
BERT - Pre-training of Deep Bidirectional Transformers for Language Understanding(BERT 논문 설명)
23 Aug 2019 | Paper_Review NLP목차
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
이 글에서는 2018년 10월 Jacob Devlin 등이 발표한 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding를 살펴보도록 한다.
어쩐지 ELMo를 매우 의식한 듯한 모델명이다.
코드와 사전학습(기학습)된 모델은 여기에서 볼 수 있다.
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
논문 링크: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Pytorch code: Github: dhlee347
초록(Abstract)
이 논문에서는 새로운 언어표현모델(language representation model)인 BERT(Bidirectional Encoder Representations from Transformers)를 소개한다. 최근의 언어표현모델과는 다르게 BERT는 모든 layer의 좌우 문맥 모두에서 깊은 양방향 표현(deep bidirectional representations)를 사전학습(pre-train)하도록 설계되었다. 결과적으로 사전학습된 BERT는 QA나 언어추론 등 대부분의 과제(task)에서, 해당 과제에 특화된 모듈을 추가하지 않고 딱 하나의 추가 출력 layer만 붙여도 state-of-the-art 결과를 얻을 수 있었다.
BERT는 개념적으로 간단하고 경험적으로 강력하다. GLUE benchmark에서 7.7% 상승한 80.5%, MultiNLI에서 4.6$ 상승한 86.7%, SQuAD v1.1에서 1.5 상승한 93.2(F1 score), SQuAD v2.0에서 5.1 상승한 83.1 F1 score를 기록하였다.
1. 서론(Introduction)
언어모델 사전학습은 자연어처리 과제들에서 효과적이다. 사전학습된 언어표현을 downstream task에 적용하는 데는 두 가지 전략이 있는데
- 사전학습된 표현을 특정과제에 특화된(task-specific) 모델구조에 추가하는 특성기반 접근법(feature-based approach), 예로 ELMo가 있다.
- 특정과제에 특화된 parameter를 최소로 추가하여, 간단히 사전학습된 모든 parameter를 미세조정(fine-tune)함으로써 downstream task에서 학습하는 방법, 예로 Generative Pre-trained Transformer(OpenAI GPT)가 있다.
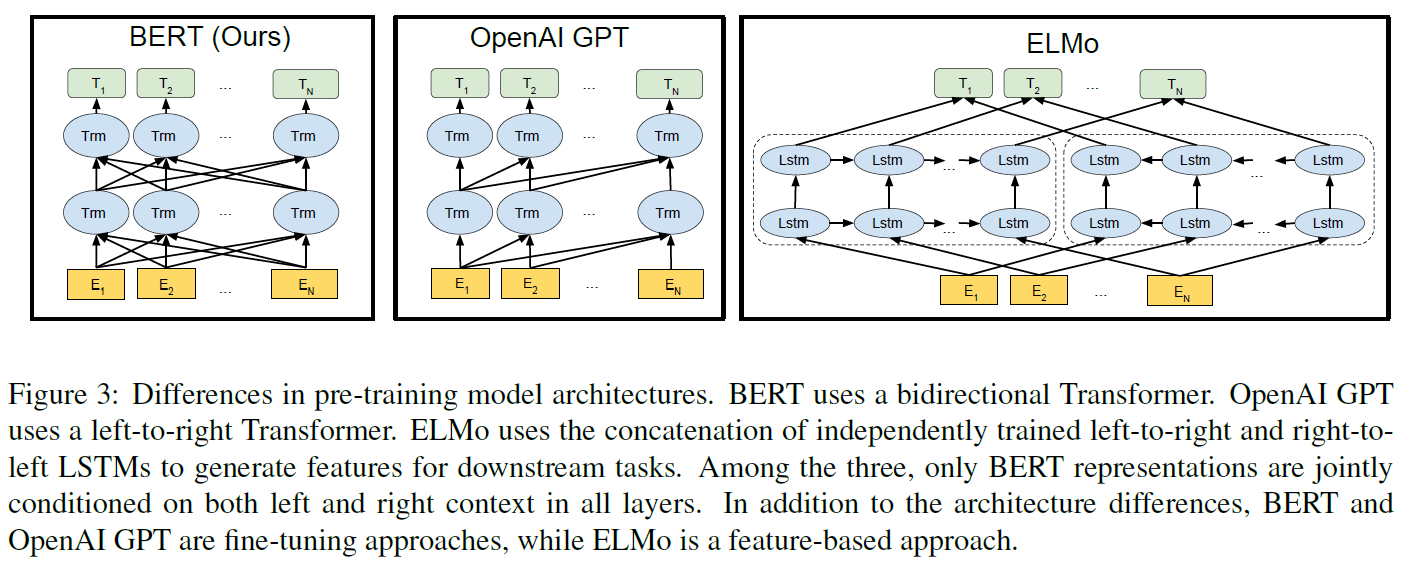
이 두 접근법은 범용언어표현을 학습하기 위해 단방향 언어모델을 사용하기 때문에 사전학습기간 동안 같은 목적함수를 공유한다.
그러나 이러한 방법은, 특히 fine-tuning 접근법은 사전학습된 표현의 능력을 제한시킨다. 가장 큰 한계는 표준언어모델은 단방향이며 이것이 사전학습하는 동안 모델구조의 선택권을 제한한다. 예로 OpenAI GPT의 경우, 좌$\rightarrow$우 구조를 사용하였는데 이는 Transformer의 self-attention layer에서 모든 token이 이전 token에만 의존하게 만든다.
이 논문에서는 fine-tuning을 기반으로 한 BERT라는 접근법을 제안한다. 이 모델은 MLM(Masked Language Model) 사전학습을 사용하여 단방향성을 제거하였다. 이는
- 입력의 일부 token을 무작위로
[mask]token으로 치환하고, 목적은 주변 문맥으로부터 마스크 처리된 단어를 유추하는 것이다. - 좌$\rightarrow$우 사전학습 언어모델과는 다르게 MLM objective는 좌/우 문맥을 결합하여 깊은 양방향(deep bidirectional) Transformer을 미리 학습시킬 수 있게 한다.
- 추가로 NSP(Next Sentence Prediction) 과제를 사용하여 문자-쌍 표현을 미리 결합학습(jointly pre-train)할 수 있게 하였다.
그래서 이 논문의 기여한 바는
- 언어표현을 위한 양방향 사전학습의 중요성을 보여주었다. 즉 deep bidirectional representation을 사전학습할 수 있다.
- 사전학습된 표현은 특정과제에 특화된 구조를 만들기 위해 조정을 계속할 필요를 줄여준다는 것을 보였다.
- 11개의 NLP 과제에서 state-of-the-art 결과를 얻어내었다.
2. 관련 연구(Related work)
범용언어표현의 사전학습 연구는 긴 역사가 있다. 간단히 살펴보자.
