
ELMo - Deep contextualized word representations(ELMo 논문 설명)
20 Aug 2019 | Paper_Review NLP목차
- ELMo - Deep contextualized word representations
이 글에서는 2018년 2월 Matthew E. Peters 등이 발표한 Deep contextualized word representations를 살펴보도록 한다.
참고로 이 논문의 제목에는 ELMo라는 이름이 들어가 있지 않은데, 이 논문에서 제안하는 모델의 이름이 ELMo이다.
Section 3에서 나오는 이 모델은 Embeddings from Language Models이다.
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
ELMo - Deep contextualized word representations
논문 링크: Deep contextualized word representations
홈페이지: OpenAI Blog
초록(Abstract)
이 논문에서는 단어 사용의 복잡한 특성(문법 및 의미)과 이들이 언어적 문맥에서 어떻게 사용되는지(다의성)를 모델링하는, 새로운 종류의 문맥과 깊게 연관된 단어표현(Deep contextualized word representation)을 소개한다. 이 논문에서의 word vector는 큰 말뭉치에서 학습된 deep bidirectional language model(biLM)의 내부 상태로부터 학습한다. 이 표현(representation)은 이미 존재하는 모델에 쉽게 불일 수 있으며 이로써 QA 등 6개의 도전적인 NLP 문제에서 상당히 향상된 state-of-the-art 결과를 얻을 수 있음을 보였다. 또한 기학습된(pre-trained) 네트워크의 깊은 내부를 살펴보는 분석도 보인다.
1. 서론(Introduction)
기학습된 단어 표현(Pre-trained word representations)은 많은 자연어이해 모델에서 중요한 요소였다. 그러나 문법, 의미, 다의성을 학습한 높은 품질의 representation을 얻는 것은 어려운 일이다. 이 논문에서는 쉽게 다른 모델에 적용가능하며 성능도 뛰어난 Deep contextualized word representation을 소개한다.
이 representation은 (문장 내) 각 token이 전체 입력 sequence의 함수인 representation를 할당받는다는 점에서 전통적인 단어 embedding과 다르다. 이를 위해 이어붙여진 language model(LM)로 학습된 bidirectional LSTM(biLM)로부터 얻은 vector를 사용한다. 이 때문에 이를 ELMo(Embeddings from Language Models) representation이라 부른다. 이는 LSTM layer의 최종 layer만을 취한 것이 아닌, 각 layer 결과를 가중합하여 얻어지며 이것이 성능이 더 좋다.
LSTM의 낮은 단계의 layer(입력과 가까운 층)는 품사 등 문법 정보를, 높은 단계의 layer(출력과 가까운 층)는 문맥 정보를 학습하는 경향이 있다.
많은 실험에서 ELMo representation이 매우 뛰어남을 보여 주었는데, 상대적으로 에러율을 20% 줄이기도 하였다.
2. 관련 연구(Related work)
기학습된 단어 벡터(pretrained word vectors)는 많은 NLP 모델에서 매우 중요한 역할을 했다. 그러나 미리 학습된 단어 벡터는 다의어도 한 개의 벡터로 표현하기 때문에 문맥 정보를 고려하지 못한다.
이를 극복하기 위한 방안으로 보조단어 정보를 활용하거나 각 단어당 여러 벡터를 만드는 방법이 고려되었다. 이 논문의 방법(ELMo representation)은 보조정보로부터의 이점을 가지며 또한 명시적으로 여러 벡터를 만들 필요도 없다.
문맥의존 표현을 학습하는 다른 연구로는 다음이 있다.
- 양방향 LSTM을 사용하는 context2vec(Melamud et al., 2016)
- 표현 안에 pivot word 자체를 포함하는 CoVe(McCann et al., 2017)
Deep biRNN의 낮은 단계의 layer를 사용하여 dependency parsing(Hashimoto et al., 2017)이나 CCG super tagging(Søgaard and Goldbert, 2016) 등의 문제에서 성능 향상을 시킨 연구도 있었다.
