
Adapting-large-language-models-to-domains-via-reading-comprehension 요약 설명
17 Jan 2025 | Machine_Learning Paper_Review목차
이번 글에서는 AdaptLLM: Adapting-large-language-models-to-domains-via-reading-comprehension 논문의 핵심 포인트만 간단히 정리한다.
- 2023년 7월(Arxiv), ICLR 2024
- Daixuan Cheng, Shaohan Huang B & Furu Wei.
- Microsoft Research,Beijing Institute for General Artificial Intelligence (BIGAI)
- 논문 링크
- Github
- Huggingface
요약
- Domain-specific corpora에서 pre-training 하는 것은 모델이 해당 domain에 대한 지식을 학습할 수 있도록 해 주지만, 반대로 해당 domain 외 일반적 task, 또는 prompting 능력을 저하시킬 수 있다.
- 이 논문에서는
- 해당 사실을 발견하여, 이를 해결할 수 있는 방법으로
- raw corpora를 reading comprehension text로 변환시켜 해당 데이터로 학습하는 과정을 통해 prompting 성능을 떨어뜨리지 않으면서도 domain-specific 지식을 학습하는 방법을 제안한다.
- 결과적으로
- biomedicine, finance, law 3가지 분야에서 보다 큰 모델과 비슷한 수준의 성능을 확보하였고 (특히, finance에서는 BloombergGPT와 비슷한 수준의 성능을 보였다)
- 그러면서도 일반적 성능이 떨어지지 않음을 실험을 통해 보였다.
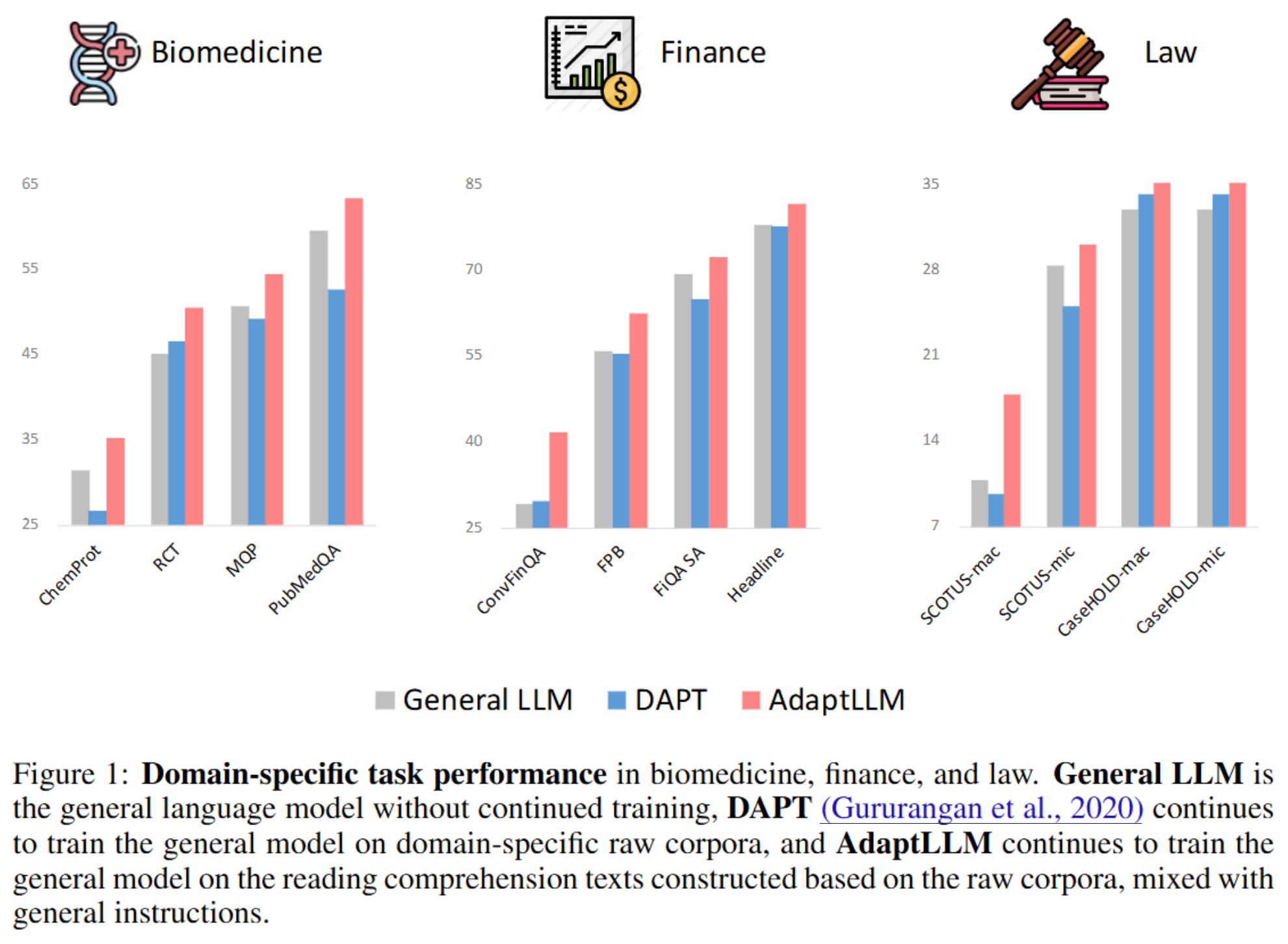
- 논문의 핵심 내용은 위의 요약과 같다.
