31 Aug 2022
|
Machine_Learning
Paper_Review
이번 글에서는 Gated Transformer Networks for Multivariate Time Series Classification
논문의 핵심 포인트만 간추려서 기술합니다.
본 논문에서는 MTS(Multivariate Time Series) 문제를 풀기 위해 transformer 구조를 활용하는 방법에 대해 기술하고 있습니다.
Multivariate Time Series task의 핵심은 stpe-wise(temporal) 정보와 channel-wise(spatial) 정보를 모두 잘 포착하는 것입니다.
본 논문은 step-wise encoder와 channel-wise encoder라는 2개의 transformer tower를 만들고 이들 output을 단순히 concatenate하는 것이 아니라 gating layer로 연결하여 최종 결과물을 산출하는 구조를 고안하였습니다.
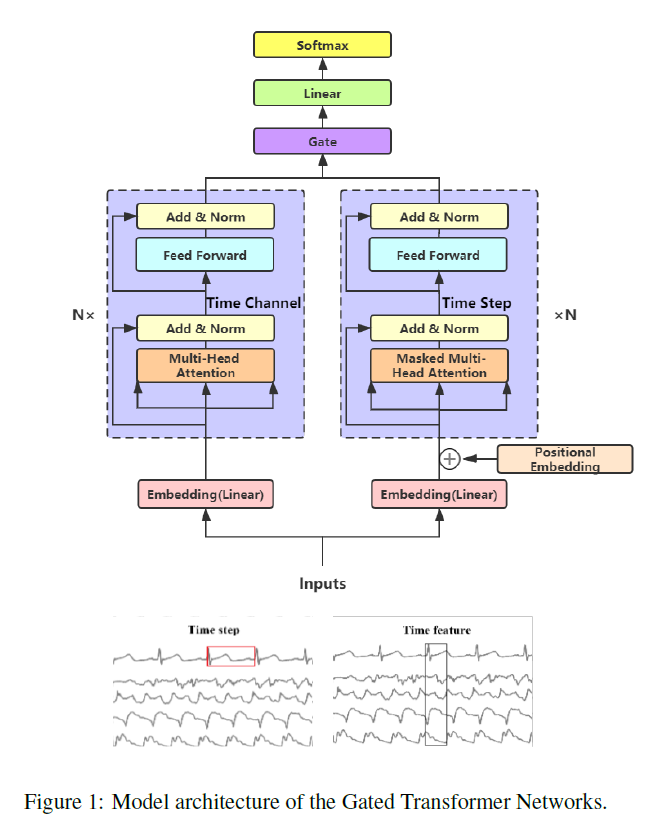
개인적으로 짧고 간결하고 좋은 아이디어라고 생각합니다. 다만 실험 결과를 보면 GTN이 꼭 우수한 것은 아니라는 결과가 나오고 이에 대해 여러 가능성을 검토한 설명이 추가되어 있긴 하지만 어떠한 확실한 정보를 주고 있지 않다는 점이 아쉬운 점으로 다가왔습니다.
MTS 문제 해결을 위한 시스템을 설계할 때 하나의 선택지로 충분히 활용할 수 있을 것으로 보입니다.
21 Aug 2022
|
Machine_Learning
Paper_Review
이번 글에서는 Transformers without Tears(Improving the Normalization of Self-Attention)
논문의 핵심 포인트만 간추려서 기술합니다.
본 논문에서는 Transformer에서 사용되는 Normalization layer를 개선하는 방법에 대해 기술하고 있습니다.
논문에서 여러 내용을 다루고 있지만 핵심 포인트는 2가지 입니다. 일단 normalization layer는 PRENORM이어야 한다는 것입니다. original Transformer에서는 POSTNORM을 사용하고 있는데, 실험 결과를 보면 PRENORM이 backpropagation을 더 효율적으로 진행할 수 있도록 도와줍니다.
