PyTorch 사용법 - 02. Linear Regression Model
02 Nov 2018 | PyTorchPyTorch 사용법 - 00. References
PyTorch 사용법 - 01. 소개 및 설치
PyTorch 사용법 - 02. Linear Regression Model
PyTorch 사용법 - 03. How to Use PyTorch
이 글에서는 가장 기본 모델인 Linear Regression Model의 Pytorch 프로젝트를 살펴본다.
사용되는 torch 함수들의 사용법은 여기에서 확인할 수 있다.
프로젝트 구조
- 02_Linear_Regression_Model/
- main.py
- data/
- 02_Linear_Regression_Model_Data.csv
- results/
- 일반적으로 데이터는
data/디렉토리에 넣는다. - 코드는 git에 두고,
data/는.gitignore파일에 추가하여 데이터는 git에 올리지 않는다. 파일은 다른 서버에 두고 필요할 때 다운로드한다. 일반적으로 dataset은 그 크기가 수 GB 혹은 그 이상도 될 수 있기 때문에 upload/download 시간이 굉장히 길어지기도 하고, Git이 100MB 이상의 큰 파일은 업로드를 지원하지 않기 때문이기도 하다.
물론 이 예제 프로젝트는 너무 간단하여 그냥 data/ 디렉토리 없이 해도 상관없다.
그리고 output/ 또는 results/ 디렉토리를 만들도록 한다.
Import
import pandas as pd
import torch
from torch import nn
import matplotlib.pyplot as plt
다음 파일을 다운로드하여 data/ 디렉토리에 넣는다.
02_Linear_Regression_Model_Data.csv
- torch: 설명이 필요없다.
- from torch import nn: nn은 Neural Network의 약자이다. torch의 nn 라이브러리는 Neural Network의 모든 것을 포괄하며, Deep-Learning의 가장 기본이 되는 1-Layer Linear Model도
nn.Linear클래스를 사용한다. 이 예제에서도 nn.Linear를 쓴다.- nn.Module은 모든 Neural Network Model의 Base Class이다. 모든 Neural Network Model(흔히 Net이라고 쓴다)은 nn.Module의 subclass이다. nn.Module을 상속한 어떤 subclass가 Neural Network Model로 사용되려면 다음 두 메서드를 override해야 한다.
__init__(self): Initialize. 여러분이 사용하고 싶은, Model에 사용될 구성 요소들을 정의 및 초기화한다. 대개 다음과 같이 사용된다.- self.conv1 = nn.Conv2d(1, 20, 5)
- self.conv2 = nn.Conv2d(20, 20, 5)
- self.linear1 = nn.Linear(1, 20, bias=True)
forward(self, x): Specify the connections.__init__에서 정의된 요소들을 잘 연결하여 모델을 구성한다. Nested Tree Structure가 될 수도 있다. 주로 다음처럼 사용된다.- x = F.relu(self.conv1(x))
- return F.relu(self.conv2(x))
- 다른 말로는 위의 두 메서드를 override하기만 하면 손쉽게 Custom net을 구현할 수 있다는 뜻이기도 하다.
- nn.Module은 모든 Neural Network Model의 Base Class이다. 모든 Neural Network Model(흔히 Net이라고 쓴다)은 nn.Module의 subclass이다. nn.Module을 상속한 어떤 subclass가 Neural Network Model로 사용되려면 다음 두 메서드를 override해야 한다.
- 참고: torch.autograd.Variable은 이전에는 auto gradient 계산을 위해 tensor에 필수적으로 씌워 주어야 했으나, PyTorch 0.4.0 버전 이후로
torch.Tensor와torch.autograd.Variable클래스가 통합되었다. 따라서 PyTorch 구버전을 사용할 예정이 아니라면 Variable은 쓸 필요가 전혀 없다.- 인터넷에 돌아다니는 수많은 코드의 Variable Class는 0.4.0 버전 이전에 PyTorch를 시작한 사람들이 쓴 것이다.
