
Generating Sequences With Recurrent Neural Networks
15 Jul 2019 | Paper_Review NLP목차
- Generating Sequences With Recurrent Neural Networks
이 글에서는 2013년 8월(v1) Alex Graves가 발표한 Generating Sequences With Recurrent Neural Networks를 살펴보도록 한다.
연구자의 홈페이지도 있다.
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
Generating Sequences With Recurrent Neural Networks
논문 링크: Generating Sequences With Recurrent Neural Networks
초록(Abstract)
이 논문은 LSTM(Long Short-term Memory) RNNs이 어떻게 넓은 범위의 구조를 가진 복잡한 시퀀스(sequences, 문장 등)를 만들 수 있는지(= 단순히 어느 시점에 하나의 부분만 예측하는 방법)를 보여준다. 이 접근법은 텍스트(이산값)와 손글씨(실수값)에 의해 보여질 것이다. 그리고 네트워크가 텍스트 문장에 대해 예측을 수행함으로써 손글씨 합성으로까지 확장한다. 이 결과 시스템은 다양한 스타일의 정말 실제 같은 필기체를 생성할 수 있다.
1. 서론(Introduction)
RNNs(Recurrent Neural Networks)은 음악, 텍스트, 모션캡쳐 데이터 등과 같은 연속데이터를 생성하기 위해 사용되는 모델이다. RNN은 일반적으로 지금까지의 입력값과 모델 내부 parameter를 바탕으로 바로 다음 것이 무엇일지를 예측하는 모델이다.
RNN은 많은 경우 그 예측이 애매하며 불확실하다(fuzzy). 그 이유는 항상 확정적이며 똑같은 결과만을 내놓는다면 생성되는 문장이나 음악은 항상 똑같을 것인데 우리는 그런 것을 원하지 않으며, 또한 확률적인(stochastic) 방법이 정확한(exact) 일치 방법에 비해 차원의 저주(the curse of dimensionality)를 피하기 적합하며 그로 인해 시퀀스 또는 다변수 데이터를 모델링하는 데 더 뛰어나다.
이론적으로는 충분히 큰 RNN은 어떤 복잡한 시퀀스(sequences)도 생성할 수 있어야 한다. 그러나 Vanilla RNN은 최근 몇 개의 입력값을 기억하며 이에 의존할 뿐 멀리 떨어진 이전 또는 장기적인 정보를 거의 기억하지 못한다.
이를 많은 부분 해결한 것이 바로 LSTM이다. 이 역시 기본적으로는 이전 정보를 기억하는 RNN 구조를 따르지만 조금 더 복잡한 구조를 가지며 장기적(long-range) 정보를 저장하는 데 뛰어난 능력을 보인다.
이 논문에서는 다음과 같은 것들을 다룰 것이다.
- Section 2: LSTM을 여럿 쌓을 ‘deep RNN’을 정의하고 어떻게 다음 단계를 예측하는 데 필요한 학습을 진행하며 시퀀스를 생성하는지 보여준다.
- Section 3: Penn Treebank와 Hutter Prize Wikipedia 데이터셋에 대해 예측을 수행하고 state-of-the-art 수준임을 보인다.
- Section 4: mixture density output layer를 사용하여 어떻게 실제 데이터에 적용할 수 있는지와 IAM Online Handwriting Database에 대한 실험 결과를 보인다.
- Section 5: 예측 네트워크를 짧은 주석에 기반하도록 하여 확장시켜서 어떻게 손글씨 합성을 시킬 수 있는지를 보인다.
- Section 6: 결론과 함께 추후 연구 방향을 제시한다.
