
Action Recognition Models(Two-stream, TSN, C3D, R3D, T3D, I3D, S3D, SlowFast, X3D)
04 Dec 2021 | CNN Paper_Review 3DCNN목차
- Two-stream Approach
- TSN(Temporal Segment Networks)
- Hidden Two-stream(Hidden Two-Stream Convolutional Networks for Action Recognition)
- C3D: Learning Spatiotemporal Features with 3D Convolutional Networks
- R3D: Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition
- R(2+1)D: ConvNet Architecture Search for Spatiotemporal Feature Learning
- T3D: Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification
- I3D: Two-Stream Inflated 3D ConvNet
- S3D: Seperable 3D CNN
- SlowFast
- X3D: Expand 3D CNN
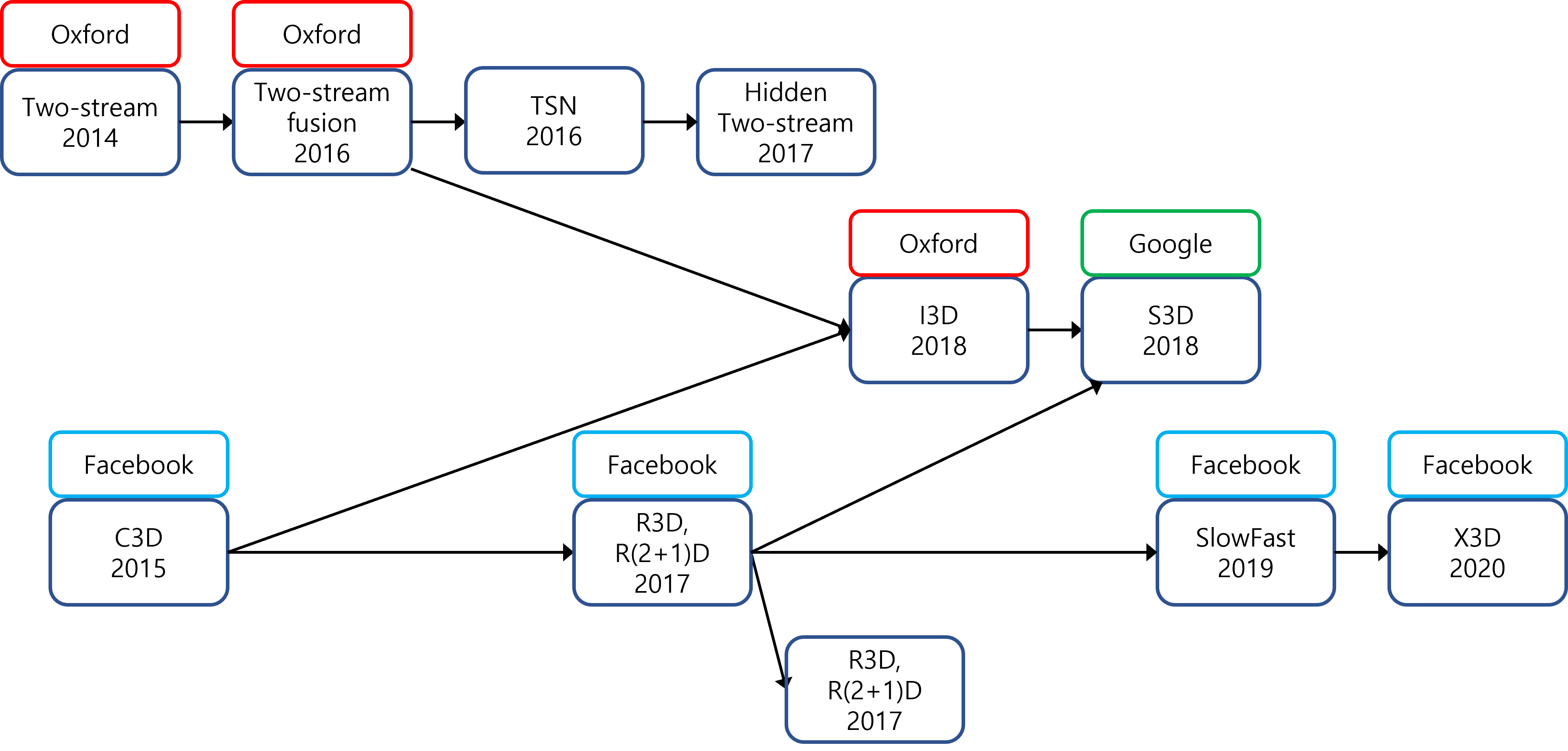
이 글에서는 Video Action Recognition Models(Two-stream, TSN, C3D, R3D, T3D, I3D, S3D, SlowFast, X3D)을 정리한다.
- Two-stream 계열: 공간 정보(spatial info)와 시간 정보(temporal info)를 별도의 stream으로 학습해서 합치는 모델.
- 3D CNN 계열: CNN은 3D로 확장하여 (iamge $\rightarrow$ video) 사용한 모델. Facebook이 주도해 왔다.
Two-stream Approach
논문 링크: Two-Stream Convolutional Networks for Action Recognition in Videos
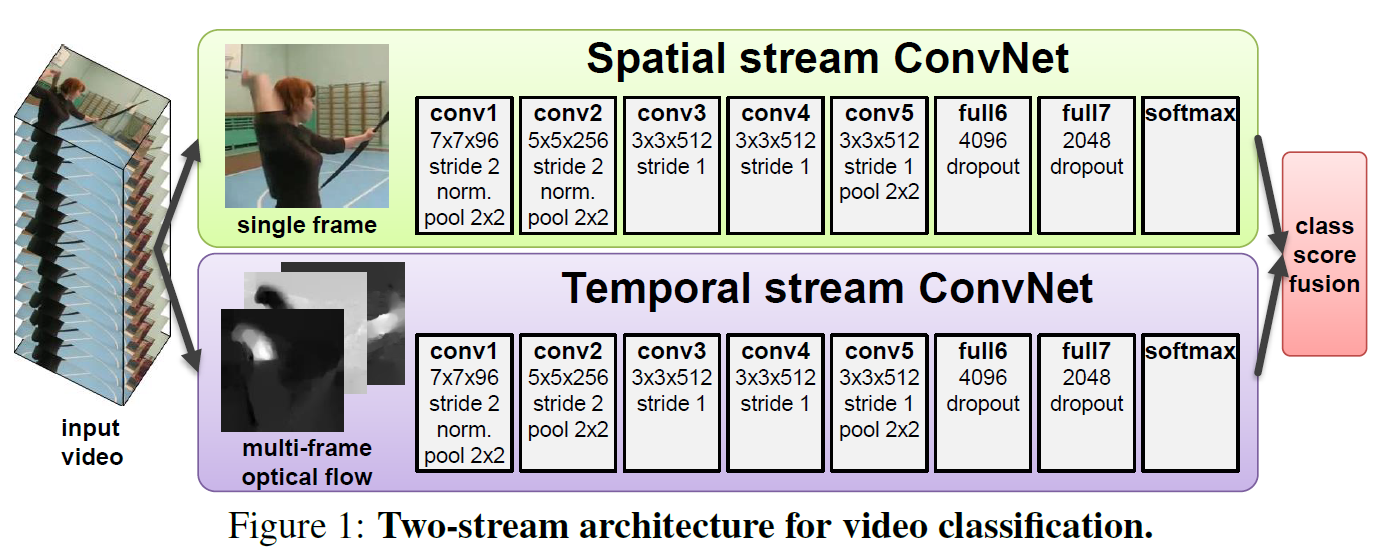
말 그대로 spatial info와 temporal info를 별개의 stream에서 각각 학습한 뒤 마지막에 fusion하는 모델이다. Action Recognition 연구 초기에는 이런 식으로 접근했었다.
