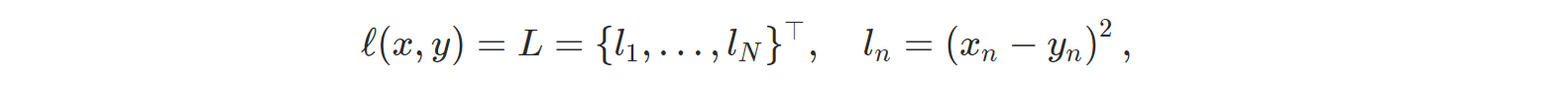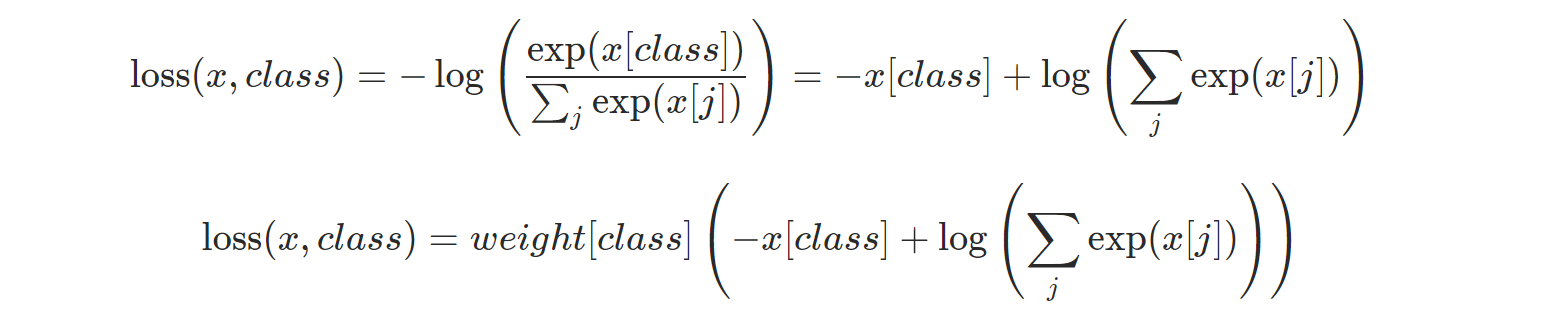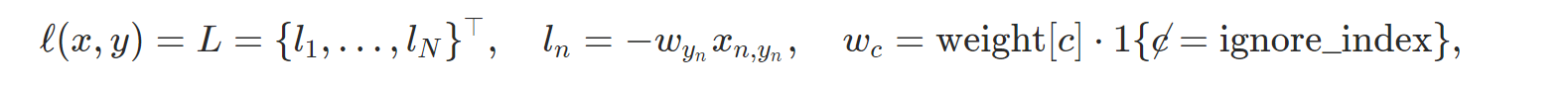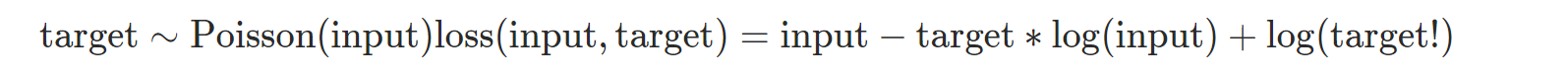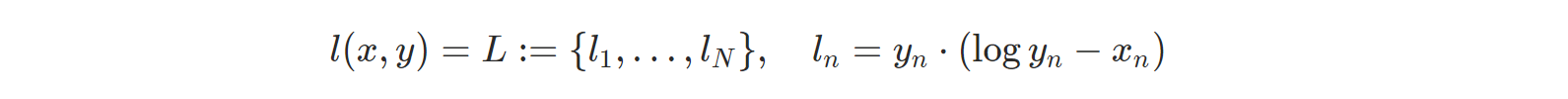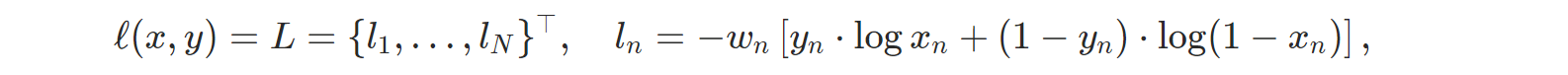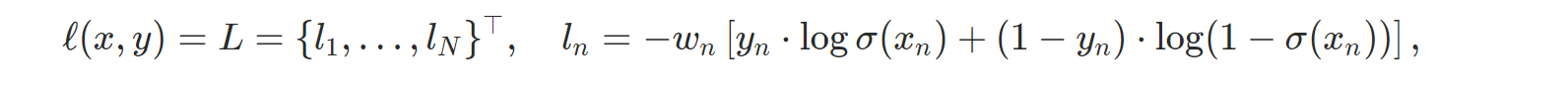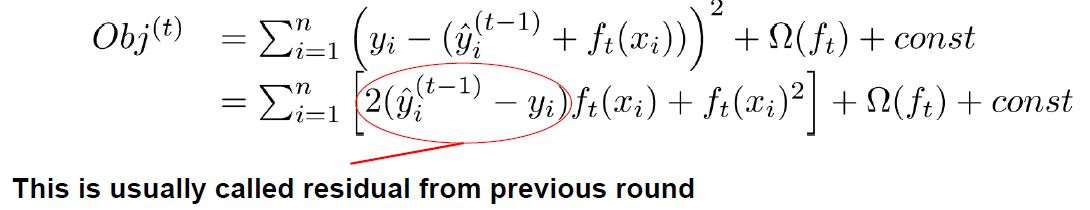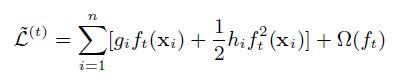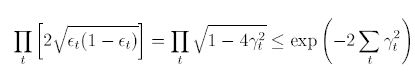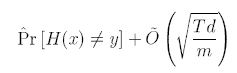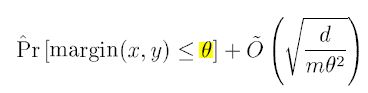PyCharm 사용법(파이참 설치 및 사용법)
07 Feb 2019 | PyCharm usagePyCharm(파이참)은 Jetbrains 사에서 제작 및 배포하는 유료/무료 프로그램이다.
Professional 버전은 돈을 주고 구입하거나, 학생이라면 학생 인증을 하고 무료로 사용할 수 있다.
글이 길기 때문에 사용법을 검색하고 싶다면 Ctrl + F 키를 누른 다음 검색해 보자.
2023.03.07 updated
설치
PyCharm 홈페이지에서 설치 파일을 다운받는다.
또는 Jetbrains Toolbox를 받은 다음 PyCharm을 받아도 된다.
유료 버전을 구매했거나 학생 인증이 가능하다면, Professional(혹은 Education) 버전을 다운받도록 한다.
Settings
설치 시 다음 창을 볼 수 있다. 해당 컴퓨터에 설치한 적이 있으면 설정 파일 위치를 지정하고, 아니면 말도록 하자.
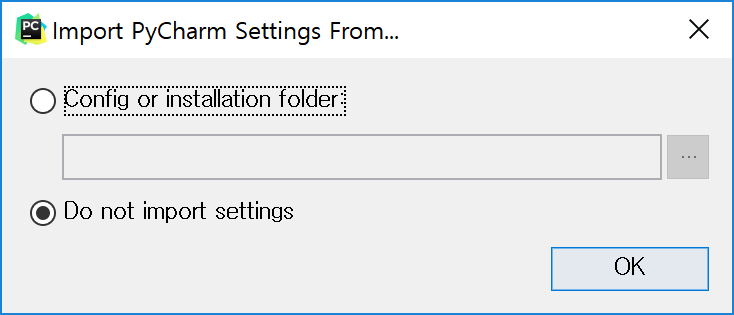
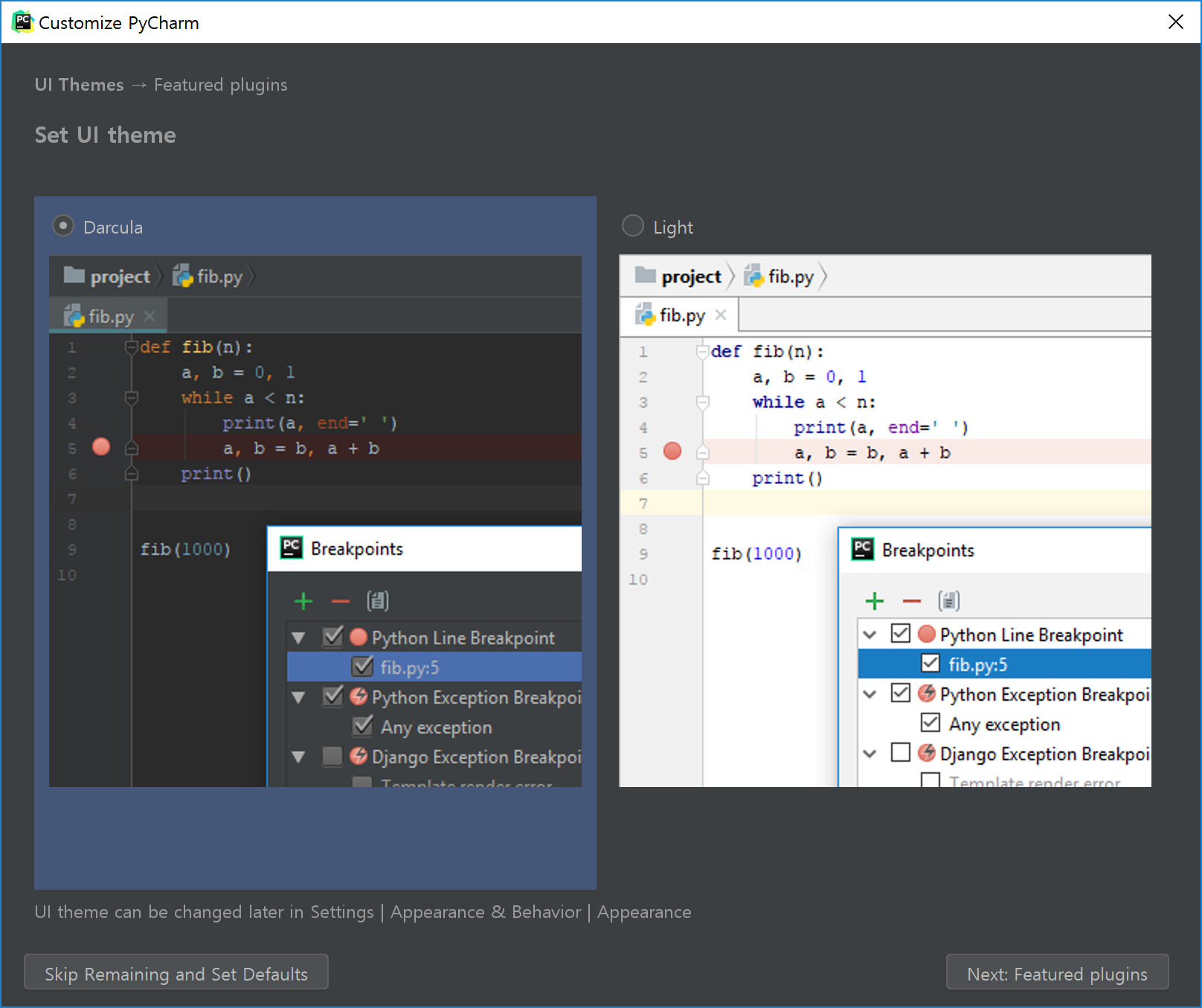
필자는 Darcula로 지정했고, 왼쪽 아래의 Skip Remaining and Set Defaults 버튼을 누른다. 본인이 추가 설정하고 싶은 부분이 있으면 이후 설정에서 마음대로 바꾸면 된다.
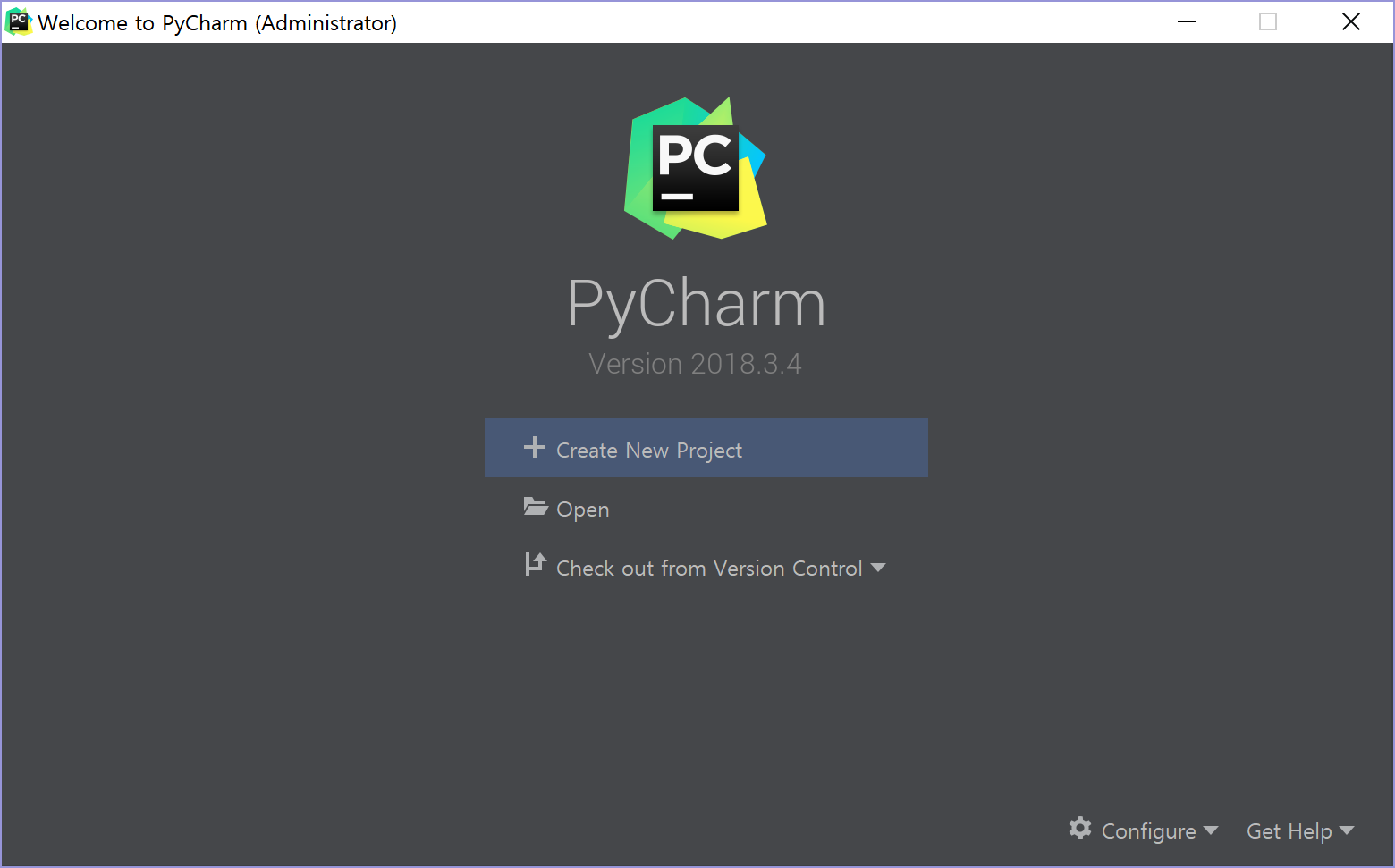
설정을 완료하면 아래와 같은 화면을 볼 수 있다. 오른쪽 아래의 Configure > Settings 를 클릭한다.
정확히는 Settings for New Projects라는 대화창을 볼 수 있다. 이는 새 프로젝트를 만들 때 적용되는 기본 설정이다. 새로운 설정을 만들고 싶다면 Default 설정을 복제(Duplicate)한 뒤 새 설정에서 바꾸도록 한다.
설정에서 Appearance & Behavior > Appearance에서, Theme를 Darcula 또는 다른 것으로 지정할 수 있다. 아래의 Use Custom Font는 메뉴 등의 폰트를 해당 폰트로 지정할 수 있다.
참고로, 코드의 폰트는 Editor > Font에서 지정한다. 이 두 가지 역시 구분하도록 한다. 기본값은 Monospaced이다.
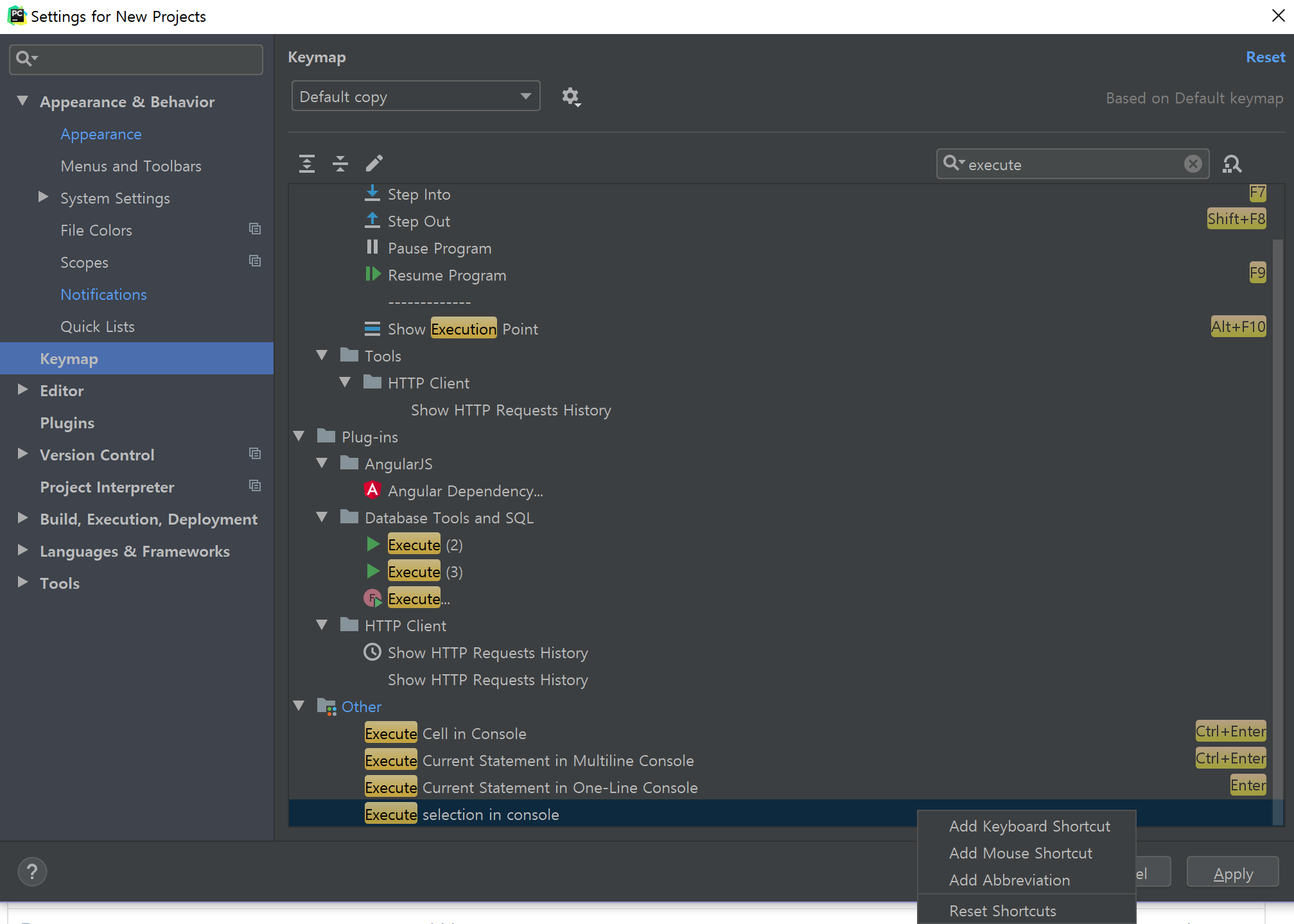
Keymap에서는 단축키를 지정할 수 있다. PyCharm의 기본 단축키는 타 프로그램과 좀 다른 부분이 많아 필자는 일부를 바꿨다.
변경하고 싶은 단축키를 찾아서 더블클릭 또는 우클릭하면 기존에 지정되어 있는 단축키를 삭제하고 새 단축키를 지정할 수 있다. 이때 겹친다면 기존 단축키를 남겨둘지 제거할지 선택할 수 있다. 또한 마우스와 조합한 단축키로 지정할 수도 있다.
그리고 검색창 옆에 돋보기 + 네모 3개로 이루어진 아이콘을 클릭하면 명령의 이름이 아닌 현재 지정되어 있는 단축키로 검색할 수 있다(예: Ctrl + W).
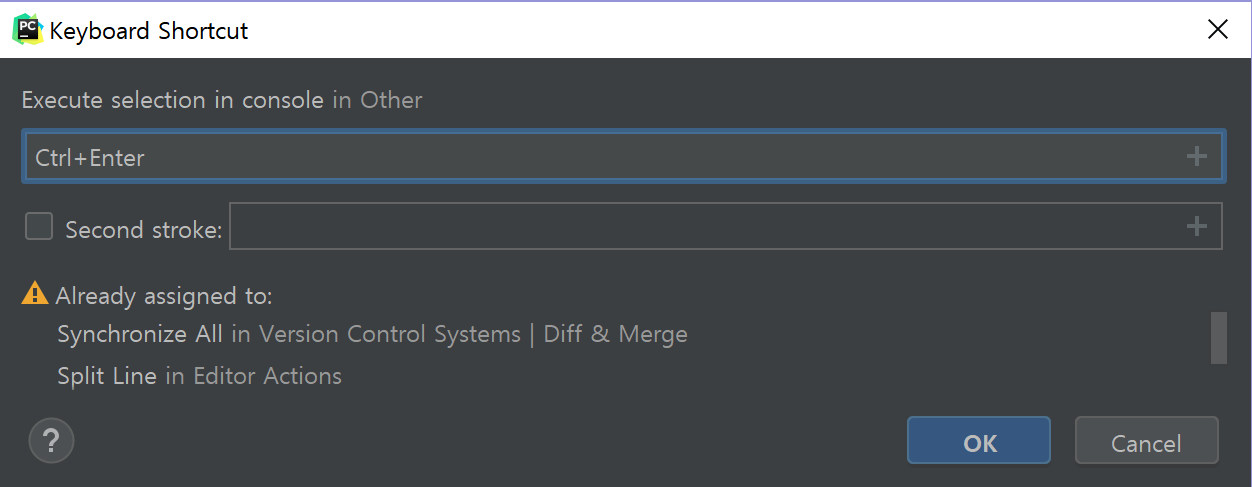
추천하는 변경할 단축키는 다음과 같다.
아래쪽은 필자가 지정하여 사용하는 단축키이다. 이외에도 유용한 기능을 몇 개 적어 놓았다.
| Menu | 변경 전 | 변경 후 |
|---|---|---|
| Execute selection in console | Alt + Shift + E | Ctrl + Enter |
| Edit > Find > Replace | Ctrl + H | Ctrl + R |
| Refactor > Rename | Shift + F6 | F2 |
| Other > Terminal | Alt + T | |
| Other > Python Console | Alt + 8 | |
| Other > SciView | Alt + 0 | |
| Show in Explorer | Ctrl + Alt + Shift + E | |
| Window > Editor Tabs > Close | Ctrl + W | |
| Type Info | Ctrl + Alt + Button1 Click | |
| Split and Move Right | Ctrl + Alt + Shift + R | |
| Go to Declaration or Usages | Ctrl + Button1 Click |
필자의 경우 나머지 설정은 그대로 두는 편이나, Ctrl + Enter로 바꿀 때는 다른 곳에 할당된 것을 지운다(Already assigned 경고창에서 Keep 대신 Remove를 선택). 안 그러면 선택한 부분이 Python Console(대화형)에서 실행되지 않는다.
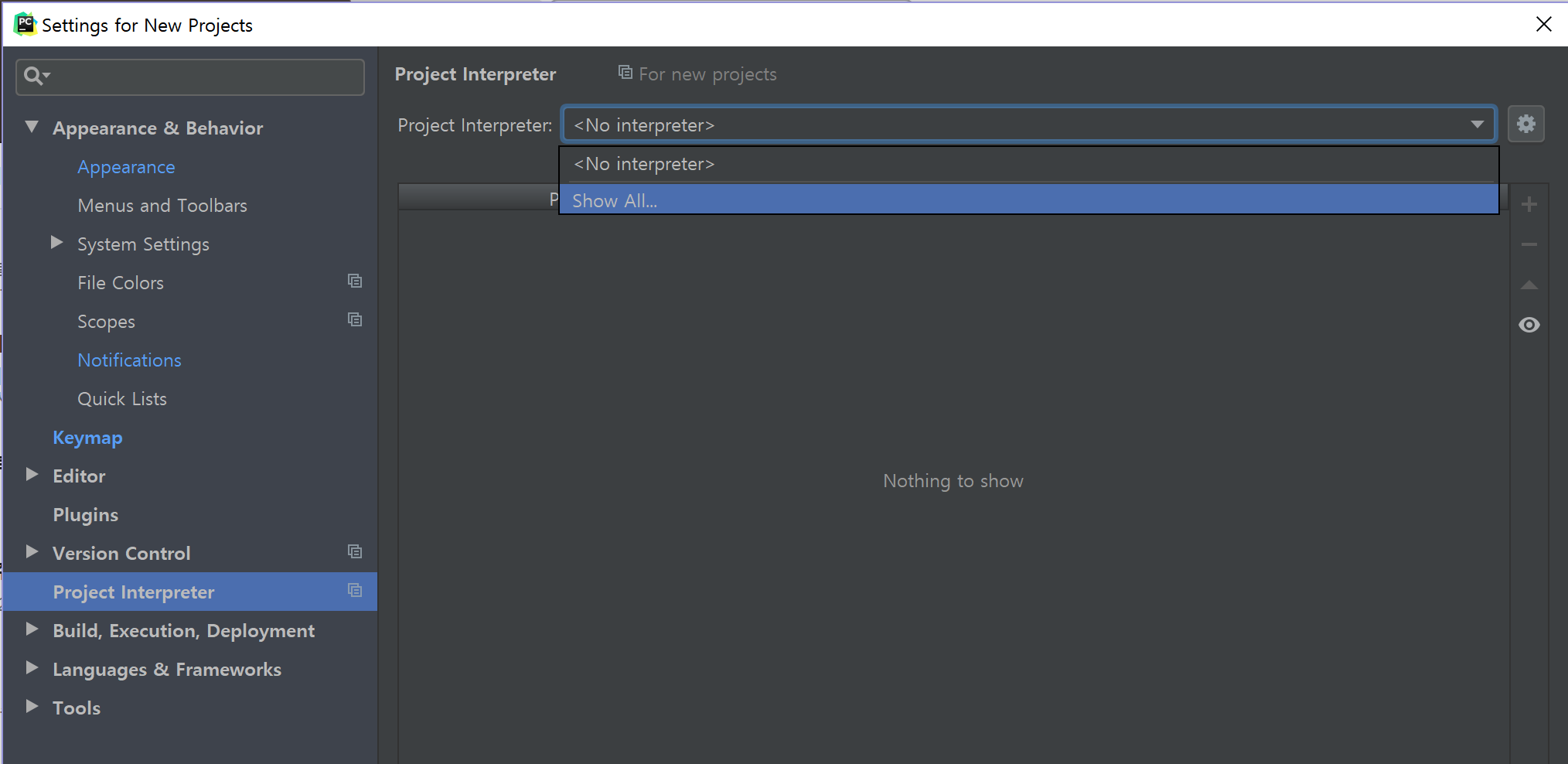
위 그림에서 기본 Python Interpreter 파일(python.exe)를 설정한다. 새 프로젝트를 생성 시 Configure Python Interpreter라는 경고가 보이면서 코드 실행이 안 되면 인터프리터가 설정되지 않은 것이다. 컴퓨터에 설치된 파이썬 파일을 찾아 설정하자.
