주의: 이 글을 읽는 여러분이, 만약 git을 많이 써 봐서 익숙한 것이 아니라면, 반드시 손으로 직접 따라 칠 것을 권한다. 눈으로만 보면 100% 잊어버린다.
저번 글에서 작업하던 것을 이어서 한다. 저번 글에서는 다른 local repo의 branch update까지 살펴보았다.
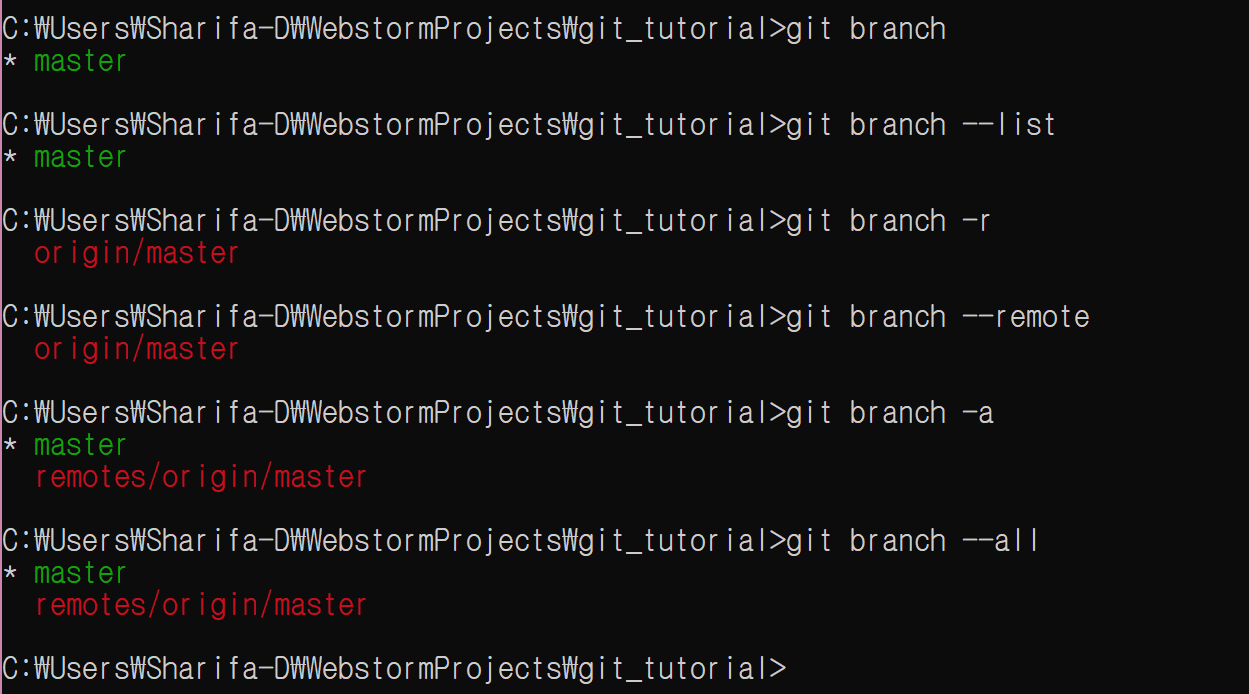
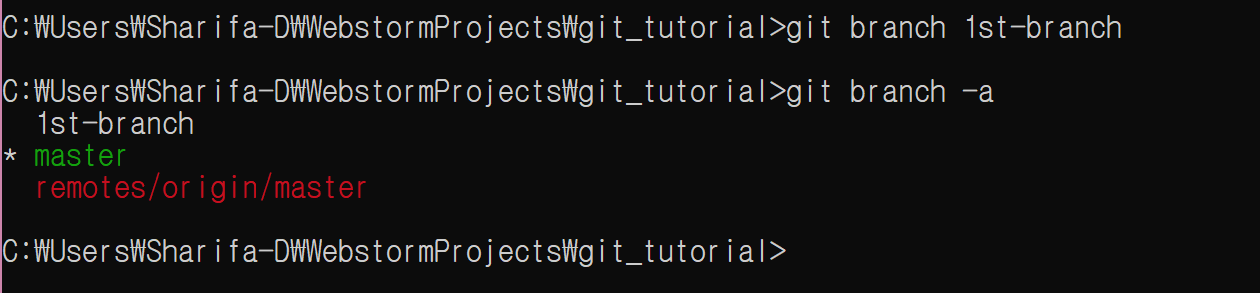
git add, git diff
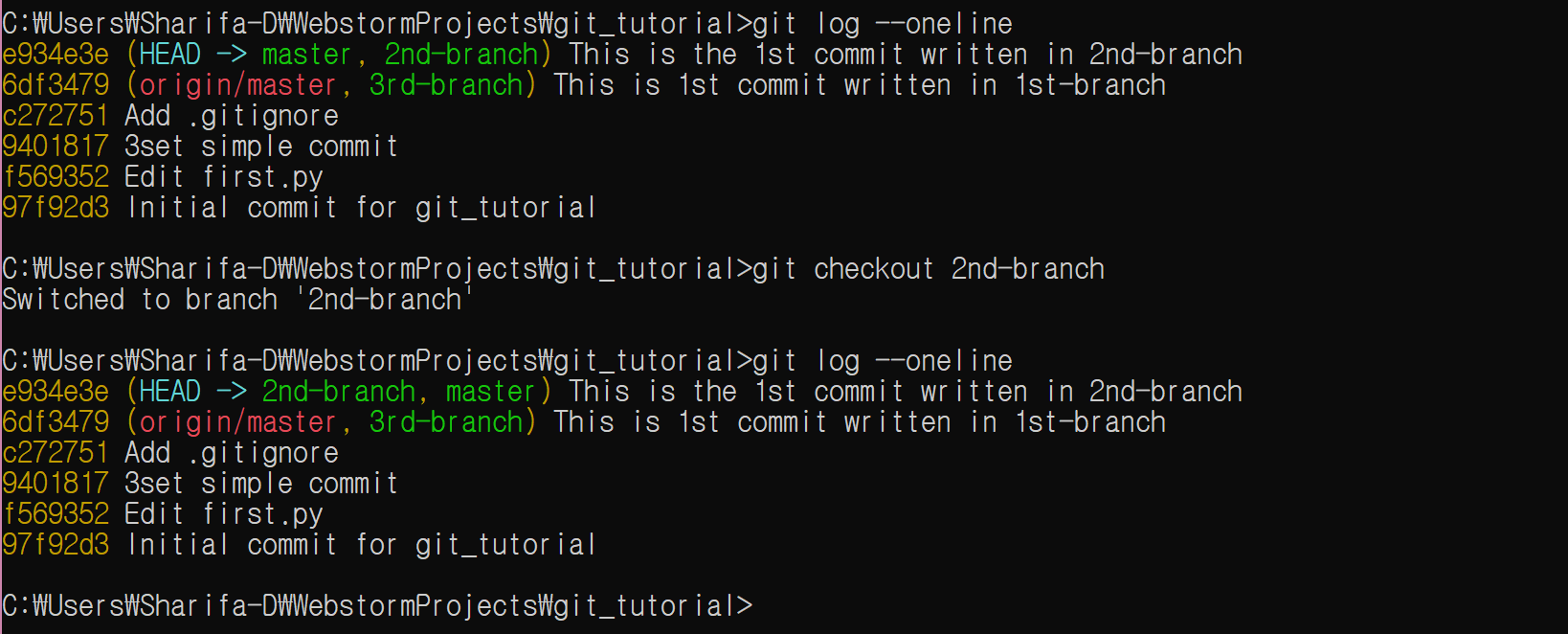
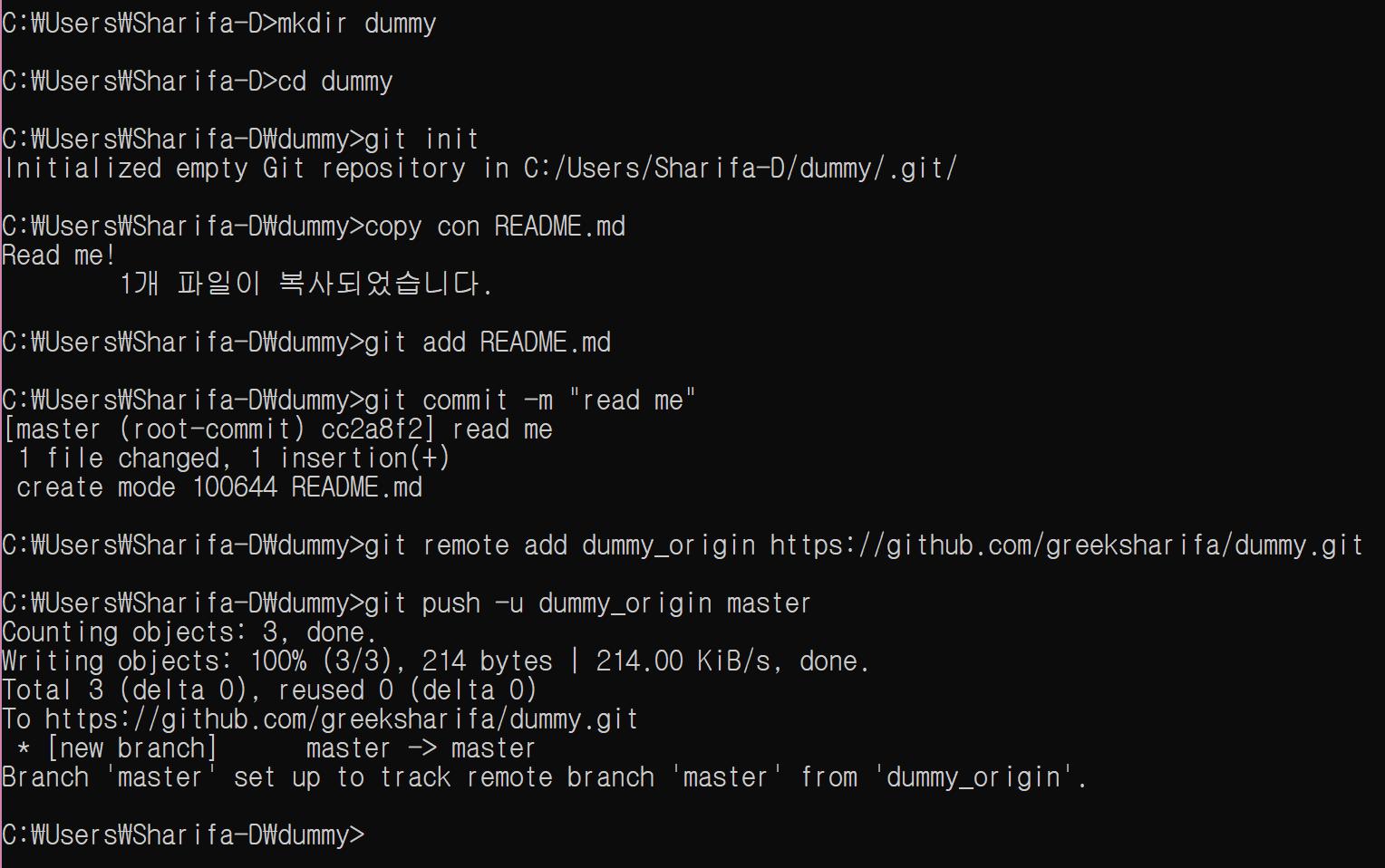
다시 git_tutorial_clone 디렉토리 밖으로 빠져 나와서, 원래 git_tutorial repository로 돌아가자. 그리고 업데이트를 한다.
cd ../../git_tutorial
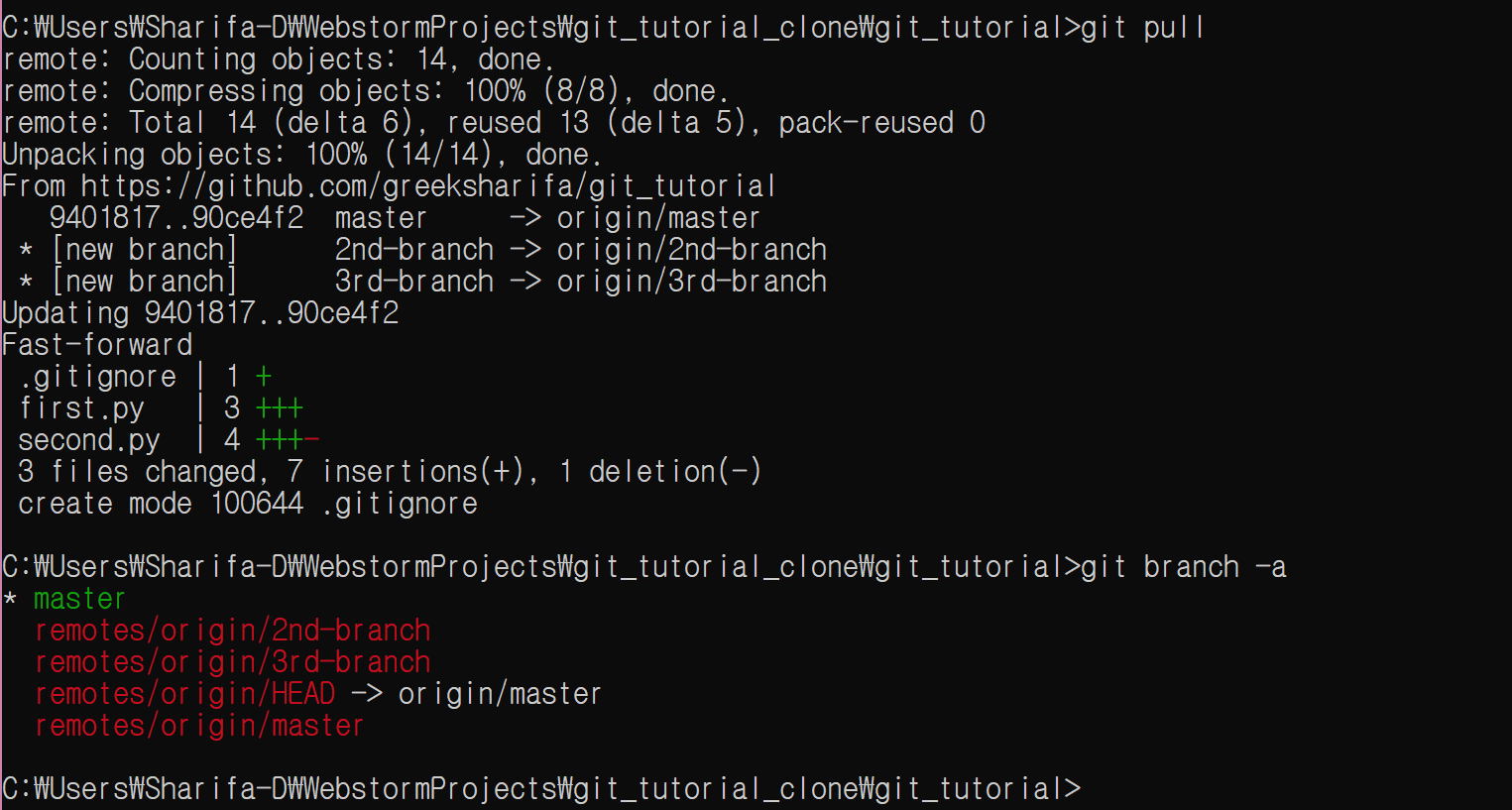
git pull
여기에서 git add 명령의 다양한 옵션을 설명했었다.