여기서 Optical Flow라는 개념이 나온다.

다음 프레임으로 넘어갈 때 각 픽셀이 어디로 이동했는지를 벡터로 나타낸 것이라고 간단히 생각하면 된다. 이를 모델 입력에 사용되는 프레임마다 구하여 temporal stream convNet에 태운다. 논문에서는 수평 방향($u$)과 수직 방향($v$)로 나누어 계산한다.
추가 설명: optical flow를 계산할 때 기본 가정이 있는데, (어떻게 보면 당연한 것들이다) 다음 프레임으로 갈 때
- Brightness Consistency: 각 object의 같은 지점은 밝기가 거의 같게 유지된다.
- Temporal Persistence: 각 object는 먼 거리를 이동하지 않는다.
- Spatical Coherence: 인접한 점들은 거의 같은 방향으로 이동한다.
모델 설명:
Spatial stream은 이미지 한 장을 사용하므로 2D convNet을 사용한다. AlexNet과 거의 유사하다.
Temporal stream은 image sequence를 입력으로 받는다. 그래서 어디선가 이 정보들을 합치는 과정이 필요한데,
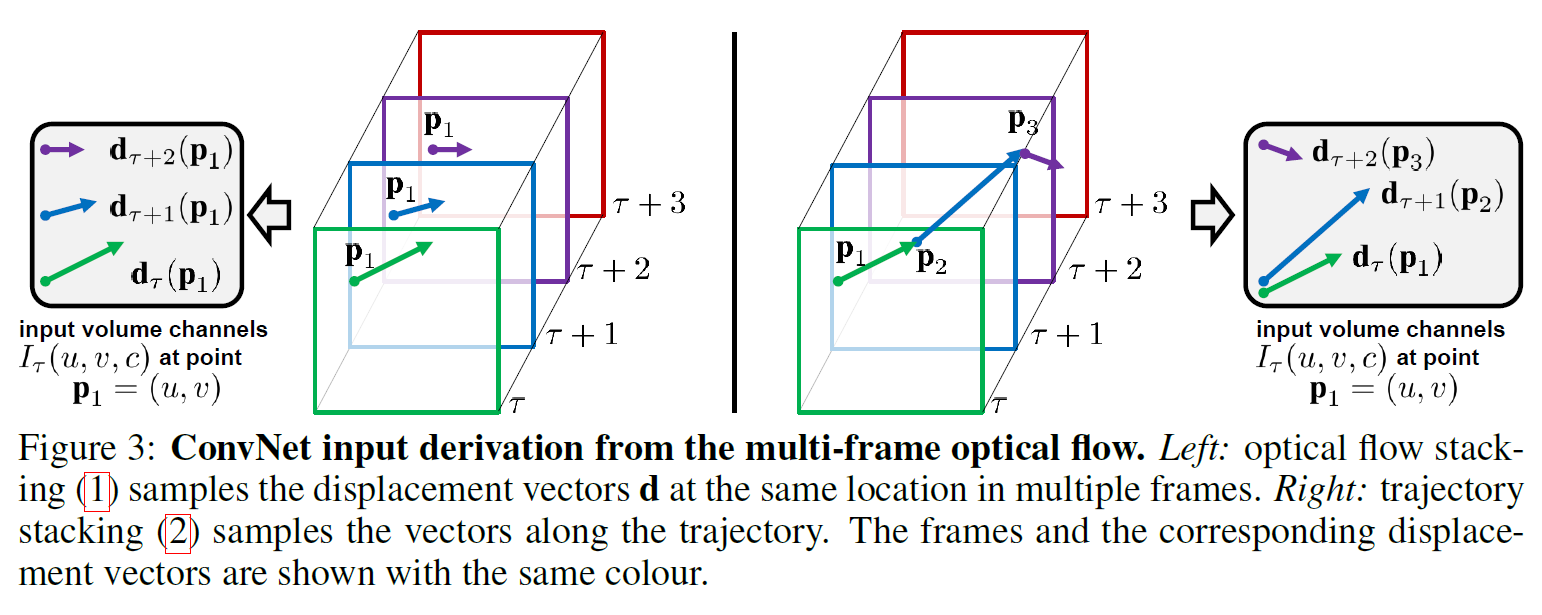
- Optical flow stacking: $L$ frame에 대해 각 방향 $u, v$가 있으므로 $2L$개의 channel이 있다.
- Trajectory stacking: optical flow vector를 그냥 쌓는 대신 flow를 따라가면서 sampling한다. 채널 수는 같게 유지된다.
단순한 방법임을 알 수 있다. 따라서 단점이 있다.
- Missing Long range temporal info: 다음 frame의 flow만 계산하므로 장거리 의존성에 대한 학습이 이루어지지 않는다.
- False label assignment: 어떤 frame을 선택하느냐에 따라 다른 label을 할당할 수 있다.
- Optical flow를 매번 계산하므로 비싸고 오래 걸린다.
- 2개의 stream을 따로 학습하므로 end-to-end 학습이 될 수 없다. (추후 논문에서 개선됨)
이후 개선점
-
논문 링크: Convolutional Two-Stream Network Fusion for Video Action Recognition
-
마지막(scoring step)에 2 stream을 합치는 대신 중간에서 합치는 방식을 사용한다.
- 중간에 합치면 성능을 해치지 않으면서도 계산량을 줄일 수 있다.
- conv layer 중에서는 마지막 conv layer에서 합치는 것이 첫 부분에서 합치는 것보다 낫다.
TSN(Temporal Segment Networks)
논문 링크: Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
- 더 나은 long-range temporal modeling을 위해 $K$개의 부분으로 나누어서 2-stream model을 각각 돌려준다.
- optical flow에 더해 2개의 temporal stream을 추가하는데,
- Warped optical flow: 카메라 움직임을 보정하기 위해 actor에 집중하여 계산함.
- RGB difference: 픽셀의 rgb 변화를 측정하는데 큰 도움은 안 됐다고 한다.
- overfitting을 줄이기 위해 batch-norm, pre-training, drop-out 등을 사용하였더니 성능이 더 좋아졌다.