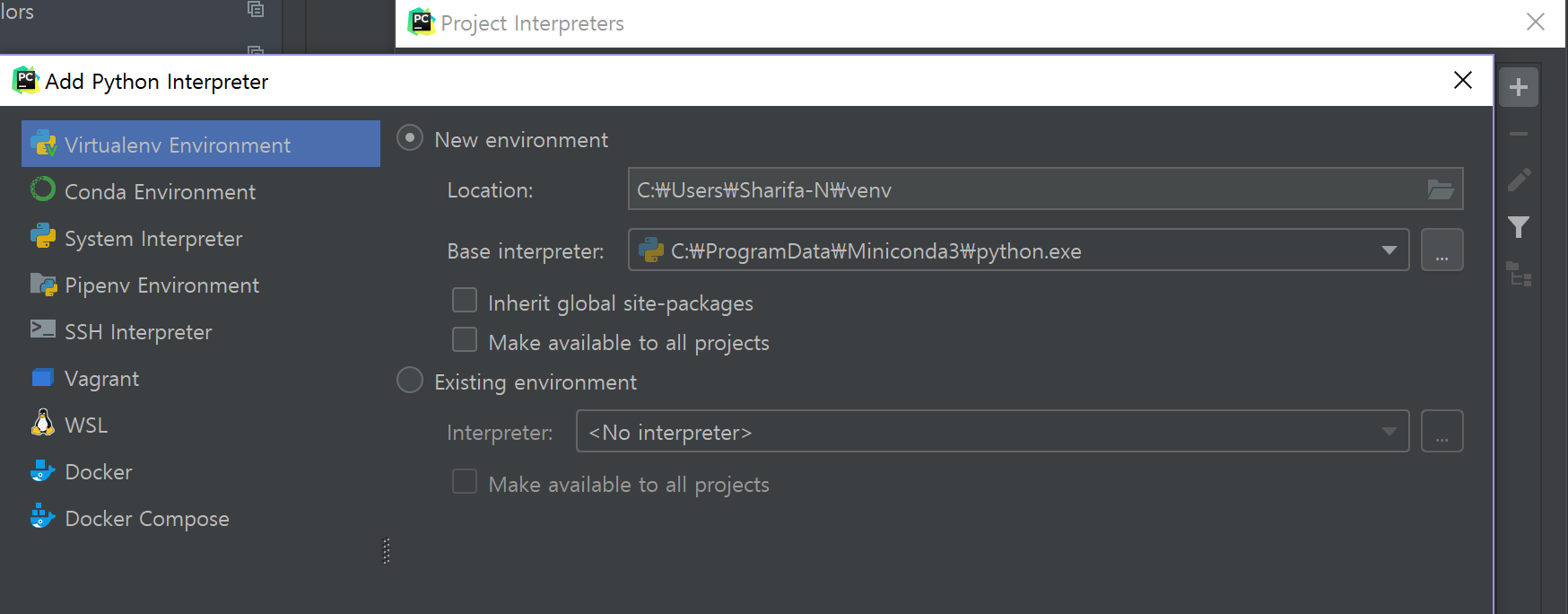
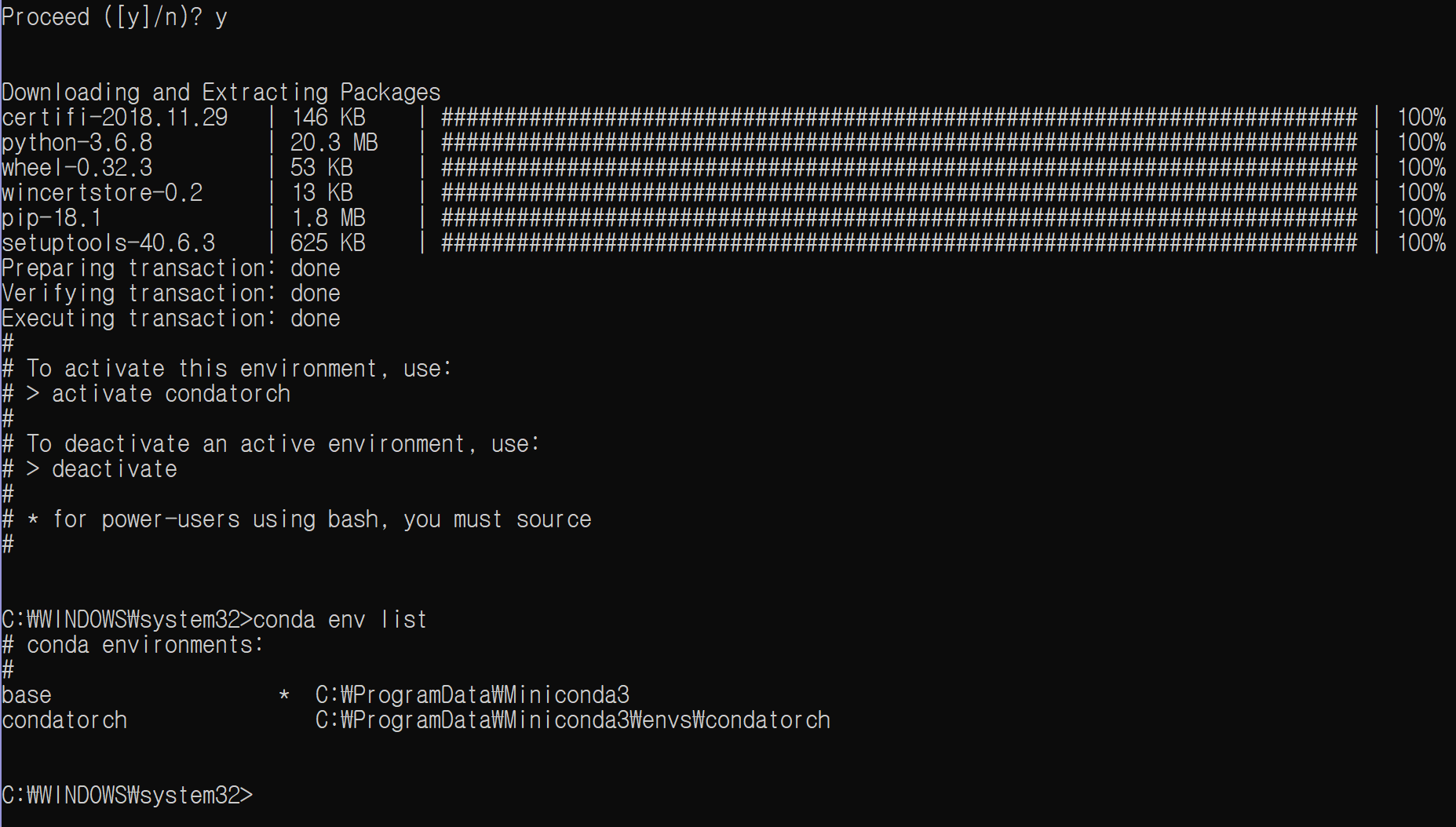
Show All...을 클릭하면 처음에는 빈 창이 보인다. +를 눌러서 원하는 환경을 추가한다. 기존의 것을 추가하거나, 새로운 가상환경(virtualenv 또는 conda)를 즉석에서 생성 가능하다.
이렇게 만든 가상환경은 해당 프로젝트에서만 쓰거나(기본 설정), 아래쪽의 Make available to all projects를 체크하여 다른 프로젝트에서도 해당 인터프리터를 택할 수 있도록 정할 수도 있다.
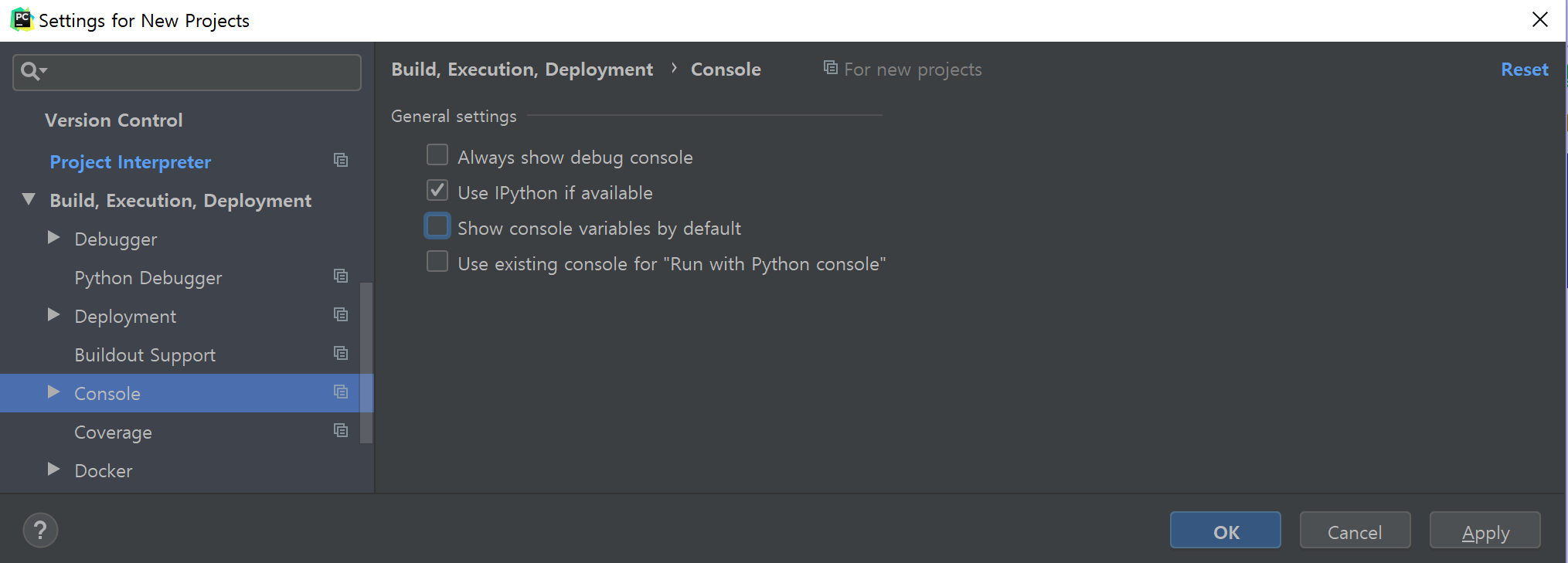
PyCharm에서 코드 실행을 대화형으로 하면 Python Console에 자꾸 Special Variables라는 창이 뜨는 것을 볼 수 있다. 보통 쓸 일이 없는데 기본으로 표시되는 것이므로, Build, Execution, Deployment > Console에서 Show console variable by default 체크를 해제한다.
해당 설정을 마쳤으면 첫 화면에서 Create New Project를 클릭한다.
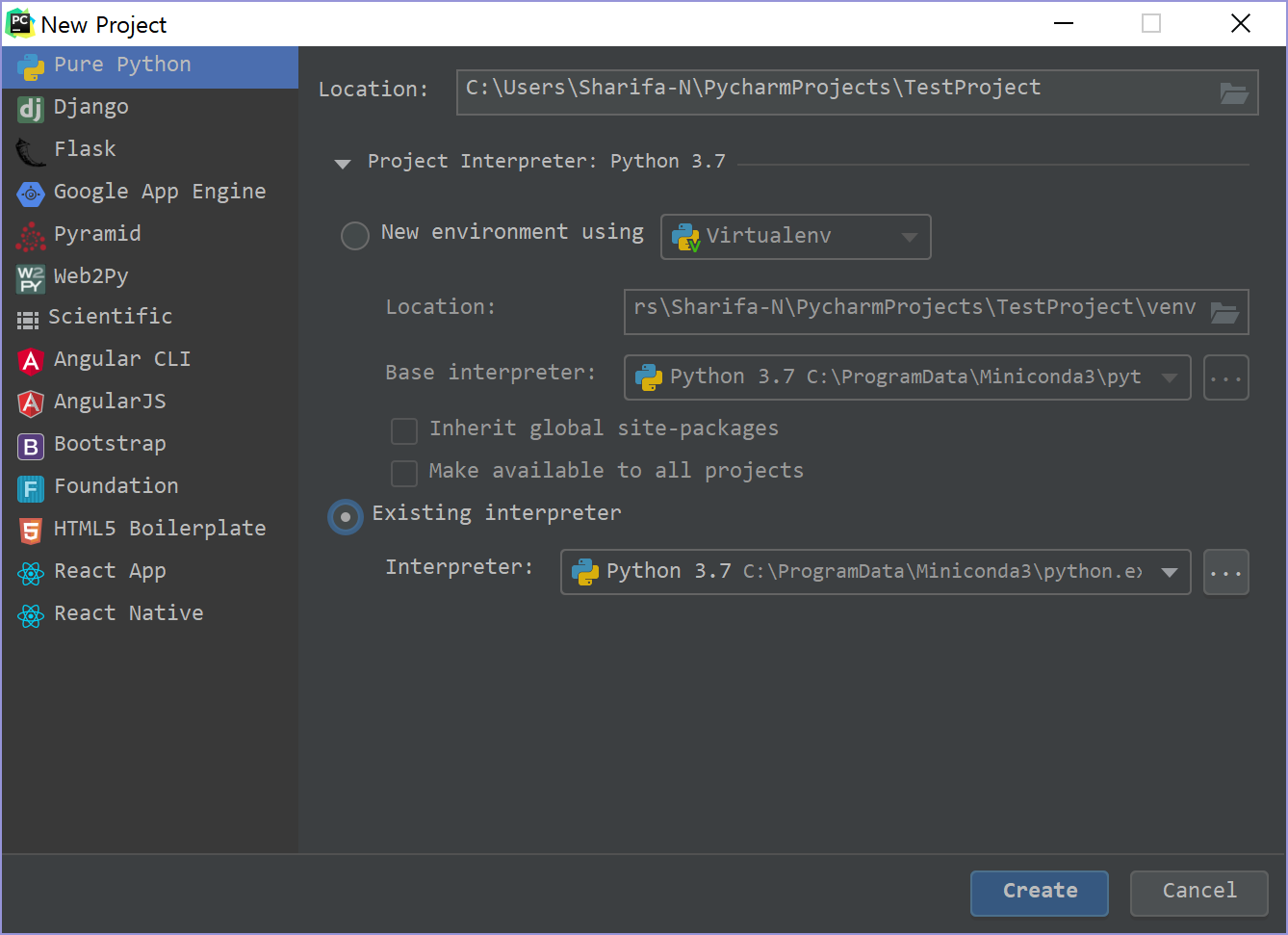
프로젝트 이름은 기본적으로 Untitled 이므로 바꿔주고, 아래쪽의 Project Interpreter를 설정해 둔다. 미리 설정했다면 목록이 보일 것이고, 아니라면 새로 생성하거나 python.exe 위치를 찾아 지정해준다.
Sync Settings
2022.3 버전 기준으로 오른쪽 상단에 Settings Sync라는 기능이 생겼다. 클릭해보자(원래는 off로 되어 있을 것이다).
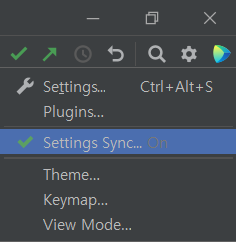
그리고 Enable Settings Sync...를 눌러 활성화한 다음 어떤 세팅을 동기화할지 선택하면 된다.
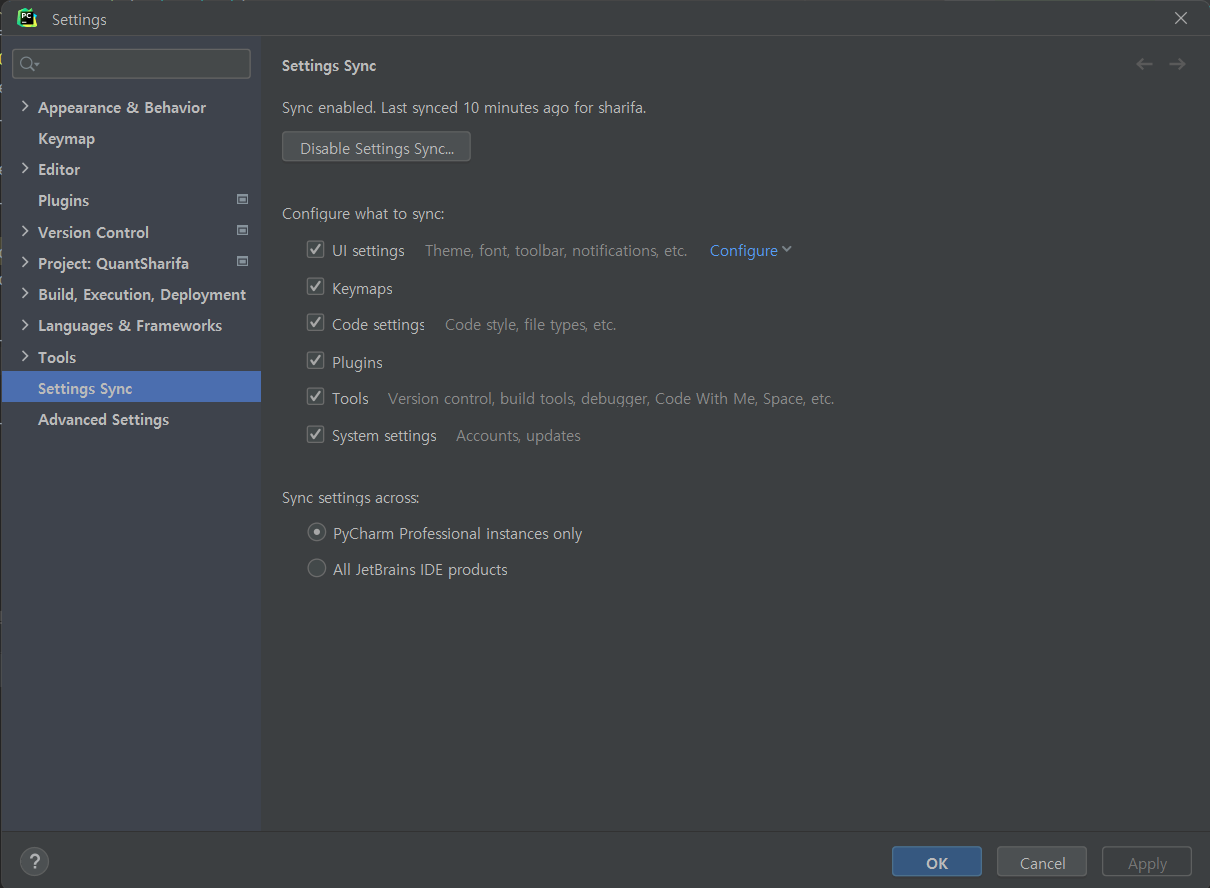
제일 아래쪽에는 지금과 같은 설정 동기화 방식을 PyCharm에만 적용할지, 다른 모든 Jetbrains 제품군에 적용할지 선택하는 설정이 들어 있다.
예전 버전 설정 방법은 아래에 설명하고 있다.
시작 화면에서 Configure > Settings Repository..., 또는 프로젝트 생성 후 File > Settings Repository... 를 클릭하면 지금까지 설정한 설정들을 git repository에 저장할 수 있다. git을 알고 있다면, Merge, Overwrite Local, Overwrite Remote의 뜻을 알 것이라 믿는다. git repository에 저장하면 컴퓨터를 옮겨도 동일한 설정을 쉽게 지정할 수 있다.
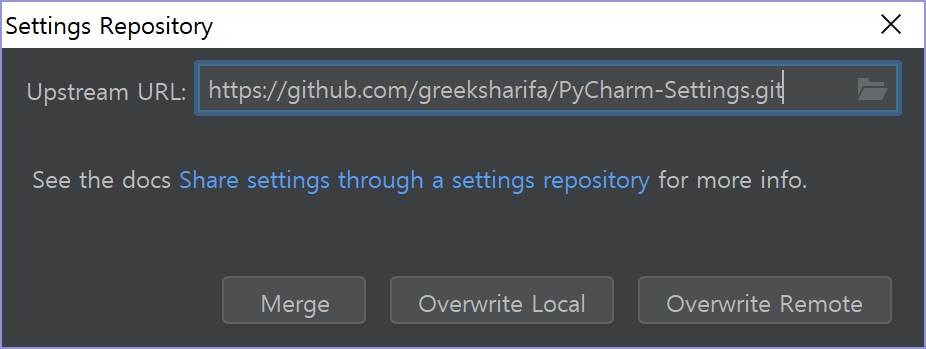
git repository는 그냥 여러분의 git 계정에서 빈 거 하나 만든 다음에 그 주소를 복사하면 된다. 그러면 PyCharm이 알아서 설정을 동기화시켜 줄 것이다.
이를 지정하려면 Personal Access Token이 필요하다. 여기를 참조한다.
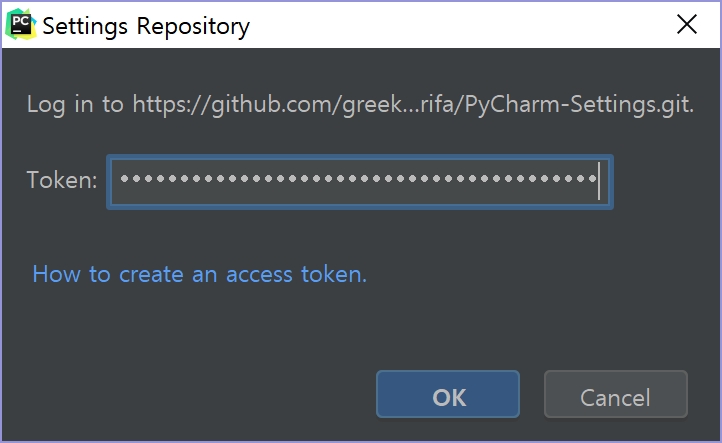
등록이 완료되면 Merge, Overwrite Local(git에 저장된 내용을 local로 덮어씀), Overwrite Remote(현재 local 설정을 인터넷에 덮어씀) 중 하나를 선택해 설정을 동기화할 수 있다.
참고: 이렇게 동기화한 경우 일부 설정(예: kepmap 등)이 바로 적용되지 않는 경우가 있다. 그런 경우는
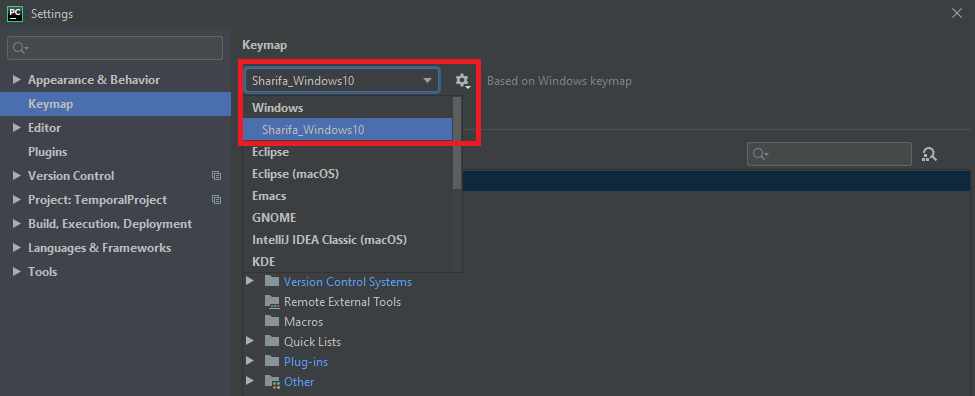
여기에서 Keymap 설정을 변경해 주면 된다. 보통 처음 동기화를 시도하면 기본 설정이나 어떤 Default Copy 버전으로 동작하고 있는 경우가 많다.
File Encoding 설정
코딩을 해 봤다면 알겠지만 한글이나 기타 UTF-8 인코딩 문자는 글자가 깨지는 경우가 흔하다. PyCharm의 기본 설정이 UTF-8이 아닌데, 이를 설정해주자.
아래 과정은 Settings을 열고 Encoding을 검색한 다음 나오는 모든 설정을 ‘UTF-8’로 바꾸는 과정과 같다.
모든 부분에서 글자가 안 깨지게 하려면 다음을 설정한다.
File > New Projects Settings > Settings for New Projects메뉴로 들어가면Settings for New Projects창이 뜬다.- 여기서
Editor > File Encodings메뉴로 들어간 다음Global Encoding,Project Encoding,Project Files > Default Encoding for properties files의 설정을 모두UTF-8로 바꿔준다.
- 여기서
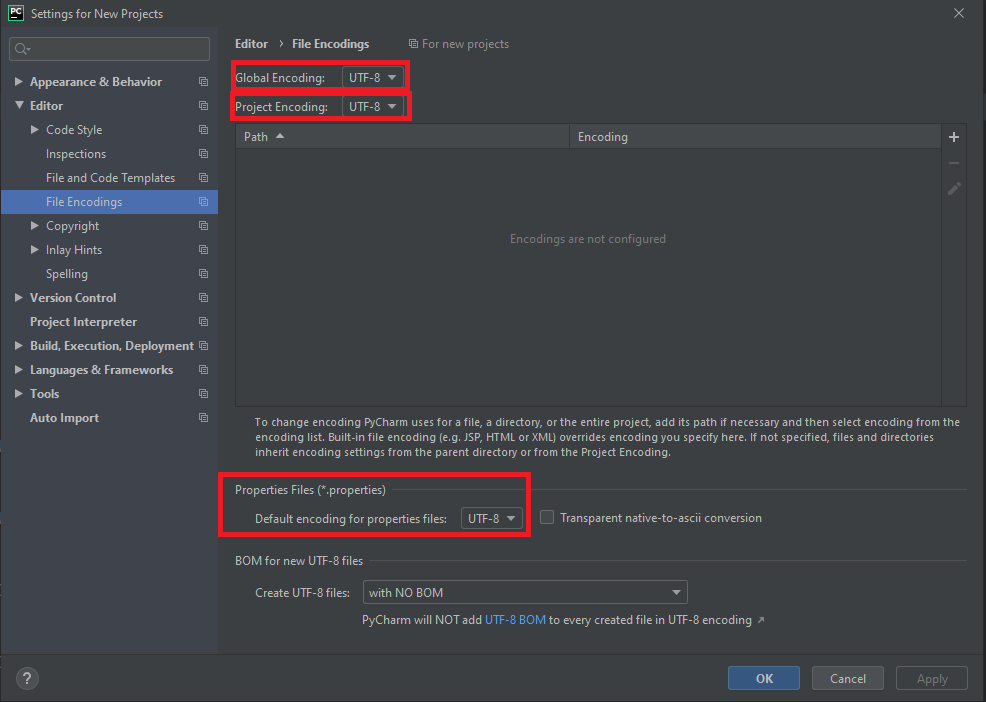
-
이미 생성한 프로젝트에도 적용하려면
File > Settings로 대화창을 연 다음 같은 과정을 반복한다. -
Help > Edit Custom VM Options...메뉴를 클릭하면<version>.vmoptions파일이 열린다.- 여기서 다음을 파일의 끝에 추가하고 저장한다.
-Dfile.encoding=UTF-8 -Dconsole.encoding=UTF-8 - 그리고 PyCharm을 재시작한다.
- 여기서 다음을 파일의 끝에 추가하고 저장한다.
여기까지 설정했으면 파일이나 터미널 등에서 문자가 깨지지 않을 것이다. 그럼에도 깨지는 게 있으면 UTF-8 인코딩이 아니거나, 설정을 빠뜨렸거나..일 것이다. 위에서 설명한 대로 Settings에서 Encoding이라고 검색해 보자.
PyCharm 메모리 설정(Heap Memory)
간혹 PyCharm에 메모리가 너무 적게 할당되어 매우 느려지는 경우가 있다. 이 때도 위와 같이 Help > Edit Custom VM Options...를 클릭하여 설정 파일을 연다.
그러면 맨 위 두 줄은 다음과 같이 되어 있을 것이다.
-Xms128m
-Xmx750m
-XX:ReservedCodeCacheSize=240m
위의 숫자 128, 750, 240(megabytes)를 본인의 컴퓨터 사양에 맞추어 적당히 몇 배 곱해서 올려준다. 램이 8G라면 4G 이상은 안 해도 된다.
여기까지 초기 설정이 끝났다(원하는 부분만 진행해도 좋다). 이제 PyCharm 프로젝트 화면을 살펴보도록 하자.
Project 창(Alt + 1)
처음 프로젝트를 열면 다음과 같은 화면이 보일 것이다. (Show tips at startup은 무시한다)
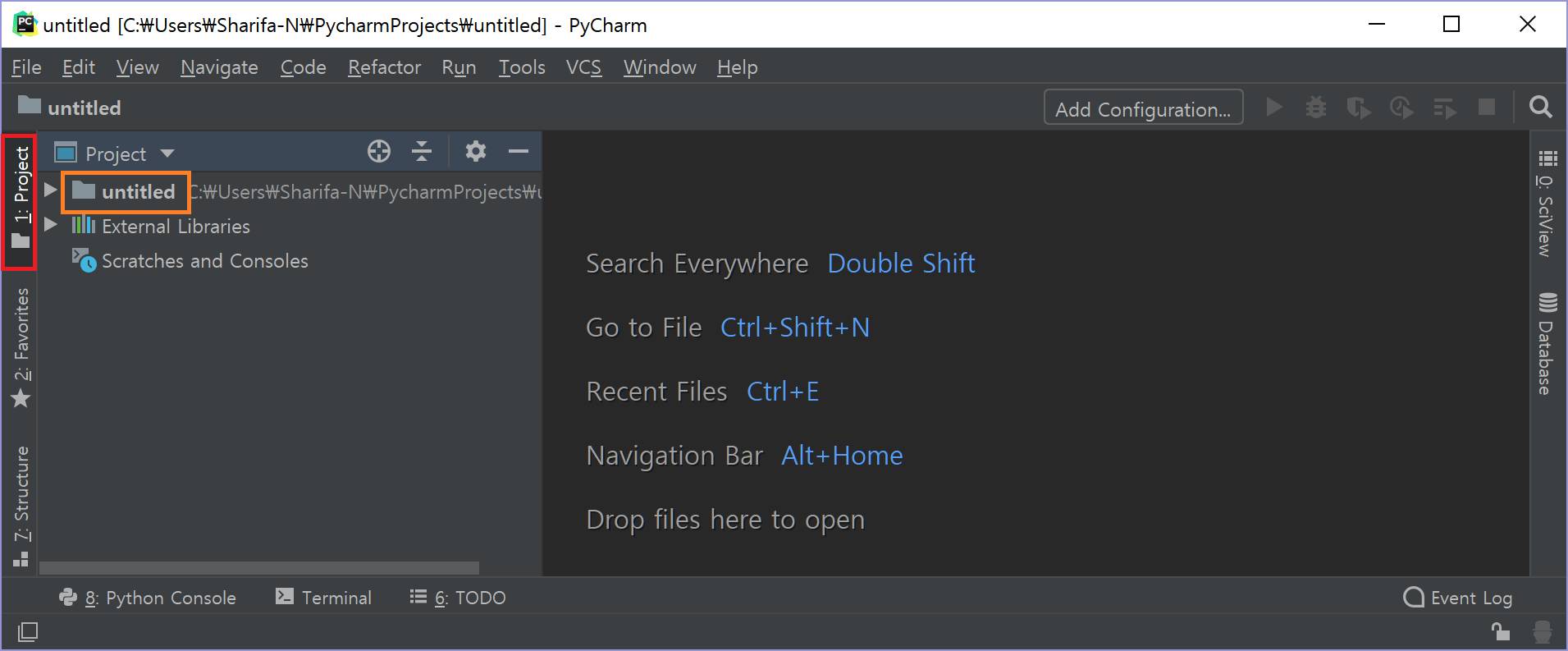
맨 왼쪽에는 프로젝트 창이 있다. 맨 왼쪽 빨간 박스로 표시한 곳을 클릭하면 프로젝트 창을 접었다 폈다 할 수 있다. 단축키를 눌러도 된다(Alt + 1).
