
Fastformer(Additive Attention Can Be All You Need) 요약 설명
18 Aug 2022 | Machine_Learning Paper_Review목차
이번 글에서는 Fastformer 논문에 대해 간략히 다뤄 보겠습니다.
본 논문은 self-attention의 pairwise interaction 모델링 구조가 굳이 필요한 것인가에 대해 의문을 제시하고 중첩된 additive attention 메커니즘을 통해 충분히 경쟁력 있는 모델을 구현할 수 있다고 주장합니다.
논문 도입부에 나온 줄 글만 봤을 때는 복잡한 과정을 거치는 것으로 생각이 들 수 있지만 실제로는 매우 쉬운 연산의 연속입니다.
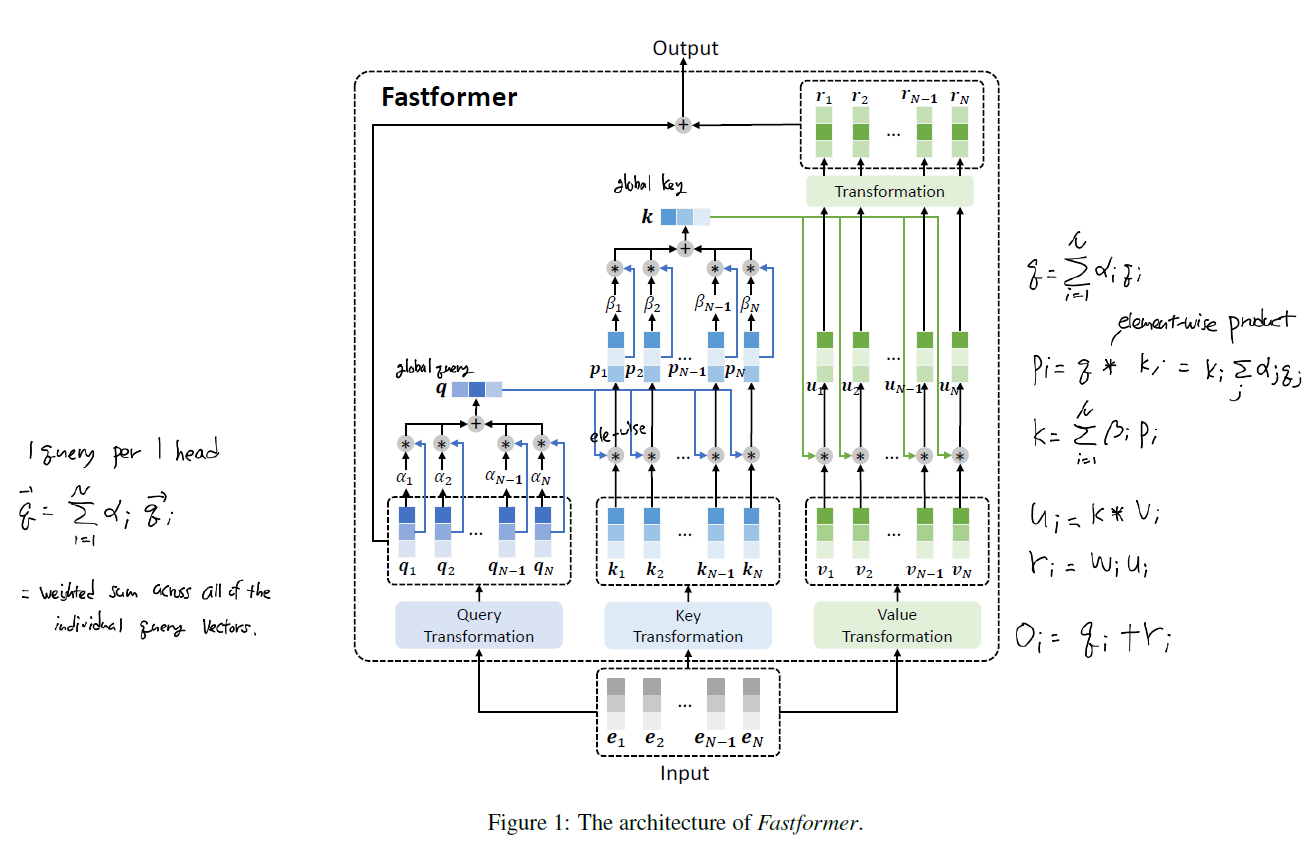
중요 아이디어는 다음과 같습니다.
- 모든 query X key 에 대해 interaction을 계산할 필요가 없다.
- global query vector와 global key vector를 만든 후 이를 value vector 들과 다시 결합하면 충분하다.
- global query 및 key vector는 각 query 혹은 key vector 들의 가중합으로 이루어진다.
global query vector는 아래와 같이 구합니다.
\[\mathbf{q} = \Sigma_{i=1}^N \alpha_i \mathbf{q}_i\] \[\alpha_i = \frac{exp(\mathbf{w}_q^t / \sqrt{d})}{\Sigma_{j=1}^N exp(\mathbf{w}_q^T \mathbf{q}_j / \sqrt{d})}\]그런데 이는 사실 상 self-attention 메커니즘을 구현한 것과 다름 없습니다. 같은 방식으로 global key vector도 구하고 최종적으로 value vector들과 곱합니다. 마지막 output vector를 만들기 이전에 query vector 값들을 다시 더합니다. 이는 일종의 residual connection 역할을 하는 것으로 보이는데 이러한 구조가 만들어진 것에 대한 논리적 설명이 없는 부분은 매우 아쉽습니다.
일단 연산의 구조로 보았을 때 Vanilla Transformer보다 속도는 빠를 가능성이 높다고 추론해 볼 수 있습니다. 논문에서 제시한 실험 결과도 이를 뒷받침합니다. 그리도 만약 token 사이의 순서가 아주 중요하지 않고 일종의 global context가 중요한 역할을 수행하는, 예를 들어 classificaion task에서는 이러한 구조가 더 적합할 수도 있겠다는 판단이 듭니다. 물론 실제 실험을 진행해봐야 아는 부분이겠지만 구현 자체가 까다로운 알고리즘이 아니기 때문에 하나의 옵션으로 고려할 수 있을 것으로 보입니다.
다만 global vector를 생성하는 부분 외에는 특별히 논리적/수식적 근거를 제시하지 않았다는 점과 Fastformer가 잘 통하는 종류의 실험들을 선별한 것이 아닌가 하는 의문이 든다는 점은 아쉬운 부분이라고 할 수 있겠습니다.