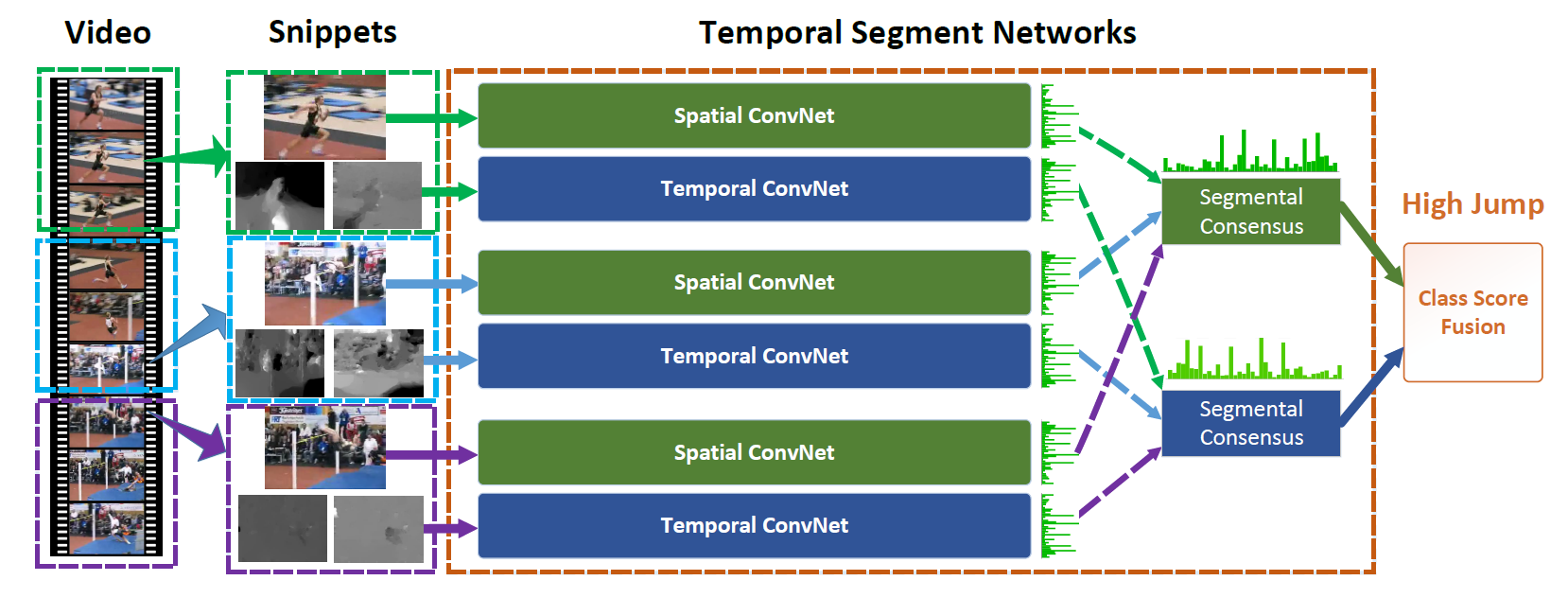
위의 그림을 보면 비디오를 여러 clip으로 나눈 뒤 각각 two-stream model을 돌려서 공간 정보/시간 정보끼리 합친 것을 볼 수 있다.
Hidden Two-stream(Hidden Two-Stream Convolutional Networks for Action Recognition)
논문 링크: Hidden Two-Stream Convolutional Networks for Action Recognition
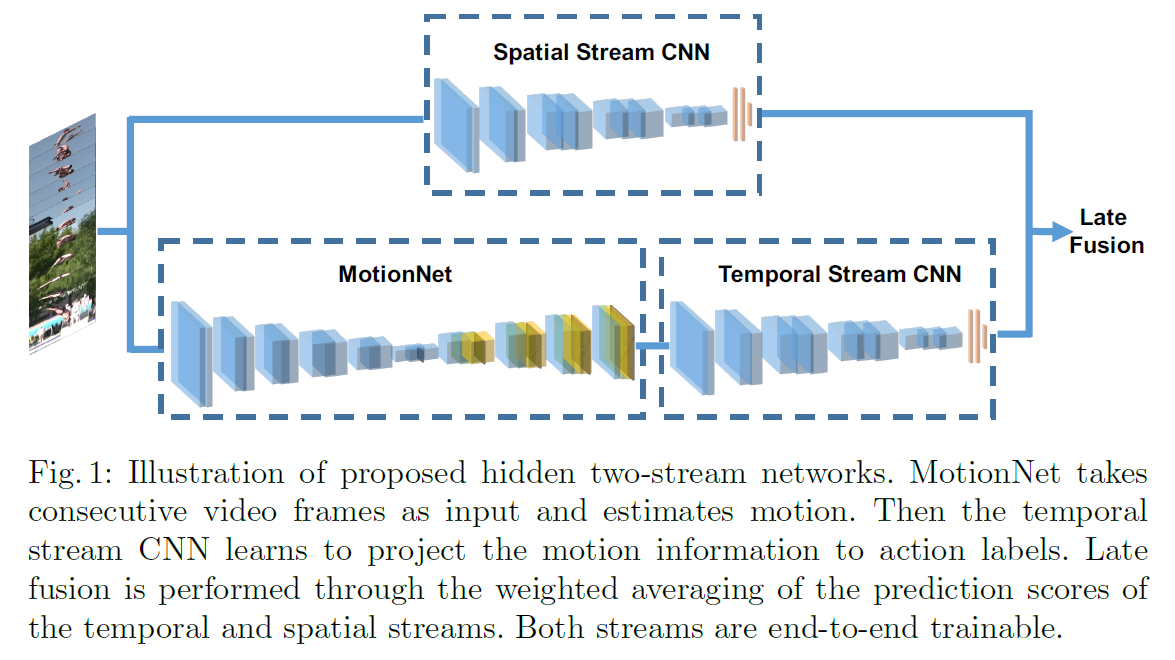
- 미리 계산한 optical flow를 사용하는 대신 그때그때 계산한다.
- spatial stream에는 변화가 없다.
- MotionNet이 temporal stream 앞에 추가되어 optical flow를 추정한다.
- MotionNet
- 연속된 이미지 $I_1, I_2$가 주어지면 그 차이 $V$를 계산한다.
- Reconstruction Loss: $I_2 - V \simeq I_1$
- 이 차이 $V$가 Temporal Stream CNN에 입력으로 주어진다.
C3D: Learning Spatiotemporal Features with 3D Convolutional Networks
논문 링크: Learning Spatiotemporal Features with 3D Convolutional Networks
어쩐지 AlexNet이 생각나는 모델 구조를 갖고 있는데, 2D CNN을 시간 축으로 한 차원 더 확장하여 3D CNN을 적용한 것이라고 보면 된다.

꽤 좋은 성능을 가지며 구조로 상당히 간단한 편이다.
단점은,
- 여전히 장거리 의존성을 잘 모델링하지 못하며,
- 계산량이 2D일 때보다 크게 늘어나서 상당히 많으며
- 아직 hand-crafted feature가 필요하다.
R3D: Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition
논문 링크(약간 불확실): Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition
ResNet을 3D로 확장한 모델이다.
차이가 있다면
- 3D는 계산량이 더 많기 때문에 152가 아닌 34개의 block을 사용하였고
- 3x3 conv가 아닌 3x3x3 conv 사용(3D니까 당연하다)
정도의 차이가 있다.

입력 차원은 $(L \times 112 \times 112 \times 3)$이며 stride는 conv1에서 1x2x2(시간 차원 1, 공간 차원 2x2), conv2부터는 2x2x2(시간 차원도 2배로 줄어듦)이다. 한 층을 지나갈 때마다 크기는 2배로 줄고 채널은 2배로 늘어난다.
R(2+1)D: ConvNet Architecture Search for Spatiotemporal Feature Learning
논문 링크: ConvNet Architecture Search for Spatiotemporal Feature Learning
R3D와 비슷하지만 시간에 대한 kernel과 공간에 대한 kernel을 분리해서 학습한다. 어떻게 보면 two-stream model과 비슷한 논리이다. 단 optical flow 같은 것을 쓰는 대신 conv 연산으로 수행한다는 점이 다르다.
같은 크기의 모델을 쓸 때 성능 상으로 이점이 있다고 한다.
