
Tab-Transformer(Tabular Data Modeling using contextual embeddings) 설명
13 Mar 2022 | Machine_Learning Recommendation System Paper_Review목차
이번 글에서는 tabular 데이터에 대해 Transformer를 적용하여 새로운 알고리즘을 고안한 논문에 대해 다뤄보겠습니다.
논문 원본은 이 곳에서 확인할 수 있습니다.
공식 repository는 awslabs-autogluon-tabtransformer를 확인하시면 되는데, 그대로 사용하기에는 어려운 부분이 있을 것입니다. 따라서 아래 두 깃헙도 참고하면 좋습니다.
본 글에서는 핵심적인 부분에 대해서만 살펴보겠습니다.
Tab-Transformer(Tabular Data Modeling using contextual embeddings) 설명
1. Introduction
tabular 데이터에 대해 tree-based 모델이 뛰어난 성능을 보이는 것은 사실입니다만, 한계점 또한 분명히 존재합니다. tabular 데이터와 image/text를 한 번에 학습시키는 multi-modality를 확보할 수 없고, 스트리밍 데이터에 대해 지속적인 학습 또한 불가능한 측면이 있습니다.
단순한 MLP로 임베딩을 한다고 하면, 그 얕은 구조와 context-free 임베딩이라는 특성 때문에 성능 측면에서 아쉬운 부분이 많습니다.
본 논문에서는 tree-based 모델에 필적하면서도 MLP보다 뛰어난 구조의 알고리즘을 소개합니다.
2. TabTransformer
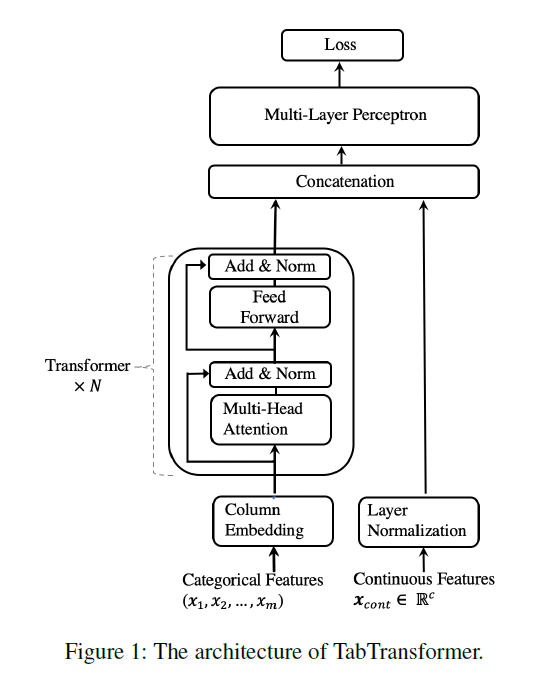
전체적인 구조 자체는 어렵지 않기 때문에 컨셉만 잘 이해하면 됩니다. DLRM 처럼 연속형 변수와 범주형 변수의 처리 방법 자체가 아예 다릅니다. 연속형 변수는 layer normalization를 거치고 난 후 최종 layer로 바로 투입되는 형태이지만, 범주형 변수의 경우 Column Embedding 과정을 거친 후 Transformer 구조를 통과 한 후에 최종 layer로 투입됩니다.
Column Embedding에 대해 상술해 보겠습니다. 범주형 변수가 $m$ 개가 존재한다고 할 때, 각각의 변수에는 또한 여러 class가 존재할 것입니다. 일단 Column Embedding을 통과하게 되면, $m$ 개의 범주형 변수는 $m$ 개의 임베딩 벡터로 변환됩니다. 만약 길이가 $d$ 라고 한다면, 길이 $d$ 를 갖는 $m$ 개의 벡터를 갖게 될 것입니다.
