
Attention based Video Models
06 Dec 2021 | Attention Paper_Review목차
이 글에서는 Attention 기반 Video (Classification) Model을 간략히 소개한다.
Multi-LSTM
논문 링크: Every Moment Counts: Dense Detailed Labeling of Actions in Complex Videos
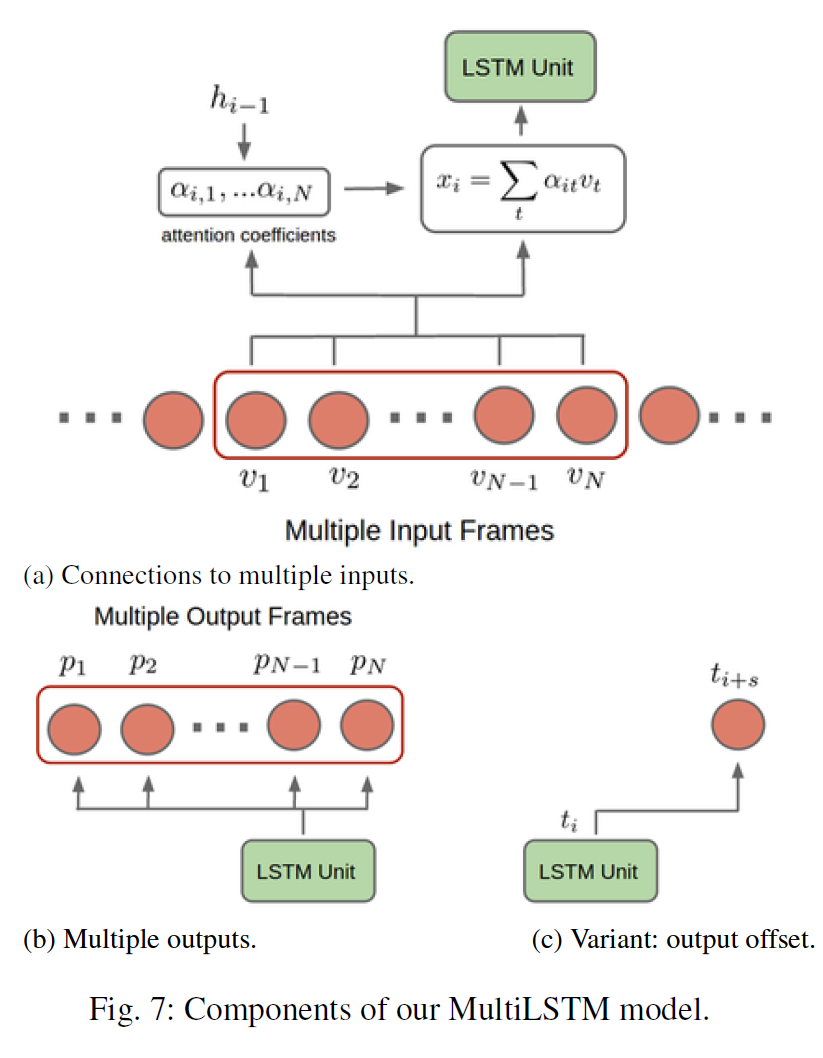
LRCN과 비슷하다.
다른 점은,
- Multiple Input: LSTM에 입력이 1개의 frame이 아니라 N개의 최근 frame에 대해 attention을 적용한다.
- Query: LSTM의 이전 hidden state $h_{i-1}$
- Key=value: $N$개의 input frame features
- Attention value: $N$개의 frame freature의 가중합
- Multiple Output: 각 LSTM cell은 $N$개의 최근 frame에 대한 예측결과를 출력한다.
