
AGQA - A Benchmark for Compositional Spatio-Temporal Reasoning 설명
03 Mar 2023 | Machine_Learning Paper_Review목차
- Abstract
- 1. Introduction
- 2. Related Work
- 3. The AGQA benchmark
- 4. Experiments and analysis
- 5. Discussion and future work
- 6. Supplementary
이번 글에서는 AGQA: A Benchmark for Compositional Spatio-Temporal Reasoning 논문을 정리한다.
- 2021년 3월(Arxiv), CVPR 2021
- Madeleine Grunde-McLaughlin, Ranjay Krishna, Maneesh Agrawala
- 홈페이지
- 논문 링크
- Github
Abstract
- Visual event는 object들과 공간적으로(spatially) 상호작용하는 actor들을 포함하는 temporal action들로 구성된다.
- 이를 위해 여러 벤치마크 및 모델들이 개발되었지만 단점들이 많았다.
- 본 논문에서는 compositional spatio-temporal reasoning을 위한, 3배 이상 대규모에 balance까지 맞춘 AGQA benchmark를 제안한다.
- 기존 모델은 47.74%의 정확도밖에 달성하지 못한다. 이 AGQA benchmark는 더 다양하고 더 많은 단계를 거치는 추론 능력 등을 좀 더 광범위하게 테스트할 수 있다.
1. Introduction

(기계와 달리) “사람”은 시각적인 이벤트를 표현할 때 ‘actor가 시간에 따라 주변 물체들과 어떻게 상호작용하는지’를 본다.
위의 비디오를 예로 들면,
- 핸드폰을 (바닥에) 내려놓고(
putting a phone down) - 병을 잡는다(
holding a bottle)- 이 행동은 다시 병을 돌려 열고(
twisting the bottle) - 왼쪽으로 옮기는 행동으로 나눌 수 있다(
shift to holding it)
- 이 행동은 다시 병을 돌려 열고(
이러한 정보들은 Action Genome으로부터 유래한 Scene Graph에서 얻을 수 있으며, AGQA에서는 이 정보들을 갖고 대답할 수 있는, 여러 단계의 추론을 거쳐야 대답할 수 있는 질문-답변을 포함한다.
AGQA의 질문들은 사람이 직접 “program”을 만들어서 정해진 규칙에 따라 생성되도록 설계되었다.
- Charades dataset의 action annotation과
- Action Genome의 spatio-temporal scene graph를 가지고 만들어졌다.
기존 모델로는 PSAC, HME, HRCN을 가지고 실험하였으며
- 학습 떄 보지 못한 새로운 composition을 잘 일반화할 수 있는지
- object를 간접적으로 표현(ex.
object ther were holding last)함으로써 간접적인 추론을 할 수 있는지 - 학습 때보다 더 많은 단계의 추론이 필요한 질문에 대답을 잘 하는지
를 테스트하였다.
일반적으로 추론 단계가 많아질수록 성능이 떨어졌다.
2. Related Work
질문을 생성하기 위해 spatio-temporal scene graphs를 사용하였으며, 새로운 평가 척도를 제안한다.
Image question answering benchmarks: 많이 있지만 어느 것도 외부 지식을 요하는 상식추론 그 이상의 temporal 추론을 다루지 않았다.
Video question answering benchmarks: 이것도 많지만 기존의 데이터셋에 비해 AGQA는 오직 vision에 입각한, 더 대규모의, 더 복잡한 다단계 추론을 평가한다.

Scene graphs: AGQA는 GQA의 pipeline의 일반화 버전이다. spatial relation에 더새 temporal localization까지 활용하였으며 질문을 program에 따라 자동 생성하기 위해 Action Genome의 spatio-temporal scene graph를 사용하였다.
Compositional reasoning: 실세계 영상에서의 복잡한 추론을 다루는 벤치마크가 필요했다. (그게 이 논문이다라는 주장)

3. The AGQA benchmark
- Action Genome의 spatio-temporal scene graphs와 Charades의 action localizations를 symbolic video representation으로 통합하였다.
- 이를 바탕으로 하여 질문을 자동 생성할 수 있는 규칙(program)을 수동으로(handcraft) 만들었다.
- 만들어진 데이터에 대해 bias를 제거하고 balance를 맞췄다.
- 모델이 얼마나 새로운 composition, 간접추론, 더 많은 단계의 추론을 잘 수행하는지 테스트할 수 있는 평가 metric을 만들었다.
