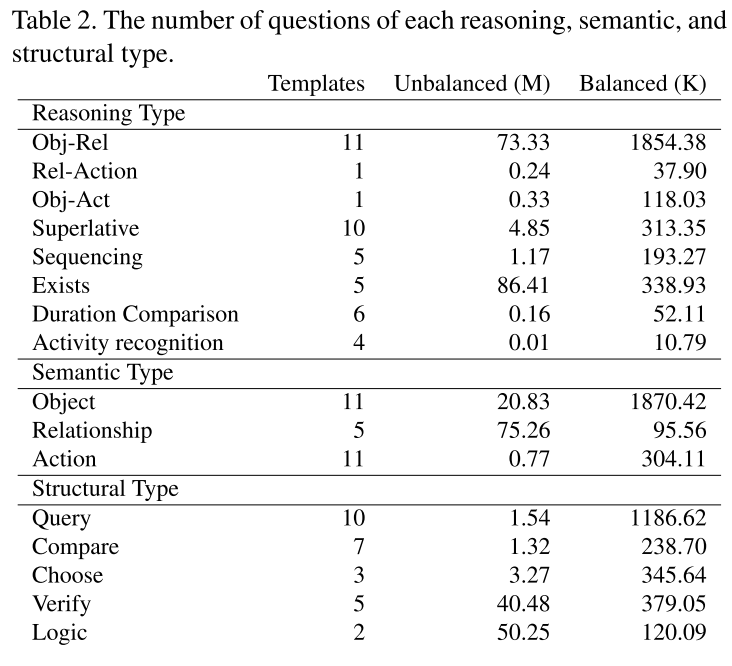
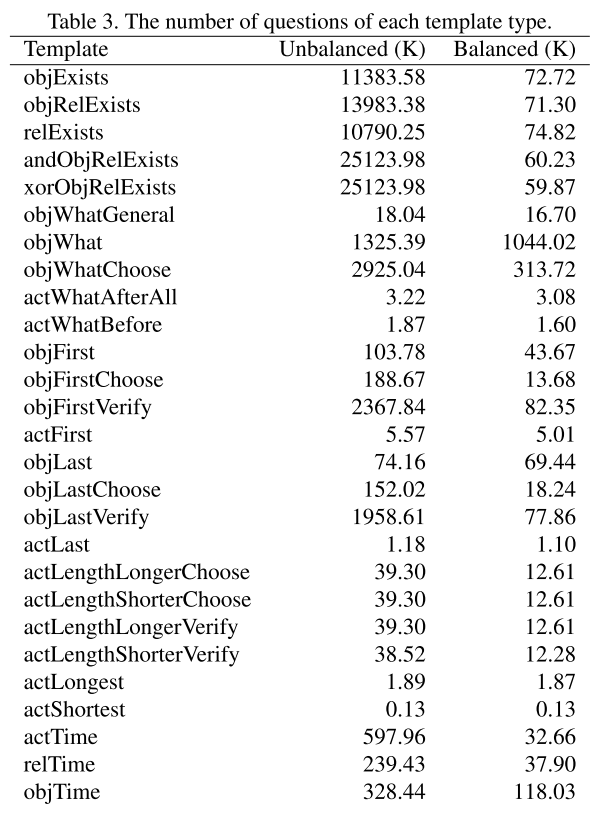
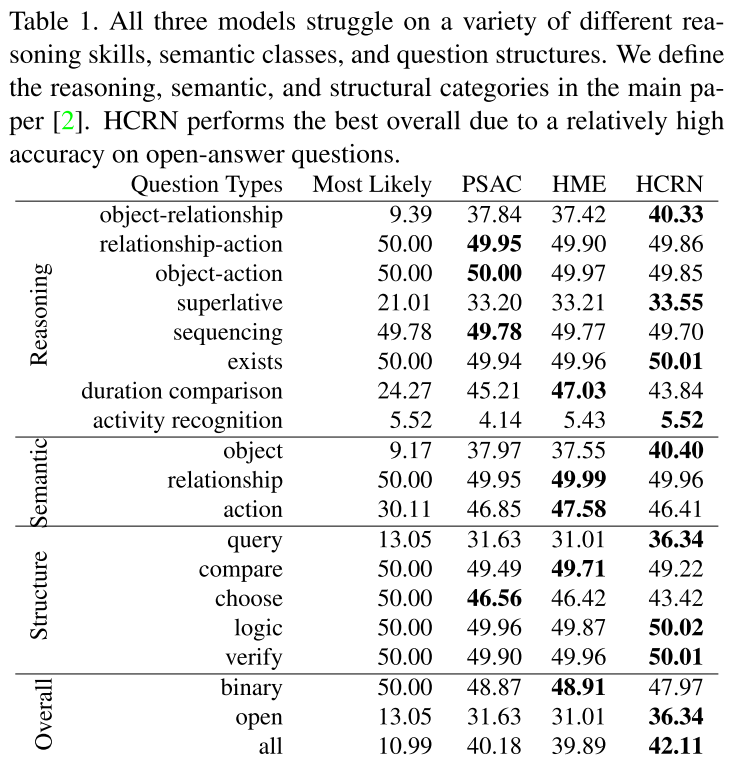
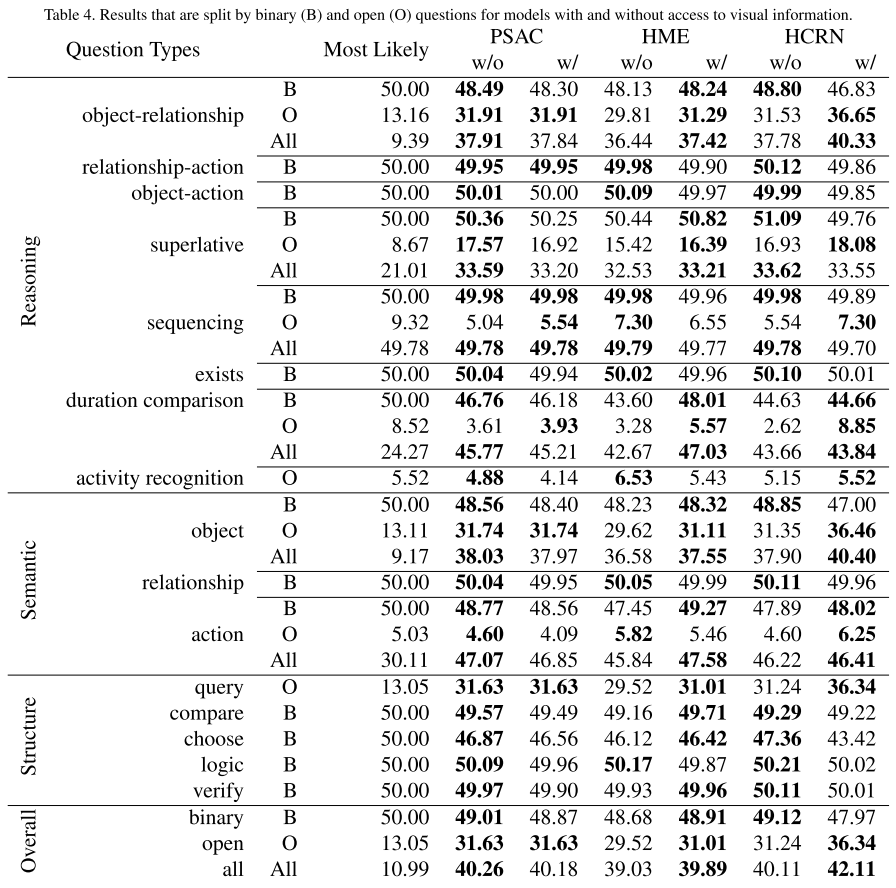