T3D: Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification
논문 링크: Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification
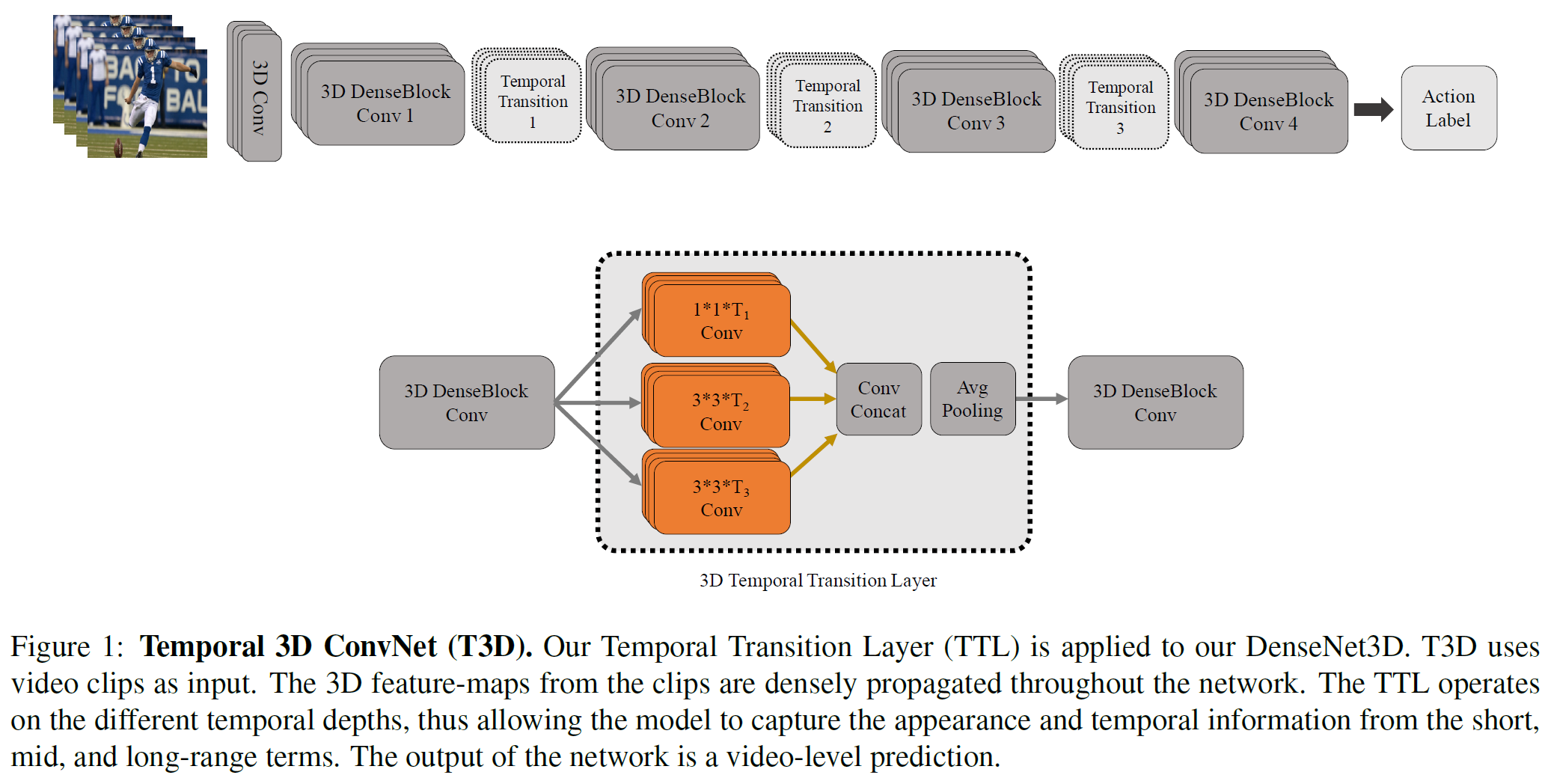
DenseNet: Densely Connected Convolutional Networks 기반으로 만든 single stream 모델이다.
다양한 길이의 temporal feature를 얻기 위해 dense block 뒤에 Temporal Transition Layer를 추가하여 temporal pooling을 수행한다. GoogLeNet에서 Inception module과 비슷한 아이디어이다.
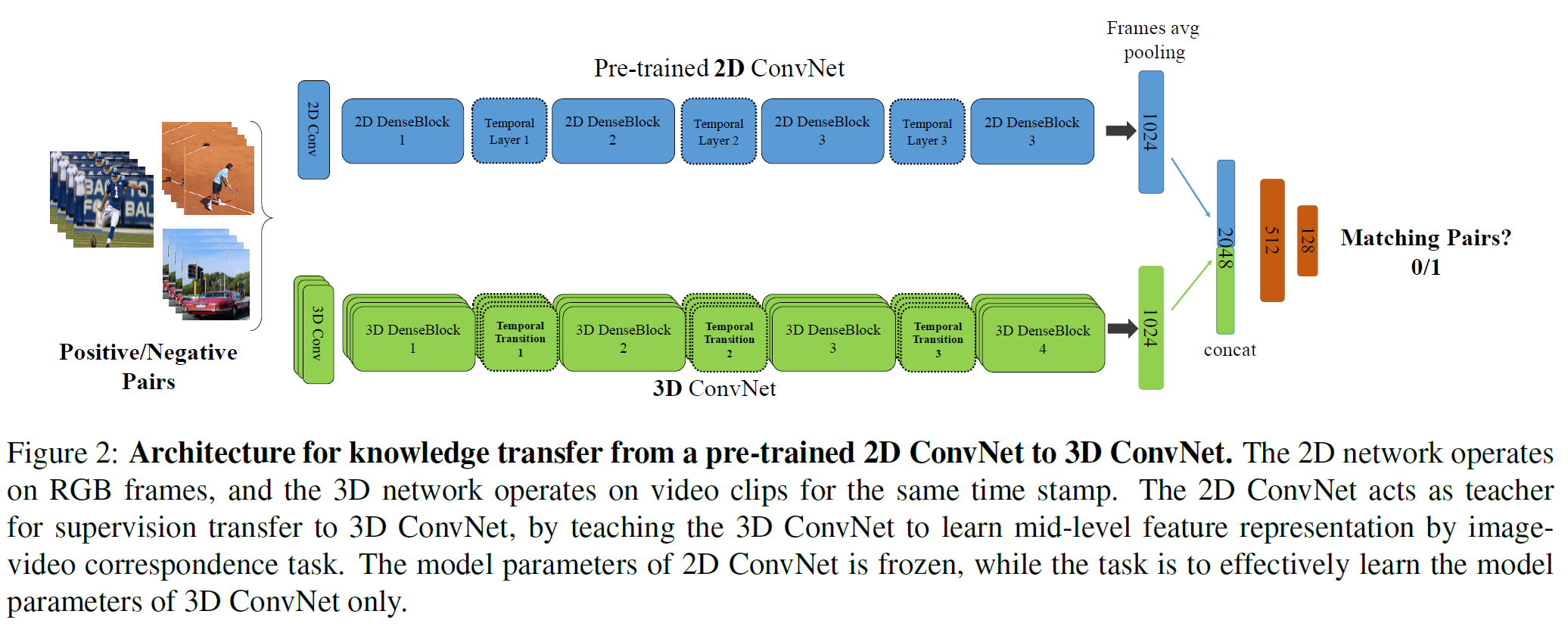
사전학습된 2D ConvNet을 일종의 teacher로서 사용하는데, 2D ConvNet에서 transfer learning하는 것과도 비슷하다고 할 수도 있다. 2D 부분은 고정시켜 두고, 3D stream만 update하는데, 2D net의 mid-level feature를 갖고 지도학습을 시키는 방식이다.
