
MobileNetV3 논문 설명(Searching for MobileNetV3 리뷰)
23 Feb 2022 | MobileNet Google목차
- Searching for MobileNetV3
이 글에서는 Google Inc.에서 발표한 MobileNet V3 논문을 간략하게 정리한다.
Searching for MobileNetV3
논문 링크: Searching for MobileNetV3
Github: https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/README.md
- 2019년 5월(Arxiv)
- Google Inc.
- Andrew Howard, Mark Sandler, Grace Chu et al.
모바일 기기에서 동작하는 것을 목표로 한, 성능을 별로 희생하지 않으면서도 모델을 크게 경량화하였다. MobileNet V1 및 MobileNet V2의 후속 논문이다.
Abstract
모바일 환경에 맞춘 새로운 세대의 MobileNets(V3)을 제안한다.
- NetAdapt 알고리즘 및
- 그 도움을 받아 Hardware-aware NAS(Network Architecture Search)와
- novel architecture advances에 기반해 있다.
이 논문은 어떻게 자동화된 탐색 알고리즘(automated search algorithm)과 네트워크 디자인을 어떻게 사용하는지 보여준다. 2가지 크기의 모델을 제안하는데,
- MobileNetV3-Large는 MobileNetV2에 비해 latency는 20% 줄이면서도 정확도는 3.2% 더 높다.
- MobileNetV3-Large LR-ASPP는 Cityspaces segmentation에서 MobileNetV2 R-ASPP보다 비슷한 정확도를 가지면서 34% 더 빠르다.
- MobileNetV3-Small는 MobileNetV2에 비해 정확도는 비슷하면서 25% 더 빠르다.
각각 자원을 더 많이 쓰냐 적게 쓰냐의 차이가 있다.
또 Semantic Segmentation task에서는 Lite Reduced Atrous Spatial Pyramid pooling(LR-ASPP)라는 새로운 효율적인 decoder를 제안한다.
1. Introduction
모바일 app이라면 어디나 존재하는 효율적인 신경망은 완전히 새로운 on-device 경험을 가능하게 한다. 이러한 상황에서 모바일과 같이 작은 device에 들어가는 네트워크는 서버에 전송되는 데이터를 줄여 더 빠른 속도, 더 적은 전력소모 등의 효과를 가져올 수 있다. 이렇게 사용되는 네트워크는 크기가 작으면서도 성능은 충분히 챙길 수 있는 효율성을 가져야만 하며 이 논문에서는 그러한 모델을 개발하는 것을 다룬다.
이를 위해
- 상호보완적 탐색 기술
- 모바일 setting에서 비선형성의 새롭고 효율적인 버전
- 효율적인 네트워크 디자인
- 효율적인 segmentation decoder
를 소개한다.
2. Related Work
정확도와 효율성(latency(반응 속도) or 실행 시간 등) 간 trade-off에 관한 연구가 최근 많이 진행되었다.
- SqueezeNet은 1x1 conv를 활용하여 parameter 수를 줄였다.
- MobileNet V1 및 MobileNet V2은 Depthwise Separable Convolution으로 연산 수(MAdds)를 크게 줄였다.
- ShuffleNet은 group conv와 shuffle 연산으로 MAdds를 더 줄였다.
- CondenseNet은 학습 단계의 group conv를 학습하고 추후를 위해 유용한 dense connection만을 남기는 방식을 채택했다.
- ShiftNet은 point-wise conv에 interleave한 shift 연산을 제안하여 값비싼 spatial conv 연산을 대체했다.
그리고 architecture 디자인 과정을 자동화하기 위한 연구도 많이 이루어졌다. RL 등이 대표적이지만 전체 상태 공간을 탐색하는 것은 매우 어렵다. 탐색 연산량을 줄이기 위해 Proxylessnas, DARTS, Fbnet 등의 논문에 발표되었다.
양자화(Quantization)은 Reduced Precision Arithmetic을 통해 네트워크의 효율성을 높이고자 하였다.
3. Efficient Mobile Building Blocks
- MobileNetV1에서는 Depthwise Separable Convolution을 제안하여 모델 크기를 크게 줄였다.
- MobileNetV2에서는 linear bottleneck \& inverted residual 구조를 제안하여 더 효율적인 구조를 제안했다.
- MnasNet은 bottleneck 구조에 squeeze and excitation 모듈에 기반한 light weight attention module을 제안했다.
MobileNet V3에서는 이러한 layer들의 조합을 building block으로 사용하여 효율적인 구조를 제안한다.