필자는 현재 untitled라는 이름으로 프로젝트를 생성했기 때문에, 루트 폴더는 현재 untitled이다. 주황 박스를 오른쪽 클릭하면 꽤 많은 옵션이 있다. 참고로 프로젝트 내 모든 디렉토리 또는 파일에 오른쪽 클릭하여 기능을 쓸 수 있다. 디렉토리를 우클릭했을 때와 파일을 우클릭했을 때 옵션이 조금 다르다.
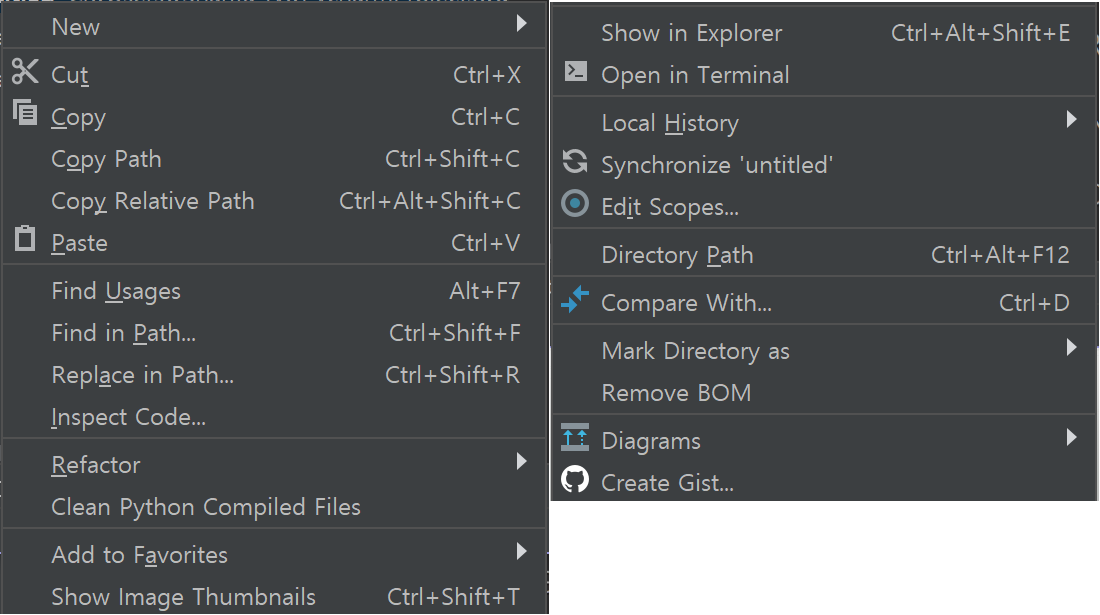
각 옵션을 대략 설명하면,
- New: File, Directory, Python File(
.py), Jupyter Notebook(.ipynb) 등을 생성한다. 단축키 설정하는 방법은 다음과 같다.- 새 Python 파일을 생성할 때는
New > Python File을 선택하면 된다. 단축키를 설정하는 방법은Settings > Keymap의 검색창에서Python File을 검색하면 아무 단축키가 지정되어 있지 않은 것을 볼 수 있다.Add Keyboard Shortcut을 눌러 원하는 키를 설정해주자.
- 새 Python 파일을 생성할 때는
- Cut, Copy, Paste 등은 설명하지 않겠다.
- Copy Path, Copy Relative Path: 각각 해당 디렉토리 또는 파일의 절대/상대 경로를 복사한다. 이미지나 데이터 파일 등의 경로를 써야 할 때 유용하게 쓸 수 있다. 단, 사용 환경에 따라 디렉토리 구분자가
/,\,//등으로 달라지는 경우가 있으니 주의. - Refactor: 해당 디렉토리 또는 파일의 이름을 변경한다. 이때 이 파일명을 사용하는 코드(file open 등)이 있으면 그 코드를 자동으로 수정하게 할 수 있다.
- Find Usages: 해당 파일을 참조하는 코드를 살펴볼 수 있다. Refactor와 같이 사용하면 좋다.
- Show in Explorer: 해당 디렉토리나 파일이 있는 디렉토리를 탐색기나 Finder 등에서 열 수 있다.
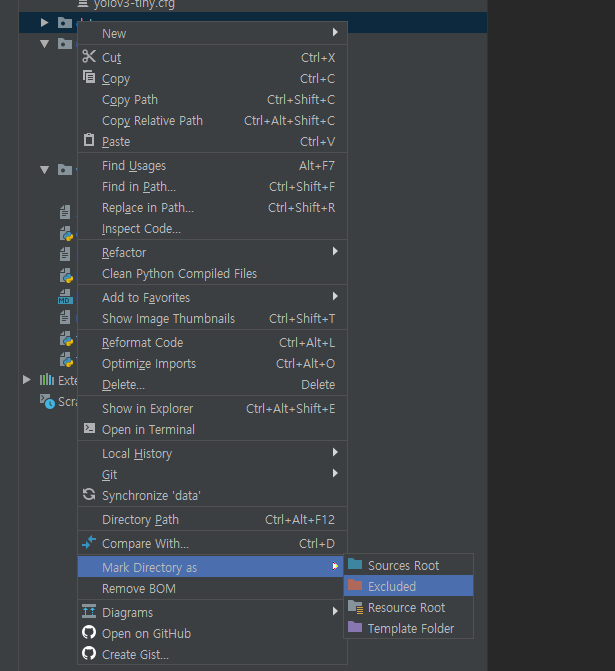
- Mark Directory as: 디렉토리의 속성을 설정한다. 세부 옵션이 4개 있다.
- **Sources Root: **프로젝트에서 코드의 최상위 폴더를 지정한다. 코드를 짜다 보면 프로젝트 루트 폴더에 직속된 파일이 아닌 경우 패키지나 파일 reference를 찾지 못하는 경우가 많은데, 그럴 때는 해당 코드를 포함하는 파일 바로 상위의 디렉토리를 Sources Root로 설정하면 빨간 줄이 사라지는 것을 볼 수 있다.
- Excluded: PyCharm 색인(Index)에서 제외시킨다. PyCharm은 Find Usages와 같은 기능을 지원하기 위해 프로젝트 내 모든 파일과 코드에 대해 indexing을 수행하는데(목차를 생성하는 거랑 비슷함), 프로젝트 크기가 크면 굳이 필요 없는 수많은 파일들까지 indexing해야 한다. 이는 PyCharm 성능 저하와 함께 색인 파일의 크기가 매우 커지므로(임시 파일까지 포함하여 수 GB까지 되기도 함) 너무 많으면 적당히 제외시키도록 하자.
- Resource Root: 말 그대로 Resource Root로 지정한다.
- Template Folder: 템플릿이 있는 폴더에 지정하면 된다. Pure Python을 쓸 때에는 별 의미 없다.
- Add to Favorites: Favorites창에 해당 디렉토리나 파일을 추가한다. 즐겨찾기 기능이랑 같다. 프로젝트 창 아래에서 창을 찾을 수 있고,
Alt + 2단축키로 토글할 수 있다.
새 파일 생성
이제 우클릭 > New > Python File로 새 파이썬 파일을 하나 생성하자. (현재 프로젝트 이름은 PythonTutorial이다)
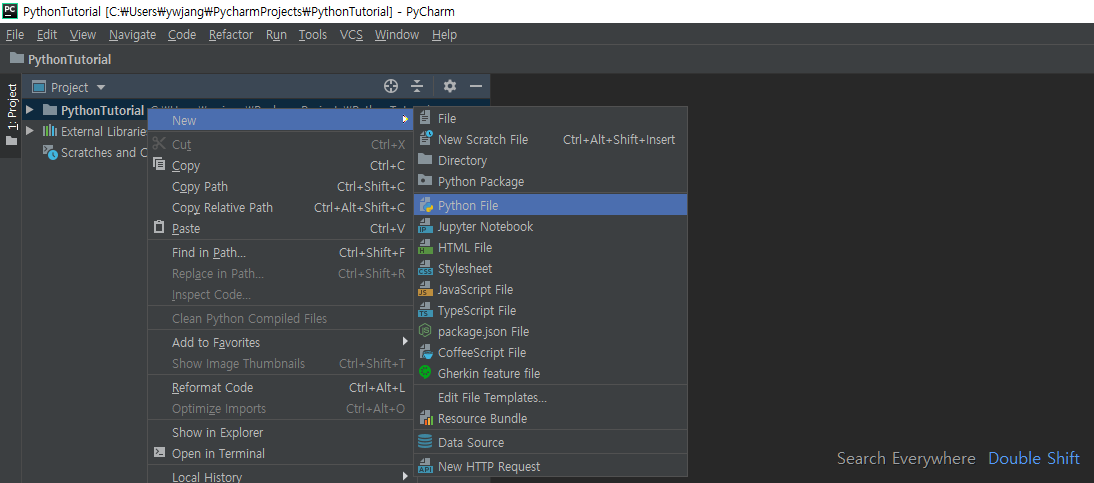
안타깝게도 새 Python 파일 생성을 위한 단축키는 지정할 수 없는 듯하다.
코드 실행(전체 또는 선택)
그리고 원하는 파일명을 입력한다. 필자는 tutorial이라고 입력하겠다. 그러면 파일명은 tutorial.py가 될 것이다.
이제 코딩할 수 있는 창이 열렸으니 코드를 입력하자.
print('Hello Pycharm!')
코드를 작성했으면 실행을 해 보아야 하지 않겠는가? 실행하는 방법은 여러 가지가 있다.
- 실행하고 싶은 코드 라인에 커서를 놓거나 실행할 만큼 드래그를 한 다음 위에서 단축키를 바꿨다면
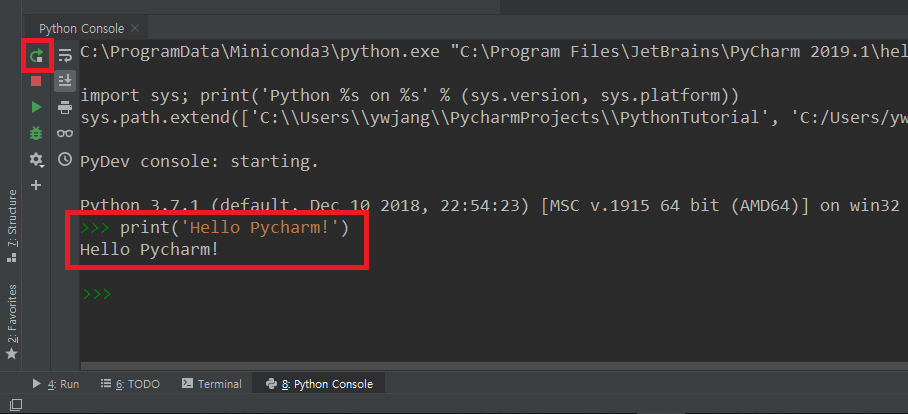
Ctrl + Enter, 바꾸지 않았다면Alt + Shift + E를 누른다. 그러면Python Console이라는 창이 아래쪽에 열리면서 실행한 코드와 실행 결과가 나타난다. 역시 단축키를 설정했다면Alt + 8로 열 수 있다. PyCharm Default settings에는 단축키가 할당되어 있지 않다.- 이것은 정확히는 Interpreter라고 부르는 대화형 파이썬 창에서 실행시키는 것이다. 명령창(cmd, terminal)에서
python을 실행시키고 코드를 입력하는 것과 같은 형태이다. Jupyter notebook과도 비슷하다. - 장점은 명령창에서 바로 입력하는 경우 오타가 나면 다시 입력해야 하는데 편집기에 코드를 써 놓고 필요한 만큼만
Ctrl + Enter로 실행시키는 이 방식은 코드 수정과 재사용이 훨씬 편하다는 것이다. - 콘솔에 문제가 있거나 해서 현재 실행창을 재시작하고 싶으면
Python Console왼쪽Rerun버튼(화살표)을 누르거나Ctrl + F5를 입력한다. - 참고로 PyCharm 아래쪽/왼쪽/오른쪽에 있는 창들 중에서 옆의 숫자는 단축키를 간략하게 나타낸 것이다. 예를 들어 필자는 좀 전 설정에서
Python Console창의 단축키를Alt + 8로 설정해 놨는데, 그래서 옆에8이라는 숫자가 표시된다.
- 이것은 정확히는 Interpreter라고 부르는 대화형 파이썬 창에서 실행시키는 것이다. 명령창(cmd, terminal)에서
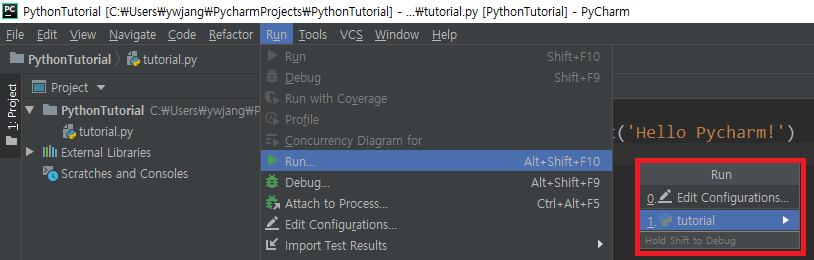
- Run > Run…을 누르면 실행시키고 싶은 파일 목록이 나타난다. 이 중 원하는 파일(현재는
tutorial)을 선택하면Terminal이라는 창에서 해당 파일의 전체 코드가 실행된다.- 다시 실행할 때는 Run > Run을 선택하면 마지막으로 실행한 파일이 전체 실행된다.
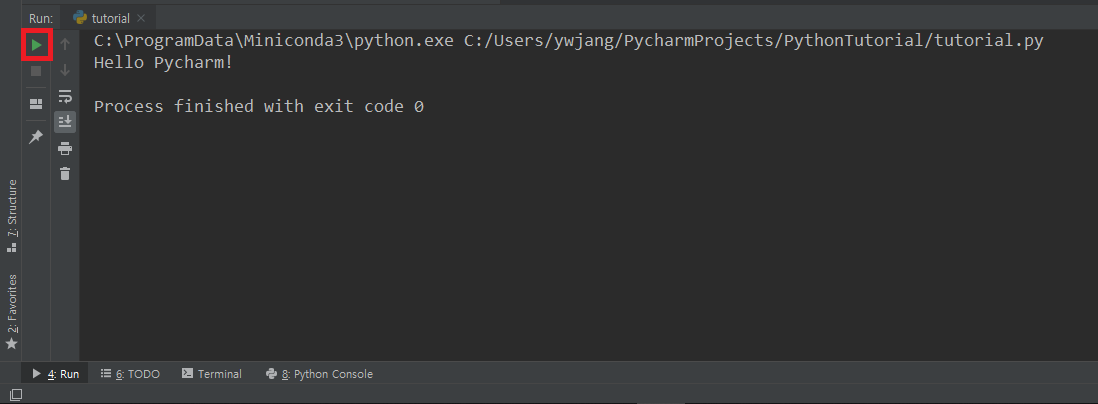
- 아래 그림의
Terminal창 왼쪽의ReRun버튼을 눌러도 마지막으로 실행한 파일이 다시 실행된다. 단축키는Ctrl + F5이다. - PyCharm 오른쪽 위에서도 실행할 파일을 선택 후 실행시킬 수 있다.
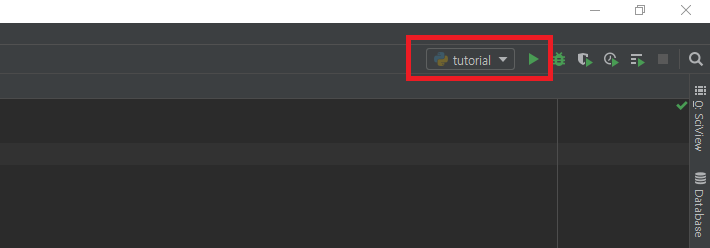
- PyCharm 아래쪽의
Terminal창을 클릭하거나Alt + T단축키(바꾼 것이다)로Terminal창을 열어서python tutorial.py를 입력한다.- 그렇다. Python 파일 실행 방법과 똑같다. 이
Terminal창은 명령창(cmd 또는 터미널)과 똑같다. - 대략
tu정도까지만 입력하고Tab키를 누르면 파일명이 자동완성된다. - 이 방법도 역시 해당 파일에 들어있는 모든 코드를 전체 실행시킨다.
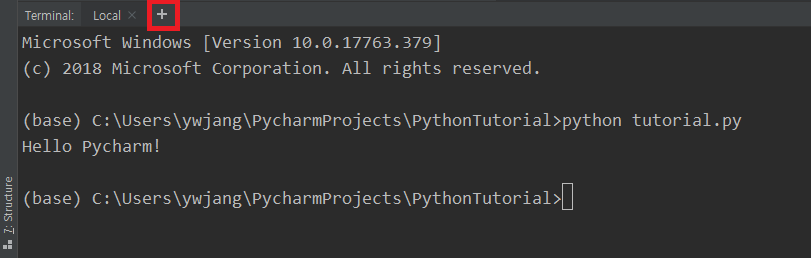
- 터미널 창 답게 여러 개의 세션을 열어 놓을 수 있다. 기본적으로
Local이라는 이름의 탭이 생성되며, 오른쪽의+버튼을 클릭하라.
- 그렇다. Python 파일 실행 방법과 똑같다. 이
Project창에서도 해당 파일을우클릭 > Run (파일명)을 클릭하면 해당 파일의 코드 전체가 실행된다.- 편집 창에서도 파일명 탭을
우클릭 > Run (파일명)해도 된다. 실행 방법은 많다. - Terminal에서 Local Environment에서 실행되는 대신, Remote SSH session에서 실행시키는 방법은 여기를 참고하면 된다.
고급 설정: working directory
working directory란 말 그대로 작업 중인 directory로, 작업 중인 환경의 path 또는 실행하려는 파일의 경로를 의미한다.
현재 실행하는 python 파일 또는 code가 working directory에서 진행되며, 상대 경로는 모두 이 working directory에서 출발한다.
PyCharm에서 코드를 실행하다 보면 경로가 자꾸 안 맞아서 오류가 나는 경우가 꽤 있는데, 이는 working directory가 잘 지정되지 않아서 생기는 문제이다.
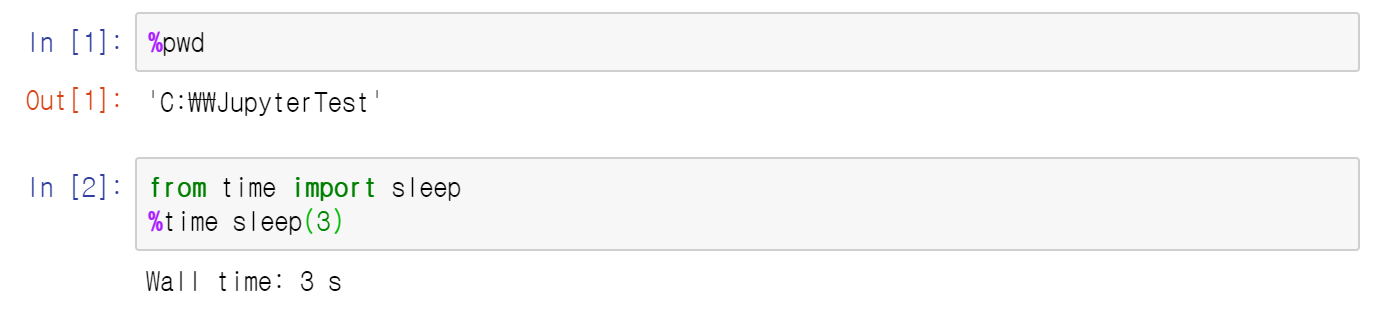
현재 코드 혹은 파일의 working directory가 어딘지 알려면 다음 코드를 넣어서 실행해보자.
import os
print(os.getcwd())
이제 PyCharm에서 working directory를 설정하는 방법을 살펴보자.
PyCharm에는 기본적으로 3가지의 실행 방법이 존재한다.
Ctrl + Enter로 interpreter에서 실행- Terminal에서
python <filename>으로 실행 또는python명령어로 interpreter 실행 - Run 메뉴로 실행
각각의 경우에 working directory를 설정하는 방법이 조금 다르다.
먼저, Ctrl + Enter로 interpreter에서 실행하는 경우를 보면:
Settings에서 working directory를 검색하자.
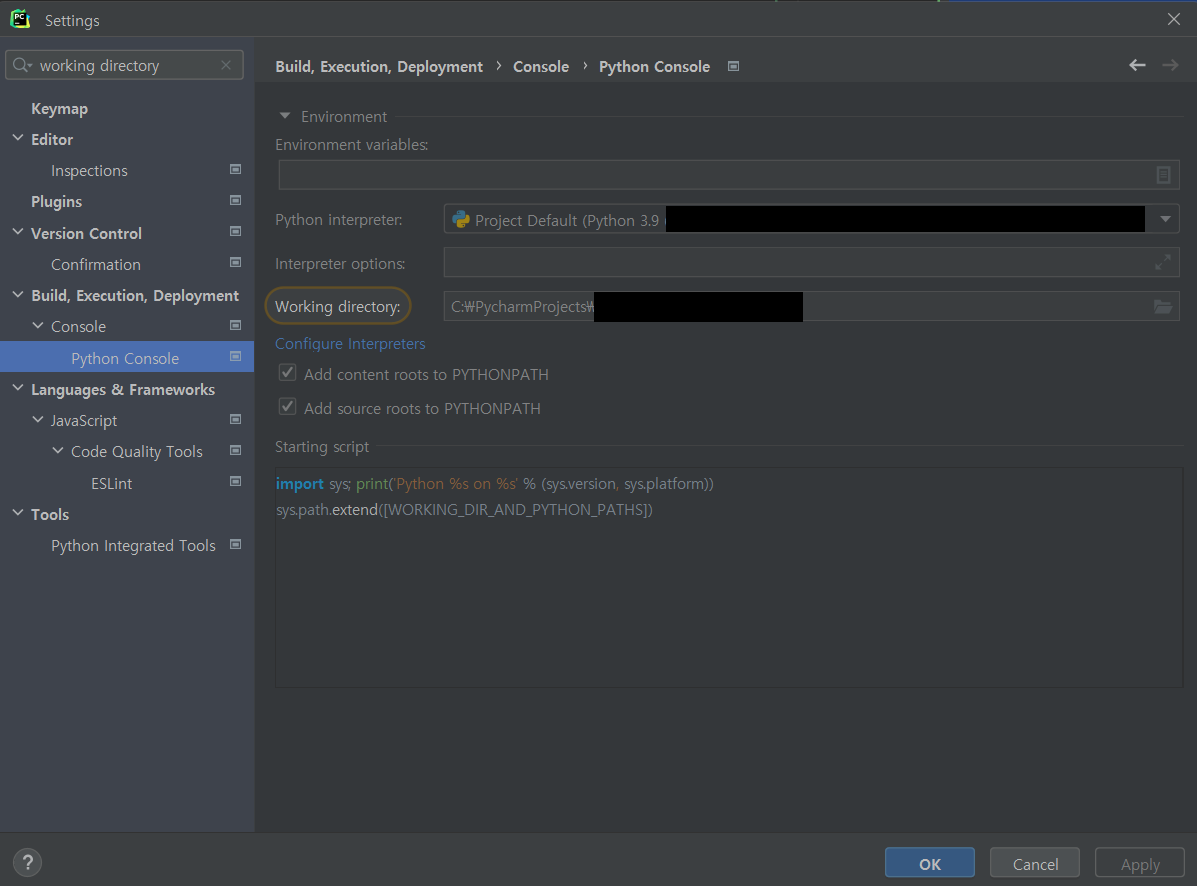
그리고 Build, Execution, Deployment > Console > Python Console 메뉴를 보면 Working directory를 설정하는 메뉴가 보인다. 이 경로를 바꿔준 후 Python Console을 재시작하면 working directory가 변경된다.
다음으로 Terminal에서 실행하는 경우는 간단하다. cd <path>명령어를 terminal에 입력하여 시작 경로를 바꿔준 다음 python <filename>이나 python을 실행하면 현재 위치가 working directory가 된다.
마지막으로, Run 메뉴로 실행할 때를 보면:
Ctrl + Shift + F5으로 run configuration을 생성하면, 기본적으로 해당 파일이 위치한 디렉토리가 working directory로 지정된다.
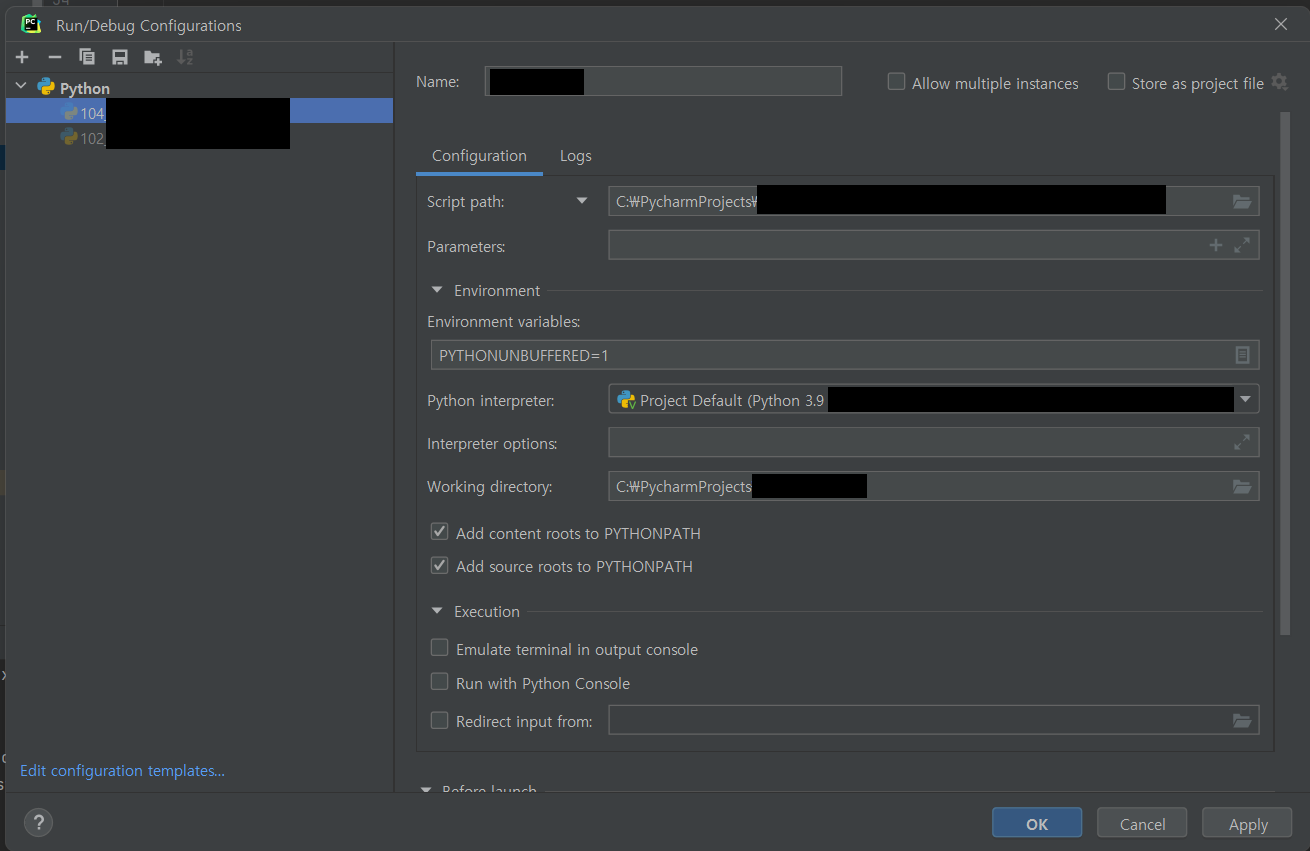
해당 configuration만 바꿀 생각이라면 중간의 Working directory를 원하는 path로 변경해주면 된다.
