
VL-BERT, ViL-BERT 논문 설명(VL-BERT - Pre-training of Generic Visual-Linguistic Representations, ViLBERT - Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks)
12 Dec 2021 | Transformer ViT목차
- VL-BERT: Pre-training of Generic Visual-Linguistic Representations
- ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
이 글에서는 VL-BERT와 ViLBERT 논문을 간략하게 정리한다.
VL-BERT: Pre-training of Generic Visual-Linguistic Representations
논문 링크: VL-BERT: Pre-training of Generic Visual-Linguistic Representations
Github: https://github.com/jackroos/VL-BERT
- 2020년 2월(Arxiv), ICLR 2020
- University of Science and Technology of China, Microsoft Research Asia
- Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, Jifeng Dai
Visual-Language BERT로, Visual info와 Language info를 BERT에다가 넣는 방법론을 제시한다.
- 학습 샘플은 image + 이미지를 설명하는 sentence 쌍으로 이루어진다.
- VQA task에 대해서는 2개의 문장(question, answer)이다.
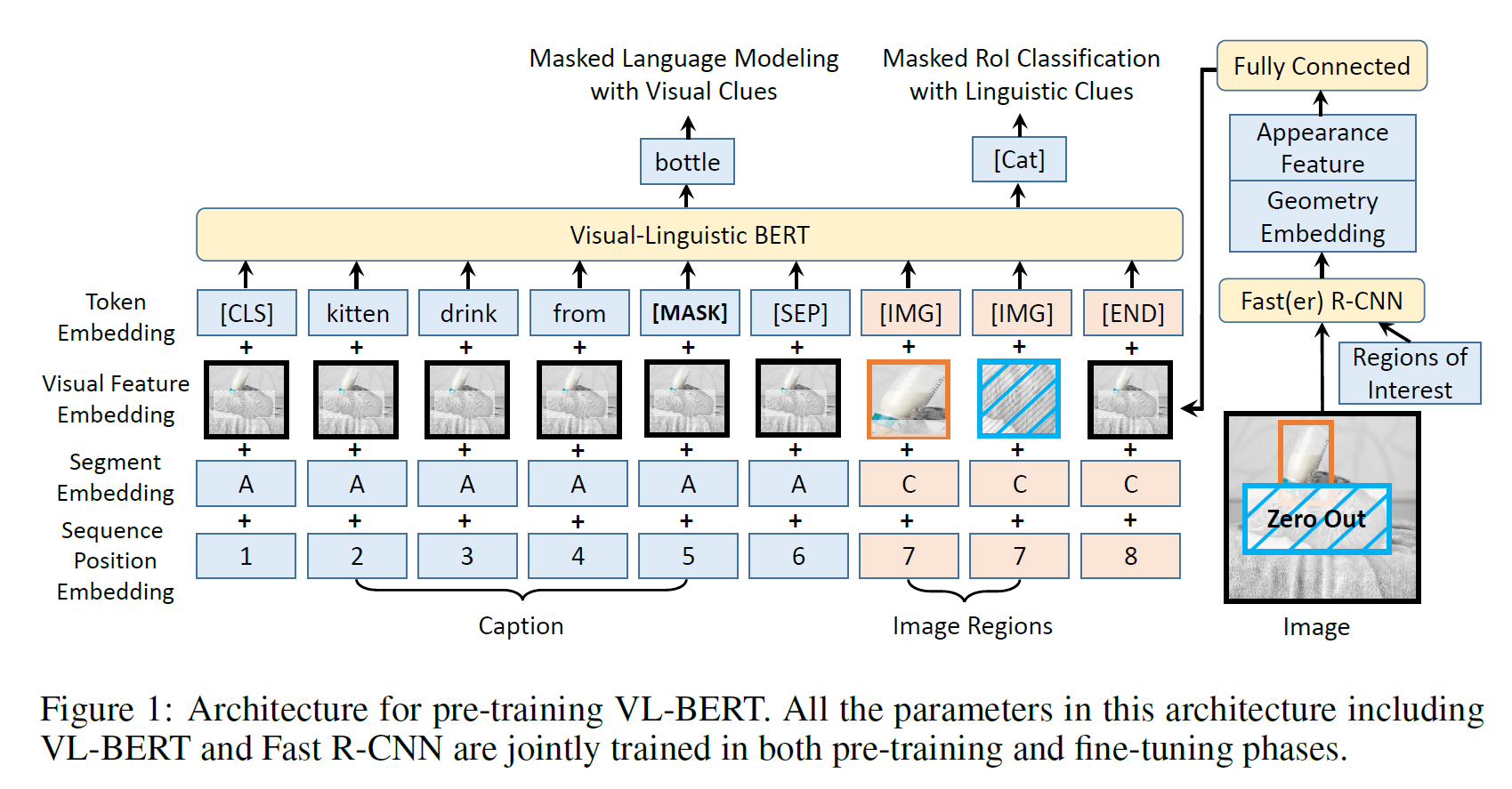
BERT와 굉장히 유사하다. Langauge 쪽은 거의 똑갈다고 보면 된다.