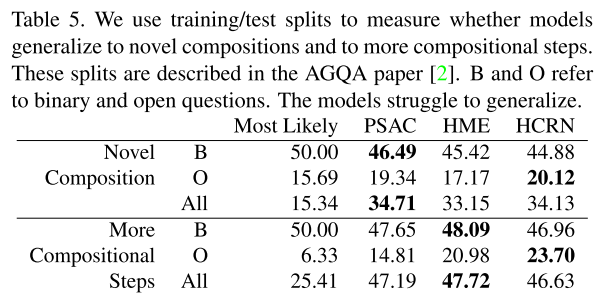
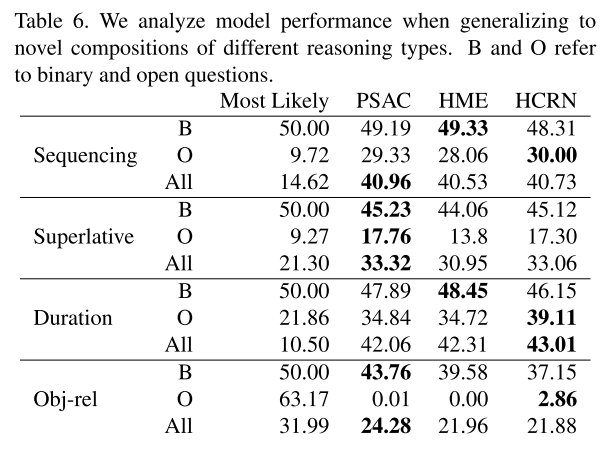
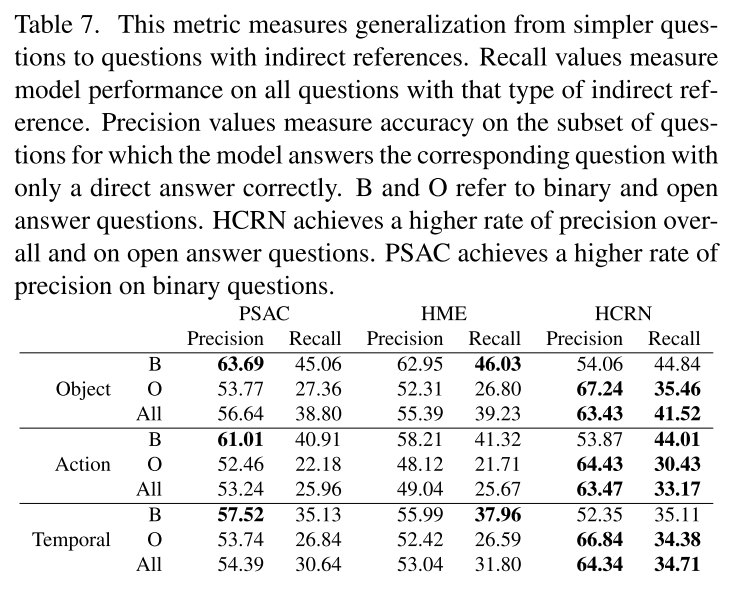
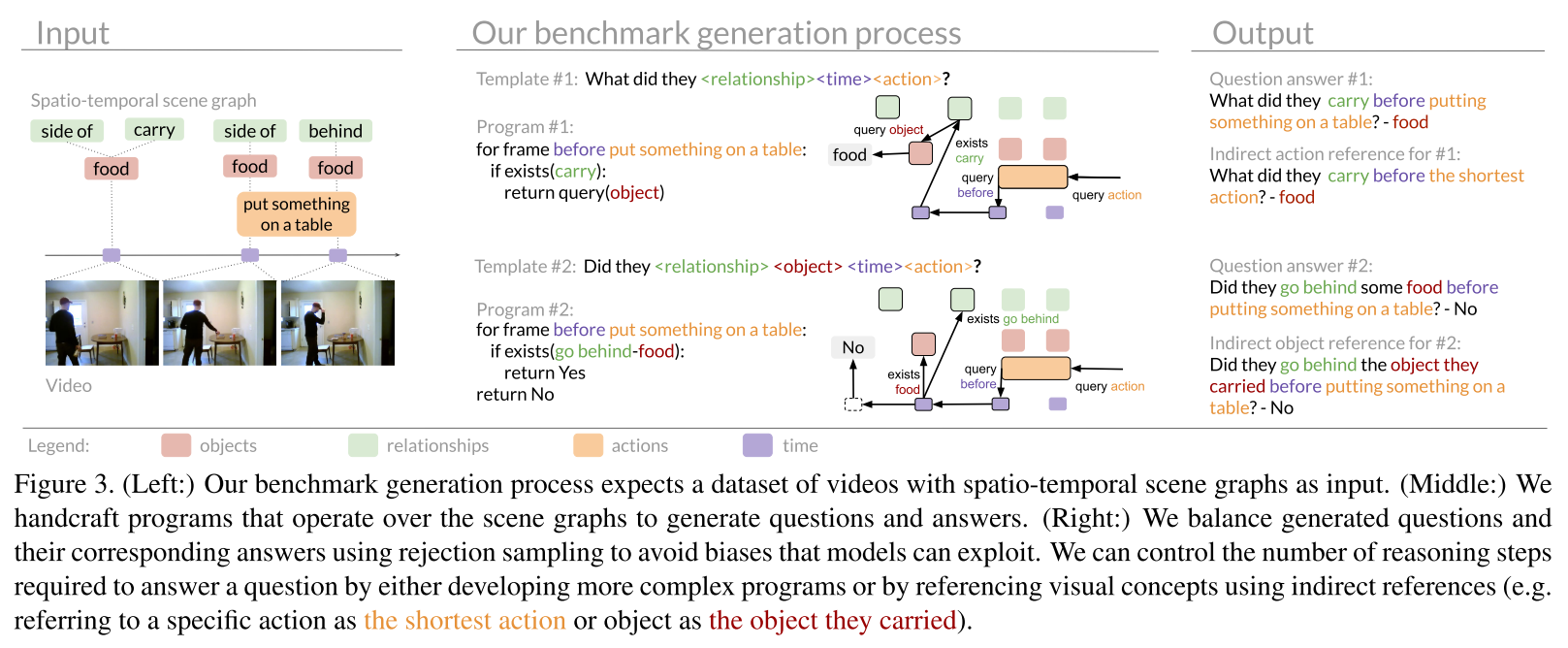
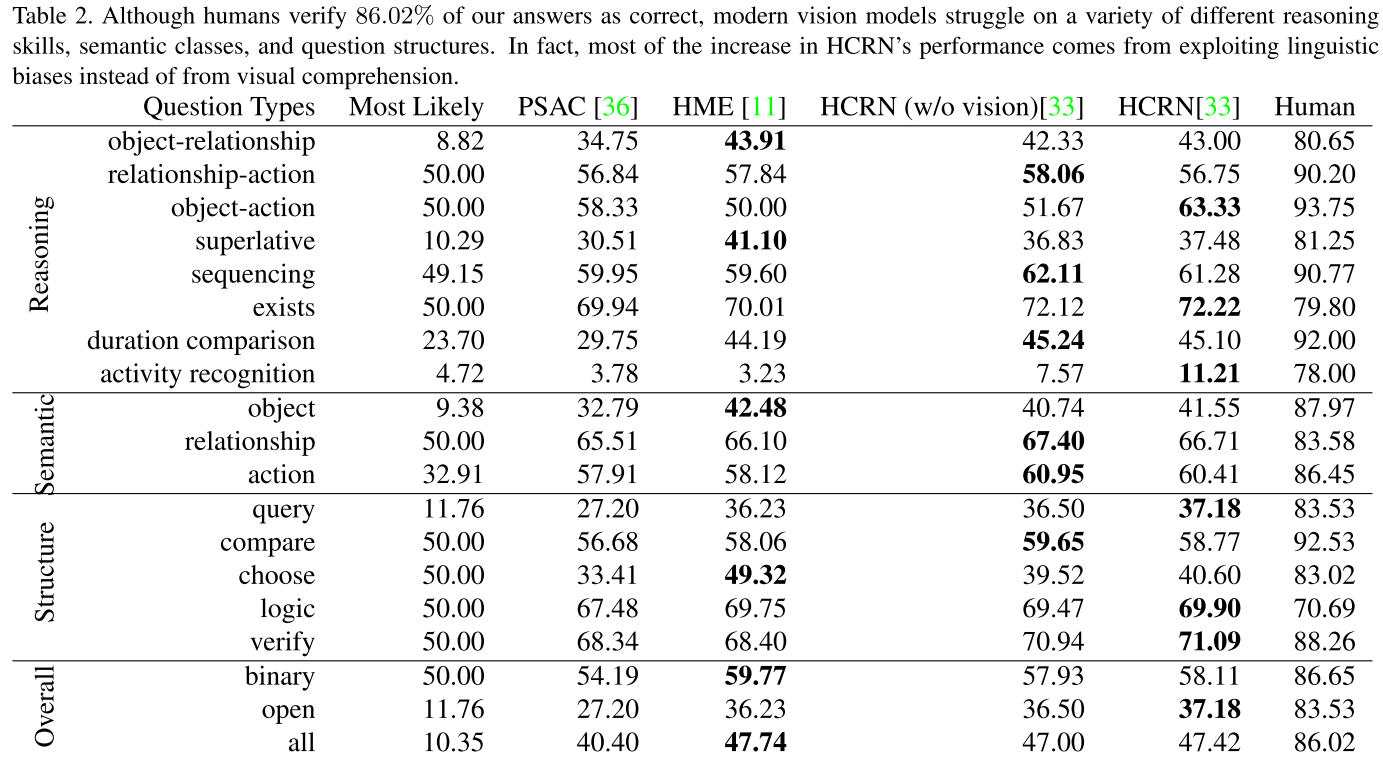
