
LightFM 설명
01 Jun 2020 | Machine_Learning Recommendation System Paper_Review목차
- 1. Metadata Embeddings for User and Item Cold-start Recommendations 논문 리뷰
- 2. LightFM 학습 및 HyperOpt를 활용한 Bayesian Optimization
- Reference
본 글에서는 2015년에 Lyst에서 발표한 Hybrid Matrix Factorization Model인 LightFM에 관한 내용을 다룰 것이며 순서는 아래와 같다.
1) 논문 요약 리뷰
2) LightFM 라이브러리 사용법 소개
3) HyperOpt를 이용한 Hyperparameter 튜닝법 소개
1. Metadata Embeddings for User and Item Cold-start Recommendations 논문 리뷰
1.1. Introduction
cold-start 상황에서 추천 시스템을 만드는 것은 아직까지도 쉽지 않은 일이다. 기본적인 행렬 분해(Matrix Factorization) 기법들은 이러한 상황에서 형편 없는 성능을 보여준다. 왜냐하면 Collaborative Interaction 데이터가 희소할 때는 User와 Item의 잠재 벡터를 효과적으로 추정하는 일이 굉장히 어렵기 때문이다.
Content-based 방법은 메타데이터를 통해 Item이나 User를 표현(Represent)한다. 이러한 정보는 미리 알고 있기 때문에 Collaborative 데이터가 존재하지 않아도 추천 로직은 성립할 수 있다. 그러나 이러한 모델에서는 Transfer Learning은 불가능하다. 왜냐하면 각 User는 독립적으로 추정되기 때문이다. 결과적으로 CB 모델은 Collaborative 데이터가 이용 가능하고 각 User에 대해 많은 양의 데이터를 필요로 할 때, 기존 행렬 분해 모델보다 더 안좋은 성능을 보인다.
패션 온라인 몰인 Lyst에서는 이러한 문제를 해결하는 것이 매우 중요했다. 매일 같이 수만 개의 상품이 등록되고, 웹 상에는 800만 개가 넘는 패션 아이템이 등록되어 있었기 때문이다. 많은 Item, 새로운 상품의 잦은 등록(Cold-Start), 고객의 다수가 신규 고객(Cold-Start)라는 3가지의 어려운 조건 속에서, 본 논문은 LightFM이라는 Hybrid형 모델을 제시한다.
본 모델은 Content-based와 Collaborative Filtering의 장점을 결합하였다. 본 모델의 가장 중요한 특징은 아래와 같다.
1) 학습데이터에서 Collaborative 데이터와 User/Item Feature를 모두 사용한다.
2) LightFM에서 생성된 Embedding 벡터는 feature에 대한 중요한 의미 정보를 포함하고 있고, 이는 tag 추천과 같은 일에서 중요하게 사용될 수 있다.
1.2. LightFM
모델 구성 자체는 어렵지 않다. 가장 특징적인 것은 기존의 Classic한 행렬 분해 모델들과 다르게, User Feature와 Item Feature를 학습 과정에 포함하는 데에 적합한 구조로 만들어져 있다는 것이다.
잠시 기호에 대해 설명하겠다.
| 기호 | 설명 |
|---|---|
| $U$ | User의 집합 |
| $I$ | Item의 집합 |
| $F^U$ | User Feature의 집합 |
| $F^I$ | Item Feature의 집합 |
| $f_u$ | $u$라는 User의 features, $f_u \subset F^U$ |
| $f_i$ | $i$라는 Item의 features, $f_i \subset F^I$ |
| $e_f^U$ | $f_u$의 각 User feature들에 대한 d-차원 Embedding 벡터 |
| $e_f^I$ | $f_i$의 각 Item feature들에 대한 d-차원 Embedding 벡터 |
| $b_f^U$ | $u$라는 User의 features, $f_u \subset F^U$ |
| $b_f^I$ | $i$라는 Item의 features, $f_i \subset F^I$ |
User $u$에 대한 잠재 벡터는 그 User의 Features의 잠재 벡터들의 합으로 구성되며, Item 또한 같은 방식으로 계산한다. Bias 항 또한 아래와 같이 계산된다.
