RNN based Video Models
04 Dec 2021 | RNN Paper_Review목차
이 글에서는 RNN 기반 Video Classification Model을 간략히 소개한다.
RNN 기반 모델은 single embedding으로 전체 seq를 인코딩하므로 정보의 손실이 입력이 길어질수록 커진다. 또 처음에 들어온 입력에 대한 정보는 점점 잊혀지는 단점이 있다.
이는 Attention Is All You Need 이후 발표되는 Attention 기반 모델에서 개선된다.
LRCN: Long-term Recurrent Convolutional Network
논문 링크: Long-term Recurrent Convolutional Networks for Visual Recognition and Description
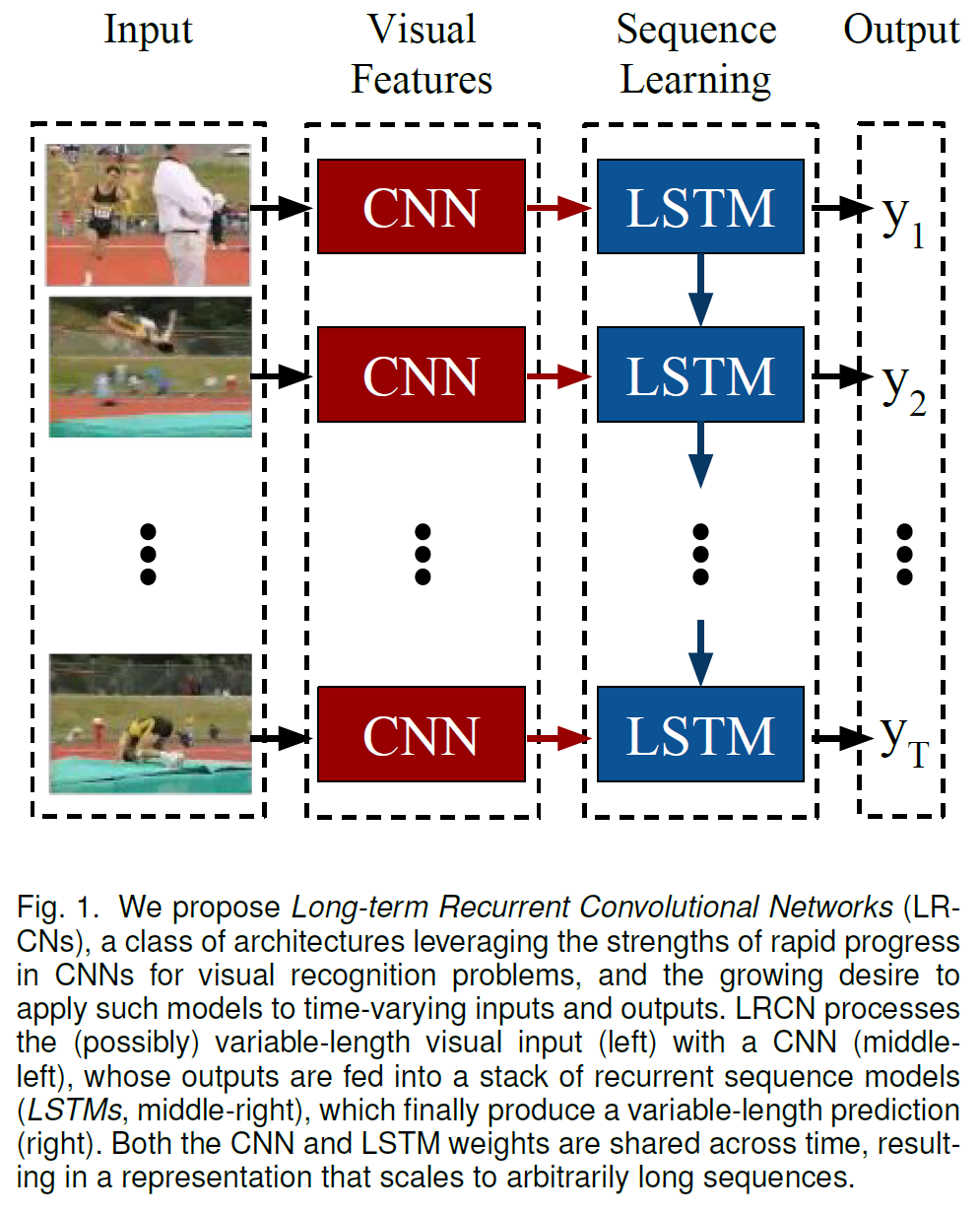
비디오의 일부 frame을 뽑아 CNN을 통과시킨 뒤 LSTM에 넣고 그 결과를 평균하여 최종 출력을 얻는 상당히 straight-forward 한 방법론을 제시한다.