페이지를 옮겨다니기 귀찮을 것이므로 다시 한번 가져왔다.
| 명령어 |
Description |
| git add first.py |
first.py 파일 하나를 staging area에 추가한다. |
| git add my_directory/ |
my_directory라는 이름의 디렉토리와 그 디렉토리 안의 모든 파일과 디렉토리를 staging area에 추가한다. |
| git add . |
현재 폴더의 모든 파일과 디렉토리, 하위 디렉토리에 든 전부를 staging area에 추가한다. 규모가 큰 프로젝트라면 써서는 안 된다. |
| git add -p [<파일>] |
파일의 일부를 staging하기 |
| git add -i |
Git 대화 모드를 사용하여 파일 추가하기 |
| git add -u [<경로>] |
수정되고 추적되는 파일의 변경 사항 staging하기 |
사실은 위의 것 말고도 조금 다른 방법이 있다. 바로 와일드카드이다.
파일을 추가할 때 .py 파일을 전부 추가하고 싶다고 하자. 그러면 다음과 같이 쓸 수 있다.
git add first.py
git add second.py
…
그러나 이는 귀찮을 뿐더러 빠트리는 경우도 얼마든지 있을 수 있다. 이럴 땐 * 를 사용한다.
git add *.py
이를 사용하면 .py로 끝나는 모든 파일이 staging area에 추가된다.
표에서 위쪽 세 종류의 명령은 어려운 부분이 아니므로, 다른 옵션을 설명하겠다.
git diff
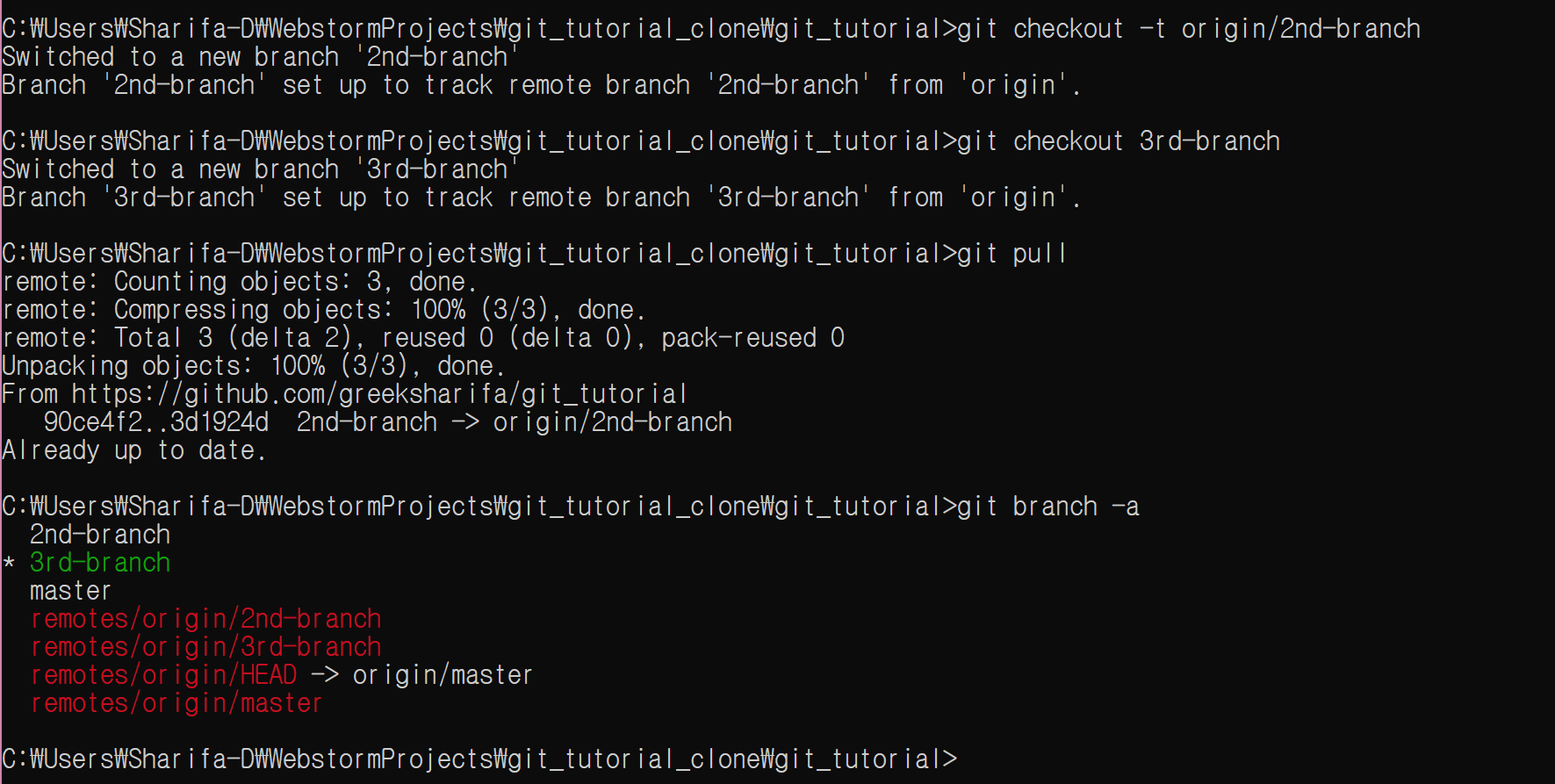
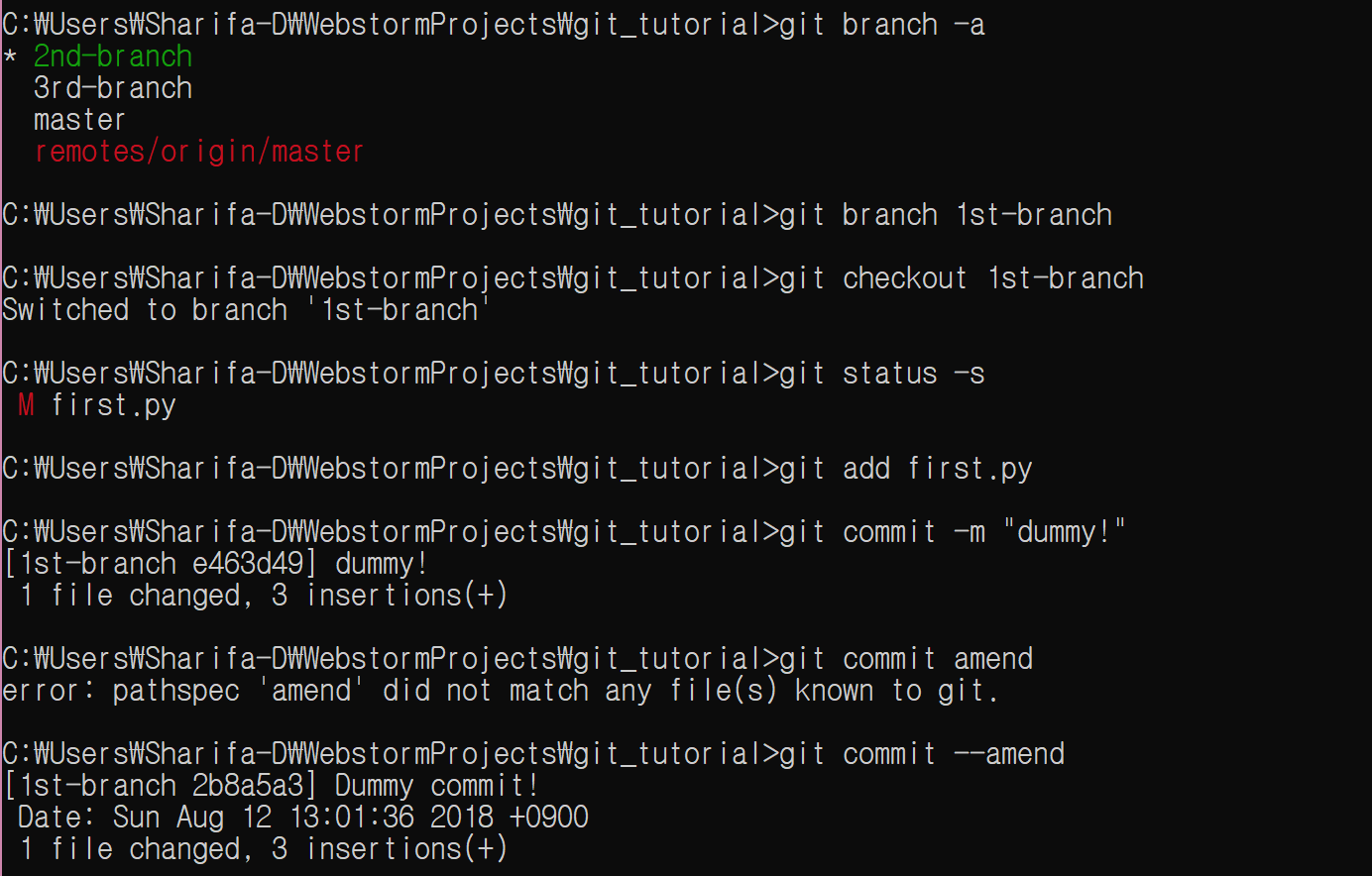
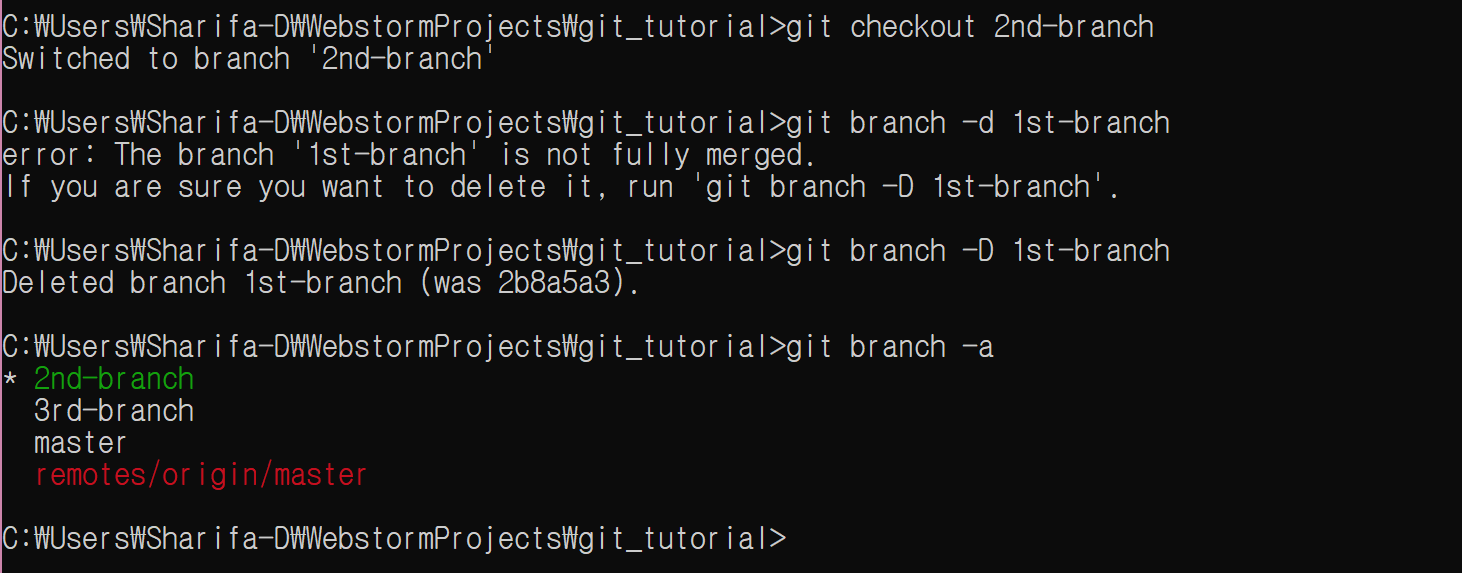
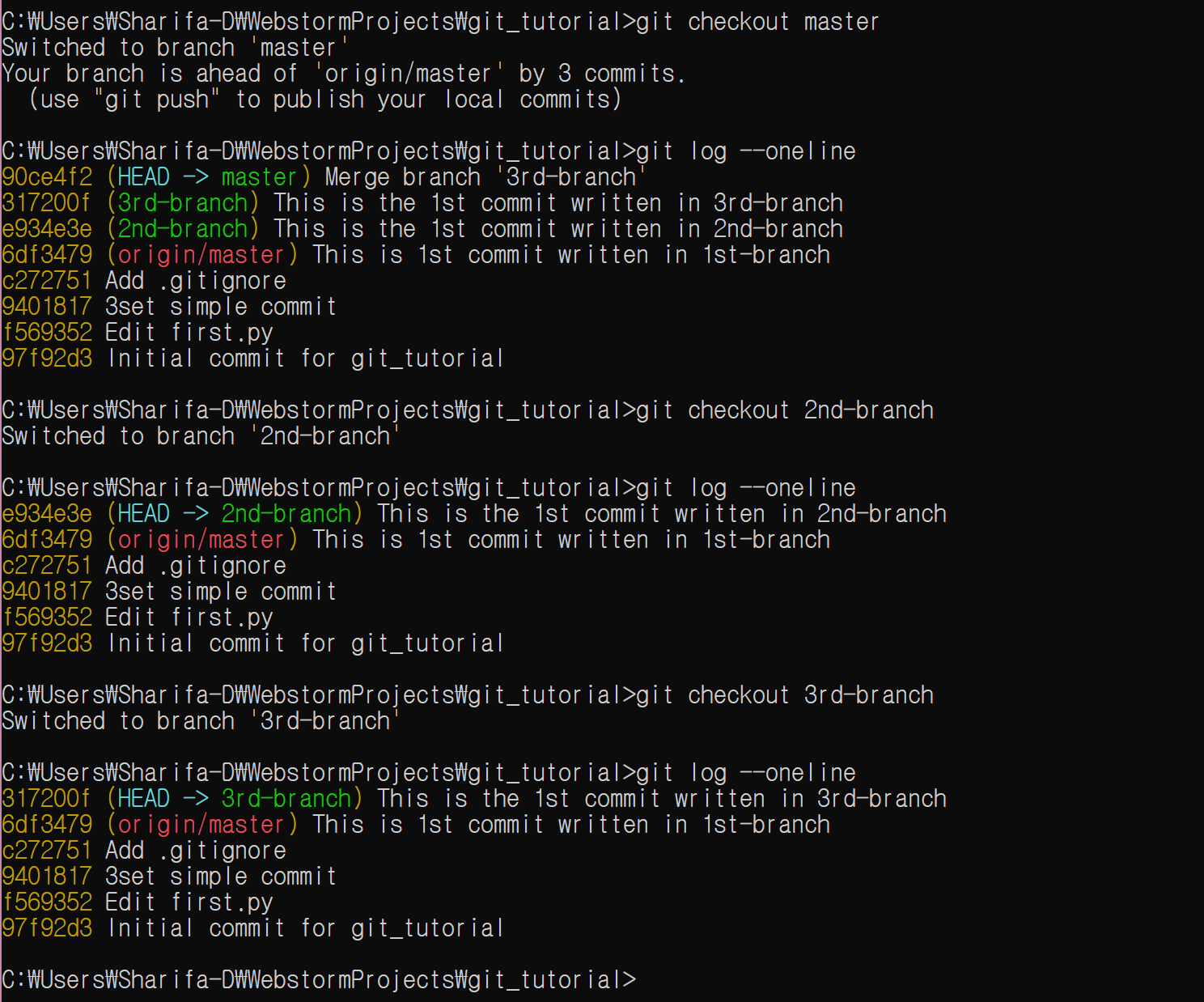
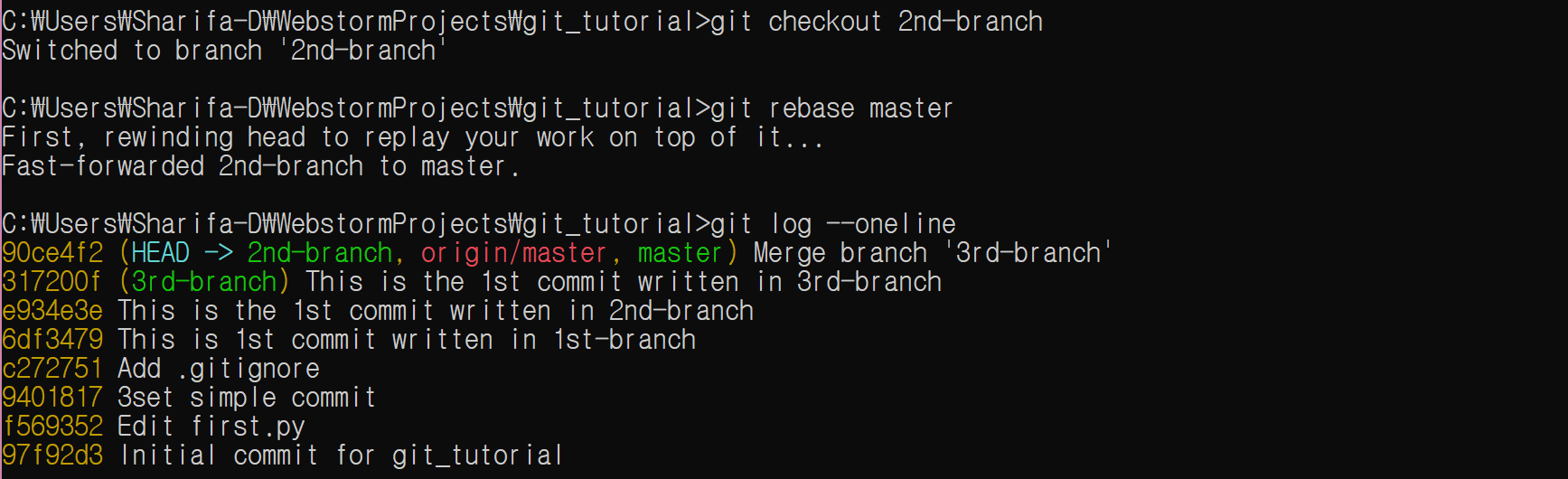
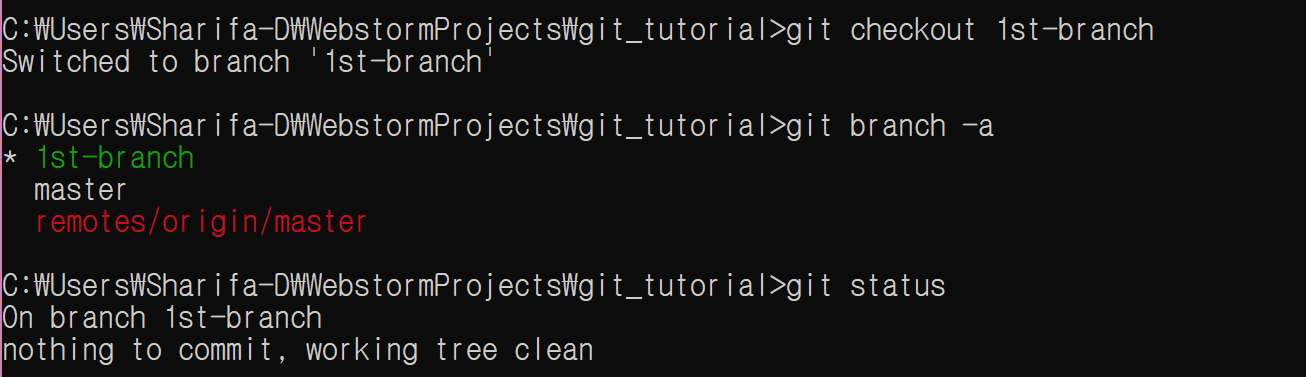
2nd-branch로 이동한다. master에는 직접 수정을 가하지 않는다.
