
Self-Supervised Learning(자기지도 학습 설명)
01 Nov 2020 | Self-Supervised Learning Paper_Review Unsupervised Learning목차
- Self-Supervised Learning
- Image Representation Learning
- Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks
- Unsupervised Visual Representation Learning by Context Prediction
- Unsupervised Learning of Visual Representations using Videos
- Joint Unsupervised Learning of Deep Representations and Image Clusters
- Colorful Image Colorization
- Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles
- Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion
- Self-supervised learning of visual features through embedding images into text topic spaces
- Colorization as a Proxy Task for Visual Understanding
- Learning Image Representations by Completing Damaged Jigsaw Puzzles
- Unsupervised Representation Learning by Predicting Image Rotations
- Cross-Domain Self-supervised Multi-task Feature Learning using Synthetic Imagery
- Self-Supervised Representation Learning by Rotation Feature Decoupling
- Unsupervised Deep Learning by Neighbourhood Discovery
이 글에서는 Self-Supervised Learning(자기지도 학습)에 대해 알아본다. Self-Supervised Learning은 최근 Deep Learning 연구의 큰 트렌드 중 하나이다.
Self-Supervised Learning의 기본적인 개념과 여러 편의 논문을 간략히 소개하고자 한다.
Self-Supervised Learning
일반적으로 Supervised Learning(지도학습)이 높은 성능의 모델을 만드는 것이 유리하지만, 수많은 데이터에 label을 전부 달아야 한다는 점에서 데이터셋 모으기가 어려우며 따라서 활용하는 방법도 제한적일 수밖에 없다.
이와 같은 문제를 해결하고자 나온 방법이
- 아주 일부분만 label이 존재하는 데이터셋을 사용하는 Semi-Supervisd Learning(준지도 학습)
- label이 전혀 없는 데이터셋을 사용하는 Unsupervised Learning(비지도 학습)
이고, 최근 주목받는 연구 방법이 Self-Supervised Learning(자기지도 학습)이다. 보통 Self-Supervised Learning을 연구할 때, 다음과 같은 과정을 따른다:
- Pretext task(연구자가 직접 만든 task)를 정의한다.
- Label이 없는 데이터셋을 사용하여 1의 Pretext task를 목표로 모델을 학습시킨다.
- 이때, 데이터 자체의 정보를 적당히 변형/사용하여 (label은 아니지만) 이를 supervision(지도)으로 삼는다.
- 2에서 학습시킨 모델을 Downstream task에 가져와 weight는 freeze시킨 채로 transfer learning을 수행한다(2에서 학습한 모델의 성능만을 보기 위해).
- 그래서 처음에는 label이 없는 상태에서 직접 supervision을 만들어 학습한 뒤, transfer learning 단계에서는 label이 있는 ImageNet 등에서 Supervised Learning을 수행하여 2에서 학습시킨 모델의 성능(feature를 얼마나 잘 뽑아냈는지 등)을 평가하는 방식이다.
여기서 Self-Supervised Learning의 이름답게 label 등의 직접적인 supervision이 없는 데이터셋에서 스스로 supervision을 만들어 학습하기 때문에, supervision이 전혀 없는 Unsupervised Learning의 분류로 보는 것은 잘못되었다는 시각이 있다.
I now call it “self-supervised learning”, because “unsupervised” is both a loaded and confusing term. In self-supervised learning, the system learns to predict part of its input from other parts of it input. In other words a portion of the input is used as a supervisory signal to a predictor fed with the remaining portion of the input. Self-supervised learning uses way more supervisory signals than supervised learning, and enormously more than reinforcement learning. That’s why calling it “unsupervised” is totally misleading. That’s also why more knowledge about the structure of the world can be learned through self-supervised learning than from the other two paradigms: the data is unlimited, and amount of feedback provided by each example is huge. Self-supervised learning has been enormously successful in natural language processing. For example, the BERT model and similar techniques produce excellent representations of text. BERT is a prototypical example of self-supervised learning: show it a sequence of words on input, mask out 15% of the words, and ask the system to predict the missing words (or a distribution of words). This an example of masked auto-encoder, itself a special case of denoising auto-encoder, itself an example of self-supervised learning based on reconstruction or prediction. But text is a discrete space in which probability distributions are easy to represent. So far, similar approaches haven’t worked quite as well for images or videos because of the difficulty of representing distributions over high-dimensional continuous spaces. Doing this properly and reliably is the greatest challenge in ML and AI of the next few years in my opinion. - Yann Lecun
게시물을 보면 예전에는 이러한 학습 방식을 “주어진” supervision이 없기 때문에 Unsupervised Learning이라 불렀지만, 사실은 모델이 “스스로” supervision을 만들어 가며 학습하기 때문에 Self-Supervised Learning이라 부르는 것이 맞다고 설명하는 내용이다.
그리고 (label은 없어도) 데이터는 무궁무진하며, 그로부터 얻을 수 있는 feedback 역시 엄청나기 때문에 “스스로” supervision을 만드는 Self-Supervised Learning 방식이 매우 중요하게 될 것이라고 언급한다.
