
Synthesizer(Rethinking self-attention for transformer models) 요약 설명
17 Aug 2022 | Machine_Learning Paper_Review목차
앞으로 Paper Review 카테고리에는 논문들을 비교적 짧고 가볍게 요약하여 정리하는 글들을 올려보고자 합니다.
첫 타자는 Synthesizer라는 논문입니다.
본 논문은 dot-product based self-attention이 정말 필요한가?에 대한 물음을 던지고 대안을 제시한 논문입니다. 논문에서 dot product self-attention은 sequence 내에서 single token이 다른 token과의 관계에서 갖는 상대적인 중요성을 결정하는 역할을 수행한다고 설명하며 (당연히 맞는 이야기) 이러한 역할은 논문에서 제시하는 구조로도 충분히 달성할 수 있음을 여러 종류의 실험을 통해 증명하고자 노력합니다. token과 token 사이의 interaction을 굳이 고려하지 않고도 fully global attention weight를 통해 충분히 주요 정보를 포착할 수 있다고 이야기 합니다.
굉장히 흥미로운 아이디어이지만 그 구조가 설명에 있어 아쉬운 부분이 많습니다. 일단 논문에서는 크게 2가지 구조를 제안합니다. Dense Synthesizer와 Random Synthesizer가 바로 그것입니다.
대단히 복잡한 식이 아닙니다. 사실 $G$ 함수는 linear transformation 역할을 수행하며 기존의 dot-product attention matrix를 단지 $B$ 라는 parameter matrix로 대체하는 것일 뿐입니다. 이 $B$ 를 계산하기 위해 input token에 의존적으로 학습된다면 이를 Dense Synthesizer라고 하며 어떠한 input token에도 영향 받지 않는 attention weight를 구성한다면 이를 Random Synthesizer라고 합니다. 이 때 이 행렬은 trainable 할 수도 있고, 그저 고정된 상수 값일 수도 있습니다. 논문에서는 행렬을 factorize 한 버전 역시 제시합니다.
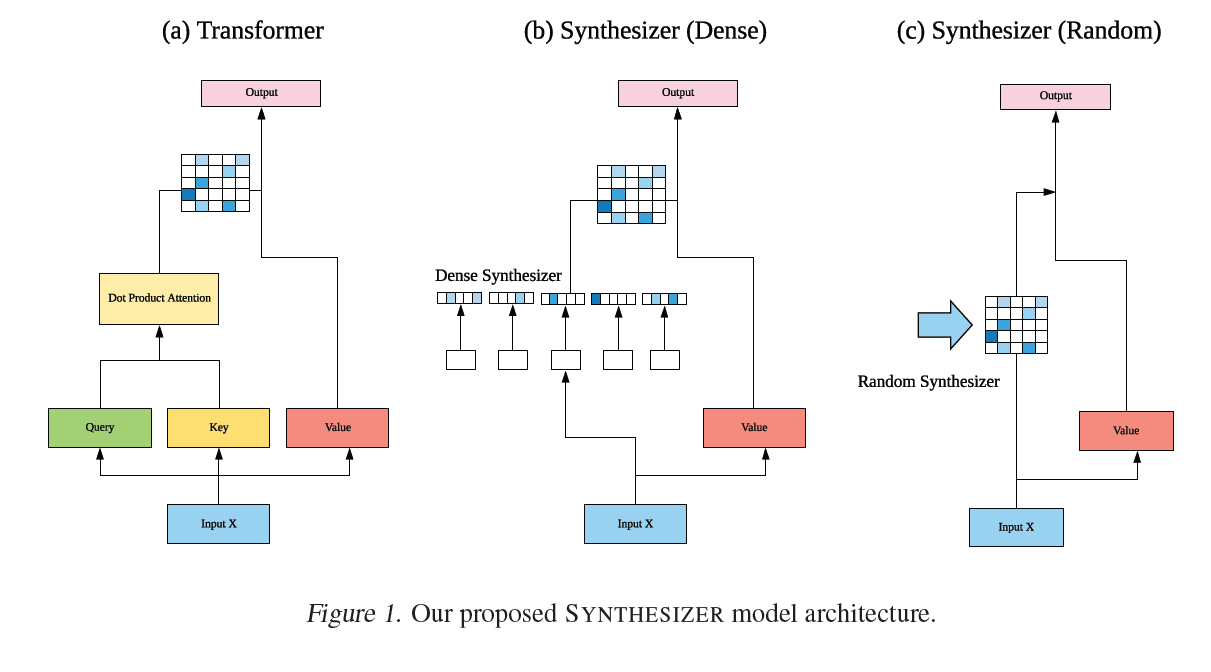
자세한 설명은 글 상단에 있는 youtube 영상을 참고하기를 추천합니다. 실험 부분에 대해 자세히 설명하고 있고, 본 논문의 한계점에 대해 명확하게 설명하고 있습니다.
간단히 이 부분에 대해 언급하면 아래와 같습니다.
- 사실상 synthesizer는 self-attention layer를 feed-forward layer로 치환한 것과 다름 없음
- 언어 구조가 비슷한 언어 간의 번역 task는 이러한 구조가 잘 기능할 가능성이 높은 task이기 때문에 논문에서 제시하는 구조가 과대 평가되었을 가능성이 높음
- 아이디어 자체는 좋지만 실질적으로 어떻게 self-attention layer를 대체할 수 있는지 그 장점이 명확하지 않음. 결국 dot-product self-atttention과 mix 한 것이 성능이 가장 좋다고 나옴