git checkout 2nd-branch
그리고 second.py를 수정한다. 최종 결과물은 다음과 같다.
print('1st')
print("Why don't you answer me, git?")
print('2nd')
print("This is the 1st sentence written in 2nd-branch.")
print('3rd')
print('4th')
참고로 모든 파일의 마지막 줄에는 빈 줄은 추가해 두는 것이 commit log를 볼 때 편하다. 이유는 마지막에 빈 줄만 추가하고 staging시켜 보면, 마지막 줄의 내용을 삭제한 후 마지막 줄의 내용 그리고 빈 줄을 추가한 것처럼 나오기 때문이다.

별로 깔끔하지 않기 때문에 빈 줄을 추가하라. commit log 볼 때뿐만 아니라 나중에 편집할 때에도 조금 더 편하다.
IDE에 따라서는 빈 줄이 없으면 경고를 띄워 주기도 한다.
여기서 다음 명령을 입력하면 지금까지 어떤 수정사항이 있었는지 볼 수 있다.
git diff
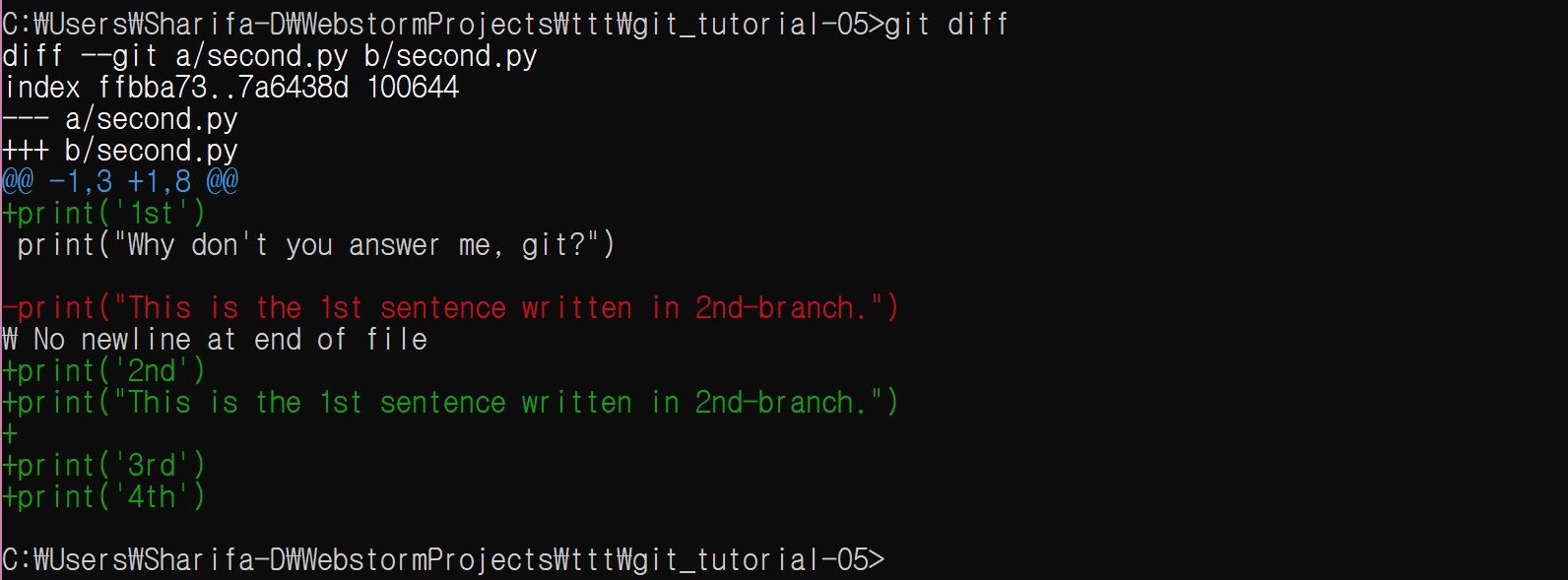
git diff는 아무 옵션 없이 입력하면 staging area에 반영되지 않은 수정사항을 보여준다.
git diff HEAD와 기능이 같다.
diff 역시 많은 옵션이 있는데, 간략히 살펴보도록 하겠다.
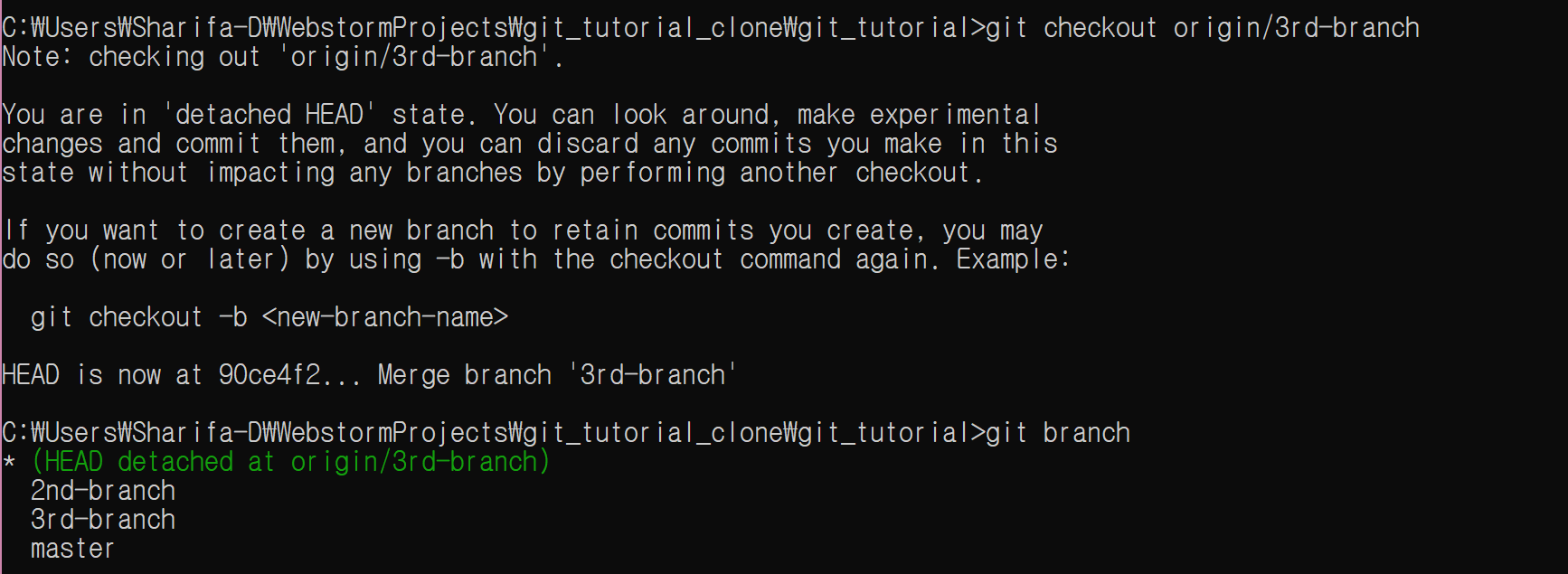
local branch 간 비교는 git diff [<branch1>] <branch2>와 같이 한다. 브랜치명을 하나만 쓰면 현재 local branch와 비교한다.
물론 remote branch와의 비교도 가능하다.
git diff 3rd-branch
git diff 2nd-branch origin/2nd-branch
커밋간 비교도 가능하다. git diff [<commit1>] <commit2>
역시 첫번째를 생략하면 현재 상태와 비교한다.
git diff 317200f
다른 옵션들은 나중에 설명하도록 하겠다. 일단은 여기까지만 하자.
git add -p [<파일>]
그리고 다음 명령을 입력한다. 지금은 second.py만 수정했기 때문에 해당 파일만 추가한다.
조금 위의 표에서 봤듯이 -p 옵션은 파일의 일부만을 staging(staging area에 올리는 것)하는 과정이다.
-p는 --patch의 단축 옵션이다.
git add -p second.py
그러면 다음과 같이 뜬다.
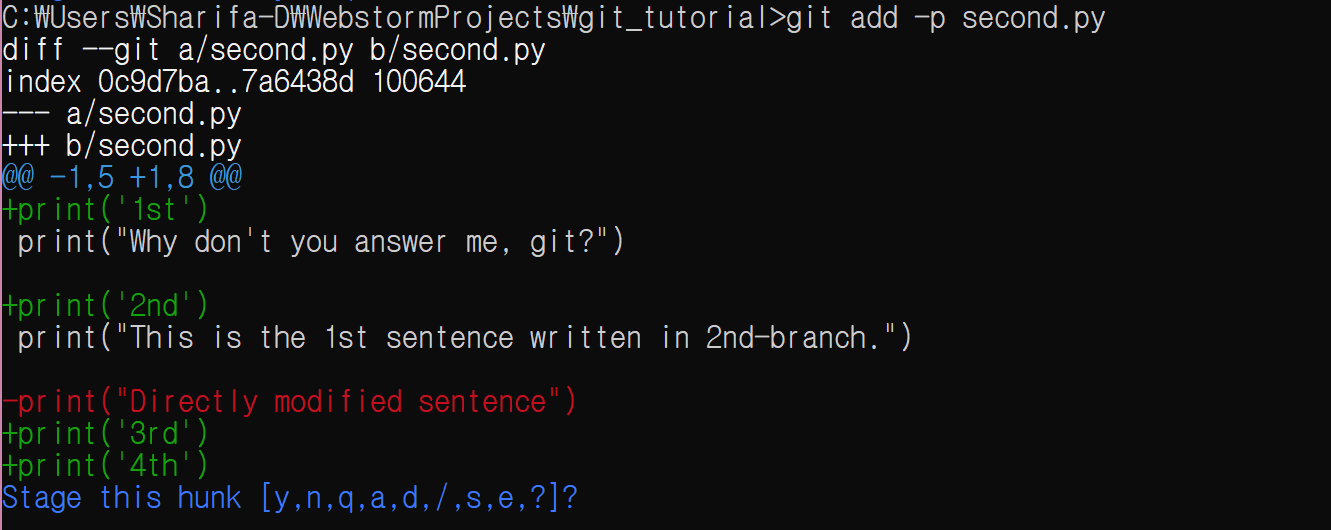
- 초록색 줄은 추가된 줄, 빨간색 줄은 삭제된 줄이다.
- 파일의 일부분만을 추가하는데, 모든 한 줄마다 따로 추가하는 것이 아니라 hunk라는 덩어리로 한 번에 staging area에 추가할지 말지를 결정한다. 만약에 git이 나눠준 hunk가 너무 크다면,
s를 입력하여 더 잘게 쪼갠다. 위의 경우는 너무 크기 때문에, 잘게 쪼갤 것이다.
- 만약에 무슨 옵션이 있는지 궁금하다면
?를 입력하라. 도움말이 표시된다.
| 명령 |
설명 |
| y |
stage this hunk |
| n |
do not stage this hunk |
| q |
quit; do not stage this hunk or any of the remaining ones |
| a |
stage this hunk and all later hunks in the file |
| d |
do not stage this hunk or any of the later hunks in the file |
| g |
select a hunk to go to |
| / |
search for a hunk matching the given regex |
| j |
leave this hunk undecided, see next undecided hunk |
| J |
leave this hunk undecided, see next hunk |
| k |
leave this hunk undecided, see previous undecided hunk |
| K |
leave this hunk undecided, see previous hunk |
| s |
split the current hunk into smaller hunks |
| e |
manually edit the current hunk |
| ? |
print help |
s, y, n, y를 차례대로 입력한다. s를 입력하면 3개의 hunk로 분리되었다고 알려 준다.