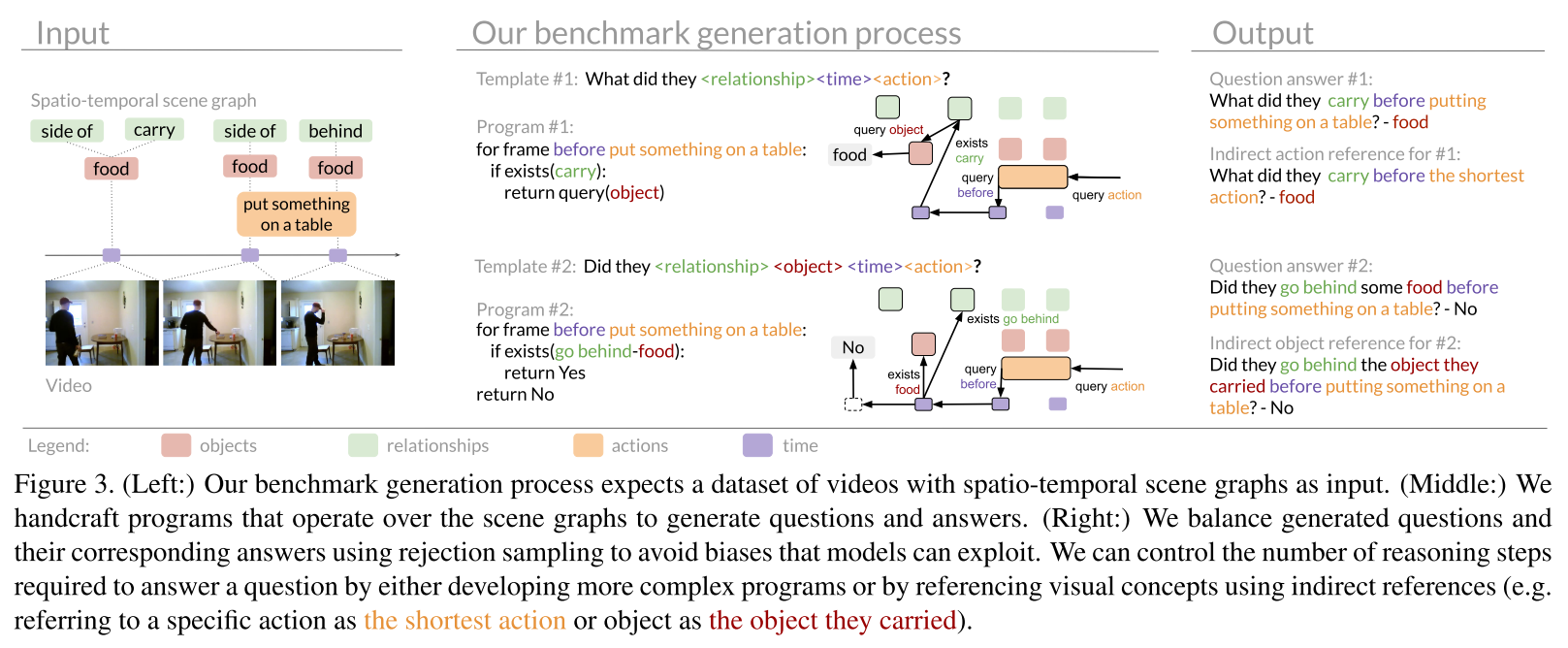
3.1. Augmenting spatio-temporal scene graphs
carrying a blanket and twisting the blanket와 같은 문장의 twisting을 holding이나 touching 등으로 바꾸어 augment를 할 수 있다.
하지만 별 의미없는 문장들, 예를 들면
Were they touching the blanket while carrying the blanket?와 같이 답을 바로 알 수 있거나- 이전 행동이 끝나기 전에 다음 행동이 시작해버리는 경우
등은 co-occurrence 등을 체크하여 생성하지 않도록 했다.
최종적으로 36 objects, 44 relationships, and 157 actions, 7787 training / 1814 test set scene graphs를 확보하였다.
3.2. Question templates
“What did they <relationship><time><action>?와 같은 program을 수동으로 만들어, What did they tidy after snuggling with a blanket?나 What did they carry before putting something on a table?와 같은 질문을 자동으로 생성할 수 있도록 했다.
이 질문에 대답하기 위해서는 put something on a table에 해당하는 action을, 그 action 이전에 일어난 event를, carry 관계가 일어나고 있는 장소를 찾고 그 object이 무엇인지를 찾아야 한다.