2. 예측 네트워크(Prediction Network)
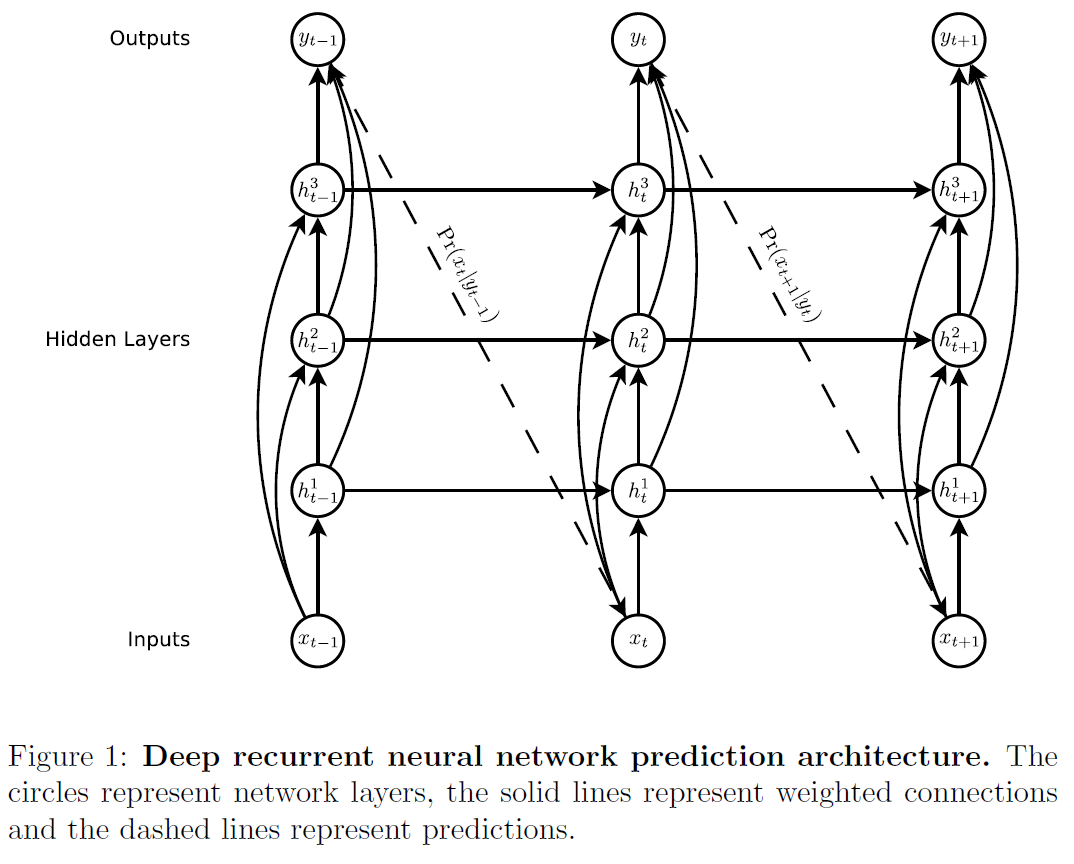
위 그림은 이 논문에서 사용된 기본 RNN 모델의 구조이다. 입력값 $x = (x_1, …, x_T)$은 $N$층에 걸쳐 쌓인 재귀적으로 연결된 hidden layers를 통과하며 $h^n = (h_1^n, …, h_T^n)$ 를 계산하고 최종적으로 $N$층을 다 통과하면 출력벡터 시퀀스 $y = (y_1, …, y_T)$를 얻는다. 각 출력벡버 $y_t$는 가능한 다음 입력값 $x_{t+1}$에 대한 예측분포 $P(x_{t+1} \vert y_t)$를 뜻한다. 초기값 $x_1$은 언제나 null 벡터이다.
입력과 모든 hidden layer, 그리고 모든 hidden layer와 출력과 ‘skip-connections’이 존재함을 기억하라. 이는 vanishing gradient 문제를 피해 깊은 신경망(DNN)을 학습시키기 용이하게 한다. $N=1$인 경우에 vanilla RNN과 같음을 확인할 수 있다.
Hidden layer의 각 활성값은 $t=1…T, n=2…N$ 동안 반복적으로 계산된다:
\[h_t^1 = \mathcal{H}(W_{ih^1x_t} + W_{h^1h^1}h^1_{t-1} + b^1_h)\] \[h_t^n = \mathcal{H}(W_{ih^nx_t} + W_{h^{n-1}h^n}h^{n-1}_{t} + W_{h^nh^n}h^n_{t-1} + b^n_h)\]$W$는 각 레이어의 가중치 행렬이다. 은닉 시퀀스가 주어졌을 때, 출력 시퀀스는
\[\hat{y_t} = b_y + \sum^N_{n=1} W_{h^n y h_t^n}\] \[y_t = \mathcal{Y}(\hat{y_t})\]$\mathcal{Y}$는 출력레이어 함수이다.
입력시퀀스 $x$에 대해 예측분포와 시퀀스 손실함수는
\[Pr(x) = \prod_{t=1}^T Pr(x_{t+1} \vert y_t)\] \[\mathcal{L}(x) = -\prod_{t=1}^T \log Pr(x_{t+1} \vert y_t)\]로 정의된다.