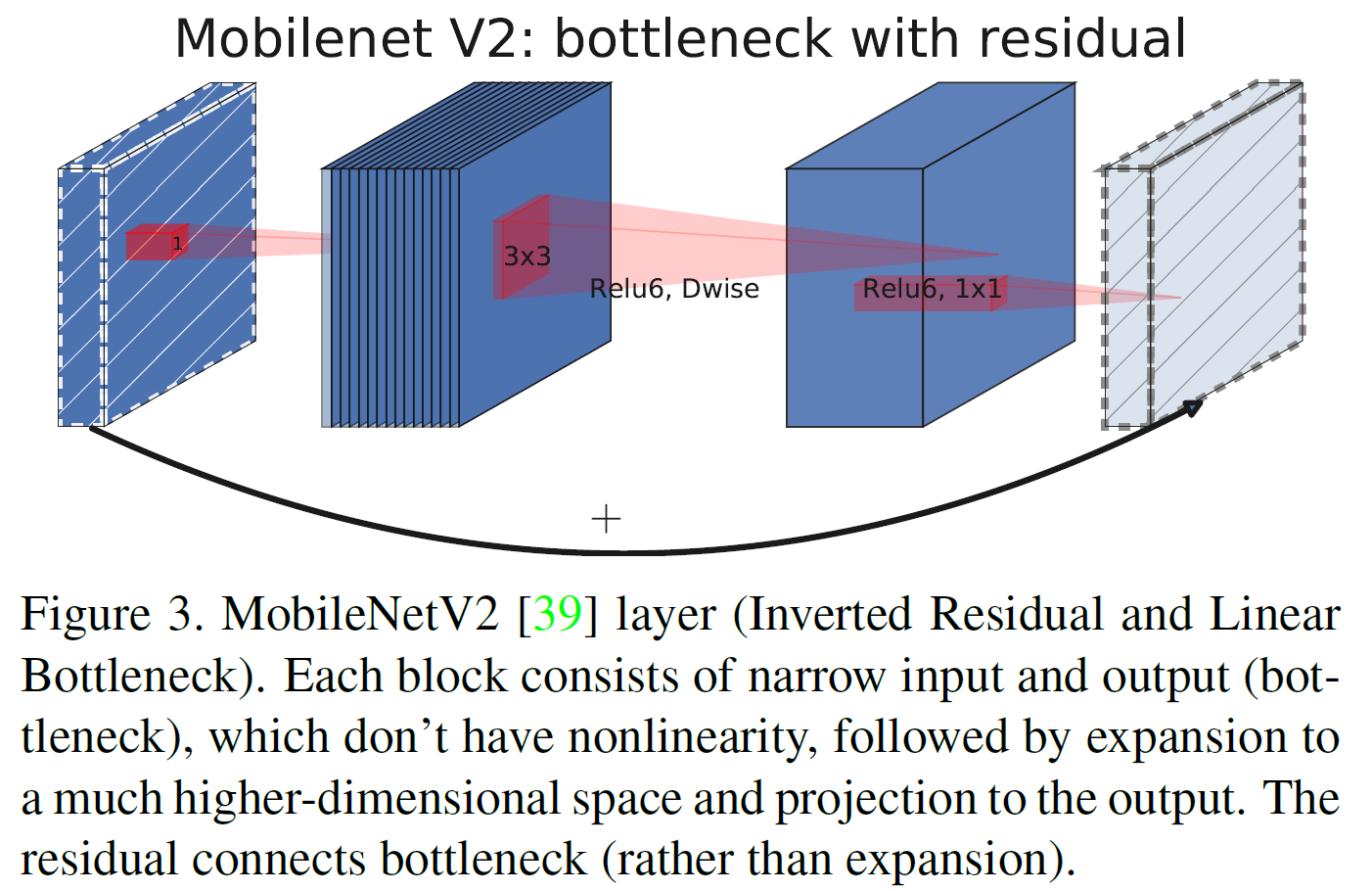

4. Network Search
- 각 network block을 최적화함으로써 전체 network struce를 찾기 위한 platform-aware NAS를 사용하였다.
- filter의 수를 찾기 위해 NetAdapt 알고리즘을 사용하였다.
- 이 테크닉들은 상호보완적이며 효율적인 모델을 찾기 위해 결합하여 사용할 수 있다.
4.1. Platform-Aware NAS for Blockwise Search
MnasNet과 같은 접근법을 사용하지만 조금 더 작은 weight factor $w=-0.15$(원래는 $w=-0.07)를 사용하여 latency가 다를 때 정확도의 큰 변화를 막고자 했다.
4.2. NetAdapt for Layer-wise Search
platform-aware NAS와 상호보완적인 접근법이다. 간략히 정리하면 다음과 같이 동작한다:
- platform-aware NAS로 찾은 seed network 구조로 시작한다.
- 각 step마다:
- 새로운 proposals를 생성한다. 각 proposal은 architecture의 변화를 포함하며 이전 step에 비해 적어도 $\delta$만큼의 latency reduction을 만들어 낸다.
- 각 proposal에 대해 이전 step의 사전학습된 model을 사용하여 새로 제안된 proposal을 덧붙이고, 자르고, 빈 weight 부분을 임의로 초기화를 적절혀 시켜서 새 구조를 얻는다. 그리고 $T$ step 동안 fine-tune 과정을 거쳐 coarse한 정확도 추정치를 얻는다.
- 어떤 (특정) metric을 사용하여 가장 좋은 proposal을 선택한다.