왼쪽의 파란색 부분을 텍스트 부분, 중간~오른쪽의 붉은색 부분을 이미지 부분이라 하자.
다른 점은
- Visual Feature Embedding이 새로 추가가 되었다.
- 텍스트 부분에서는 이미지 전체를 visual feature embedding으로 만들어 넣는다.
- 이미지 부분에서는 detect된 object들을 하나하나 embedding으로 만들어 넣는다.
- BERT의 2번째 문장 대신
[IMG]token을 사용한다. - 마지막에
[END]token이 추가되었다. - Segment Embedding은 텍스트의 경우
A, 이미지의 경우C로 넣는다. - 이미지 부분의 Sequence Position Embedding은 딱히 순서가 없으므로 똑같은 값을 넣는다. (위 예시에서는 image region은
7의 값을 갖는다)
Pre-training task는 MLM과 비슷한 task를 진행하는데,
- 텍스트에 대해서는 MLM과 같다. 단, MLM with Visual clues라고 이름 붙였는데, 텍스트만 있는 게 아니라 이미지 정보를 같이 사용하여 예측하기 때문이다.
- Object detect를 할 때 Faster-RCNN으로 뽑아내는데, 이 때 object class가 나온다. 이를 Ground Truth로 사용하여, 특정 object 부분이 가려졌을 때, 이미지의 나머지 부분 + 텍스트 정보를 갖고 이 class를 예측하는 task를 수행할 수 있다. 이는 Masked RoI Classification with Linguistic Clues라 부른다.
VQA에 대해서 학습할 때도 거의 갈은데, Question에는 Mask를 씌우지 않고 대신 Answer에만 masking을 수행한다. 그러면 주어진 Question에 대해 답을 맞추는 것과 같아진다.
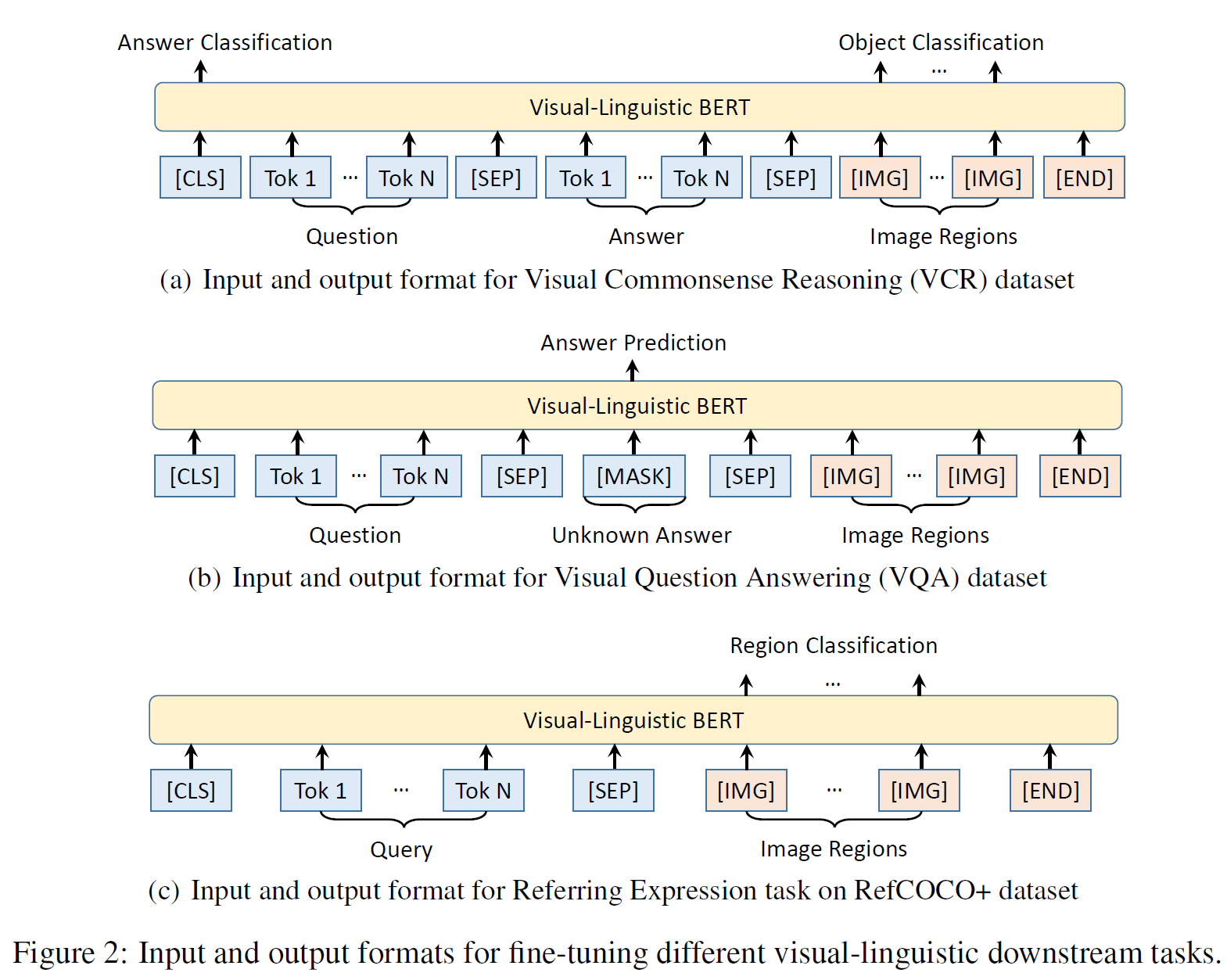
위 그림에서는 VQA 말고도 다른 downstream task에서 input/output의 형태를 나타내고 있다.
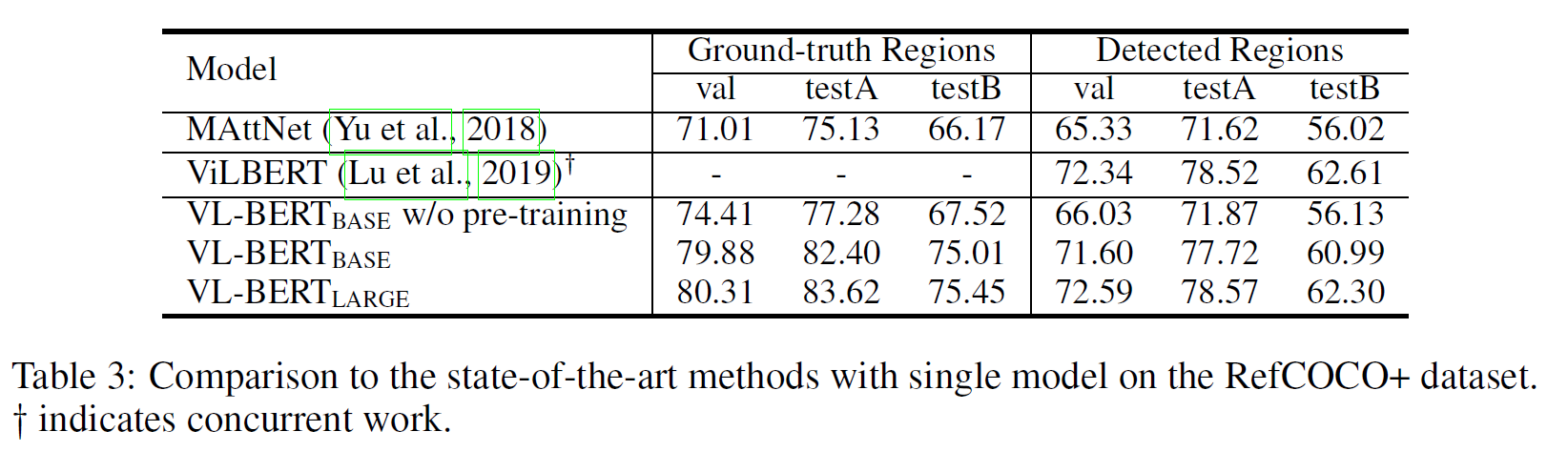
VCR, VQA, Reffering Expression Comprehension) downstream task에 대한 결과는 아래와 같다.