2.1. Unsupervised Feature-based Approaches
넓은 범위에서 사용가능한 단어의 표현을 학습시키는 것은 비신경망 모델과 신경망 모델 모두에서 많은 연구가 이러우졌다. 현대 NLP 체계에서 사전학습된 단어 embedding은 굉장한 성과를 거두었는데, 이 벡터를 학습시키기 위해서 좌$\rightarrow$우 언어모델 objective 또는 좌우 문맥으로부터 정확/부정확한 단어를 가려내는 방법 등이 사용되었다.
이러한 접근법은 문장/문단 embedding과 갈은 더 세부적인 부분으로 일반화되었다. 문장표현을 학습하기 위해서 다음 후보문장의 순위를 매기거나, 이전문장의 표현이 주어졌을 때 다음문장의 좌$\rightarrow$우 생성을 하거나, auto-encoder의 noise를 줄이는 방법 등이 사용되었다.
ELMo와 그 이전 모델들은 전통적인 단어 embedding을 다른 차원으로 일반화했다. 이들은 문맥에 민감한 특성들을 좌$\rightarrow$우 및 우$\rightarrow$좌 모델로부터 추출했다. 각 token의 문맥 표현은 좌$\rightarrow$우 및 우$\rightarrow$좌 표현의 결합으로 만들어진다.
이외 여러 모델이 있으나 전부 특정기반이며 또한 깊은 양방향 학습이 이루어지지 못했다.
2.2. Unsupervised Fine-tuning Approaches
이 방법은 미분류된(unlabeled) 문자로부터 사전학습된 단어 embedding을 얻는 것부터 시작한다.
더 최근에는, 문맥 token 표현을 생성하는 문장/문서 인코더가 미분류 문자로부터 사전학습되고 지도 downstream task에 맞춰 미세조정되었다. 이 접근법의 장점은 parameter의 수가 적다는 것이다.
OpenAI GPT는 GLUE benchmark에서 높은 성능을 기록핬다. 좌$\rightarrow$우 언어모델링과 auto-encoder objective가 이러한 모델에 사용되었다.
2.3. Transfer Learning from Supervised Data
언어추론이나 기계번역 등의 분야에서 지도가 있는 task에서 큰 dataset으로 효과적인 전이학습을 하려는 연구가 있어왔다. Computer vision 연구는 또한 ImageNet 등 사전학습된 큰 모델로부터의 전이학습이 중요함을 보였다.
3. BERT
이 framework에는 크게 두 가지 단계가 있다: pre-training(사전학습)과 fine-tuning(미세조정)이다.
pre-training 동안 모델은 다른 사전학습된 과제, 미분류된 데이터로 학습된다.
fine-tuning 동안 BERT 모델은 사전학습된 parameter로 초기화된 후, 모든 parameter가 downstream task로부터 분류된 데이터를 사용하여 미세조정된다. 각 downstream task는 그들이 같은 사전학습된 parameter로 초기화되었다 하더라도 독립된 fine-tuned 모델이다. 다음 Figure 1에 나오는 QA 예제로 설명이 이어질 것이다.
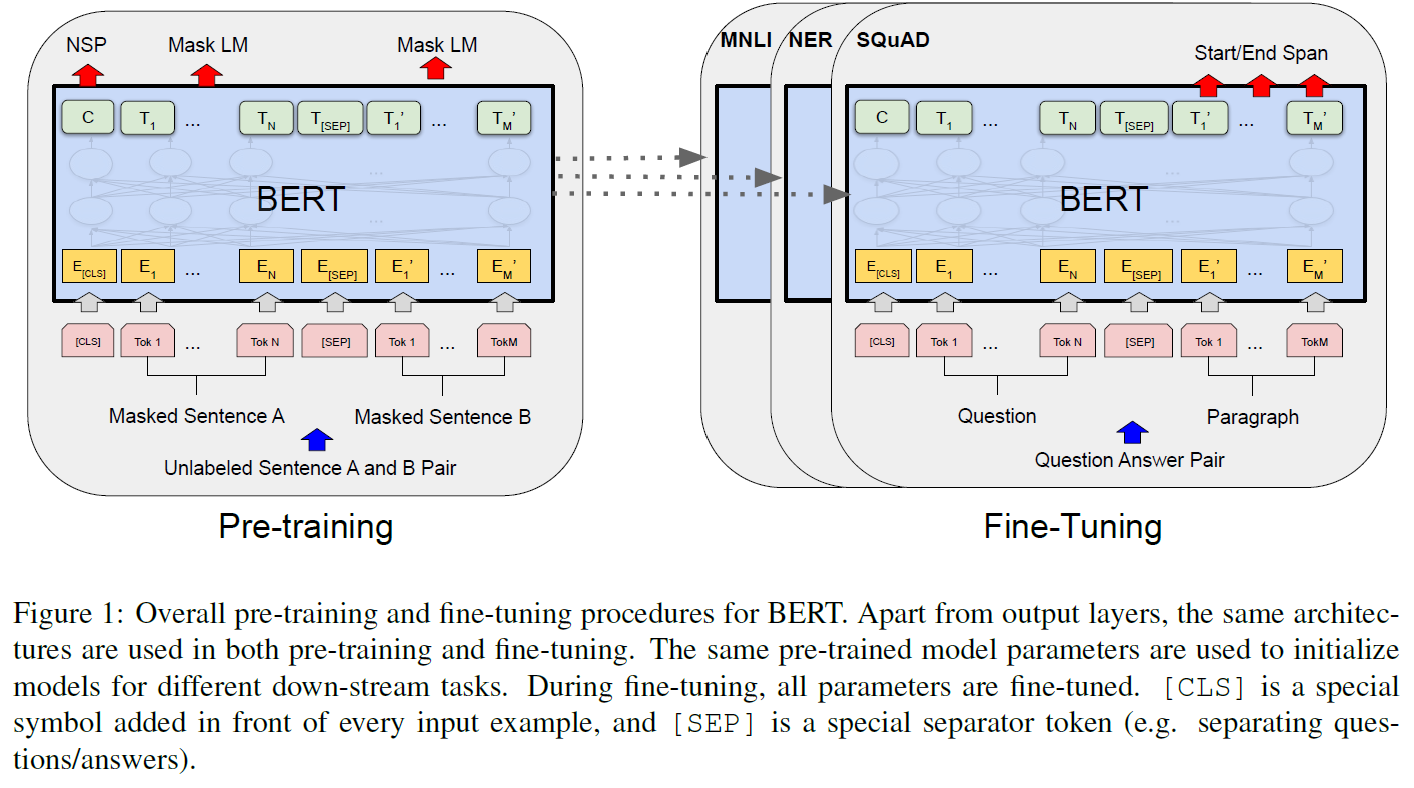
BERT의 다른 모델과 구분되는 특징은 여러 다른 과제에 대해서도 통합된 모델구조를 갖는다는 것이다. 사전학습된 모델구조와 최종 downstream 구조에는 최소한의 차이만 존재한다.