Image Representation Learning
Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks
NIPS 2014

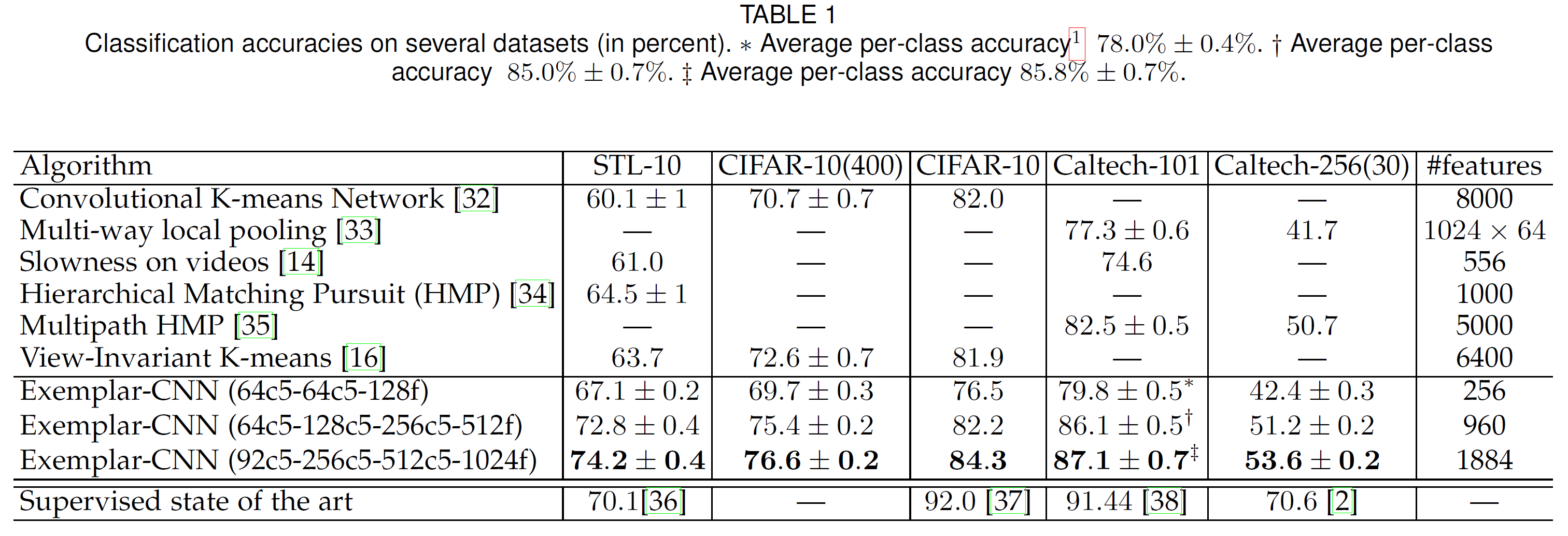
이 논문에서는 Examplar를 pretext task로 한 Examplar-CNN이라고 하는 모델을 소개한다.
$N$개의 이미지에서 중요한 부분, 정확히는 considerable gradients를 가지고 있는 32 $\times$ 32 크기의 patch를 하나씩 추출한다(Gradient 크기의 제곱에 비례하는 확률로 patch를 선정함). 이렇게 추출한 Seed patch를 갖고 여러 가지 data augmentation을 진행한다. 위 그림의 오른쪽에서 볼 수 있듯이 translation, scaling, rotation, contrast, color 등을 이동하거나 조정하여 만든다.
분류기는 Data augmentation으로 얻어진 patch들은 하나의 class로 학습해야 한다. 여기서 Loss는 다음과 같이 정의된다.
\[L(X) = \sum_{\text{x}_i\in X} \sum_{T \in T_i} l(i, T\text{x}_i)\]$l(i, T\text{x}_i)$은 Transformed sample과 surrogate true lable $i$ 사이의 loss를 의미한다. 즉 하나의 이미지가 하나의 class를 갖게 되는데, 이는 데이터셋이 커질수록 class의 수도 그만큼 늘어난다는 문제를 갖고 따라서 학습하기는 어렵다는 단점을 안고 있다.
아래는 실험 결과이다.
Unsupervised Visual Representation Learning by Context Prediction
ICCV 2015
이 논문에서는 context prediction 종류의 pretext task를 제안하는데, 간단하게 말하면 이미지에 $ 3 \times 3 = 9$개의 patch를 가져와, 중간 patch와 다른 1개의 patch를 보여 주고, 다른 1개의 patch가 중간 patch의 어느 뱡향(왼쪽 위, 위, 오른쪽 등 8방향)에 위치하는지를 찾는 문제이다. 아래 그림을 보면 이해가 빠를 것이다:
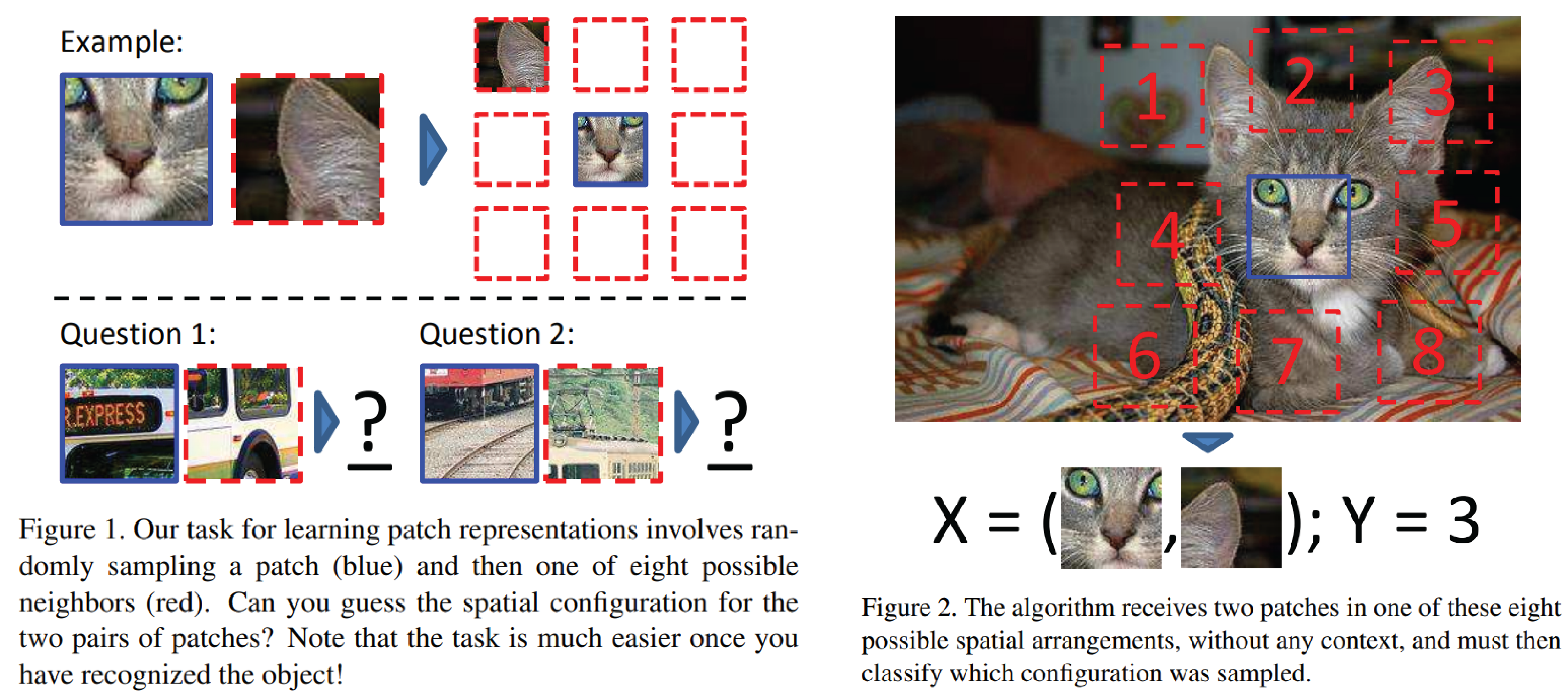
위 그림에서 무엇이 정답인지 보기
Answer key: Q1: Bottom right Q2: Top center
두 장의 이미지를 한 번에 입력으로 받아야 하기 때문에 아래와 같이 patch를 받는 부분을 두 부분으로 만들었다.
