
StyleCLIP 논문 리뷰(StyleCLIP - Text-Driven Manipulation of StyleGAN Imagery)
24 Dec 2021 | Multimodal OpenAI목차
이 글에서는 2021년 3월 발표된 StyleCLIP 논문을 간략하게 정리한다.
CLIP
논문 링크: StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
Github: https://github.com/orpatashnik/StyleCLIP
- 2021년 3월(Arxiv), ICCV 2021
- Hebrew University of Jerusalem, Tel-Aviv University, Adobe Research
- Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, Dani Lischinski
StyleGAN + CLIP이라고 보면 된다.

Abstract
다양한 도메인에서 고해상도의 이미지를 생성할 수 있는 StyleGAN의 능력에 힘입어 어떻게 StyleGAN의 latent space에 대해 이해하고 다룰 수 있는지 연구가 많았으나 사람이 직접 공들여 manipulation을 수행해야 했다.
이 논문에서는 총 3가지 방법을 제시하는데,
- CLIP에다가 StyleGAN을 접목시켜 사용자가 제공한(user-provided) text prompt의 응답으로 input latent vector를 수정하여 CLIP based loss를 쓰는 최적화 기법을 소개한다.
- 다음으로 주어진 input image에 대해 text-guided latent manipulation을 암시하는 latent mapper를 제안하여 더 빠르고 안정적인 manipulation을 가능하게 한다.
- 마지막으로 text prompt를 StyleGAN의 style space로 보내는 입력과 무관한 mapping 방법을 제안하여, 이는 text-driven image manipulation이 가능하게 한다.
1. Introduction
GAN 이후 StyleGAN이 굉장히 유명하다. (이후 StyleGAN2과 StyleGAN-Ada 등도 나왔음) StyleGAN에서 manipulation을 특히 파고든 논문으로는 StyleRig, StyleFlow 등이 있다.
그러나 지금까지의 연구에서 control은 오직 (이미 존재하는) preset semantic 방향으로만 제한적으로 가능해서 창조적으로 혹은 상상력, 창작으로 만들었다고는 보기 어려웠다.
이 논문에서는 StyleGAN과 CLIP을 사용하여 이 문제를 해결해보고자 한다.
방법론으로 총 3가지를 제시한다. (초록과 같은 내용)
- Text-Guided latent optimization. CLIP 모델은 loss network로 사용된다. 이 방법은 제일 다목적인 방법이지만, 각 이미지에 최적화를 적용하는 데 분 단위의 시간이 걸린다.
- A latent residual mapper. 특정 text prompt에 학습된다. latent space에서 시작점이 주어지면(ex. manipulate할 이미지), mapper는 latent space에서 local step을 반환한다.
- mapping a text prompt into an input-agnostic (global) direction in StyleGAN’s style space. 말 그대로 StyleGAN의 style space에서 입력과 무관하게 global direction만큼 이동하는 방법인데, 이는 disentanglement 차원만큼이나 강력한 manipulation control을 제공한다.
2. Related Work
2.1. Vision and Language
Joint representations
Vision + Language Multimodal 연구는 최근 활발히 진행되고 있다. BERT의 성공에 힘입어 이를 vision 분야에도 적용시키는 등 Transformer도 많이 사용되고 있다. CLIP 등.
Text-guided image generation and manipulation
특정 텍스트를 주고 이에 기반하여 이미지를 생성하거나 변화시키는 분야이며 GAN이 주축이다.
- GAN, AttnGAN, StyleGAN
- Dall-E, TediGAN 등
2.2. Latent Space Image Manipulation
많은 연구들은 image manipulation을 위해 사전학습된 generator의 latent space를 어떻게 다룰지를 탐구해 왔다.
대부분의 연구들이 $\mathcal{W}$나 $\mathcal{W}+$ space에서 image manipulation을 수행했으나, Wu et al.에서는 Style space $\mathcal{S}$에서 수행하는 것이 더 나은 disentanglement를 제공하는 것을 밝혔다.
3. StyleCLIP Text-Driven Manipulation
초록 및 서론에서 제시한 3가지 방법론에 대한 간단한 설명이 있다. 아래 표가 대략 어떤 방법인지 나타내 주고 있다.

4. Latent Optimization
제시한 방법론 중 첫 번째에 대한 내용이다.