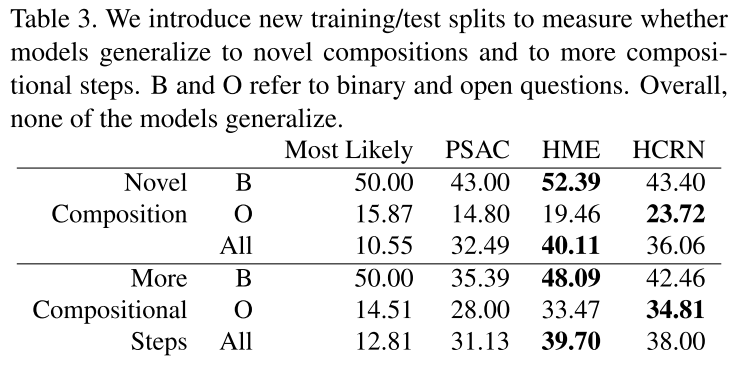
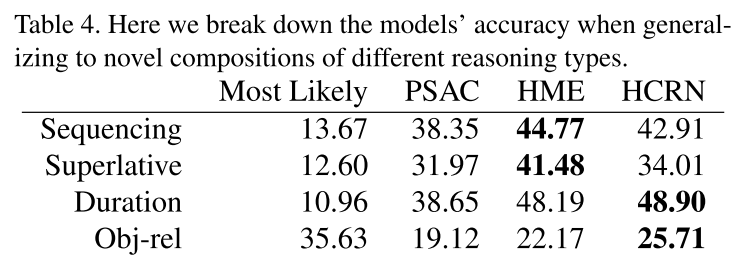
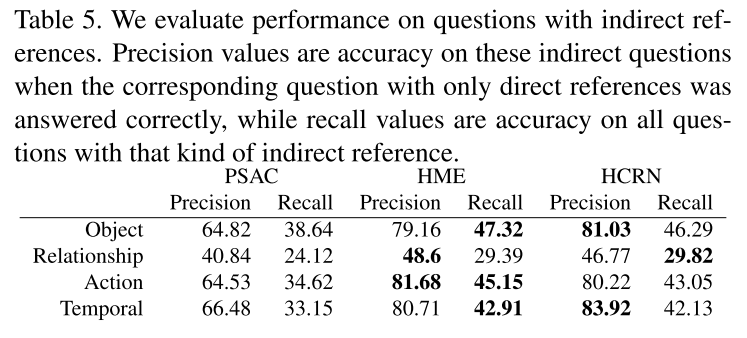
구글 스프레드시트는 어떤 결과 같은 것을 정리하기에 꽤 괜찮은 도구이다.