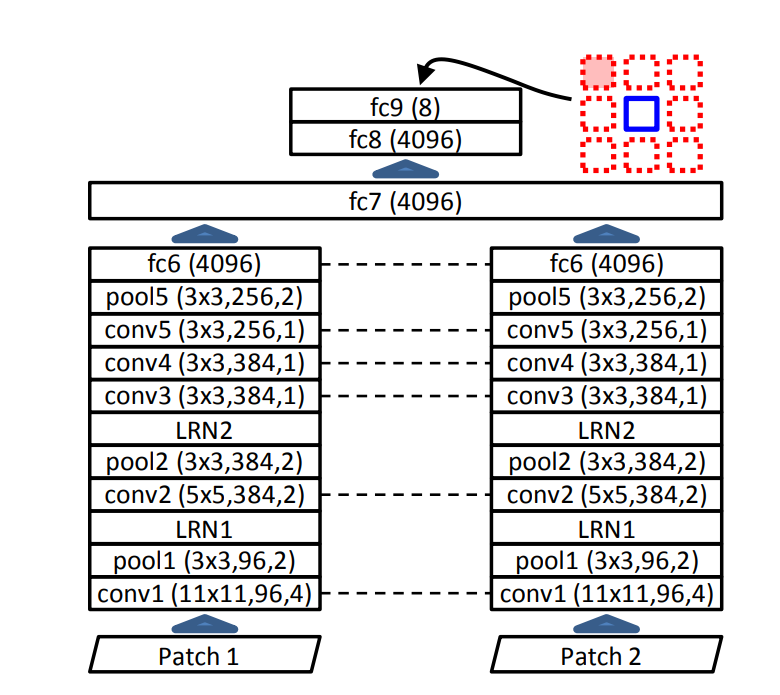
그리고 “자명한” 해를 쉽게 찾을 것을 방지하기 위해, 9개의 patch들이 딱 붙어 있지 않도록 하였으며 중심점의 위치도 랜덤하게 약간 이동하여 patch를 추출하여 자명한 경우를 최대한 피하고자 하였다(하지만 충분치는 않았다고 한다).
아래는 실험 결과이다.
Unsupervised Learning of Visual Representations using Videos
ICCV 2015
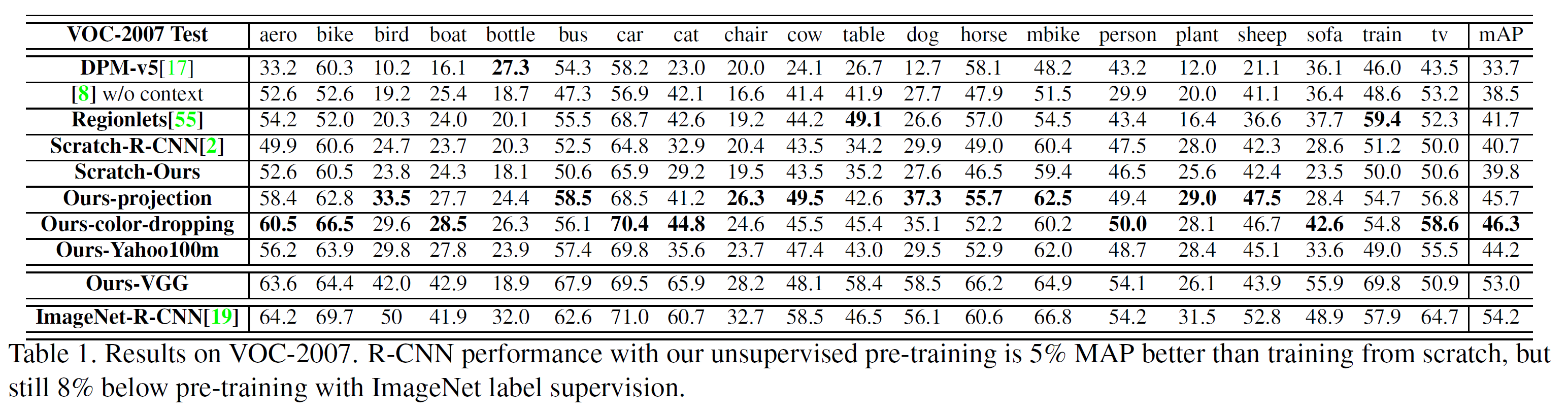
CNN에 의미적으로 레이블링된(semantically-labeled) 것이 꼭 필요한지 의문을 가지며 출발하는 이 논문은 시각적 표젼(visual representatinos)을 학습하기 위해 레이블이 없는 십만 개의 영상을 웹에서 가져와 사용하였다. 핵심 아이디어는 visual tracking이 supervision을 준다는 것이다. track으로 연결된 두 개의 패치는 같은 물체나 그 일부분을 포함할 것이기에, deep feature space에서 비슷한 시각적 표현을 갖고 있을 것이라 생각할 수 있다. 이러한 CNN 표현을 학습하기 위해 ranking loss function을 사용하는 Siamese-triplet 네트워크를 사용한다.