Dai and Le(2015)와 Ramachandran et al.(2017)에서는 언어모델(LM)로 인코더-디코더 쌍을 기학습시키고 특정 task에 fine-tune시켰다.
이 논문에서는 미분류된 데이터로부터 biLM을 기학습시킨 후 weights를 고정시키고 task-specific한 부분을 추가하여 leverage를 증가시키고 풍부한 biLM representation을 얻을 수 있게 하였다.
3. ELMo: Embeddings from Language Models
다른 단어 embedding과는 다르게 ELMo word representation은 전체 입력 sequence의 함수이다. 이는 글자수준 합성곱(character convolutions, Sec. 3.1)로부터 얻은 biLM의 가장 위 2개의 layer의 선형함수(가중합, Sec. 3.2)으로 계산된다. 이는 준지도학습과 더불어 biLM이 대규모에서 기학습되며(Sec 3.4) 쉽게 다른 NLP 모델에 붙일 수 있도록(Sec 3.3) 해준다.
3.1. Bidirectional language models
$N$개의 token $(t_1, t_2, …, t_N)$이 있을 때, 전방언어모델(forward language model)은 $(t_1, …, t_{k-1})$이 주어졌을 때 token $t_k$가 나올 확률을 계산한다:
\[p(t_1, t_2, ..., t_N) = \prod_{k=1}^N p(t_k \vert t_1, t_2, ..., t_{k-1})\]최신 언어모델은 token embedding이나 문자단위 CNN을 통해 문맥-독립적 token representation $x_k^{NM}$을 계산하고 이를 전방 LSTM의 $L$개의 layer에 전달한다.
각 위치 $k$에서, 각 LSTM layer는 문맥-의존적 representation $\overrightarrow{h}_{k, j}^{LM}(j = 1, …, L)$을 출력한다.
LSTM의 최상위 layer LSTM 출력 $\overrightarrow{h}_{k, L}^{LM}$은 Softmax layer와 함께 다음 token을 예측하는 데 사용된다.
후방(backward) LSTM은 거의 비슷하지만 방향이 반대라는 것이 다르다. 식의 형태는 똑같지만 뒤쪽 token을 사용해 확률을 계산하고 token을 예측한다.
\[p(t_1, t_2, ..., t_N) = \prod_{k=1}^N p(t_k \vert t_{k+1}, t_{k+2}, ..., t_N)\]즉 $(t_{k+1}, …, t_N)$이 주어졌을 때 representation $\overleftarrow{h}_{k, j}^{LM}$을 계산한다.
biLM은 이 둘을 결합시킨 로그우도를 최대화한다.
\[\sum_{k=1}^N \Big( \log \ p(t_k \vert t_1, ..., t_{k-1}; \Theta_x, \overrightarrow{\Theta}_{LSTM}, \Theta_s) + \log \ p(t_k \vert t_{k+1}, ..., t_N; \Theta_x, \overleftarrow{\Theta}_{LSTM}, \Theta_s) \Big)\]$\Theta_x$는 token representation, $\Theta_s$는 Softmax layer이며 이 둘은 LSTM의 parameter과는 다르게 고정된다.
3.2. ELMo
ELMo는 biLM의 중간 layer representation을 task-specific하게 결합한다. biLM의 $L$개의 layer는 각 token $t_k$당 $2L+1$개의 representation을 계산한다.
각 biLSTM layer에서
\[h_{k, 0}^{LM}: \text{token layer}, h_{k, j}^{LM} = [\overrightarrow{h}_{k, j}^{LM}; \overleftarrow{h}_{k, j}^{LM}]\]일 때
\[R_k = \{ x_k^{LM}, \overrightarrow{h}_{k, j}^{LM}, \overleftarrow{h}_{k, j}^{LM} \vert j = 1, ..., L \} = \{ h_{k, j}^{LM} \vert j = 0, ..., L \}\]위의 식은 위치 $k$에서 $R_k$는 $1+L+L=2L+1$개의 representation으로 이루어져 있다는 뜻이다.