그렇다면 파이썬으로 실험한 결과를 스프레드시트에 자동 기록하게 한다면..?
이 글에서는 python gspread를 이용해 자동으로 구글 스프레드시트에 값을 기록하는 방법을 정리한다.
코드의 일부는 gspread docs에서 가져왔다.
gspread 설치
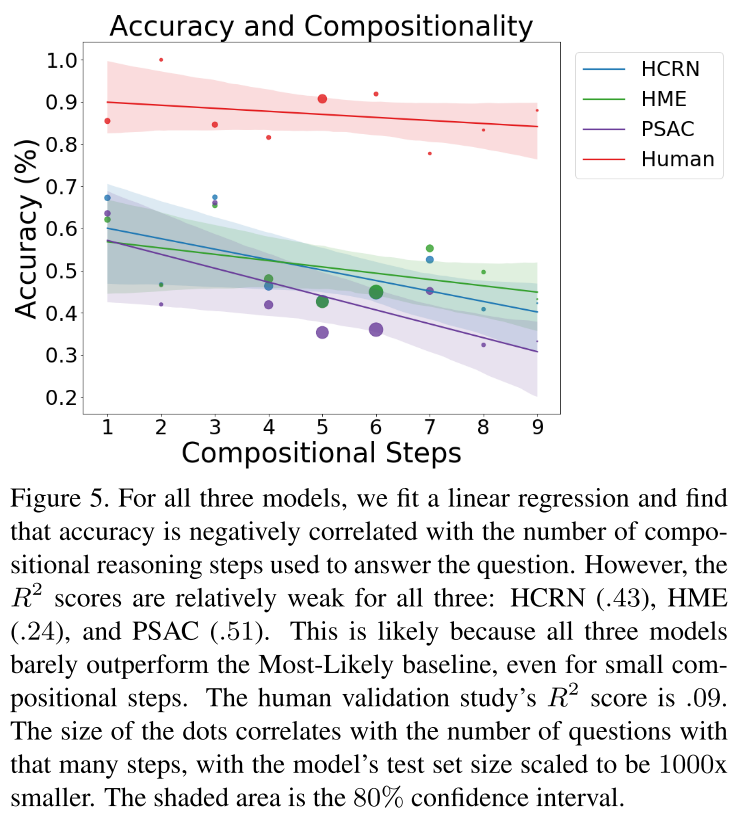
설치는 꽤 간단하다.
권한 및 환경 설정
먼저 프로젝트를 생성한다.
구글 클라우드에 로그인을 한 다음에 프로젝트 만들기를 누른다.
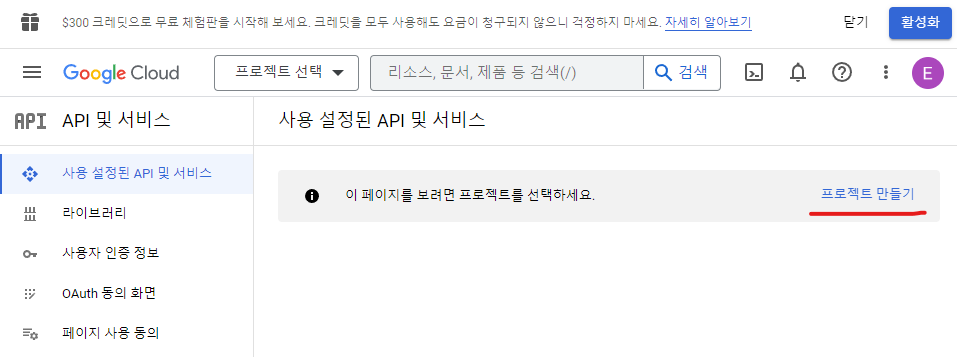
아래 스크린샷처럼 프로젝트 이름을 마음대로 지정한다. 위치를 지정하고 싶으면 지정한 다음(선택), 만들기를 누른다.
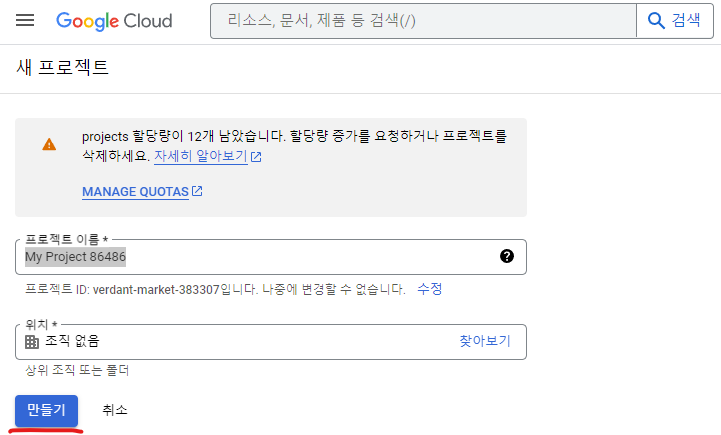
그러면 프로젝트가 하나 만들어진다. 먼저, 위쪽의 검색 창에서 Google Drive API를 검색한다.
그리고 사용을 눌러 준다. 마찬가지로, Google Sheets API를 검색한 다음 사용을 클릭한다.