ImageNet에서 단일 이미지를 가져오는 대신 레이블이 없는 10만 개의 영상과 VOC 2012 dataset을 사용하여 비지도 학습을 수행, 52% mAP를 달성하였다. 이는 지도학습을 사용한 ImageNet 기존 결과의 54.4% mAP에 거의 근접하는 수치이다.
또한 이 논문은 surface-normal 추정 문제와 같은 것도 충분히 잘 수행함을 보여준다.
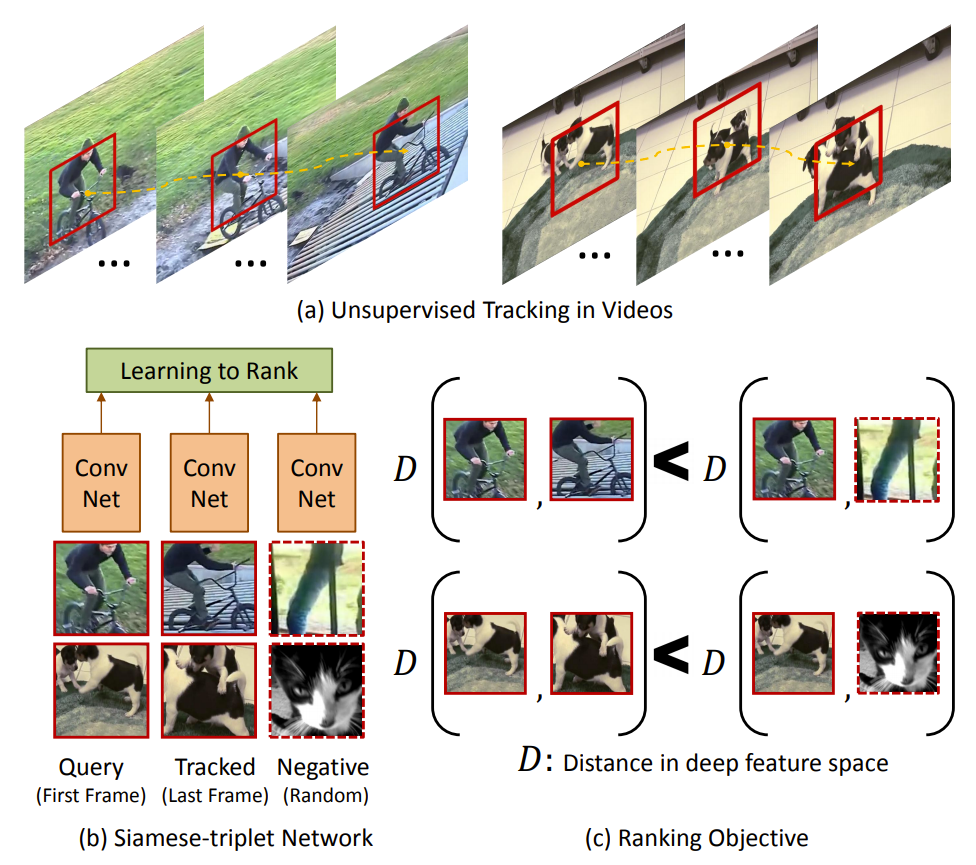
- (a) 레이블이 없는 영상이 주어지면 그 안에서 비지도 tracking을 수행한다.
- (b) 첫 frame에서 Query 패치, 마지막 frame에서 추적하는 patch, 다른 영상에서 가져온 무작위 패치로 구성된 총 3개의 패치가 siamese-triplet 네트워크에 입력으로 들어가 학습된다.
- (c) 학습 목표: Query 패치-추적된 패치 사이의 거리가 Query 패치-무작위 패치 사이의 거리보다 더 작게 되도록 학습한다.