Downstream model로의 포함을 위해, ELMo는 $R$의 모든 layer를 하나의 벡터 $\text{ELMo}_k = E(R_k; \Theta_e)$로 압축시킨다.
가장 단순한 예로 ELMo가 단지 최상위 레이어를 택하는 $E(R_k) = h_{k, L}^{LM}$는 TagLM이나 CoVe의 것과 비슷하다.
더 일반적으로, 모든 biLM layer의 task-specific한 weighting을 계산한다:
\[\text{ELMo}_k^{task} = E(R_k; \Theta^{task}) = \gamma^{task} \sum_{j=0}^L s_j^{task} h_{k, j}^{LM}\]$s^{task}$는 softmax-정규화된 가중치이고 scalar parameter $\gamma^{task}$는 전체 ELMo 벡터의 크기를 조절하는 역할을 한다. $\gamma$는 최적화 단계에서 중요하다.
각 biLM layer에서의 활성함수는 다른 분포를 갖는데, 경우에 따라 가중치를 정하기 전 각 biLM layer에 정규화를 적용하는 데 도움이 되기도 한다.
3.3. Using biLMs for supervised NLP tasks
목표 NLP task에 대한 기학습된 biLM과 지도(supervised) 모델구성이 주어지면, 해당 task 모델을 향상시키도록 biLM을 쓰는 과정은 간단하다.
- 단지 biLM을 돌리고 각 단어마다 모든 layer representation을 기록한다.
- 그리고 모델이 이 representation들의 선형결합을 배우도록 한다.
- 먼저 biLM이 없는 지도 모델을 고려한다.
- 대부분의 NLP 지도 모델은 가장 낮은 단계의 layer에서 공통구조를 공유하는데, 이는 ELMo를 일관된 방법으로 추가할 수 있게 해 준다.
- $(t_1, t_2, …, t_N)$이 주어지면 기학습된 단어 embedding(+글자기반 representation)을 사용하여 각 token 위치마다 문맥-독립적 token representation $x_k$를 만든다.
- 그러면 모델은 biRNN이든 CNN이든 FFN이든 사용하여 문맥-의존적 representation $h_k$를 생성한다.
ELMo를 지도 모델에 추가하려면
- 먼저 biLM의 weight를 고정시키고
- ELMo 벡터 $\text{ELMo}_k^{task}$와 $x_k$를 이어붙인 후
- ELMo enhanced representation $[x_k; \text{ELMo}_k^{task}]$를 task RNN에 전달한다.
SNLI, SQuAD 등의 task에서는 $h_k$를 $[x_k; \text{ELMo}_k^{task}]$로 대체하면 성능이 더 향상되었다.
또한 ELMo에 dropout을 적용하는 것과, $\lambda \Vert w \Vert_2^2$를 loss에 더해 ELMo weight를 정규화하는 것이 ELMo weight에 inductive bias를 유도하여 모든 biLM layer의 평균에 더 가까워지도록 하여 성능에 도움을 주는 것을 발견하였다.
3.4. Pre-trained bidirectional language model architecture
기학습된 biLM은 이전 모델(Józefowicz et al. 2016)의 것과 비슷하지만 양방향 학습의 동시학습을 가능하게 하고 LSTM layer 사이에 residual connection을 추가하였다.
완전히 문자기반인 입력 representation을 유지하면서도 모델복잡도와 계산요구량의 균형을 맞추기 위해, embedding과 은닉차원을 반으로 줄였다.
최종 모델은 4096개의 unit과 512차원의 projection layer, 1-2번 layer 사이 residual connection을 갖는 $L=2$ biLSTM을 사용한다.
그 결과 biLM은 각 입력 token마다 순수 문자기반 입력 때문에 학습셋을 벗어나는 것을 포함한, 3개의 layer of representation을 생성한다. 이는 전통적인 단어 embedding이 고정된 단어사전 하에서 token에 대해 단 한개의 layer of representation을 생성하는 것과 대비된다.
1B word Benchmark로 10 epoch만큼 학습시킨 결과 perplexity가 30.0에서 39.7로 크게 늘었다.