LSTM의 구조에 대해서는 다른 블로그들에 자세히 잘 설명되어 있으니 참고하자.
3. 문자 예측(Text Prediction)
텍스트 데이터는 이산값이고, 이런 것들은 보통 ‘one-hot’ 방식으로 인코딩된다. 텍스트의 경우 단어(word) 수준으로 인코딩을 수행하게 되고, 이는 벡터의 크기가 단어 사전의 크기(보통 적어도 10만 이상)가 되는 문제가 발생한다.
최근에는 단어 수준 대신 문자 수준으로 예측을 수행하는 방법이 많이 고려되고 있다. 이 방법의 장점은
- 단어 수준 인코딩에 비해 성능이 별로 떨어지지 않으며
- 벡터의 크기가 작고
- 이전에 나타나지 안았던(unknown) 단어에 대한 대비가 필요 없어지며
- 새로운 단어를 만들 가능성도 생긴다.
따라서 이 논문에서는 문자 단위로 생성하는 모델을 고려할 것이다.
3.1. Penn Treebank Experiments
이 데이터셋은 Wall Street Journal corpus의 일부로 네트워크의 예측능력보다는 시퀀스 생성능력에 초점을 두고 실험할 것이다.
Penn Treebank 데이터셋은 100만 단어 정도의 작은 데이터셋이지만 언어 모델링 벤치마크에서 널리 사용된다. 93만 단어의 training set, 7만 4천 단어의 validation set, 8만 2천 단어의 test set을 포함한다. 단어는 1만 종류이며 나머지는 전부 unknown 처리되어 있다.
이 실험은 Penn corpus에 대해 단어 수준과 문자 수준의 LSTM 예측기의 성능을 비교하는 것이다. 두 경우 모두 1000개의 LSTM unit을 사용했고, 단어/문자 수준 벡터의 크기는 다르다(49 vs 10000, 가중치행렬의 크기는 4.3M vs 54M).
SGD(Stochastic Gradient Descent), learning rate 0.0001, momentum 0.99, LSTM derivates는 [-1, 1] 범위로 clip된다.
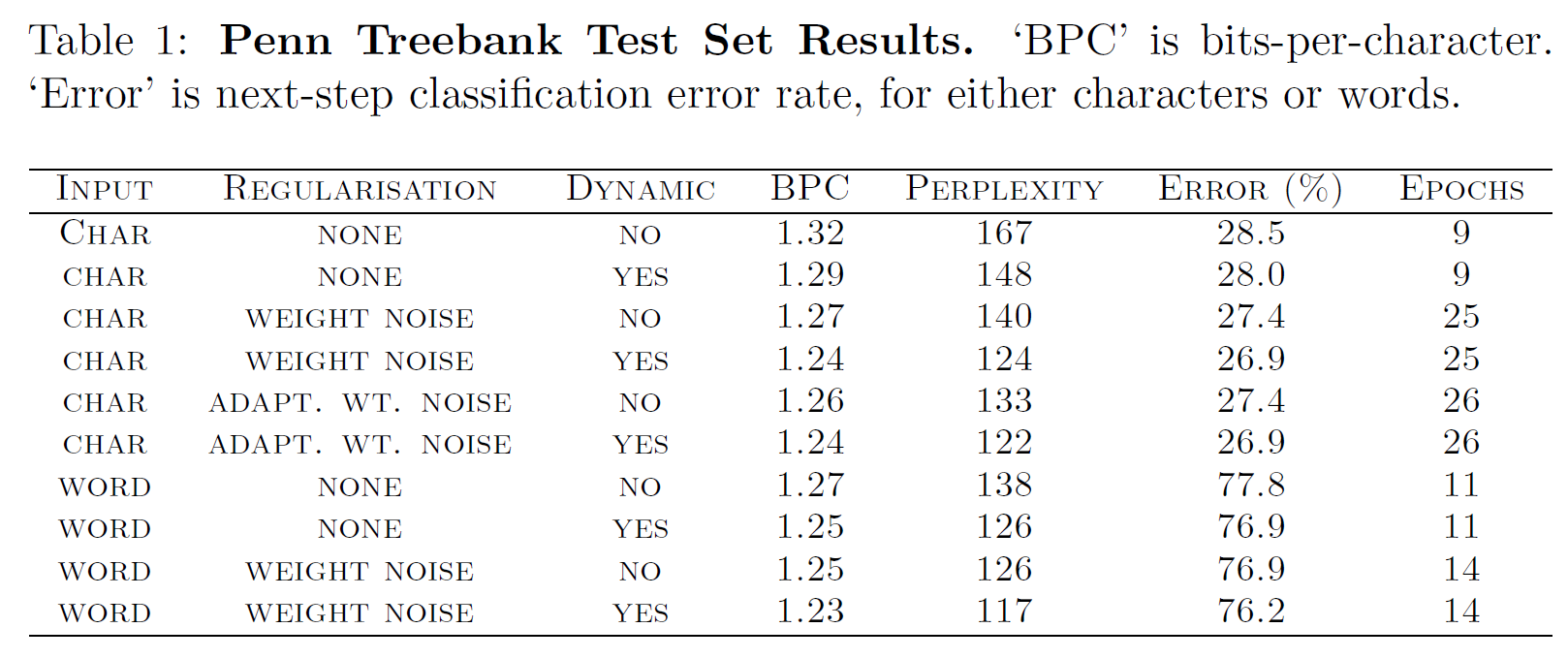
위 실험의 결과를 두 가지로 요약하면
- 단어 수준 모델이 문자 수준 모델보다 약간 더 성능이 좋다는 것과
- LSTM은 Vanilla RNN보다 훨씬 빠르고 새 데이터에 최적화된다는 것이다.
3.2. Wikipedia Experiments