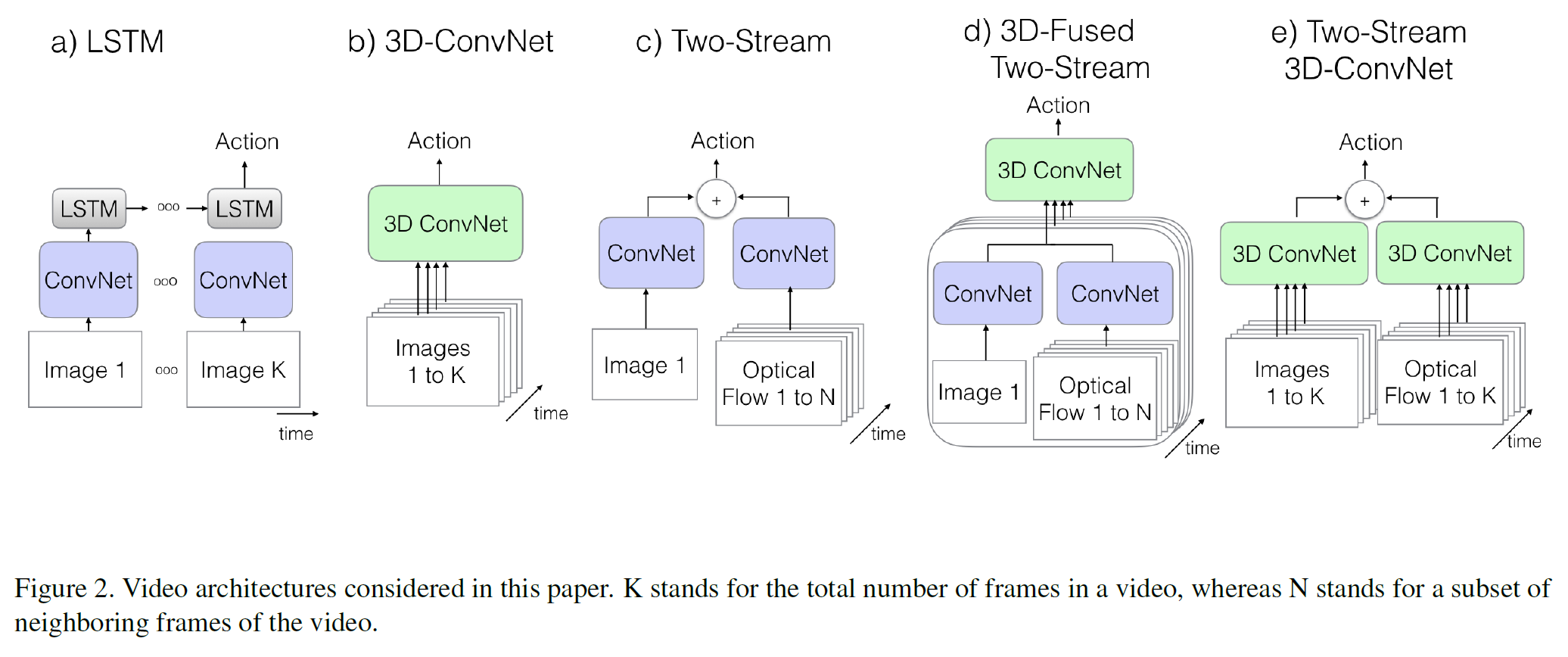
아래부터는 two-stream과 3D conv(C3D)의 아이디어를 합친 논문이다.
I3D: Two-Stream Inflated 3D ConvNet
논문 링크: Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
- Two-stream 방법에서, spatial stream을 3차원으로 확장하였다.
- Temporal stream은 여전히 미리 계산된 optical flow를 입력으로 하되 이제 early fusion 대신 3D conv 방식을 사용한다.
Architecture는 GoogLeNet(Inception-V1)에 기초하지만 바뀐 점은 2D가 아닌 3D로 확장한 버전이다.
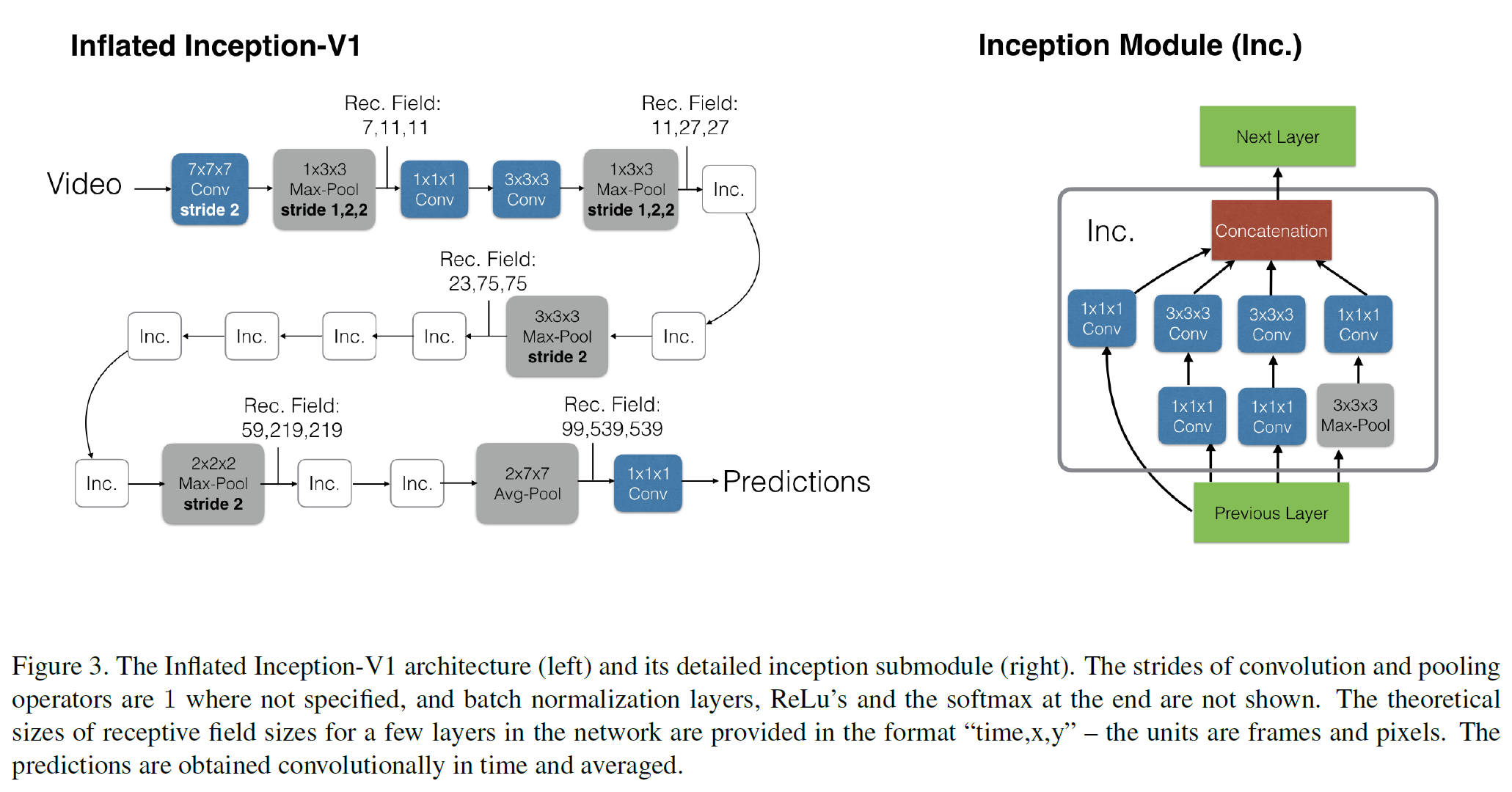
Optical flow를 여전히 써야 하는가? 하는 의문을 던지는데,
- 3D ConvNet은 여전히 순수 feed-forward 계산을 사용하는데, optical flow는 어떤 recurrent한 계산을 수행한다(flow field에서 반복적 최적화를 수행한다).