결과적으로 269개의 natural language question frames(that can be answered from a set of 28 programs)와, 이 program을 이용하여 192M개의 question-answer 쌍을 만들었다. 이는 45M개의 unique questions, 174개의 unique answers을 포함한다.
3.3. Balancing to minimize bias
program대로 만들 수 있는 질문들을 전부 생성해보면 특정 형태의 질문들이 거의 대부분을 차지하게 된다. 이렇게 생기는 bias를 줄이기 위해 질문의 특성에 따라 비율을 강제로 맞춰줌으로써 전체 데이터셋의 balance를 맞추고자 했다.
Question reasoning type, Question Semantics, Question structures 등에 따라 비율을 맞췄고, 각 type에 따른 비율은 아래 그림에 정리되어 있다.

3.4. New compositional spatio-temporal splits
평가를 위해 새로운 split을 몇 개 제안한다.
- Novel compositions를 평가하기 위해 training set에는 존재하지 않고 test set에만 나타나는 concept pair를 따로 선택하였다.
- Indirect references을 위해서는 object나 action 등이 간접적인 방식으로 표현되었을 때(ex.
blanket -> the object they threw) 모델이 잘 대답하는지를 측정하는 metric이 있다. - More compositional steps: $M$개 이하의 추론 단계를 포함하는 질문과 $M$ 이상의 단계를 포함하는 질문을 나누어 모델이 각각에 대해 얼마나 잘 대답하는지를 측정한다.
4. Experiments and analysis
- 사람이 AGQA의 답변에 얼마나 동의하는지를 체크하여 데이터셋이 올바른지 평가하고
- AQGA에 기존 SOTA QA 모델을 테스트해 보고
- spatio-temporal reasoning, different semantics, each structural category에서 잘 동작하는지 체크하고
- 모델이 얼마나 novel compositions, indirect references, more compositional steps에 대해 일반화를 잘 하는지를 실험한다.
- 모든 실험은 AGQA의 balanced version에 대해서 이루어졌다.\
- 사용한 모델은
- PSAC(positional self-attention and co-attention blocks),