일단 기학습된 biLM은 어떤 task에서도 representation을 계산할 수 있다. 대부분의 downstream task에서는 fine-tuned biLM을 사용하였다.
4. 평가(Evaluation)
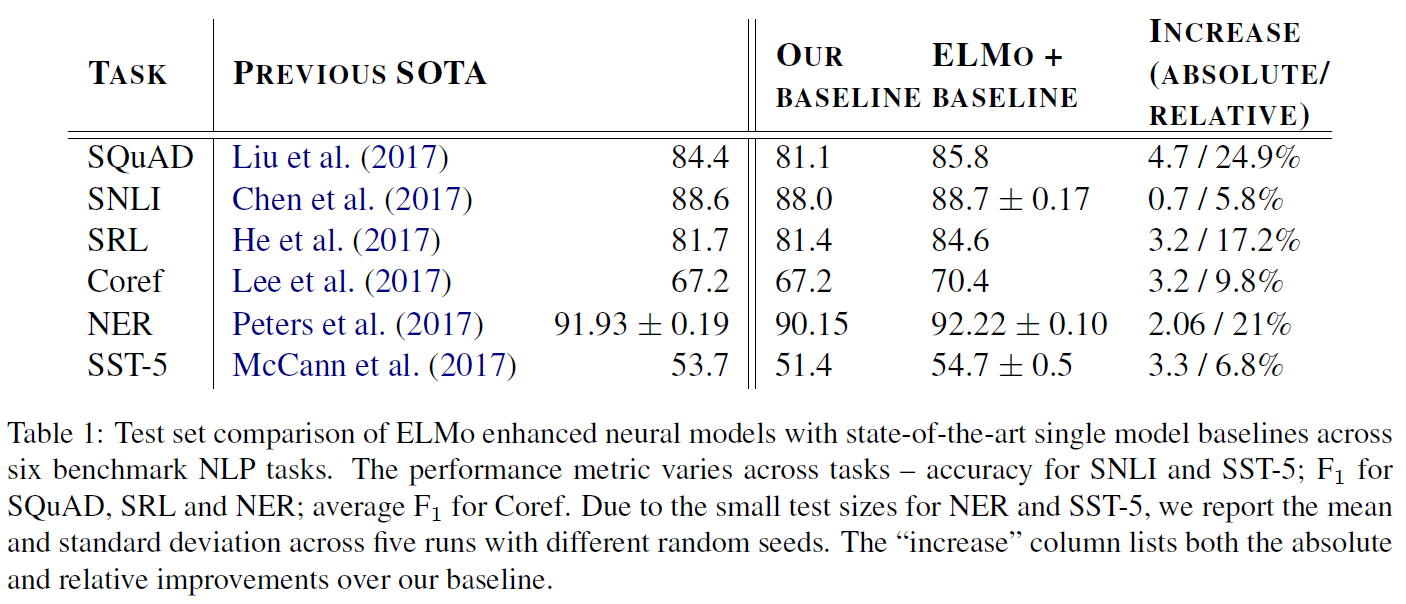
6개의 NLP task에서 에러율을 상대적으로 6~20%만큼 줄였다.
Question Answering 부문에선 SQuAD, Textual Entailment에서는 SNLI 데이터셋을 사용했으며, Semantic role labeling, Coreference resolution, Named entity extraction, Sentiment analysis 등의 task에서도 높은 점수를 기록했음을 볼 수 있다.
데이터셋과 어떤 향상이 있었는지에 대한 정보는 원문을 찾아보면 된다.
5. 분석(Analysis)
이 섹션에서는 특정 부분을 빼거나 교체해서 해당 부분의 역할을 알아보는 ablation 분석을 수행한다.