Model Architecture
BERT의 모델구조는 Attention Is All You Need의 Transformer를 기반으로 한 multi-layer bidirectional Transformer encoder이다. Transformer를 썼기 때문에 특별할 것이 없으며 그 구현은 원본과 거의 같기 때문에 자세한 설명은 생략한다. 여기에서 인코더 부분을 살펴보자.
Layer의 수를 $L$, 은닉층의 크기를 $H$, self-attention head의 수를 $A$라 한다.
BERT에는 두 가지 모델이 있는데
- BERT_base: $L=12, H=768, A=12$. 전체 parameter 수: 110M
- BERT_large: $L=24, H=1024, A=16$. 전체 parameter 수: 340M
BERT_base는 비교를 위해 OpenAI GPT와 같은 크기를 가지도록 만들었다. 그러나 BERT Transformer는 양뱡향 self-attention을 사용하고 GPT Transformer는 모든 token이 왼쪽 문맥만 참조하도록 제한된 self-attention을 사용한다.
Input/Output Representations
BERT가 다양한 downstream task를 처리할 수 있게 하기 위해, 입력표현은 단일 문장인지 문장들의 쌍(Q & A 등)인지 구분되어야 한다. 여기서 “문장”이란 실제 언어학적 문장이 아닌 인접한 문자들의 연속으로 본다. “Sequence”가 BERT의 입력 token sequence가 되는데, 이는 단일 문장이나 문장의 쌍이 될 수 있다.
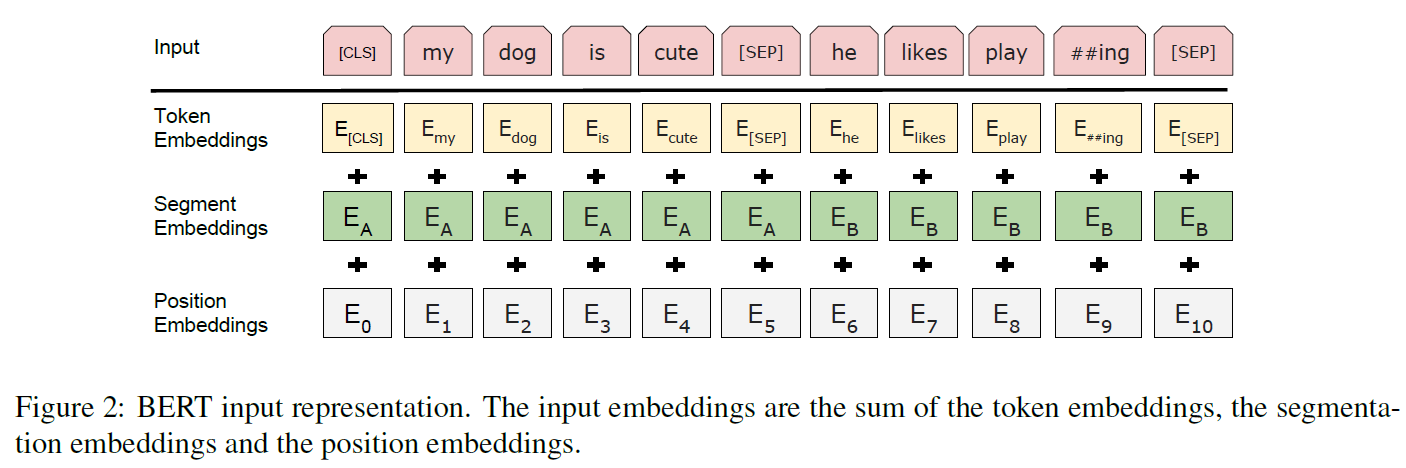
이 논문에서는 3만 개의 단어 수를 갖는 WordPiece embedding을 사용한다. 모든 sequence의 첫 번째 token은 [CLS]라는 특별한 분류 token이다. 이 token과 연관된 최종 은닉상태는 분류문제에서 sequence 표현을 총합하는 것으로 사용된다. 문장의 쌍은 한 개의 문장으로 합쳐지는데 두 가지 방법으로 구분된다:
[SEP]라는 특별한 token이 두 문장 사이에 들어간다.- 문장들의 모든 token에 해당 토큰이 문장 A에 속하는지 B에 속하는지에 대한 정보를 담은 embedding이 추가된다.
위 그림에서처럼, 입력 embedding을 $E$라 하면, [CLS] token의 최종 은닉벡터 $C$와 $i$번째 입력 token에 대한 최종 은닉벡터 $T_i$는 $C \in \mathbb{R}^H, T_i \in \mathbb{R}^H$를 만족한다.
주어진 token에 대해 그 입력표현은 연관된 token, segment, position embedding의 합으로 구성된다. 이 구조는 Figure 2에서 볼 수 있다.
3.1. Pre-training BERT
BERT를 사전학습시키기 위해 전통적인 좌$\rightarrow$우 또는 우$\rightarrow$좌 언어모델을 사용하지 않는다. 대신, 다음의 두 가지 비지도 task를 사용하여 학습시켜 놓는다.
Task #1: Masked LM
직관적으로, 깊은 양방향 모델은 좌$\rightarrow$우 모델 또는 얕은 양방향 모델보다 더 강력할 것이다. 그러나, 전통적인 언어모델은 단방향으로만 쉽게 학습가능한데, 양방향 조건은 각 단어가 간접적으로 ‘그 단어 자체’를 의미할 수 있으며, 모델은 자명하게 다층 문맥 안에서 목표 단어를 예측할 수 있기 때문이다.
양방향 모델을 학습시키기 위해 입력 token을 무작위로 masking한 다음, 문맥을 통해 해당 단어를 예측하게 한다. 문학에서 Cloze task라고도 하지만 이 과정을 MLM(masked LM)라 부르기로 한다.
이 경우, mask token과 연관된 최종 은닉벡터는 표준 LM처럼 단어집합 내 출력 softmax로 넘어간다. Denoising auto-encoder과는 다르게 전체 입력이 아닌 masked word만을 예측한다.
이것이 양방향 사전학습 모델을 얻을 수 있도록 해주지만, [mask] token은 fine-tuning 단계에 나타나지 않기 때문에 pre-training 단계와 fine-tuning 단계 간 mismatch가 생긴다는 단점이 있다. 이를 완화하기 위해, 어떤 token을 항상 [mask] token으로 바꿔버리지 않는다. 구체적으로는,
- 학습데이터 생성자는, 전체 token 중 무작위로 15%를 선택한다.
- 선정된 위치의 token은
- 80%의 확률로
[mask]token으로 치환되고, - 10%의 확률로 무작위 token으로 치환되고,
- 10%의 확률로 그대로 남는다.
- 80%의 확률로
그러면 $T_i$는 cross entropy loss로 원본 token을 예측한다. 이 과정의 변형은 부록 C.2에서 다룬다.
Task #2: Next Sentence Prediction(NSP)
QA(Question Answering)나 NLI(Natural Language Inference) 등의 많은 중요한 문제는 언어모델에는 직접적으로 포착되지 않는 두 문장 사이의 관계(relationship)를 이해하는 것에 기반한다. 문장 간 관계를 모델이 학습하도록, 아무 단일 언어 말뭉치에서 생성될 수 있는 이진화된 다음 문장 예측(binarized next sentence prediction)을 사전학습시켰다.