- HME(memory modules for visual and question features and then fuses them together),
- HCRN(a current best model, stacks a reusable module into a multi-layer hierarchy, integrating motion, question, and visual features at each layer)이다.
- “Most-Likely”(가장 빈도수가 높은 답만 찍는 모델)와도 성능 비교를 수행하였다.
4.1. Human evaluation
AMT로 “사람”에게 테스트를 시켜 보았더니 AGQA 데이터 중 86.02%를 정답으로 인정하였다. 에러가 13.98% 있다는 것인데 이는 대체로 scene graph나 relationship의 오류 또는 모호성으로 인한 것으로 추측된다. 대략 이 정도면 AGQA 데이터셋이 믿을 만한 정도라는 뜻이다.
4.2. Performance across reasoning abilities
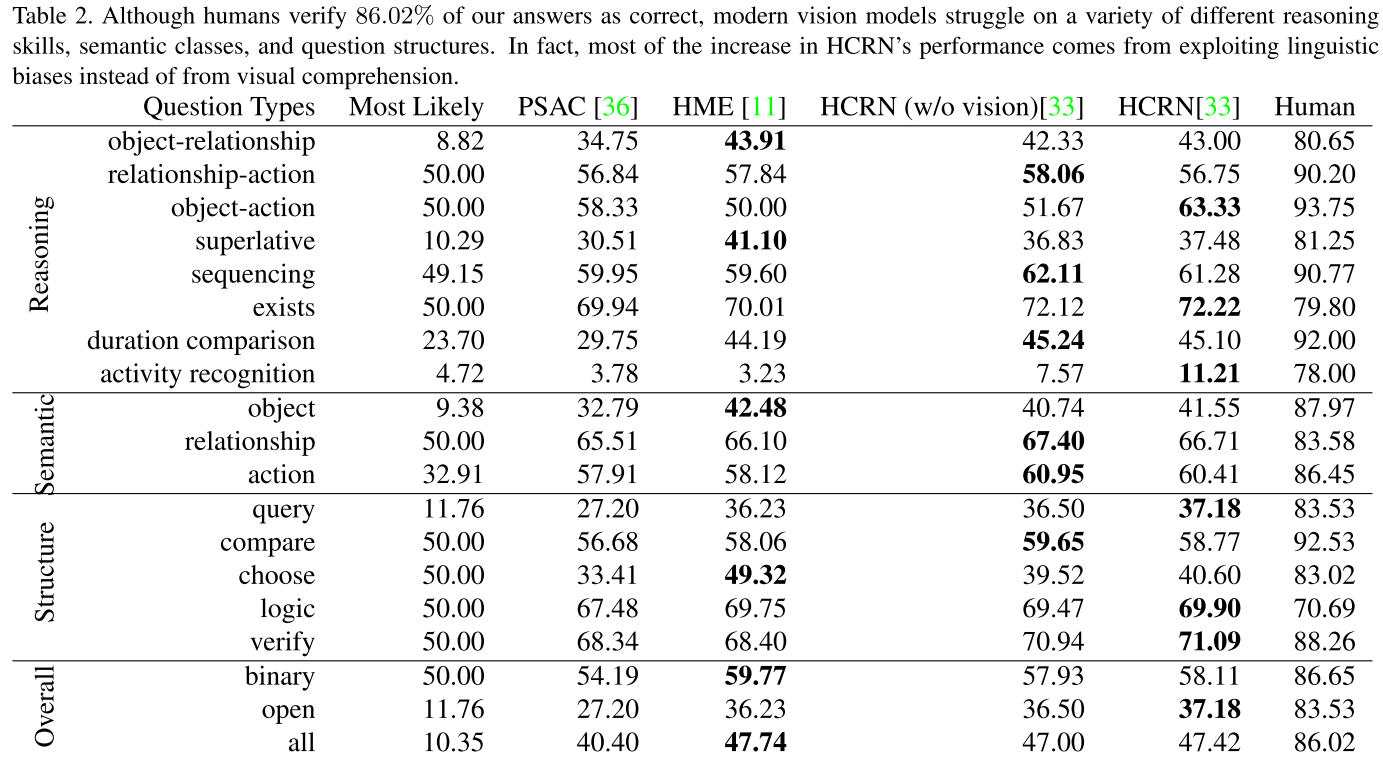
PSAC는 성능이 별로고, HME는 superlative에 대해 묻는 질문에서 가장 좋은 성능을, HCRN은 sequencing이나 activity recognition 등에서 괜찮은 성능을 보였다.
그러나 HCRN은 visual 정보를 써도 language-only 모델에 비해 성능이 겨우 1.5%밖에 높지 않았다.
4.3. Performance across question semantics
HCRN은 object 주위에 대한 질문 정도만 language-only에 비해 성능이 좋지만 object와 연관된 질문은 대체로 3개 모델 모두에게 어려운 질문이다.
4.4. Performance across question structures
질문 구조가 달라지면 더 어려워진다. HCRN은 language-only에 비해 겨우 0.68% 높은 성능을 보인다. 즉 visual 정보를 거의 활용하지 못하고 있다.
4.5. Generalization to novel compositions
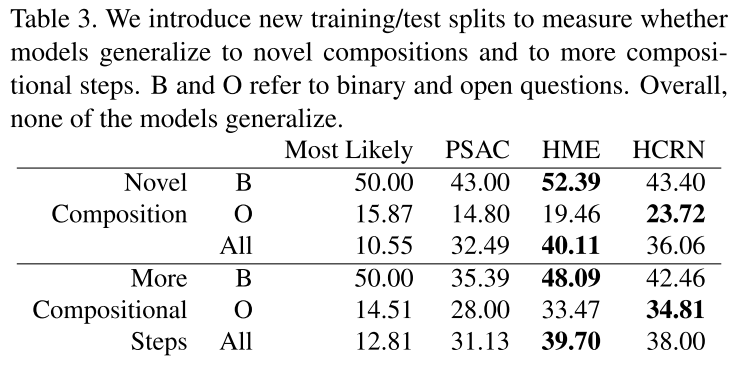
3개 모델 모두 학습 때 보지 못했던 구성에 대해 어려워하는 모습을 보인다. 심지어 가장 빈도수 높은 답만 찍는 “Most-Likely”를 능가하는 것은 HCRN(52.39%) 뿐이었다.
그리고 모델들은 대체로 새로운 object나 relationship을 포함하는 새로운 composition에 대해 매우 낮은 성능을, 새로운 action의 길이에 대한 추론에서는 좋은 성능을 보였다.