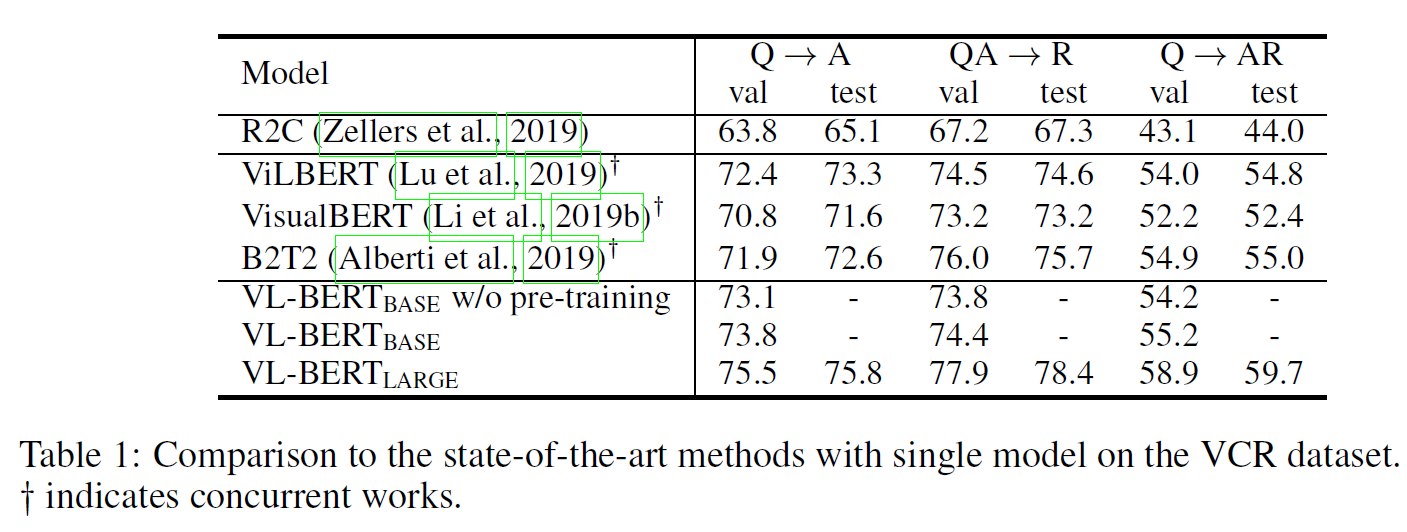
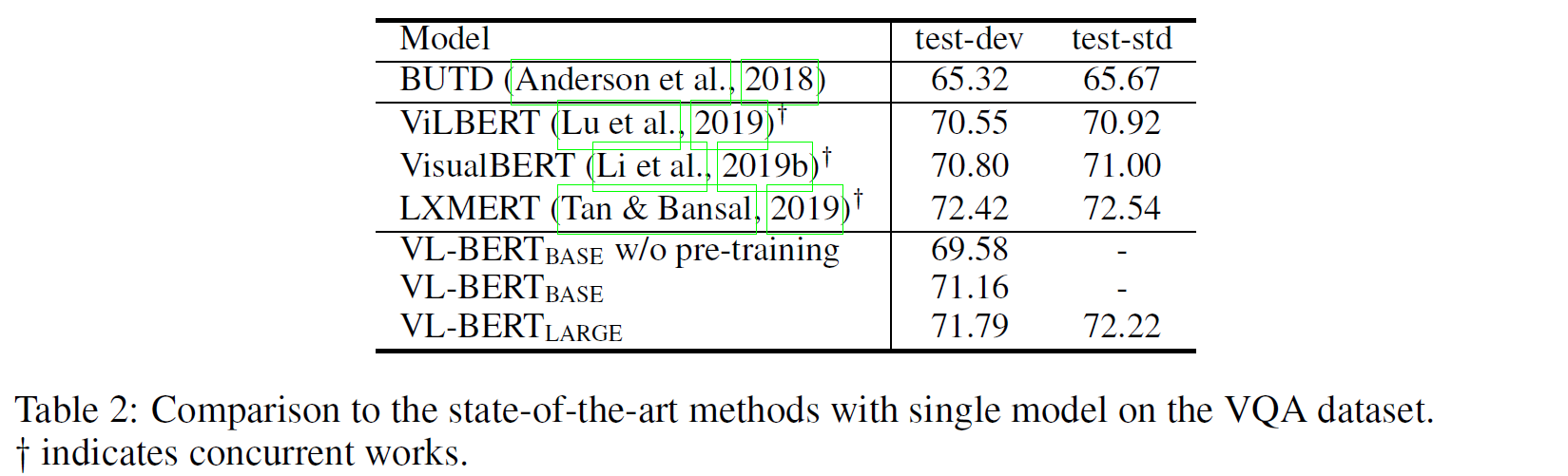
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
논문 링크: ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
Github: https://github.com/facebookresearch/vilbert-multi-task
- 2019년 8월(Arxiv), NIPS 2020