모든 input frame마다 LSTM cell이 activity class를 예측한다.
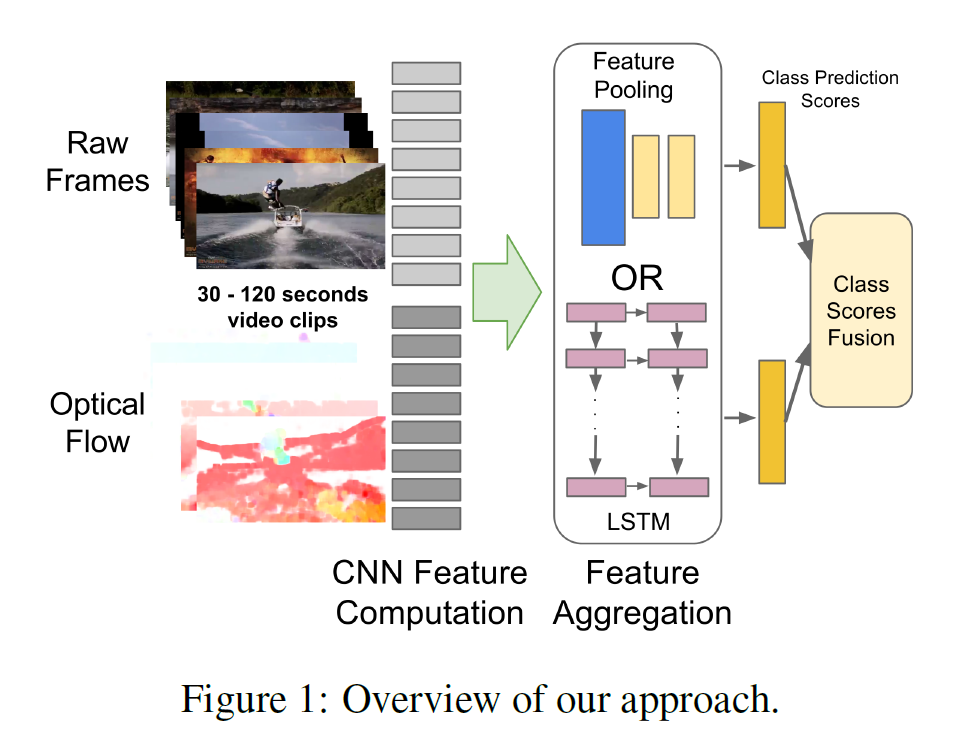
Beyond Short Snippets
논문 링크: Beyond Short Snippets: Deep Networks for Video Classification
이전에는 짧은 video snippet(16 frame 등)만을 사용했는데 이 논문에서 (거의?) 처음으로 긴 영상(300 frame)을 다룰 수 있게 되었다.
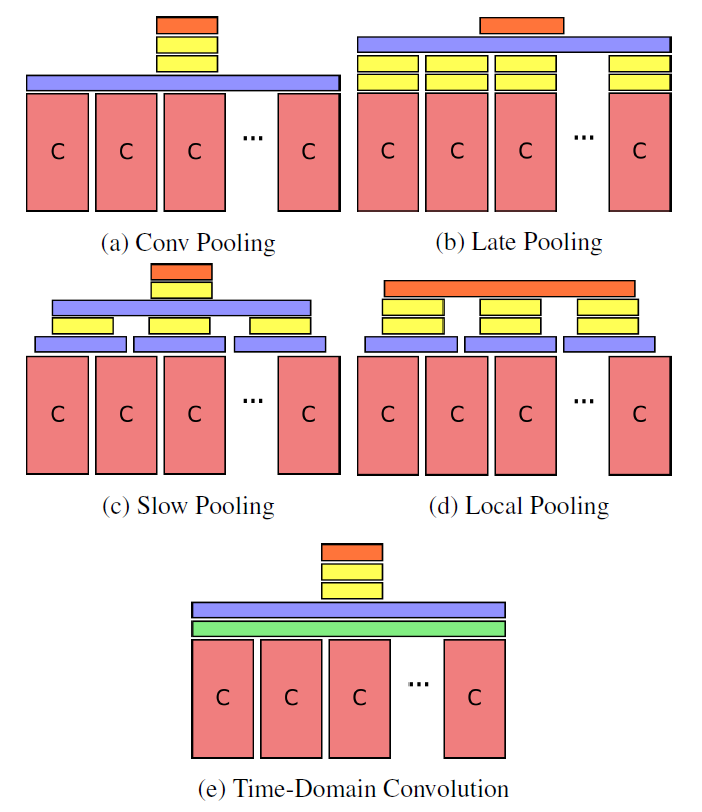
Pooling 방법을 여러 개 시도하였는데,
- Conv Pooling: 사실상 max와 갈다.