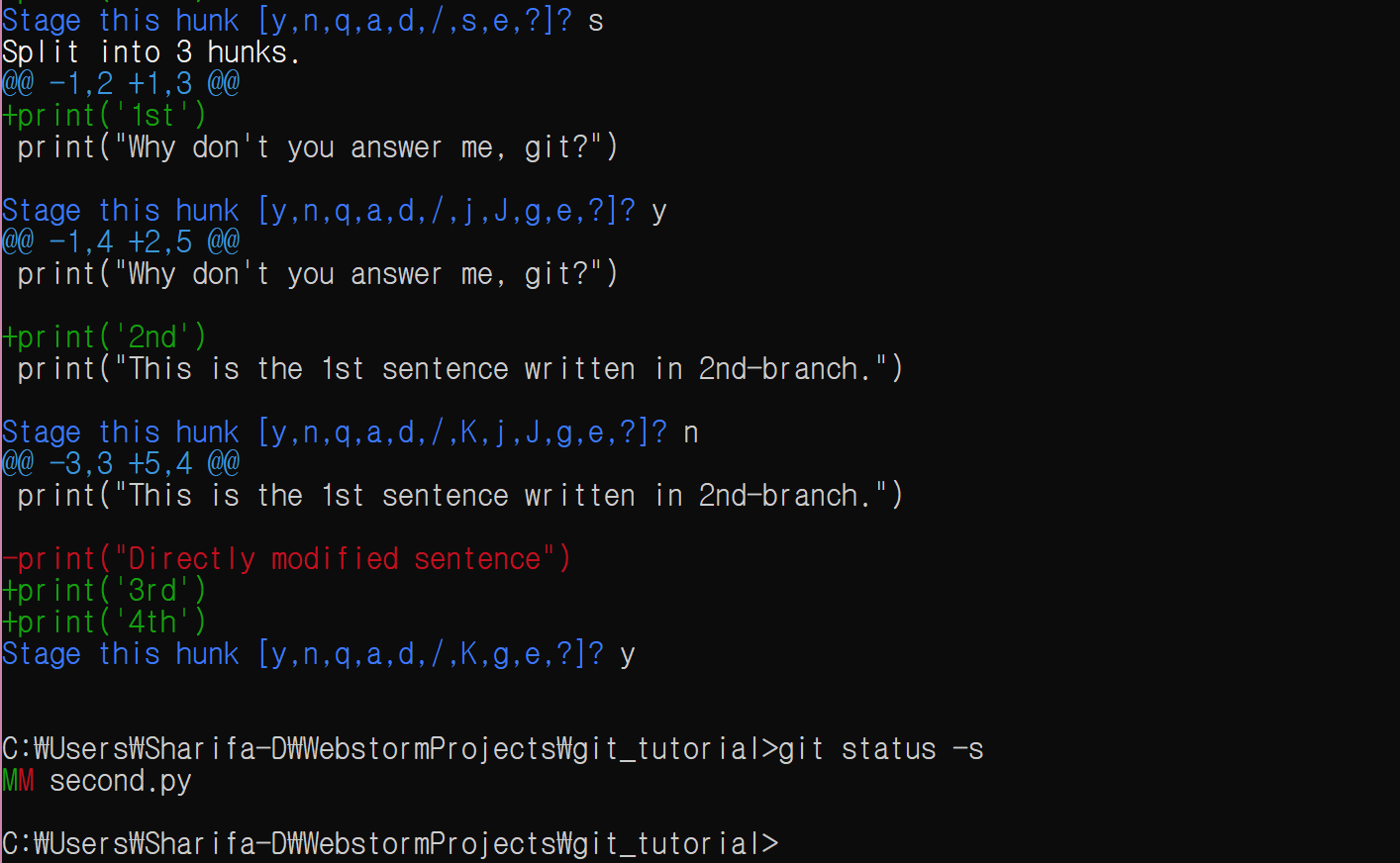
참고:
- untracked files는
-p를 할 때 나오지 않는다. 새로 추가된 파일이라면 먼저 staging area에 올린 후, 수정한 파일만을 p 옵션으로 처리하라.
- 디버깅을 위해 넣어 놓은 print문 등을 제거하고 push할 때 유용하다.
- 파일명으로 추가하는 대신
*나 .를 쓰는 것도 가능하다.
git add -i [<파일>]
대화형으로 파일 수정사항을 staging area에 추가하는 방법이다. first.py를 수정하자.
print("Hello, git!") # instead of "Hello, World!"
print("Hi, git!!")
print('1st')
print("This is the 1st sentence written in 1st-branch.")
print("This is the 1st sentence written in 3rd-branch.")
print('2nd')
그리고 git add -i first.py를 입력한 다음, 다음 그림대로 따라 해 보자.
중간쯤에 아무것도 안하고 Enter만 입력한 곳이 있는데, 이렇게 하면 선택한 파일들이 staging area에 추가된다.
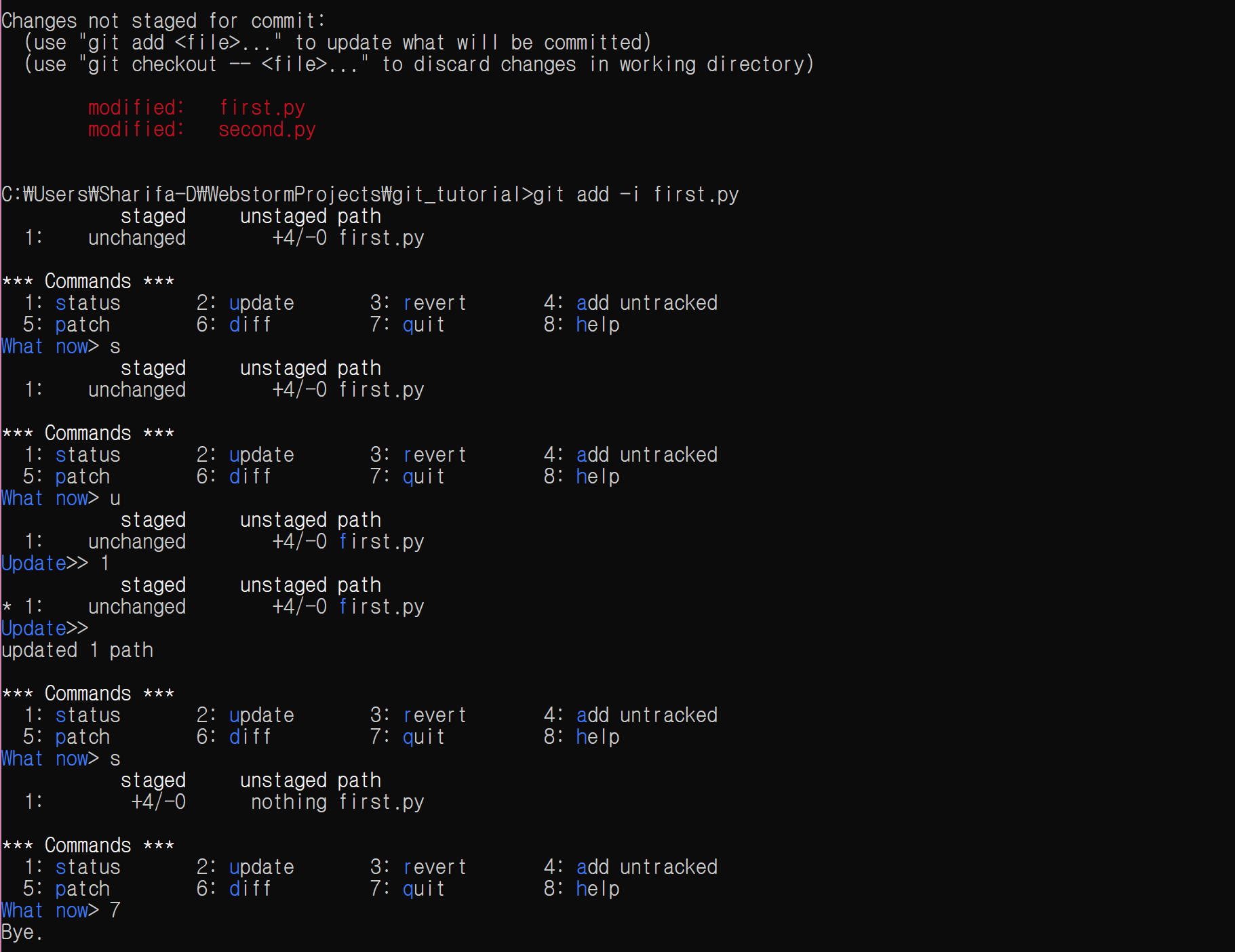
파란색으로 강조된 부분을 잘 따라가면 이해하기 어렵진 않을 것이다.
위와 같이 하면 first.py 파일이 staging area에 추가된다.
git add -u [<경로>]
git add .와 git add -u는 하는 일이 비슷하지만, 차이점은 다음과 같다.
git add .는 현재 디렉토리의 모든 변경사항을 staging area에 추가한다. untracked files를 포함한다.git add -u는 업데이트(‘u’)된 파일, 즉 untracked files는 제외하고 staging area에 추가한다.
뒤에 경로를 추가하면 해당 디렉토리 혹은 파일들에 대해서만 위의 작업을 수행한다.
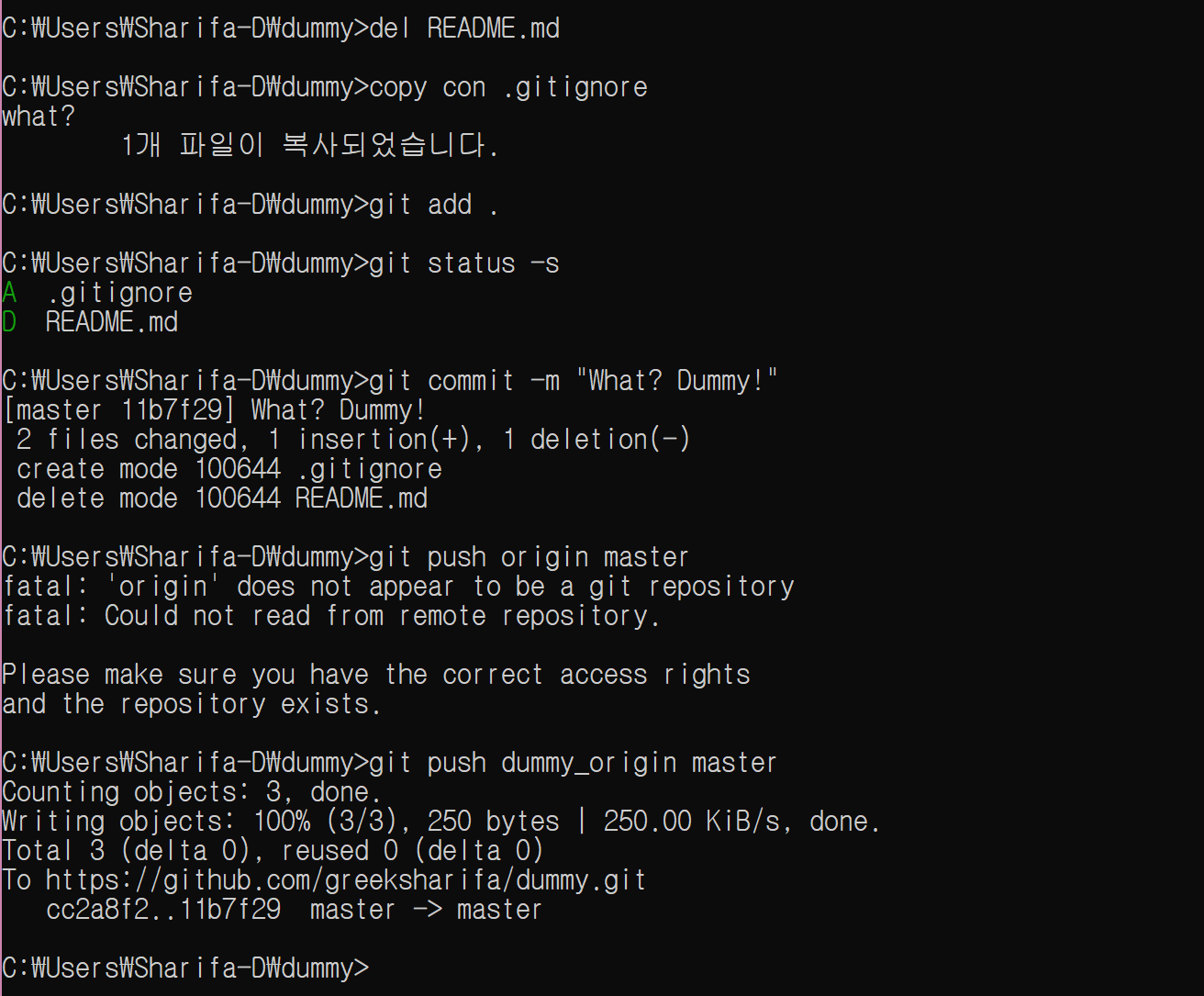
아무 파일이나 하나 추가한 다음 차이를 확인하자. first.py 파일 끝에 다음을 추가하고, dummy1.txt 파일을 생성만 하자.

-s 옵션을 줄 때 ‘??’는 untracked files를 의미한다.
이제 git add .로 staging area에 추가해 보자.
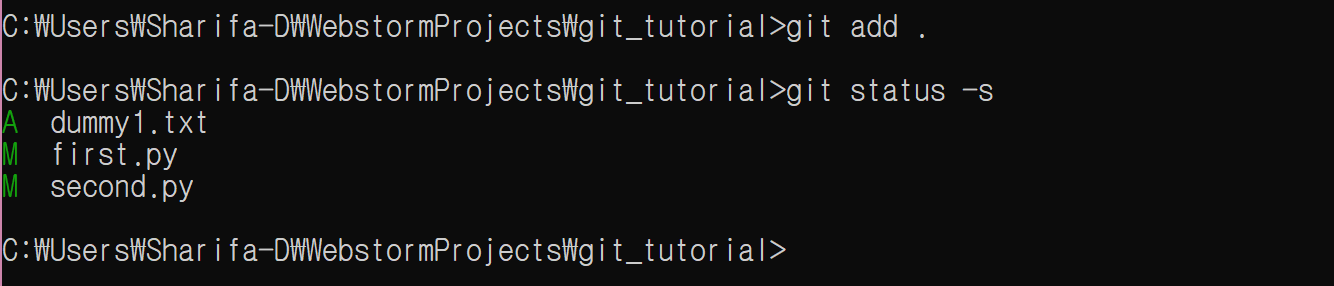
모두 추가되었다.
이제 조금 전과 비슷하게 second.py 파일의 끝에 다음을 추가하고 dummy2.txt 파일을 생성만 하자.

untracked files 상태인 dummy2.txt는 여전히 추가되지 않은 상태로 남아 있는 것을 볼 수 있다.
git commit: 중급
git commit에도 옵션은 굉장히 많으나, 여기서는 -v 옵션과 tag 두 가지만 설명한다.
-v 옵션
-v 옵션은 git add의 -p와 비슷하다. 즉 수정사항을 미리 볼 수 있는데, git diff를 밑에 보여주는 것과 비슷하다.