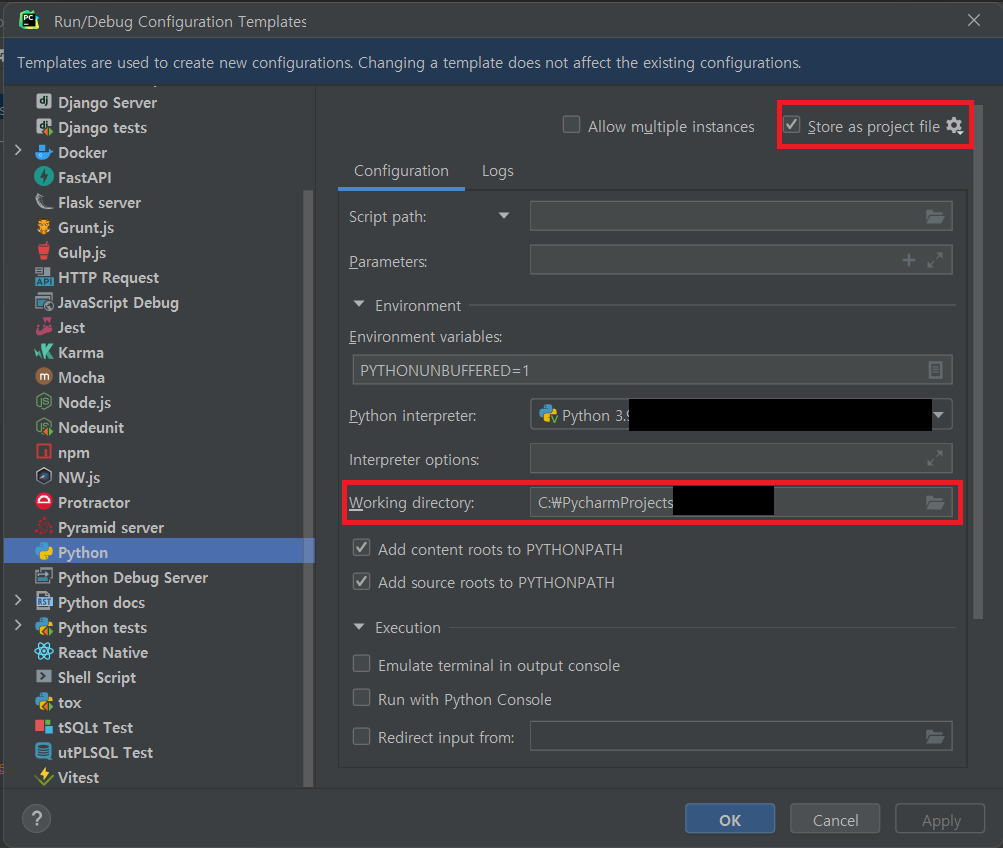
만약 지금 다루는 프로젝트 전체의 default working directory 설정을 하고 싶다면 위 그림의 왼쪽 아래에 있는 Edit configuration templates...를 클릭한다.
그 다음에 아래 그림처럼 Working directory 항목을 변경하면 된다. 프로젝트 파일에 넣으려면 오른쪽 위 박스의 Store as project file을 체크하자.
편집 창(코드 편집기)
코드를 편집하는 부분에도 여러 기능들이 숨어 있다.
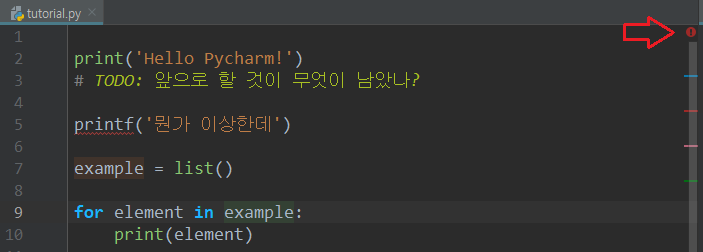
위 그림의 오른쪽 부분을 보자. 경고인 듯한 느낌표와 함께 여러 색깔의 줄이 있다. 현재 커서는 9번째 라인의 example 변수에 위치해 있다.
- 먼저 왼쪽에는 줄 번호(line number)라는 것을 다들 알 수 있을 것이다.
- 하지만 이 단축키는 모르는 사람이 많다.
Ctrl + G를 누르면 원하는 라인으로 이동할 수 있다. 줄의 어느 부분으로 이동할지도line:column형식으로 정할 수 있다. 줄 번호만 지정하고 싶으면 그냥 숫자만 입력하면 된다.
- 하지만 이 단축키는 모르는 사람이 많다.
- 빨간 화살표가 가리키고 있는 경고 표시는 현재 이 파일에 syntax error가 있다는 뜻이다. 메인 화면에도 해당 부분에는 빨간 줄이 그어진다(
printf). 그리고 오른쪽에도 빨간색 bar가 생긴다.- 이 bar들은 현재 파일에서의 상대적 위치를 뜻한다. 즉, 예를 들어 맨 아래에 있는 오류 코드가 화면에 안 보이더라도 bar는 제일 아래쪽 근처에 표시된다.
- 커서가 위치한 곳이 변수나 함수 등이라면 해당 파일의 모든 부분에서 같은 이름을 가진 변수(또는 함수)에는 옅은 초록색 배경색이 칠해진다. 그리고 해당 변수(함수)가 선언된 곳에는 옅은 주황색으로 배경색이 칠해진다(이 색깔은
Settings에서 바꿀 수 있다). 어디서 사용되고 있는지 쉽게 알 수 있다. 그리고 그림에서 오른쪽에도 주황색 또는 초록색 짧은 bar가 생긴 것을 볼 수 있다.- 옅어서 잘 안보인다면 색깔을 바꾸거나 아니면 Find and Replace(
Ctrl + H)로 찾으면 더 선명하게 표시되기는 하는데, 해당 이름을 포함한 다른 변수 등도 같이 선택된다는 문제가 있다. 적당히 선택하자.
- 옅어서 잘 안보인다면 색깔을 바꾸거나 아니면 Find and Replace(
- 특별히 TODO 주석문은 일반 회색 주석과는 다르게 연두색으로 눈에 띄게 칠해진다. 또한 오른쪽에 파란색 bar가 생긴다. 이 주석은 참고로
TODO창(Alt + 6)에서도 확인 가능하다. 못다한 코딩이 있을 때 쓸 수 있는 좋은 습관이다.
편집 창의 아무 부분을 우클릭하여 Local History > Show History를 클릭하면 해당 파일이 어떻게 수정되어 왔었는지가 저장된다. 잘 안 쓸 수도 있지만 잘못 지운 상태로 코딩을 좀 진행했다거나 하는 상황에서 쓸모 있는 기능이다.
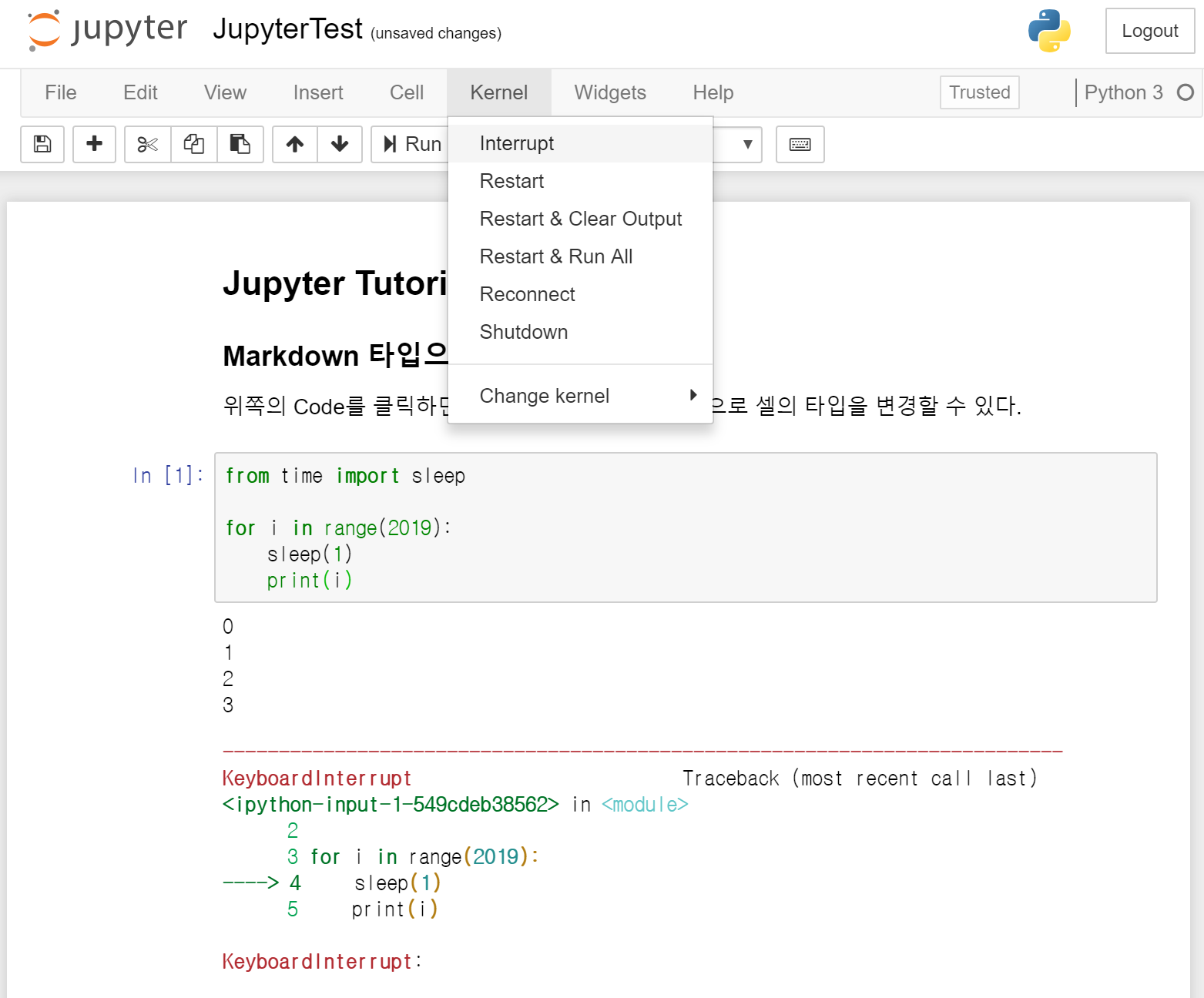
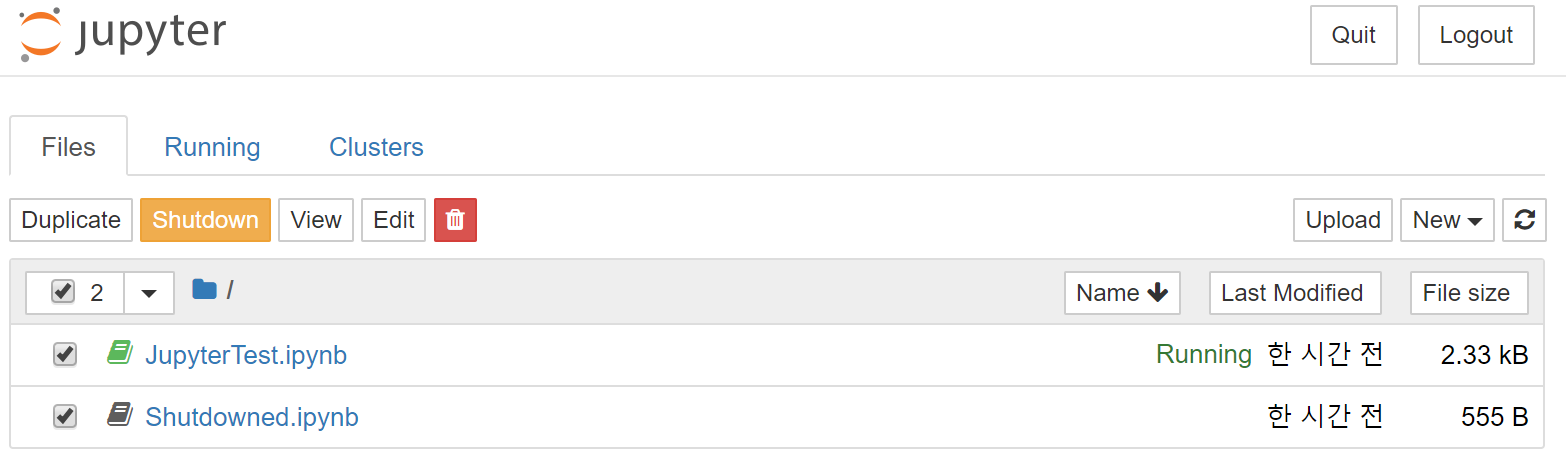
.ipynb 파일 사용
PyCharm에서도 .ipynb파일을 사용할 수 있다. 웹브라우저에서 보는 jupyter notebook과 모양이 매우 흡사하다.
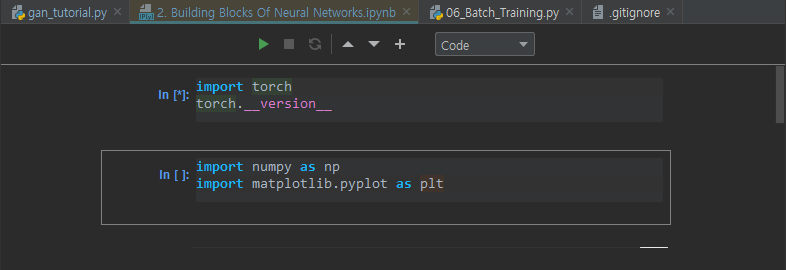
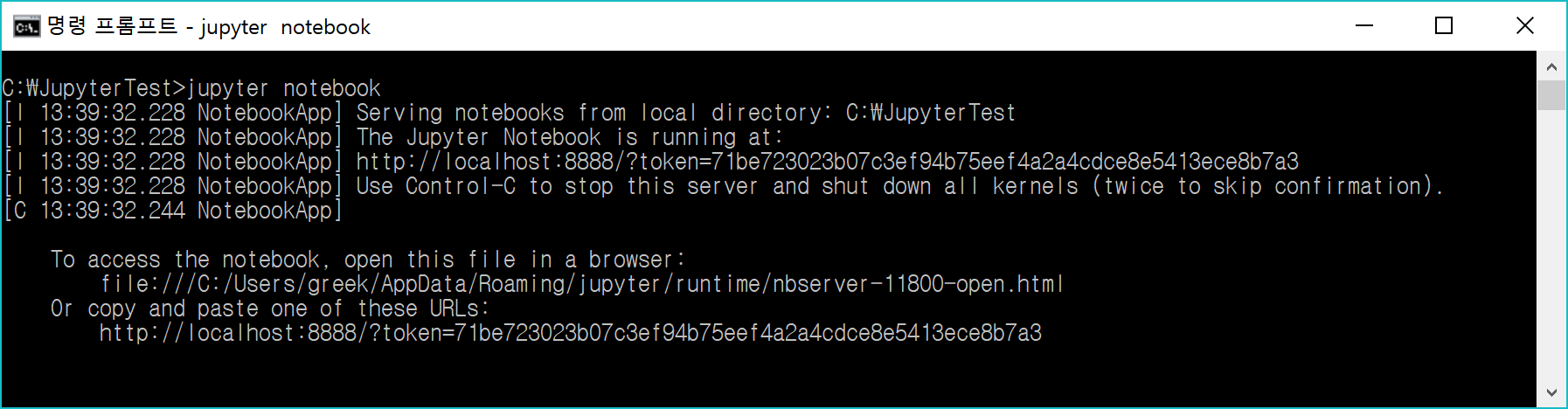
위쪽의 셀 실행 버튼을 누르면(초록색 삼각형) jupyter 서버 주소 토큰을 입력하라고 나온다. 본인이 jupyter 서버를 실행시켰다면 jupyter notebook 서버를 켠 상태에서 해당 주소를 입력해주고 실행하면 .ipynb 파일을 브라우저에서 쓰는 것처럼 사용할 수 있다.
자동완성 기능
일반적인 편집기에는 다 들어있는, 변수나 함수 등의 이름을 일부만 입력하고 Tab 키를 누르면 자동완성이 된다는 것은 알고 있을 것이다.
아래는 일부 코드 블록을 간편하게 입력할 수 있는 방법을 소개한 것이다.
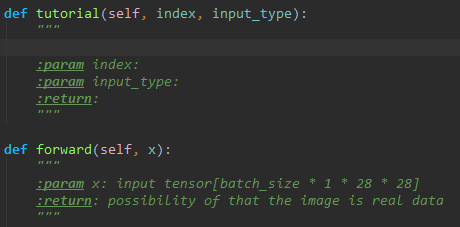
- 클래스 내부의 함수를 작성할 때는
(를 입력하는 순간self인자가 자동으로 추가된다. 기본적으로 써야 하는 인자이기 때문에 자동 추가되며, 이를 비활성화하고 싶으면File > Settings > Editor > General > Smart Keys에서 바꿀 수 있다. - 함수나 클래스를 작성할 때, 삼중큰따옴표를 함수 prototype 정의 바로 밑에 써 주면 깔끔하게 함수 사용법을 정리할 수 있는 주석이 나타난다.
- 빈 줄에 함수 설명을,
param에는 각 인자의 설명을,return에는 이 함수의 반환값에 대한 설명을 써 주자.
- 빈 줄에 함수 설명을,
빠른 선택, 코드 정리, 편집 등등 단축키
원하는 부분을 빠르게 선택할 수 있는 단축키는 많다. 이를 다 알고 빠르게 할 수 있다면 코딩 속도는 아주 빨라진다.
- 변수/함수 더블클릭: 해당 변수 이름 선택
Ctrl + Z: 실행 취소(Undo)Ctrl + Shift + Z: 재실행(Redo)Ctrl + D(Duplicate): 현재 커서가 있는 한 줄(또는 드래그한 선택 범위)을 복사해 아래에 붙여 넣는다.Ctrl + X/Ctrl + C: 현재 커서가 있는 한 줄(또는 드래그한 선택 범위)을 잘라내기/복사한다. 한 줄도 된다는 것을 기억하라.Ctrl + W: 현재 선택 범위의 한 단계 위 범위를 전체 선택한다. 무슨 말인지 모르겠다면 직접 해 보면 된다. 범위는 블록이나 괄호 등을 포함한다.Tab: 현재 커서가 있는 한 줄(또는 드래그한 선택 범위)를 한 단계(오른쪽으로 이동) indent한다.Shift + Tab: 현재 커서가 있는 한 줄(또는 드래그한 선택 범위)를 반대 방향으로(왼쪽으로 이동) 한 단계 indent한다.-
Ctrl + A: 현재 파일의 코드를 전체선택한다. Ctrl + Shift + O(Import Optimization): 코드 내에 어지럽게 널려 있는 import들을 파일 맨 위로 모아 잘 정리한다.-
Ctrl + Shift + L: 코드의 빈 줄, indentation 등을 한 번에 정리한다. Ctrl + 좌클릭: 해당 변수/함수가 선언된 위치로 화면/커서가 이동한다. 변수가 어떻게 정의됐는지 또는 함수가 어떻게 생겼는지 보기 유용하다.Alt + 좌클릭: 커서를 원하는 곳에 일단 놓고, 또 같은 것을 입력하고 싶은 곳에Alt를 누른 채로 새로 클릭하면, 커서가 여러 개가 되는 것을 확인할 수 있다. 이 상태에서 키보드로 입력을 시작하면 여러 곳에서 한번에 입력이 가능하다.
이외에도 기능은 정말 많다(Toggle Case, Convert indents to space/tab, Copy as Plain Text, Paste without Formatting, …). 한번 잘 찾아보자.
각각의 기능들은 Edit 탭이나 Navigate, Code, Refactor 탭 등에 잘 분류되어 있다. 한번쯤 살펴보고 본인에게 필요한 기능들은 기억해두면 좋다.
찾기(및 바꾸기), (Ctrl + F | Ctrl + H)
찾기 및 바꾸기의 기본 단축키는 Ctrl + R이다(Replace). 많은 다른 프로그램들은 Ctrl + H를 쓰기 때문에 바꾸는 것도 좋다.
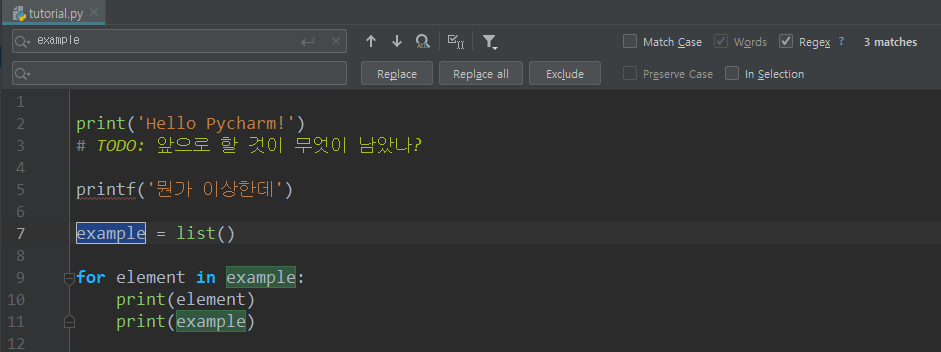
여기도 여러 기능들이 있다. 찾기 설명은 찾기 및 바꾸기의 설명 안에 포함되므로 생략하겠다.
아래에서 설명할 기능들은 모두 그림에 나온 버튼이나 체크박스 등에 대한 것이다.
- 왼쪽 검색창에 찾고자 하는(또는 대체될) 문자열 또는 정규식을 입력한다. 아래쪽 창에는 대체할 문자열을 입력한다.
- 왼쪽 돋보기를 클릭하면 이전에 검색했던 문자열들을 재검색할 수 있다.
F3: 다음 것 찾기Shift + F3: 이전 것 찾기- Find All: 전부 다 찾아서 보여준다.
- Select All Occurrences: 매칭되는 결과를 전부 선택한다.
- Show Filter Popup: 찾을 범위를 지정할 수 있다. 전부(Anywhere), 주석에서만(In comments), 문자열에서만(In String Literals), 둘 다에서만, 혹은 제외하고 등의 필터를 설정 가능하다.
- Match Case: 체크하면 대소문자를 구분한다.
- Words: 정확히 단어로 맞아야 할 때(해당 문자열을 포함하는 단어를 제외하는 등) 체크한다.
- Regex: 정규표현식을 사용하여 찾는다. 잘 쓸 줄 안다면 아주 좋다.
- 오른쪽에는 몇 개나 매칭되는 문자열을 찾았는지 보여준다(3 matches). 만약 하나도 없으면 문자 입력 창이 빨갛게 되면서 No matches라고 뜬다.
- Replace(
Alt + p): 현재 선택된 부분을 대체한다.. - Replace all(
Alt + a): 매칭되는 모든 문자열을 찾아 대체한다. - Exclude: 해당 매칭된 부분은 대체할 부분에서 제외한다.
- Preserve Case: 대체 시 대소문자 형식을 보존한다.
- In Selection: 파일 전체가 아닌 선택한 부분에서만 찾는다.
더 넓은 범위에서 찾기
선택한 파일 말고 더 넓은 범위에서 찾으려면 Ctrl + Shift + F를 누르거나 다음 그림을 참고한다.
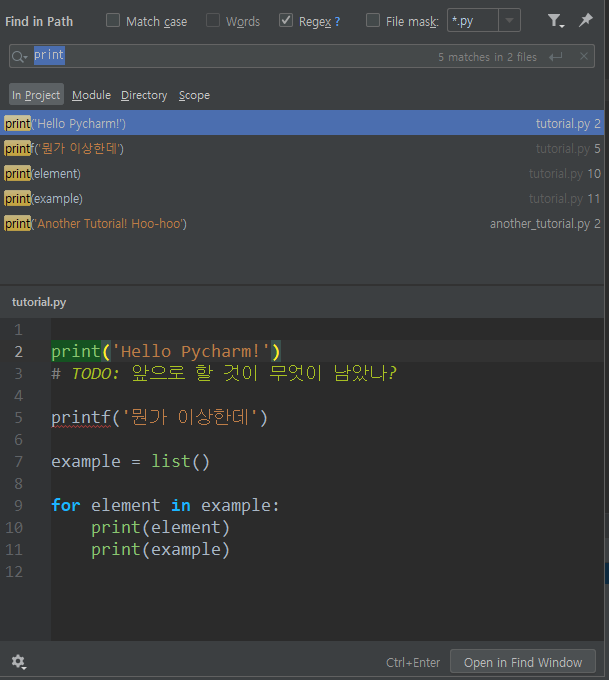
위의 Match Case등은 사용법이 똑같지만, 여기서는 파일뿐 아니라 프로젝트 전체, 모듈, 디렉토리, 또는 특정 범위(scope)에서 찾을 수 있다. Edit > Find > 안의 다른 선택지들 역시 사용법은 크게 다르지 않으니 참고하자.
다른 (범용) 찾기 단축키로 Shift + Shift(Shift 키를 두번 누름)이 있다. 한번 해 보자.
변수/함수 등이 사용된 위치 찾기
찾고자 하는 변수/함수를 우클릭하여 Find Usages를 클릭하거나 Alt + F7을 누른다.
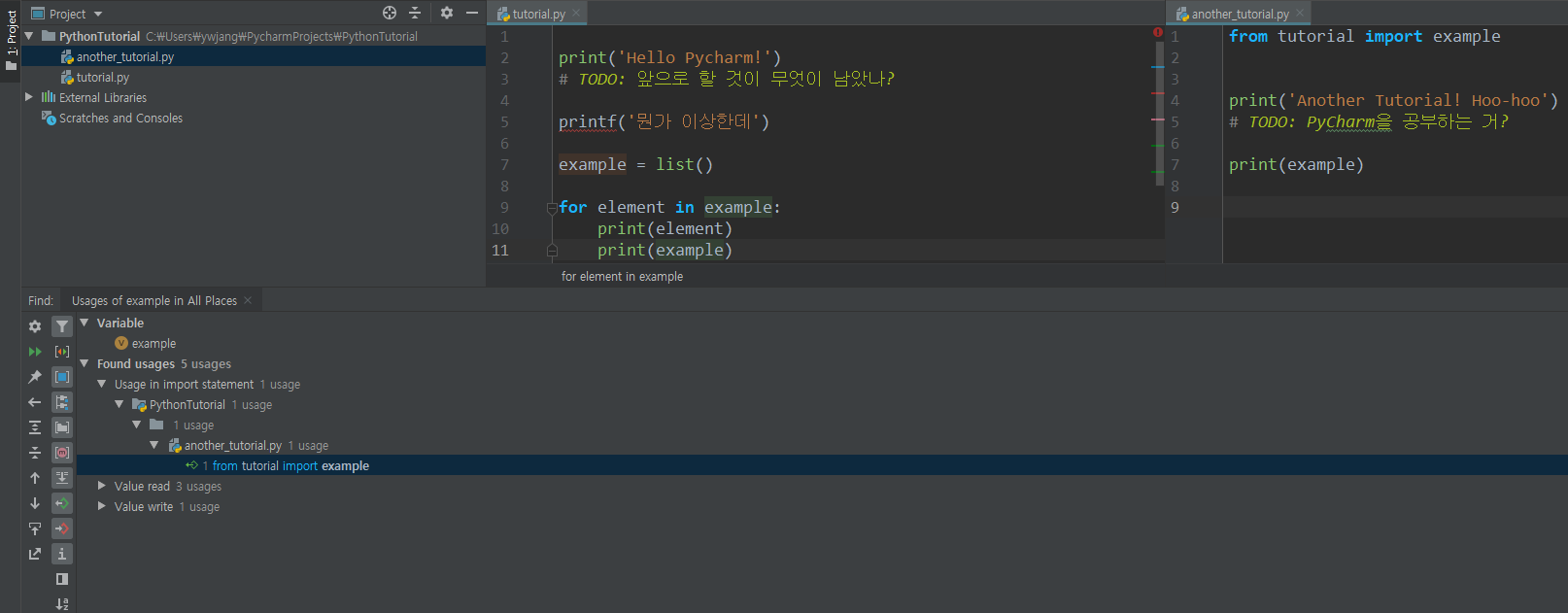
그러면 해당 변수/함수가 어디서 사용되었는지 정보가 전부 나온다. 왼쪽에 있는 많은 버튼들로 적절한 그룹별로 묶거나 하는 등의 작업을 할 수 있다.
Refactor(이름 재지정)
변수명을 바꾸고 싶어졌을 때가 있다. 무식하게 일일이 바꾸거나, 아니면 Find and Replace로 선택적으로 할 수도 있다.
하지만 매우 쉽고 편리한 방법이 있다. 해당 변수를 선택하고 Shift + F6을 누른다.
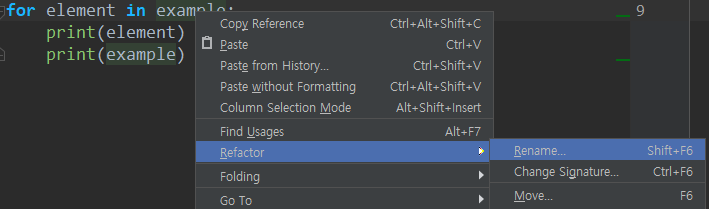
원하는 이름으로 바꾸고 Refactor을 누르면 해당 변수만 정확하게 원하는 이름으로 바뀐다. 심지어 import해서 사용한 다른 파일에서도 바뀐다.
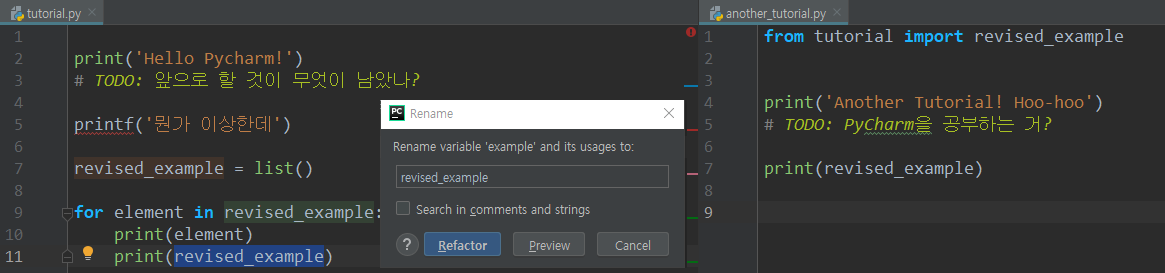
아주 편리하다.
