
AGQA 2.0 - An Updated Benchmark for Compositional Spatio-Temporal Reasoning 설명
06 Mar 2023 | Machine_Learning Paper_Review목차
- Abstract
- 1. Action Genome Question Answering
- 2. Updates to AGQA
- 3. Results
- 3.1. Performance across question types
- 3.2. Performance without visual data
- 3.3. Model performance by binary and open answer questions
- 3.4. Generalization to novel compositions
- 3.5. Generalization to more compositional steps
- 3.6. Generalization to indirect references
- 3.7. Performance by question complexity
- 4. Discussion
이번 글에서는 AGQA 2.0: An Updated Benchmark for Compositional Spatio-Temporal Reasoning 논문을 정리한다.
Abstract
- AGQA 1.0에서는 언어적 편향의 영향을 줄이기 위해 균형 잡힌 답변 분포로 훈련/테스트 분할을 제공하였다.
- 그러나 여전히 편향성(bias)이 일부 남아 있다.
- 2.0 benchmark에서는 몇 가지 개선 사항, 특히 더 엄격한 balancing이 적용되었다.
- 그리고 모든 실험에 대해 업데이트된 benchmark 결과를 report한다.
1. Action Genome Question Answering
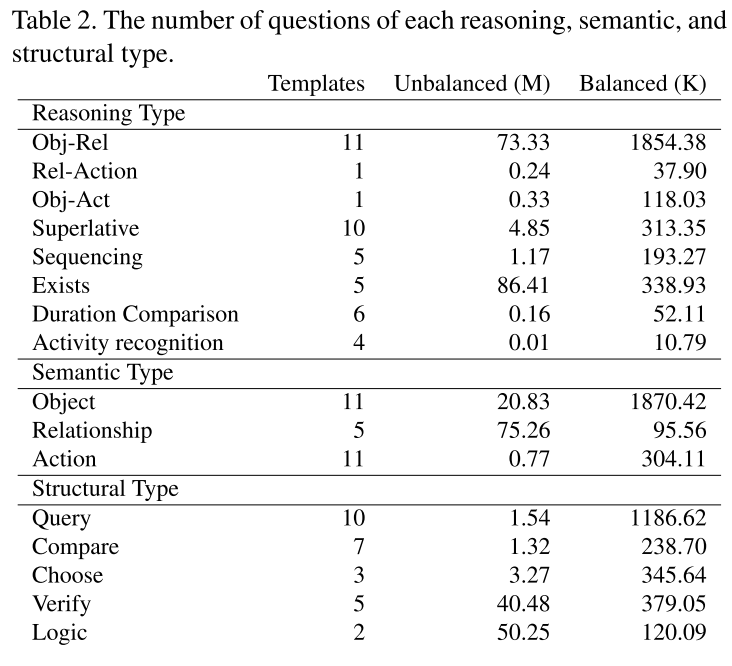
AGQA는 bias를 많이 없앤 좋은 VQA benchmark이지만 부족한 점이 여전히 있었다. 그래서 본 논문에서 2.0 버전으로 업그레이드한 버전을 소개하고자 한다. 언어적 편향성(language bias)을 더욱 제거할 수 있는 더 강력한 balancing 작업을 진행하여 총 96.85M개의 QA 쌍에서 2.27M쌍의 균형잡힌 데이터셋을 만들었다.
Section 2에서는 1.0과 2.0의 차이를, Section 3에서는 기존 모델들의 달라진 성능 체크를 report한다. balanced 버전에서는 어떤 모델도 이지선다형 질문에 51%의 정확도를 넘지 못했다.
2. Updates to AGQA
2.0에서는 특히 balancing 과정에 신경을 많이 썼다. 이전의 balancing 작업 역시 bias를 많이 없애기는 하였으나 여전히 남아 있는 bias를 모델들이 활용하였다.
- balancing algorithm은 (다지선다형에서) 각 정답의 비율이 동일하도록 조정한다. 즉 특정 종류의 질문의 대답이 yes/no라면 yes가 50%, no도 50%의 비율로 나타나도록 한다.