원래 알고리즘은 metric이 정확도 변화를 최소화하는 것이다. 이를 조금 바꿔서 latency 변화량 대비 정확도 변화량의 비율을 사용했다.
\[\frac{\Delta \text{Acc}}{\vert \Delta \text{latency} \vert}\]이 과정은 latency가 목표에 도달할 때까지 반복하며 그 다음엔 scratch로부터 새로운 architecture를 재학습한다.
MobileNet V2를 위해 NetAdapt에서 사용된 것과 동일한 proposal 생성기를 사용하였다. 구체적으로 다음 2가지 종류의 proposal이 있다:
- 어떤 expansion layer든지 그 크기를 줄인다.
- (residual connection을 유지하기 위해) 같은 bottleneck 크기를 갖는 모들 block 안의 bottleneck을 줄인다.
이 논문에서는 $T=10000, \delta=0.01 \vert L \vert$이며 $L$은 seed model의 latency이다.
5. Network Improvements
network search에 더해 몇 가지 component를 소개한다.
- 비싼 계산량의 layer를 재설계
- h-swish: 새로운 비선형성. 계산이 더 빠르고 quantization-friendly함
5.1. Redesigning Expensive Layers
특히 (연산량이) 비싼 몇 개의 layer가 대부분을 차지하는 경향이 있다. 그래서 일부 구조를 변경하여 정확도를 유지하면서도 계산량을 줄이려 했다.
- 마지막 몇 개의 layer가 최종 feature를 효율적으로 생성하기 위해 어떻게 상호작용해야 하는지에 대한 재작업: 1x1 conv로 고차원으로 보내는 작업은 rich feature를 얻는 데 필수적이지만 latency를 증가시킨다.
- 그래서 7x7 spatial resolution 대신 1x1 spatial resolution을 사용하였다.
- feature 생성 layer의 연산량을 좀 줄이고 난 다음으로 할 일은 이전 bottleneck projection layer가 더 이상 계산량을 증가시키지 않는다는 것에서 착안하여 projection과 filtering을 이전 bottleneck layer에서 없애는 것이다.
- 이전 모델은 expansive layer에서 32개의 3x3 layer를 썼는데 이 filter는 종종 좌우 반전의 image를 갖는(처리하는) 경우가 있다. 그래서 중복을 줄일 수 있게 filter 수를 16개로 줄였다.
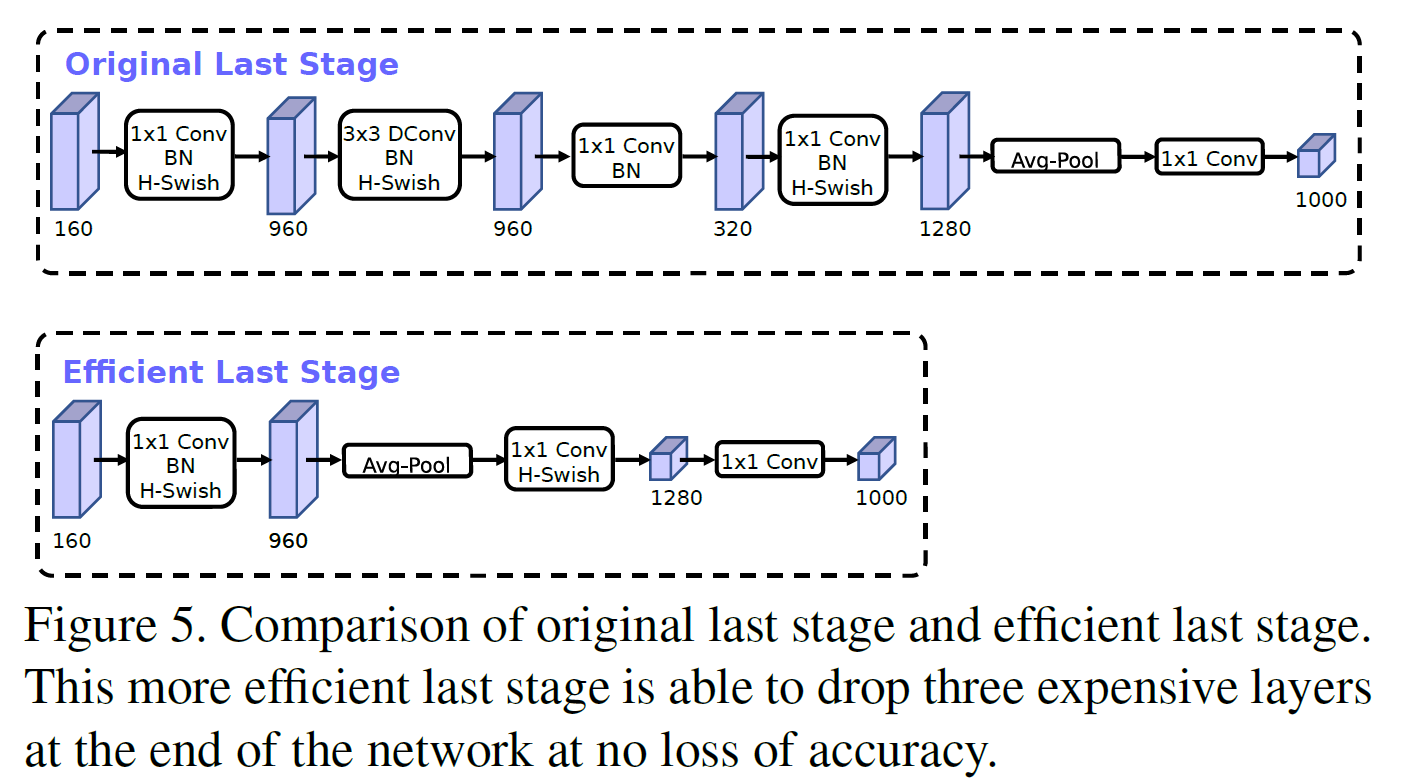
5.2. Nonlinearities
swish라 불리는 비선형성을 ReLU에서 사용되는 부분이다. swish는 다음과 같다.