$i$ 번째 범주형 변수가 $d_i$ 개의 class를 갖고 있다고 하면, 임베딩 테이블 $e_{\phi_i} (.)$ 는 $d_i + 1$ 개의 임베딩을 갖게 됩니다. 1개가 추가된 것은 결측값에 대응하기 위함입니다. 해당 범주형 변수에 결측값이 많은 경우 이렇게 별도의 임베딩을 생성하면 되고, 만약 충분하지 않다고 하면 다른 임베딩 벡터의 평균 값 등을 이용할 수도 있을 것입니다.
모든 범주형 변수의 각 class에 대해 독립적인 임베딩 벡터를 만들 수도 있지만, 각 범주형 변수는 분명 다른 특성을 갖게 됩니다. 예를 들어 성별, 직업 이란 2개의 범주형 변수가 있다고 하면, 남성/여성이라는 특성은 분명 직업과는 다른 종류의 의미를 갖고 있을 것입니다. 이 때문에 같은 변수 내에서 일부 같은 parameter를 공유하게 설정할 수 있습니다. $i$ 변수의 $j$ class에 대한 변환을 식으로 표현하면 아래와 같습니다.
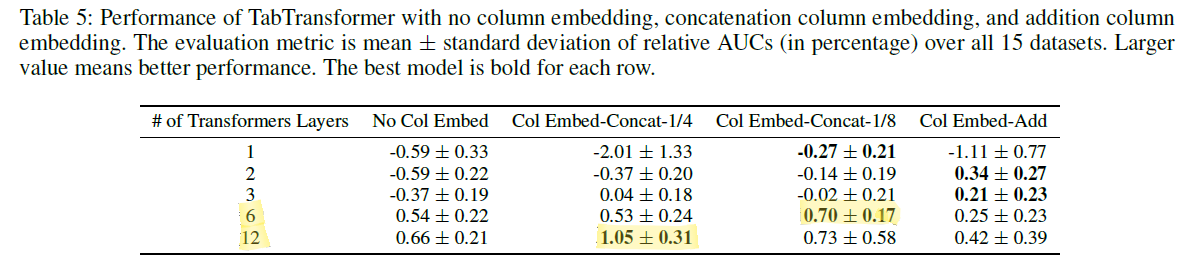
\[e_{\phi_i} (j) = [\mathbf{c}_{\phi_i}, \mathbf{w}_{\phi_{ij}}]\] \[\mathbf{c}_{\phi_i} \in \mathbb{R^l}, \mathbf{w}_{\phi_{ij}} \in \mathbb{R^{d-l}}\]이 때 $\mathbf{c}$ 라고 하는 각 변수 내에 존재하는 공유되는 parameter를 어느 정도 비중으로 가져갈 지는 실험의 영역입니다. 즉 $l$ 은 hyper-parameter에 해당합니다. 적정한 $l$ 을 찾는 것은 실험으로 해결해야하는 부분입니다만 논문의 ablation study에서 그 힌트를 찾을 수 있습니다. 논문에서는 1/4 또는 1/8이 가장 적절한 비율이라고 판단하였습니다.
tabular 데이터에서는 변수 간 순서라는 것이 존재하지 않는 경우가 많기 때문에, positional encoding을 쓰는 대신 이런 식으로 다른 중요한 정보를 활용할 수 있습니다.
앞서 설명하였듯이 이렇게 Column Embedding을 통해 생성된 벡터는 Transformer layer를 통과하게 됩니다. 통과한 결과물은 아래와 같이 표현할 수 있습니다.
\[[\mathbf{h}_1, \mathbf{h}_2, ..., \mathbf{h}_m]\]이 벡터들을 Contextualized Embedding이라고 부르며, top MLP에 투입되기 전 연속형 변수인 $\mathbf{x}_{cont}$ 와 합쳐지게 됩니다. 그렇다면 이 concatenated 벡터의 차원은 $(d*m + c)$ 입니다.
top MLP를 거치면 최종 output이 산출되게 됩니다.
3. Experiments
실험 종류가 많아서 모두 자세히 기록하지는 않겠습니다. 몇 가지만 살펴보겠습니다.
