ViT(Vision Transformer) 논문 설명(An Image is Worth 16x16 Words - Transformers for Image Recognition at Scale)
10 Dec 2021 | Transformer ViT Google Research목차
이 글에서는 ViT(Vision Transformer) 논문을 간략하게 정리한다.
ViT(An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale)
논문 링크: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Github: https://github.com/google-research/vision_transformer
- 2020년 10월, ICLR 2021
- Google Research, Brain Team
- Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, et al.
이미지 class 분류를 위해 이미지를 여러 patch로 잘라 Transformer에 넣는 방법을 제안한다.
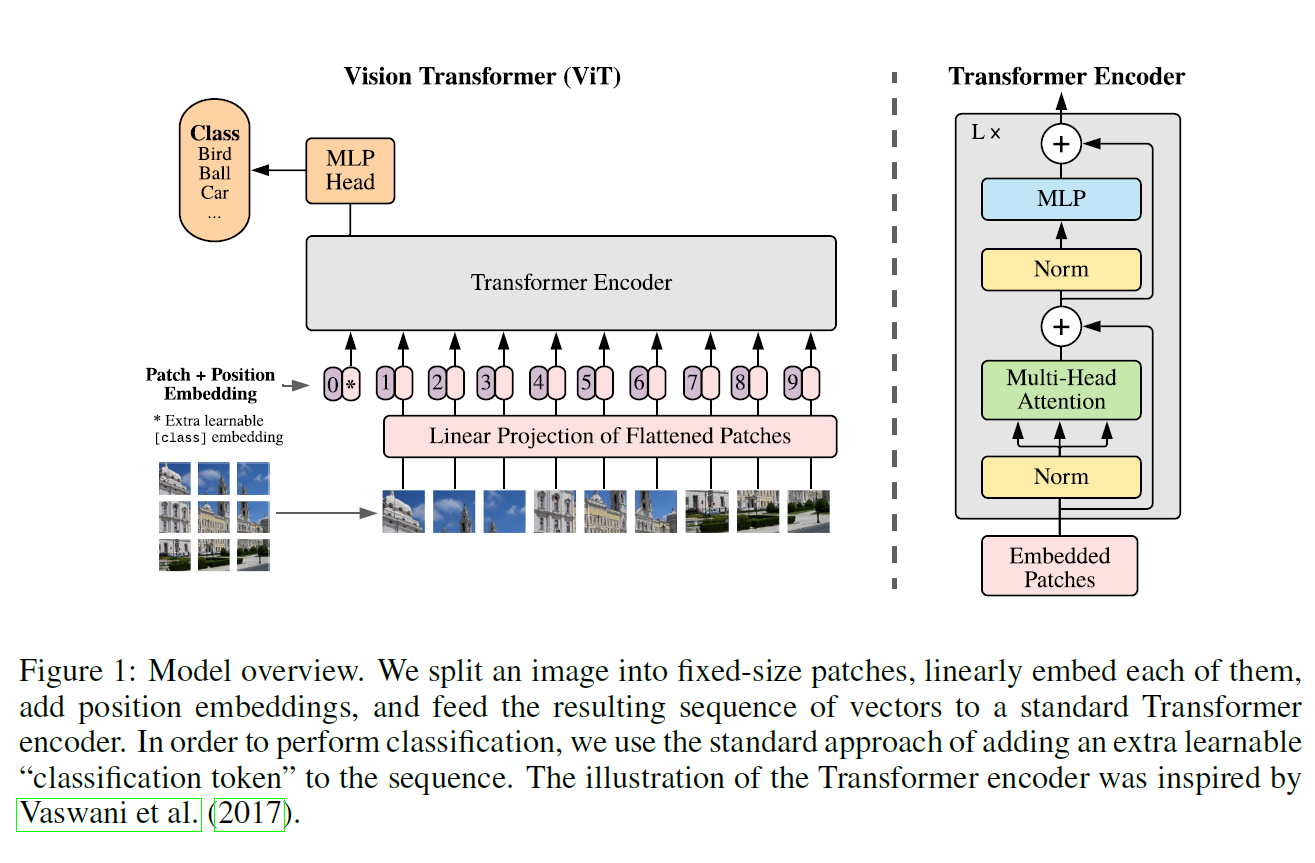
전체 구조를 순서대로 따라가보자. 왼쪽 아래에서부터 출발한다.
- 이미지를 16 x 16 크기의 patch로 나눈다. 자연어에서 word token sequence가 주어지는 것처럼, 여기서는 이미지를 16 x 16크기의 token으로 취급한다.
- 이미지 크기가 224 x 224라면 총 196($=N$)개의 patch가 생긴다.
- 이 patch들의 linear embedding을 Transformer에 입력으로 주어야 하는데, 그 전에
[CLS]token embedding이 맨 앞에 추가된다.- Linear Embedding을 구하는 것은 Linear Projection $E \in \mathbb{R}^{(P^2C)\times D}$ 를 통해 가능하다.