Joint Unsupervised Learning of Deep Representations and Image Clusters
CVPR 2016
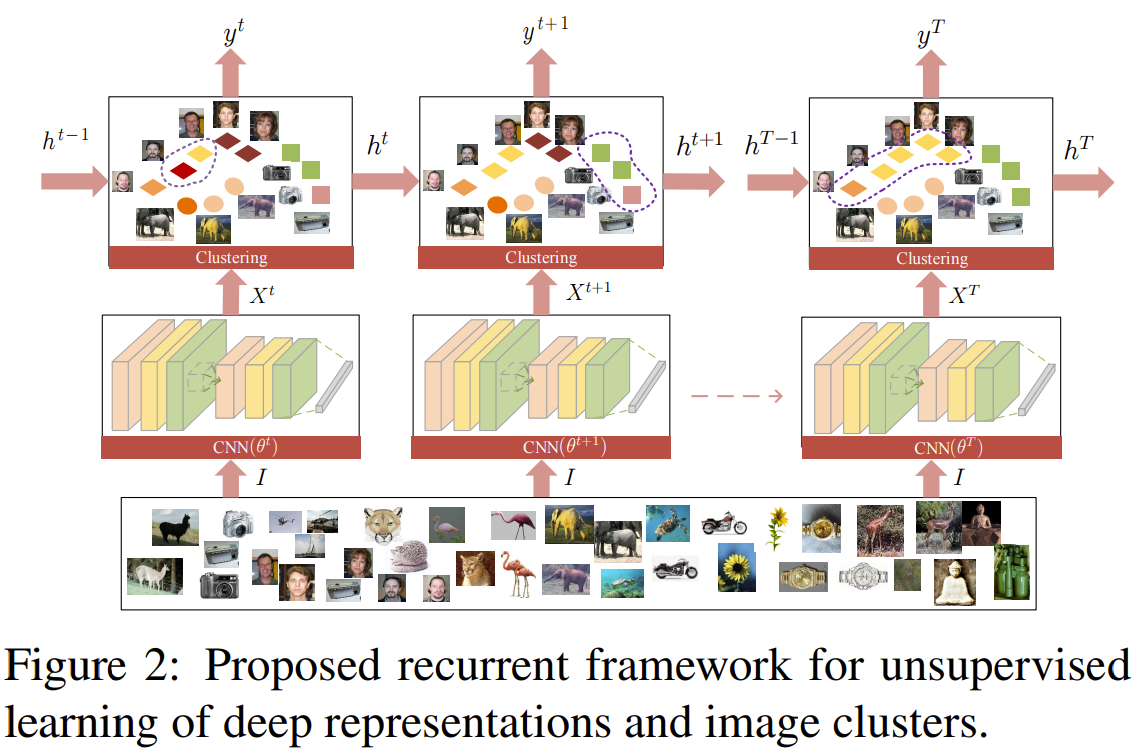
JULE는 deep representations와 image cluster의 Joint Unsupervised LEarning을 위한 recurrent framework를 말한다. 이 framework에서, clustering 알고리즘에서 연속적인 동작이 recurrent process의 한 스텝으로 표현되어, CNN의 representation 출력의 위에 쌓아지는 형태를 갖는다. 학습하는 동안, image clusters와 representations는 공동으로 업데이트된다: image clustering은 forward pass로, representation 학습은 backward pass로 수행된다.
좋은 표현은 image clustering에 유익하며, 그 결과는 representation 학습에 지도를 해 줄 수 있을 것이라는 것이 핵심 부분이다. 두 과정을 하나의 모델에 통합하여 합쳐진 가중 triplet loss를 사용하여 end-to-end 방식으로 최적화했기에, 더 강력한 표현뿐만 아니라 더 정확한 image cluster도 얻을 수 있다.
여러 실험은 이 방법이 여러 데이터셋에서 image clustering을 할 때 기존 SOTA를 뛰어넘는다는 것을 보여준다.

Colorful Image Colorization
ECCV 2016
이 논문에서는 회색조 이미지가 입력으로 주어지면 적절히 색깔을 입혀 그럴 듯한 컬러 이미지로 바꾸는 작업을 수행한다. 이 문제는 명백히 제약조건이 부족하기 때문에, 기존 접근법은 사용자와 상호작용하거나 채도를 감소시킨 채색에 의존하였다.
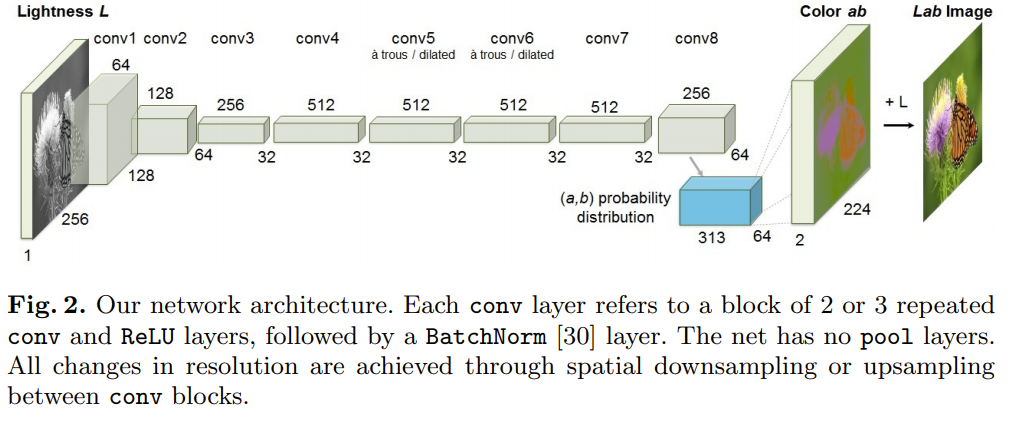
여기서는 선명하고 사실적인 채색 결과를 도출하는 완전히 자동화된 접근법을 제시한다. 저자들은 이 문제에 내재하는 불확실성을 포용하여 이 문제를 분류 문제로 생각하고 채색 결과의 색깔 다양성을 증가시키기 위해 학습 시간에서 class별 rebalancing을 사용한다. 시스템은 CNN에서 feed-forward pass로 구성된다.
결과는 ‘채색 튜링 테스트(colorization Turing test)’으로 평가하는데, 사람 지원자에게 실제 이미지와 생성된 이미지 중 어떤 것이 실제 이미지인지 판별하도록 하였다. 결과는 32%가 답을 틀렸다는 점에서 이전 방법에 비해 매우 뛰어난 결과를 보여준다.
더욱이, 채색이라는 문제가 cross-channel encoder로서 기능하는 self-supervised feature 학습을 위한 강력한 pretext task로 기능할 수 있음을 보였다.
아래에서 채색(colorization) 결과를 확인할 수 있다. 꽤 뛰어난 결과를 보여준다.

전체 모델 구조는 아래와 같다.
Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles
ECCV 2016
이 논문은 직소 퍼즐처럼 이미지에 9개의 patch를 만들어 순서를 뒤섞은 뒤 원래 배치를 찾아내는 문제를 pretext task로 지정하였다. 대부분은 너무 비슷한 순열이기 때문에 딱 100개의 순열만을 지정하여 이를 분류하는 것을 목표로 한다.

다른 문제 간 호환성을 위해 context-free network(CFN, siamese-enread CNN)을 사용하였다. 이미지 패치를 입력으로 하고 CFN은 AlexNet에 비해 적은 parameter를 가지면서 동일한 의미 학습 능력을 유지한다고 한다.