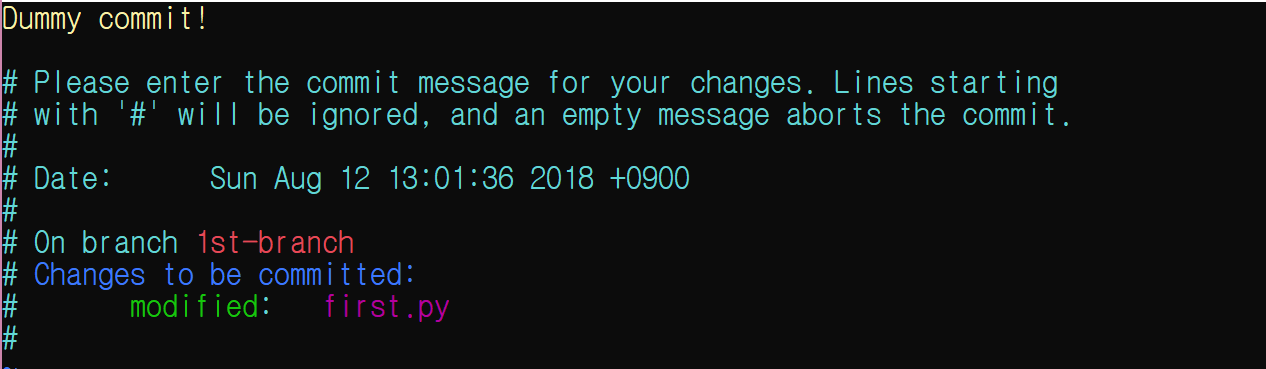
git commit -v
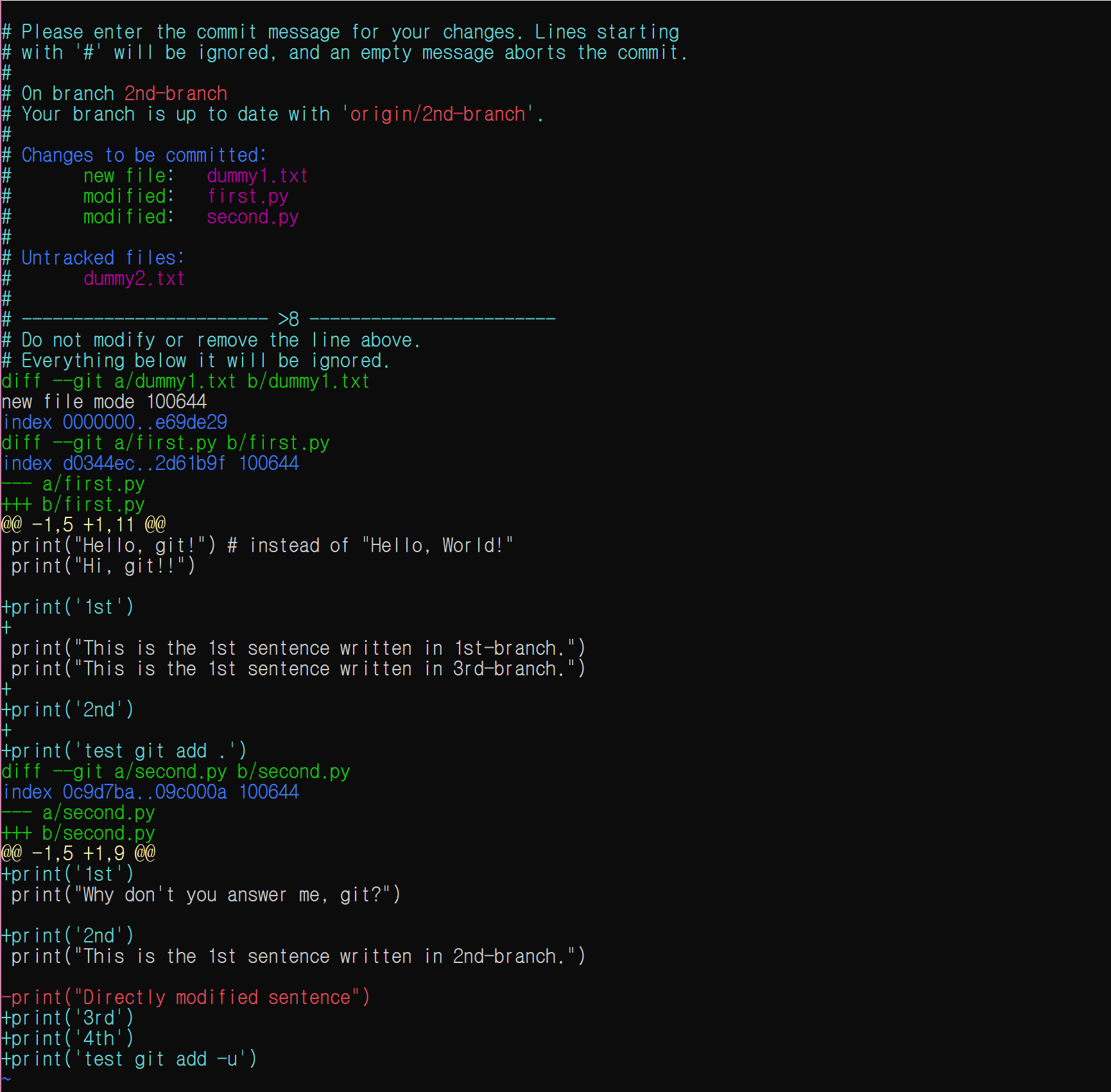
i 입력 후, 커밋 메시지는 적당히 입력하고 ESC, :wq 를 입력하라. 무엇인지 까먹지 않았기를 바란다.
tag
commit에는 태그를 붙일 수 있다. 여러분이 블로그에서 볼 수 있는 그 태그와 같은 기능이다.
태그에는 두 종류가 있는데, 단순 태그 기능만 하는 Lightweight 태그와 태그를 만든 사람, 시간, 메시지, 서명 정보 등을 저장하는 Annotated 태그가 있다.
먼저 Lightweight 태그는 다음과 같이 붙일 수 있다. 뒤에 commit 코드를 명시하지 않으면 현재 commit에 붙는다.
git tag v0.7
버전 정보를 저장할 때 태그로 하면 편하다.
현 repo의 태그 목록을 확인하려면 다음을 입력한다.
git tag
태그의 정보를 자세히 확인하고 싶다면 다음과 같이 입력한다.
git show v0.7
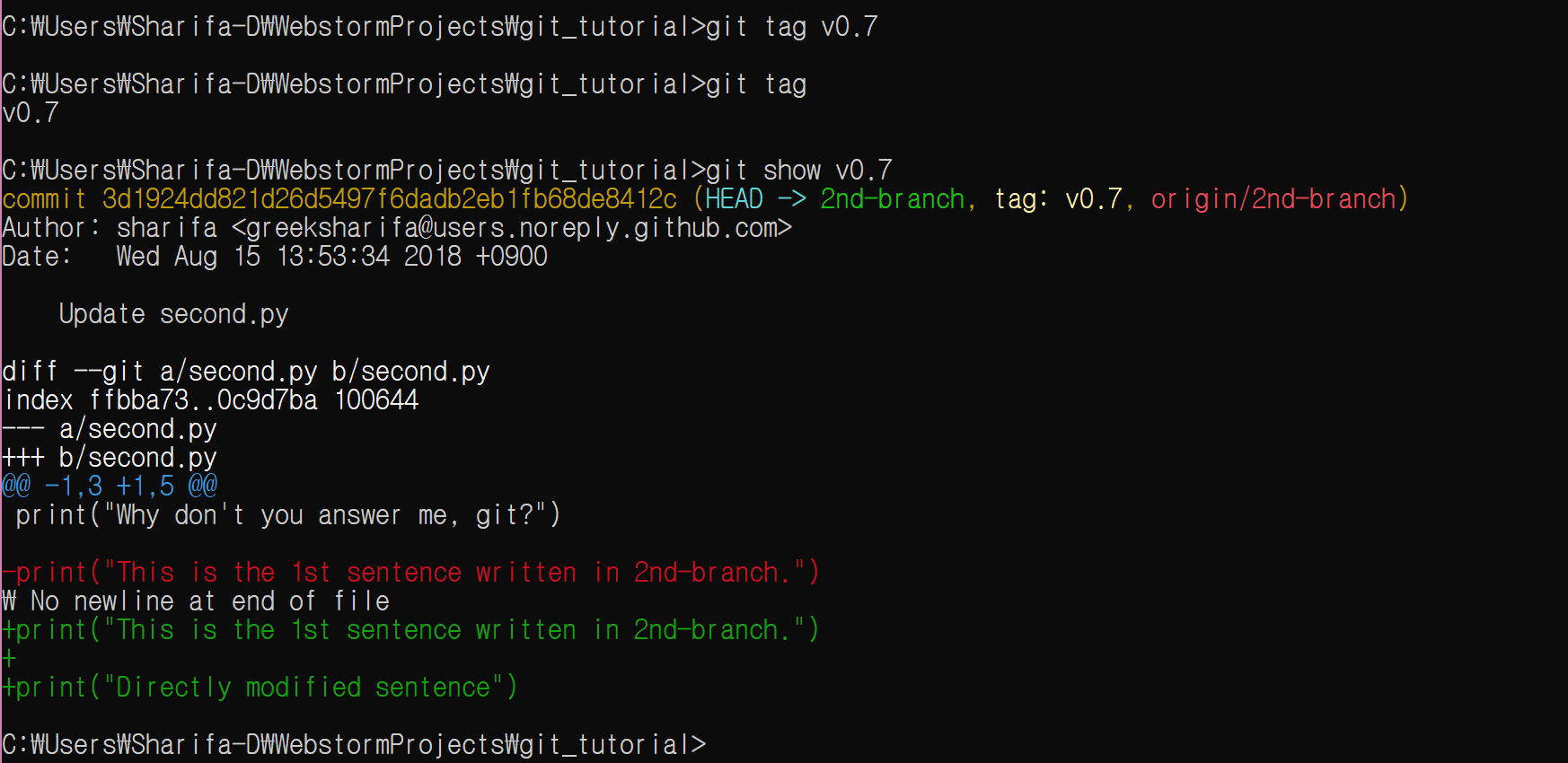
태그를 삭제하려면 -d 옵션을 붙인다.
git tag -d v0.7
Annotated 태그를 붙일 때에는 -a 옵션을 사용한다. 메시지를 입력하려면 -m 옵션을 붙인다.
메시지를 입력하지 않으면 일반적인 커밋 메시지를 쓰지 않았을 때처럼 vim 편집기가 열린다.
git tag -a v0.7 -m “git tutorial ver 0.7”
뒤에 commit 코드를 명시할 경우 이전 커밋에도 태그를 붙일 수 있다.
git tag v0.5 90ce4f2
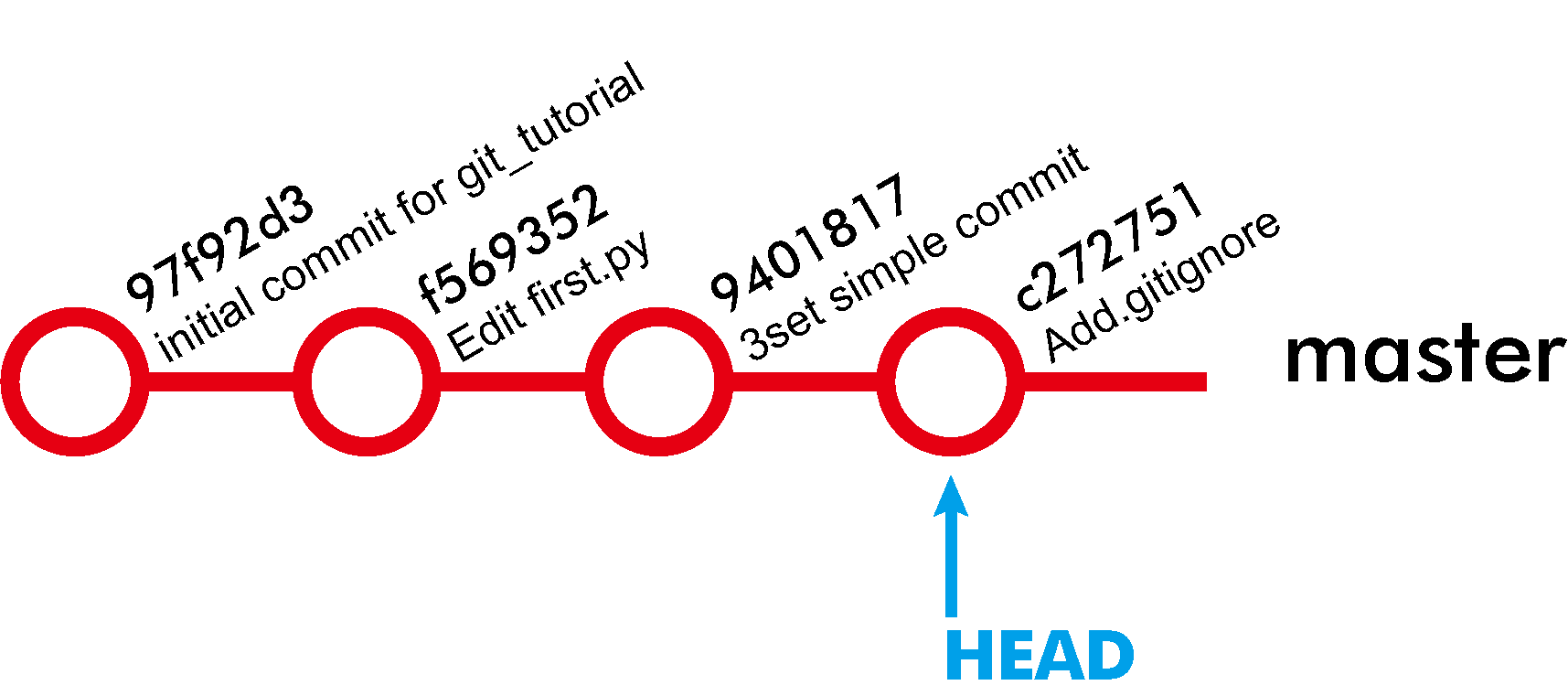
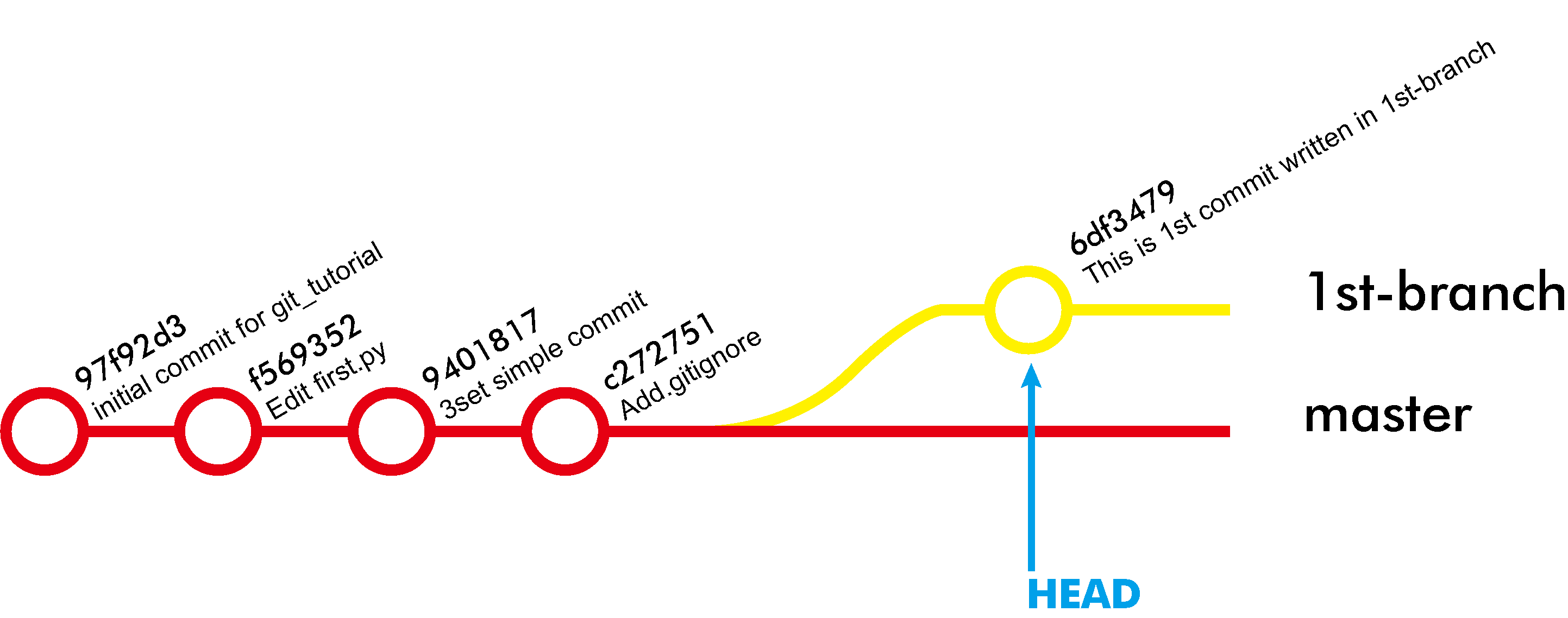
당연하게도 여러분이 직접 커밋을 만들었다면 커밋 코드는 다를 것이다. git log로 먼저 확인 후 원하는 커밋에 태깅하도록 한다.