- 남은 중요한 부분은 raw corpora를 reading comprehension text로 변환시키는 방법에 대한 부분인데,
- 아래 figure 02처럼 $-$ 그냥 평범한 글을, 특정한 regex expression에 맞는 부분이 있으면 그것을 일종의 QA task처럼 바꾸는 과정이다.
- 이렇게 생성된 task들을 해당 domain에 맞는 데이터로 학습시키면 해당 domain에 대한 지식을 학습할 수 있게 된다.
- 생성한 task는 보통의 QA task와 비슷하므로, 그냥 raw corpora를 학습시키는 것에 비해 모델이 원래 가지고 있던 instruction-following 능력을 저하시키지 않는다.
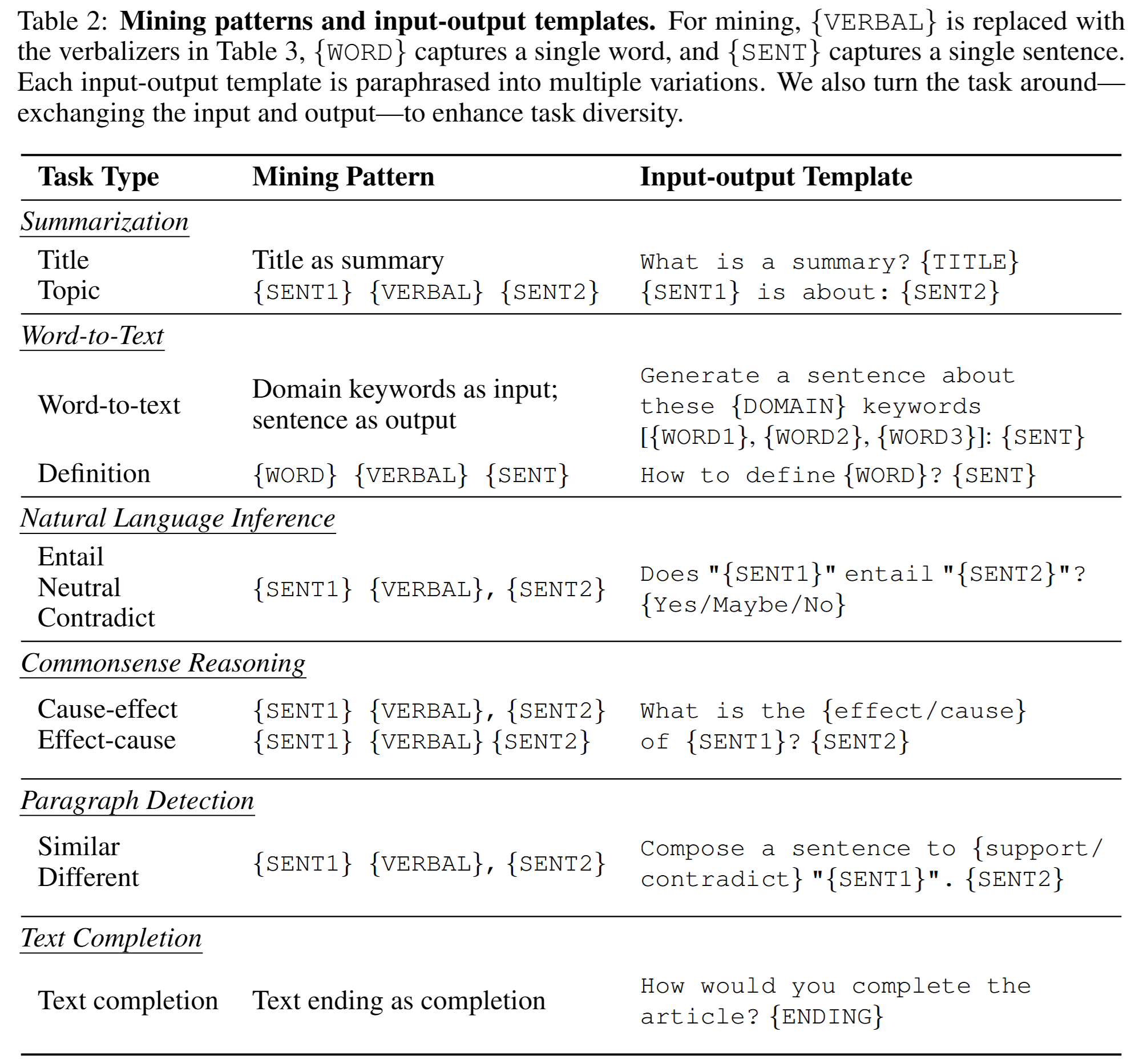
- 발굴한 task들은 요약, 특정 주제에 대한 문장 생성, 추론, 문단 완성 등이 있다.

- 전체 pattern은 아래 table 02와 같다.
- 코멘트. 간단한 방식으로 raw corpora를 reading comprehension task로 변환시키는 방법이 매우 흥미롭다.