\(q_u = \sum_{j \in f_u}e_j^U\) \(p_i = \sum_{j \in f_i}e_j^I\) \(b_u = \sum_{j \in f_u}b_j^U\) \(b_i = \sum_{j \in f_i}b_j^I\)
User $i$와 Item $i$에 대한 모델의 예측 값은, 이 User와 Item의 Representation(잠재 벡터)의 내적으로 이루어진다.
\[\hat{r}_{ui} = sigmoid(q_u \odot p_i + b_u + b_i)\]최적화 목적함수는 parameter들이 주어졌을 때의 데이터에 대한 우도를 최대화 하는 것으로 설정된다. 이는 아래와 같다.
\[L(e^U, e^I, b^U, b^I) = \prod_{(u,i) \in S^+} \hat{r}_{ui} \times \prod_{(u,i) \in S^-} (1- \hat{r}_{ui})\]여기서 $S^+$는 Positive Interaction, $S^-$는 Negative Interaction을 가리킨다.
이 식들만 봐서는 모델의 구조에 대해 완벽히 이해를 하지 못할 수도 있다. 아래 그림을 보면 이해가 될 것이다.
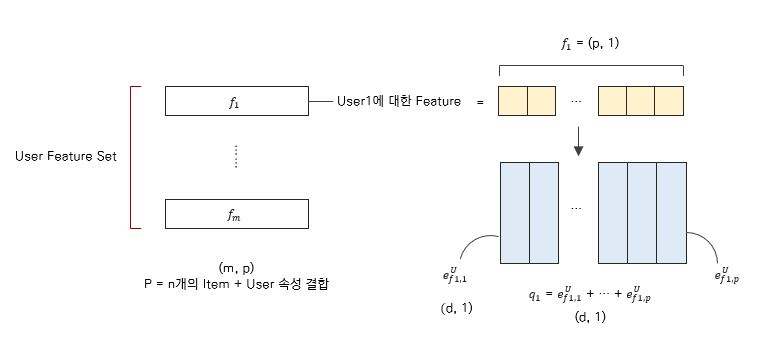
위 그림의 경우, User Feature를 예시로 든 것이고, Item Feature에 대해서도 같은 논리가 적용된다. $m$은 User의 수이다.
지금까지 논문에서 소개된 모델에 대해 알아보았다. Experiment 부분은 직접 읽어보도록 하고, 이제는 코드로 넘어가도록 하겠다.
2. LightFM 학습 및 HyperOpt를 활용한 Bayesian Optimization
2.1. Data Preparation
학습에 사용될 데이터는 Goodbook 데이터이다. 이 데이터셋에는 여러 독자(User)가 책(Item)에 대해 평점을 남긴 데이터이다. 사실 Implicit Feedback이 아닌 Explicit Feedback이기에 학습이 더욱 쉬울 수는 있지만, 그 부분은 잠시 접어두기로 하자. 데이터는 이곳에서 직접 다운로드할 수 있다.
학습에 사용한 파일은 ratings.csv와 books.csv인데, 아래와 같은 형상을 지녔다.
# ratings.csv
user_id book_id rating
0 1 258 5
1 2 4081 4
2 2 260 5
3 2 9296 5
4 2 2318 3
# books.csv
book_id authors average_rating original_title
0 1 Suzanne Collins 4.34 The Hunger Games
1 2 J.K. Rowling, Mary GrandPré 4.44 Harry Potter ...