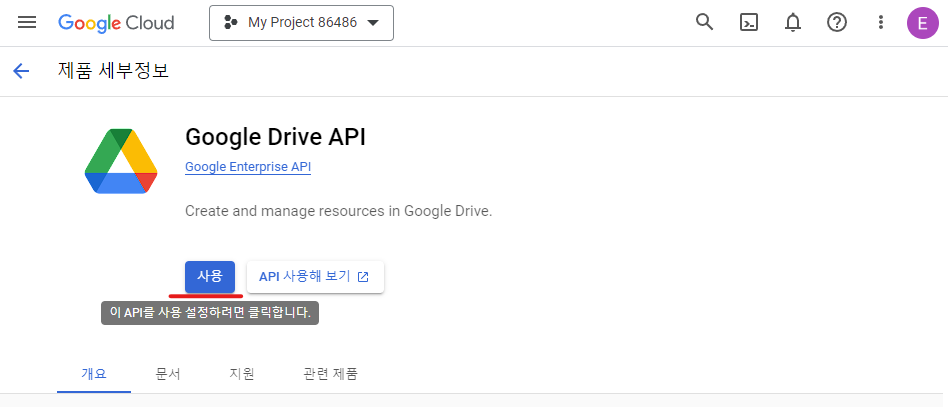
이제 API 및 서비스 > 사용자 인증 정보(영어라면 APIs & Services > Credentials) 페이지로 이동한 다음, 사용자 인증 정보 만들기 > 서비스 계정(Create credentials > Service account key)를 클릭한다. 설명을 보면 로봇 계정이라 되어 있다. python을 쓸 수 있을 것 같지 않은가?
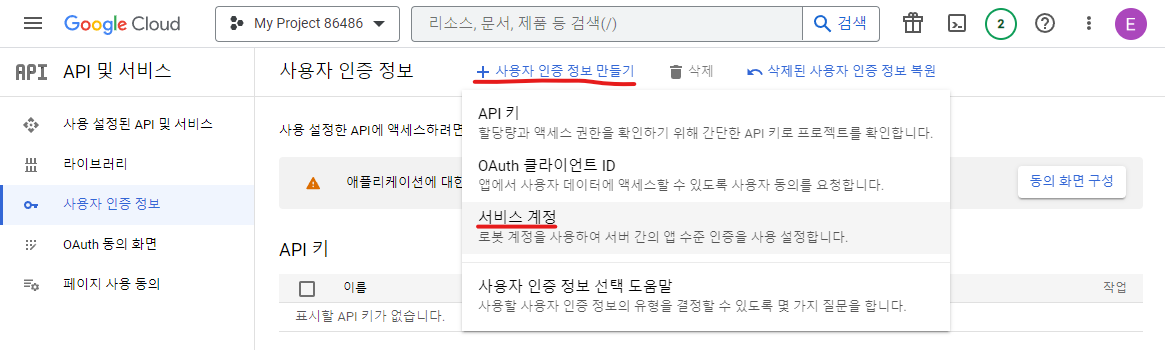
서비스 계정 이름을 설정한다. 그러면 자동으로 계정 ID도 만들어지는데, 수정해도 상관없다.
아래의 계정 설명이나 액세스 권한 부여(2, 3)번은 선택사항으로 패스해도 된다. 제일 아래의 완료를 클릭한다.
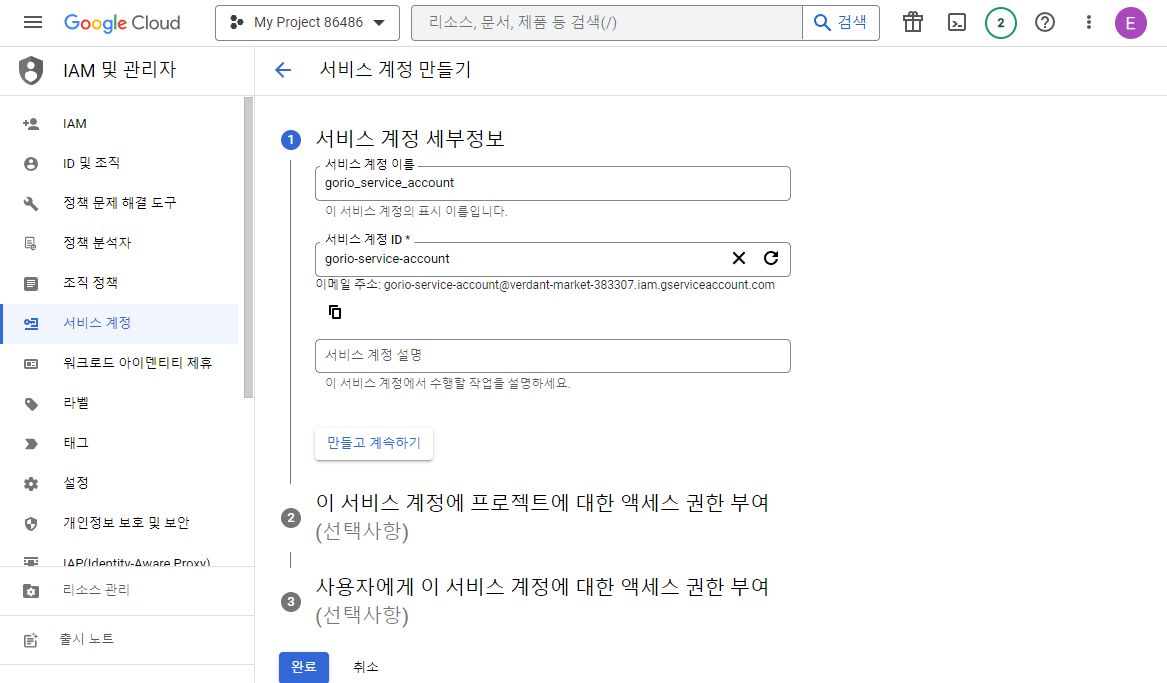
그러면 서비스 계정이 하나 생성된 것을 볼 수 있다. 서비스 계정 관리(Manage service accounts)를 클릭해 준다.