\[\text{swish} x = x \cdot \sigma(x)\]이 비선형성은 정확도를 높이는 데 도움이 되지만 sigmoid 연산은 비싼 연산이다. 그래서 2가지 방식으로 해결하고자 한다.
- sigmoid를 다른 함수로 바꾼다.
이러면 비선형성 및 gradient 변화를 잘 유지하면서도 계산량이 많이 줄어든다.
아래 그림을 보면 쉽게 이해가 될 것이다.
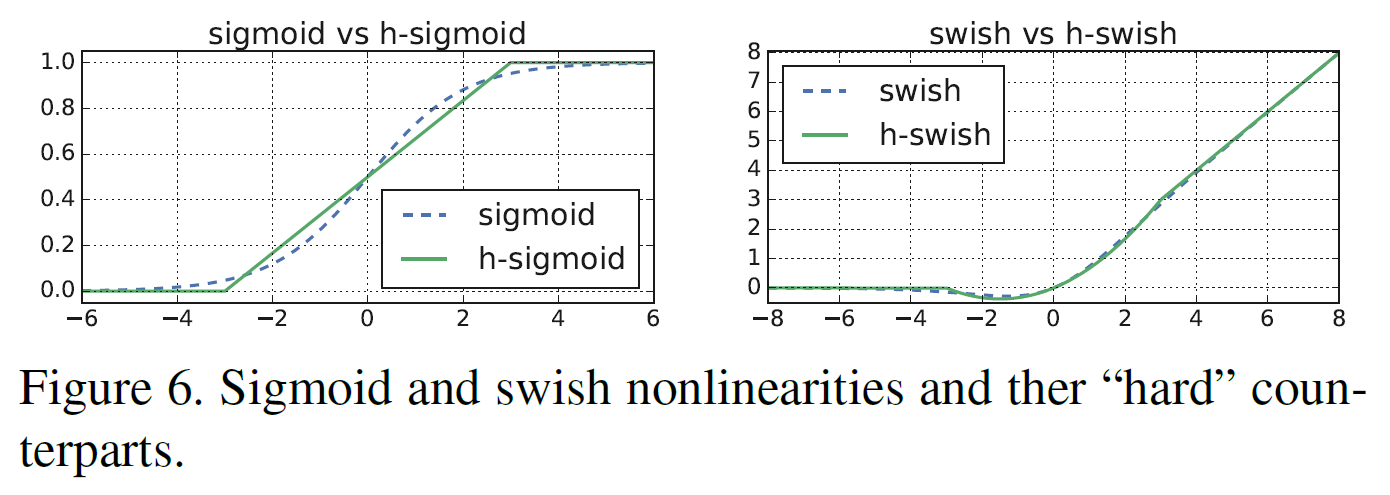
- 비선형성을 적용하는 비용은 네트워크가 깊어질수록 줄어든다(activation 수 자체가 줄어드므로). 그런데 swish의 이점은 거의 깊은 layer에서만 얻을 수 있다. 그래서 h-swish는 모델의 후반부 절반에서만 사용하도록 했다.
5.3. Large squeeze-and-excite
이전 연구(SENet)에서 squeeze-and-excite bottleneck은 conv bottleneck의 것에 비례했으나 이 논문에서는 expansion layer의 채널 수의 1/4로 고정하였다. 이는 약간의 parameter 수 증가만으로 정확도 향상을 이끌어내었다.
5.4. MobileNetV3 Definitions
MobileNet V3는 Large와 Small 모델이 있다. 각 크기는 다음과 같다.