그러나 사실 이 논문 이후로는 optical flow가 사실상 사용되지 않는다.
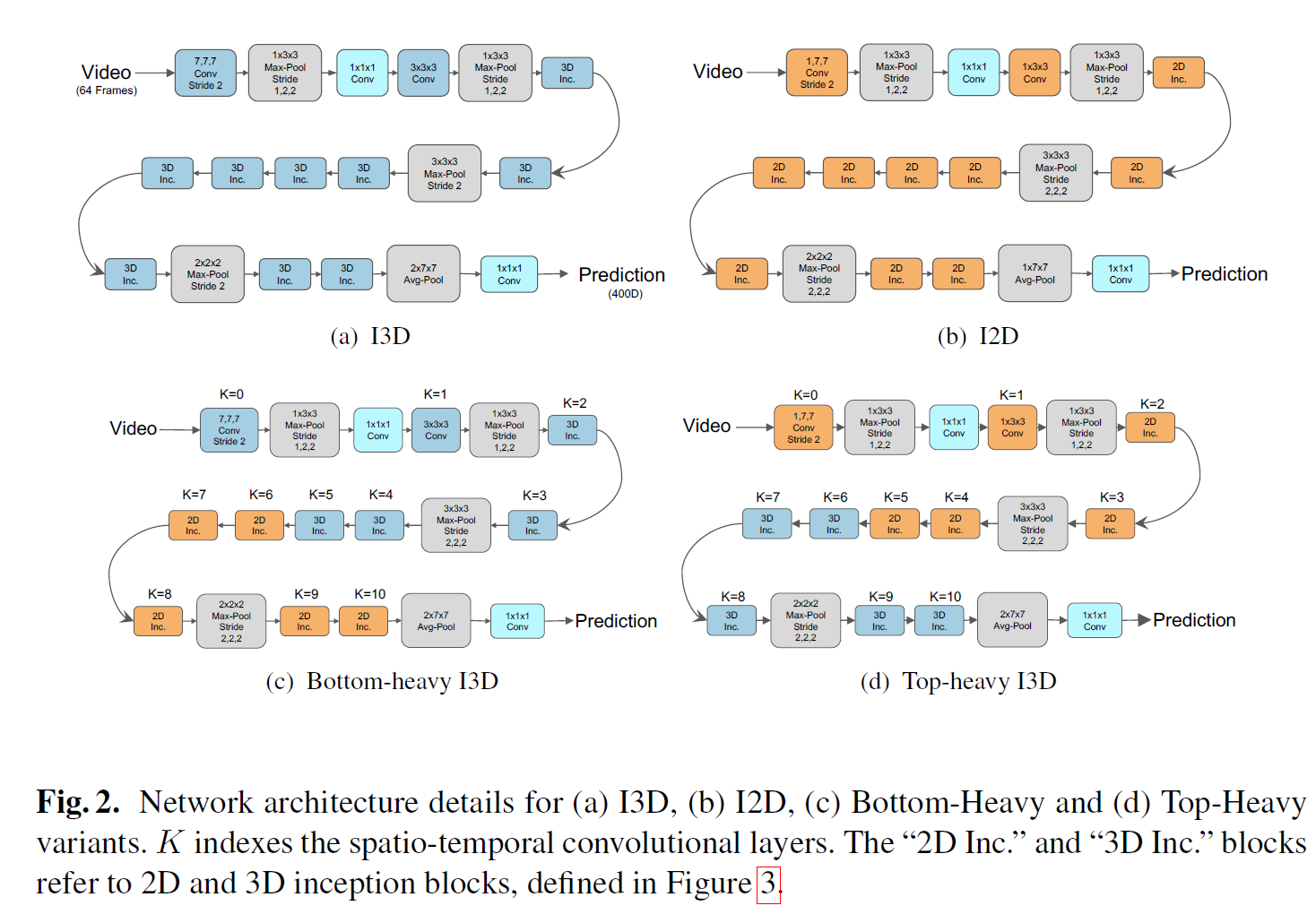
S3D: Seperable 3D CNN
논문 링크: Rethinking Spatiotemporal Feature Learning: Speed-Accuracy Trade-offs in Video Classification
R3D를 R(2+1)D로 바꾼 것과 비슷한데 I3D의 Inception block의 3D를 2D+1D로 바꾼 것이다.
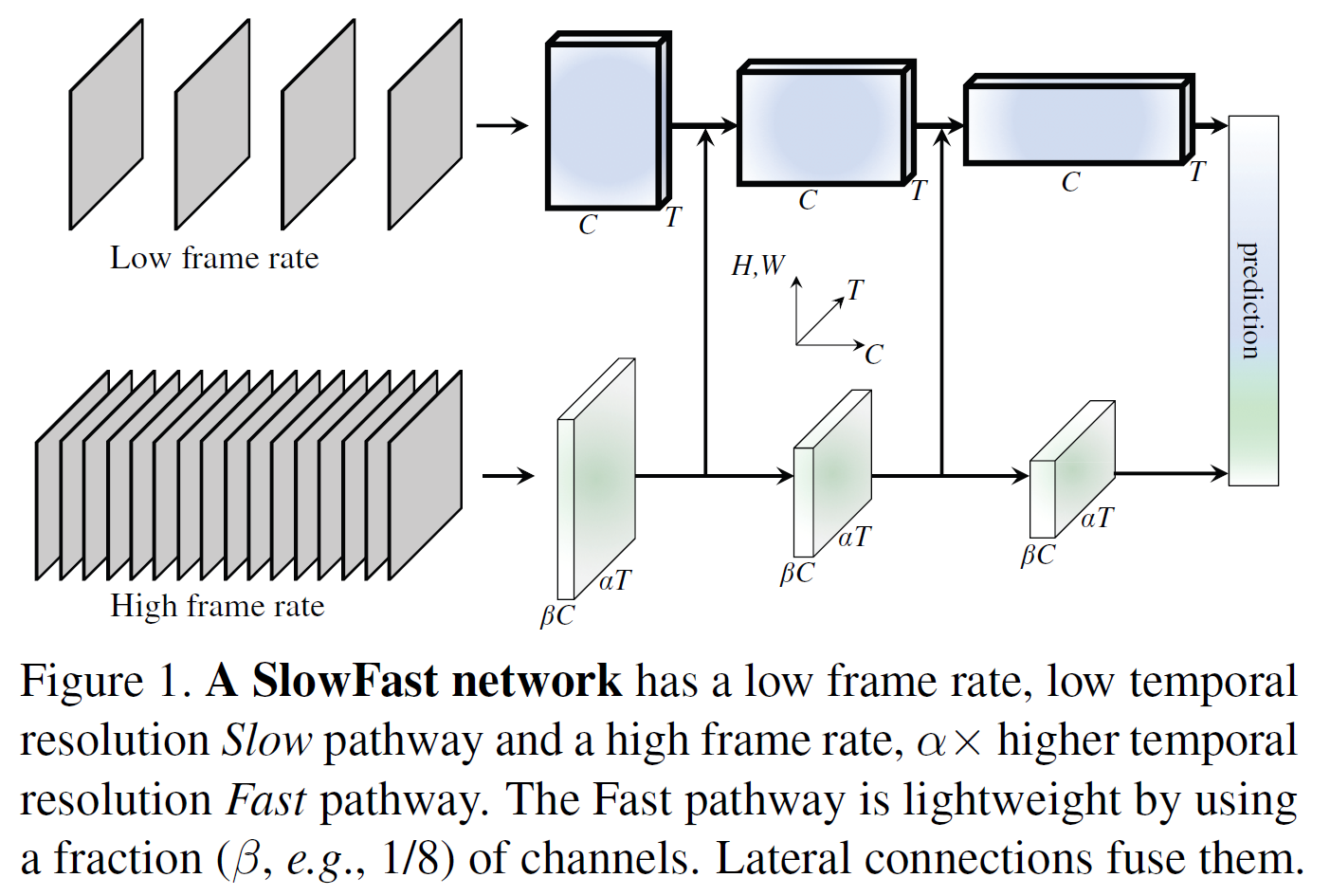
SlowFast
논문 링크: SlowFast Networks for Video Recognition
- 낮은 rate로 frame을 조금 뽑아서 사용하는 Slow pathway(spatial info에 집중)
- 높은 rate로 frame을 많이 뽑아서 사용하는 Fast pathway(temporal dynamics에 집중됨)
2개의 pathway를 사용하는 어떻게 보면 R3D와 비슷한 구조를 사용한다.