그리고 이 논문에 따르면 Batch Normalization의 효율성은 internal covariate shift를 감소시킨 것에서 얻어진 것이 아니라 loss landscape를 smooth하게 만듦으로써 달성된다고 합니다. 따라서 본 논문에서는 LAYERNORM 대신 SCALENORM이라는 구조를 제안합니다.
[SCALENORM(x: g) = g \frac{x}{\Vert x \Vert}]
l2 normazliation을 적용한 것인데 여기서 $g$ 는 학습 가능한 scalar입니다. 식에서 알 수 있듯이 LAYERNORM에 비해 파라미터 수가 훨씬 적습니다. 논문의 실험 결과에 따르면 (데이터셋에 따라 다르겠지만) 학습 속도를 약 5% 정도 향상시켰다고 합니다.
이 SCALENORM은 어떻게 보면 d 차원의 벡터를 학습가능한 radius g를 활용하여 d-1 차원의 hypersphere로 project 시키는 것으로 해석할 수도 있겠습니다. 이러한 아이디어는 각 sublayer의 activation이 이상적인 global scale을 갖는다는 인사이트를 담고 있습니다.
논문에는 이 SCALENORM과 다른 논문에서 제시된 FIXNORM을 결합한 구조도 설명하고 있습니다. SCALENORM의 $g$ 는 $\sqrt{d}$ 로 초기화됩니다.
실험 결과는 논문 본문을 참고해주세요.
19 Aug 2022
|
Machine_Learning
Paper_Review
이번 글에서는 Recommendation for new users & items via randomized training and M-o-E transformation
논문의 핵심 포인트만 간추려서 기술합니다.
본 논문에서는 일반적인 CF 구조의 문제를 3가지로 지적합니다.
- 최종 loss는 CF loss + Transformation loss로 이루어지는데, seperate-training (user/item representation을 별도로 학습) 방법의 경우 이를 따로 따로 학습하다 보니 괴리가 발생함
- 한 번에 학습하는 joint-training의 경우 user/item feature를 받아들이는 transformation layer와 최종 output layer와의 거리가 너무 멀어 효과적인 학습이 일어나지 않음
- 일반적으로 side information은 noisy & complex하므로 unified transformation으로 주요 정보를 잘 포착하여 개인화된 결과를 만들어내는 것은 힘듦
논문에서는 이를 해결하기 위해 Heater라는 구조를 제안하고, 이는 크게 3가지 부분으로 이루어져 있습니다.
- user/item feature를 input으로 받아들여 생성된 intermediate vector(최종 output vector 아님)는 양질의 representation이 아니므로 미리 학습된 high-quality의 cf representation을 가져와 이 둘 사이의 차이를 줄이는 guide objective function을 설정하고, 이를 최종 objective 함수에 포함함
- 하지만 이 또한 역시 충분하지 않을 수 있으므로 Randomized Training이라는 방법을 사용하는데, 일정 확률 p를 설정하여 intermediate vector 대신 pre-trained high-quality cf representation을 사용함
- side information을 단일 transformation 함수로 변환하는 것은 다양한 input을 충분히 수용할 수 없기 때문에 Mixture-of-Experts 구조, 즉 여러 MLP layer의 가중합으로 output을 생성하도록 함
재미있는 아이디어가 많지만, 실제로 쉽게 활용하기는 어렵지 않나 하는 생각이 드는 논문이었습니다. 일단 논문에서 이야기한 구조를 구현하기 위해서는 high-quality cf representation을 먼저 얻어야 합니다. 그런데 이 임베딩의 성능 또한 결국 실험을 통해 파악할 수 밖에 없습니다. Randomized Training은 바로 위 부분에 의해 영향을 받습니다. 그리고 확실하진 않지만 MLP layer의 가중합이 단일 MLP layer 보다는 나을 수 있겠지만 최근 몇 년 사이에 등장한 여러 구조에 비해 무엇이 나은 것인지는 잘 모르겠다는 생각도 듭니다.