2006년 Marcus Hutter, Jim Bowery, Matt Mahoney로부터 시작된 영문 위키피디아의 첫 1억(100M) 바이트의 데이터인 Wikipedia data는 다양한 단어와 문자를 포함한다. 아랍어나 중국어 등 비 라틴 알파벳 뿐만 아니라 메타데이터를 지정하는 XML 태그 등 그 종류가 꽤 방대하다.
첫 96M 바이트는 training set, 나머지 4M 바이트는 validation으로 사용된다. 데이터는 205 one-byte 유니코드 기호를 사용한다.
여기서는 더 큰 모델을 사용했다. 700 LSTM unit을 포함하는 7층짜리 네터워크로 가중치행렬의 크기는 21.3M이다. momentum이 0.9인 것을 제외하면 다른 조건은 같다.
Wikipedia는 글의 주제와 같은 수천 단어 이상일 수 있는 넓은 범위(long-range) 의존성을 포함하기 때문에 LSTM의 내부 상태는 매번 100 sequence 만큼만을 리셋한다. 즉 gradient를 근사하는 것인데, 이는 넓은 범위 의존성을 최대한 잃지 않으면서 학습속도를 높이는 방법이다.
아래 결과를 보면 Dynamic evaluation을 사용했을 때 성능이 더 좋게 나온다. 이는 위키피디아의 넓은 범위 일관성 때문인 것으로 보인다(예: 특정 단어들은 특정 글에서 더 빈번히 등장하며, 평가 중에 이에 맞출 수 있는 것이 더 유리하다).

논문에는 실제 위키피디아 페이지와, 예측 네트워크가 생성한 위키피디아 페이지를 보여주고 있는데 그 중 일부를 가져왔다.

보면 은근히 괜찮은 품질의 글을 생성해냈음을 볼 수 있다. 특히 봐줄 만한 이름들(Lochroom River, Mughal Ralvaldens, swalloped) 등의 모델이 직접 생성해낸 이름들이 눈의 띈다.
괄호나 따옴표를 여닫는 것은 언어 모델의 메모리에 명백히 이를 알려주는 지시자가 있는데, 이는 좁은 범위(short-range)의 문맥으로는 모델링될 수 없어서 중간 글자들만으로는 예측할 수 없기 때문이다. 위 샘플 결과는 괄호나 따옴표의 적절한 수를 지켰을 뿐만 아니라 nested XML tag 등도 잘 구현해 내었다.
네터워크는 비 라틴 문자들, 키릴 문자나 한자, 아랍 문자 등을 생성했고, 이는 영어보다 더 기본적인 모델을 배운 것으로 보인다. 이 경우에도 봐줄 만한 이름들을 생성했다.