Diff(Differences viewer for files)
2개의 파일 코드가 어떤 차이가 있는지 알아보려면, Project 창(Alt + 1)에서 2개의 파일을 Ctrl키로 동시 선택하거나, 한 파일을 누르고 Ctrl + D를 누른다. 그러면 1개의 파일을 선택했다면 추가 파일을 선택하는 창이 나오고, 이것까지 선택하면 2개의 파일을 비교하는 창이 나온다.
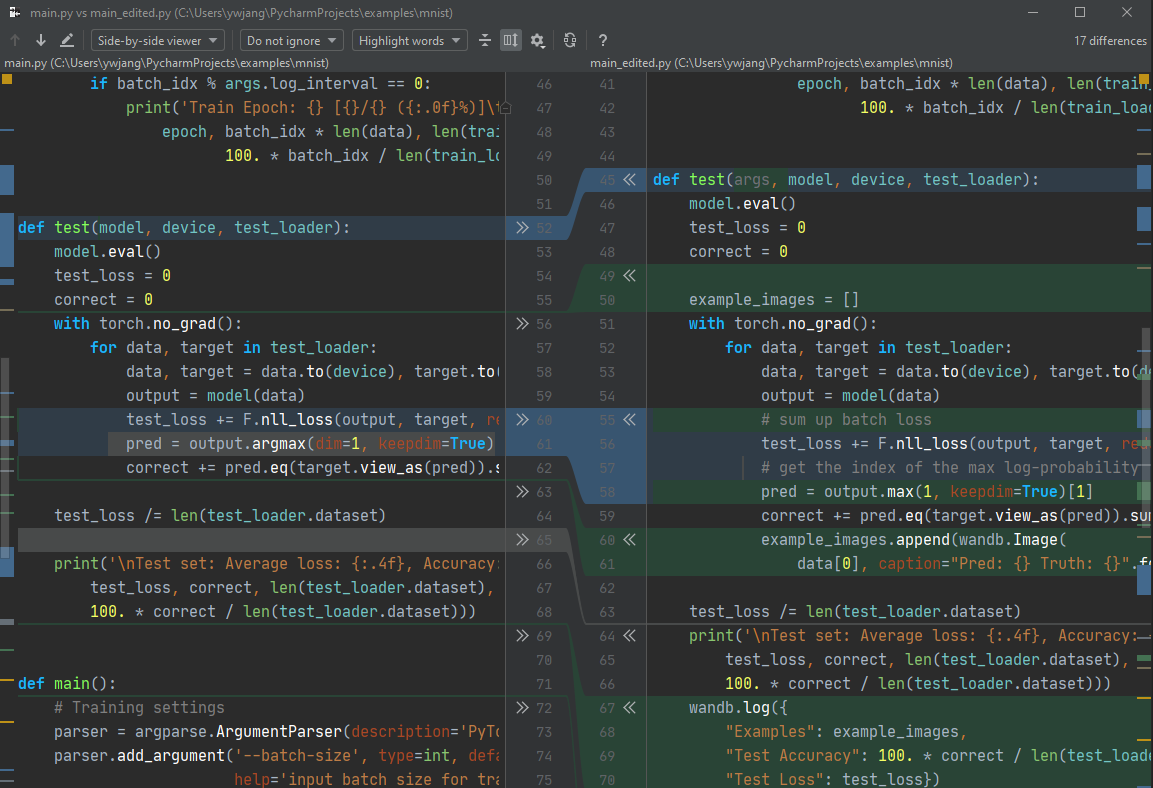
- 파란색으로 표시된 부분은 2개의 파일이 다른 코드,
- 회색으로 표시된 부분은 1번째 파일(왼쪽 파일)에만 있는 코드,
- 초록색으로 표시된 부분은 2번째 파일(오른쪽 파일)에만 있는 코드
를 나타낸다.
중간의 >>나 << 표시를 누르면 해당 코드가 화살표 방향으로 복사되어 덮어씌운다.
Bookmark(북마크) 기능
창 위치 및 크기 변경
Python Console 등의 창은 위치나 크기가 변경 가능하다. 크기는 창의 경계에 마우스 커서를 갖다대는 방식이니 굳이 설명하지 않겠다.
위치는 탭을 끌어서 이동시키거나 아니면 우클릭 > Move to > 원하는 곳을 선택하면 된다.
또 모니터를 2개 이상 쓴다면 View Mode에서 해당 설정을 변경할 수 있다. 기본은 PyCharm 내부에 위치 고정된 Dock Pinned 모드이다. Float이나 Window를 선택하면 위치를 자유롭게 이동할 수 있다.
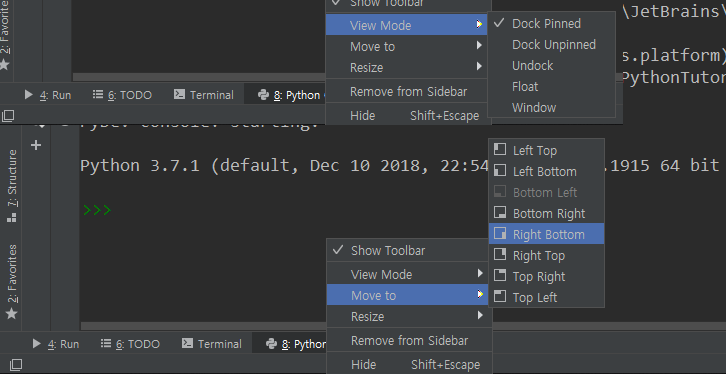
모니터 크기는 충분한데 코드는 위아래로만 길게 보여서 공간이 아까웠다면, PyCharm에서는 굳이 그럴 필요 없다. Vim의 Split View와 비슷한 기능이 있다.
편집 창(메인 화면)의 탭을 우클릭한 다음 Split Vertically를 클릭해 보라. Split Horizontally도 괜찮다.
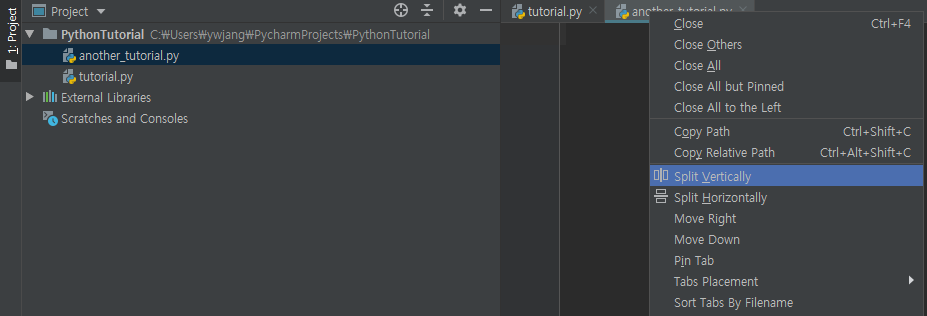
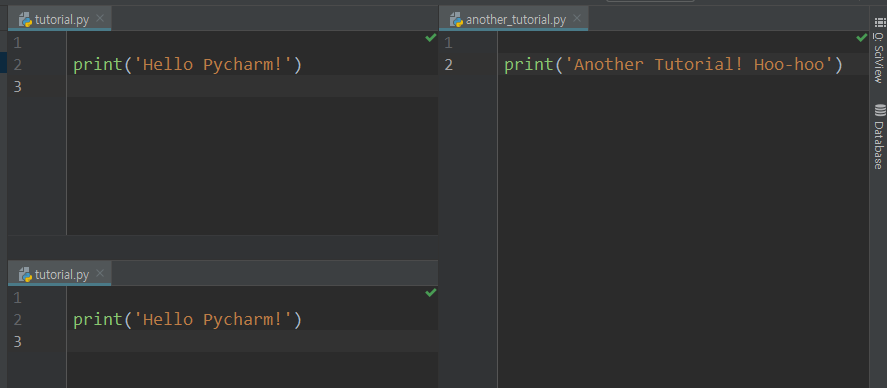
동일한 파일을 여러 번 열고 다른 부분을 보는 것도 가능하다. 꽤 유용한 기능이다.
Favorites 창(Alt + 2)
Alt + 2를 눌러 Favorites 창을 연다.
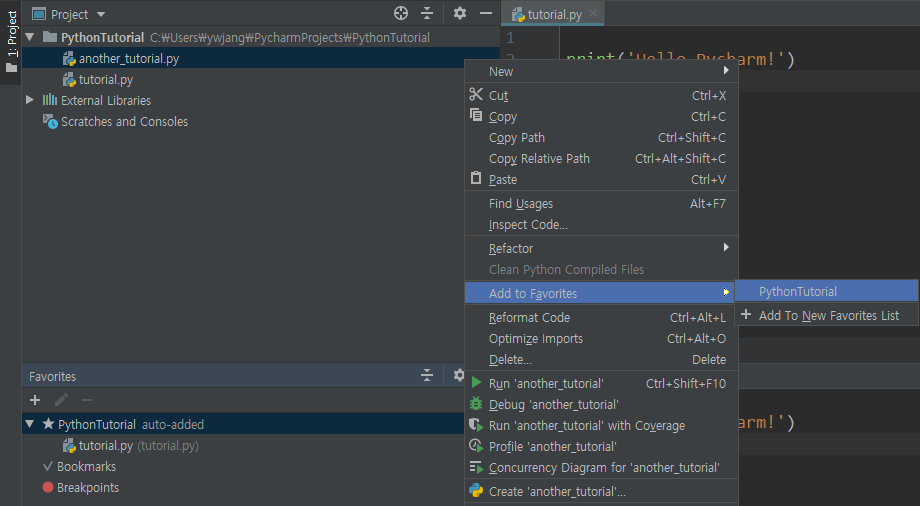
말 그대로 즐겨찾기이다. 자주 사용하는 파일을 Favorites에 등록할 수 있다. 기본적으로 현재 프로젝트 이름으로 리스트가 하나 생성되어 있다.
이게 싫거나 새로운 리스트를 추가하고 싶으면 아래 그림의 오른쪽에 보이는 Add to New Favorites List를 클릭하라.
그러면 Favorites 창에 해당 리스트에 추가한 파일이 등록된다. 이제 프로젝트 창에서 찾을 필요 없이 바로 파일을 열어볼 수 있다.
Run 창(Alt + 4)
Alt + 3은 기본적으로 할당되어 있지 않다. 추가하고 싶으면 추가하라.
Run 창은 조금 전 코드를 실행할 때 본 것이다. 여기서는 왼쪽에 몇 가지 버튼이 있는데, 각각
- Rerun(마지막 실행 파일 재실행)
- Stop(현재 실행 중인 파일 실행 중단)
- Restore Layout(레이아웃 초기화)
- Pin Tab(현재 실행 탭 고정)
- Up/Down to Stack Trace(trace 상에서 상위 또는 하위 단계로 이동)
- Soft-Wrap(토글 키. 활성화 시 출력 내용이 한 줄을 넘기면 아래 줄에 출력됨. 비활성화 시 스크롤해야 나머지 내용이 보인다)
- Scroll to the end(제일 아래쪽으로 스크롤)
- Print(출력 결과를 정말 프린터에서 뽑는 거다)
- Clear All(현재 출력 결과를 모두 지우기)
Soft-wrap 등은 꽤 유용하므로 잘 사용하자.
Run 창을 우클릭 시 Compare with Clipboard 항목이 있는데, 현재 클립보드에 있는(즉, Ctrl + C 등으로 복사한) 내용과 출력 결과를 비교하는 창을 띄운다. 정답 출력 결과를 복사해 놨다면 유용하게 쓸 수 있다.
TODO 창(Alt + 6)
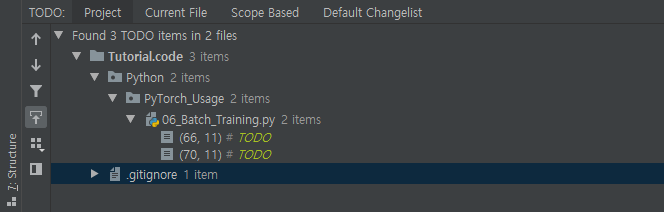
PyCharm에서는 주석(#)을 달면서 앞에 TODO:라는 문구를 적으면 해당 주석은 특별히 눈에 띄는 연두색으로 바뀐다.
이 TODO들은 앞으로 해야 할 것을 모아 놓은 것이다. 이를 나중에 찾아보려면 PyCharm 아래쪽의 TODO 창을 클릭하거나 Alt + 6으로 열자.
그럼 현재 프로젝트의 어느 부분이 미완성인 채로 남아 있는지 한번에 볼 수 있다. 기본적으로 파일별로 정렬되어 있다.
Structure 창(Alt + 7)
현재 파일이 어떤 구조로(클래스는 무엇을 포함하고, 함수는 어떤 statement들을 포함하는지 등) 되어 있는지 살펴보려면 코드를 한줄한줄 다 뜯어보는 대신 Structure 창에서 볼 수 있다.
어떤 변수가 어디에 정의되었는지까지도 볼 수 있다.
Python Console 창(Alt + 8)
단축키는 필자가 지정한 것이다.
이는 명령창에서 Python을 실행했을 때 나타나는 것과 같다고 말했었다. 어려울 것 없이 똑같이 사용할 수 있다.
단, 사용 환경에 따라 이런 대화형 창에서는 가용 메모리를 다 쓰지 못하는 경우가 있다. 예를 들어 GPU 메모리를 수 GB씩 쓰는 학습 알고리즘 등의 경우 터미널에서 python 파일명으로 실행하면 잘 작동하는데 대화형 창에서 실행하면 작동이 중지되는 것을 종종 볼 수 있다. 참고하자.
Version Control 창(Alt + 9)
이건 Git 기능을 PyCharm에 옮겨놓은 것과 같다. git 사용법을 안다면 쉽게 이용 가능하다. 하지만 git을 잘 알고 있다면 그냥 Python의 terminal 창을 열어서 git 명령어를 치는 것이 편할 수 있다.
SciView 창(Alt + 0)
PyCharm에서 matplotlib 등으로 그래프를 그린다면 바로 이 창에 표시가 된다.
여기서 한 장씩 보기 또는 grid 모드로 보기 등을 선택할 수 있고, 확대 및 축소, 1:1, 창 크기에 맞추기 등의 옵션도 가능하다.
그림 오른쪽 위에 작게 표시되는 x 표시를 누르면 그림을 지울 수 있다. 또한 우클릭을 통해 저장하거나 전체 삭제 등의 작업을 할 수 있다. 배경화면 사진으로도 지정할 수 있다(!).
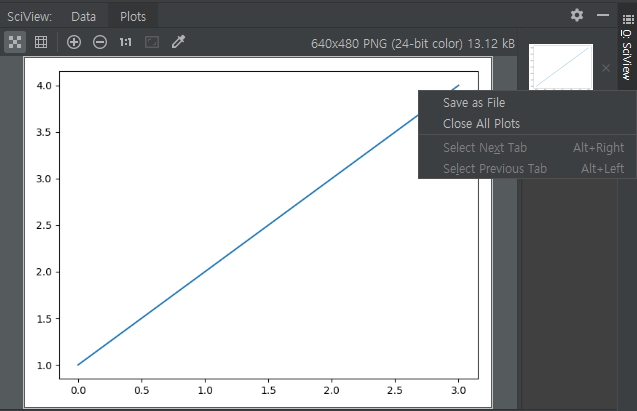
참고로 pycharm에서는 일반적으로 plt.show()를 그냥 하면 그림이 표시되지 않는 경우가 있다. 이에 대한 해결법은 링크를 참고하자.
plt.interactive(False)
# plt.show(block=True)
디버깅(Debugging)
PyCharm의 훌륭한 기능 중 하나이다. 사실 웬만한 코드 편집기에 있기는 한데, python을 쓰는 사람들 중에 이를 활용할 줄 알아서 쓰는 경우는 생각보다 많지 않은 것 같다.
(물론 알아서 코드를 수정해 주는 것은 아니다…)
예를 들어 다음과 같은 프로그램을 짰다고 생각해 보자.
def func(idx):
example[idx] = example[idx - 2] + example[idx - 1]
example = [1] * 20
for i in range(20):
func(i)
for i, e in enumerate(example):
print('fibonacci({})\t: {:8d}'.format(i, e))
결과는 다음과 갈다.
fibonacci(0) : 2
fibonacci(1) : 3
fibonacci(2) : 5
fibonacci(3) : 8
...
피보나치 수열은 2부터 시작하지 않으므로 잘못되었다. 그러면? 디버깅을 시작한다(물론 간단한 예시라서 바로 고칠 수 있지만 우선 넘어간다).
디버깅을 시작하는 방법은 여러 가지가 있다. 이는 코드를 실행할 때와 매우 비슷한데, 초록색 삼각형 대신 벌레 모양의 아이콘을 클릭하면 된다. 그게 다이다. Run 대신에 Debug를 누를 뿐이다.
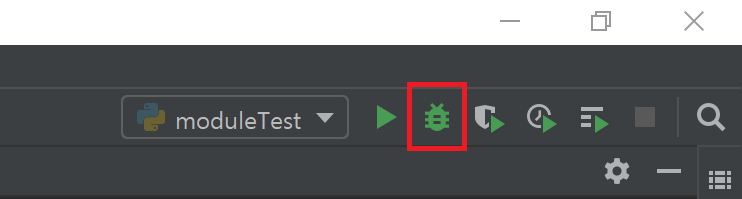
그러나 시작하기 전 Breakpoint를 하나 설정한다. 버그가 있다고 생각하는 시점 직전에 설정하면 된다. 우선 이번 예시에서는 example을 선언한 라인에 설정하겠다. 코드 왼쪽, 라인 번호 바로 오른쪽 빈 공간을 클릭하자.
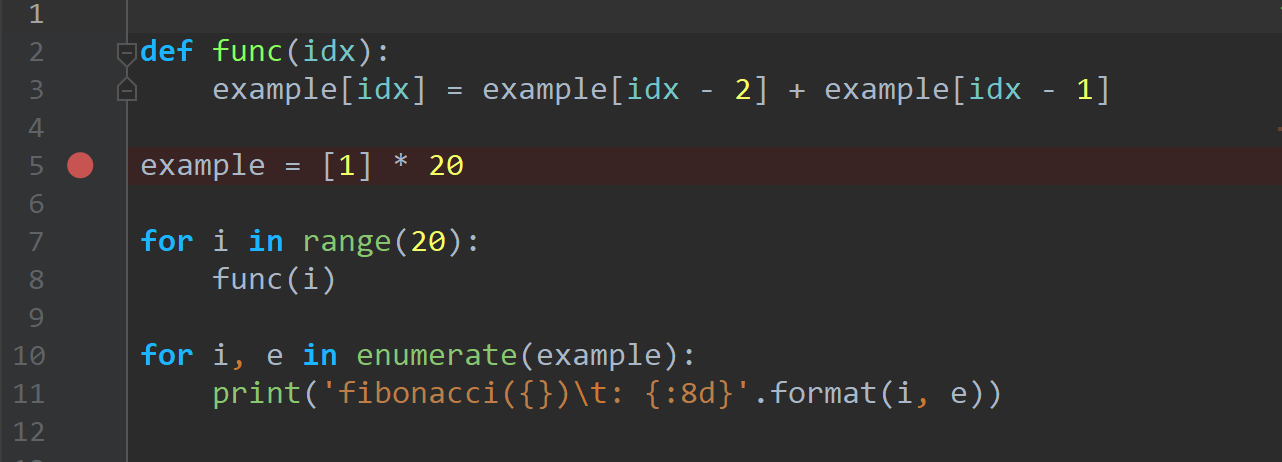
그러면 빨간 점과 함께 해당 라인의 배경이 빨간색으로 칠해진다.
그리고 Run > Debug를 클릭한다. 벌레를 클릭해도 좋다.
뭔가 다른 프로그램이 실행되고 있는 것 같으면, 실행하려는 파일명을 다시 확인하라.
디버깅할 때는 코드를 그냥 실행할 때와는 동작이 많이 다르다.
- 실행 시에는 코드가 처음부터 끝까지 멈춤 없이 진행된다.
- 물론 사용자의 입력을 기다리거나, 계산이 오래 걸리거나,
sleep()등으로 지연시키는 경우는 예외이다. 그러나 이 경우에도 입력/계산/시간이 완료되면 자동으로 다음 코드를 지체 없이 빠르게 실행한다.
- 물론 사용자의 입력을 기다리거나, 계산이 오래 걸리거나,
- 디버깅 시, 처음에는 Breakpoints 까지는 실행 시와 똑같이 순식간에 진행된다. 그러나 Breakpoints에 도달하면 그 라인의 실행 직전까지만 코드가 실행된 후 대기 상태로 전환한다(이름이 왜 breakpoint이겠는가?).
- 그리고 이후 진행은 사용자가 무엇을 클릭했느냐에 따라 달라진다. 디버깅 모드에서는
- 한 줄 실행(딱 한줄만 실행),
- 지정 위치까지 실행(해당 지점을 Breakpoints 삼아 그 라인 직전까지 실행),
- 어떤 함수 내부로 들어가 한 줄씩 실행,
- 현재 실행 중인 함수 밖으로 나오는 데까지 실행
- 등등의 옵션이 있는데, 각각의 옵션에 따라 딱 필요한 만큼까지만 코드가 실행된 후 대기 상태로 멈춰 있는다.
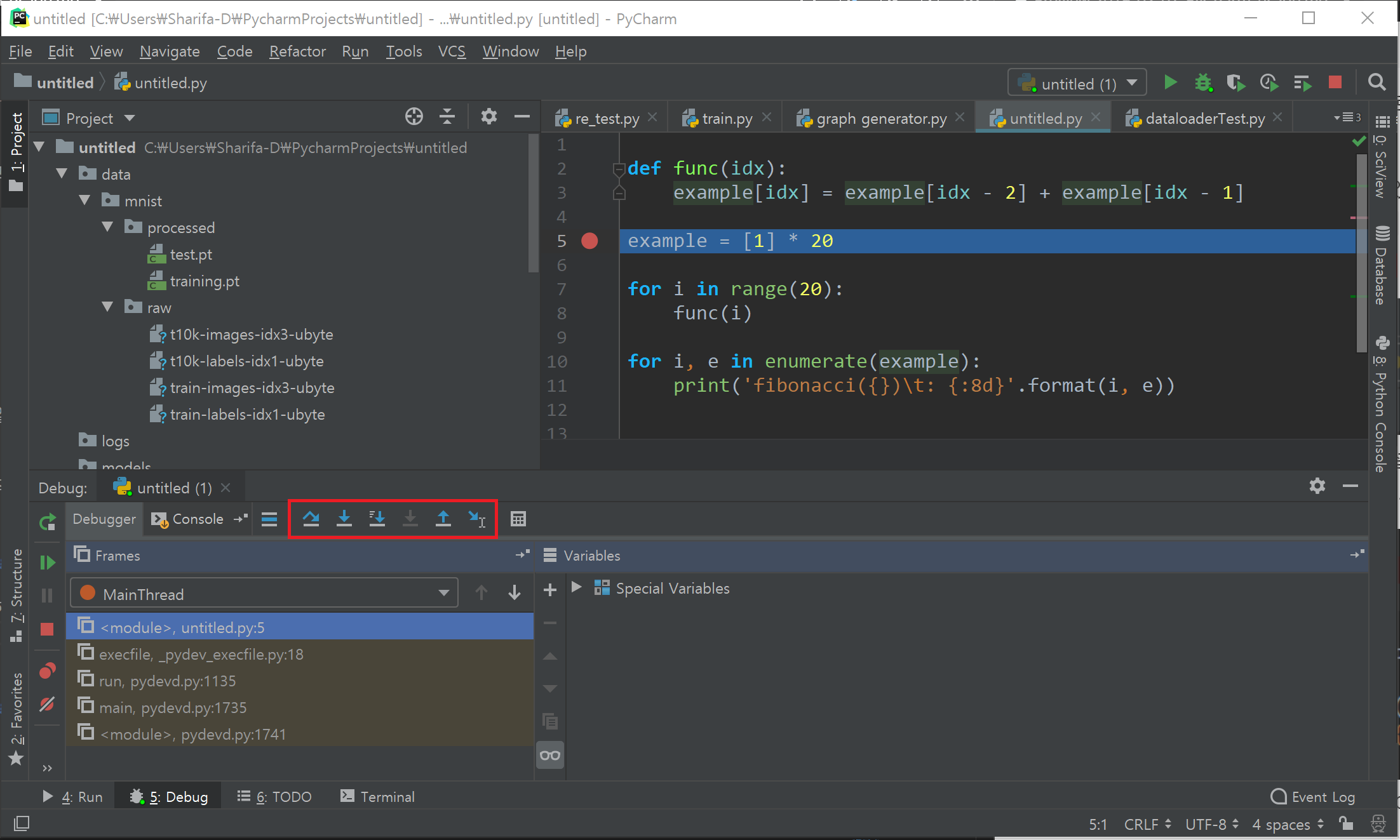
우선 F8을 눌러보자. Step Over이라고 되어 있다. 위 그림에서 빨간 박스 안의 첫 번째 아이콘을 클릭해도 된다.
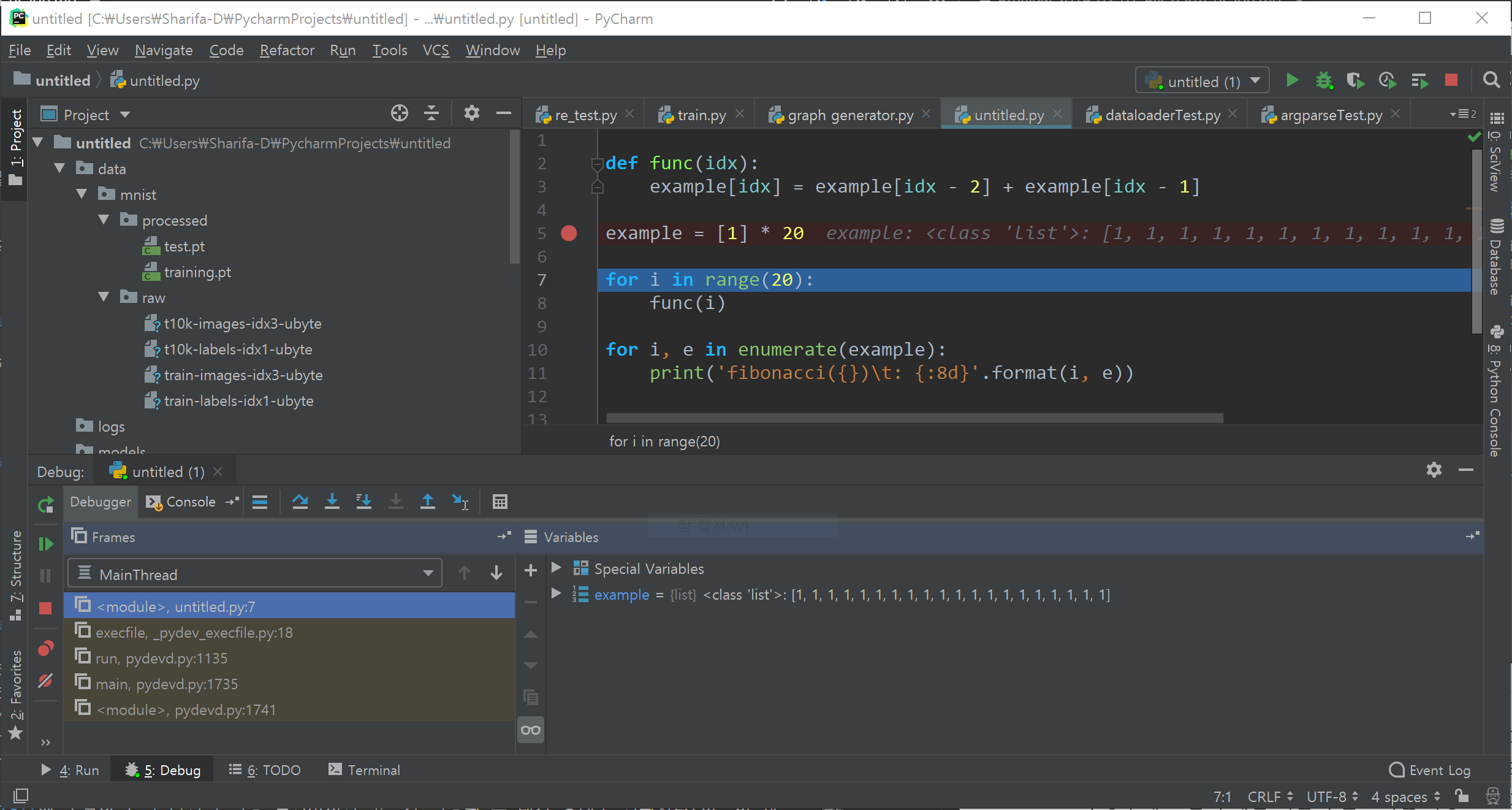
- 그럼 한 줄을 실행하고 다음 statement로 넘어가 있다. 빈 줄은 건너뛴다.
- 실행한 줄 옆에 그 줄의 변수에 들어 있는 값이 업데이트된다.
example변수는list타입이며, 값 1을 20개 갖고 있는 리스트이다. - 왼쪽 아래 untitled.py: 7로 값이 바뀌었다. 현재
untitled.py의 7번째 줄을 실행하기 직전이란 뜻이다. - 아래쪽
Variables창에서 접근할 수 있는 변수 목록이 업데이트되었다. 현재는example하나뿐이므로 그 값을 볼 수 있다.