19 Aug 2022
|
Machine_Learning
Paper_Review
이번 글에서는 PinnerSage 논문의 핵심 포인트만 간추려서 기술합니다.
본 논문은 multi-embedding based user representation scheme에 대한 내용을 담고 있습니다.
논문에서는 기존 연구에서 한계점으로 다음 내용들을 언급합니다.
user-item을 같은 공간에 임베딩했을 때 item은 보통 1가지 종류를 갖는데 반해(예: 영화), 고 품질의 user embedding은 user의 다양한 취미, 스타일, 흥미를 반영해야 한다는 어려움이 있습니다. 이를 보완하기 위해 복수의 user embedding을 만들 수는 있지만 여러 한계점이 존재합니다.
user, item을 jointly 학습하게 되었을 때, user가 interact 했던 item 들은 자연스럽게 가까운 거리를 갖게 되는데, 예를 들어 어떤 user가 신발, 미술작품, SF를 좋아한다고 해서 이들 item이 가까운 거리를 갖는 것은 상식적으로 말이 되지 않습니다.
embedding을 1개로 제한한 상황에서 (single embedding) 이들을 merge했을 때 이상한 결과가 도출될 가능성이 존재합니다. 예를 들어 신발, 미술작품, SF를 merge하면 이와 전혀 상관없는 item이 등장할 수 있는 것입니다. 이는 single embedding이 item의 여러 측면을 표현하지 못함을 의미합니다.
PinnerSage는 다음과 같은 과정을 거치게 됩니다.
- item embedding은 미리 다른 모델에 의해 학습되어 fixed됨. 본 논문에서는 graph 기반의 PinSage가 이에 해당됨
- user가 반응한 과거 90일 치의 item 목록을 가져와서 clustering을 실시함. 이 때 clustering은 Ward(계층적 군집화)으로 이루어짐
- 각 item이 cluster에 배정되었으면 cluster를 대표하는 representation을 medoid를 통해 설정함
- 모든 cluster에 대해 추론하는 것은 불가능하기 때문에 cluster importance score를 계산하여 3개의 cluster를 추출함. 이 score는 frequency와 recency를 반영하며 두 factor의 균형을 조절할 수 있는 hyperparameter가 존재함
- 추출된 3개의 representation이 곧 user embedding에 해당하며 ANN을 통해 수 많은 item embedding 사이의 유사도를 계산하여 가장 적합한 item을 user 별로 추천하게 됨
논문에서는 AB Test를 통해 single embedding을 사용하는 것에 비해 유의미한 개선이 있었음을 증명하였습니다. 그리고 논문 후반부에 언급되는 추천 시스템 구조는 꽤 도움이 많이 되는 정보를 담고 있는데, 그 중에서도 daily batch inference와 lightweight online inference를 분리하여 진행한 것이 실질적으로 운영에 큰 도움이 되었을 것으로 판단합니다.
본 논문은 굉장히 많은 item embedding 사이의 유사도를 계산해야 하고, single item embedding이 충분한 표현력을 갖지 못한다고 판단될 때 실질적으로 활용 가능성이 매우 높은 방안을 제시했다는 점에서 굉장히 인상적이었습니다.
19 Aug 2022
|
Machine_Learning
Paper_Review
이번 글에서는 DropoutNet 논문의 핵심 포인트만 메모해 둡니다.
-
논문 링크
- cold start 문제를 좀 더 잘 풀기 위해 dropout 구조를 활용함
- denosing autoencoder에서 영감을 받았다고 하며, 무작위로 user 혹은 item의 content feature를 0으로 masking하여 학습함
- 위 방법 자체를 dropout 구조라고 명명하며, cold start 문제를 더 잘 풀기 위해 objective function에 항을 추가하는 이전의 여러 방법보다 간단한 방법이라고 함
- 학습/예측을 위한 추천 모델 자체에는 특별한 부분은 없음