- 입력의 차원 변화는 $P^2C \rightarrow D$이다.
- 여기서 $C=3, D=1024$를 사용했다.
- 여기까지 보면, word를 embedding으로 바꿔서 Transformer에 입력으로 주는 것과 거의 동일한 과정이다.
- Patch Embedding에 더해 Position Embedding이란 것을 추가하는 것을 볼 수가 있다. 이는 Transformer나 BERT에서 위치 정보를 추가해 주는 것과 같은 과정이다.
- $E_{pos} \in \mathbb{R}^{(N+1)\times D}$을 곱한다. 이미지 patch 개수 $N$에
[CLS]를 더해 총 $N+1$개에 position embedding을 불인다.
- $E_{pos} \in \mathbb{R}^{(N+1)\times D}$을 곱한다. 이미지 patch 개수 $N$에
- Transformer에 이 embedding들을 태우는데 Transformer는 Norm이 맨 앞으로 온 것을 빼면 똑같은 구조를 사용한다.
- 그리고 input image를 분류하기 위해 MLP에 태운다. 이 과정을 통해 이미지 분류를 수행할 수 있다.
- MLP는 아래 식을 따른다. 여기서 MSA는 Multi-head Self-Attention이다.

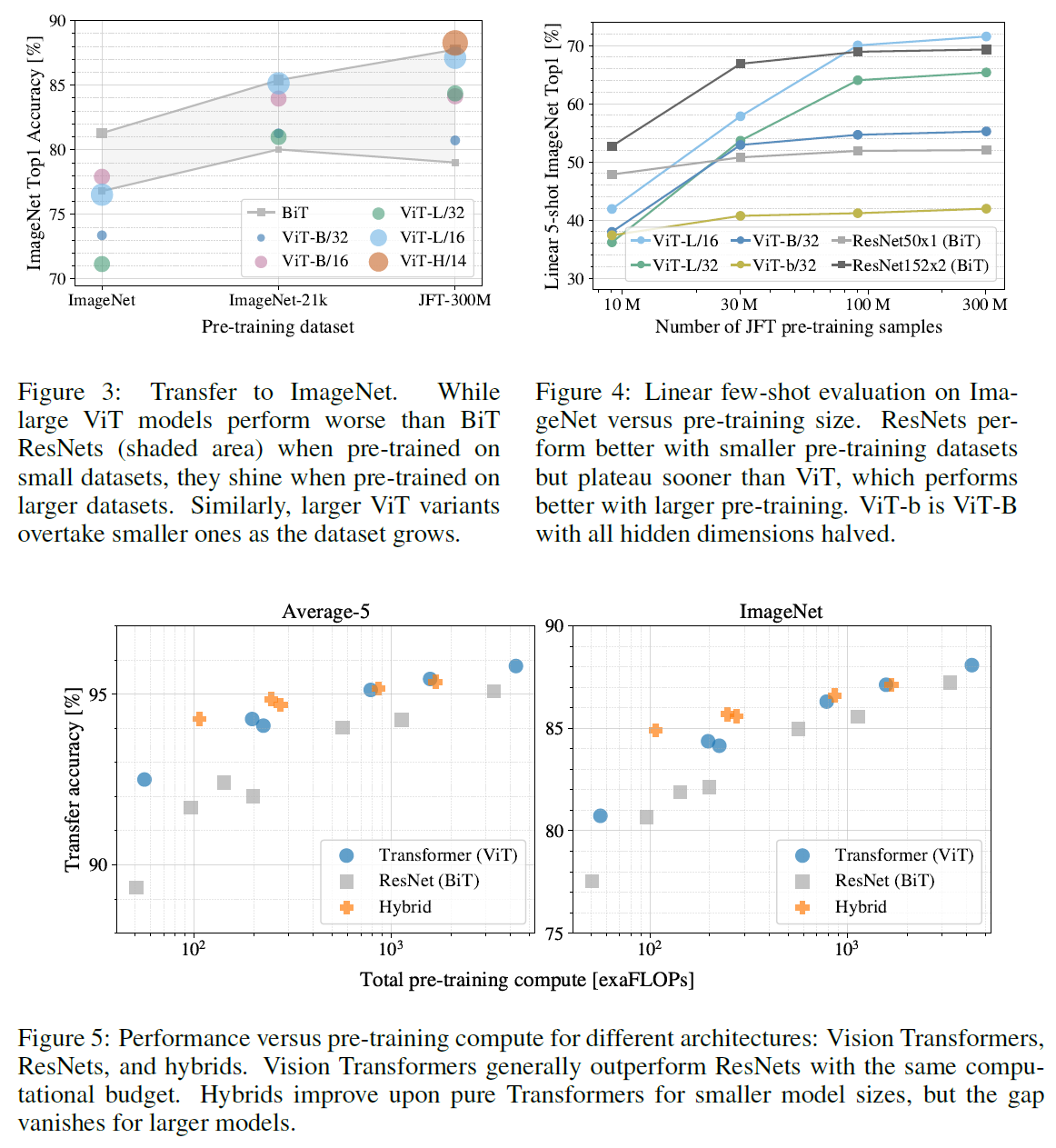
실험 결과는 다음과 갈다.