구체적으로, 학습 예제에서 문장 A와 B를 선택하는데,
- 학습 데이터의 50%는 A와 B가 이어지는 문장이고(
IsNext로 분류됨) - 학습 데이터의 50%는 B는 A와는 아무 관련 없는 무작위로 선택된 문장(
NotNext로 분류됨)이다.
Figure 1에 나와 있듯이 $C$는 NSP(Next Sentence Prediction)을 위해 사용된다. 이렇게 간단함에도 이 task가 QA와 NLI에 굉장히 유용함을 Section 5.1에서 보일 것이다.
이 NSP task는 표현 학습에 긴밀히 연관되어 있지만, 이전 연구에서는 오직 문장 embedding만 downstream task로 이전(transfer)이 됐는데, BERT는 end-task 모델 parameter를 초기화하기 위해 모든 parameter를 이전시킨다.
Pre-training data
사전학습 과정은 언어모델 사전학습에서 이미 있던 것을 거의 따라간다. 사전학습 말뭉치로 BooksCorpus(800M 단어)와 English Wikipedia(2,500M 단어)를 사용했다. 위키피디아에 대해서는 문자 정보만을 추출했다.
긴 연속적 seqeunce를 추출하기 위해서는, 순서가 섞인 문장들의 집합인 Billion Word Benchmark같은 것보다는 문서단위 말뭉치를 쓰는 것이 매우 중요하다.
3.2. Fine-tuning BERT
Fine-tuning 단계는 Transformer의 self-attention mechanism이 적절한 입력과 출력은 교환해냄으로써, BERT가 많은 downstream task이 문자 또는 문자 쌍을 포함함에도 이들을 모델링할 수 있게 해주기 때문에 간단하다.
문자 쌍을 포함하는 문제에 대해 일반적인 패턴은 양방향 교차 attention을 적용하기 전 문자 쌍을 독립적으로 encoding하는 것이다.
BERT는 이 두 단계를 통합하기 위해 self-attention mechanism을 사용했다. 이는 두 문장 간 양방향 교차 attention을 효과적으로 포함하는 self-attention으로 결합한 문자 쌍을 encoding하는 것으로 이루어진다.
각 task마다, task-specific한 입출력을 BERT에 연결하고 모든 parameter를 end-to-end로 미세조정(fine-tune)했다.
입력 단계에서, 사전학습에서 나온 문장 A와 문장 B는
- ‘의역에서의 문장 쌍(sentence pairs in paraphrasing)’이나
- ‘함의에서 가장-전제 쌍(hypothesis-premise pairs in entailment)’이나
- ‘질답에서 질문-지문 쌍(question-passage pairs in question answering)’이나
- ‘문서분류나 sequence tagging에서의 퇴색된 문장-공집합 쌍(a degenerate text-∅ pair in text classification or sequence tagging)’
과 유사하다.
출력 단계에서,
- token 표현은, sequence tagging이나 QA처럼, token-level task을 위한 출력층으로 넘어가고,
[CLS]표현은, 함의나 감정분석처럼, 분류를 위한 출력층으로 넘어간다.
pre-training과 비교하여, fine-tuning은 상대적이로 연산량이 적다. 이 논문의 모든 결과는 같은 사전학습된 모델로부터 시작했을 때 단일 Cloud TPU에서 최대 한 시간, GPU에서 몇 시간 정도 안에 재현될 수 있다.
실험 결과는 Section 4에, 더 자세한 것은 부록 A.5를 보면 된다.
4. 실험(Experiments)
4.1. GLUE
GLUE benchmark는 다양한 자연어이해 문제들을 모아놓은 것이다.
GLUE에 대해 미세조정하기 위해, 입력 sequence를 Section 3에서 언급한 대로 변환하고, 첫 번째 token([CLS])와 연관된 최종 은닉벡터 $C \in \mathbb{R}^H$를 총합 표현으로 사용한다. fine-tuning 단계에서 새로 도입하는 유일한 parameter는 분류 layer weights $W \in \mathbb{R}^{K \times H}$($K$는 분류의 수)이다. 이제 $C$와 $W$의 표준 분류 loss log(softmax($CW^T$))를 계산한다.
모든 GLUE task에 대해 batch size 32, 3 epochs으로 실험한 결과는 다음과 같다.
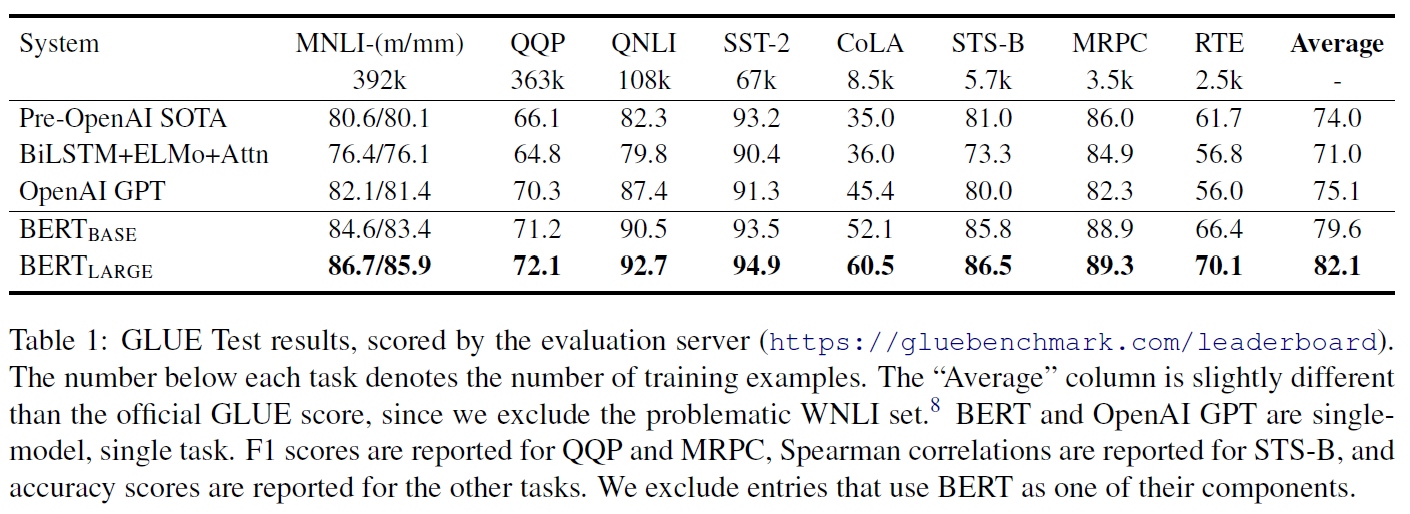
- 각 task마다 Dev set에서 최적의 learning rate를 선택했다.