- Temporal localization phrases를 다루는 category definition도 재정의했다.
- 결과적으로 HCRN의 경우 yes/no 질문에서 1.0에서는 72.12%의 정답률을 보였지만 bias를 제거한 2.0에서는 50.10%밖에 달성하지 못했다.
이외에도 작은 upgrade들이 있었다:
- relationship type을 명시하지 않고 object의 존재 여부를 물을 때
contacting과touching용어를interacts with로 바꾸었다. 이는 actor가 object를 물리적으로 “touch”하지 않아도 답변이 yes가 될 수 있음을 의미한다. 또한doorway상호작용은 불명확하므로 제거하였다. - 종종 모호할 수 있는 간접적인 표현을 제거하였다.
the thing they were doing to <object>와 같은 간접 관계 표현은 동치인 직접 관계 표현으로 바꾸기 애매하다. 또한the object they held before running와 같이 temporal localization phrases와 관련한 object에 대한 간접 표현도 제거하였다. - temporal localization phrases를 쓰려면 적어도 한 개의 annotated frame이 영상 안에 존재해야 하는 조건을 추가하였다.
What did they do before running?와 같은 질문을 생성하려면running정보가 있는 frame이 적어도 하나는 존재해야 한다. (역자: 당연한 거긴 하지만) - 간접표현에서
backward용어가 잘못 사용된 것을forward로 수정하였다. - GT answer를 일반적인 단어인
action으로 대체함으로써What action were they doing the longest?와 같이 최상급 표현으로 된 action에 대한 program을 개선하였다.- 가장 긴 action이
sitting인 영상 하나를 생각하자. What was the person doing for the longest amount of time?프로그램은Superlative(max, Filter(video, [actions]), Subtract(Query(end, sitting), Query(start, sitting)))에서Superlative(max, Filter(video, [actions]), Subtract(Query(end, action), Query(start, action)))으로 바뀌었다.
- 가장 긴 action이
- 질문의 추론 단계를 최대 8단계로 제한하였다.
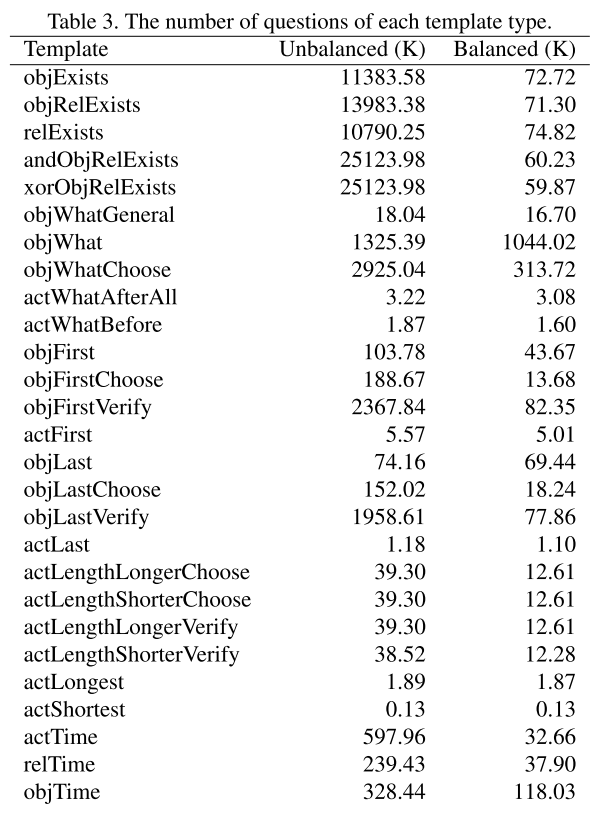
relTime및objTime유형의 문제는 sequencing 추론 유형으로 labeling했다.- 모든 답변은 소문자로 표시한다.
