
LoRA - Low-Rank Adaptation of Large Language Models 요약 설명
21 Sep 2022 | Machine_Learning Paper_Review목차
이번 글에서는 LoRA: Low-Rank Adaptation of Large Language Models 논문의 핵심 포인트만 간단히 정리한다.
- GPT-3같은 거대한 모델을 fine-tuning하면 그 엄청난 parameter들을 다 재학습시켜야 함 → 이는 계산량도 많고 시간도 꽤 걸리는 부담스러운 작업이다.
- 이를 줄이기 위해
- 원래 parameter는 freeze시키고
- Transformer architecture의 각 layer마다 학습가능한 rank decomposition matrices를 추가하는 방식을 도입하였다(Low-Rank Adaptation).
- 결과적으로
- 메모리는 3배, 파라미터는 10,000배 정도 줄일 수 있었고
- RoBERTA, DeBERTa, GPT-2, GPT-3같은 모델에서 비슷하거나 더 높은 fine-tuning 성능을 보였다.
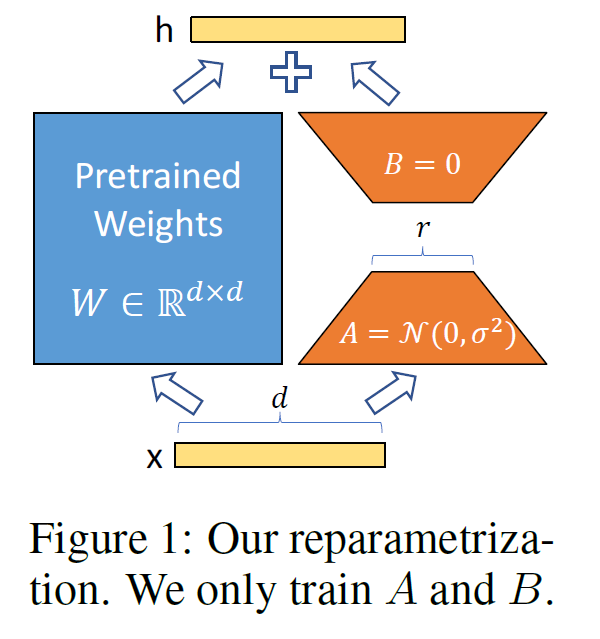
- LoRA의 장점은
- 사전학습된 모델을 그대로 공유하면서 작은 LoRA 모듈을 여럿 만들 수 있다. 모델을 공유하면서 새로 학습시키는 부분(위 그림의 오른쪽에 있는 A, B)만 쉽게 바꿔끼울 수 있다.
- layer에 추가한 작은 matrices만 학습시키고 효율적으로 메모리를 사용할 수 있다.
- inference 과정에서 추가적인 latency 없이 사용할 수 있다.
- 기존의 많은 방법들과도 동시 사용 가능하다.