Action Recognition using Visual Attention
논문 링크: Action Recognition using Visual Attention
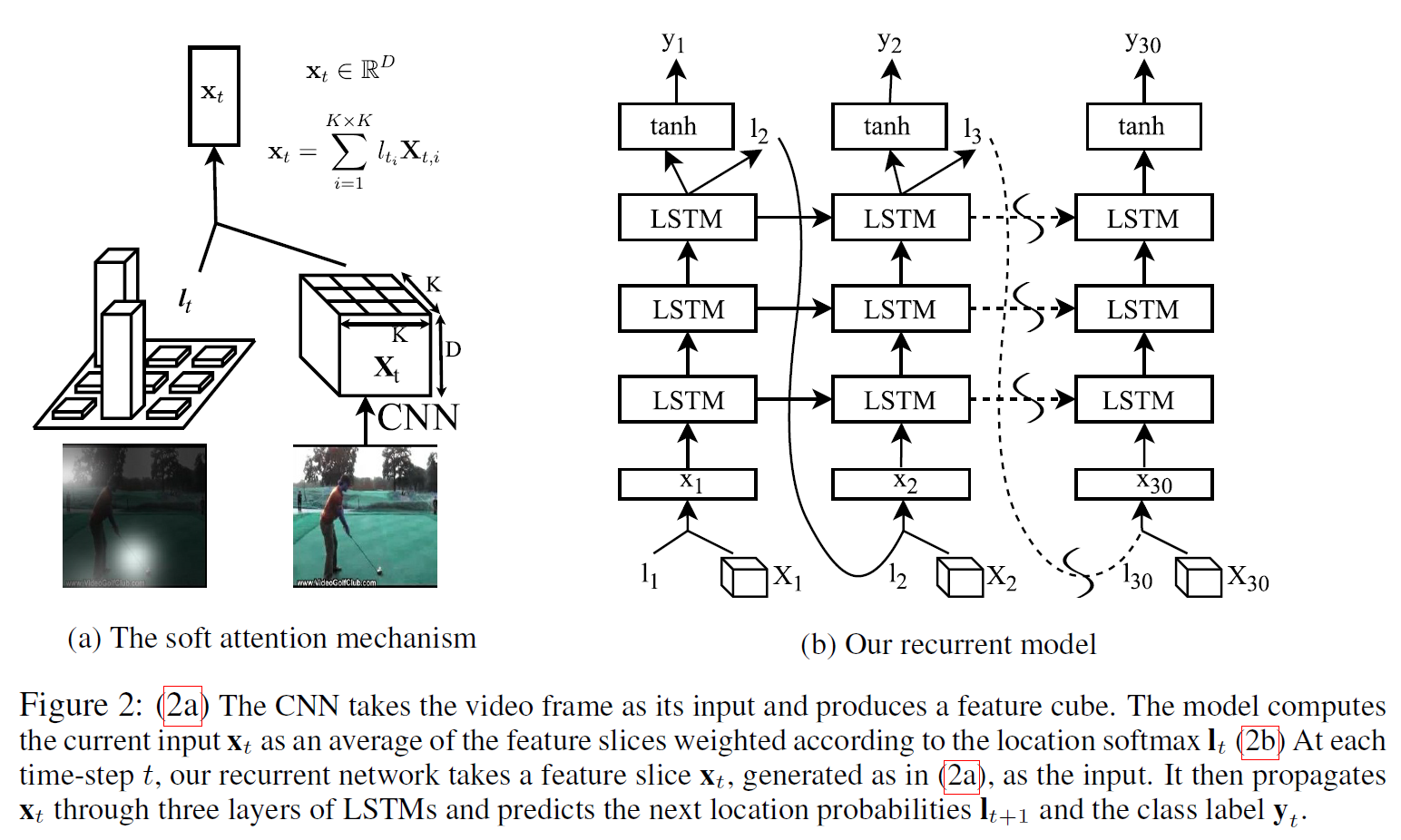
- LSTM의 이전 hidden state(=query)와 입력 이미지의 region feature(7 x 7 x 1024)를 49개의 candidate로 보고 spatial attention을 수행한다. 이를 통해 attention value(1024차원)를 얻는다.
- Query: LSTM의 직전 hidden state
- Key=Value: 입력 이미지 $X_t$의 $K \times K$의 region feature
- Attention Value: region feature의 가중합. Weight: $h_{t-1}$
이 모델의 장점은 Interpretability가 좋다(spatial attention에 의함). 정답을 맞췄을 때 어떤 부분을 보고 맞추었는지, 혹은 반대로 틀렸을때 어디를 보고 틀렸는지를 볼 수 있다(spatial attention의 의미를 생각해보면 알 수 있다).