- https://pytorch.org/docs/stable/autograd.html#variable-deprecated/
- https://pytorch.org/blog/pytorch-0_4_0-migration-guide/
Load Data
데이터 준비
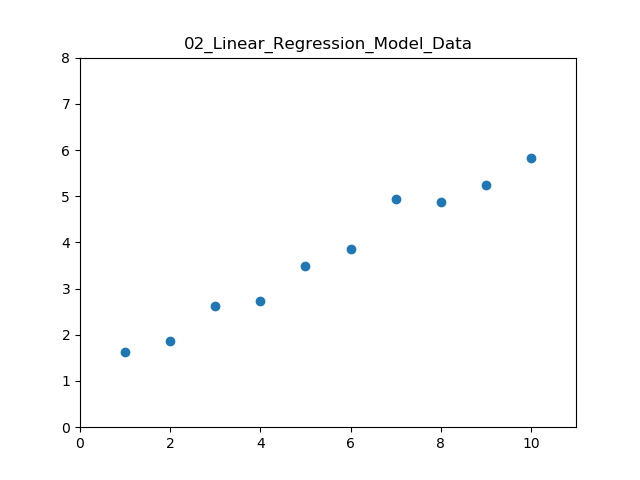
지금의 경우는 전처리할 필요가 없으므로 그냥 데이터를 불러오기만 하면 된다. 데이터가 어떻게 생겼는지도 확인해 보자.
데이터가 어떤지 살펴보는 것은 모델을 결정하는 데 있어 매우 중요하다.
다운로드는 여기에서 할 수 있다.
data = pd.read_csv('data/02_Linear_Regression_Model_Data.csv')
# Avoid copy data, just refer
x = torch.from_numpy(data['x'].values).unsqueeze(dim=1).float()
y = torch.from_numpy(data['y'].values).unsqueeze(dim=1).float()
plt.xlim(0, 11); plt.ylim(0, 8)
plt.title('02_Linear_Regression_Model_Data')
plt.scatter(x, y)
plt.show()
from_numpy로 불러오는 이유는 데이터를 복사하여 새로 텐서를 생성하는 대신 원 데이터와 메모리를 공유하는 텐서를 쓰기 위함이다. 지금은 상관없지만 대용량의 데이터를 다룰 때에는 어떤 함수가 데이터를 복사하는지 아닌지를 확실하게 알아둘 필요가 있다.
물론, 정말 대용량의 데이터의 경우는 read_csv로 한번에 불러오지 못한다. 이는 데이터를 batch로 조금씩 가져오는 것으로 해결하는데, 이에 대해서는 나중에 살펴보자.
참고: 이 데이터는 다음 코드를 통해 생성되었다.
x = torch.arange(1, 11, dtype=torch.float).unsqueeze(dim=1)
y = x / 2 + 1 + torch.randn(10).unsqueeze(dim=1) / 5
data = torch.cat((x, y), dim=1)
data = pd.DataFrame(data.numpy())
data.to_csv('data/02_Linear_Regression_Model_Data.csv', header=['x', 'y'])
Define and Load Model
매우 간단한 모델이므로 코드도 짧다.
여기서는 여러분의 편의를 위해 함수들의 parameter 이름을 명시하도록 한다.
PyTorch에서 Linear 모델은 torch.nn.Linear 클래스를 사용한다. 여기서는 단지 x를 y로 mapping하는 일차원 직선($ y = wx + b $)을 찾고 싶은 것이므로, in_features와 out_features는 모두 1이다.
nn.Linear은 nn.Module의 subclass로 in_features개의 input을 선형변환을 거쳐 out_features개의 output으로 변환한다. parameter 개수는 $ (in _ features \times out _ features [ + out _ features]) $ 개이다. 마지막 항은 bias이다.
from torch import nn
model = nn.Linear(in_features=1, out_features=1, bias=True)
print(model)
print(model.weight)
print(model.bias)
"""
Linear(in_features=1, out_features=1, bias=True)
Parameter containing:
tensor([[-0.9360]], requires_grad=True)
Parameter containing:
tensor([0.7960], requires_grad=True)
"""
별다른 utility 함수가 필요 없으므로 따로 utils.py는 만들지 않는다.
Set Loss function(creterion) and Optimizer
적절한 모델을 선정할 때와 마찬가지로 loss function과 optimizer를 결정하는 것은 학습 속도와 성능을 결정짓는 중요한 부분이다.
지금과 같이 간단한 Linear Regression Model에서는 어느 것을 사용해도 학습이 잘 된다. 하지만, 일반적으로 성능이 좋은 AdamOptimizer를 사용하도록 하겠다.