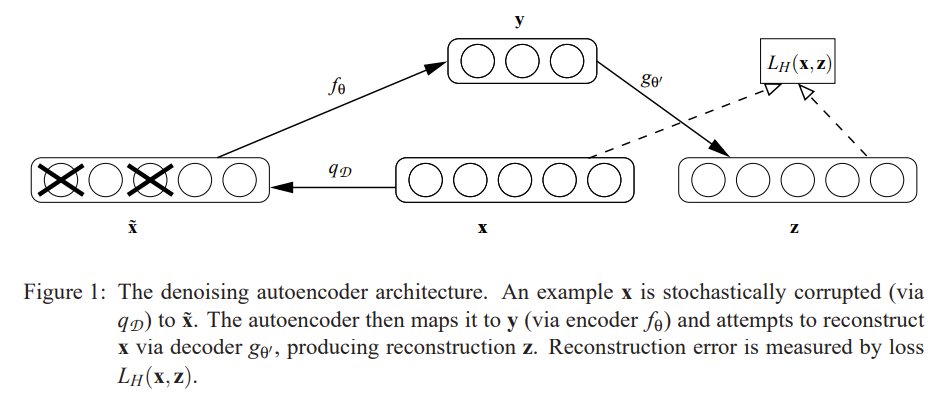
Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion
입력 이미지에 무작위 noise를 추가한 뒤 원래 이미지를 복원하는 것을 pretext task로 지정하였다.
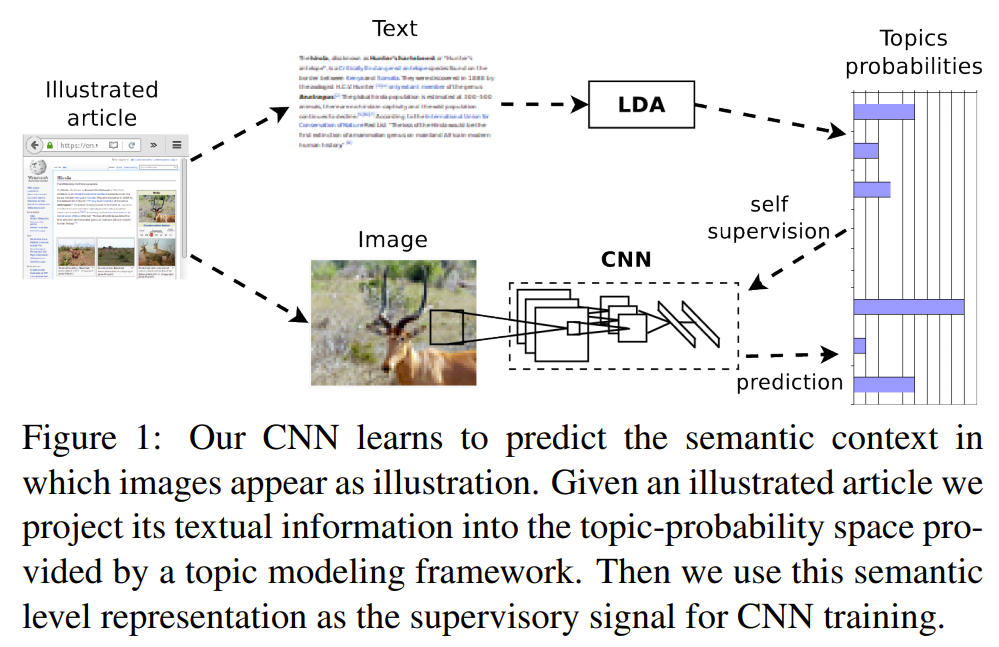
Self-supervised learning of visual features through embedding images into text topic spaces
CVPR 2017
대규모의 multimodal (텍스트와 이미지) 문서를 사용함으로써 visual features를 self-supervised learning을 수행한 논문이다. 특정 이미지가 그림으로 나타날 가능성이 더 높은 의미론적 문맥을 예측하는 CNN을 학습함으로써 구별되는 visual features이 학습될 수 있음을 보였다고 한다.
이를 위해 잘 알려진 주제 모델링 기술을 사용하여 텍스트 말뭉치에서 발견 된 숨겨진 의미 구조를 활용하였고, 최근의 자기지도 접근 방식과 비교하여 이미지 분류, object detection 및 multimodal 검색에서 SOTA 성능을 보여주었다.
Colorization as a Proxy Task for Visual Understanding
여기서는 Proxy Task라는 이름으로 self-supervised learning을 수행했다. 이 논문에서는 ImageNet의 학습 paradigm을 재검토하여 다음 질문에 대한 답을 찾는다:
- 얼마나 많은 학습 데이터가 필요한가?
- 얼마나 많은 레이블이 필요한가?
- 미세조정할 시 얼마나 많은 features가 변화하는가?
그래서 Proxy task로 채색(colorization) 문제를 사용하여 강력한 지도를 해줄 수 있음을 보인다.