holding a blanket과 같은 action은 relationship(holding)과 object(blanket)으로 나눌 수 있다. 하지만 action은 여러 frame과 연관된 반면 object는 하나의 frame과만 연관된다. 그래서 action이 겹치는 경우가 있다면 동일한 질문에 여러 대답이 나올 수 있다. 이를 막기 위해 frame 기반 object-relationship 표현에 우선순위를 두었다. 그러면서actExists템플릿은 제거되었다.- 최상급 표현의 질문에서 답변은 처음 또는 마지막의 것으로 제한된다. 만약 어떤 사람이 들었던 물건들의 순서가 접시, 담요, 의자였다면 중간에 위치한 담요는 답변이 될 수 없다.
결과적으로 96.85M개의 질문-답변 쌍에서 bias를 제거하였더니 2.27M 쌍이 남았다.

3. Results
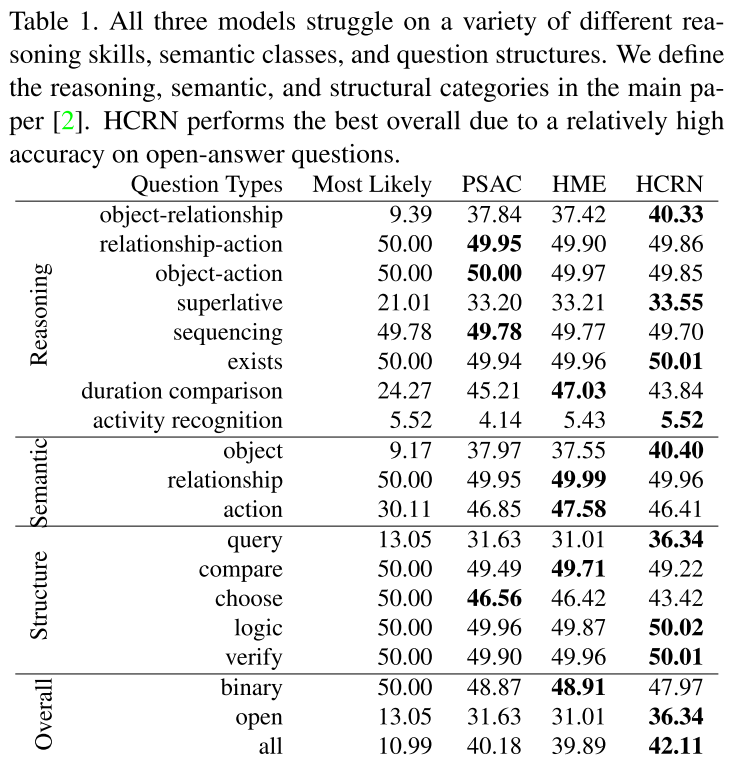
3.1. Performance across question types
HCRN이 좀 나은 성능을 기록했지만 2지선다형 문제에서 어느 모델도 50%를 넘기지 못했다. 1.0에서는 HME가 제일 잘 했었다.
3.2. Performance without visual data
어느 모델도 visual data를 썼을 때가 안 썼을 때보다 2% 이상 성능이 오르지 않았다. 이는 모델이 거의 대부분 visual feature가 아니라 언어적인 부분에 의존한다는 것을 보여준다.