전체 구조를 표로 나타내면 다음과 같다.
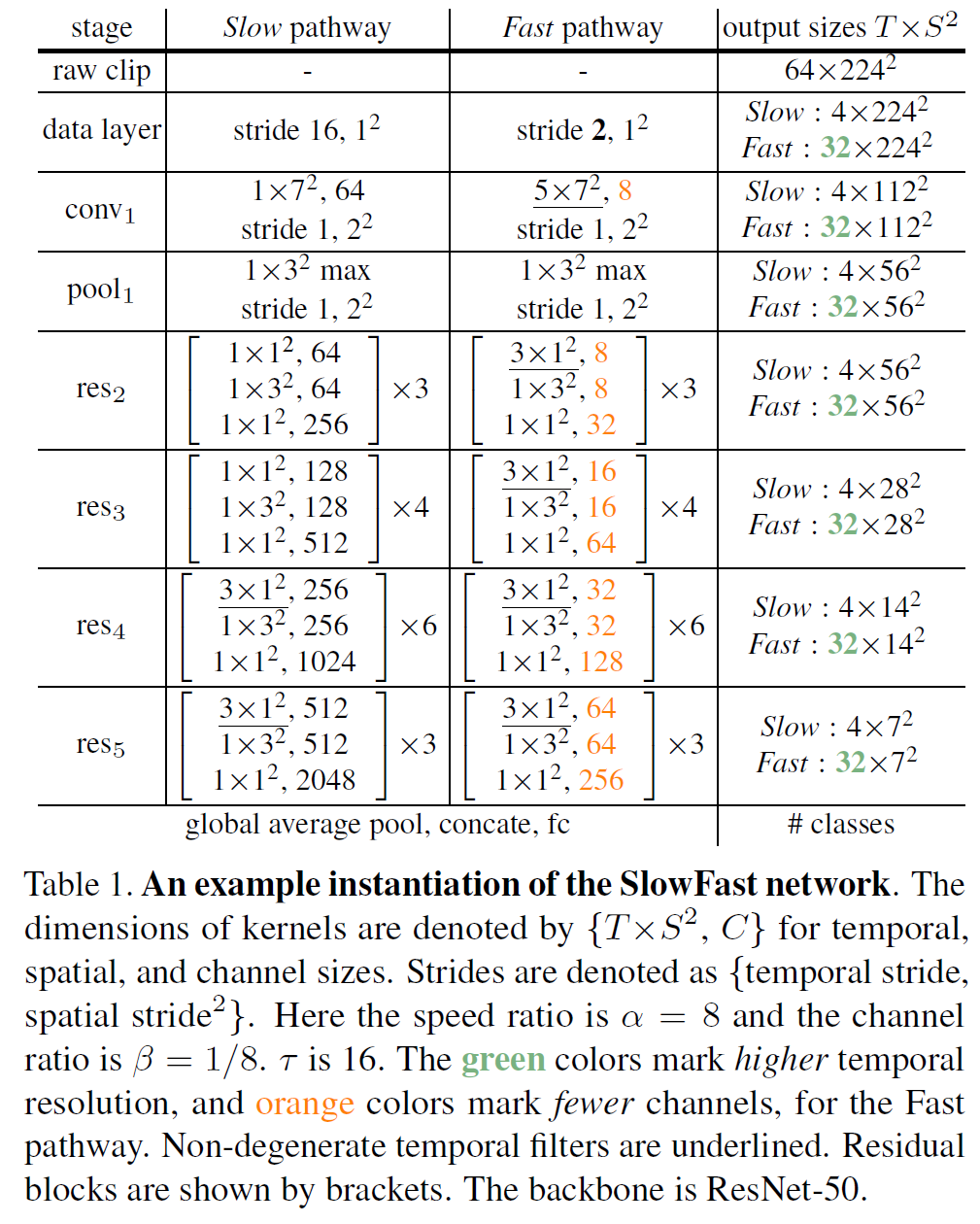
Slow pathway에서는,
- stide가 16이라 다음 프레임으로 넘어가면 정보가 많이 바뀐다.
- 시간 차원이 1인데, 이는 이미지를 한 장으로 처리한다는 뜻이므로 시간 정보가 포함되지 않는다. res4, res5에 와서야 한 번씩 차원이 3이 되므로, 전체적으로 spatial info에 집중한다는 것을 알 수 있다.
- 더 많은 channel을 사용한다.
Fast pathway에서는,
- Slow보다 8배 더 많이 뽑는다(stride 2).
- 시간 차원이 늘어서 정보를 더 많이 쓰고, orange색 숫자를 보면 채널이 그만큼 줄어들었다는 것을 의미한다.
연결 부분에서는,
- pathway 간 연결을 중간에 추가하는데, fast 쪽에서 slow 쪽으로만 연결을 추가해도 성능이 괜찮아졌다고 한다.
- 단, 정보를 갖다 쓰려면 conv output의 크기가 같아야 한다. 위의 표에서, 공간 정보의 차원은 slow에서나 fast에서나 갈은 것을 볼 수 있다.
X3D: Expand 3D CNN
논문 링크: X3D: Expanding Architectures for Efficient Video Recognition
X: expand이다. 간단한 stepwise network expansion을 각 step의 한 축마다 확장을 시켜본다.