- BERT_large는 작은 dataset에 대해 fine-tuning 학습이 불안정할 때가 있어서, 무작위 시작을 여러 번 하여 가장 좋은 것을 선택했다.
BERT_base만으로도 state-of-the-art 결과를 얻었으며, BERT_large는 그보다도 더 뛰어난 성능을 보여준다.
4.2. SQuAD v1.1
Stanford Question Answering Dataset은 10만여 개의 질답 쌍으로 구성되어 있다. 질문과 그에 대한 답을 포함하는 위키피디아 지문이 주어지면, 해당 지문에서 답이 되는 부분을 찾는 과제이다.
Figure 1에서 보인 것과 같이, QA task에서는 입력 질문(A)과 지문(B)을 하나의 결합된 sequence로 둔다. fine-tuning 중에 새로 추가하는 것은 시작벡터 $S \in \mathbb{R}^H$와 종료벡터 $E \in \mathbb{R}^H$ 뿐이다. 답이 지문의 $i$번째 span(단어뭉치)의 시작이 될 확률은 지문에서 다음 식으로 계산된다:
\[P_i = \frac{e^{S \cdot T_i}}{\sum_f e^{S \cdot T_i}}\]유사한 식이 span의 끝에도 사용된다. 위치 $i \sim j$의 점수는 $S \cdot T_i + E \cdot T_j$로 정의되며, $j \ge i$이면서 최대 점수를 갖는 span이 예측 결과가 된다.
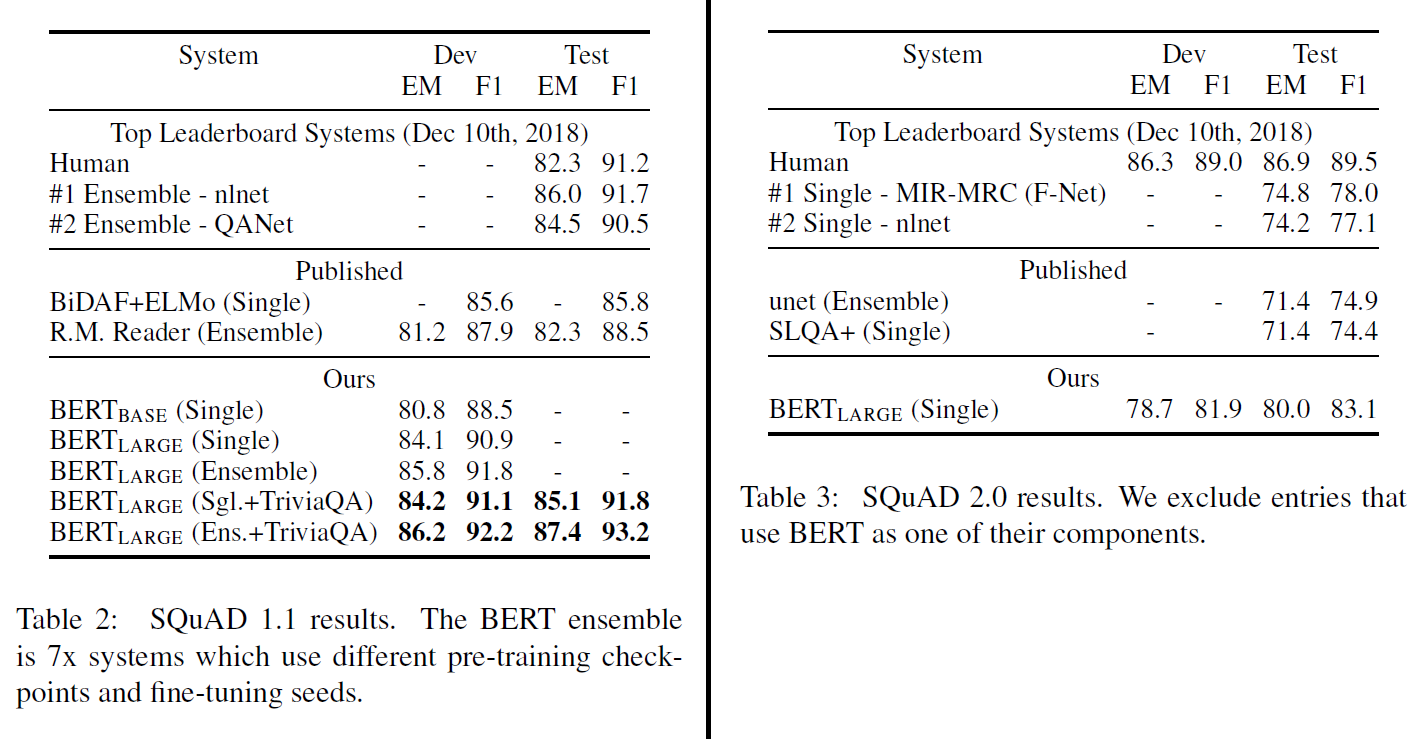
4.3. SQuAD v2.0
SQuAD v2.0은 (짧은) 답이 지문에 없는 경우를 포함시켜 더 확장한, 더 현실적인 task이다.
이를 위해 답이 없는 경우는 답이 되는 span의 시작과 끝이 [CLS]인 것으로 바꿔서 생각하는 것으로 해결한다. 이 때 점수는 다음과 같이 계산된다.
F1을 최대화하기 위해, non-null span이 답이 되려면 한계점 $\tau$에 대해 $ s_{\hat{i}, j} > s_{null} + \tau$이어야 한다.
4.4. SWAG
Situations With Adversarial Generations dataset은 113k개의 배경상식을 평가하는 문장 쌍으로 되어 있다. 이어지는 문장으로 4개 중 가장 그럴듯하게 이어지는 문장을 고르는 과제이다.
여기서도 첫 번째 문장(A)과 나머지 4개 선택지(B)로 묶어 진행하였고, 추가되는 parameter는 벡터 하나뿐인데, 이 벡터와 [CLS] token 표현 $C$와의 내적이 softmax로 정규화된 각 선택지의 점수를 나타낸다.
batch size 16, learning rate 2e^-5, 3 epochs로 진행한 결과는 다음과 같다. 역시 성능이 상당히 좋다.
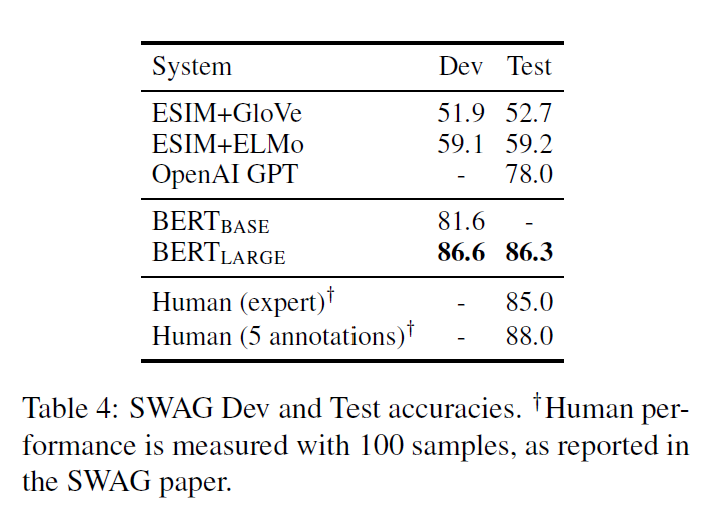
5. Ablation Studies
이 섹션에서는 특정 부분을 빼거나 교체해서 해당 부분의 역할을 알아보는 ablation 분석을 수행한다. 한국어로 번역하기 참 어려운 단어이다.