2 3 Stephenie Meyer 3.57 Twilight
3 4 Harper Lee 4.25 To Kill a Mockingbird
4 5 F. Scott Fitzgerald 3.89 The Great Gatsby
이 데이터를 그대로 LightFM에 Input으로 넣을 수는 없다. 다소 귀찮은 전처리 과정을 거쳐야 한다.
import pandas as pd
from lightfm.data import Dataset
from scipy.io import mmwrite
# Data Load
# ratings_source: build_interactions 재료, list of tuples
# --> [(user1, item1), (user2, item5), ... ]
# item_features_source: build_item_features 재료
# --> [(item1, [feature, feature, ...]), (item2, [feature, feature, ...])]
ratings = pd.read_csv('data/ratings.csv')
ratings_source = [(ratings['user_id'][i], ratings['book_id'][i]) for i in range(ratings.shape[0])]
item_meta = pd.read_csv('data/books.csv')
item_meta = item_meta[['book_id', 'authors', 'average_rating', 'original_title']]
item_features_source = [(item_meta['book_id'][i],
[item_meta['authors'][i],
item_meta['average_rating'][i]]) for i in range(item_meta.shape[0])]
코드를 보면 알 수 있겠지만, ratings_souce와 item_features_source라는 iterable 객체가 필요하다. 먼저 전자는 LightFM Dataset clss의 build_interactions 메서드의 재료로 활용되며, 후자의 경우 build_item_features의 재료가 된다. 본 학습에서는 User Feature를 따로 사용하지는 않았지만, Item Feature와 사용법이 동일하니, 참고해두면 되겠다.
이렇게 재료가 준비가 되었으면 LightFM의 Dataset 클래스를 불러온 후, fit을 해준다.
dataset = Dataset()
dataset.fit(users=ratings['user_id'].unique(),
items=ratings['book_id'].unique(),
item_features=item_meta[item_meta.columns[1:]].values.flatten()
)
여기서 중요한 것은, 이 때 argument로 들어가는 객체에 결측값은 없어야 한다는 것이다.
이후 build를 해주면 데이터셋은 완성되었다.
interactions, weights = dataset.build_interactions(ratings_source)
item_features = dataset.build_item_features(item_features_source)
# Save
mmwrite('data/interactions.mtx', interactions)
mmwrite('data/item_features.mtx', item_features)
mmwrite('data/weights.mtx', weights)
# Split Train, Test data
train, test = random_train_test_split(interactions, test_percentage=0.1)
train, test = train.tocsr().tocoo(), test.tocsr().tocoo()
train_weights = train.multiply(weights).tocoo()
2.2. Hyper Parameter Optimization with HyperOpt
hyperopt는 꽤 오래 전부터 사용되던 Hyper Parameter 최적화 라이브러리이다. skopt도 널리 사용되고 있지만, 앞으로 업데이트가 계속 진행될 지 확실하지 않으므로… 본 글에서는 hyperopt를 소개하도록 하겠다.
먼저 Search Space를 정의해 주어야 한다.
from hyperopt import fmin, hp, tpe, Trials
# Define Search Space
trials = Trials()
space = [hp.choice('no_components', range(10, 50, 10)),
hp.uniform('learning_rate', 0.01, 0.05)]
자세한 정보는 이곳에서 확인할 수 있다. space는 아래에서 소개할 objective 함수의 argument로 활용된다. space는 반드시 리스트로 작성할 필요는 없고, 필요에 따라 Dictionary나 OrderedDict 같은 객체를 사용해주면 좋다.
다음으로는 목적 함수를 정의해보자.
# Define Objective Function
def objective(params):
no_components, learning_rate = params
model = LightFM(no_components=no_components,
learning_schedule='adagrad',
loss='warp',
learning_rate=learning_rate,
random_state=0)
model.fit(interactions=train,
item_features=item_features,
sample_weight=train_weights,
epochs=3,
verbose=False)
test_precision = precision_at_k(model, test, k=5, item_features=item_features).mean()
print("no_comp: {}, lrn_rate: {:.5f}, precision: {:.5f}".format(
no_components, learning_rate, test_precision))
# test_auc = auc_score(model, test, item_features=item_features).mean()
output = -test_precision
if np.abs(output+1) < 0.01 or output < -1.0:
output = 0.0
return output
일반적으로 위 함수의 반환 값은 loss가 되는데, 본 모델의 경우 loss를 직접 반환하는 메서드가 존재하지 않기 때문에 evaluation metric을 불러온 후, 이를 음수화하는 작업을 거쳤다.