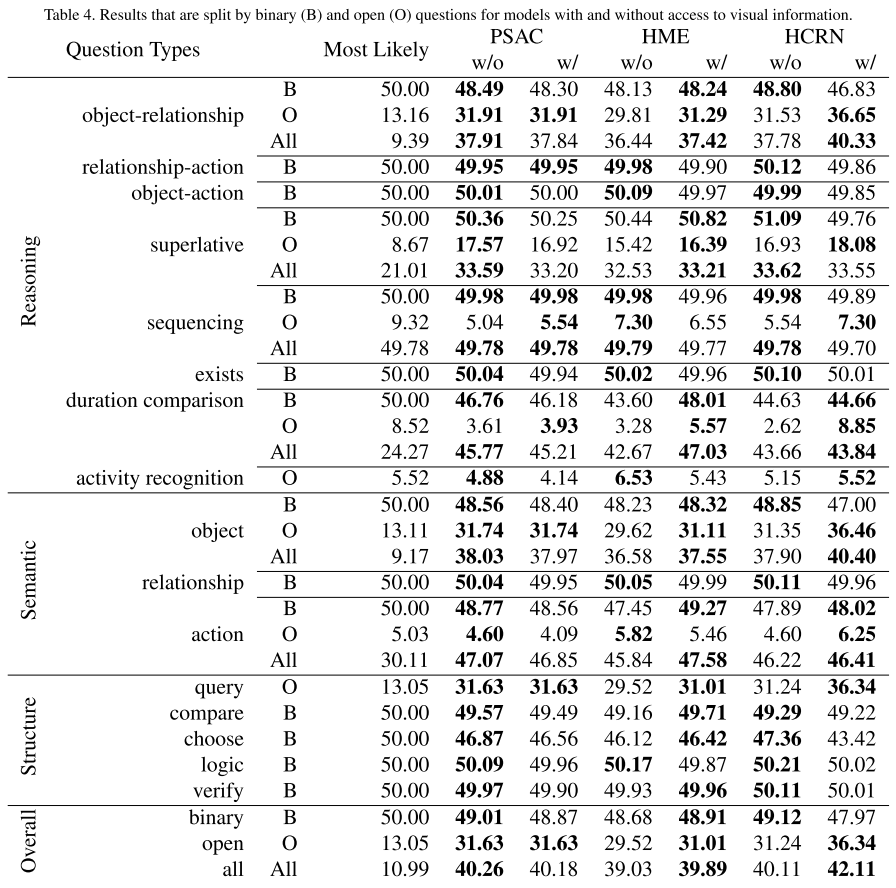
3.3. Model performance by binary and open answer questions
주관식 문제에서는 모든 모델이 binary일 때보다 못했다.
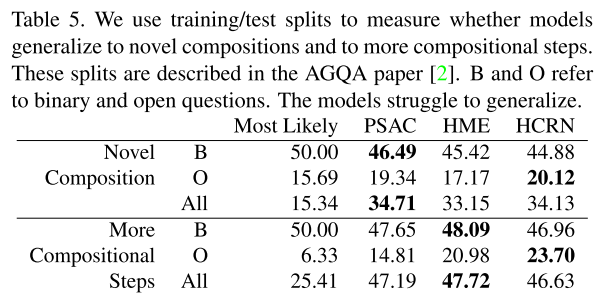
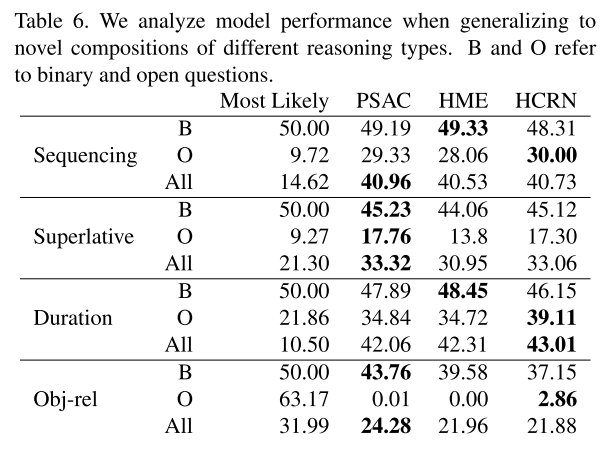
3.4. Generalization to novel compositions
이전과 마찬가지로 새로운 composition에서 힘을 잘 쓰지 못한다.
3.5. Generalization to more compositional steps
1.0 때와 마찬가지로 추론 단계가 적은 것과 많은 것으로 나누어 실험하였다. open-answer question에서는 모델이 “Most-Likely”를 이겼지만 binary에서는 그렇지 못했다.
