
Strategies for pre-training Grapn Neural Networks 설명
01 Feb 2022 | Machine_Learning Recommendation System Paper_Review목차
이번 글에서는 GNN을 pre-train하는 과정에 대해 설명하는 논문에 대해 간략히 다뤄보겠습니다. domain-specific한 실험에 대한 내용이 많아 전반적인 과정과 인사이트에 대해서면 요약해서 정리해보겠습니다.
논문 원본은 이 곳에서 확인할 수 있습니다. pytorch geometric에서는 이 곳에서 처럼 본 논문에서 사용된 convolution layer를 모듈화 해 두었습니다.
Strategies for pre-training Grapn Neural Networks 설명
1. Introduction
거대한 모델을 pre-train한 후 downstream task에 적용하는 방법 효과적이라는 사실은 이미 증명이 되었습니다만, 이러한 과정이 GNN에도 효과적인지에 대해서는 여전히 의문 부호가 남습니다. 본 논문에서는 개별 node 및 전체 그래프 수준에서 효과적으로 GNN을 pre-train하고 이를 downstream task 수행 과정까지 잘 이어지도록 하는 방법에 대해 설명하고 있습니다.
pre-train의 어려운 점이라고 한다면, 목표로 하는 downstream task와 관계 있는 target label과 example을 잘 골라야 하는데 여기서 상당한 수준의 domain expertise가 필요하다는 점입니다. 만약 이를 적절히 수행하지 못한다면 downstram task에 negative transfer를 하는 셈이 될 것입니다.
논문에서는 이를 해결하기 위해 쉽게 접근할 수 있는 node-level의 정보를 이용하고 GNN으로 하여금 graph-level knowledge 외에도 node와 edge에 대한 domain-specific한 knowledge를 포착하도록 유도하는 것을 핵심 아이디어로 제시하고 있습니다.
2. Strategies for pre-training GNN
pre-train 전략의 핵심은 GNN을 개별 node-level 및 graph-level 모두에서 pre-train 시키는 것입니다.
2.1. node-level pre-training
먼저 node-level에 대해서 알아봅니다.
2가지 방법이 존재합니다. Context Prediction 과 Attribute Masking이 바로 그것입니다.
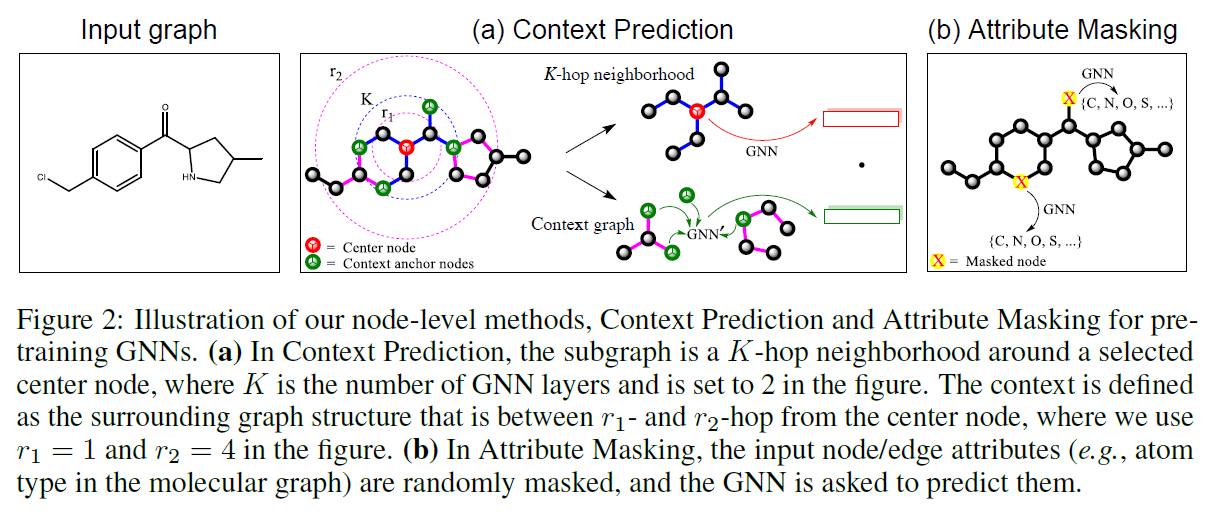
Context Prediction은 이웃 정보를 활용하여 해당 node 주위에 존재하는 그래프 구조를 예측하는 것이고 이 때 subgraph를 추출하여 학습이 진행됩니다. 그림에서처럼 context graph는 2가지 hyperparameter로 정의됩니다.