- Georgia Institute of Technology, Facebook AI Research, Oregon State University
- Jiasen Lu, Dhruv Batra, Devi Parikh, Stefan Lee
위의 VL-BERT와 거의 같은 방식인데(이름도 비슷하다), Cross-modal Attention을 썼다는 점이 가장 중요한 차이이다.
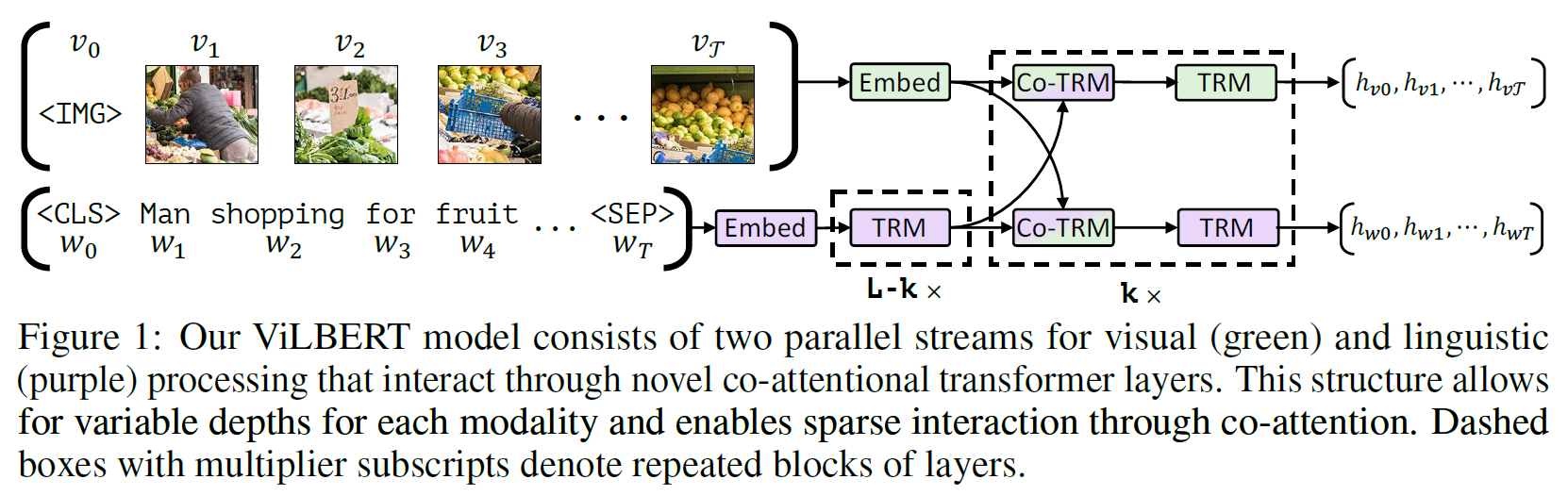
참고로 TRM은 Transformer이다.