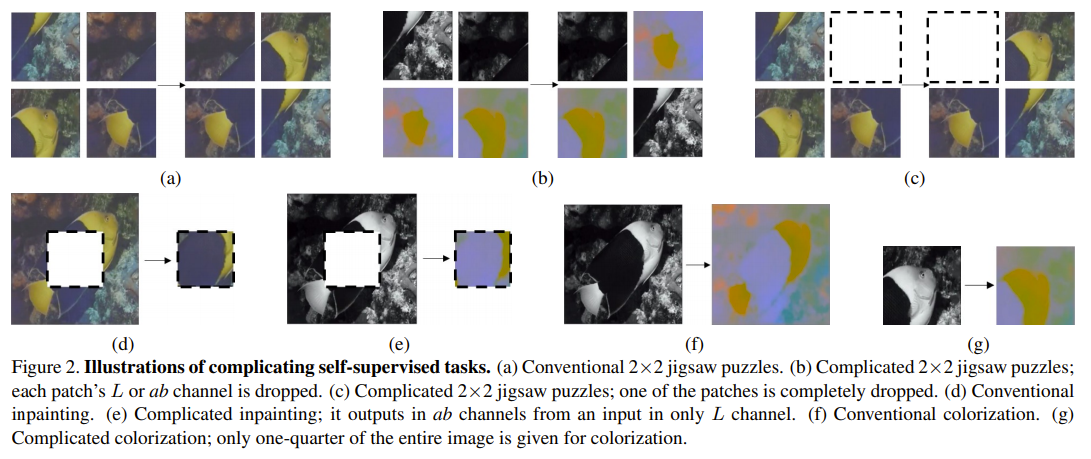
Learning Image Representations by Completing Damaged Jigsaw Puzzles
WACV 2018
이 논문은 직소 퍼즐을 사용하는데 위의 논문과는 달리 일부 손상이 가해진 직소 퍼즐을 pretext task로 삼아 손상된 직소 퍼즐을 맞추는 것을 목표로 하였다.
3 $\times$ 3개의 패치를 만들고 순서를 섞은 뒤, 9개 중 1개를 제거하고 회색조 이미지로 변환한다. 이를 원래 이미지로 복원하는 것이 목표이다.

Unsupervised Representation Learning by Predicting Image Rotations
ICLR 2018

이 논문은 이미지를 0°, 90°, 180°, 270° 회전시킨 후 얼마나 회전시켜야 원본 이미지가 나오는지를 맞히는 4-class 분류 문제를 pretext task로 사용하였다.
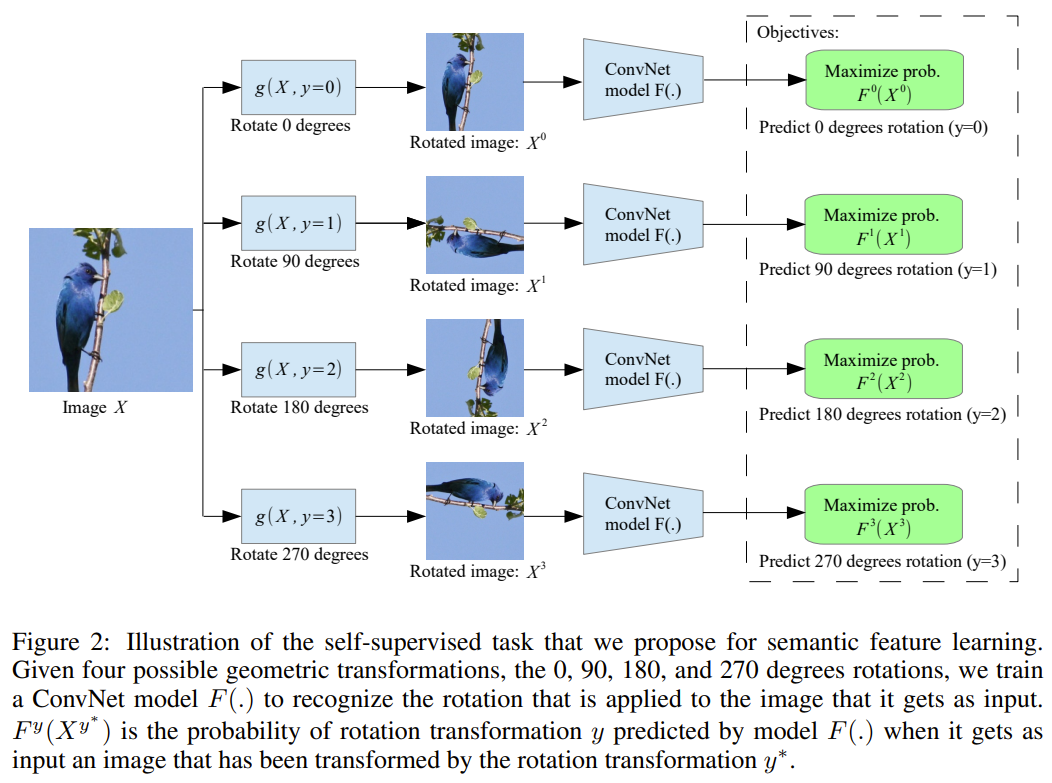
회전시킨 4종류의 이미지를 한 번에 넣는 것이 효율이 좋고, 2 또는 8방향 회전도 고려하였으나 4방향이 가장 좋은 성능을 보인다고 한다.
Cross-Domain Self-supervised Multi-task Feature Learning using Synthetic Imagery
CVPR 2018
보다 일반적인 고수준의 시각표현을 얻기 위해 하나의 task가 아닌 여러 개의 task를 학습시키는 방법을 제안하는 이 논문은 합성된 이미지를 학습한다. 실제 이미지와 합성된 이미지의 도메인 차이를 극복하기 위해 적대적 학습 방법에 기초한 비지도 domain adaptation 방법을 사용한다. 합성된 RGB 이미지가 입력으로 들어오면 네트워크는 그 표면 normal, depth, 등고선 등을 동시 추정하며 실제와 합성된 이미지 domain 간의 차이를 최소화하려 한다.