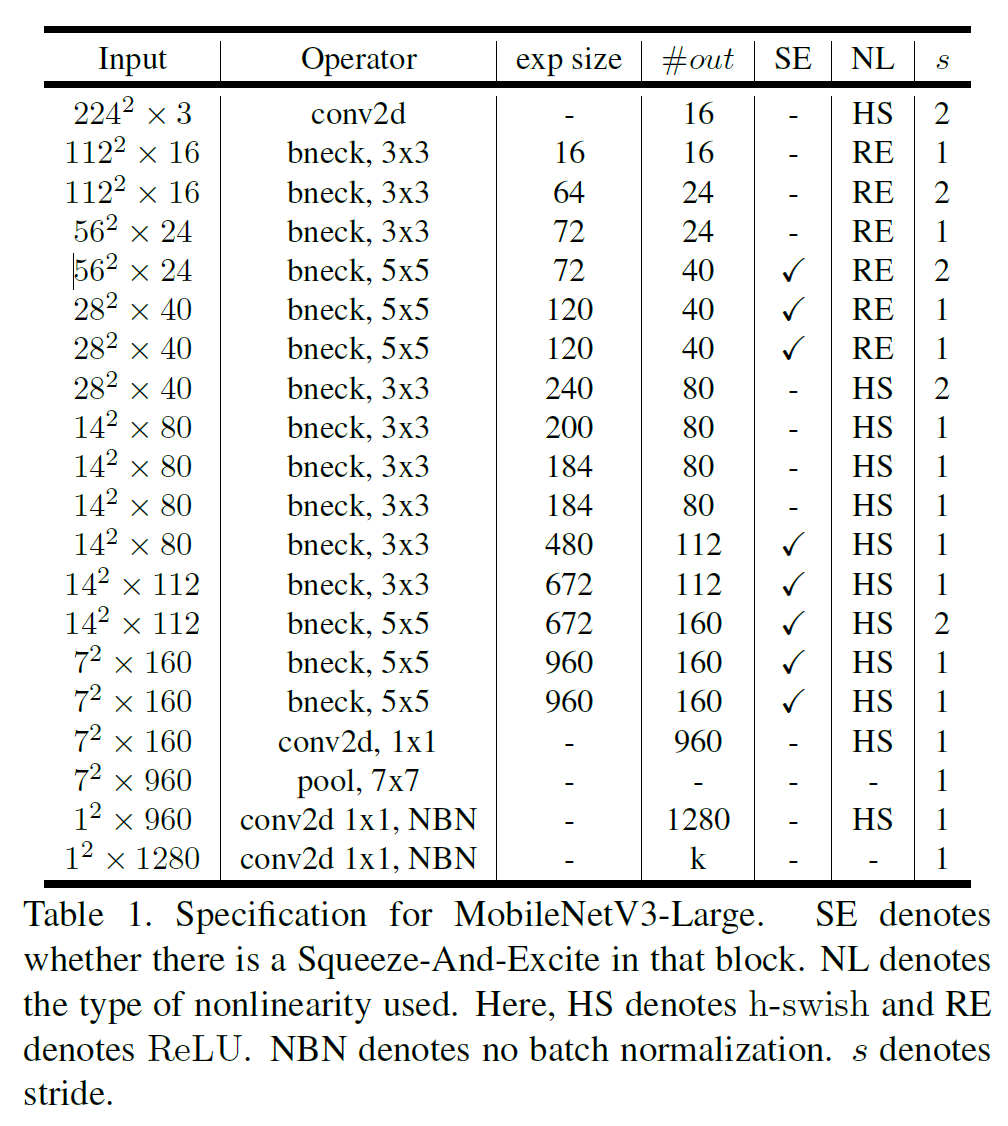
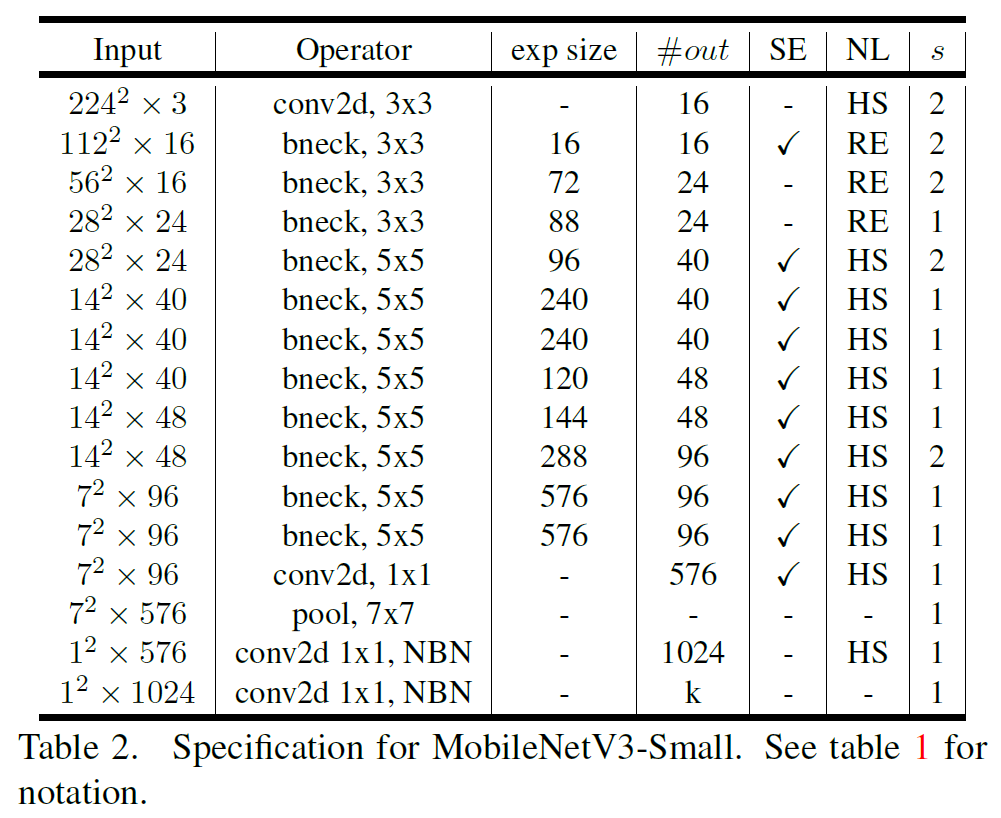
6. Experiments
6.1. Classification
ImageNet으로 실험함.