TRM은 원래의 것과 같고, Co-TRM이 Co-attention Transformer이다. 아래 그림에서 그 차이를 볼 수 있다.
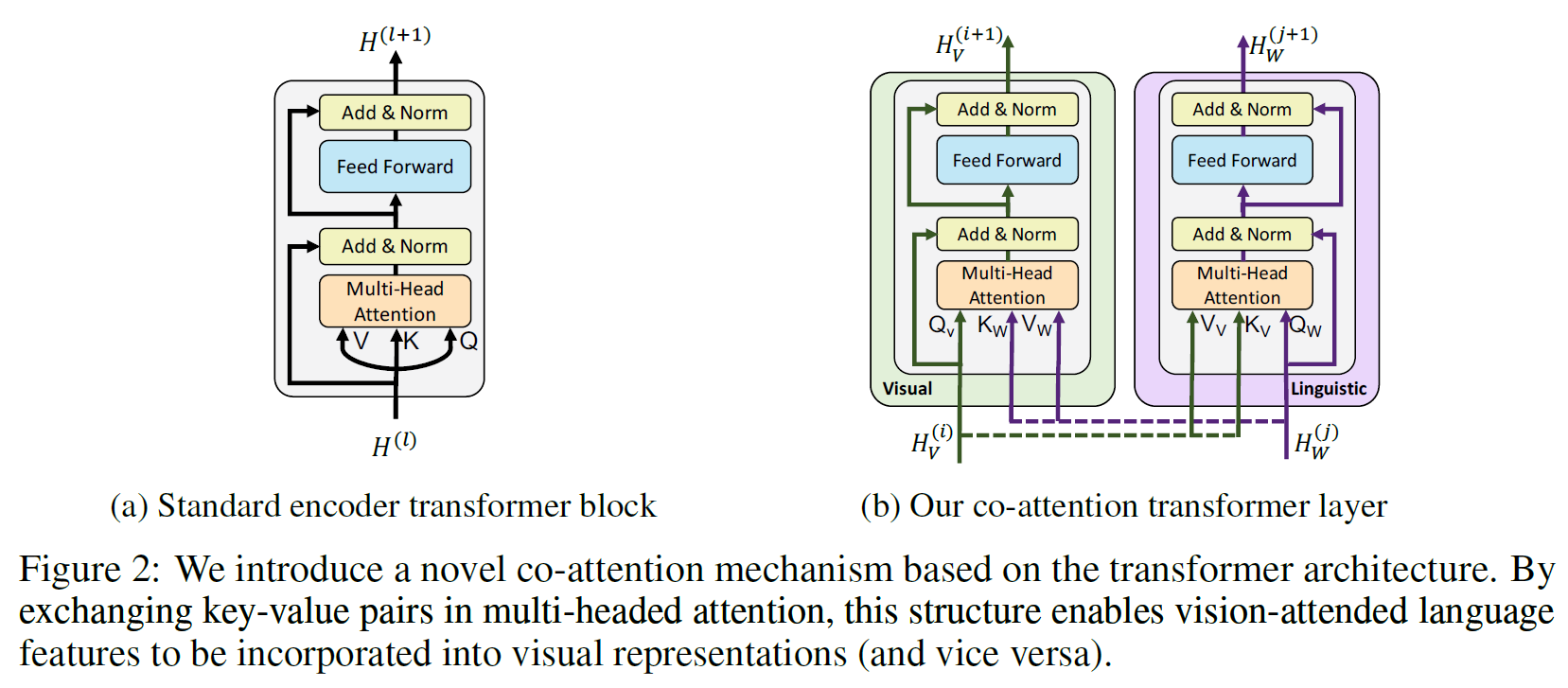
Co-TRM을 보면 왼쪽의 Co-TRM에서는 Q를 Visual 쪽에서, K와 V는 Language 쪽에서 받는다.