4. 손글씨 예측(Handwriting Prediction)
예측 네트워크가 실수값 시퀀스(real-valued sequences)도 충분히 잘 생성할 수 있는지 확인하기 위해 online 손글씨 데이터에 이를 적용해 보았다(online 필기 데이터란 그냥 필기 이미지만 있는 offline 데이터와는 달리 펜으로 해당 필기를 할 때 어떤 궤적을 그렸는지에 대한 정보가 있는 것이다). IAM-OnDB 데이터셋을 사용하였다.
IAM-OnDB 데이터셋은 221명의 사람이 Lancaster-Oslo-Bergen 말뭉치를 쓴 필기 데이터이다.

4.1 혼합밀도 출력값(Mixture Density Outputs)
Mixture Density Outputs의 아이디어는 혼합분포(mixture distribution)을 parameterise하기 위해 신경망의 출력값을 사용하는 것이다. 출력값의 부분집합은 혼합가중치(mixture weights)를 정의하기 위해, 남은 출력값은 독립적인 mixture components를 parameterise하도록 사용된다. Misture weight 출력값은 정규화, softmax 등을 거쳐 의미 있는 범위 안에 포함되도록 한다. 이는 Boltzmann machine이나 다른 무방향 모델과는 달리 density가 정규화되고 직접 미불되며 편향되지 않는 샘플을 고른다는 점에서 대비된다.
손글씨 실험을 위해, 기본적인 RNN 구조는 Section 2에서 변하지 않았다. 각 입력벡터 $x_t$는 이전 입력으로부터의 pen offset을 정의하는 실수쌍 $x_1, x_2$로 구성되며, 벡터가 stroke로 끝나면(다음 벡터가 기록되기 전에 펜이 보드에서 떨어지면) 1, 아니면 0의 값을 갖는 이진값 $x_3$로 구성된다.
이변수 혼합 가우시안(A mixture of bivariate Gaussians)이 $x_1, x_2$를 베르누이 분포가 $x_3$을 예측한다.