5.1. Alternate layer weighting schemes
biLM layer를 결합시키는 방법은 매우 다양하다. 또한 정규화 parameter $\lambda$도 매우 중요한 역할을하는데, $\lambda$가 크면(e.g., $\lambda=1$) 가중함수를 단순평균함수로 만들고, 작으면(e.g., $\lambda=0.001$) layer 가중치를 서로 달라지게 한다.
\[\text{ELMo}_k^{task} = E(R_k; \Theta^{task}) = \gamma^{task} \sum_{j=0}^L s_j^{task} h_{k, j}^{LM}\]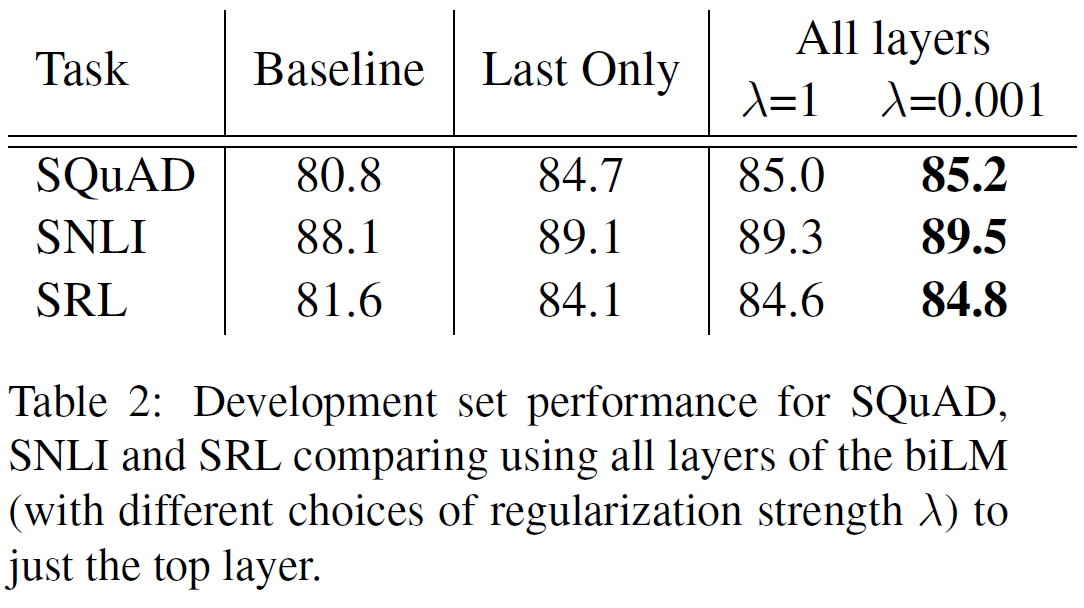
위 결과에서 보듯이 단지 마지막 layer만 쓰는 것보다 모든 layer를 쓰는 것이 더 좋으며, 각각을 단순평균하는 것이 아닌 가중합을 하였을 때(이는 $\lambda$가 작은 것으로 구현됨) 더 성능이 좋아지는 것을 볼 수 있다.
즉 작은 $\lambda$가 ELMo에 도움이 되며 task의 종류에는 크게 영향받지 않는 것 같다.
5.2. Where to include ELMo?
이 논문에서는 단어 embedding을 biRNN의 최하층에만 넣었지만 일부 task에서는 biRNN의 출력에 ELMo를 포함시키는 것이 성능향상을 가져오는 것을 볼 수 있다.