반대로, 오른쪽 Co-TRM에서는 Q를 Language 쪽에서, K와 V는 Visual 쪽에서 받는다.
Training task로는 BERT의 MLM과 NSP와 거의 비슷하다.
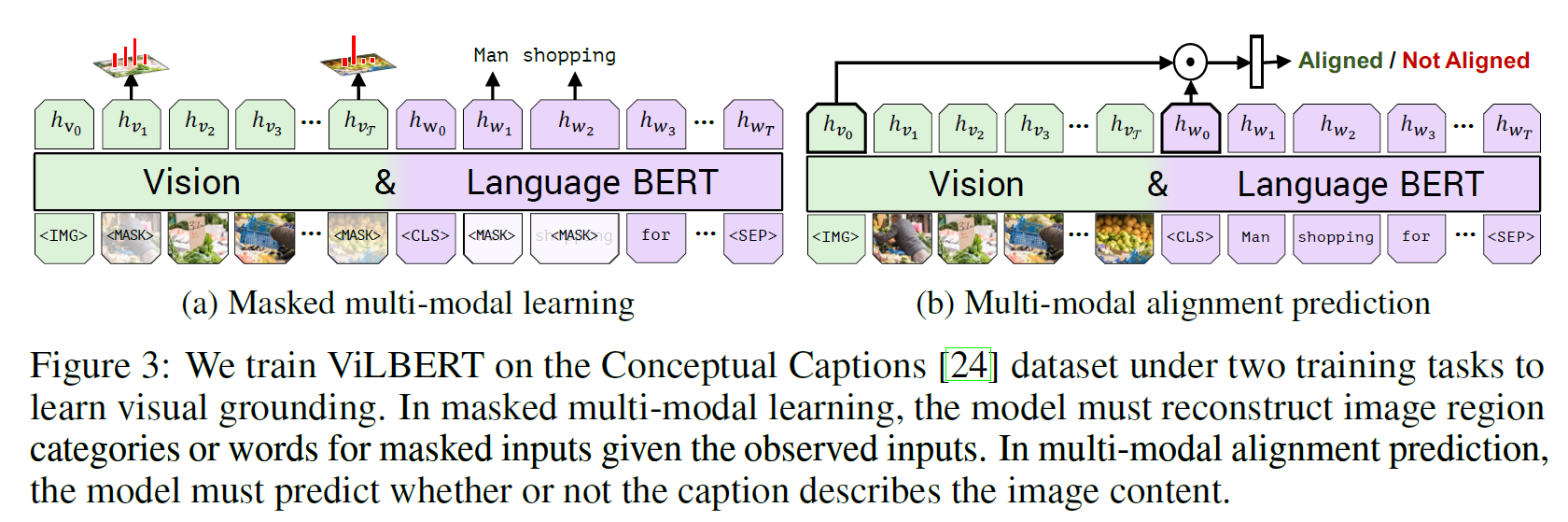
- Masked multi-modal learning(MLM과 비슷함): image region에 대해 semantic classes의 distribution을 예측한다. Faster-RCNN의 예측 결과가 GT로 사용된다(이 부분은 VL-BERT의 것과 같다).
- 텍스트 부분은 MLM과 같다.
- Multi-modal alignment prediction(NSP와 비슷함): 모델은 (image, text) 쌍을 입력으로 받아 여러 image patch를 추출한다. 텍스트의 각 부분과 이미지의 각 부분이 연관이 있는지(aligned / not aligned)를 예측한다. 이 task가 상당히 강력하다고 한다.
VQA, VCR, Grounding Referring Expressions, Caption-Based Image Retrieval, ‘Zero-shot’ Caption-Based Image Retrieval 등에 대해 실험을 진행하였고 결과는 아래와 같다. 비교한 모든 부분에서 성능이 제일 좋다고 한다.