각 출력벡터 $y_t$는 stroke로 끝날 확률 $e$, 평균 $\mu^j$, 표준편차 $\sigma^j$, 상관계수 $\rho^j$, $M$ mixture components에 대한 혼합가중치 $\pi^j$로 구성된다.
\[x_t \in \mathbb{R} \times \mathbb{R} \times \{0, 1\}\] \[y_t = \Big( e_t, \{ \pi_t^j, \mu_t^j, \sigma_t^j, \rho_t^j \}_{j=1}^M \Big)\]평균과 표준편차는 2차원 벡터이고 나머지는 스칼라이다. 벡터 $y_t$는 네트워크 출력값 $\hat{y}_t$로부터 얻어지며,
\[\hat{y}_t = \Big( \hat{e}_t, \{ \hat{w}_t^j, \mu_t^j, \sigma_t^j, \rho_t^j \}_{j=1}^M \Big) = b_y + \sum_{n=1}^N W_{h^ny}h_t^n\]이다.
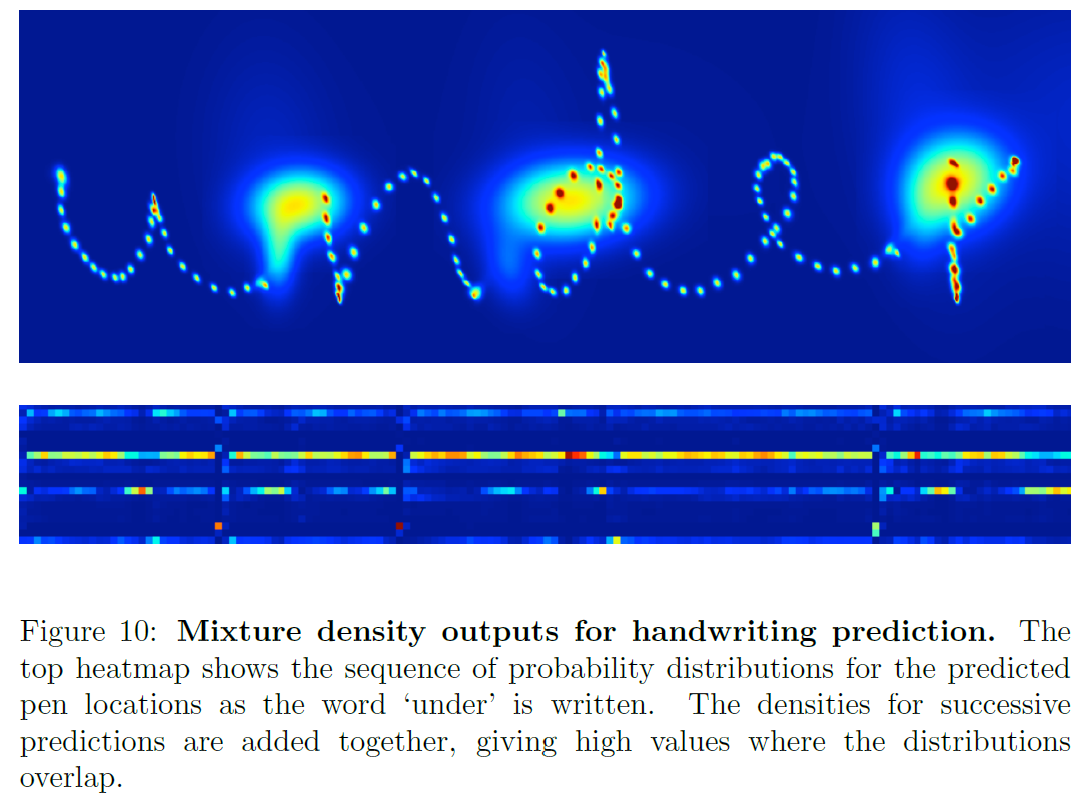
이 density map에서 두 종류의 예측을 볼 수 있다:
- 글자를 따라 존재하는 작은 점들(지금 써지고 있는 stroke를 예측)
- 세 개의 큰 원(다음 stroke의 시작점이 되는, stroke의 끝을 예측)
끝획(end-of-stroke)는 더 큰 분산을 갖는데 이는 화이트보드에서 펜이 떨어졌을 때 그 위치가 기록되지 않기 때문이며, 따라서 다음 stroke와의 거리가 커질 수 있다.
아래쪽 열지도는 갈은 sequence에서 misture component weights를 보여준다.
4.2 실험(Experiments)
네트워크는 RMSProp을 사용하였으며 가중치 업데이트 식은 다음과 갈다.
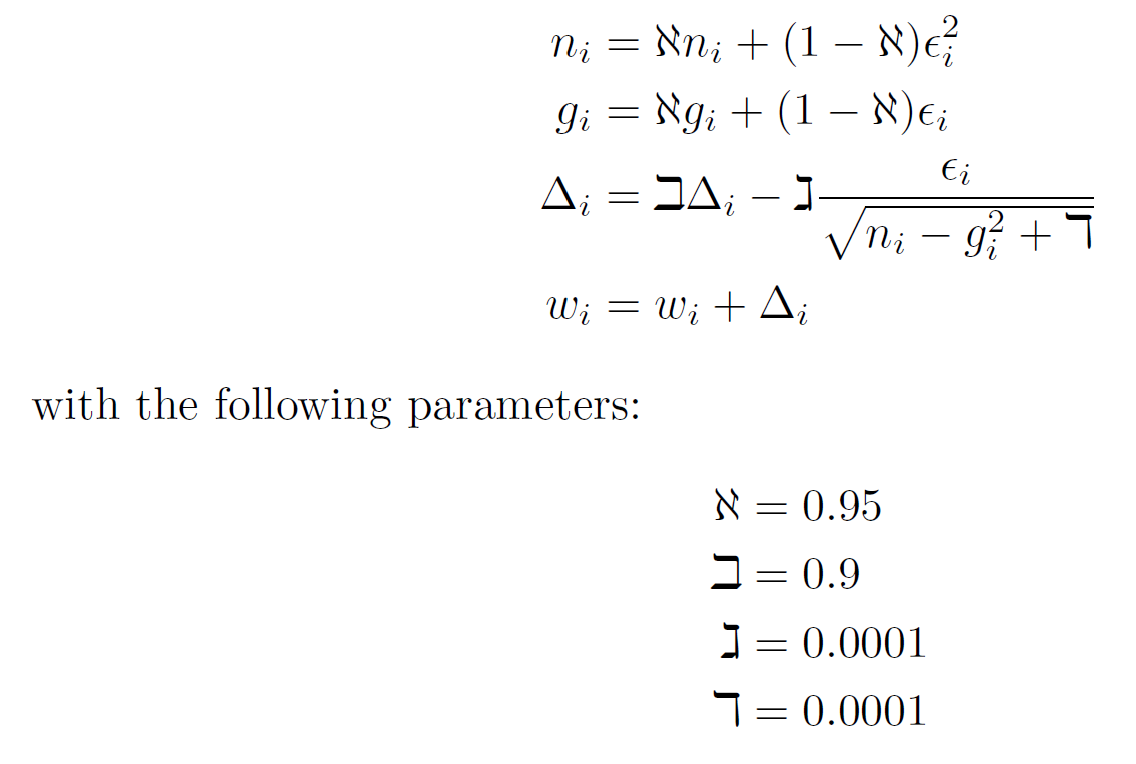
손글씨 예측 결과는 다음과 같다.