StyleGAN의 $\mathcal{W+}$ space에 있는 이미지의 latent code가 주어지면 CLIP space에서 계산되는 loss를 최소화하는 간단한 latent optimization 방법이다. 최적화는 각 (source image, text prompte) 쌍에 대해 수행된다.
그래서 이 방법은 여러 곳에 사용될 수 있는 다목적성을 가지지만 매번 최적화를 해주는 시간이 필요하며(분 단위) contol하기 어렵다는 단점이 있다.
source latent code $w_s \in \mathcal{W}+$와 자연어 지시문 혹은 text prompt $t$가 주어지면 다음 최적화 문제를 푸는 것이다:
\[\argmin_{w \in \mathcal{W}+} D_{\text{CLIP}}(G(w), t) + \lambda_{L2} \Vert w - w_s \Vert_2 + \lambda_{\text{ID}} \mathcal{L}_{\text{ID}}(w) \quad (1)\]- $G$는 사전학습된 StyleGAN generator
- $D_{\text{CLIP}}$는 CLIP embedding의 2개의 argument 사이의 cosine 거리이다.
입력 이미지의 유사도는 latent space의 $L_2$ distance에 의해 조절되며, identity loss는:
\[\mathcal{L}_{\text{ID}}(w) = 1 - <R(G(w_s)), R(G(w))> \quad (2)\]- $R$은 얼굴인식을 위해 사전학습된 ArcFace network
- $<\cdot . \cdot >$는 cosine 유사도이다.
Gradient descent로 이 최적화 문제를 푼다. 목적함수는 $(1)$ 식을 쓴다. $G$는 고정(fixed)이다.
이 방법으로 수정한 이미지 예시는 아래와 같다. 최적화 과정은 200~300회 반복하였다.

이미지 아래의 숫자는 설명대로 $(\lambda_{\text{L2}}, \lambda_{\text{ID}})$이다.
5. Latent Mapper
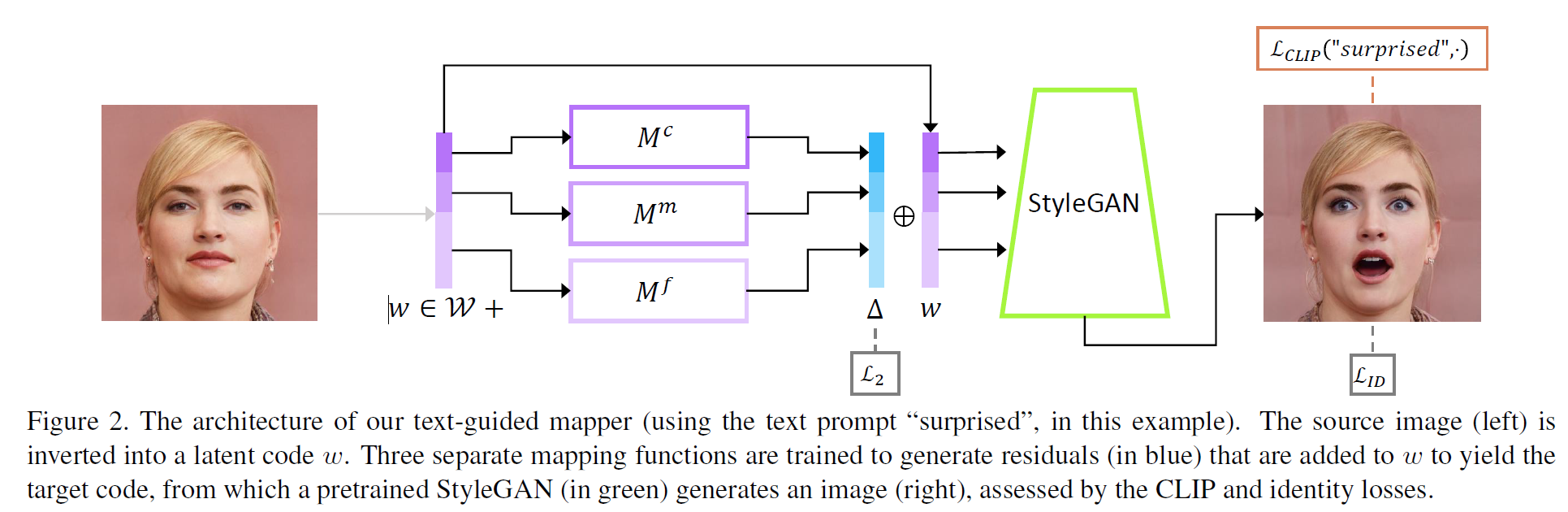
위의 최적화 방법은 매 이미지마다 최적화를 수행하다보니 오래 걸려서 비실용적이다. 여기서 설명하는 2번째 방법은 특정 text prompt에 대한 mapping network만을 사전학습하고 이후 입력 이미지에 대해서는 빠른 추론을 가능하게 한다. 입력 latent vector는 3개의 모델(Course, Medium, Fine)로 들어가고 L2 loss를 적용, StyleGAN generator를 통과하여 최종적으로 이미지를 생성한다. Course-Medium-Fine은 StyleGAN의 것과 유사함을 알 수 있다.