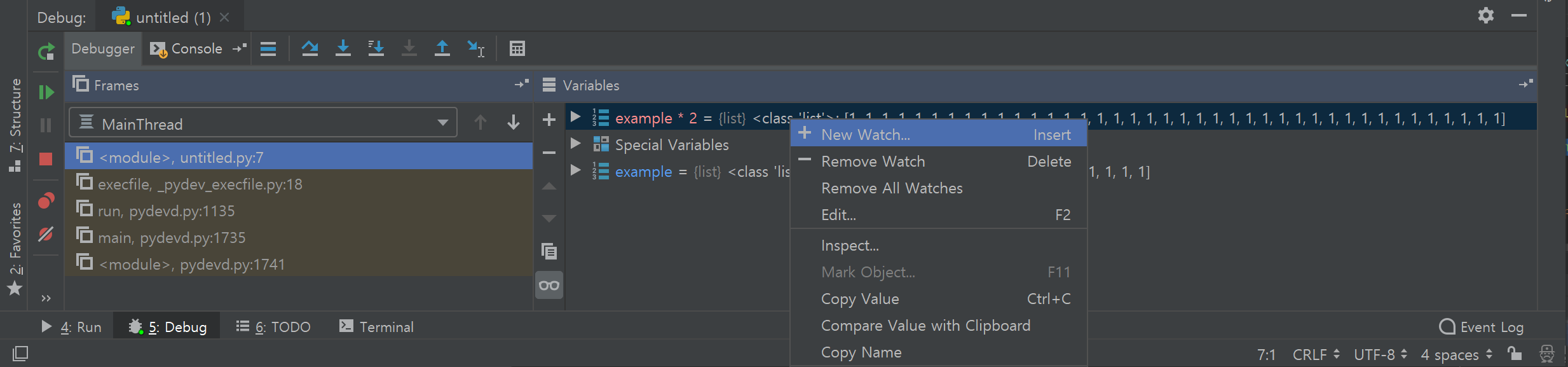
Variables 창에서는 현재 scope에서 접근가능한 변수 목록이 자동으로 업데이트되지만, 미리 보고 싶거나 혹은 계산 결과 등을 보고 싶다면 새로운 Watch를 추가할 수 있다. Variables 창 아무 곳이나 우클릭하면 새로 보고 싶은 변수 혹은 수식 결과값 등을 추가할 수 있다. 예시로 example * 2를 추가해 보았다.
Step Over 외에 다른 버튼들은 다음과 같다.
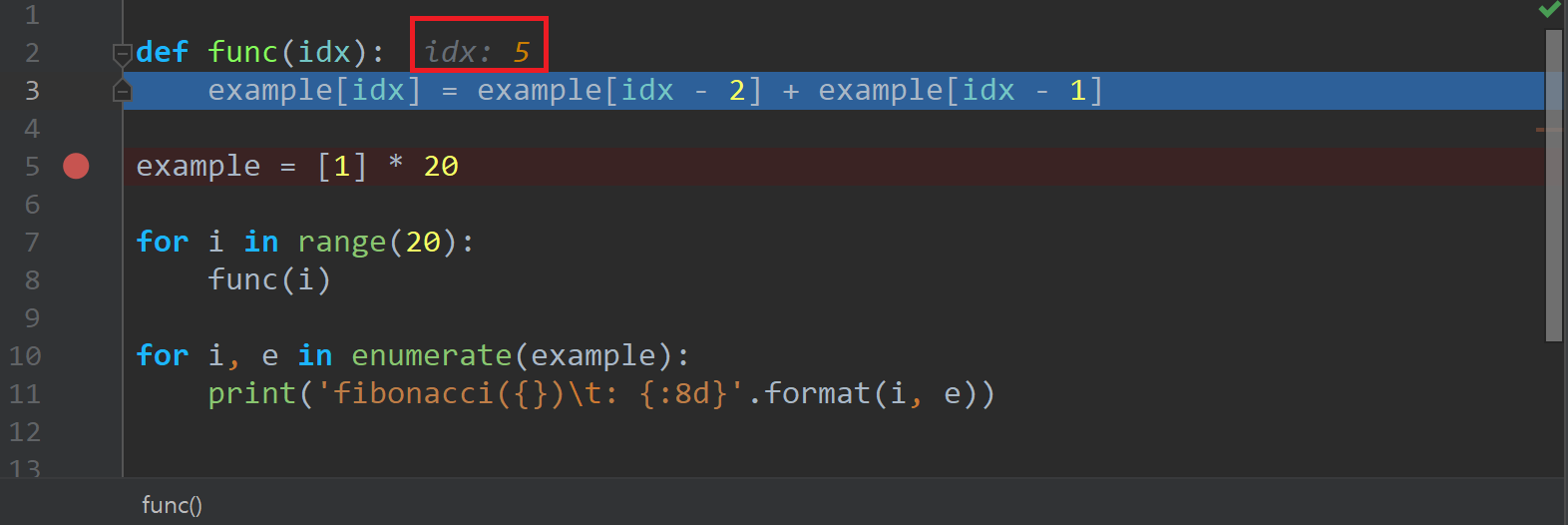
Step Into(F7): 코드가 어떤 함수를 실행하는 경우(예: 예시의func, 내장 함수인print등), 해당 함수의 내부로 들어가서 실행할 수 있게 해 준다.- 아래 예시는
func()내부로 들어간 모습을 보여준다. - 참고로 argument로 무엇이 전달되었는지 등도 표시된다(아래 그림의 경우
idx: 5라고 되어 있는 것을 볼 수 있다). argument뿐 아니라 업데이트되고 있는 변수들 모두 값을 보여주며, 방금 업데이트된(조금 전 실행한 라인의 결과) 값은 회색이 아닌 주황색으로 표시된다.
- 아래 예시는
Step Into My Code: 위의Step Into는print같은 내장 함수들 안으로까지 파고들어 코드를 실행한다. 내장 함수가 오작동하는 것은 아니기 때문에 자신의 코드만 검사하고 싶다면 이쪽을 택하자.Force Step Into: 말 그대로 강제로 함수 안으로 들어가 실행시킨다. 비활성화된 경우가 많을 것이다.Step Out(Shift + F8): 실행되고 있는 함수 밖으로 나오는 데까지 실행시킨다.func또는print끝난 다음 줄로 이동한다.Run to Cursor(Alt + F9): 커서가 있는 곳으로까지 코드를 실행시킨다. 반복문 내부인 경우 가장 가까운 반복 단계에서 멈춘다.
위의 모든 명령은 Breakpoint에서 걸린다. 즉, Run to Cursor 등으로 많이 이동하려 해도 그 사이에 Breakpoint가 있으면 그 직전까지만 실행된 상태로 멈춘다.
이런 기능들을 활용하면서 디버깅하면 어느 단계에서 코드가 잘못 되었는지 확인할 수 있다.
Breakpoint에는 한 가지 중요한 기능이 있다. 지금까지 설정한 것은 코드가 설정된 라인에 가면 무조건 멈추는데, 이 조건을 바꿀 수 있다. 8번째 줄에 Breakpoint를 설정하고, Breakpoint를 나타내는 빨간 원을 우클릭하자.
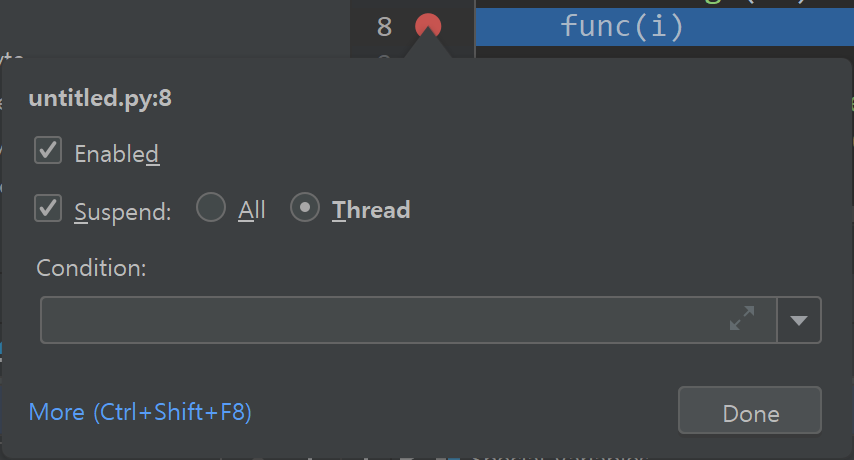
조건을 설정할 수 있는 창이 나온다.
아래의 More...를 클릭하면,
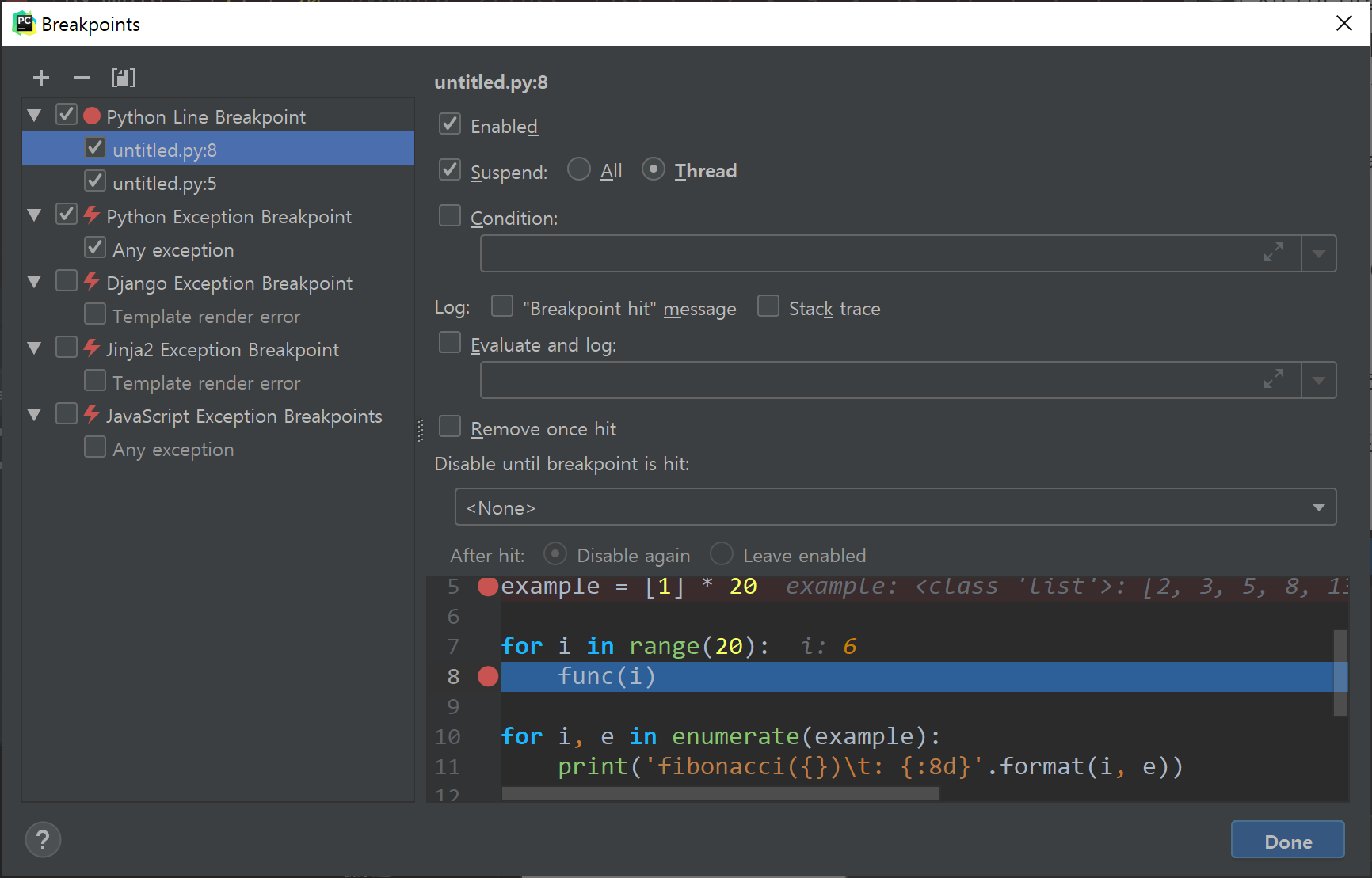
더 자세한 조건을 설정할 수 있다.
예시를 한 개만 들어보겠다. 8번째 줄의 Breakpoint를 아래처럼 설정한다. i == 5 일 때만 Breakpoint가 작동할 것이다.
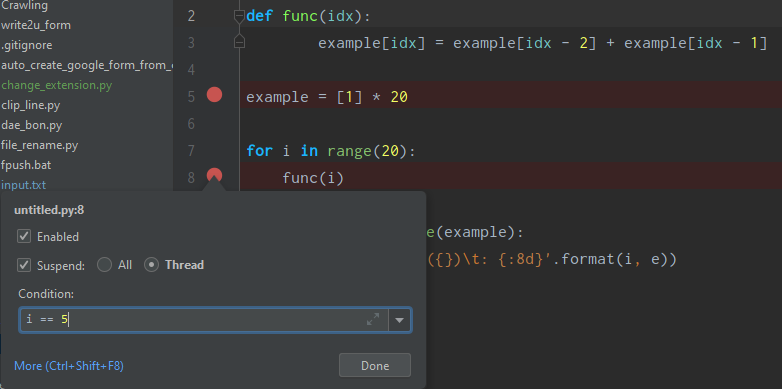
조건을 설정하면 빨간 원 옆에 ?가 생기면서 condition이 설정되었음을 나타낸다.
디버깅 모드를 종료했다가 다시 시작한 다음, 프로그램 끝에 커서를 놓고 Run to Cursor를 실행해 보자.
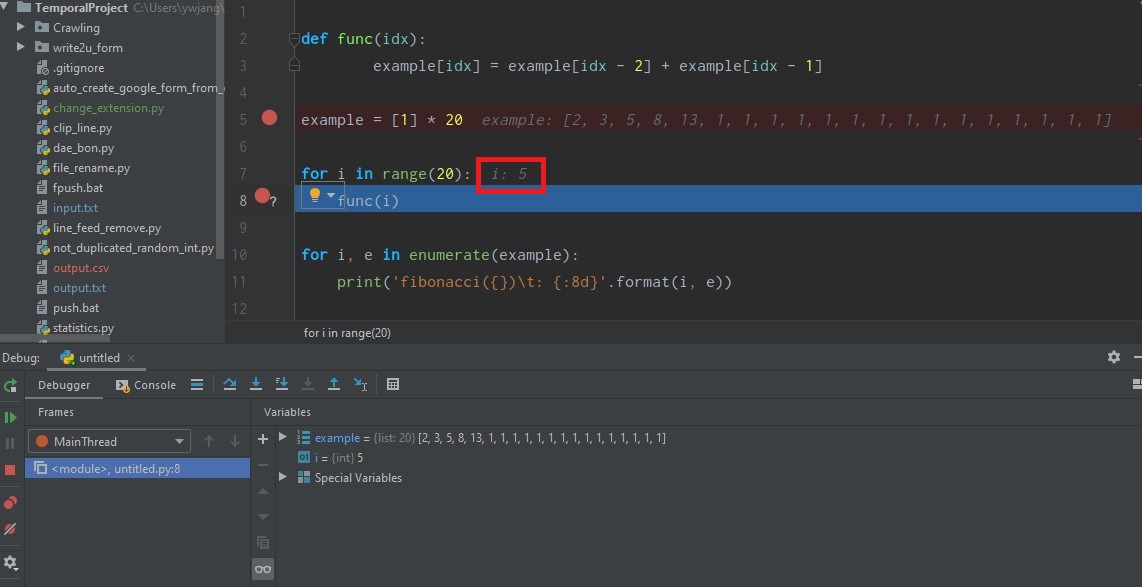
그러면 i == 5일 때 func 함수 내부에 멈춰 있음을 볼 수 있다. 한 번 더 Run to Cursor로 이동하면 그때서야 끝부분으로 이동한다. 즉 i == 5인 조건을 지났기 때문에 다시 발동하지 않는 것이다.
이 기능은 반복문이 여러 차례 반복된 뒤에야(예: 1000번쯤, Step Over를 1000번씩 누르긴 싫을 것이다) 버그가 나타나는 경우 해당 지점 직전에까지 가도록 Breakpoint를 설정하는 방법으로 쉽게 탐색할 수 있다.
잘 쓰면 꽤 유용하니 이것도 익혀 두도록 하자.
Profilers(코드 실행시간 측정)
코드 실행시간을 측정할 때 매번 코드 시작과 끝 지점에 start_time와 end_time 같은 코드를 삽입하지 않고도 특정 함수나 코드 일부분 등의 실행 시간을 측정하는 기능을 PyCharm에서 제공한다. 이는 Terminal이나 IPython 등으로 실행한 것이 아닌 PyCharm의 Run 과 같은 방식으로 파일을 실행시켰을 때(Configurations에서 설정 가능) 설정 가능하며, Professional 버전에서만 이용 가능하다.
정확히는, Configurations에서 실행할 파일을 지정한 다음, Run 버튼이 아닌 Profile 버튼을 클릭한다.
temp.py 파일을 다음과 같이 작성했다고 하자.
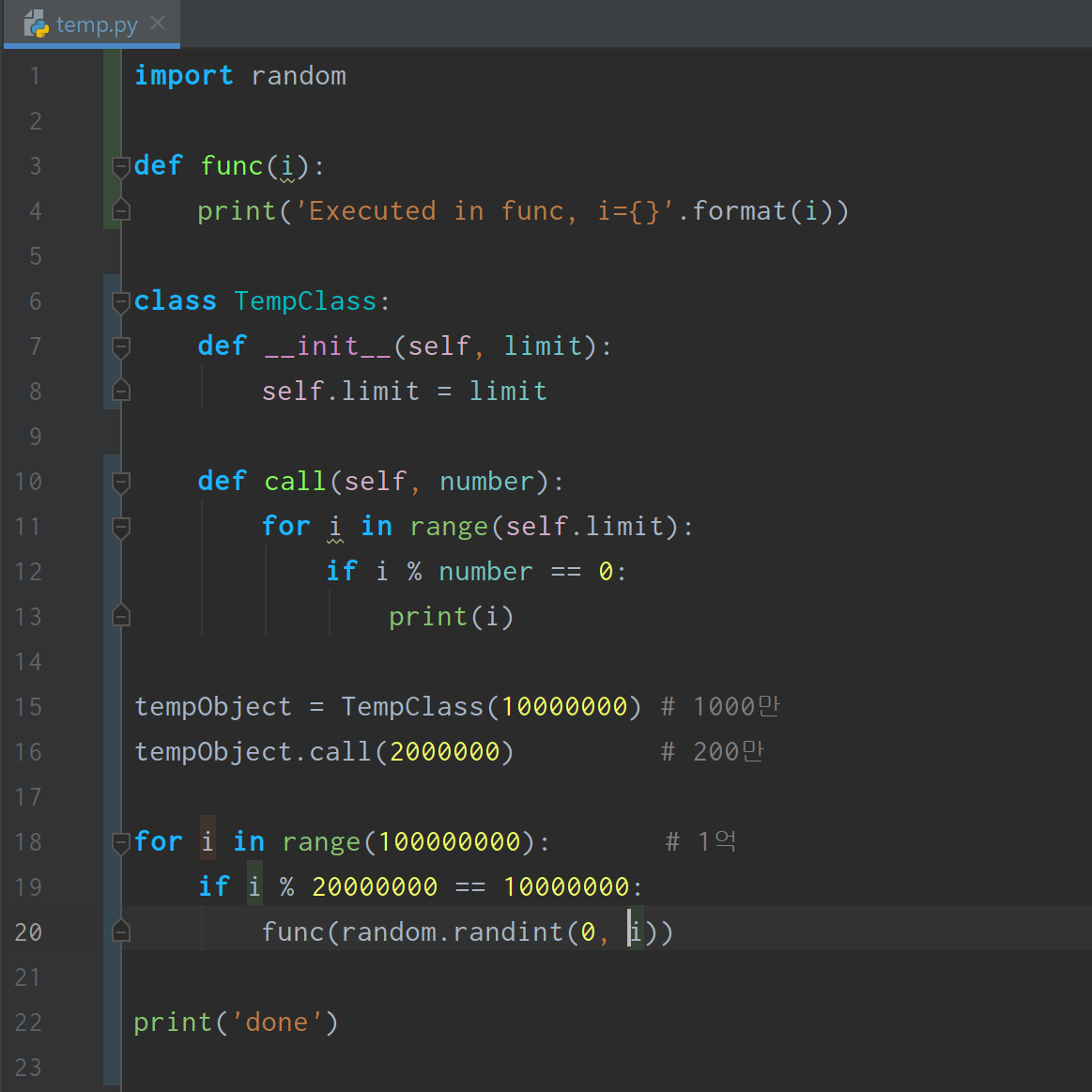
이제 이 코드에서 어느 부분이 실행시간의 많은 부분을 차지하는지 알아보자. PyCharm의 우상단에 있는 Profile 버튼을 클릭한다.

그러면 실행창에는 다음과 같이 Starting cProfile profiler라는 문구가 출력되면서 실행이 된다. done 출력 이후에 한 줄이 더 출력되어 있는데, Snapshot(pstat 파일)이 지정된 경로에 저장되었다는 뜻이다.
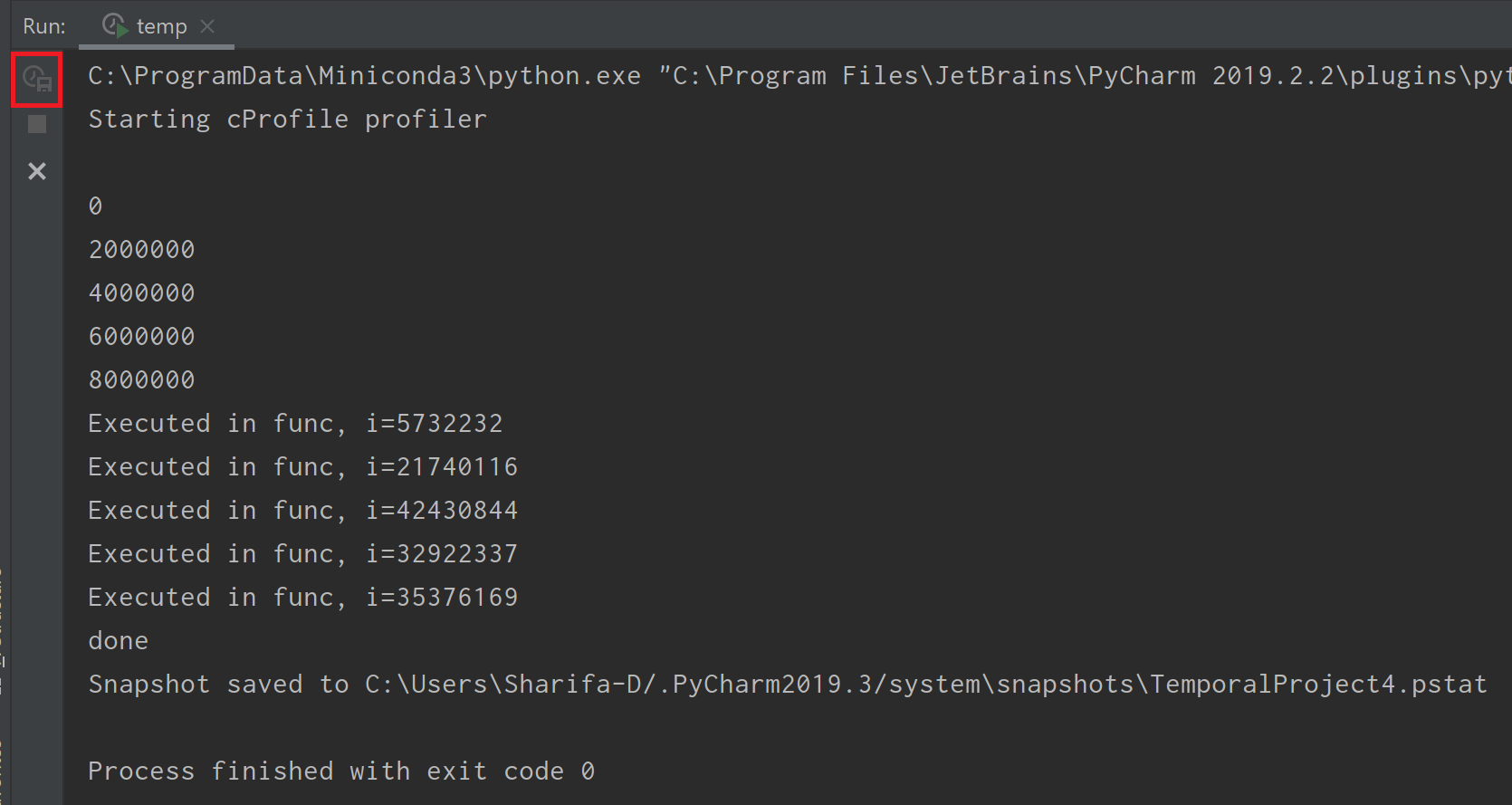
그리고 실행이 끝나면 확장자가 pstat인 파일이 열린다. 실행이 너무 오래 걸린다면, 위 그림의 빨간 박스(Capture Snapshot, 실행이 끝난 상태에서는 비활성화됨)를 클릭하면 snapshot이 바로 저장되면서 중간 결과를 볼 수 있다.
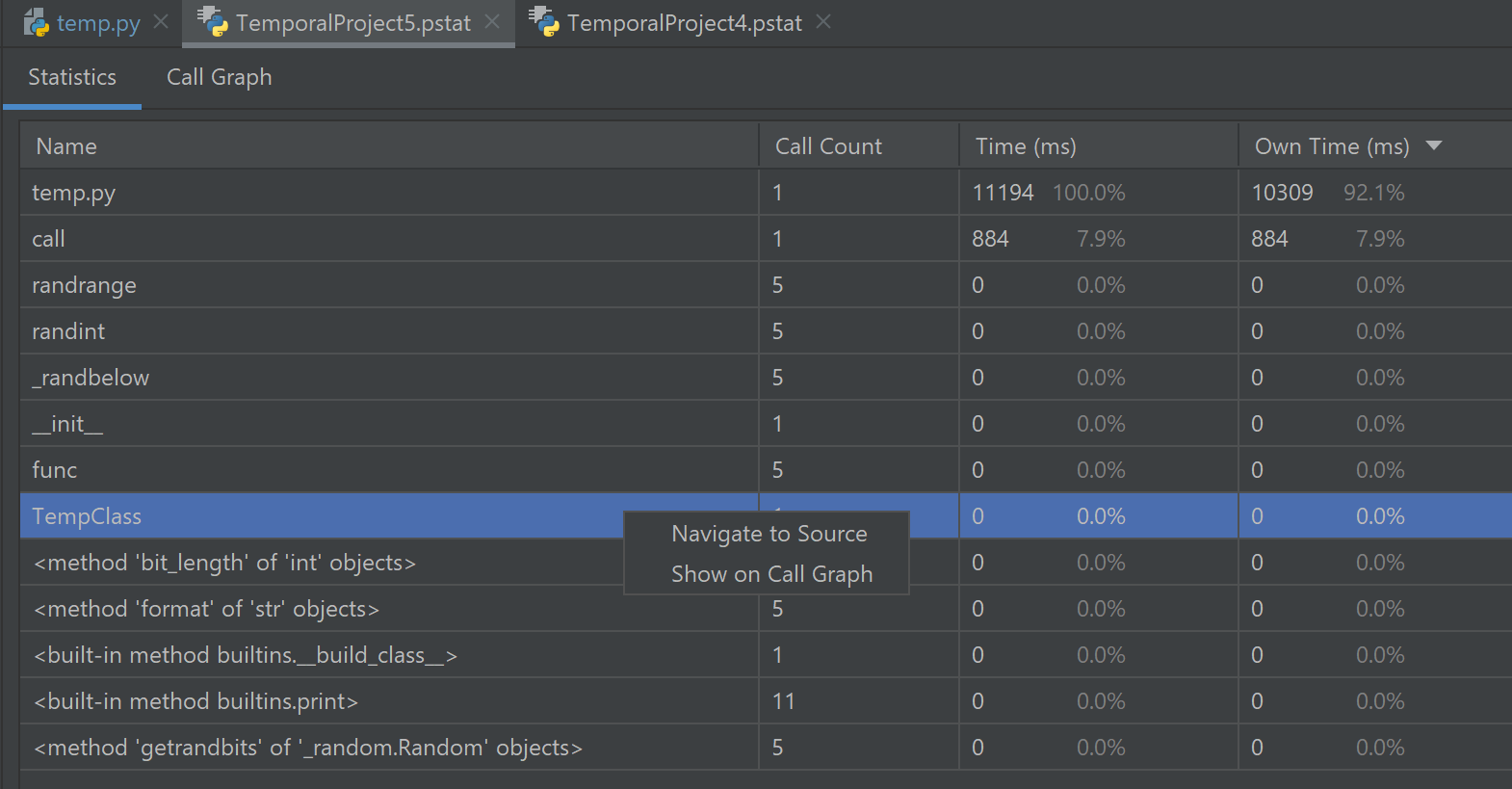
pstat 파일에는 2개의 탭이 있다. Statistics 탭에는 각 함수별로
- 실행 수
- 해당 함수에 포함된 모든 함수의 실행 시간을 모두 더한 값
- 해당 함수 자체만의 실행 시간의 총합(해당 함수가 여러 번 실행되었을 수 있으므로) 이 나열되어 있다.