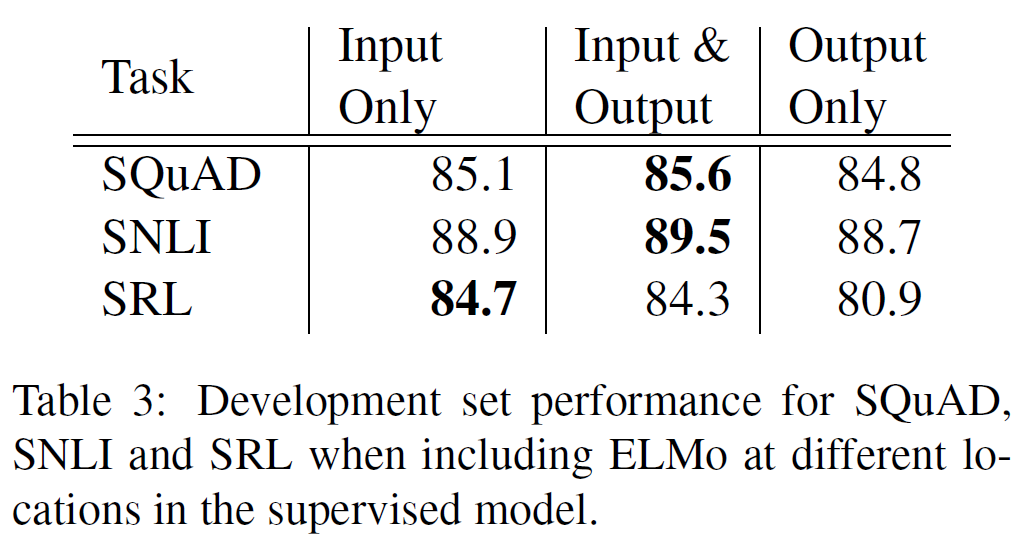
단 위에서 보듯이 모든 경우에 좋은 것은 아니다. SQuAD와 SNLI 모델구성은 biRNN 뒤에 attention layer을 사용하므로 이 layer에 ELMo를 추가하는 것은 biLM의 내부 representatino에 직접 접근할 수 있도록 해 주며 SRL의 경우 task-specific한 문맥 representation이 더 중요하기 때문이라는 설명이 가능하다.
5.3. What information is captured by the biLM’s representations?
ELMo를 추가하는 것만으로 단어 벡터만 있을 때보다 성능이 향상되었기 때문에, biLM의 문맥적 representation은 단어 벡터가 잡아내지 못한 어떤 정보를 갖고 있어야 한다. 직관적으로 biLM은 다의어를 명확화(disambiguation, 다의어의 여러 뜻 중 어떤 의미로 쓰였는지 알아내는 것)한 정보를 갖고 있어야 한다.

위 표에서 GloVe 단어벡터에서 ‘play’ 와 비슷한 단어는 품사를 변형한 것 또는 스포츠에 관한 것만 유사 단어로 뜬다.
그러나 biLM에서는 ‘play’이 비슷한 의미로 쓰인 문장을 유사한 것으로 판단할 수 있음을 알 수 있다.
Word sense disambiguation
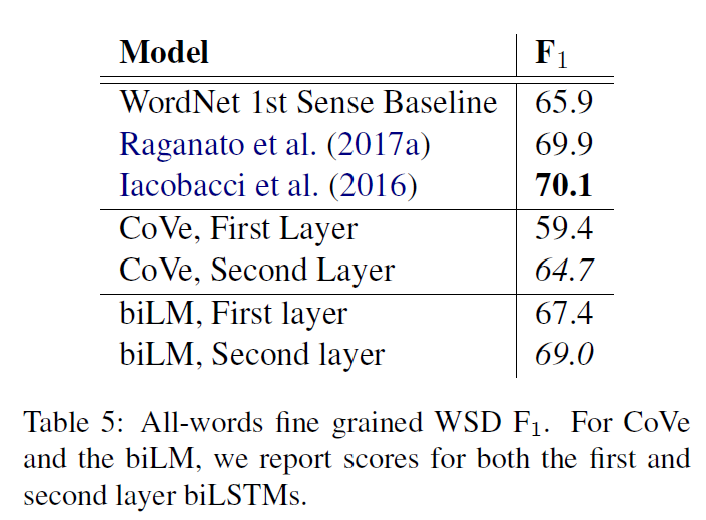
단어 의미 명확화에서 충분히 괜찮은 성능을 보여준다.