입력 이미지의 latent code를 $w = (w_c, w_m, w_f)$라 하면 mapper는 다음과 같이 정의할 수 있다:
\[M_t(w) = (M_t^c(w_c), M_t^m(w_m), M_t^f(w_f))\]Loss
CLIP loss는 mapper로 하여금 CLIP latent space에서 cosine 거리를 최소화하도록 한다.
\[\mathcal{L}_{\text{CLIP}}(w) = D_{\text{CLIP}}(G(w + M_t(w)), t)\]$(2)$번 식의 ID loss를 같이 써서 identity를 보존한다.
전체 loss는 아래와 같다.
\[\mathcal{L}(w) = \mathcal{L}_{\text{CLIP}}(w) + \lambda_{L2} \Vert M_t(w) \Vert_2 + \lambda_{\text{ID}} \mathcal{L}_{\text{ID}}(w) \quad (1)\]
text prompt는 1가지 이상을 한번에 적용할 수도 있다.

첫번째 방법에 비하면 잘 나오기는 하지만, 어쩐지 다른 스타일이나 이미지에 적용해도 뭔가 비슷해보이는 이미지가 최종 생성되는 문제가 있다고 한다.
6. Global Directions
그래서 3번째 방법으로 이 문제를 해결하려 한다. 이 방법은 한 문장으로 설명하면 text prompt를 StyleGAN의 style space $\mathcal{S}$에 있는 하나의 global direction으로 mapping하는 방법이다.
Notation:
- $s \in \mathcal{S}:=$ style code
- $G(s):=s$에 연관되는 생성된 이미지
원하는 특성을 지시하는 text prompt가 주어지면 원하는 조작(manipulation) 방향 $\Delta s$를 찾아야 한다. 이때 $\Delta s$는 $G(s + \alpha \Delta s)$(즉, 조작을 가한 이미지)가 다른 특성을 별로 해치지 않으면서 원하는 특성을 포함하거나 증폭된 상태여야 한다. 조작의 정도는 $\alpha$로 정한다.
- CLIP text encoder를 사용하여 CLIP의 언어-이미지 결합 임베딩 space 안의 vector $\Delta t$를 얻는다.
- $\Delta t$를 $\mathcal{S}$ 안의 조작 방향 $\Delta s$로 mapping한다.
- 안정적인 $\Delta t$는 자연어로부터 prompt emgineering을 통해 얻는다.
- 연관되는 방향 $\Delta s$는 각 style channel의 원하는 특성과의 연관도를 평가하여 얻는다.
좀더 자세히 알아보자.
- $\mathcal{I}:=$ CLIP의 joint embedding space 안의 이미지 임베딩의 manifold
- $\mathcal{T}:=$ text 임베딩의 manifold
이 둘 간의 직접적인 mapping은 없다(이미지는 여러 텍스트로 표현할 수 있고, 반대로 한 텍스트 문장으로부터 여러 이미지를 생각할 수 있다).
CLIP을 학습하는 동안, 모든 임베딩은 unit norm으로 정규화되고, 따라서 임베딩의 방향은 semantic 정보만을 담게 된다. 잘 학습된 CLIP space의 영역에서는 $\mathcal{T}, \mathcal{I}$(의 원소)가 같은 조작 방향에 대해서 같은 방향으로 움직일 것이라고 기대할 수 있다(즉, 높은 cosine 유사도를 갖는다). 정규화 후에는 방향뿐 아니라 움직이는 거리도 거의 같을 것이다.