정확히는 사용자 정의 함수와 같은 일반 함수 외에도 Python 내장 함수(print 등) 및 기본(__init__ 등) 함수, class, 실행 파일 등이 포함된다.
원하는 함수명을 오른쪽 클릭하면 해당 함수가 위치한 곳으로 이동하거나, 아래의 Call Graph에서 찾아볼 수도 있다.
Call Graph 탭에서는 어떤 파일/함수에서 어떤 함수가 실행(call)되었고, 각 함수의 실행 시간을 전부 볼 수 있다.
이 기능은 복잡한 코드가 어떤 과정으로 실행되는지를 대략 알아보는 데도 쓸 수도 있다(순서는 Traceback을 보는 것이 낫다).
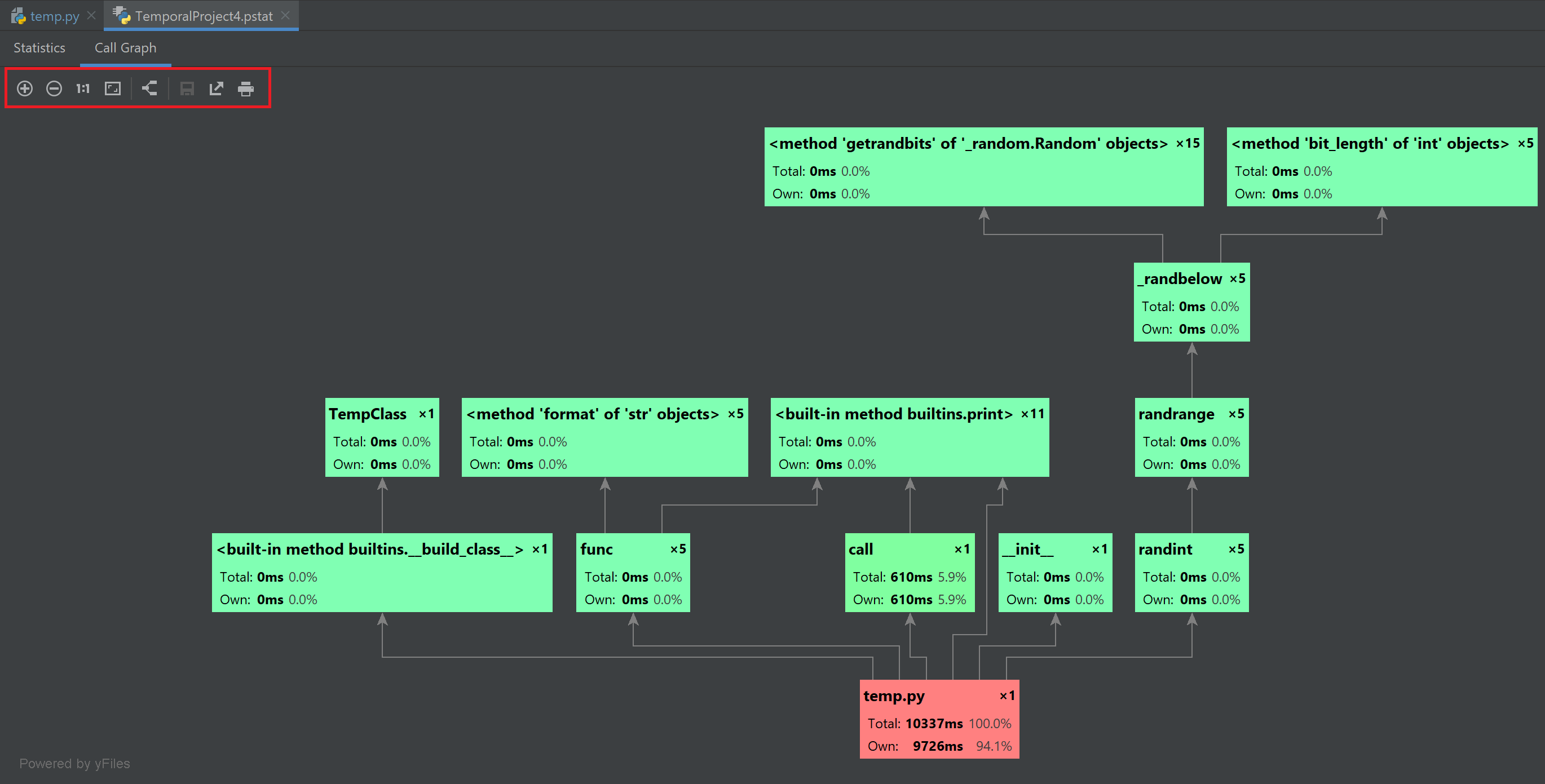
왼쪽 위에 있는 +, - 등의 메뉴에서는 그림 확대/축소, 화면 맞추기, 이미지로 저장 등을 수행할 수 있다.
Configurations(실행 시 parameter 설정)
실행(Run)이나, 디버깅(Debugging) 버튼을 통해서 실행하고자 할 때, 엉뚱한 파일이 실행되는 경우가 있다. 이는 실행 버튼 바로 옆의 실행 파일명 또는 configuration 이름을 살펴보고 원하는 부분이 아니라면 바꿔주도록 하자.
참고로, Run/Debug configuration 설정 창에서는 실행 파일뿐 아니라 인자(argparse 등에서 사용하는 argument)를 설정해 줄 수도 있다. Python에서는 기본적으로 실행 시 인자를 주기 위해서는 명령창에서 python <실행할 파일.py> --option1 <option1> 형식으로 실행시켜야 하는데, PyCharm에서는 이 설정을 저장해두고 바로바로 쓸 수 있다. 위의 그림에서 Edit Configurations를 눌러보자.
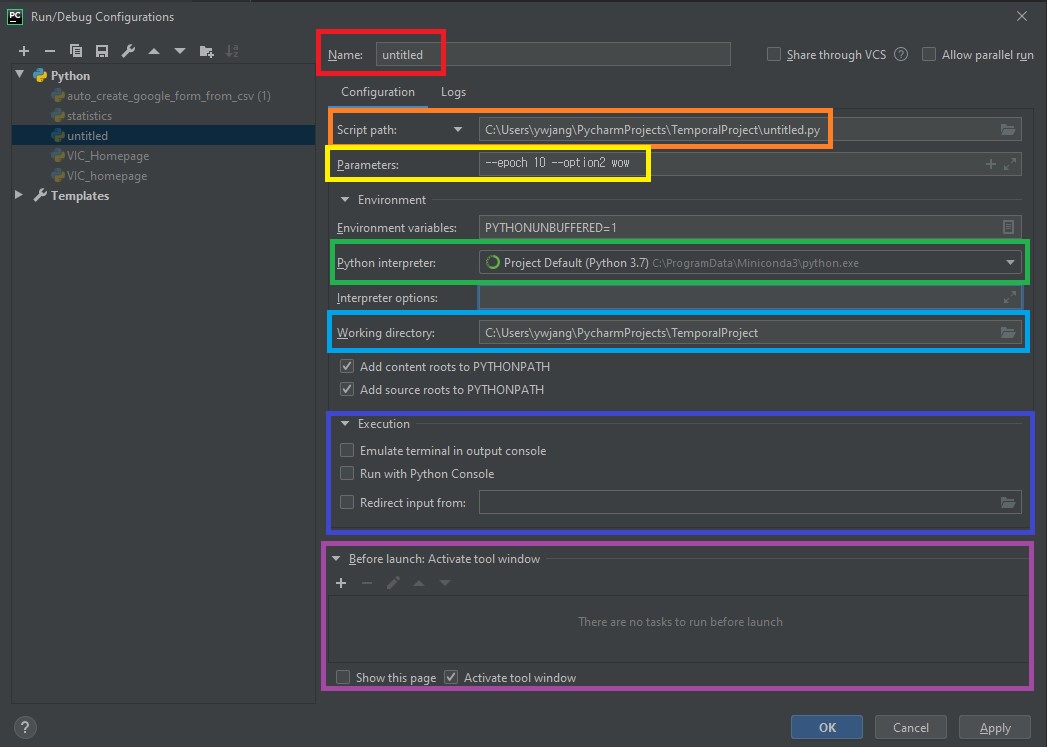
순서대로 설명하면,
- (빨간색) configuration의 이름을 설정할 수 있다. 기본적으로 실행하고자 하는 파일명으로 설정되며, 파일명으로 뿐만 아니라 원하는 이름으로 변경할 수 있다.
- (주황색) 실행하고자 하는 python 파일을 설정할 수 있다. 여기서 직접 추가하거나, 상단 메뉴 바의
Run에서 새로 파일을 설정하면 추가된다. - (노란색) 딥러닝 등에서 보통 많이 쓰는
argparse에서 인자를 받곤 하는데 이를 여기서 추가할 수 있다. 물론 argparse 뿐만 아니라sys.argv[]가 받는 것도 동일하다. 사실 이게 제일 중요한 듯 - (초록색) 원하는 실행 환경을 바꿔줄 수 있다.
- (파란색) 실행 폴더의 위치를 지정한다. 기본적으로 실행 파일과 같은 위치로 지정되며, Python 코드 내의 상대 경로는 이 경로의 영향을 받는다.
- (남색) 콘솔에서 실행시킬지 등을 결정할 수 있다. 기본적으로는 해제되어 있다.
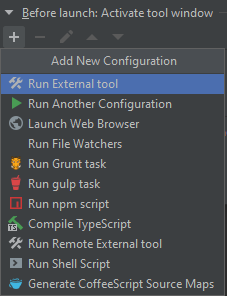
- (보라색) 실행시키기 전에 tool window 등을 미리 활성화 할 수 있다. 가능한 메뉴는 다음과 같다.
SSH를 통한 외부 서버 원격 접속
보통 ssh를 통해서 외부 서버에 진입할 때는 명령창에서 vim이나, 혹은 기타 조잡한(?) 편집기를 통해서 코드 수정을 하게 된다. 그러나, PyCharm Pro 버전은 SSH로 접속할 수 있는 외부 서버를 연결하여 코드를 편집하면서, 서버에 변경사항을 실시간으로 업데이트할 수 있다.
이 강력한 기능은 아쉽게도 community 버전에서는 지원하지 않는다.
먼저 새 프로젝트 또는 로컬에 존재하는 기존 프로젝트를 연다.
Settings > Project: name > Project Interpreter 로 이동한 뒤, 오른쪽 위의 톱니바퀴를 누르면 Add 또는 Show All이 뜬다. Add를 누르자. Show All을 누른 다음 + 버튼을 눌러도 좋다.
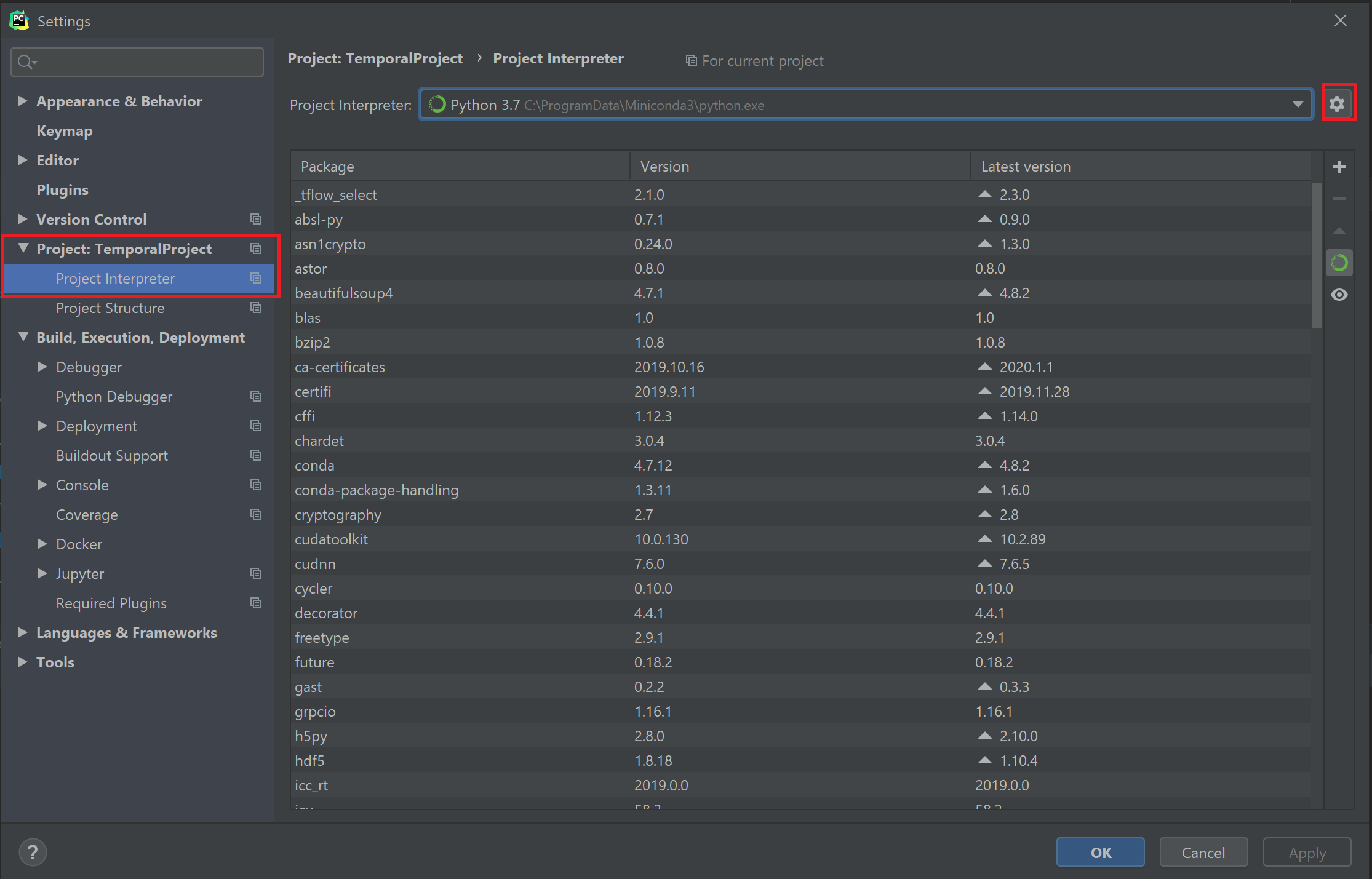
새 Interpreter를 만드는 과정에서, Virtualenv나 conda 등이 아닌 SSH Interpreter를 선택해준다. 그리고 서버 설정을 똑같이 입력해준다.
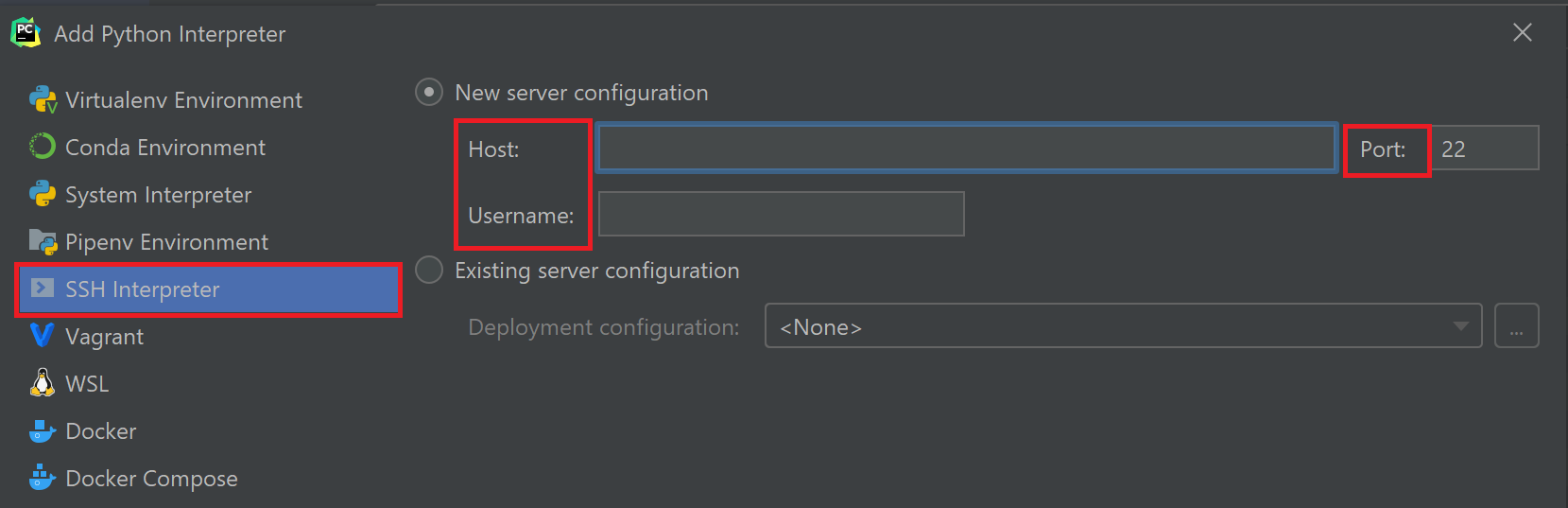
다음 화면에서 비밀번호도 잘 입력해준다.
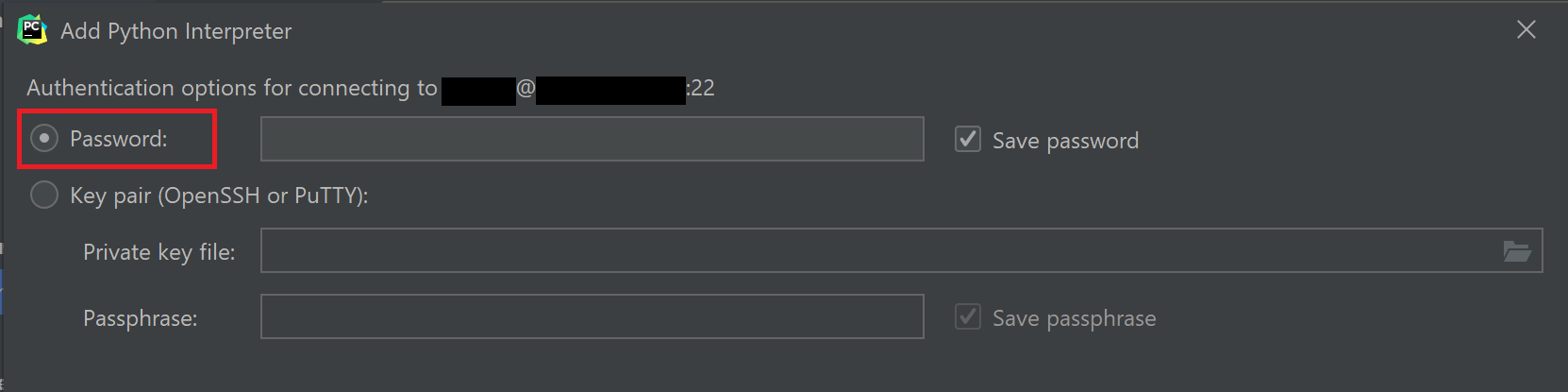
그러면 이제 서버에 저장되어 있을 Interpreter를 설정하는 단계이다. 여러분이 그냥 Python 하나만 깔아놓고 쓰거나, Conda를 쓰거나, Virtualenv를 쓰거나 하는 경우마다 Python Interpreter의 위치는 전부 다르다.
아무튼 어딘가에 있을 python.exe를 잘 찾아서 경로를 지정해 주어야 한다. Ubuntu 환경에서 Miniconda를 쓰는 필자는 대략 다음과 같은 interpreter 경로를 갖는다.
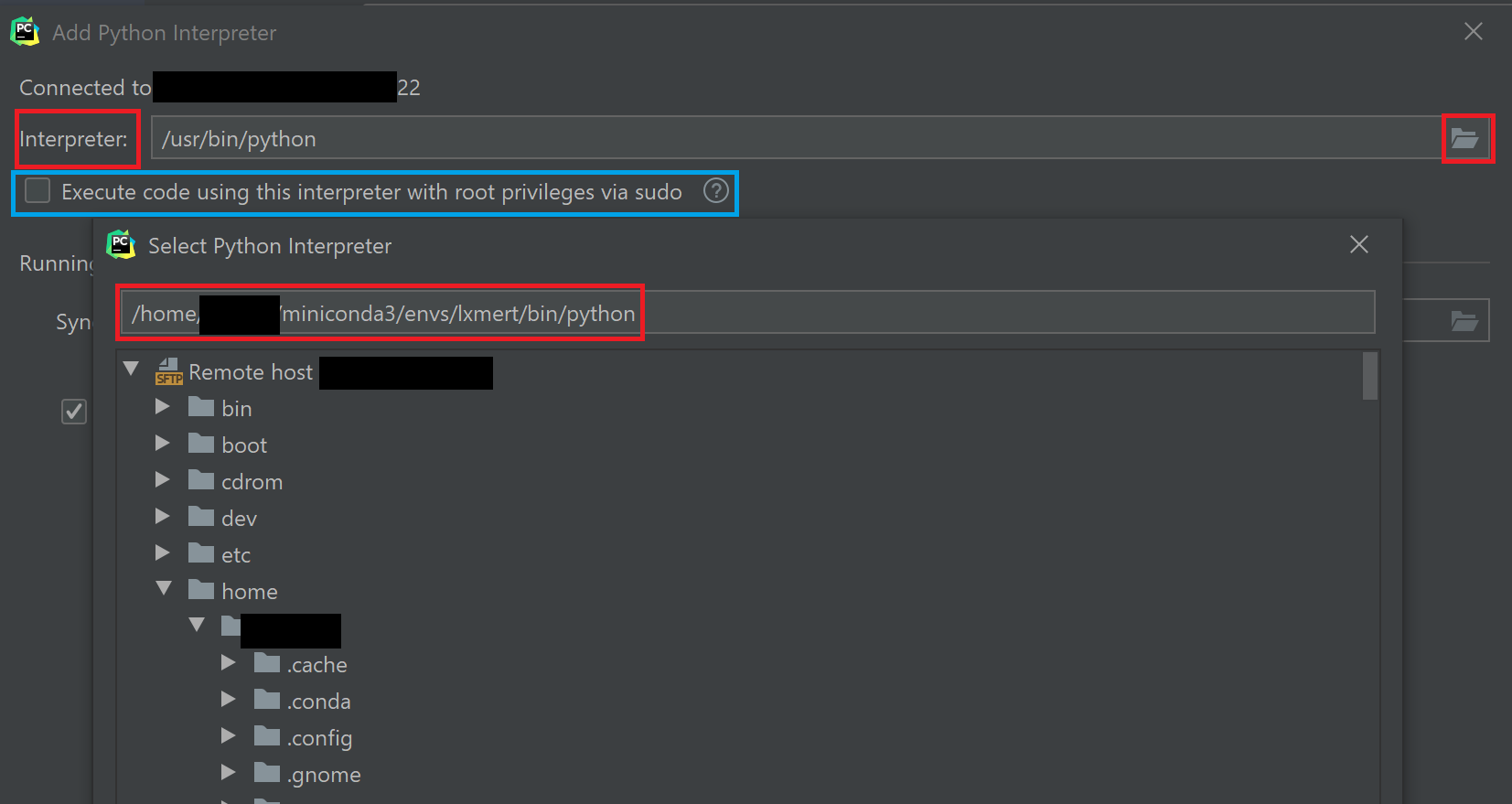
Interpreter 경로 지정은 오른쪽의 디렉토리 아이콘을 누르면 서버에 존재하는 파일과 디렉토리를 볼 수 있다.
그리고 관리자 권한으로 실행해야 하는 경우가 있다면, 위 그림에서 파란색으로 표시한 Execute code using this interprete with root privileges via sudo 옵션을 체크한다. (보안 상 문제가 없으면 하는 거 추천)
다음으로는 아래쪽에 있는, 원격 서버의 파일과 로컬 파일을 동기화시키는 항목이 나온다. 이 부분의 의미는,
- PyCharm의 기능은
- 원격 서버를 ssh를 통해 vim 등의 편집기로 수정만 하는 방식이 아니라,
- 로컬에 같은 파일을 복사한 채로 진행되며,
- 로컬 파일을 수정하면 자동으로 원격 서버의 파일도 동기화가 되며(옵션을 체크했을 경우)
- 로컬에서 실행 명령을 내리면 로컬에서 실행되는 것이 아닌 원격 서버에서 실행이 된다.
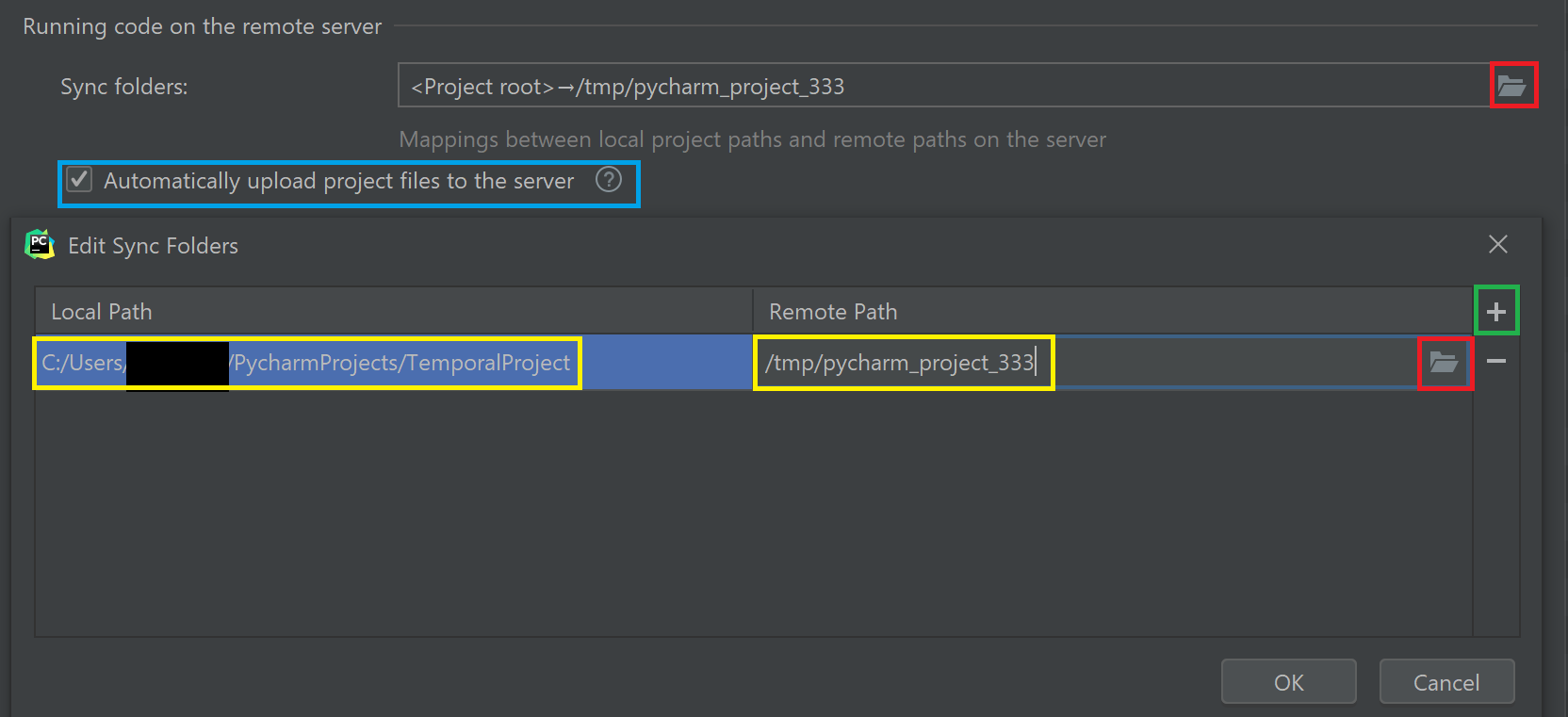
이를 위해서는 Sync folders 옵션의 오른쪽에 있는 디렉토리 아이콘(위쪽 빨간 박스)을 클릭한다. 그리고 Edit Sync Folders 대화창이 뜨면 동기화를 시킬 노란 박스로 표시한 Local Path와 Remote Path를 잘 지정한다(아래쪽 빨간 박스를 누르면 수정 가능). 클라우드 드라이브 서비스처럼 알아서 동기화가 된다.
초록 박스로 표시한 + 버튼을 누르면 동기화할 Path를 추가 지정할 수 있다. 이는 같은 Interpreter를 사용하는 여러 프로젝트가 있을 때 사용하면 된다.
원격 서버에 이미 파일이 존재하는 경우, 위 그림에서 파란 박스로 표시한 부분을 체크 해제한다. 반대로 로컬에서 처음 시작하는 경우, 체크해도 좋다. 만약 서버에 파일이 있는데 로컬 파일을 원격으로 자동 업데이트하는 옵션을 체크하면 원격 서버의 파일이 지워진다는 경고창을 보게 된다.
OK를 누른 뒤 Finish 버튼을 누르면 한번 더 비밀번호를 입력하는 창이 뜬다.
그러면 Interpreter 목록에서 원격 Interpreter를 확인할 수 있다.