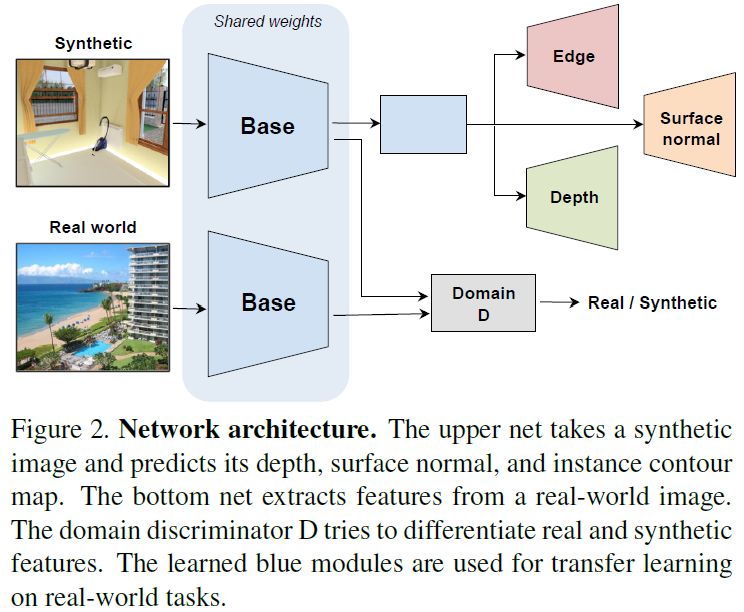
Depth prediction에서 기존 feature 학습 방법은 패치의 상대적 위치를 예측하능 등의 task를 pretext task로 한다. 이 논문에서, pretext task는 pixel prediction task를 채택하였다.
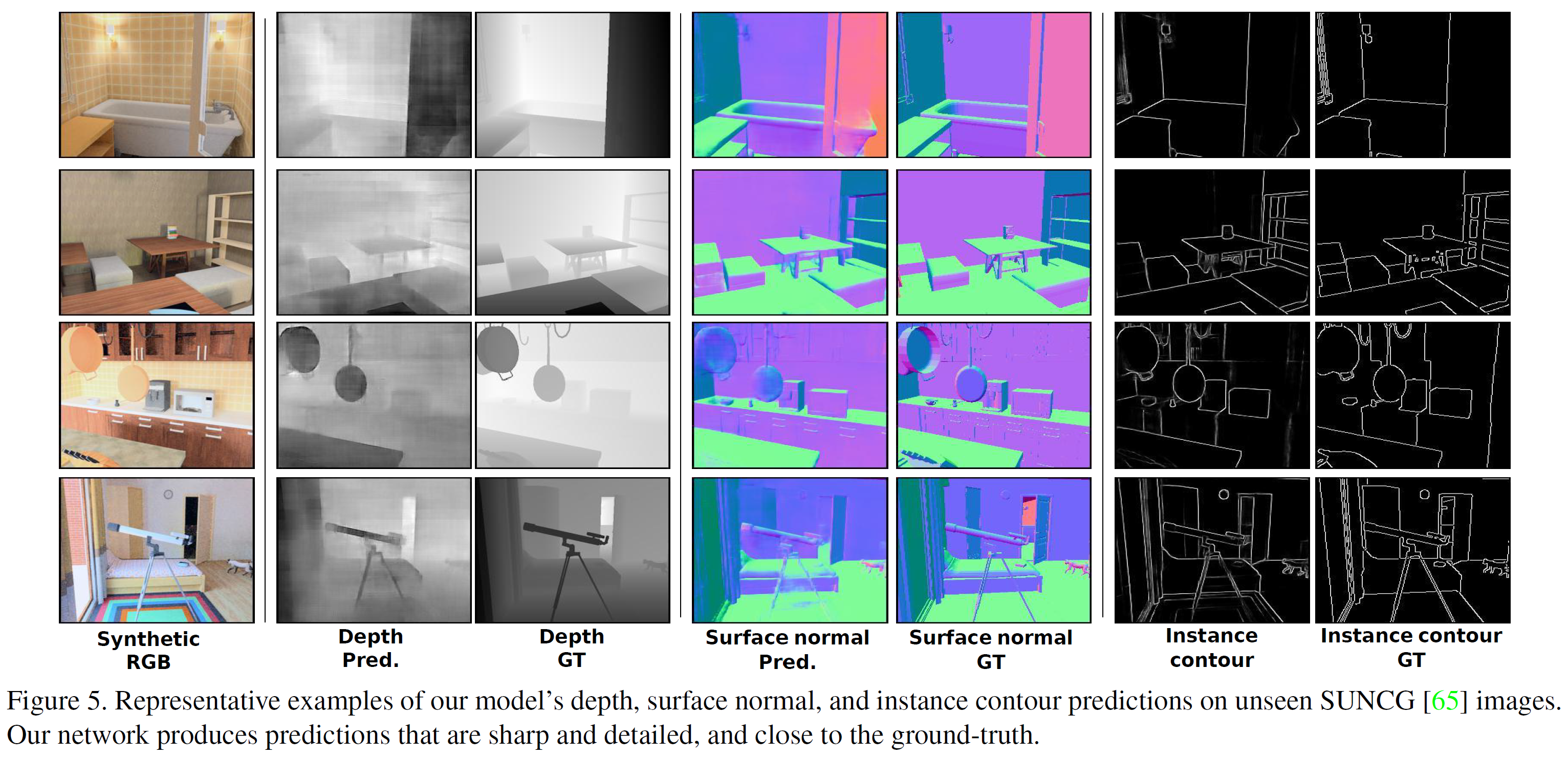
이 논문에서, Instance contour detection(객체 등고선 탐지), Depth Prediction(깊이 추정), Surface normal estimation(표면 수직벡터 추정)이 multi-task를 구성한다.
Self-Supervised Representation Learning by Rotation Feature Decoupling
ICML 2019
이 논문에서는 회전과 관련된 부분과 무관한 부분을 포함하는 split representation을 학습하는 모델을 제시한다. 이미지 회전과 각 instance를 동시에 식별하는데, 회전 식별과 instance 식별을 분리함으로써 회전의 noise 영향을 최소화하여 회전 각도 예측의 정확도를 높이고 이미지 회전과 관계없이 instance를 식별하는 것 역시 향상시키도록 한다.

방법은 다음으로 구성된다:
- Rotation Feature Decoupling
- 이미지 회전 예측
- Noisy한 회전된 이미지 식별
- Feature Decoupling
- 회전 분류
- 회전과 무관한 부분
- 이미지 instance 분류

Unsupervised Deep Learning by Neighbourhood Discovery
ICML 2019
##
##
##
##