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.01)
print(model(x))
"""
tensor([[-0.1399],
[-1.0759],
[-2.0119],
[-2.9478],
[-3.8838],
[-4.8197],
[-5.7557],
[-6.6917],
[-7.6276],
[-8.5636]], grad_fn=<ThAddmmBackward>)
"""
참고: 보통 변수명은 criterion 혹은 loss_function 등을 이용한다.
Train Model
Train은 다음과 같이 이루어진다.
- 모델에 데이터를 통과시켜 예측값(현재 모델의 weights로 prediction)을 얻은 뒤
- 실제 정답과 loss를 비교하고
- gradient를 계산한다.
- 이 값을 통해 weights를 업데이트한다(backpropagation).
for step in range(500):
prediction = model(x)
loss = criterion(input=prediction, target=y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 20 == 0:
"""
Show your intermediate results
"""
pass
코드의 각 라인을 설명하면 다음과 같다.
prediction: 모델에 데이터(x)를 집어넣었을 때 예측값(y). 여기서는 $ y = wx + b $의 결과들이다.loss: criterion이 MSELoss로 설정되어 있으므로, prediction과 y의 평균제곱오차를 계산한다.optimizer.zero_grad(): optimizer의 grad를 0으로 설정한다. PyTorch는 parameter들의 gradient를 계산해줄 때 grad는 계속 누적되도록 되어 있다. 따라서 gradient를 다시 계산할 때에는 0으로 세팅해주어야 한다.loss.backward(): gradient 계산을 역전파(backpropagation)한다.optimizer.step(): 계산한 gradient를 토대로 parameter를 업데이트한다($ w \leftarrow w - \alpha \Delta w, b \leftarrow b - \alpha \Delta b $)- 학습 결과를 중도에 확인하고 싶으면 그래프를 중간에 계속 그려주는 것도 한 방법이다.
Visualize and save results
결과를 그래프로 보여주는 부분은 matplotlib.pyplot에 대한 내용이므로 여기서는 넘어가도록 하겠다.
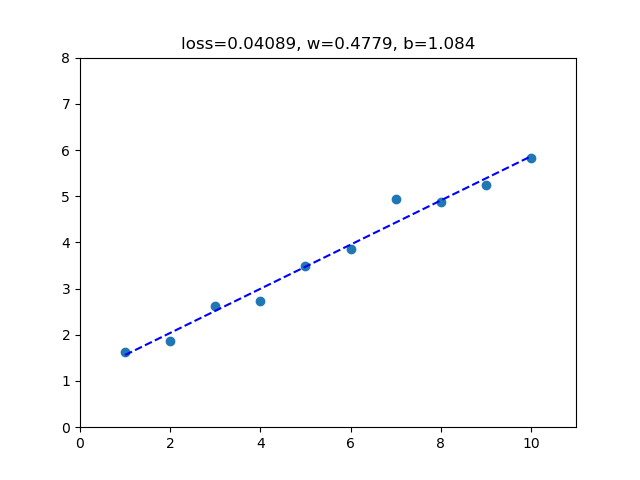
def display_results(model, x, y):
prediction = model(x)
loss = criterion(input=prediction, target=y)
plt.clf()
plt.xlim(0, 11); plt.ylim(0, 8)
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'b--')
plt.title('loss={:.4}, w={:.4}, b={:.4}'.format(loss.data.item(), model.weight.data.item(), model.bias.data.item()))
plt.show()
# plt.savefig('results/02_Linear_Regression_Model_trained.png')
display_results(model, x, y)
모델을 저장하려면 torch.save 함수를 이용한다. 저장할 모델은 대개 .pt 확장자를 사용한다.
torch.save(obj=model, f='02_Linear_Regression_Model.pt')
참고: .pt 파일로 저장한 PyTorch 모델을 load해서 사용하려면 다음과 같이 한다. 이는 나중에 Transfer Learning과 함께 자세히 다루도록 하겠다.
loaded_model = torch.load(f='02_Linear_Regression_Model.pt')
display_results(loaded_model, x, y)
정확히 같은 결과를 볼 수 있을 것이다.
전체 코드는 여기에서 살펴볼 수 있다.