- Late Pooling: max 전에 FC layer를 추가했다.
- Slow Pooling: FC를 사이에 추가하면서 max를 계층적으로 취한다.
- Local Pooling: max를 지역적으로만 사용하고 softmax 전에 이어 붙인다.
- Time-domain conv Pooling: 1x1를 max pooling 전에 사용한다.
근데 결과는 Conv Pooling(max pool)이 가장 좋았다고 한다..
LSTM 갖고도 실험을 해보았는데, Multi-layer LSTM을 사용하였다.
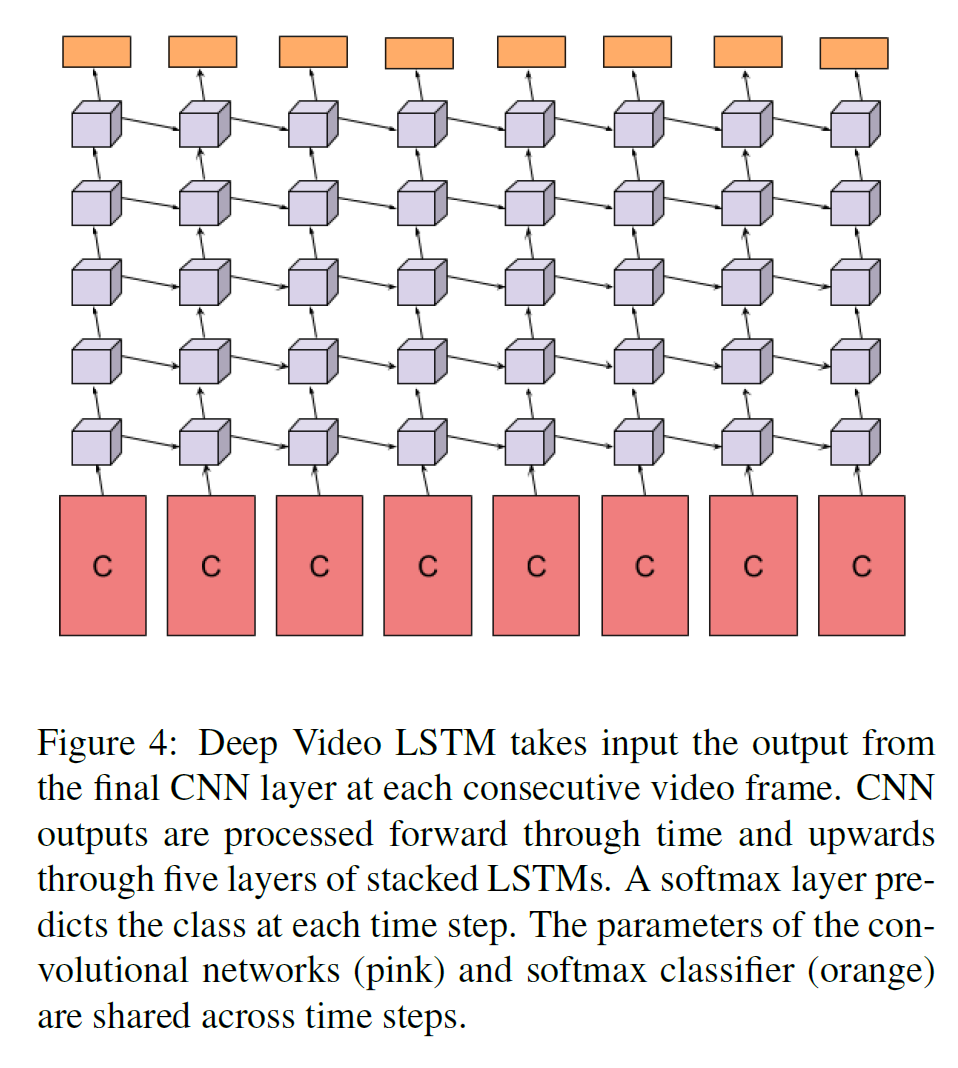
frame-level prediction을 aggregate하기 위해 여러 방식을 사용하였다.