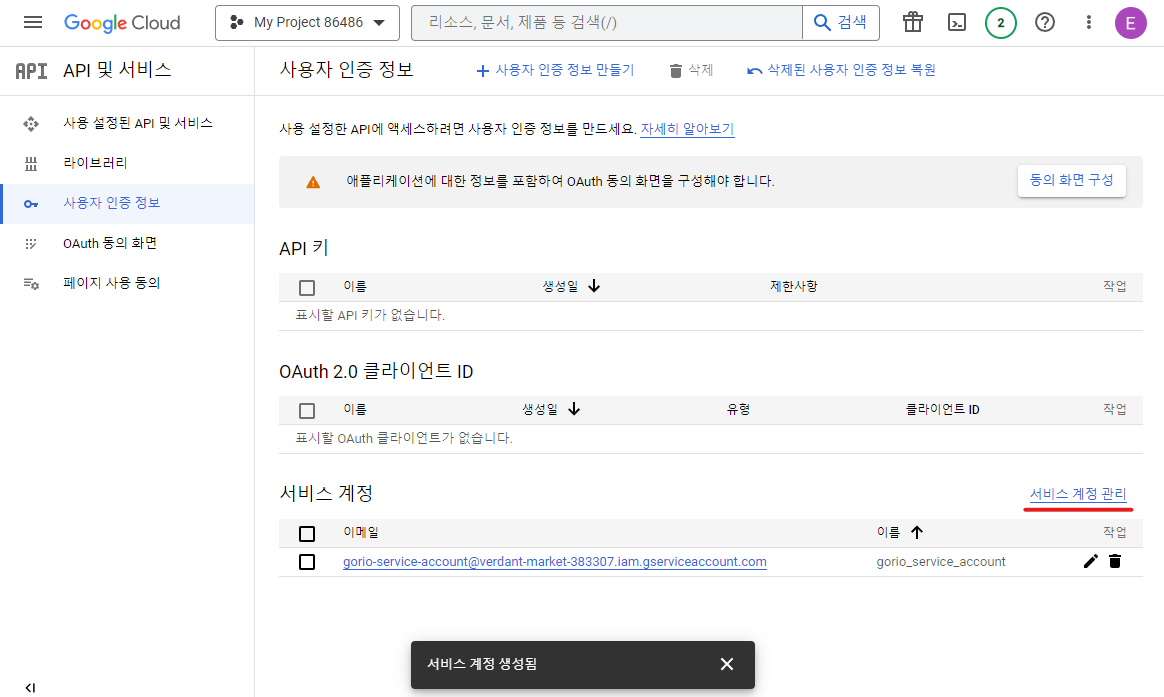
아래 그림과 같이 3점 버튼을 누르고 키 관리(Manage Keys)를 클릭한다.
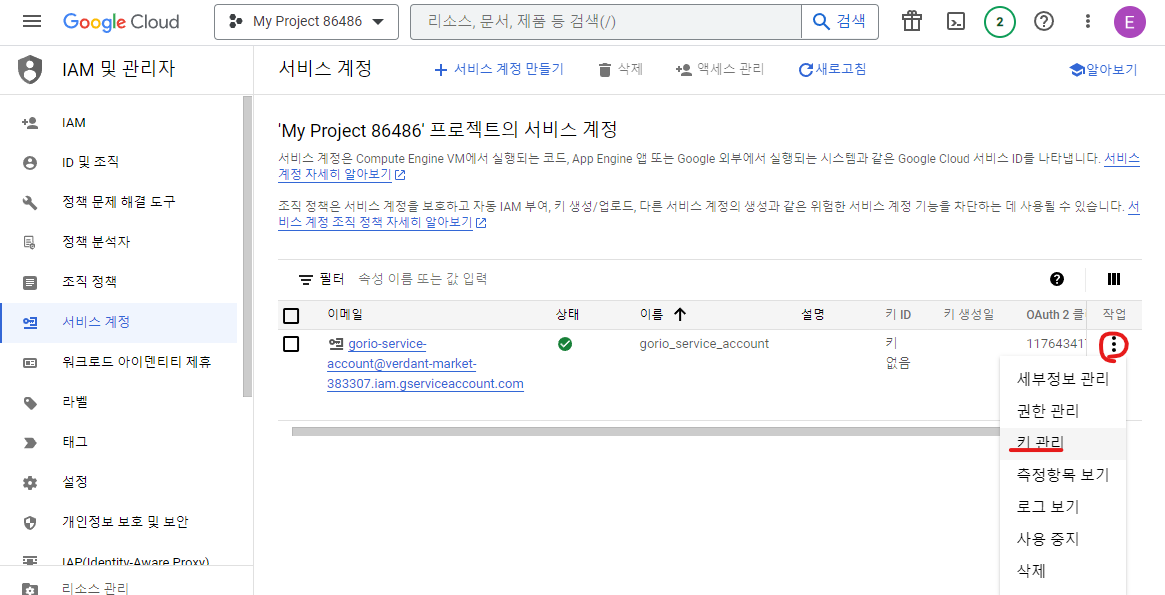
키 추가 > 새 키 만들기를 클릭한다. (ADD KEY > Create new key)
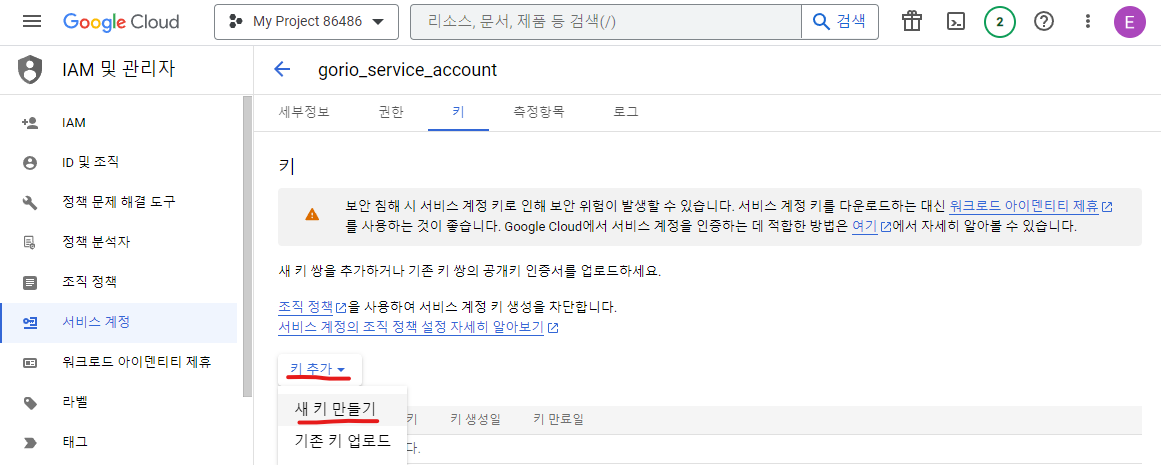
그리고 뜨는 창에서 JSON을 그대로 두고 만들기(Create)를 클릭한다.