5. 손글씨 합성(Handwriting Synthesis)
손글씨 합성은 sequence가 매우 다른 길이를 가질 수 있고 그 사이의 alignment는 데이터가 생성되기 전까지 알려지지 않는다는 점에서 어렵다. 이는 각 글자가 필체, 크기, 펜 속도 등에 따라 매우 달라지기 때문이다.
연속적인 예측을 할 수 있는 한 신경망 모델은 RNN transducer이다. 그러나 이전 연구 결과들은 만족스럽지 못하다.
5.1. 합성 네트워크(Synthesis Network)
네트워크 구조는 다음과 같다.
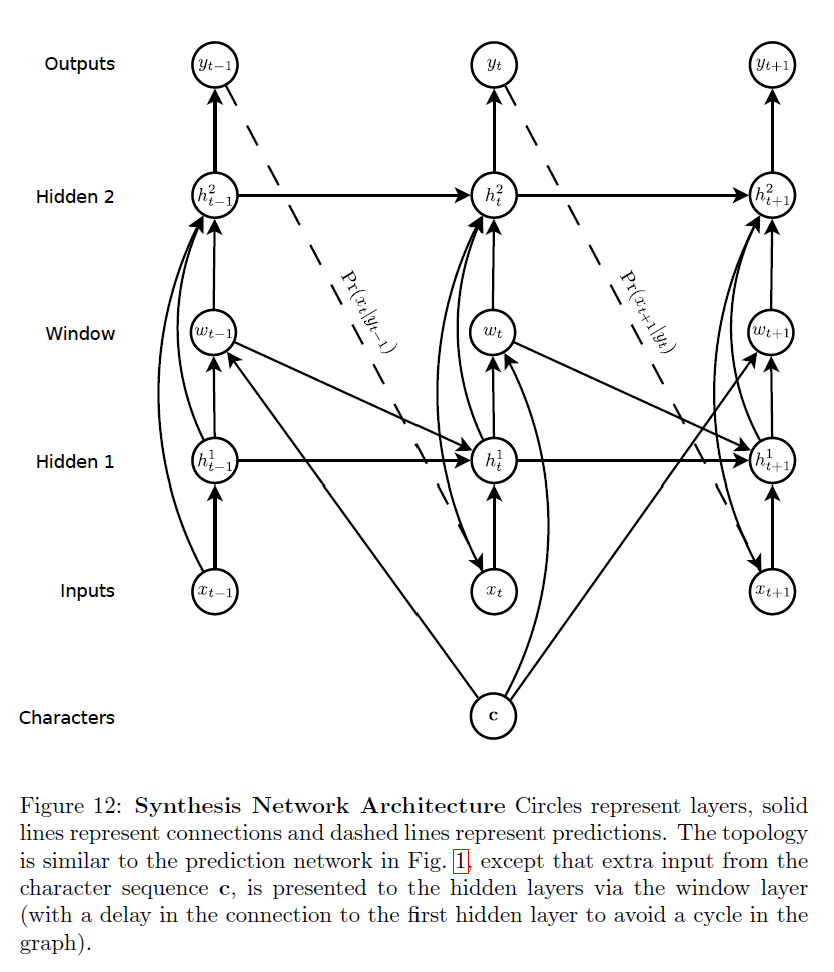
길이 $U$의 글자 sequence $c$가 주어지고 길이 $T$의 data sequence $x$가 주어졌을 때, 시간 $t(1\le t \le T)$에서 $c$로의 soft window $w_t$는 $K$ Gaussian 함수의 혼합에 의해 정의된다:
\[\phi(t, u) = \sum_{k=1}^K \alpha_t^k \text{exp} \Big( - \beta_t^k (\kappa_t^k - u)^2 \Big)\] \[w_t = \sum_{u=1}^U \phi(t, u)c_u\]$\phi(t, u)$는 시간 $t$에서 $c_u$의 window weight이고, $\kappa_t$는 window의 위치를 제어하며, $\beta_t$는 window의 너비를, $\alpha_t$는 혼합 내에서 window의 중요도를 제어한다.