6.1.1 Training setup
4x4 TPU, RMSProp(0.9 momentum), batch size 4096(클립당 128 image), lr 0.1, 3 epoch당 decay 0.01, dropout 0.8, l2 weight decay 1e-5, 지수이동평균 0.9999로 학습하였다.
6.1.2 Measurement setup
Google Inc.에서 발표한 논문답게 구글 픽셀 폰 위에서 표준 TFLite Benchmark tool로 실험했다.
6.2. Results
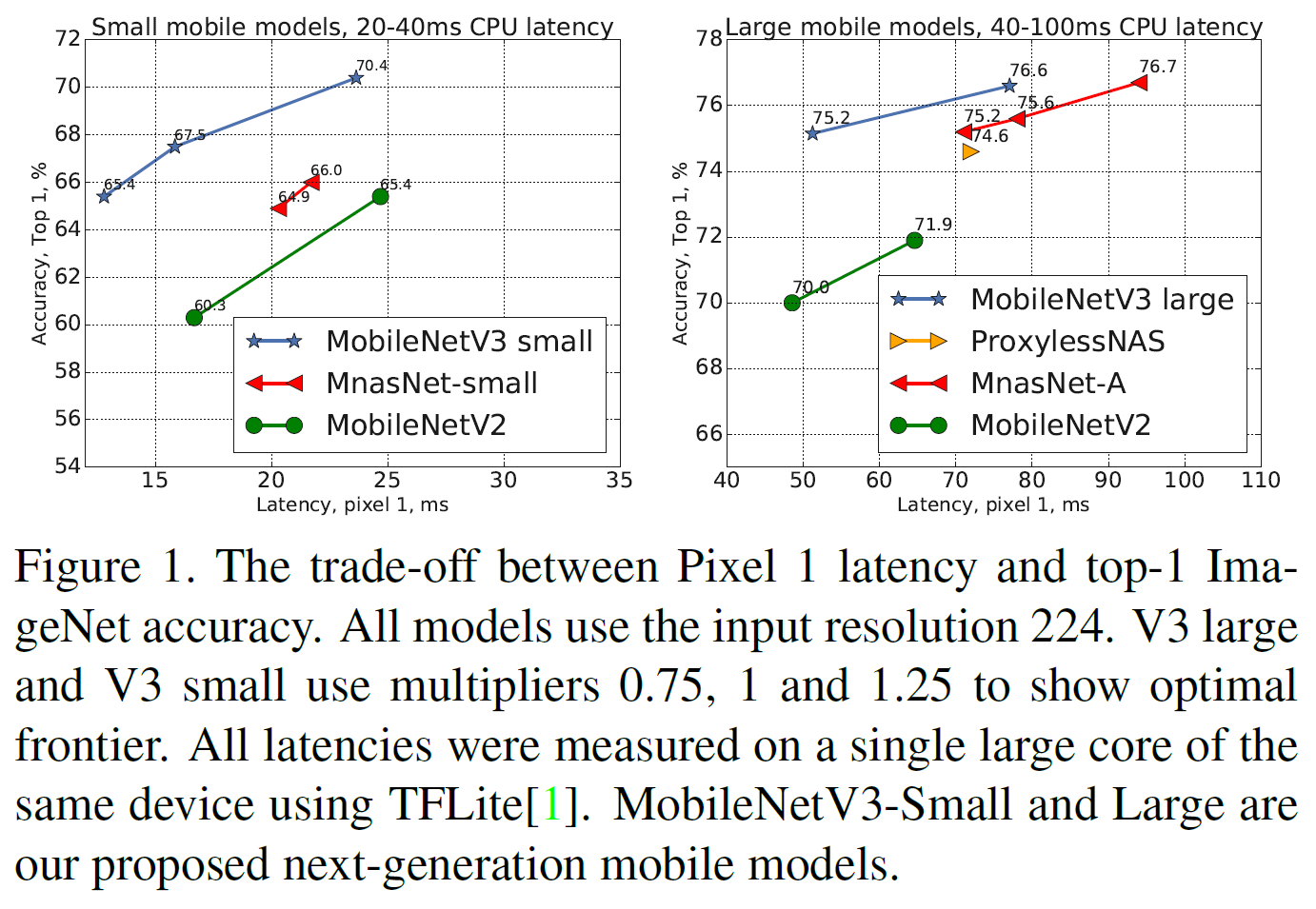
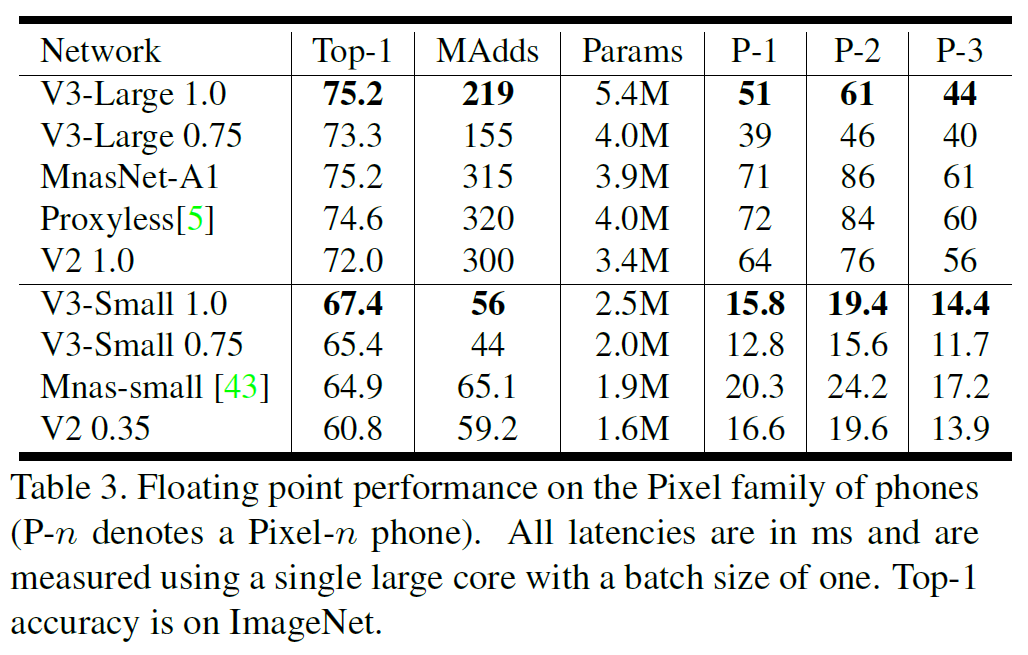
그림 1에서 보듯시 MnasNet, ProxylessNas, MobileNetV2과 갈은 기존의 SOTA를 모두 능가한다.
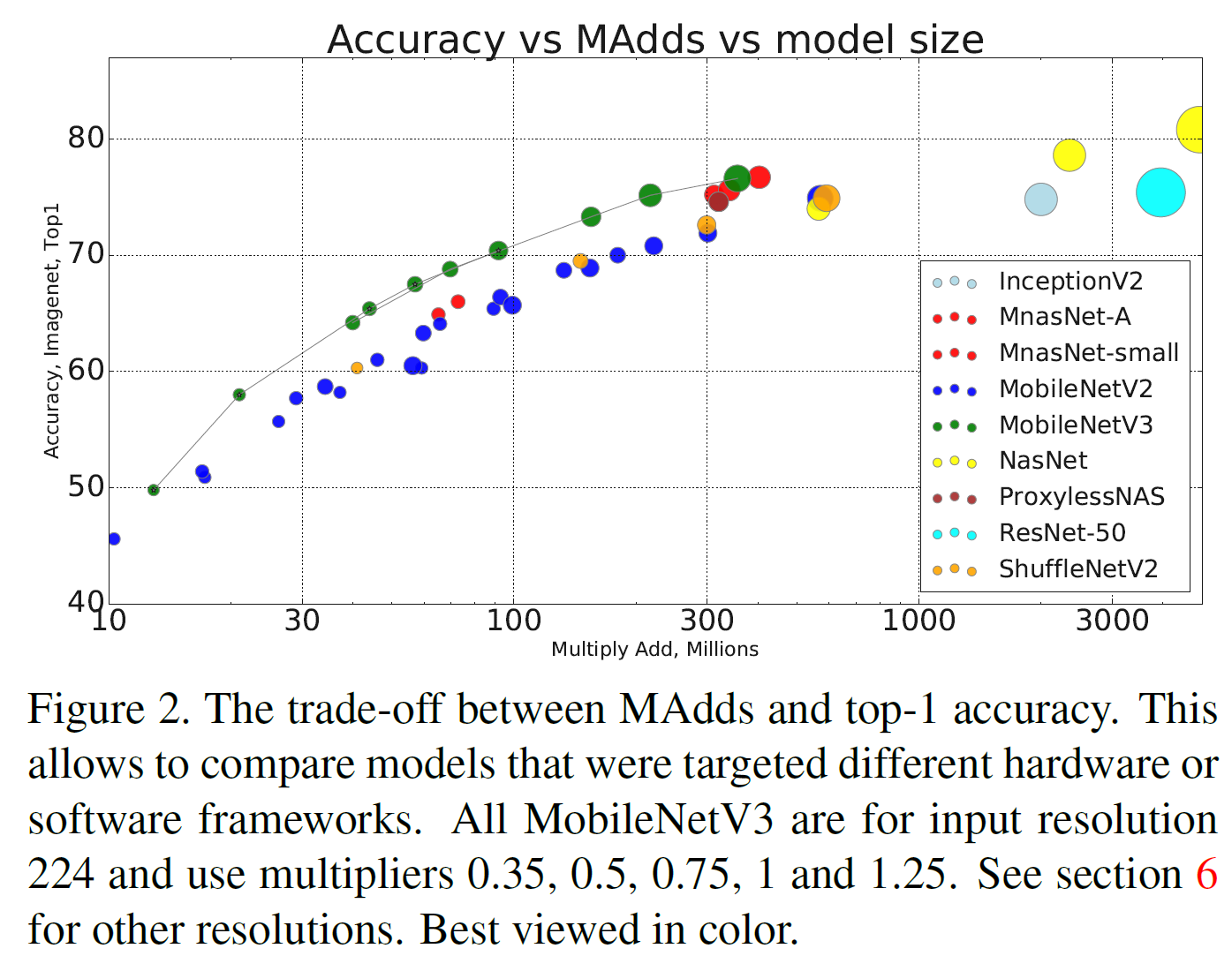
floating point 성능은 표 3에, 양자화 결과는 표 4에 있다.