그러면 json 파일이 하나 다운로드될 것이다. json 파일을 열어보면, 아래랑 비슷하게 생겼다.
{
"type": "service_account",
"project_id": "api-project-XXX",
"private_key_id": "2cd … ba4",
"private_key": "-----BEGIN PRIVATE KEY-----\nNrDyLw … jINQh/9\n-----END PRIVATE KEY-----\n",
"client_email": "473000000000-yoursisdifferent@developer.gserviceaccount.com",
"client_id": "473 … hd.apps.googleusercontent.com",
...
}
client_email key가 보일 것이다. 옆에 value로 자동 생성된 어떤 email 주소가 보일 것이다. 이 이메일 주소를, 이제 python으로 결과를 입력할 스프레드시트에 다른 사용자를 추가하듯이 사용자 추가를 하면 된다.
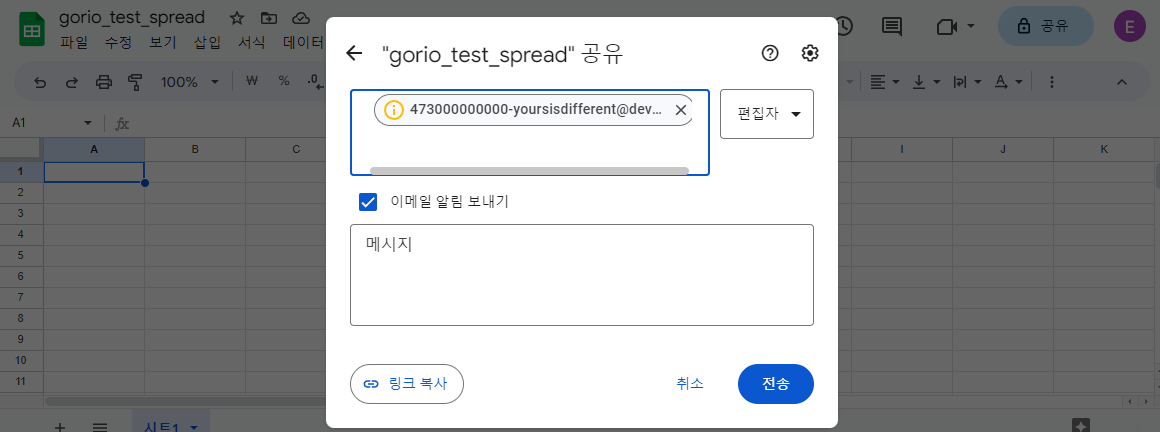
이제, 아까 그 json 파일을 아래 기본 경로에 둔다. 파일 이름도 service_account.json로 바꿔준다.
- Linux:
~/.config/gspread/service_account.json
- Windows:
%APPDATA%\gspread\service_account.json
이제 테스트를 해 보자. 스프레드시트를 원하는 제목으로 하나 만든다. (필자는 제목을 gorio_test_spread으로 했다)
1번째 행, 1번째 열(A1 셀)에 텍스트를 아무거나 입력하고(gspread test와 같은), 아래 코드를 python으로 실행시켜보자.
import gspread
gc = gspread.service_account()
sh = gc.open("gorio_test_spread") # 스프레드시트 제목으로 설정할 것
print(sh.sheet1.get('A1'))
# 결과: [['gspread test']]
참고로, 기본 권한 파일은 위의 기본 경로에 저장된 service_account.json이고, 다른 파일(즉, 다른 권한을 가진 계정 등)을 쓰려면 아래와 같이 쓰면 된다.
import gspread
gc = gspread.service_account(filename='C:/rnsrnbin_gorio_test_spread.json')
sh = gc.open("gorio_test_spread") # 스프레드시트 제목으로 설정할 것
print(sh.sheet1.get('A1'))
service account는 credential을 사용하거나 dictionary 형태로 받을 수 있다.
from google.oauth2.service_account import Credentials
scopes = [
'https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive'
]
credentials = Credentials.from_service_account_file(
'path/to/the/downloaded/file.json',
scopes=scopes
)
gc = gspread.authorize(credentials)
또는
import gspread
credentials = {
"type": "service_account",
"project_id": "api-project-XXX",
"private_key_id": "2cd … ba4",
"private_key": "-----BEGIN PRIVATE KEY-----\nNrDyLw … jINQh/9\n-----END PRIVATE KEY-----\n",
"client_email": "473000000000-yoursisdifferent@developer.gserviceaccount.com",
"client_id": "473 … hd.apps.googleusercontent.com",
...
}
gc = gspread.service_account_from_dict(credentials)
sh = gc.open("Example spreadsheet")
print(sh.sheet1.get('A1'))
credential과 관련해 더 자세한 내용은 여기를 참조하면 된다. 사실 위의 내용과 거의 같은 내용도 포함한다.
gspread 사용법
Spreadsheet open, create, share
권한과 환경설정을 모두 마쳤으면, 스프레드시트를 불러올 차례가 되었다.
스프레드시트는 시트의 제목, 또는 url로부터 고유 id를 가져오거나, 그냥 url 전체를 복붙하면 된다.
sh = gc.open('gorio_test_spread')
sh = gc.open_by_key('1kXGuatJwOmkMAat38UZ7OLdGBjt3HS1AobTGmlOuDns')
sh = gc.open_by_url('https://docs.google.com/spreadsheets/d/1kXGuatJwOmkMAat38UZ7OLdGBjt3HS1AobTGmlOuDns/edit#gid=0')
단, 제목으로 하면 같은 제목을 가진 스프레드시트가 여러 개 있을 경우에 그냥 마지막으로 수정된 시트가 열린다. 가능하면 url이라도 쓰자.
스프레드시트는 다음과 같이 생성할 수 있다.
sh = gc.create('A new spreadsheet')
공유하는 방법도 어렵지 않다.
sh.share('otto@example.com', perm_type='user', role='writer')
Sheet select, create, delete
가장 많이 쓰는 경우는 첫 번째 시트를 선택하는 경우이므로 아예 따로 지정되어 있다. 물론 다른 방법으로도 선택 가능하다.
worksheet 번호로 선택할 수 있다. 물론 번호는 0부터 시작한다.
worksheet = sh.get_worksheet(0)
시트 제목으로 선택할 수도 있다.
worksheet = sh.worksheet("Gorio")
전체 시트 목록을 얻으려면 다음과 같이 하면 된다.
worksheet_list = sh.worksheets()
worksheet를 추가하거나 삭제하는 법도 간단하다.
