.
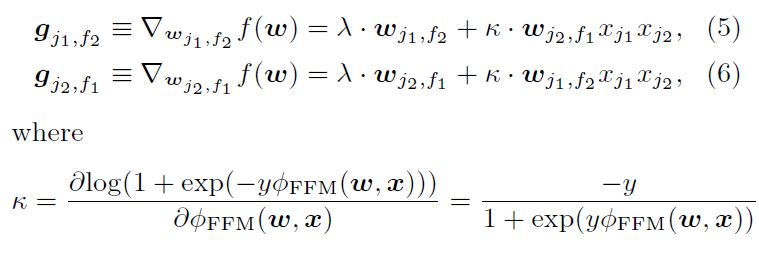
d=1…k에 대해 gradient의 제곱합은 아래와 같이 합산된다.
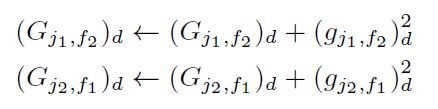
최종적으로 $(w_{j1, f2})d$과 $(w{j2, f1})_d$ 는 아래와 같이 업데이트 된다.
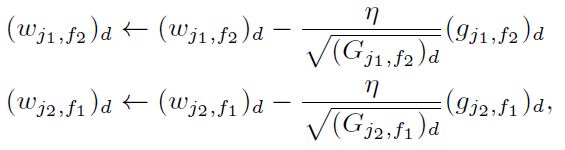
여기서 $\eta$는 직접 정한 learning rate를 의미한다. $w$의 초깃값은 $[0, 1/\sqrt{k}]$ 사이의 Uniform Distribution 에서의 랜덤한 값으로 초기화된다. $G$는 $(G_{j1, f2})_d^{-\frac{1}{2}}$의 값이 매우 커지는 것을 막기 위해 모두 1로 세팅된다. 전체적인 과정은 아래와 같으며, 각 instance를 normalize해주는 것이 성능 향상에 도움이 되었다는 말을 남긴다.

1.3.2. Parallelization on Shared-memory Systems
본 논문에서는 Hog-WILD!라는 병렬처리 기법을 사용하였다.
1.3.3. Adding Field Information
널리 사용되는 LIBSVM의 데이터 포맷은 다음과 같다.
label feat1:val1 feat2:val2 …
여기서 각 (feat, val) 쌍은 feature index와 value를 의미한다. FFM을 위해 우리는 위 포맷을 아래와 같이 확장할 수 있다.
label field1:feat1:val1 field2:feat2:val2 …
이는 적합한 field를 각 feature 마다 지정해주어야 함을 의미한다. 특정 feature에 대해서는 이 지정 작업이 쉽지만, 나머지들에 대해서는 그렇지 않을 수도 있다. 이 부분에 대해서는 feature의 3가지 종류의 관점에서 논의해보도록 하자.
Categorical Features
선형 모델에서 categorical feature는 여러 개의 binary feature로 변환하는 것이 일반적이다. 우리는 다음과 같이 데이터 instance를 변형할 수 있다.

LIBSVM 포맷에서는 0의 값은 저장되지 않기 때문에 이렇게 모든 categorical feature들을 binary feature로 변형할 수 있는 것이다. 이제 위 데이터는 최종적으로 아래와 같은 형상을 갖게 된다.
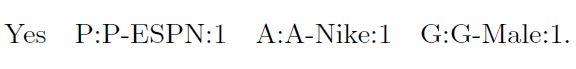
Numerical Features
conference에서 논문이 통과될지에 대한 데이터가 있다고 하자. 칼럼의 의미는 아래와 같다.
- AR: accept rate of the conference
- Hidx: h-index of the author
- Cite: # citations of the author
각 feature를 dummy field로 취급하여 아래와 같은 데이터 형상을 만들 수도 있지만, 이는 딱히 도움이 되지 않는 방법 같다.
Yes AR:AR:45.73 Hidx:Hidx:2 Cite:Cite:3
또 하나의 방법은, feature는 field에 넣고, 기존의 실수 값을 이산화하여 feature로 만든 후, binary하게 1과 0의 값을 넣어주는 방식이다.
Yes AR:45:1 Hidx:2:1 Cite:3:1
이산화 방법에 대해서는 여러가지 방식이 존재할 수 있다. 어떠한 방법이든 일정 수준의 정보 손실은 감수해야 한다.
Single-field Features
일부 데이터 셋에 대해서 모든 feature가 단일 field에 속하여 각 feature에 대해 field를 지정해주는 것이 무의미한 경우도 있다. 특히 NLP와 같은 분야에서는 이러한 현상이 두드러진다.