$r_1, r_2$ 는 각각 내부/외부 범위를 지정합니다. 위 그림에서 처럼 $r_2=4, r_1=1$ 로 설정하면 2-hop에서 4-hop 까지를 정보로 활용하겠다는 의미입니다. context anchor node를 지정하고 이 node들은 이웃들와 context 그래프가 얼마나 연결되어 있는지에 대한 정보를 제공합니다. 그리고 이에 대한 예측을 수행하기 위해서는 이들을 고정된 길이의 벡터로 변환해야 합니다. 논문에서는 이를 위해 context graph에 존재하는 node embedding들을 평균화하여 context embedding을 얻는다고 이야기 합니다. 그래프 $G$ 에서 이러한 context embedding을 얻었다면 다음과 같이 표현할 수 있습니다.
\[c_v^G\]어떻게 학습할지는 정했습니다. 그럼 label은 무엇일까요? 논문에서는 supervised-learning을 통해 pre-train하는 것을 제안하고 있습니다. 기본적으로 그래프 데이터만 주어지면 negative label은 딱히 존재하지 않습니다. 연결 되어 있지 않다는 정보를 바탕으로 negative label을 추출해야 합니다. 논문에서는 positive:negative 비율을 1:1로 맞추어 무작위 추출을 진행했다고 합니다.
그리고 다음 값을 구하여 학습을 진행합니다.
\[\sigma( h_i^{(K)T} c_j^{G^j})\]그리고 만약 $i, j$ context graph가 같은 node에 속한다면 위 값은 1이 되어야 할 것이고 그렇지 않다면 0이 되어야 할 것입니다.
Attribute Masking은 node 및 edge의 attribute를 masking 하고 GNN이 이 특징을 예측하도록 task를 정의하는 것입니다. 무작위로 input node/edge attribute를 masking하고 GNN을 통해 이에 상응하는 node/edge embedding을 얻도록 합니다. 이 때 edge embedding은 edge의 end node에 해당하는 node들의 embedding의 합으로 구성됩니다. 그리고 최종적으로 마지막 linear model이 적용되어 masked node/edge attribute를 예측하도록 학습이 수행됩니다.
2.2. graph-level pre-training
이전 section에서 유용한 node embedding을 얻었습니다. 이를 통해 쓸모 있는 graph embedding을 만들어야 합니다. 이를 위해 2가지 task를 생각할 수 있습니다.
하나는 그래프의 구조적 유사성을 판별하는 일인데, 논문에서는 이 과정이 너무 어렵고 ground truth label을 찾는 것이 쉽지 않아 논문에서는 다루지 않겠다고 이야기 하고 있습니다.
다른 하나는 graph-level의 property를 예측하는 일입니다. 예를 들어 분자 구조 그래프가 있다고 할 때 이 구조의 특성을 예측해 볼 수 있을 것입니다.
graph-level representation인 $h_G$ 가 생성되었을 때 이를 직접적으로 downstream prediction task에서 파인 튜닝하는 데 사용하고 domain-specific한 정보를 $h_G$ 에 인코딩하도록 해야 합니다. 많은 graph property에 대해 동시에 예측을 진행하고 각각의 property에 대해 binary classification task를 수행합니다. 이 때는 물론 linear classifier가 붙어야 할 것입니다.
주의점은 있습니다. 그냥 생각 없이 pre-training task를 만들면 negative transfer가 일어날 수 있기 때문에 정말로 관계있는 supervised pre-training task를 구상해야 합니다. 물론 이를 위해서는 상당한 수준의 domain expertise가 필요할 것입니다.
이러한 문제를 조금이나마 덜기 위해 논문에서는 먼저 node-level의 pre-train을 수행하고 graph-level에서는 multi-task supervised pre-train을 수행하라고 이야기 합니다.
최종적으로 node-level, graph-level에서의 pre-training을 마쳤으면 이를 통해 downstream task를 풀어내면 됩니다.
(후략)