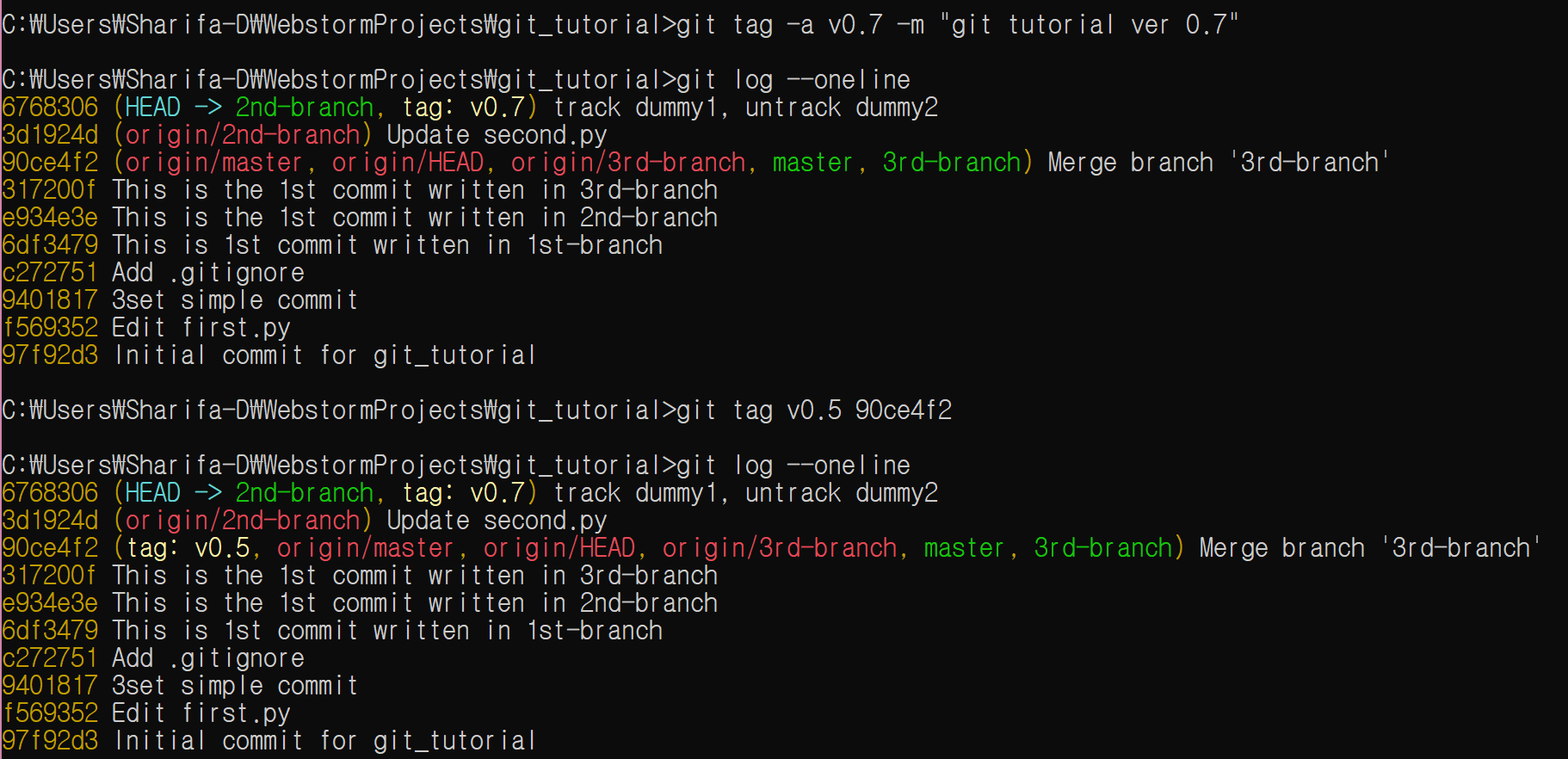
그림에서 커밋 로그에 ‘tag: v0.5’ 등이 생겼음을 확인하라.
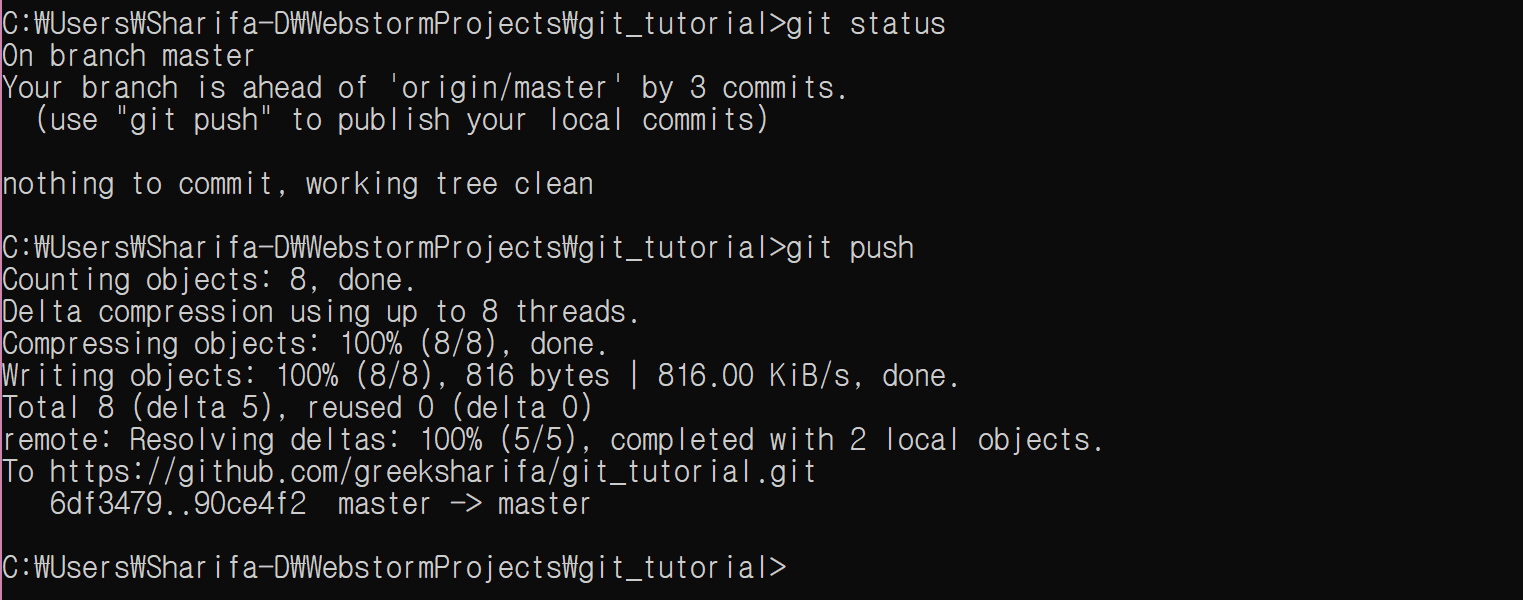
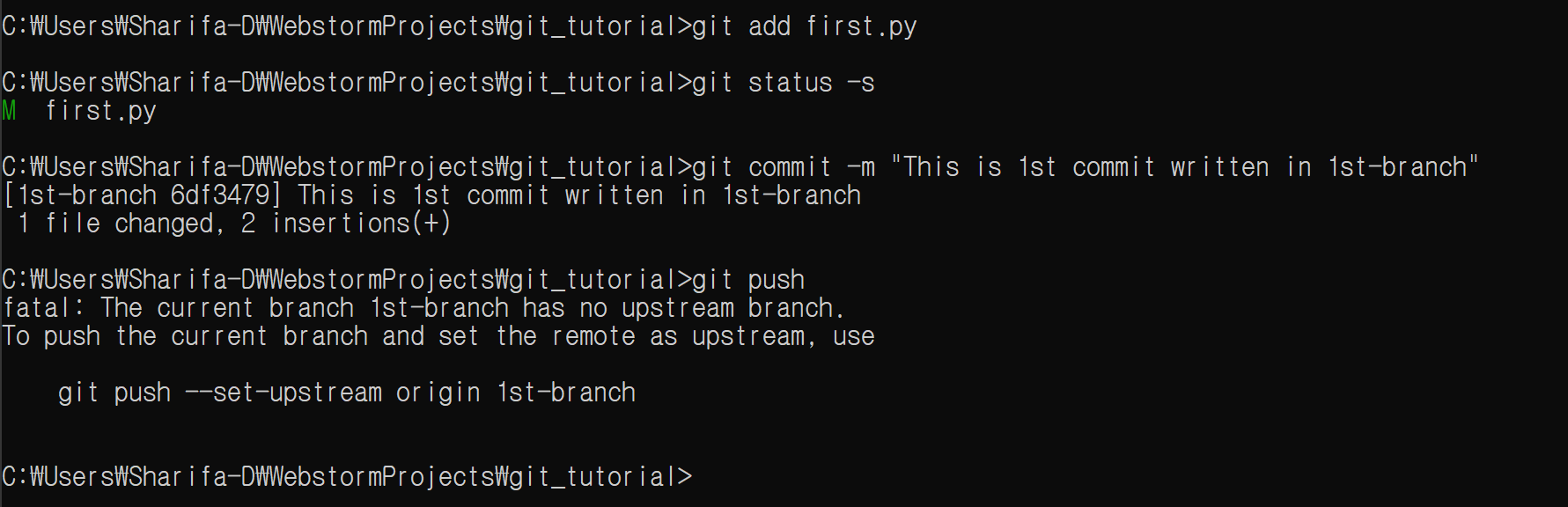
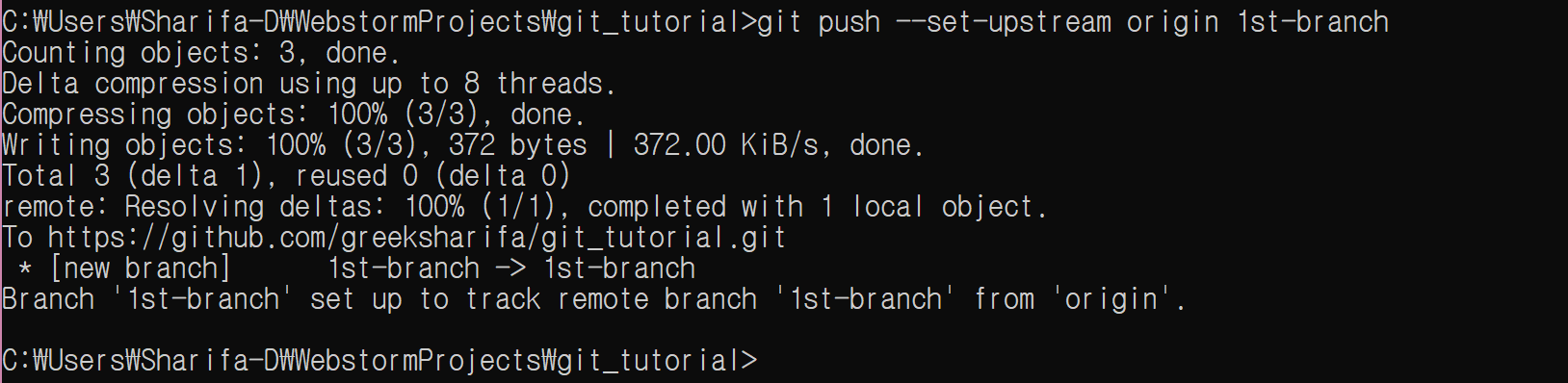
이제 push를 하자.
git push
그러나 태그는 git push명령에 자동으로 remote repo에 올라가지 않는다.
태그는 따로 올리면 된다.
git push origin v0.5
git push origin –tags
--tags 옵션은 모든 태그를 remote repo에 올린다.
.gitignore 중급
사실 .gitignore 사용법은 어렵지 않다. 파일을 제외하거나, 디렉토리를 제외하거나, 와일드카드를 사용하여 여러 파일을 staging area에 올라가는 것을 막는 것뿐이다. 각각은 다음과 같이 사용한다.
.gitignore 파일의 각각 다른 줄에 추가하면 된다.
이 내용은 .gitignore 파일에 추가하지 않아도 된다.
dummy_txt
data/
*.tar
data/raw/*
*dummy*
대신 한 가지 흔히 하는 실수를 다루도록 하겠다. 데이터 파일이나 설정 파일, IDE가 자동으로 생성한 파일 등은 git add .를 생각없이 사용하다 보면 어느새 remote repo에 올라가 있는 경우가 많은데, 이 파일은 나중에 .gitignore 파일에 추가해도 repo에서 자동으로 사라지지 않는다.
예제를 하나 갖고 왔다. 우선 git_tutorial 디렉토리를 PyCharm IDE로 열거나, 아니면 .idea/라는 디렉토리를 하나 만들어 보자.
PyCharm으로 열면 자동으로 .idea/라는 디렉토리가 생겨버린다.
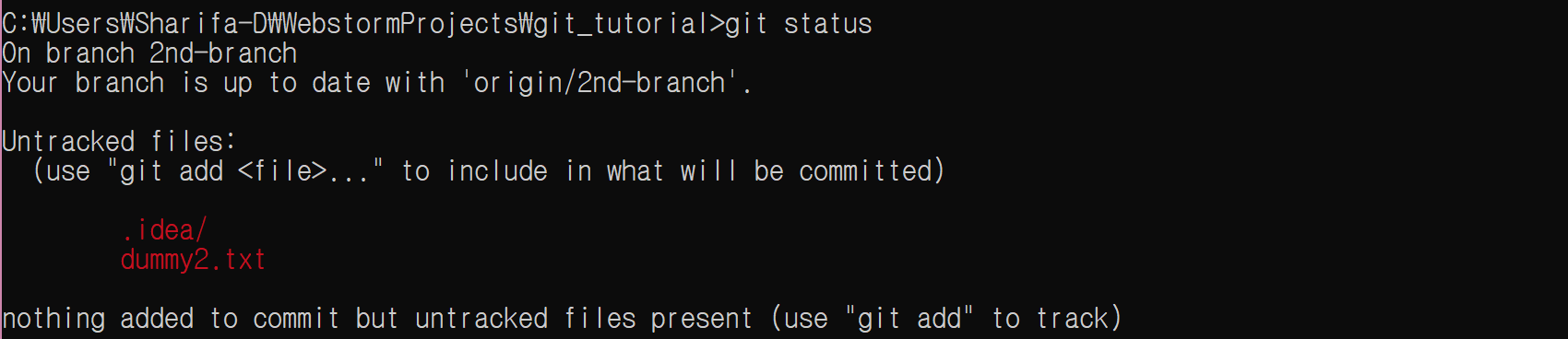
이를 그냥 생각없이 추가하면 직접 생성하지도 않은 수많은 파일들이 추가된다.