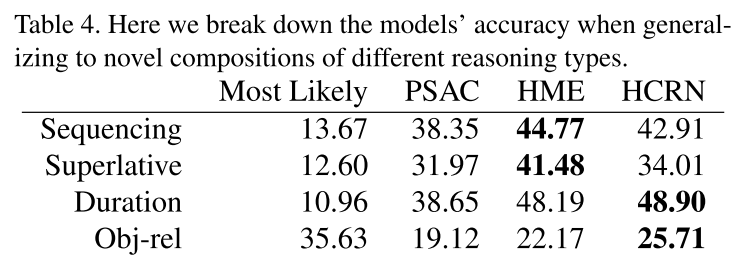
4.6. Generalization to indirect references
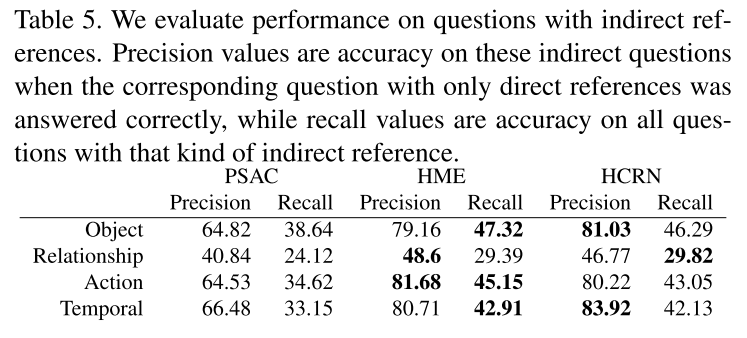
HCRN이 좀 낫기는 하지만 여전히 모델들은 direct한 질문에는 잘 대답해도 indirect한 질문에는 잘 대답하지 못한다.
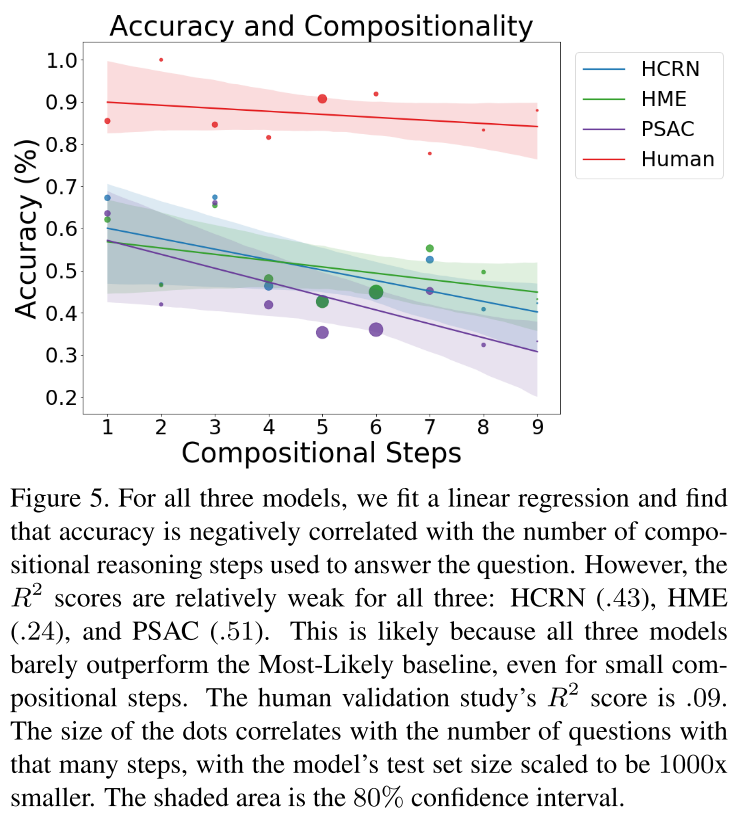
4.7. Generalization to more compositional steps
복잡한 구조를 갖는 (추론 단계가 많은) 질문에 대해서는 50%도 안되는, 찍기보다 못한 성능을 보여준다. 특히 단계가 많아질수록 성능이 전반적으로 하락하는 경향을 보인다.
5. Discussion and future work
- AGQA는 novel compositions, indirect references, more compositional steps를 측정할 수 있는, 기존의 것보다 3배 이상 큰 데이터셋이자 벤치마크이다.
- 더 좋은 성능을 보일 수 있을 것 같은 방법론은:
- Neuro-symbolic and semantic parsing approaches(training questions에서 systematic rule를 추출할 수 있는 핵심 모듈이 없었다)
- Meta-learning and multi-task learning(숨겨진 compositional rule을 파악할 수 있는 옵션이 될 것이다)
- Memory and attention based approaches(HME는 더 많은 단계를 갖는 질문에서 그나마 나았는데 이는 question feature를 처리할 때 사용하는 explicit memory에 의한 것 같다)
- 등이 있을 것 같다.