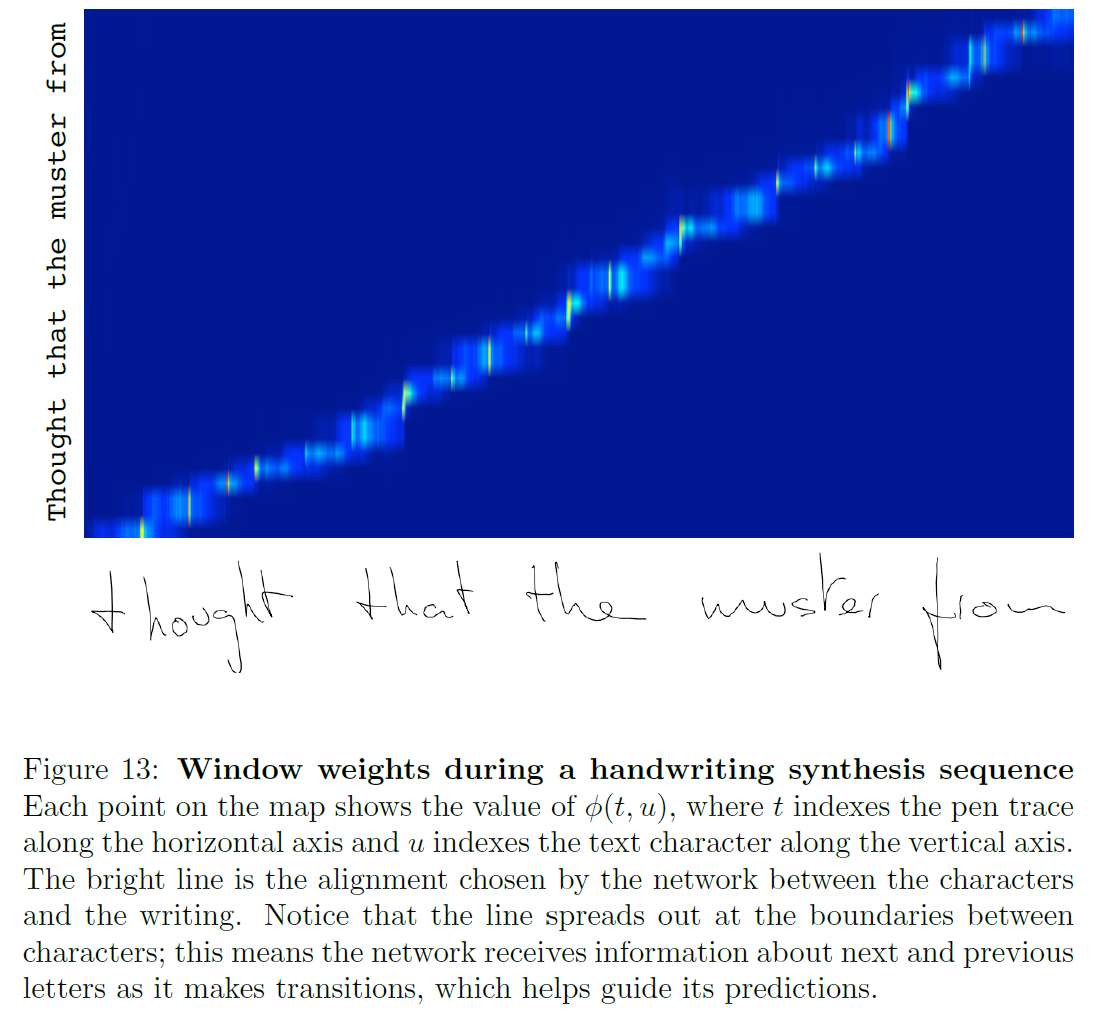
5.2. 실험(Experiments)
실험은 이전 section과 동일한 입력 데이터를 사용한다. IAM-OnDB는 이제 글자 sequence $c$를 정의한다.


5.3~5.5 Sampling(Unbiased, Biased, Prime Sampling)
Bias를 다르게 하는 등의 변형을 거쳐 손글씨를 합성한 결과를 몇 개 가져왔다.





Refenrences
논문 참조. 33개의 레퍼런스가 있다.