이제는 fmin 함수를 불러와서 최적화 작업을 진행해보자.
max_evals 인자는 최대 몇 번 모델 적합을 진행할 것인가를 결정하며, timeout 인자를 투입할 경우 최대 search 시간을 제한할 수도 있다. best_params는 가장 좋은 Hyperparameter 조합에 관한 정보를 담은 Dictionary이다.
best_params = fmin(fn=objective, space=space, algo=tpe.suggest, max_evals=10, trials=trials)
2.3. 결과 확인
학습만 하고 끝낼 수는 없다. 학습이 끝난 모델을 활용하여 유사한 책(Item)에 대한 정보를 얻어보자. 유사도 측정은 코사인 유사도를 활용하였다.
# Find Similar Items
item_biases, item_embeddings = model.get_item_representations(features=item_features)
def make_best_items_report(item_embeddings, book_id, num_search_items=10):
item_id = book_id - 1
# Cosine similarity
scores = item_embeddings.dot(item_embeddings[item_id]) # (10000, )
item_norms = np.linalg.norm(item_embeddings, axis=1) # (10000, )
item_norms[item_norms == 0] = 1e-10
scores /= item_norms
# best: score가 제일 높은 item의 id를 num_search_items 개 만큼 가져온다.
best = np.argpartition(scores, -num_search_items)[-num_search_items:]
similar_item_id_and_scores = sorted(zip(best, scores[best] / item_norms[item_id]),
key=lambda x: -x[1])
# Report를 작성할 pandas dataframe
best_items = pd.DataFrame(columns=['book_id', 'title', 'author', 'score'])
for similar_item_id, score in similar_item_id_and_scores:
book_id = similar_item_id + 1
title = item_meta[item_meta['book_id'] == book_id].values[0][3]
author = item_meta[item_meta['book_id'] == book_id].values[0][1]
row = pd.Series([book_id, title, author, score], index=best_items.columns)
best_items = best_items.append(row, ignore_index=True)
return best_items
# book_id 2: Harry Potter and the Philosopher's Stone by J.K. Rowling, Mary GrandPré
# book_id 9: Angels & Demons by Dan Brown
report01 = make_best_items_report(item_embeddings, 2, 10)
report02 = make_best_items_report(item_embeddings, 9, 10)
해리포터와 마법사의 돌 그리고 천사와 악마, 이 두 권의 책과 유사한 책에 관한 정보를 확인해 보자.
# 해리포터와 마법사의 돌
book_id title author score
2 Harry Potter and the Philosopher's Stone J.K. Rowling, Mary GrandPré 1.000000
5006 Blue Smoke Nora Roberts 0.768227
1674 Prince of Thorns Mark Lawrence 0.767087
1376 The Ugly Truth Jeff Kinney 0.761519
418 Spirit Bound Richelle Mead 0.760111
1577 Being Mortal: Medicine and What Matters in the... Atul Gawande 0.755845
2230 The Black Cauldron Lloyd Alexander 0.739562
5776 Frog Music Emma Donoghue 0.739197
2083 The Darkest Night Gena Showalter 0.735191
1262 Children of Dune Frank Herbert 0.735112
# 천사와 악마
book_id title author score
9 Angels & Demons Dan Brown 1.000000
666 Anansi Boys Neil Gaiman 0.876268
3687 Lord of Misrule Rachel Caine 0.869406
504 NaN Francine Rivers 0.859091
308 Can You Keep a Secret? Sophie Kinsella 0.847986
971 NaN Marcus Pfister, J. Alison James 0.847010
138 The Scarlet Letter Nathaniel Hawthorne, Thomas E. Connolly, Nina ... 0.840049
552 The Rescue Nicholas Sparks 0.834288
208 The Immortal Life of Henrietta Lacks Rebecca Skloot 0.834270
503 2001: A Space Odyssey Arthur C. Clarke 0.812411
결과에 대해서는 독자의 판단에 맡기겠다.
Reference
1) LightFM 공식 문서 2) LigghtFM 관련 블로그 3) Hyperopt 깃헙