위 경우에서 유일한 field는 “sentence”가 될 것이다. 일부 사람들은 numerical features의 경우처럼 dummy field를 만들면 어떨까 하고 의문을 가지지만, 사실 그렇게 되면 n(feature의 수)이 너무 커지기 때문에 굉장히 비효율적이다.
(FFM의 모델 크기가 $O(nfk)$임을 기억해보자. 이 경우에는 $f=n$이 될 것이다. (field의 수 = feature의 수))
1.4. Experiments
(후략)
2. xlearn
2.1. 설치
여러 가지 방법으로 설치를 진행할 수 있지만, 여기에서 whl파일을 통해 설치하는 것이 가장 간단하다.
2.2. 코드
def _convert_to_ffm(path, df, type, target, numerics, categories, features, encoder):
# Flagging categorical and numerical fields
print('convert_to_ffm - START')
for x in numerics:
if(x not in encoder['catdict']):
print(f'UPDATING CATDICT: numeric field - {x}')
encoder['catdict'][x] = 0
for x in categories:
if(x not in encoder['catdict']):
print(f'UPDATING CATDICT: categorical field - {x}')
encoder['catdict'][x] = 1
nrows = df.shape[0]
with open(path + str(type) + "_ffm.txt", "w") as text_file:
# Looping over rows to convert each row to libffm format
for n, r in enumerate(range(nrows)):
datastring = ""
datarow = df.iloc[r].to_dict()
datastring += str(int(datarow[target])) # Set Target Variable here
# For numerical fields, we are creating a dummy field here
for i, x in enumerate(encoder['catdict'].keys()):
if(encoder['catdict'][x] == 0):
# Not adding numerical values that are nan
if math.isnan(datarow[x]) is not True:
datastring = datastring + " "+str(i)+":" + str(i)+":" + str(datarow[x])
else:
# For a new field appearing in a training example
if(x not in encoder['catcodes']):
print(f'UPDATING CATCODES: categorical field - {x}')
encoder['catcodes'][x] = {}
encoder['currentcode'] += 1
print(f'UPDATING CATCODES: categorical value for field {x} - {datarow[x]}')
encoder['catcodes'][x][datarow[x]] = encoder['currentcode'] # encoding the feature
# For already encoded fields
elif(datarow[x] not in encoder['catcodes'][x]):
encoder['currentcode'] += 1
print(f'UPDATING CATCODES: categorical value for field {x} - {datarow[x]}')
encoder['catcodes'][x][datarow[x]] = encoder['currentcode'] # encoding the feature
code = encoder['catcodes'][x][datarow[x]]
datastring = datastring + " "+str(i)+":" + str(int(code))+":1"
datastring += '\n'
text_file.write(datastring)
# print('Encoder Summary:')
# print(json.dumps(encoder, indent=4))
return encoder
위와 같이 LIBSVM 데이터 포맷으로 데이터를 변경한 후에,
import xlearn as xl
model = xl.create_ffm()
# 학습/테스트 데이터 path 연결
model.setTrain("data/train_ffm.txt")
model.setValidate("data/test_ffm.txt")
# Early Stopping 불가
model.disableEarlyStop()
# param 선언
param = {'task': 'binary', 'lr': 0.2, 'lambda': 0.00002,
'k': 3, 'epoch': 100, 'metric': 'auc', 'opt': 'adagrad',
'num_threads': 4}
# 학습
# model.fit(param=param, model_path="model/model.out")
# Cross-Validation 학습
model.cv(param)
# Predict
model.setTest("data/test_ffm.txt")
model.setSigmoid()
model.predict("model/model.out", "output/predictions.txt")
위와 같이 학습을 진행하면 된다. 간단하다.
Reference
https://wngaw.github.io/field-aware-factorization-machines-with-xlearn/