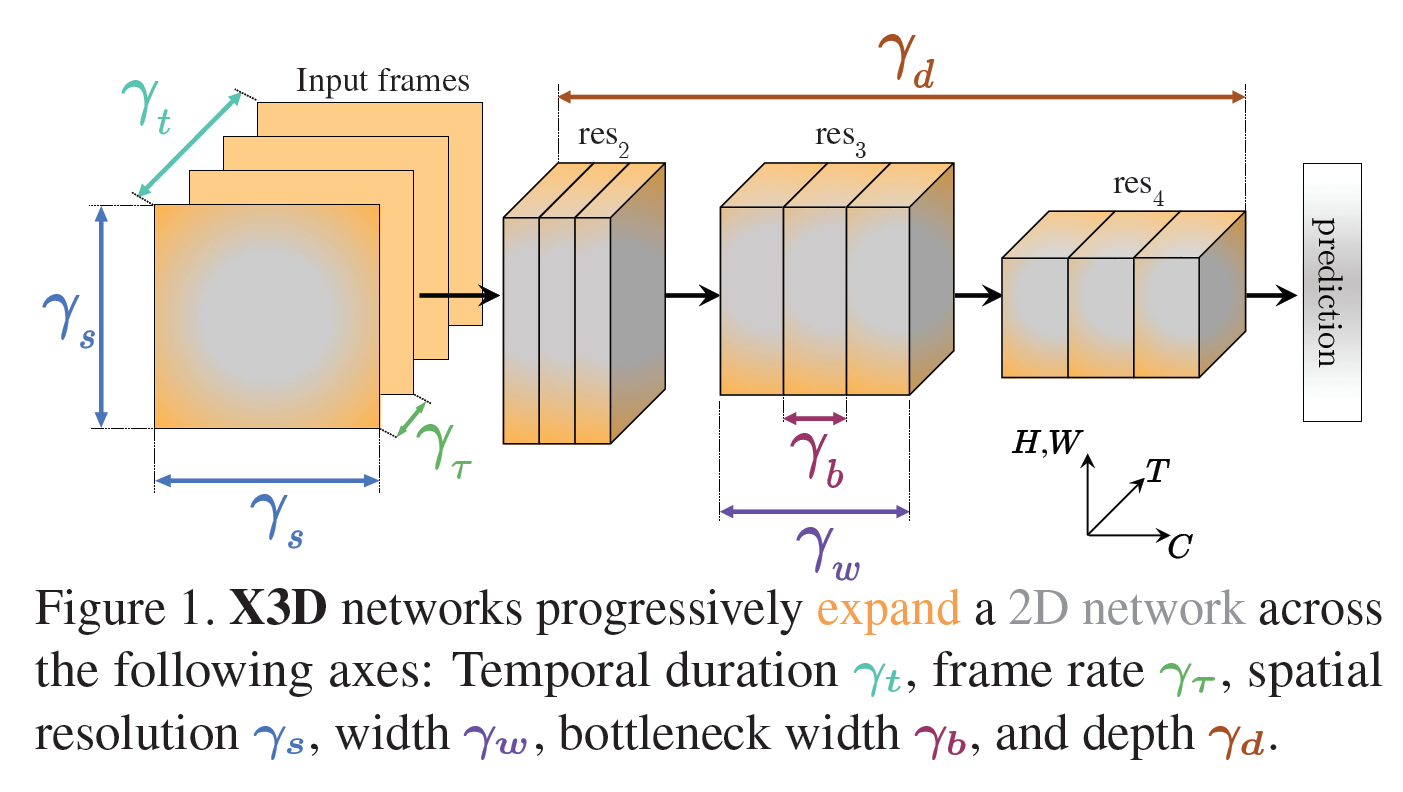
전체 구조는 아래와 같은데, 아래의 각 색깔로 표시된 부분을 조금씩 늘려 보면서 가장 좋은 결과를 찾아내는 방법이라 생각하면 된다.

- X-Fast($\gamma_\tau$): 입력의 frame rate.
- X-Temporal($\gamma_t$): 입력의 frame 개수.
- X-Spatial($\gamma_s$): sampling resolution.
- X-Depth($\gamma_d$): residual stage 당 layer의 수.
- X-Width($\gamma_w$): 모든 layer의 채널의 수.
- X-Bottleneck($\gamma_b$): 중간 conv filter의 inner channel width.
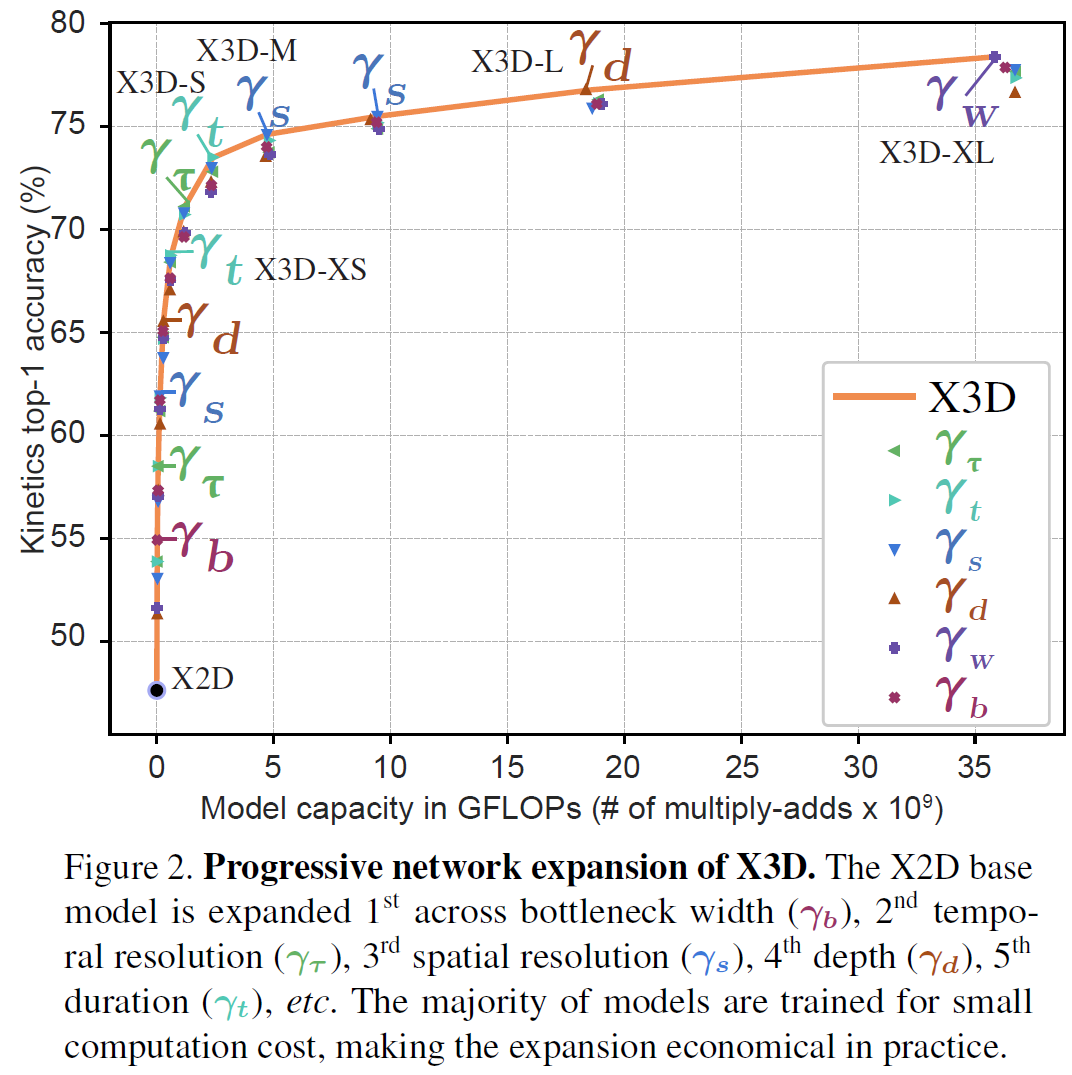
실험을 매우 많이 해본 논문이라 보면 된다. 특별히 반짝이는 아이디어는 없다.
참고할 만한 자료
- A Comprehensive Study of Deep Video Action Recognition: Video Action Recognition의 모델 역사를 정리해 놓았다고 보면 된다. X3D 이후에도 TPN, V4D, AssembleNet 등의 논문이 정리되어 있다고 한다.