- Max, average, weighted, …
물론 결과는 비슷하다고 한다.
FC-LSTM
논문 링크: Generating Sequences With Recurrent Neural Networks
LSTM cell에서, 각 gate 계산 시 short term에 더해 long term 부분을 집어넣어 계산하였다.
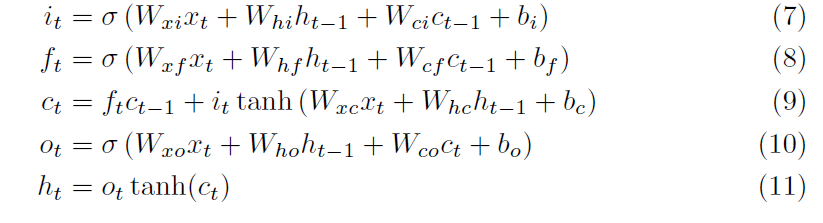
Conv-LSTM
논문 링크: Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting
데이터의 Spatio-Temporal dynamics를 학습하기 위해 FC-LSTM을 확장한 모델이다.
변경점은,
- Input $x$와 hidden $(h, c)$가 vector에서 matrix(Tensor)로 확장되었다.
- Weights $(W, U)$를 $(x, h)$와 연산할 때 FC 대신 Conv 연산으로 바꾼다.
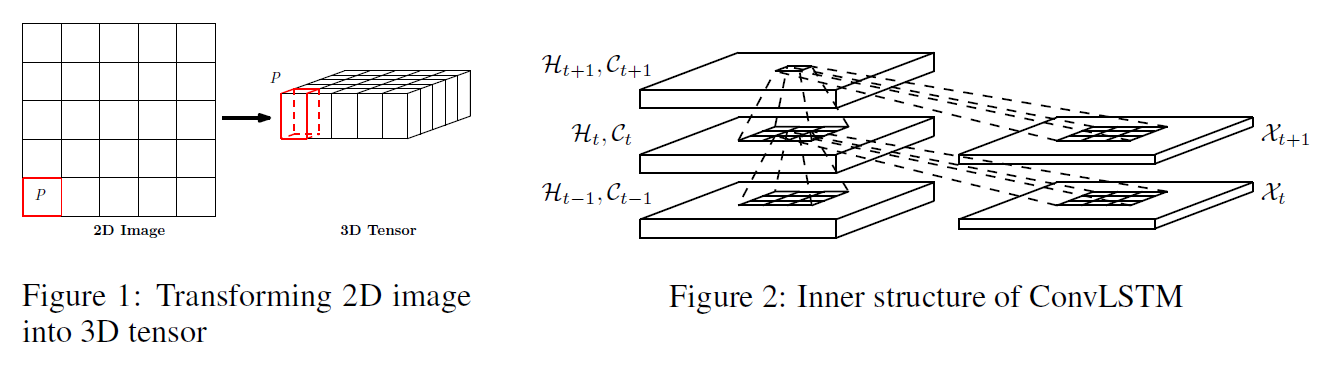
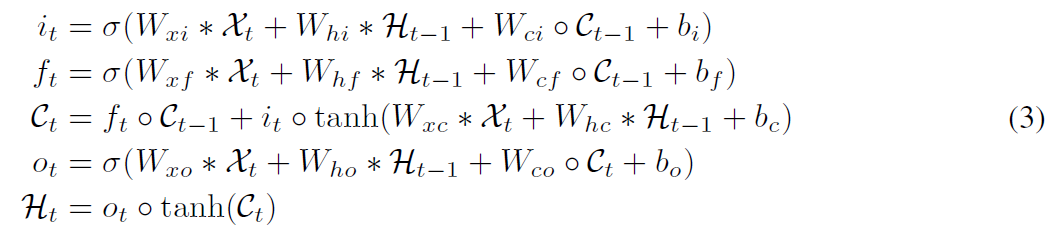
이로써 장점이 생기는데,
- Multi-layer LSTM과 비슷하게 ConvLSTM layer를 여러 층 쌓을 수 있다.