# 추가
worksheet = sh.add_worksheet(title="New gorio worksheet", rows=50, cols=26)
# 삭제
sh.del_worksheet(worksheet)
셀 값 얻기
특정 1개의 셀 값을 얻는 방법은 여러 가지가 있다.
# 1행 3열의 셀 값 얻기
val = worksheet.cell(1, 3).value
val = worksheet.acell('C1').value
val = worksheet.get('C1') # 사실 get은 범위 연산도 가능하다. 출력되는 결과를 보면 2차원 리스트로 조금 다르게 생겼다.
# 결과:
# 'MR-full-mAP'
# 'MR-full-mAP'
# [['MR-full-mAP']]
# cell formula를 사용하는 방법도 있다.
cell = worksheet.acell('C1', value_render_option='FORMULA').value # 또는
cell = worksheet.cell(1, 3, value_render_option='FORMULA').value # 1행 3열 -> C1
특정 행이나 열 전체의 셀 값을 가져올 수 있다.
values_list = worksheet.row_values(1)
values_list = worksheet.col_values(1)
이외에도 범위를 지정해서 셀 값을 가져올 수 있다.
get_all_values()는 worksheet 전체의 값을 가져온다.get()는 지정한 범위의 셀 값을 전부 가져온다.batch_get()는 1번의 api call로 여러 범위의 셀 값을 가져올 수 있다.update()는 값을 가져오는 것이 아니라 원하는 값으로 셀을 수정할 수 있다.- 이제
batch_update()는 무슨 함수인지 알 것이다.
참고로 api call을 너무 많이 날리면 429 RESOURCE_EXHAUSTED APIError가 뜰 수 있다. 그래서 위에 소개한 범위 함수를 잘 쓰는 것이 중요하다.
api call limit은 다음과 같다.
- 한 프로젝트당, 60초간 300회
- 1명의 유저당, 60초간 60회
worksheet의 모든 값을 list의 list 또는 dict의 list 형태로 가져올 수 있다.
list_of_lists = worksheet.get_all_values()
list_of_dicts = worksheet.get_all_records()
셀 값 찾기
기본적으로, 셀은 다음과 같은 값들을 attribute로 갖는다.
value = cell.value
row_number = cell.row
column_number = cell.col
특정 문자열을 가지는 셀을 하나 또는 전부 찾는 방법은 아래와 같다.
cell = worksheet.find("Gorio")
print("'Gorio' is at R%sC%s" % (cell.row, cell.col))
# 전부 찾기
cell_list = worksheet.findall("Gorio")
정규표현식을 사용할 수도 있다.
amount_re = re.compile(r'(Big|Enormous) dough')
cell = worksheet.find(amount_re)
# 전부 찾기
cell_list = worksheet.findall(amount_re)
셀 값 업데이트하기
먼저, 선택한 범위의 셀 내용을 지우는 방법은 다음과 같다.
# 리스트 안에 요소로 셀 범위나 이름을 부여한 named range를 넣을 수 있다.
worksheet.batch_clear(["A1:B1", "C2:E2", "named_range"])
# 전체를 지울 수도 있다.
worksheet.clear()
특정 1개 또는 특정 범위의 셀을 지정한 값으로 업데이트할 수 있다.
worksheet.update('B1', 'Gorio')
# 1행 2열, 즉 B1
worksheet.update_cell(1, 2, 'Gorio')
# 범위 업데이트
worksheet.update('A1:B2', [[1, 2], [3, 4]])
서식 지정
셀 값을 단순히 채우는 것 말고도 서식을 지정할 수도 있다.
# 볼드체로 지정
worksheet.format('A1:B1', {'textFormat': {'bold': True}})
여러가지 설정을 같이 할 수도 있다. dict에 원하는 값을 지정하여 업데이트하면 된다.
worksheet.format("A2:B2", {
"backgroundColor": {
"red": 0.0,
"green": 0.0,
"blue": 0.0
},
"horizontalAlignment": "CENTER",
"textFormat": {
"foregroundColor": {
"red": 1.0,
"green": 1.0,
"blue": 1.0
},
"fontSize": 12,
"bold": True
}
})
어떤 서식을 지정할 수 있는지는 여기를 참고하자.
또한, 셀 서식뿐만 아니라 워크시트의 일부 서식을 지정할 수도 있다.
예를 들어 행 또는 열 고정은 다음과 같이 값을 얻거나 지정할 수 있다.
get_frozen_row_count(worksheet)
get_frozen_column_count(worksheet)
set_frozen(worksheet, rows=1)
set_frozen(worksheet, cols=1)
set_frozen(worksheet, rows=1, cols=0)
셀의 높이나 너비를 지정하거나 데이터 유효성 검사, 조건부 서식 등을 지정할 수도 있다.
설치 방법 및 사용법은 다음을 참고하자.
- https://gspread-formatting.readthedocs.io/en/latest/
numpy, pandas와 같이 사용하기
워크시트 전체를 numpy array로 만들 수 있다.
import numpy as np
array = np.array(worksheet.get_all_values())
# 시트에 있는 header를 떼고 싶으면 그냥 [1:]부터 시작하면 된다.
array = np.array(worksheet.get_all_values()[1:])
물론 numpy array를 시트에 올릴 수도 있다.
import numpy as np
array = np.array([[1, 2, 3], [4, 5, 6]])
worksheet.update('A2', array.tolist())
워크시트 전체를 불러와 pandas dataframe으로 만들고 싶으면 다음과 같이 쓰면 된다.
import pandas as pd
dataframe = pd.DataFrame(worksheet.get_all_records())
dataframe의 header와 value를 전부 worksheet에 쓰는 코드 예시는 다음과 같다.
import pandas as pd
worksheet.update([dataframe.columns.values.tolist()] + dataframe.values.tolist())
더 많은 기능은 다음 github을 참고하자.
- https://github.com/aiguofer/gspread-pandas
- https://github.com/robin900/gspread-dataframe
References
- https://docs.gspread.org/en/latest/oauth2.html#enable-api-access
- https://developers.google.com/sheets/api/reference/rest/v4/spreadsheets/cells#cellformat
- https://gspread-formatting.readthedocs.io/en/latest/