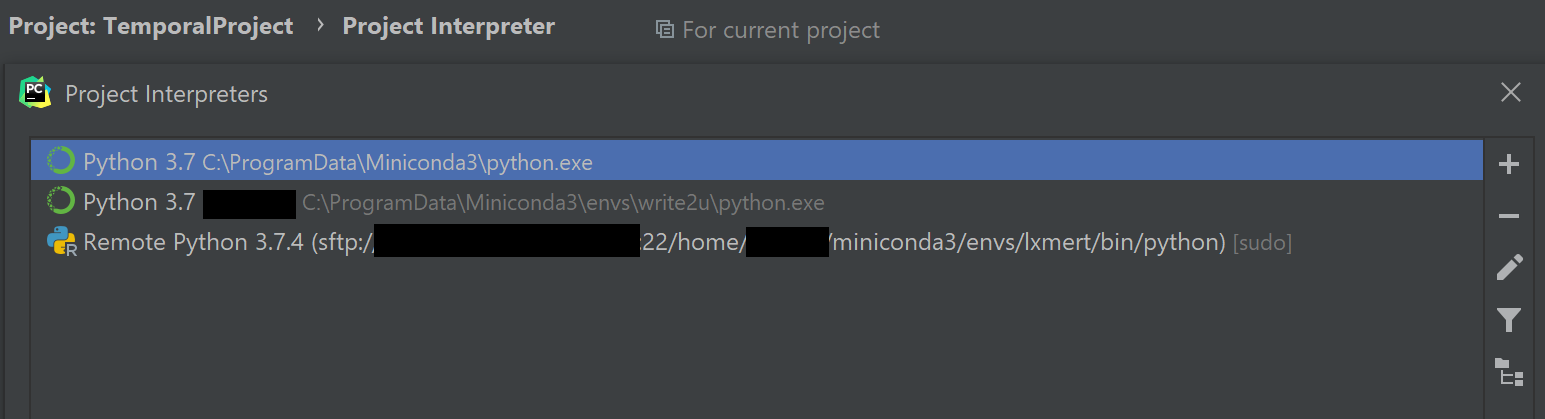
</br>
다음으로 Settings > Build, Execution, Deployment > Deployment으로 이동한다. 그러면 Deployment에 조금 전 추가한 정보가 들어가 있을 것이다. 만약 없으면 아래 그림처럼 새 SFTP 서버를 추가한다.
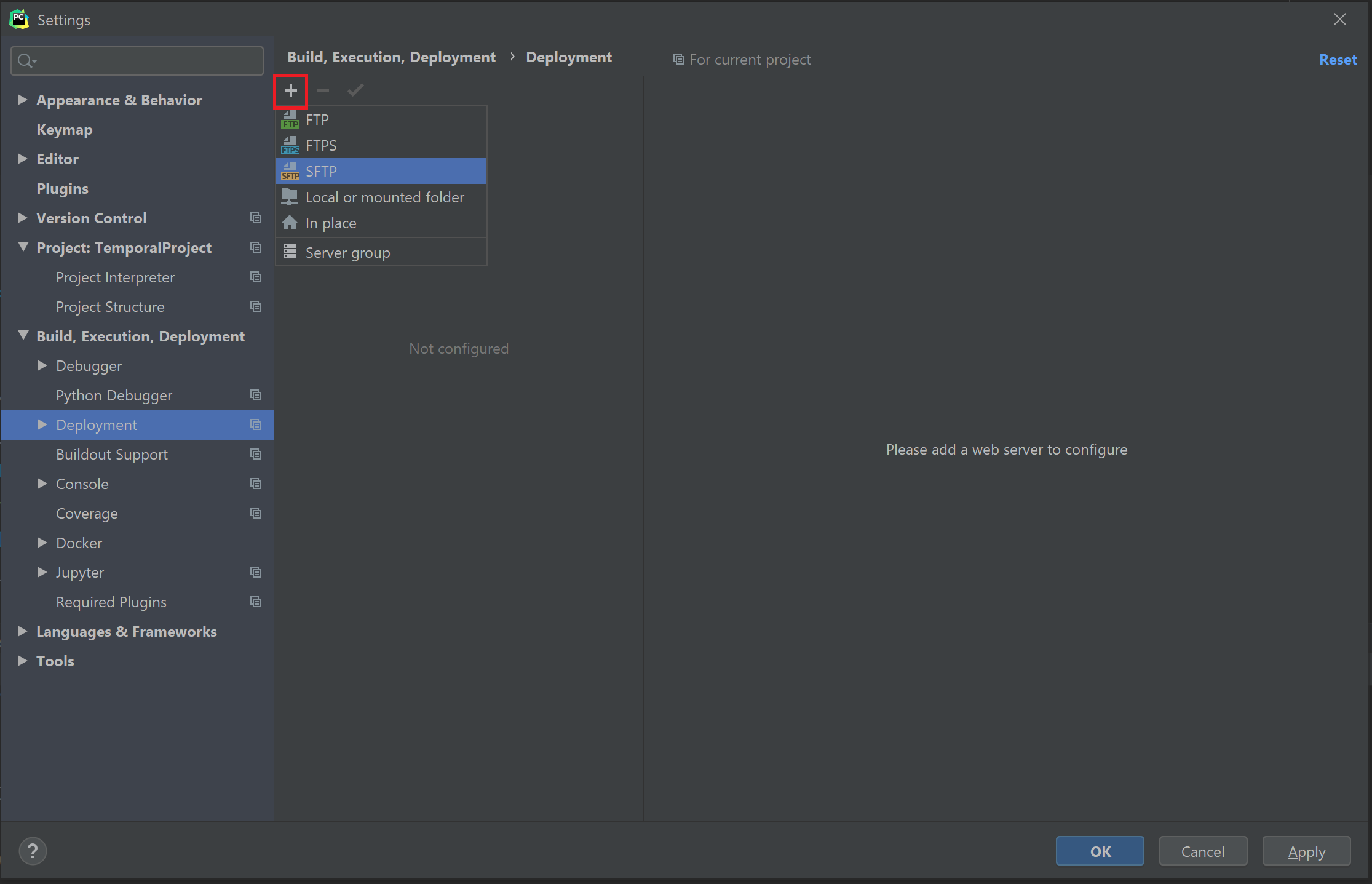
그러면 서버 이름을 입력하는 대화창이 나온다. 입력해주자.
다음 그림을 보자.
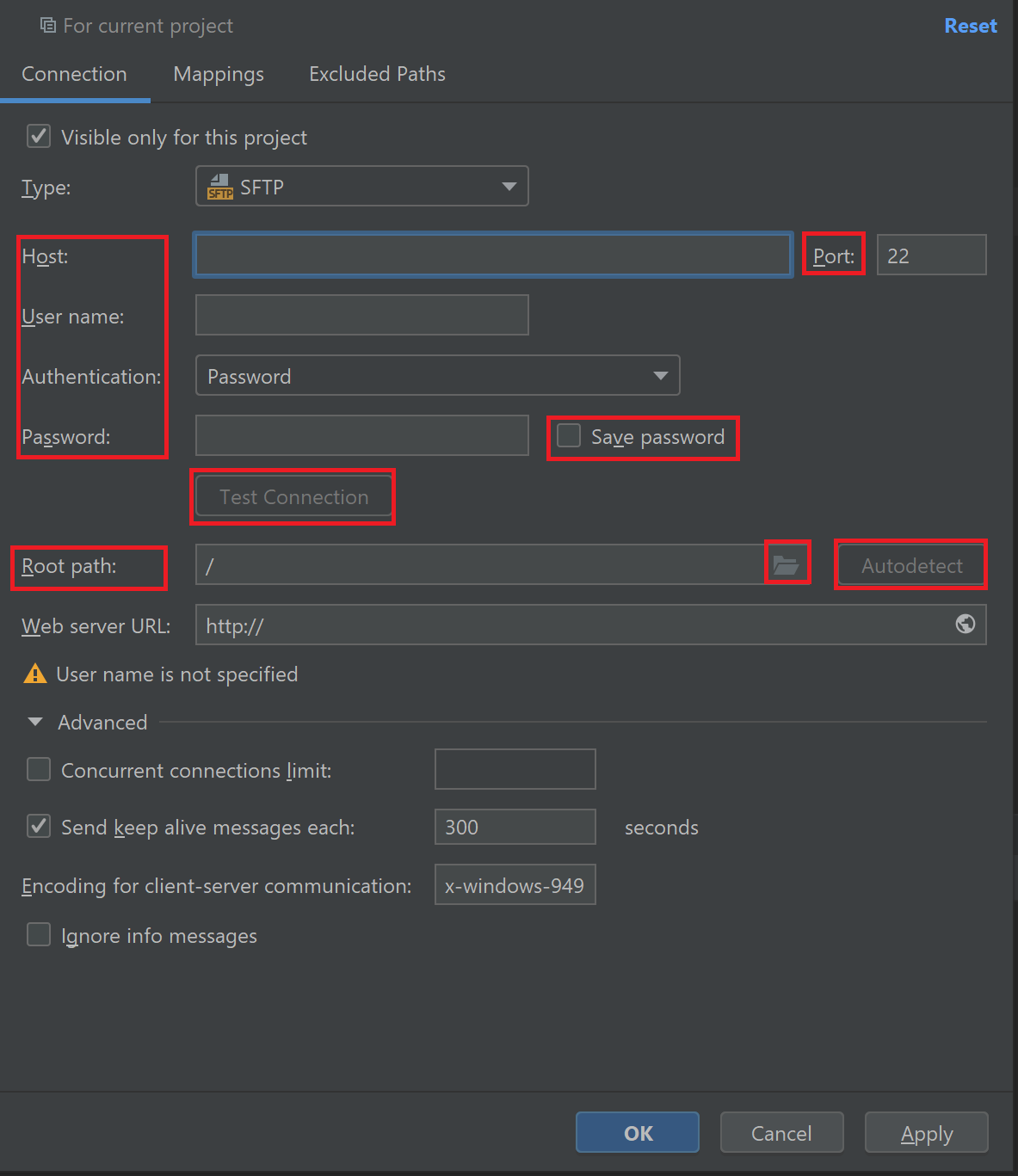
- Host에는 서버의 IP 주소(ex. 123.124.125.126),
- 포트 번호는 원격 서버에서 허용한 번호,
- User name은 서버의 사용자 이름,
- 인증 방식은 보통 비밀번호를 많이 쓸 테니 사용자 이름에 맞는 비밀번호를 입력해준다. 비밀번호는 저장해도 좋다.
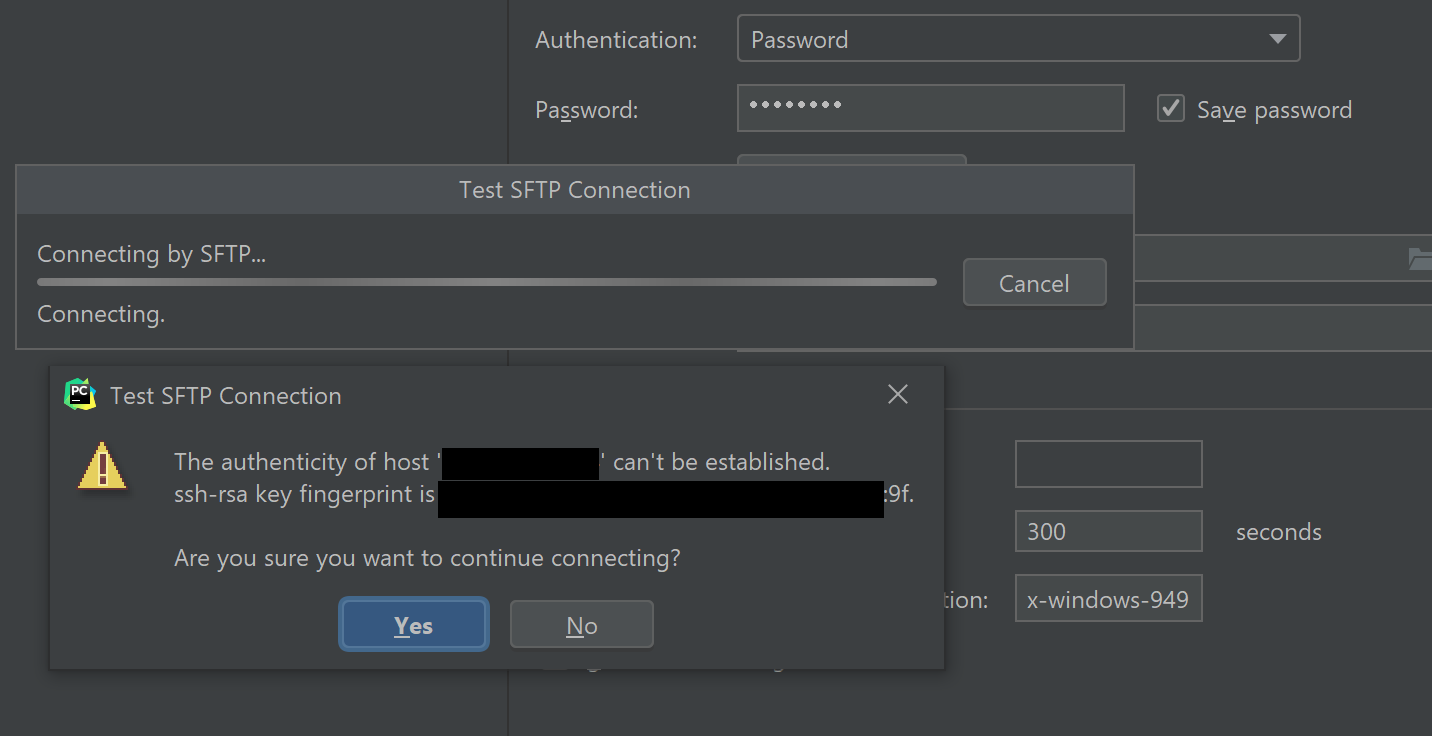
- 그리고 아래쪽 Test Connection을 누르면 연결이 정상적인지 확인한다. 안 된다면 잘못 입력했거나, 외부 접속 또는 포트 등이 차단되어 있을 가능성이 높다. 테스트를 해보면 아래와 같은 창이 뜨는데, Yes를 눌러준다.
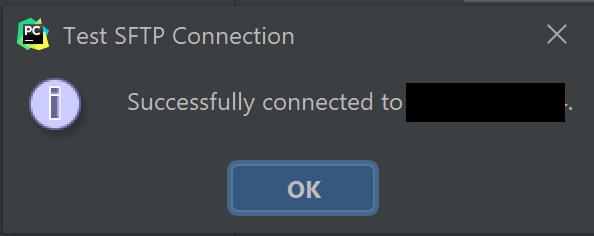
- 정상적이면 연결이 성공했다는 메시지가 뜬다.
- Root Path는 기본값으로 두어도 되고, 인증이 잘 되었다면 AutoDetect를 사용해도 된다. 특정 directory에서 시작하고 싶으면 오른쪽 디렉토리 아이콘을 눌러 직접 지정해준다.
- Web Server URL와 그 아래 고급 옵션은 필수는 아니다.
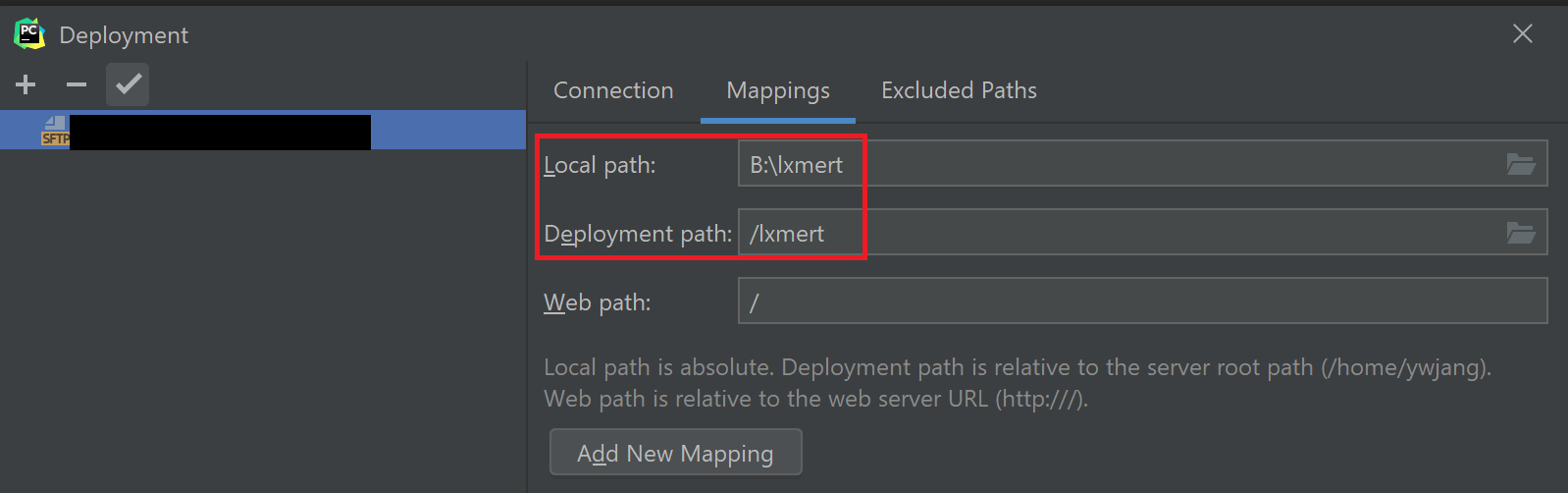
그리고 Mappings 탭을 클릭하면 Local Path와 Deployment Path(Remote Path)를 mapping할 수 있는 탭이 나온다. 역시 디렉토리 아이콘을 눌러 경로를 지정해 준다. 이때 경로는 위에서 기억한 Root path에 더한 상대 경로임을 유의한다. 즉 mapping되는 Remote Path는 Root path + Deployment Path이다.
이제 Project: name > Project Interpreter에서 조금 전에 만든 Interpreter를 선택하고 설정을 마치면 파일 전송이 이루어진다.

코드 수정을 하면 자동 업로드가 된다(옵션을 체크했다면). 또한, 실행을 시키면 원격 서버에서 실행되게 된다.
참고. 원격 서버에서 실행을 하긴 하지만 linux 시스템에서 사용하는 bash 파일을 윈도우에서 실행시킬 수는 없다. 이 부분은 조금 아쉬운 부분이다.
로컬 -> 원격 또는 원격 -> 로컬 간 파일 전송을 수동/자동으로 할 수도 있다. Tools > Deployment를 누른다.
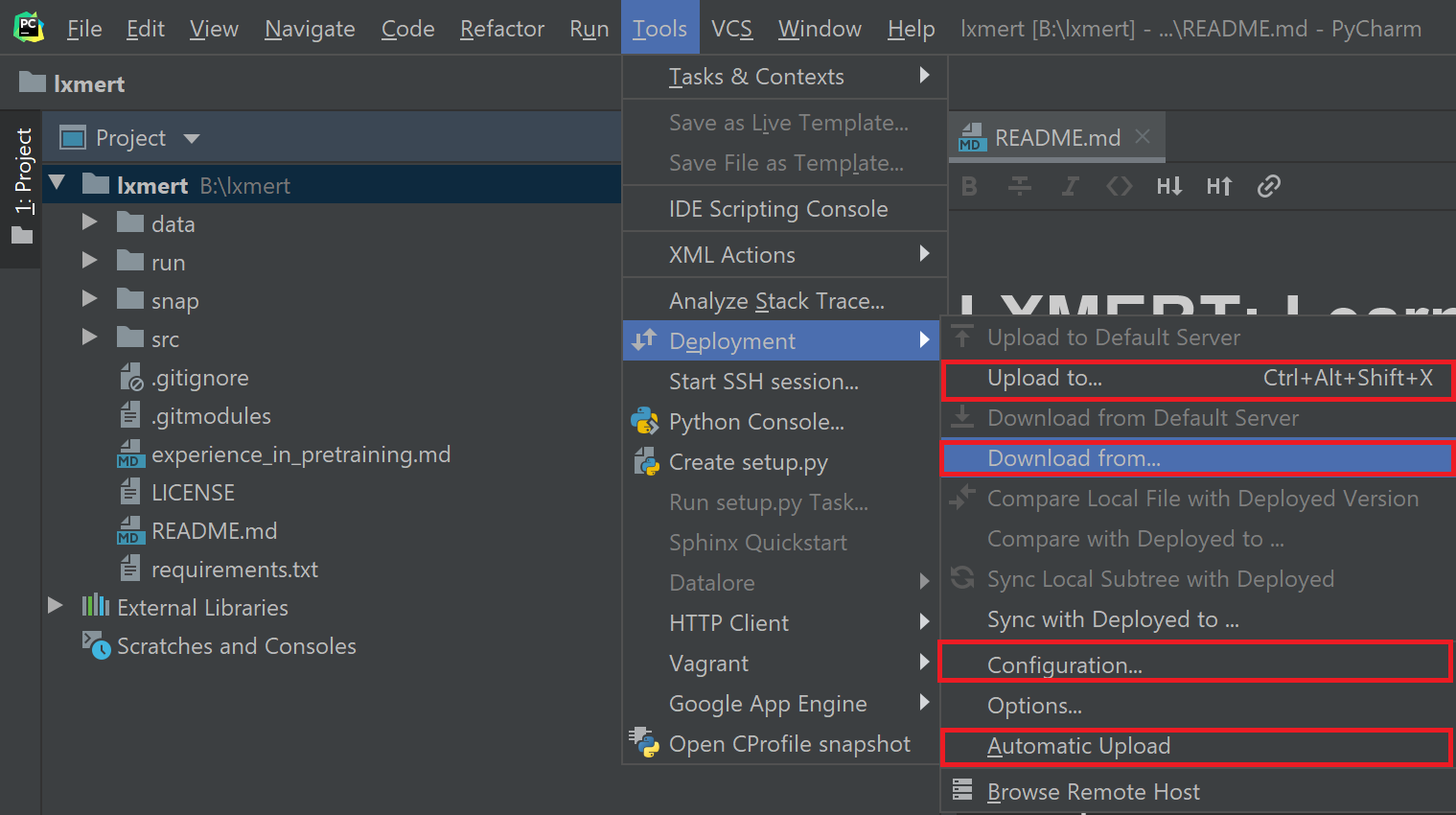
Upload to를 눌러 서버를 선택하면 현재 로컬 프로젝트 파일들을 저장된 원격 서버에 업로드할 수 있다.Download from을 눌러 서버를 선택하면 마찬가지로 원격 서버의 파일을 로컬에 내려받을 수 있다.Configuration을 누르면 조금 전 보았던Mappings탭을 포함해 설정을 다시 할 수 있다.Automatic Upload를 누르면 토글이 되며, 로컬 파일을 원격 서버에 자동으로 업데이트할지를 결정할 수 있다.
Terminal에서 SSH session으로 열기
메뉴 바에서 Tools > Start SSH session...을 클릭하면 Select host to connect 창이 뜬다. 이때 아래쪽 목록에는 현재 프로젝트에 설정되어 있는 python environment들이 뜬다. SSH 연결을 추가하고 싶으면, Edit credentials...를 클릭한다.
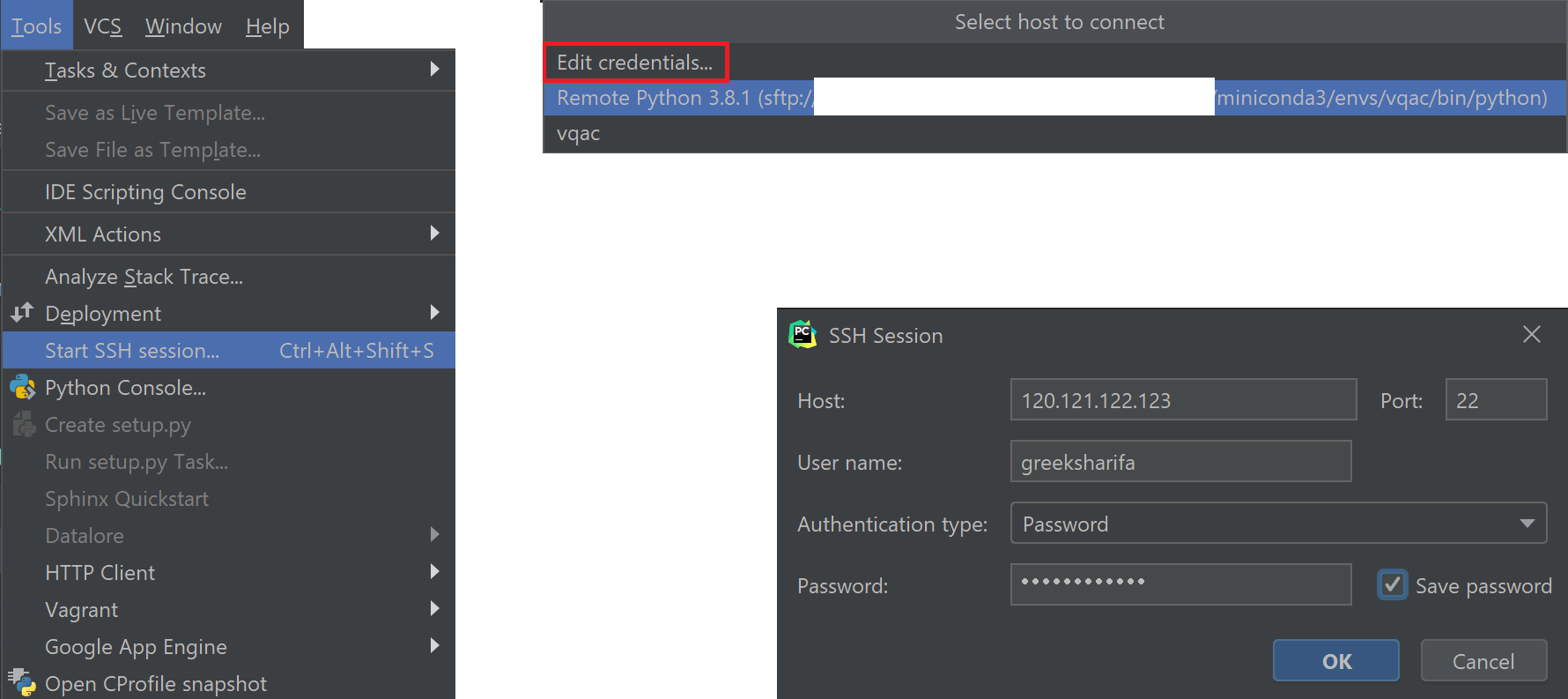
그러면 위 그림과 같이 SSH Session 대화창이 뜬다. 여기서 보통 ssh 연결할 때처럼 서버 주소, 사용자명, 비밀번호 등을 입력하고 OK를 누르면 Terminal 창에서 로컬 환경 대신 SSH 환경에서 열리게 된다. 파일 접속은 물론이고 실행까지 원격 ssh 서버 상에서 이루어지게 된다.
오류 해결법
파이썬 가상환경 보안 에러(오류): about_Execution_Policies PSSecurityException
윈도우에서 powershell을 관리자 권한으로 실행한다.
Set-ExecutionPolicy Unrestricted을 입력한 다음에 Y(대문자)를 누르고 enter 입력하면 해결 완료된다.
References
공식 홈페이지에서 더 자세한 사용법을 찾아볼 수 있다.
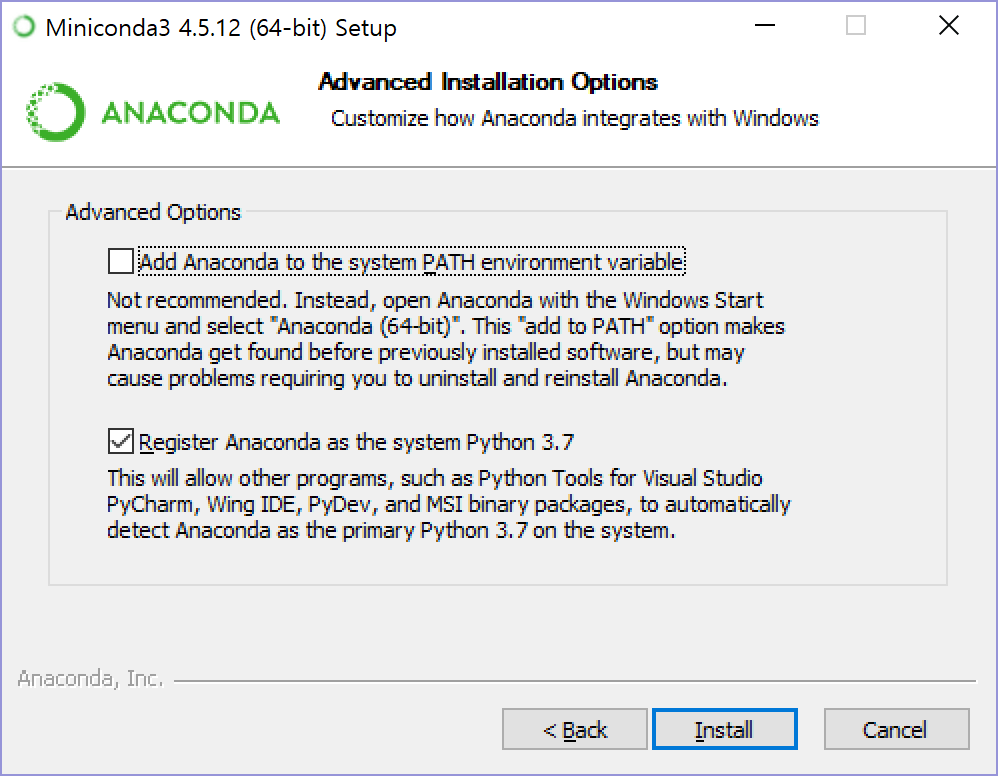
 Not recommended라고 되어 있는 옵션이지만 체크하면 PATH에 등록하지 않아도 된다(이건 환경마다 조금 다르다).
Not recommended라고 되어 있는 옵션이지만 체크하면 PATH에 등록하지 않아도 된다(이건 환경마다 조금 다르다).