추가 연구는 부록 C에서 찾아볼 수 있다.
5.1. Effect of Pre-training Tasks
다음 두 가지 경우와 BERT_base를 비교한다: (No NSP), (LTR & No NSP).
MLM 대신 좌$\rightarrow$우(left-to-right, LTR) LM을 사용한 것으로, 이러한 제약은 pre-training뿐 아니라 fine-tuning에도 적용되었는데 두 단계 사이의 mismatch를 피하기 위해서다. 이는 같은 dataset, 입력표현, fine-tuning scheme을 사용하여 OpenAI GPT와도 직접비교가 가능하다.
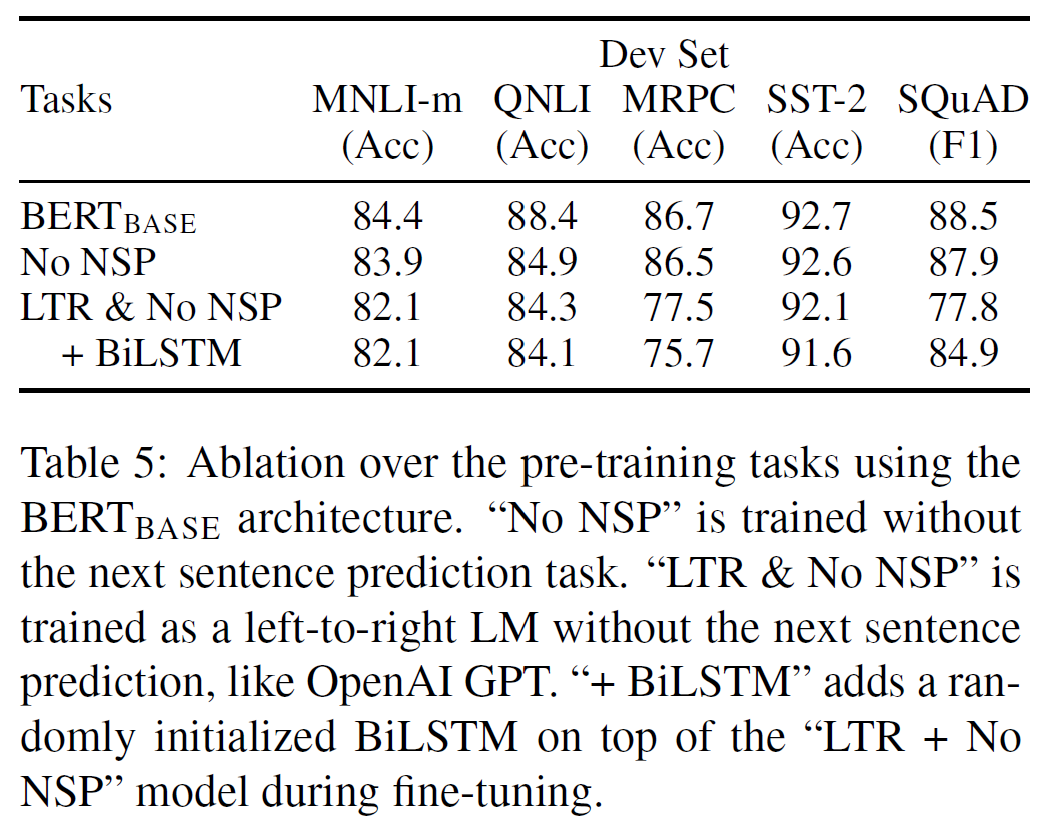
NSP를 제거했을 때에도, MLM을 LTR로 바꿨을 때에도 성능이 크게 하락함을 볼 수 있다.
직관적으로, SQuAD에서는 token-level 은닉상태가 오른쪽 문맥에 대한 정보가 없기 때문에 이러한 결과가 명백하다.
5.2. Effect of Model Size
Layer 수, hidden units, attention head 등의 hyperparameter를 각각 바꿔보면서 최적의 모델을 찾아 보았다.
일반적으로 모델 크기가 커지면 성능도 향상되는데, 이 논문에서는 충분히 사전 학습되었다는 가정 하에 극단적으로 크기를 키우는 것 또한 아주 작은 규모의 과제에서도 큰 성능 향상이 있다는 것을 첫 번째로 보여주기도 했다.
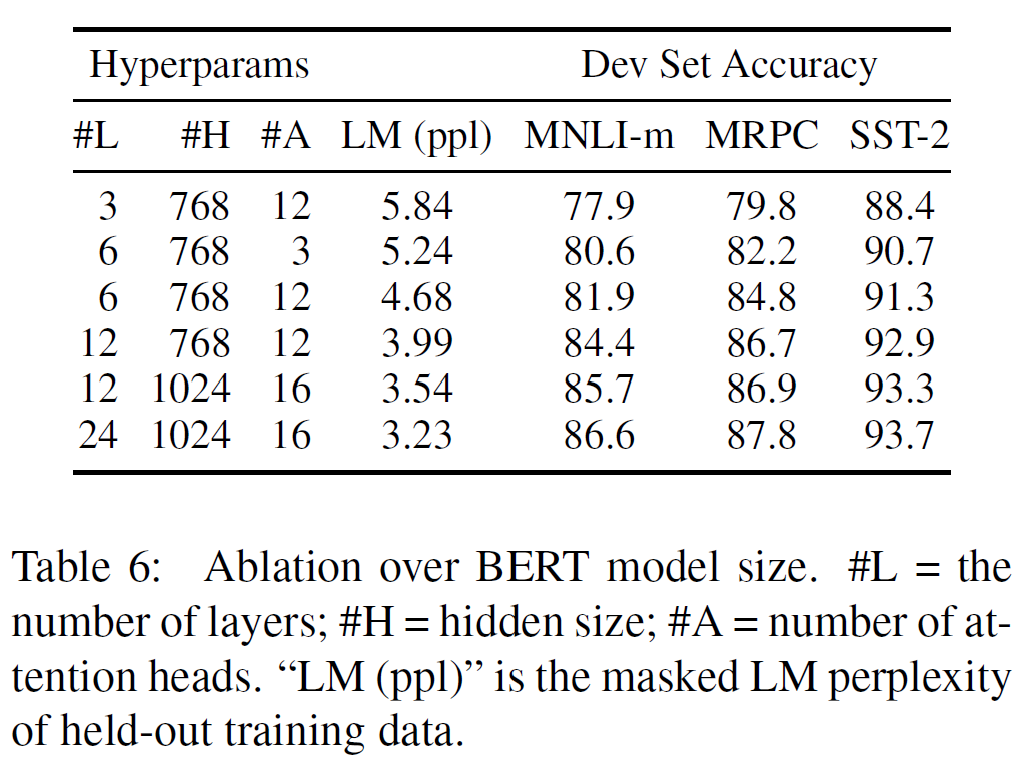
5.3. Feature-based Approach with BERT
BERT의 모든 결과는 간단한 분류 layer만 사전학습된 모델에 추가하는 fine-tuning 접근법을 사용했고, 모든 parameter는 downstream task에서 결합학습되었다.