- seq2seq 구조에 적용하면 decoder는 이후 출력을 예측할 수 있다.
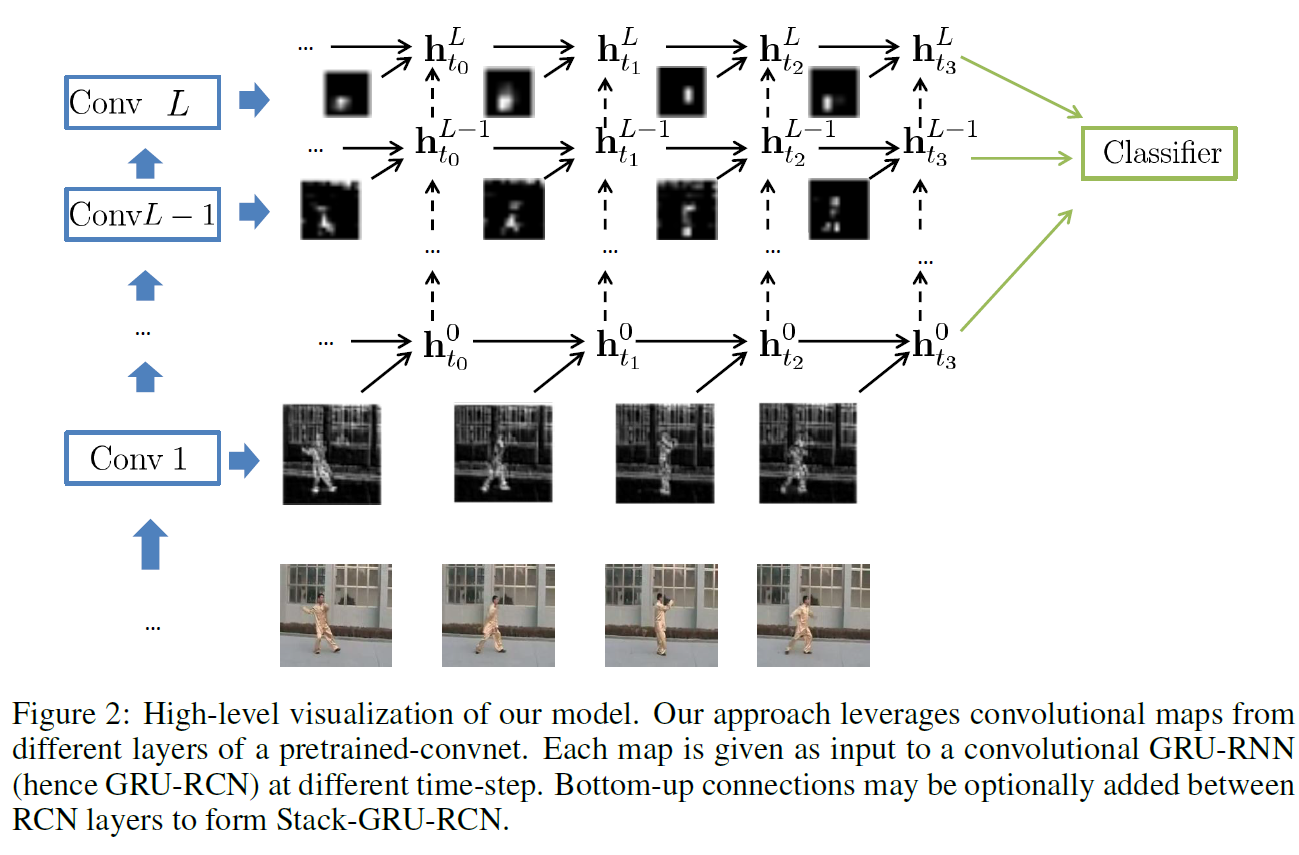
Conv-GRU
논문 링크: Delving Deeper into Convolutional Networks for Learning Video Representations
GRU에다가 같은 아이디어를 적용한 논문이다.