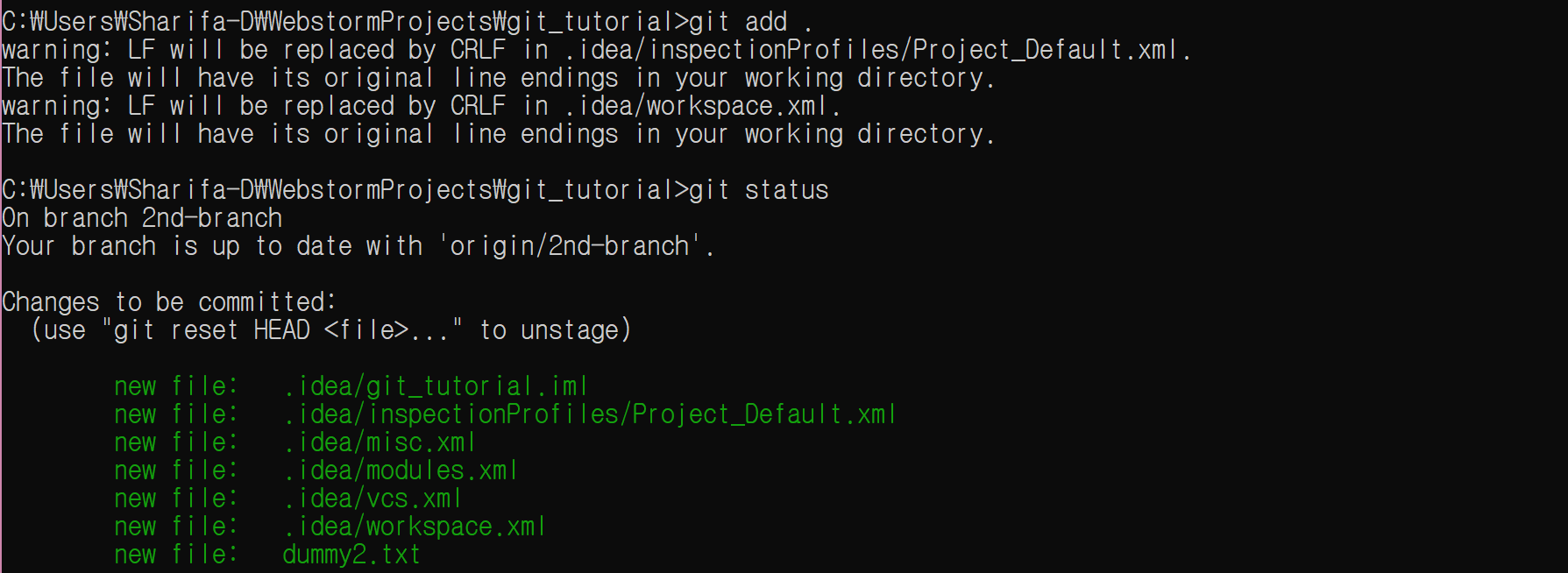
그리고 한번 remote repo에 올려 보자.
git commit -m “Doong!”
git push
이건 그다지 좋은 상황이 아니기 때문에, remote repo에서 제거하려고 한다. 서둘러 .gitignore 파일에 다음을 추가한다.
그리고 3종 세트를 입력하자.
git add .gitignore
git commit -m “edit .gitignore: remove .idea/ directory”
git push
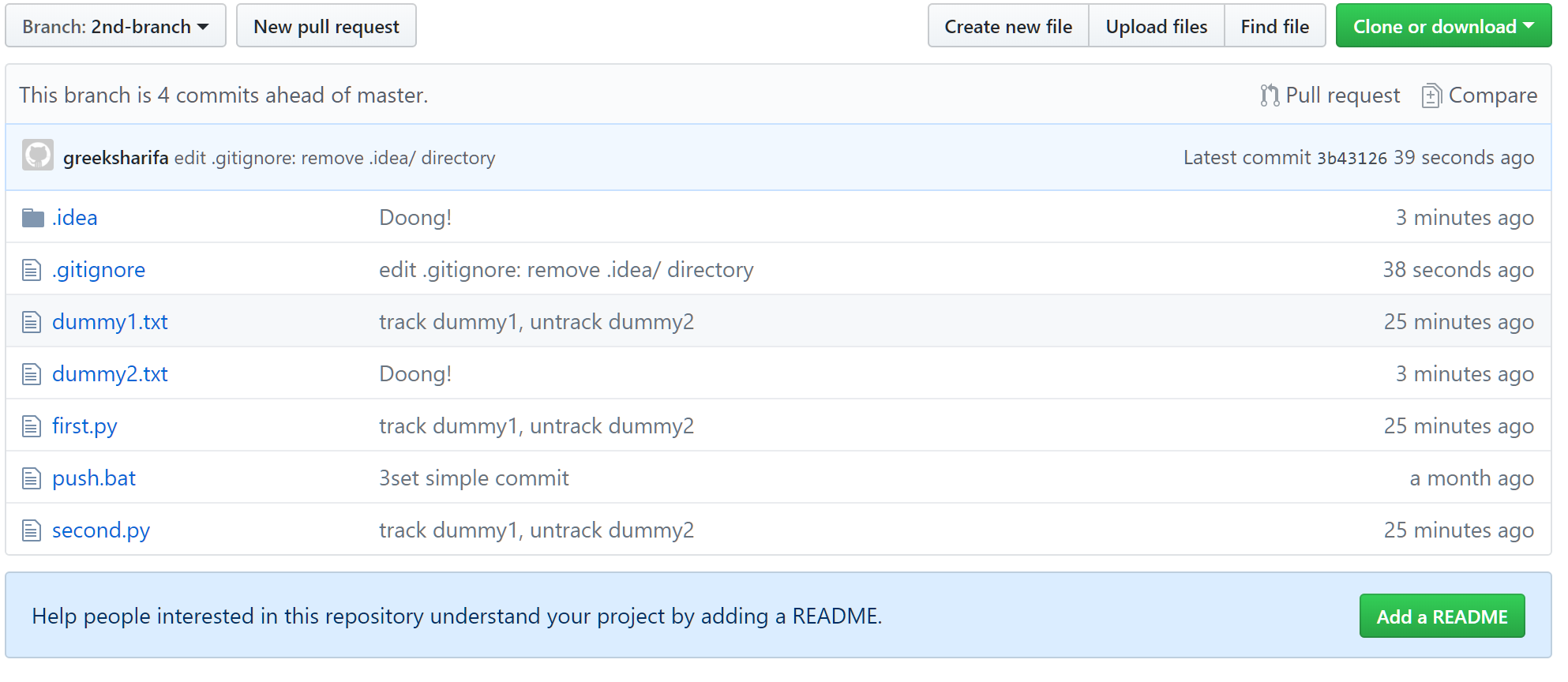
물론 앞서 말한 대로, 자동으로 지워지지 않는다.
이럴 때는 어디선가 본 듯한 명령을 사용한다.
git rm –cached .idea/ -r
git rm –cached *dummy*
디렉토리를 제거하려고 할 때는 -r 옵션을 사용한다.
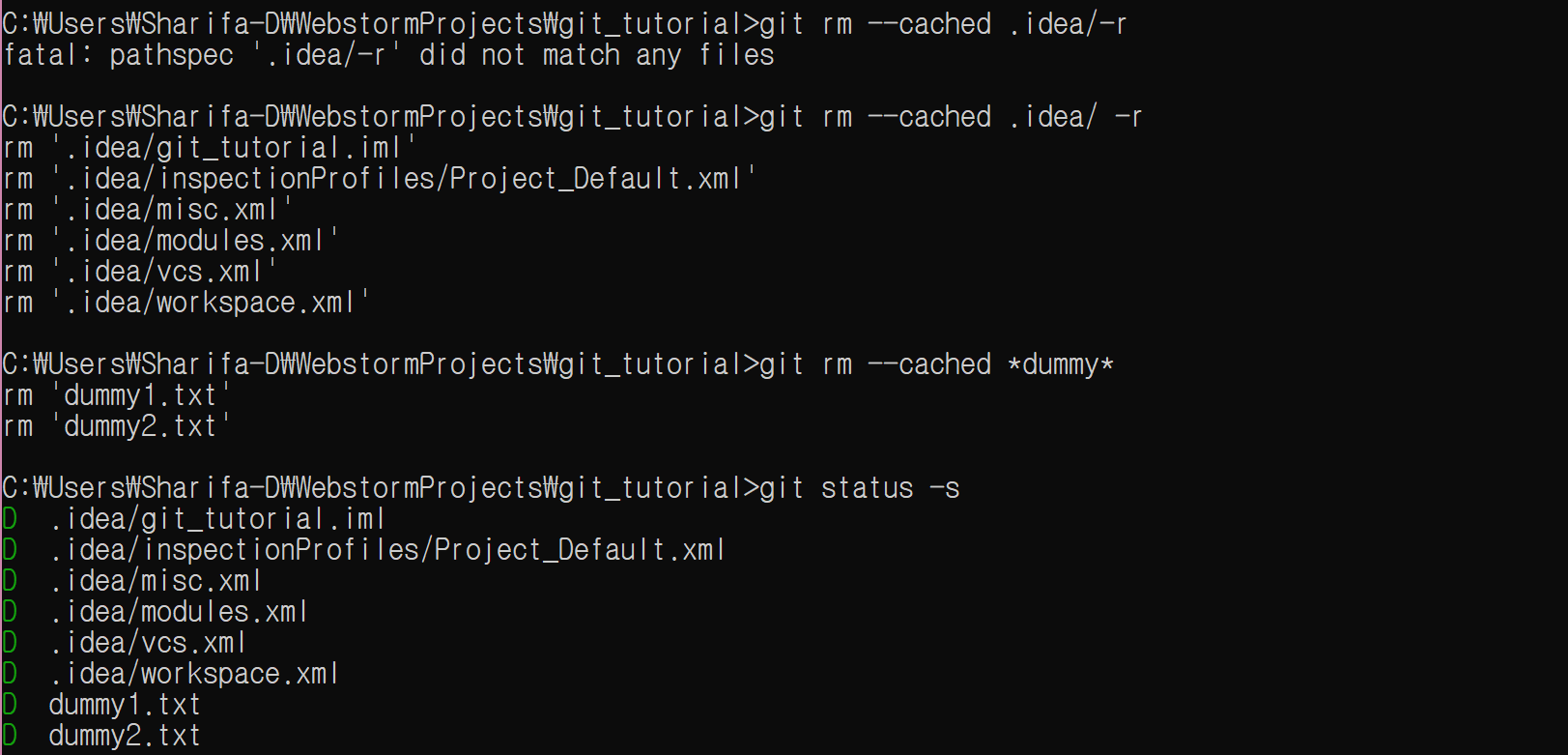
이제 push를 한다. git add 명령은 필요없다.
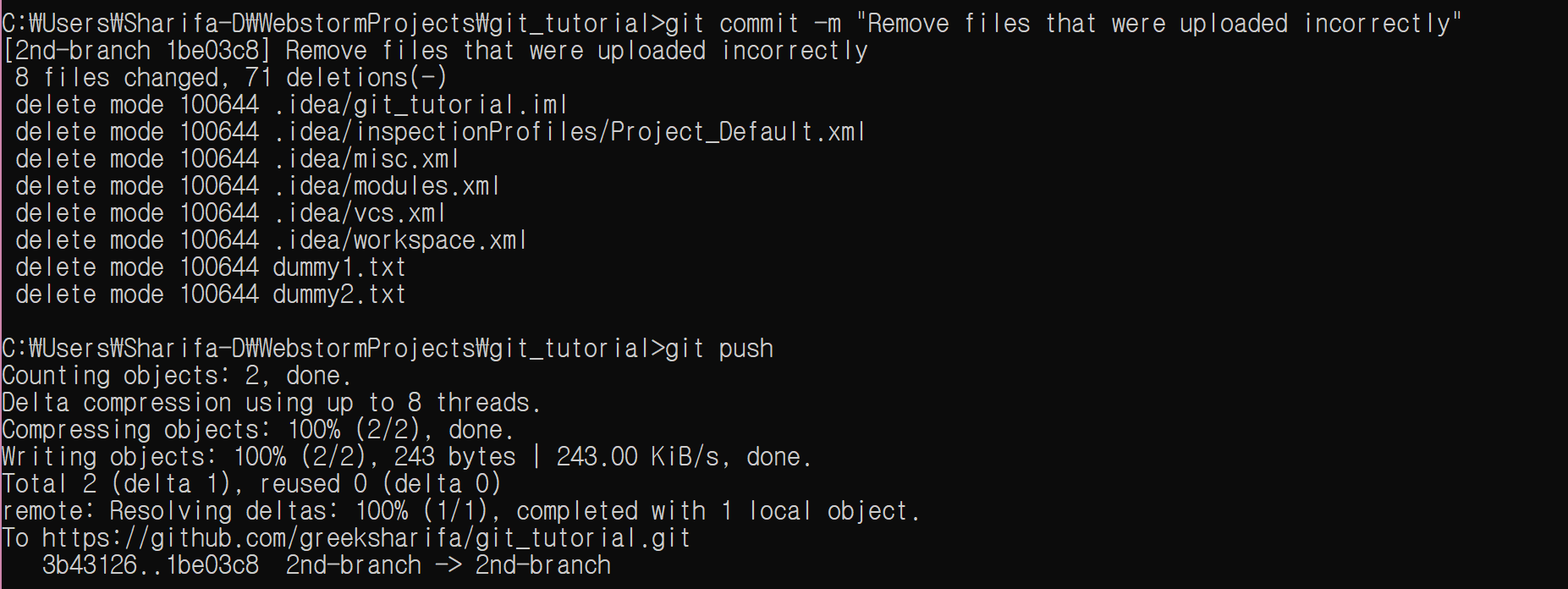
이와 같은 실수를 막기 위해서는, 아예 .gitignore 파일에 git에 올라가지 말아야 할 파일을 정리해 두는 것도 괜찮다.
추천하는 것은 데이터 파일, 설정 파일, 패키지, 압축 파일 등이다.
PyCharm 기준으로는 구글링을 하면 적당히 쓸 만한 설정 파일을 구할 수도 있다.