그러나 이러한 특성기반 접근법에서, 고정된 특성이 사전학습된 모델로부터 추출될 때 특정 이점을 갖는다.
- 모든 task가 Transformer 인코더 구조로 쉽게 표현될 수 있는 것은 아니며, 따라서 특정과제에 특화된 모델구조가 추가될 필요가 있다.
- 학습데이터에 대한 한 번의 ‘비싼’ 사전 계산에 대한 연산량 관점에서의 이득이 있고 이 표현 위에서 연산량이 적은 모델에 대한 많은 실험을 진행할 수 있다.
BERT에 특성기반 접근법을 적용할 과제로는 CoNLL-2003 Named Entity Recognition(NER) task이 선정되었다. BERT에는 WordPiece 모델을 사용했고, 데이터에서 제공된 최대한의 문서 문맥을 포함시켰다.
fine-tuning 접근법을 피하기 위해, BERT의 어떤 parameter에 대해서도 fine-tuning 없이 하여 하나 또는 더 많은 layer에 대해 활성값을 추출한 특성기반 접근법을 사용하였다. 이러한 문맥 embedding은 분류 layer에 들어가기 전 무작위 초기화된 768차원 2-layer BiLSTM의 입력으로 사용되었다.
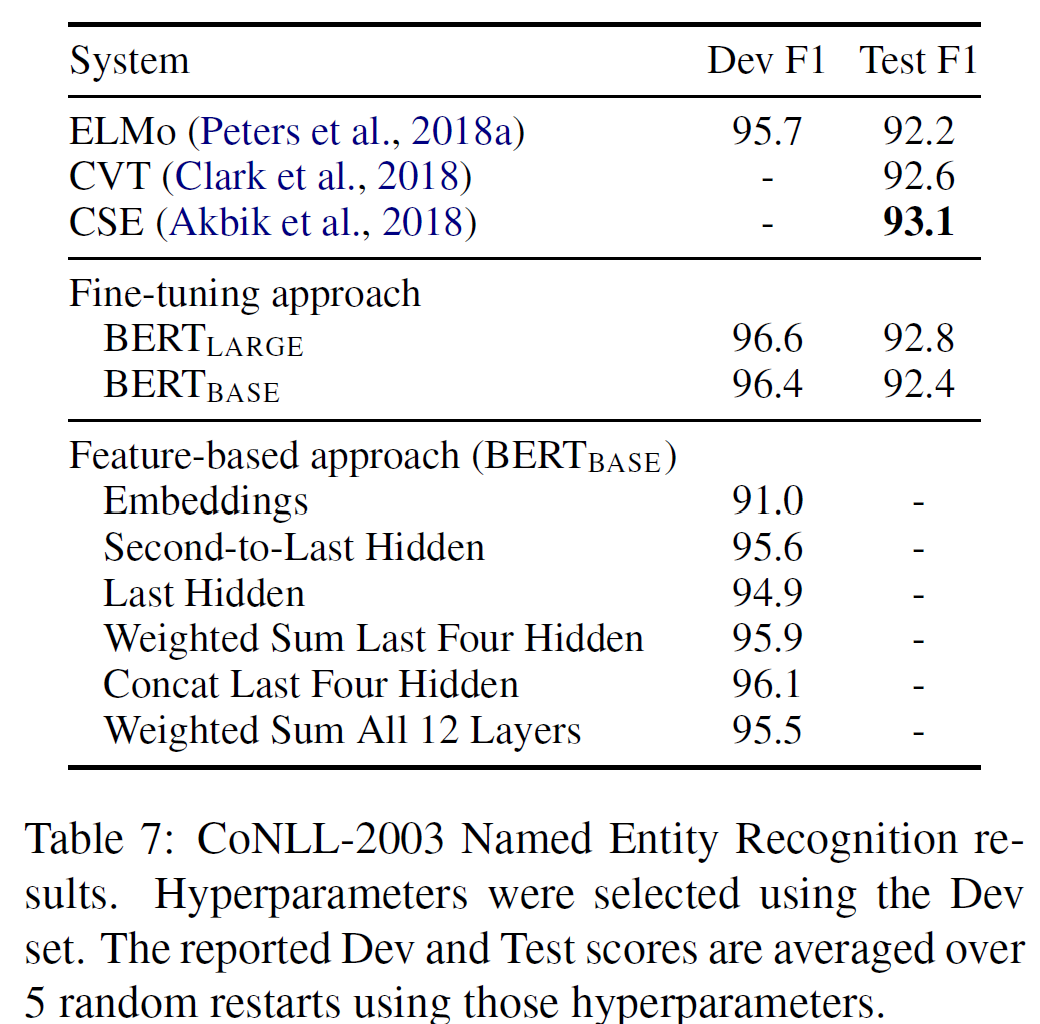
BERT_large는 거의 state-of-the-art 성능을 가지며, 이는 BERT가 미세조정과 특성기반 접근법 모두에서 효율적임을 보여준다.
6. 결론(Conclusion)
최근 경험적 향상은 언어모델에서의 전이학습, 비지도 사전학습 등에 의해 이루어졌다. 특히, 이러한 결과들은 자원이 적은 task에서도 깊은 양방향 구조에서 이점을 얻도록 하였다. 이 논문의 가장 큰 기여는 같은 사전학습된 모델을 넓은 범위의 NLP task에 적용시킬 수 있도록 하는 깊은 양방향 구조를 일반화한 것이다.
Refenrences
논문 참조. 레퍼런스가 많다.
Appendix
A. Additional Details for BERT
부록 A.1은 MLM이 어떻게 masking을 하는지, NSP는 어떤지 예시와 함께 자세히 설명한다. 예시는 다음과 같다.

부록 A.2와 A.3은 각각 pre-training 단계와 fine-tuning 단계를 부가 설명한다.
부록 A.4는 다른 모델과의 구조 차이를 설명한다.