주어진 이미지 쌍 $G, G(s+\alpha \Delta s)$에 대해 그 $\mathcal{I}$의 임베딩을 각각 $i, i + \Delta i$라 하자. 그러면 CLIP space에서 두 이미지 간 차이는 $\Delta i$가 된다. 자연어 지시문 $\Delta t$가 주어지고 $\Delta t, \Delta i$의 등선성(collinearity)를 가정하면, 조작 방향 $\Delta s$를 $\mathcal{S}$의 각 channel과 방향 $\Delta i$간의 연관도를 측정하여 구할 수 있다.
From natural language to $\Delta t$
text embedding noise를 줄이기 위해 prompt emgineering을 사용한다: 같은 의미를 지니는 여러 문장을 text encoder에 넣은 뒤 그 embedding을 평균하는 방법이다.
예를 든어, ImageNet zero-shot 분류 문제를 생각하자.
80개의 문장 template이 사용되는데 대충 다음과 같이 생겼다.
- “a bad photo of a {}”
- “a cropped photo of the {}”
- “a black and white photo of a {}”
- “a painting of a {}”
추론할 때에는 ({}가) target class로 자동으로 대체되고 각 문장의 embedding을 평균하여 구하게 된다. 이 과정은 분류 성능을 3.5% 정도 향상시킨다.
$\mathcal{T}$에서 더 안정적인 방향을 얻기 위해 이와 비슷한 방법을 사용한다. 예를 들어 위에서 target class가 “car”이었다면 좀 더 특정한 style을 적용하기 위해 “a sports car”라는 텍스트를 쓰는 방식이다.
Channelwise relevance
이제 우리의 목표는 style space 조작 방향 $\Delta s$를 구성하는 것인데 이는 목표 방향 $\Delta t$와 등선성을 가지는 변화 $\Delta i$를 반환하는 것이다. 이를 위해 CLIP의 joint embedding space의 주어진 방향 $\Delta i$에 대한 $\mathcal{S}$의 각 channel의 연관도를 측정해야 한다.
style code $s \in \mathcal{S}$ 집합을 생성하고 $c$ channel에 양 또는 음의 값을 더해 약간의 perturbation을 준다. 이미지의 결과 쌍 간의 CLIP space direction을 $\Delta i_c$라 하면, channel $c$와 목표 조작방향 사이의 연관도는 다음과 같다:
즉 $\Delta i_c$를 $\Delta i$에 mean projection한 것과 같다.
평균을 얻기 위해 100개의 이미지 쌍에 대해 계산을 수행했고 각 이미지 쌍은 $G(s \pm \alpha \Delta s_c$)로 얻는다.
- $\Delta s_c$는 channel $c$를 제외하고 0인 벡터이다. channel $c$에 대해서는 그 표준편차만큼의 값을 갖는다.
그런데 여기서 값을 바꿀 때 원하는 특성 외에 다른 특성이 변화되는 정도를 제한할 필요가 있다(예로, 머리카락 색만 백발로 바꾸려고 하는데, 얼굴까지 노인이 되는 것을 방지). 그래서 각 channel별로 어떤 threshold 값 $\beta$를 설정한다.
\[\Delta s = \Biggl\{ \begin{matrix} \Delta i_c \cdot \Delta i \quad \text{if} \vert \Delta i_c \cdot \Delta i \vert \ge \beta \\ 0 \qquad \text{otherwise} \end{matrix}\]$\alpha, \beta$를 변화시키면서 이미지를 생성한 결과를 아래에서 볼 수 있다. $\beta$가 커질수록 일부의 특징만이 바뀌는 것을 볼 수 있다.

더 많은 비교 결과..


7. Comparisons and Evaluation
TediGAN 등 다른 모델과 비교한 결과이다.
아래는 text-driven 얼굴 이미지 조작 방법을 비교한 결과를 나타낸다. 이 논문에서 제안한 첫번째 방법인 최적화 방법은 시간도 오래 걸리고 hyper-parameter에 민감한 등의 이유로 생략했다. 트럼프 전 대통령으로 얼굴을 바꾸거나, 머리를 모히칸 스타일로, 혹은 주름 없애기 등을 적용한 결과가 꽤 흥미롭다.