POS tagging
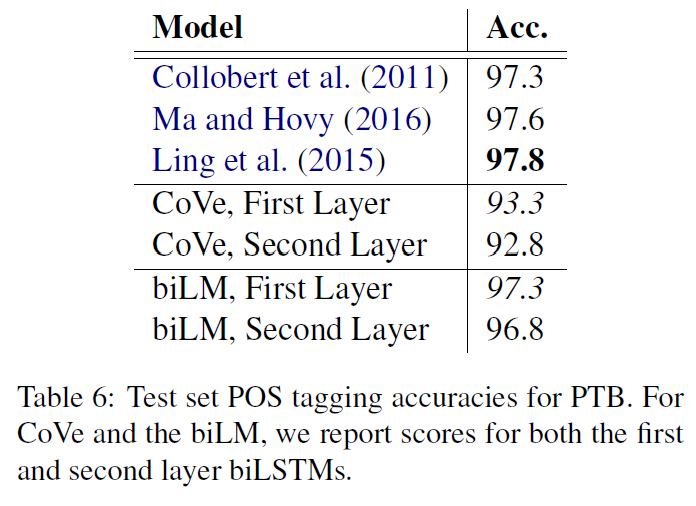
품사 태깅도 꽤 잘 한다고 한다.
Implications for supervised tasks
이러한 실험들은 왜 biLM에서 모든 layer가 중요한지를 알려 준다. 각 layer마다 잡아낼 수 있는 문맥정보가 다르기 때문이다.
5.4. Sample efficiency
ELMo를 추가했을 때는 그렇지 않을 때보다 학습속도도 빠르며(최대 49배 정도) 학습데이터가 적을 때도 훨씬 효율적으로 학습한다.
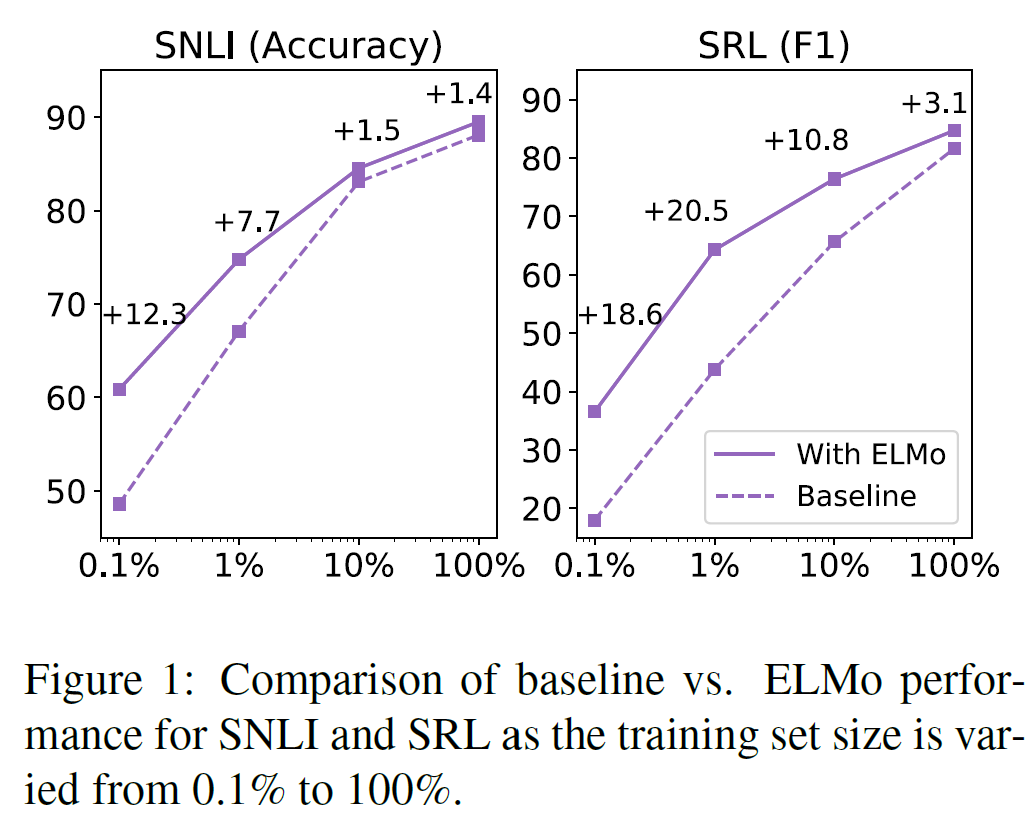
5.5. Visualization of learned weights
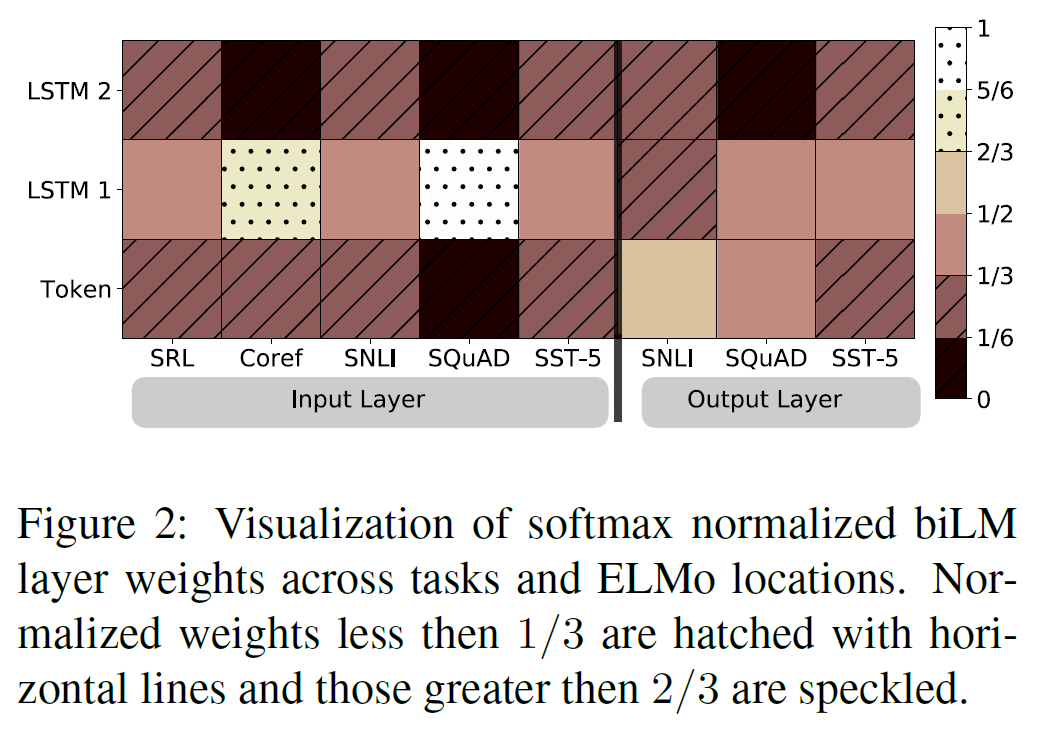
입력 layer에서 task 모델은, 특히 corefenrece와 SQuAD에서 첫번째 biLSTM layer를 선호한다. 출력 layer에서 낮은 레이어에 조금 더 중점을 두지만 상대적으로 균형잡힌 모습을 보여준다.
6. 결론(Conclusion)
이 논문에서는 biLM으로부터 고품질의 깊은 문맥의존 representation을 학습하는 일반적인 방법을 소개했으며, 넓은 범위의 NLP 문제들에서 ELMo를 적용했을 때 많은 성능 향상을 가져오는 것을 보였다. 또한 ablation을 통해 biLM의 모든 layer들이 각각 효율적으로 문맥 정보를 포착하여, 이를 모두 사용하는 것이 좋다는 것을 보였다.
Refenrences
논문 참조. 레퍼런스가 많다.
또한 이 논문이 일부 모듈의 원형으로 삼은 모델들의 구조를 살펴볼 수 있다.
Appendix
부록에서는 $\gamma$의 중요성이나, 각 NLP task에서 ELMo를 붙였을 때 성능 향상이 이루어지는 예시들을 많이 들고 있다. 한번쯤 살펴보자.