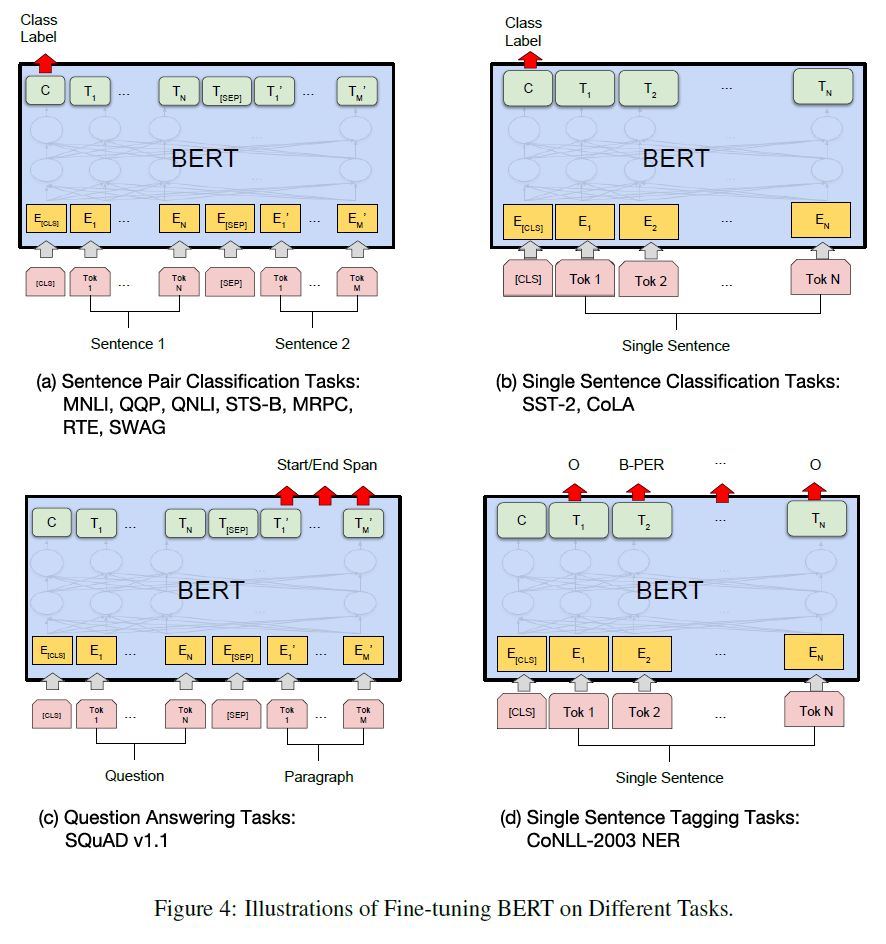
부록 A.5는 다른 task에 fine-tuning을 적용하는 방법을 설명한다. 그림으로 설명한 것은 다음과 같다.
B. Detailed Experimental Setup
부록 B.1은 GLUE benchmark에서 사용한 실험 세팅을 더 자세히 설명한다. 재현하고 싶다면 눈여겨보자.
C. Additional Ablation Studies
부록 C.1은 학습단계(Training Steps)의 수를 바꿔서 실험했다. 실험 결과는
- BERT는 엄청난 사전학습을 필요로 한다(128k words/batch * 1M steps).
- MLM 사전학습은 LTR보다 더 느리게 수렴하지만(최대 15%만이 치환되므로), 최종 정확도는 더 높다.
부록 C.2는 masking 과정을 변화시켰을 때의 실험이다.
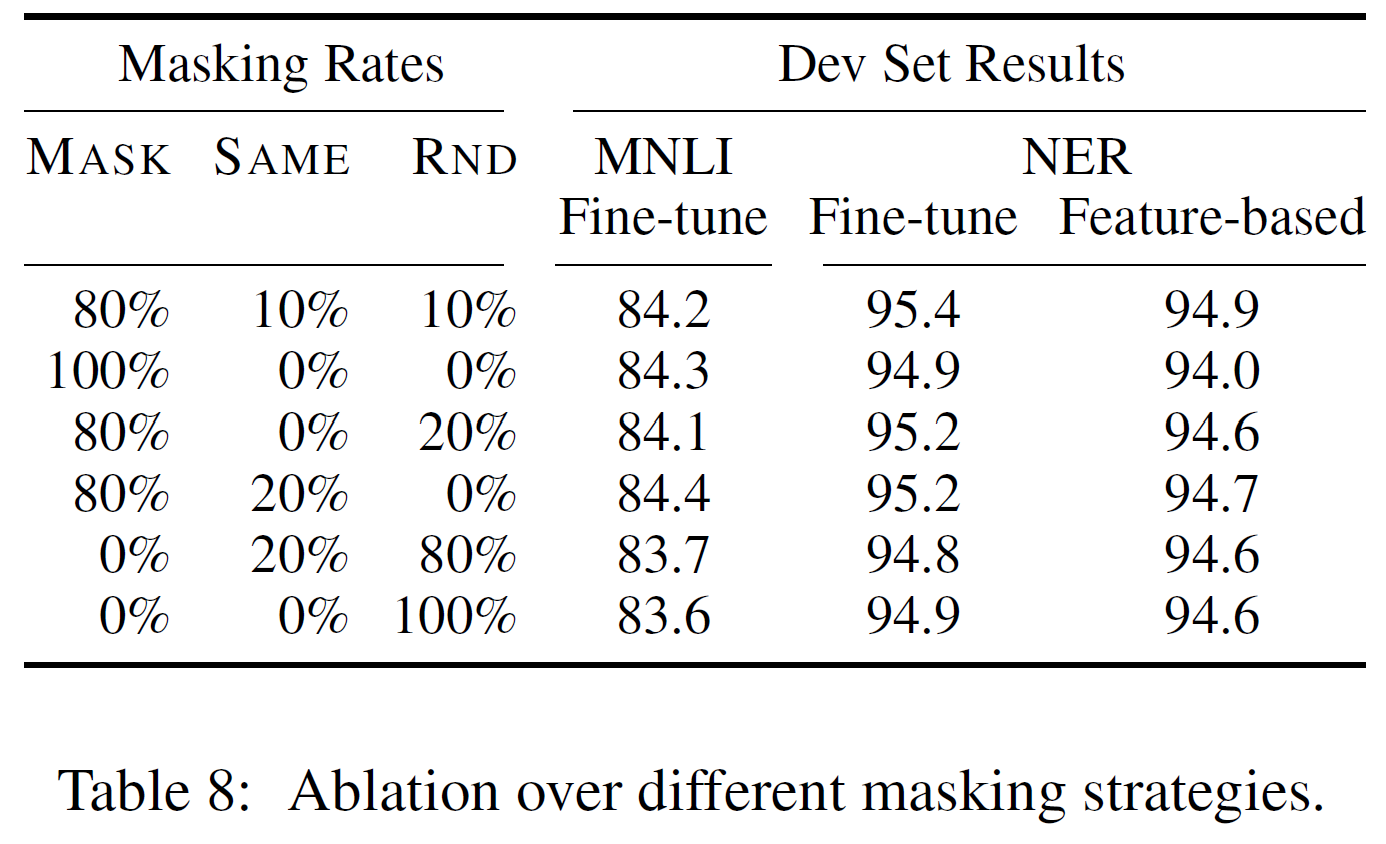
결국 처음 설명한 80%-10%-10% 비율이 가장 적절했다는 결론이다.