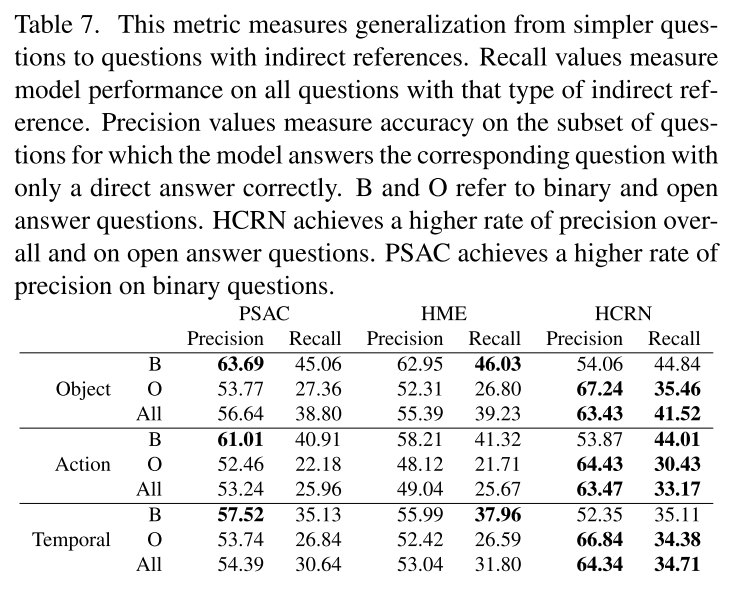
3.6. Generalization to indirect references
각 모델별로 잘하는 부분이 있고 아닌 부분이 있었다. PSAC와 HME는 binary question에서 더 높은 Precision을 기록했으며 HCRN은 open answer에서 Recall과 Precision값이 큰 차이를 보였다.
3.7. Performance by question complexity
Binary: 모델의 정답률과 추론 단계 사이에는 음의 상관관계가 있었다(0.44~0.64). Open answer: 미묘한 차이가 있다. 답변이 어떤 action인 선다형 문제(예: “그 사람은 가장 오랜 시간 동안 무엇을 하고 있었나요?”)는 구성 단계가 4개를 넘지 않으며, Most-Likely는 5.03%를 기록했다. 반면, 객관식 답변이 있는 주관식 질문의 94%는 구성 단계가 4개 이상이고 Most-Likely는 13.32%를 기록했다. 객관식(선다형) 문제에서 문제 복잡도와 정확도 사이에는 약한 양의 상관관계가 있다(0.41~0.52). visual 정보가 없을 때에도 양의 상관관계가 있다(0.42~0.59). 그러나 구성 단계, 템플릿 및 “Most-Likely” 점수 간의 연관성으로 인해 이러한 상관관계의 결과를 해석할 때는 주의가 필요하다고 밝히고 있다.
4. Discussion
- 본 논문에서는 몇 가지 개선 사항, 특히 더 강력한 balancing algorithm이 포함된 업데이트된 버전의 AGQA를 제안한다.
- 기존 AGQA 벤치마크의 결과와 유사하게, 실험한 모델들은 새로운 구성과 더 복잡한 문제로 일반화하는 데 어려움을 겪고 있음을 확인하였다.
- 또한, 실험한 모델 3개 중 1개 모델만이 시각적 데이터 없이 학습된 버전보다 1% 이상 정확도가 향상되었다.
- language-only 버전과 비교했을 때, 이 모델은 전반적으로 성능이 향상되지 않고 특정 문제 유형에서만 개선되었다.
- 세 모델 모두 language-only 버전에 비해 개선되는 정도가 제한적이기 때문에, 추가 지표를 통해 도출할 수 있는 시각적 구성 추론에 대한 결론은 이 세 가지 모델에 대해 제한적일 수 있다.
- 그러나 dataset 구성은 이러한 모델이 language bias에 의존하는 정도를 보여주며, 향후 모델에 대한 시각적 구성 추론에 대한 세분화된 분석을 수행할 수 있는 잠재력을 가지고 있다.