기본적인 MLP와의 성능 비교는 아래와 같습니다.
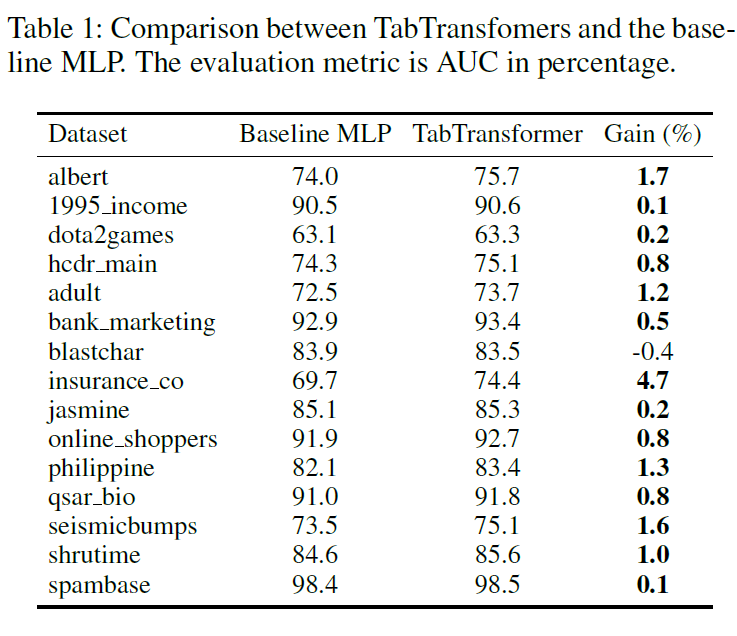
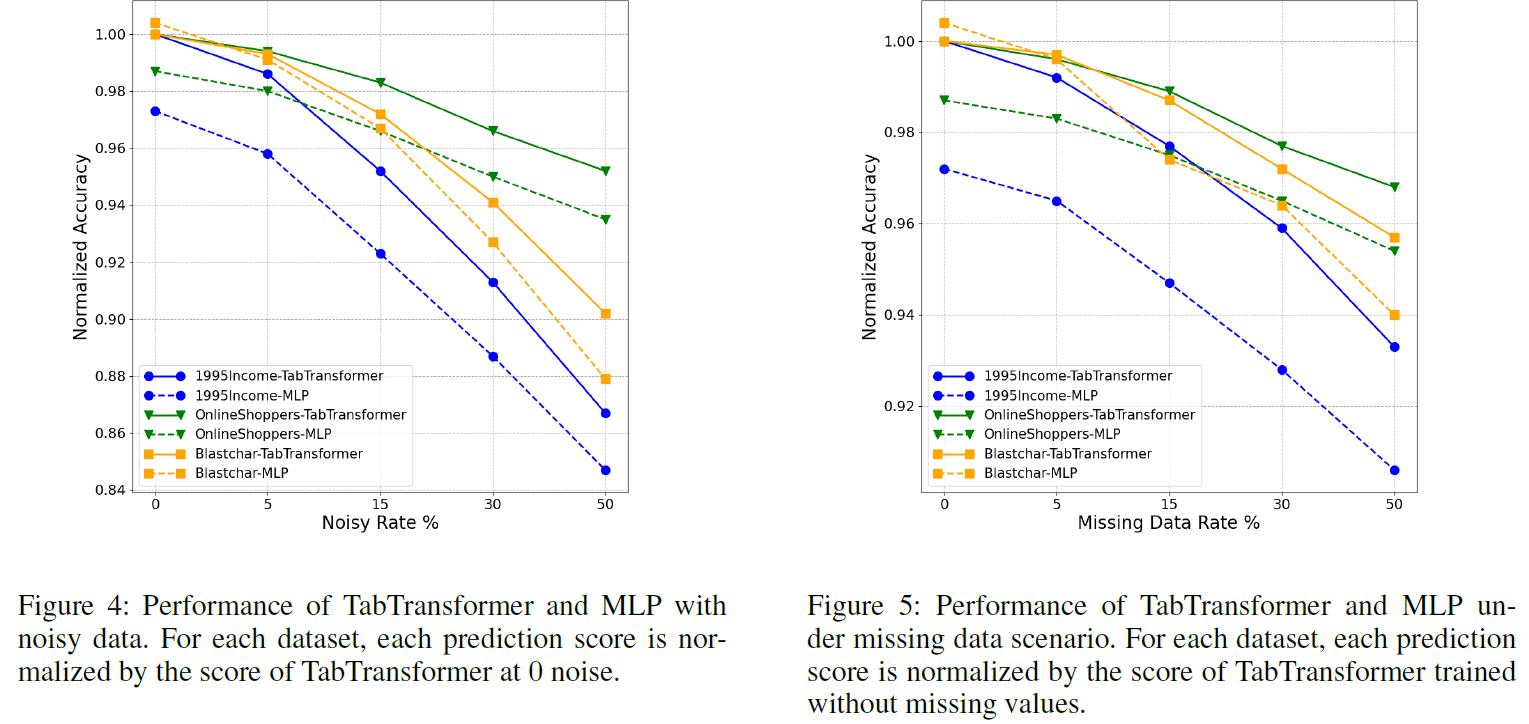
noisy 데이터와 결측값이 있는 데이터에 대해서도 TabTransformer는 기본적인 MLP 보다 더 높은 성능을 보여줍니다. (robust)
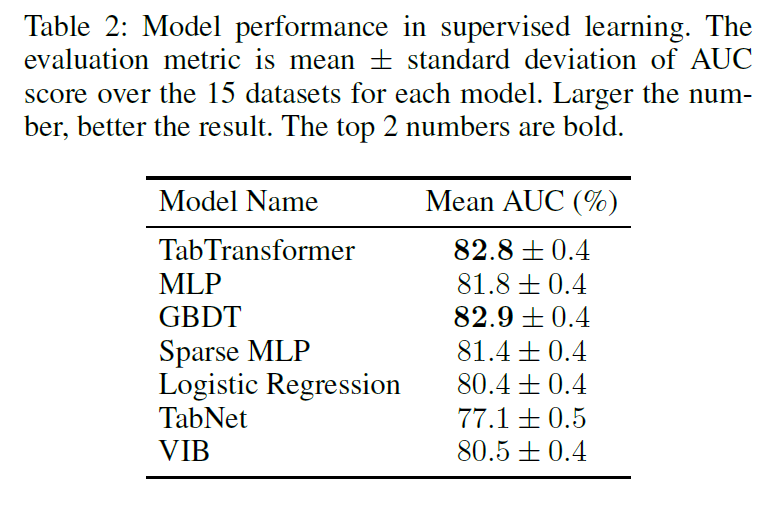
지도 학습 상의 모델 성능을 보면, TabTransformer는 GBDT에 필적하는 성능을 보임을 알 수 있습니다.
부록에 보면 Column Embedding에서 $\mathbf{c}_{\phi_i}$ 의 비율에 대한 실험이 나옵니다. Transformer Layer의 수에 따라 조금씩 다르지만 보통 1/4 ~ 1/8의 비율이 높은 성능을 보여줌을 알 수 있습니다. Column Embedding이 아예 없는 경우가 제일 좋지 않은 성능을 보여준 것도 확인해 보아야 할 대목입니다.
4. Conclusion
semi-supervised learning에 대한 이야기도 많이 있으니 (본 글에서는 생략) 논문을 직접 참고하시길 바랍니다. TabTransformer는 tabular 데이터를 이용한 딥러닝 알고리즘으로 MLP, GBDT에 비해 차별화된 장점을 갖고 있는 방법론입니다. 다양한 유형의 데이터를 소화할 수 있으면서도 안정적인 성능을 낼 수 있는 알고리즘으로 평가할 수 있겠습니다.