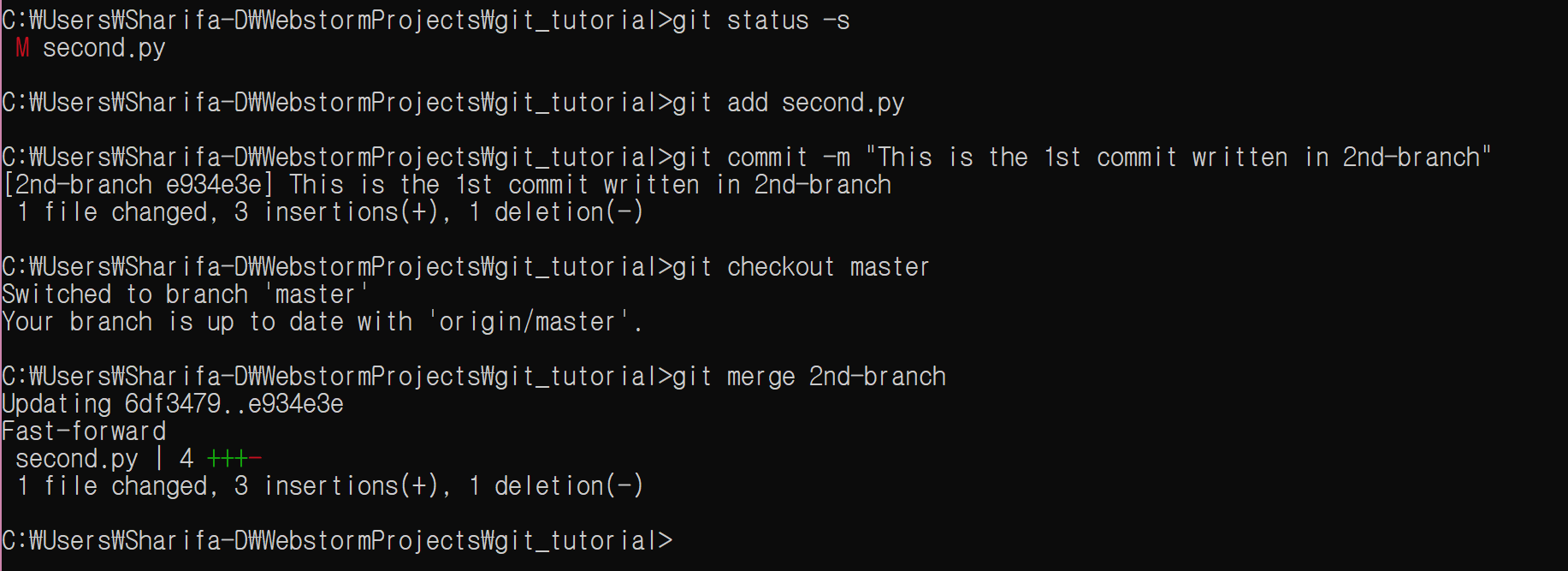
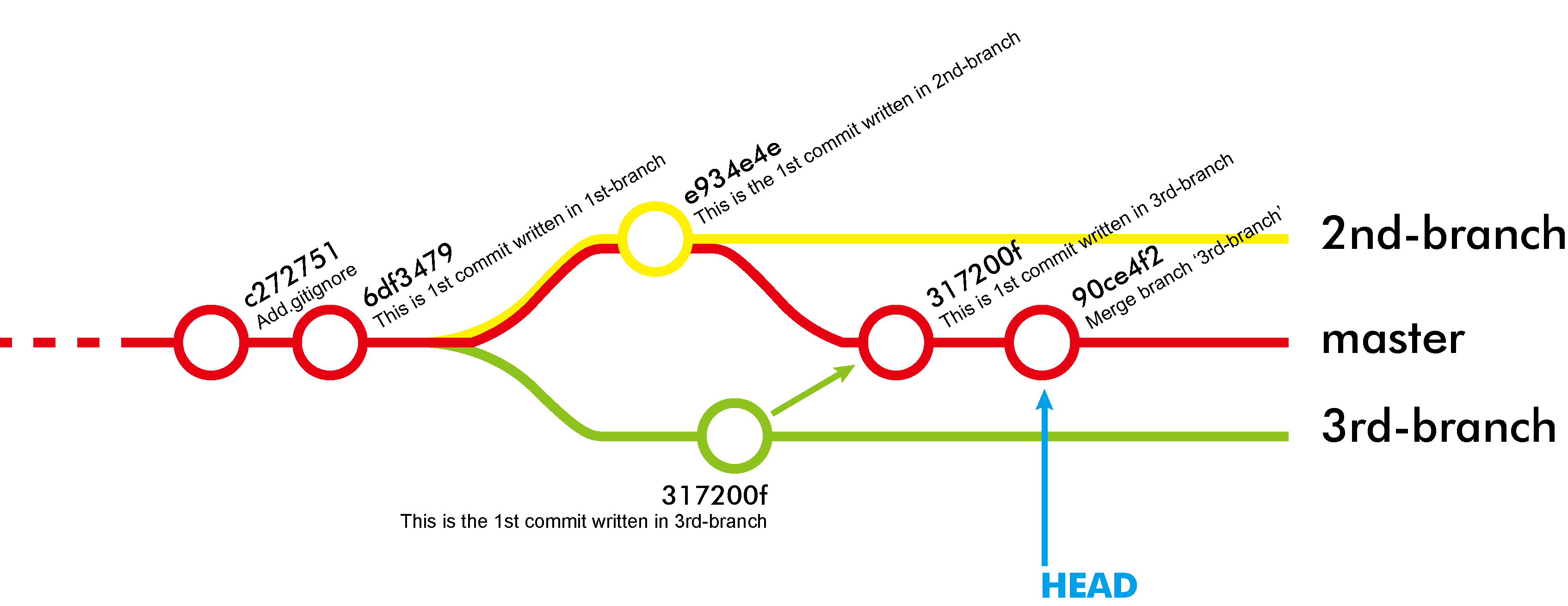
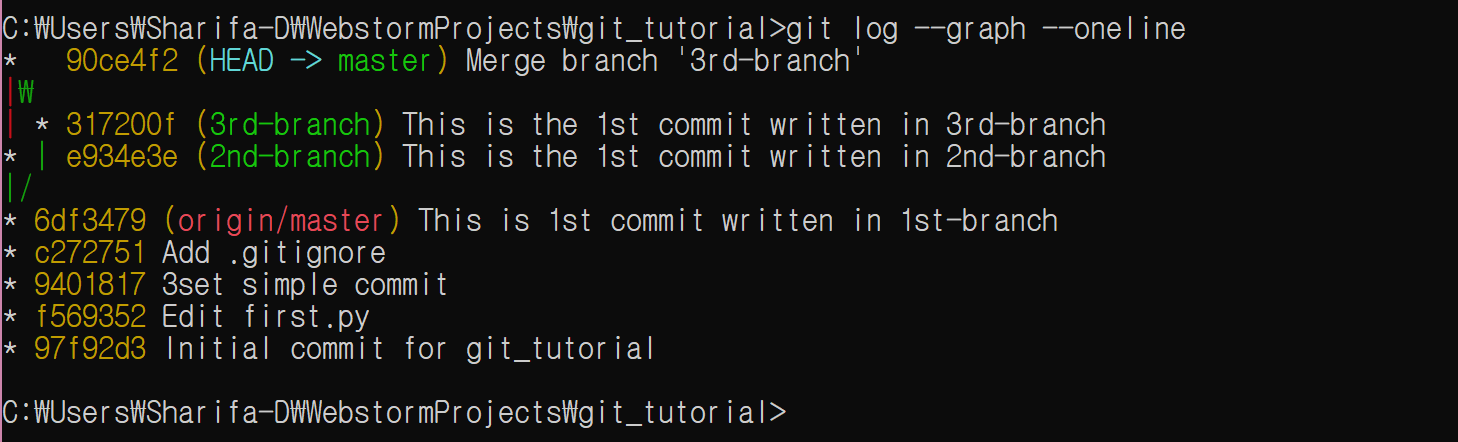
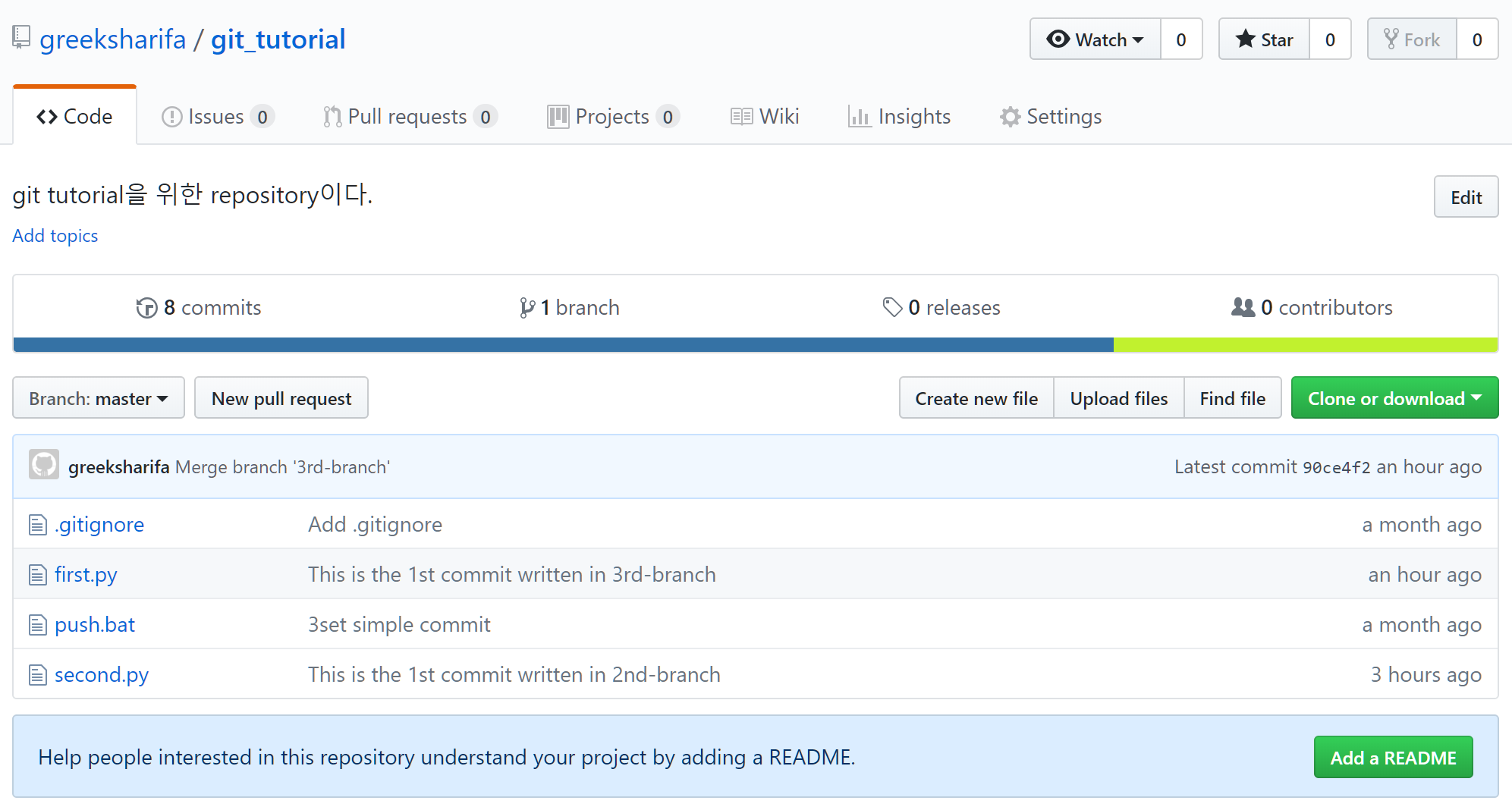
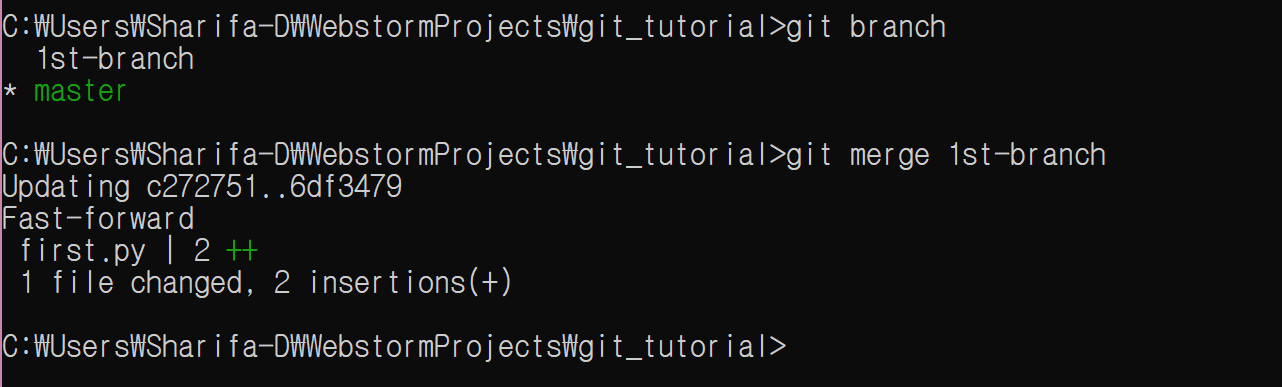
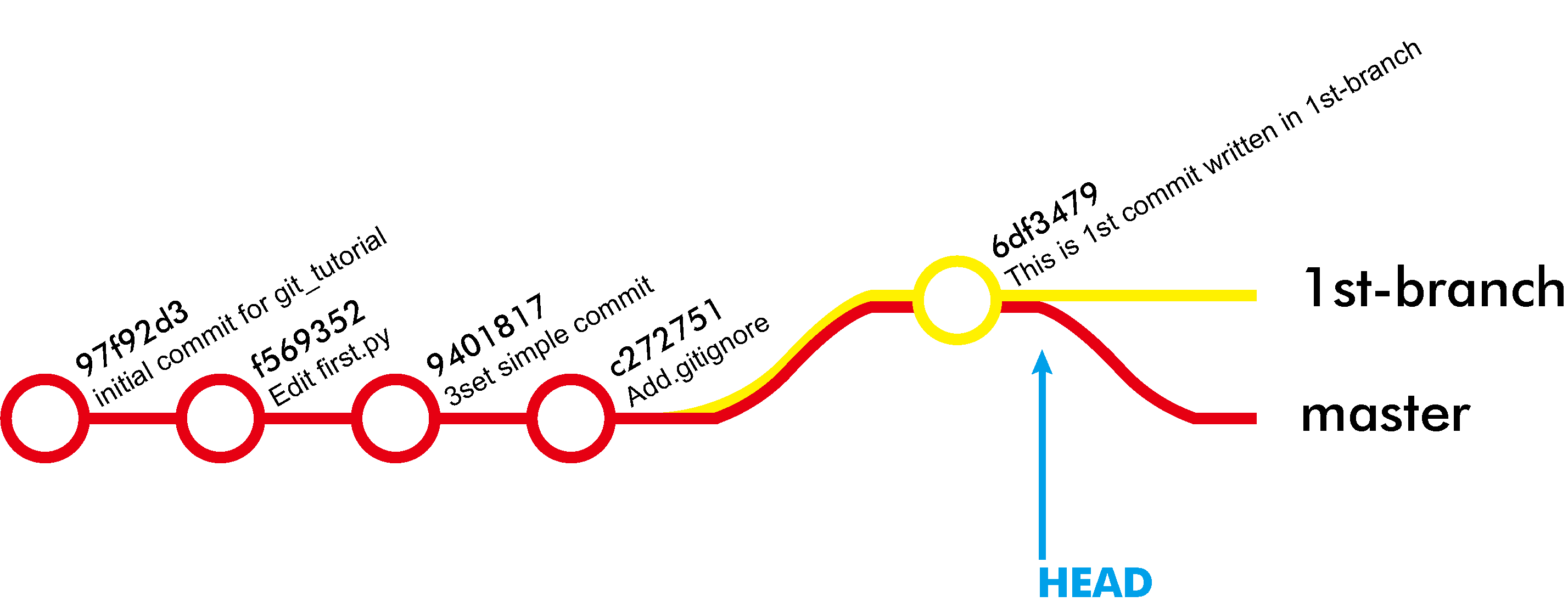
이제 master branch에 merge를 하자.
git checkout master
git merge 2nd-branch
git push
다음 글에서는 대망의 conflict에 대해서 알아본다. 여러 사람이 작업 분할을 충실하게 하지 않는다면 필히 만나게 될 것이다.
물론 혼자서도 만들 수도 있다.
Git 명령어
GitHub 사용법 - 00. Command List에서 원하는 명령어를 찾아 볼 수 있다.