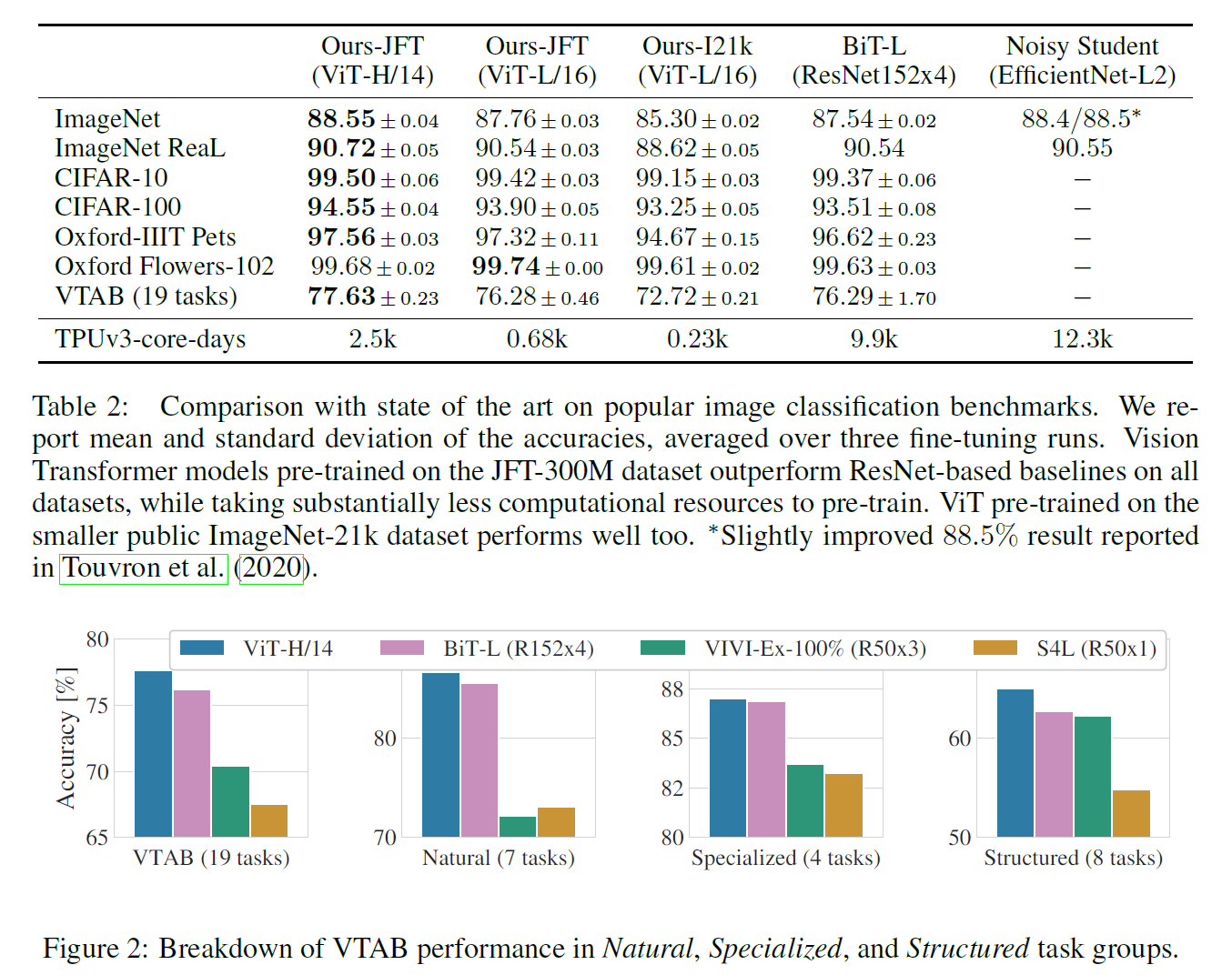
이 논문의 강점은,
- 꽤 많은 일반적인 데이터셋에서 좋은 성능을 보인다.
- Image를 Transformer에 적용시켰다는 점에서 아이디어를 높이 살 수 있다.
- 데이터가 많기만 하다면 spatial locality를 넘어 더 많은 어떤 feature를 잡아낼 수 있다.
단점은,
- 계산량이 매우 많다.
- JFT-300M과 같이 매우 큰 데이터셋에서 학습했을 때에만 잘 동작한다.
- 이미지를 patch로 잘라서 일렬로 집어넣기 때문에 spatial info(inductive bias)를 활용하지 못한다. 작은 데이터셋에서 결과가 잘 나오지 않는 이유이기도 하다.
가장 작은 데이터셋인 ImageNet에서 성능이 가장 좋지 않다는 점을 아래 결과에서 확인할 수 있다.