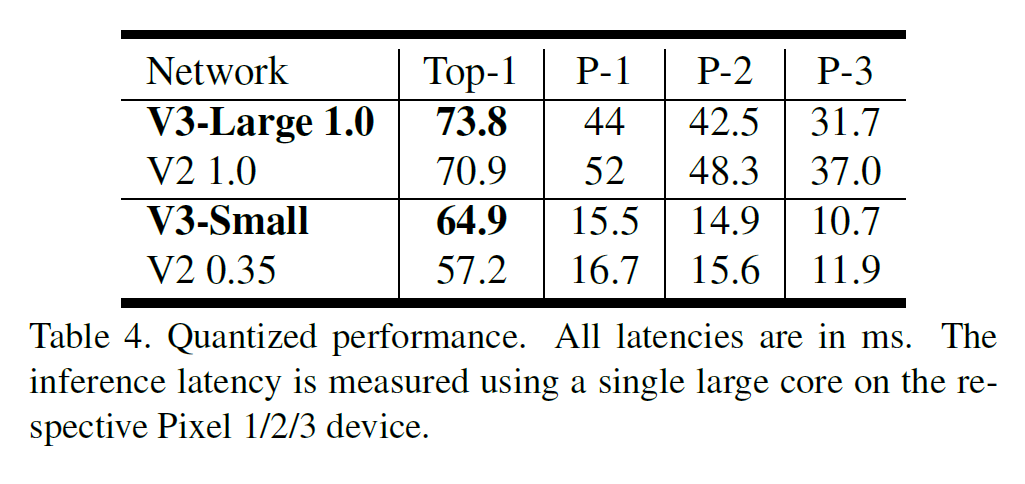
6.2.1 Ablation study
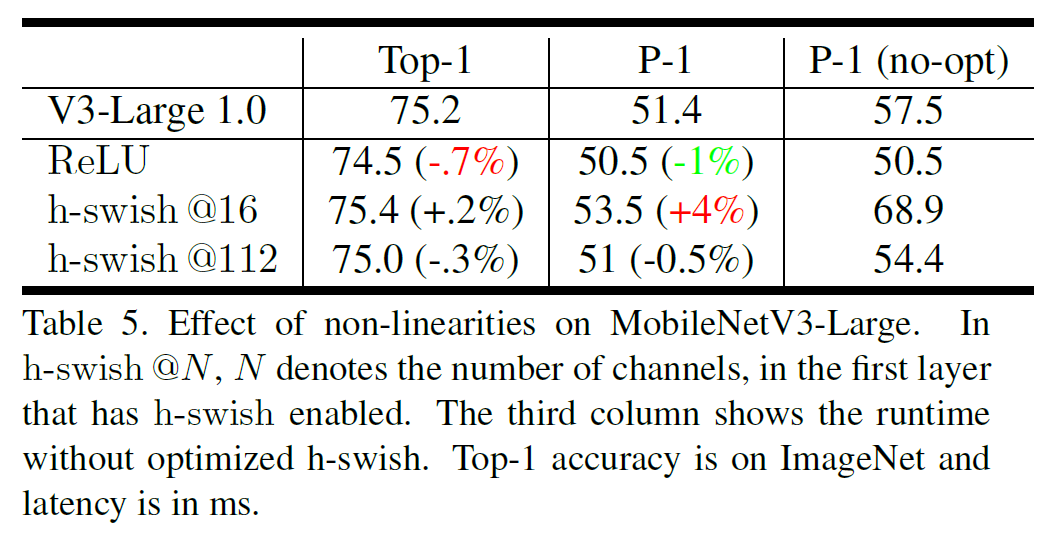
Impact of non-linearities
표 5에서는 h-swish의 효과를 보여준다. 6MS 정도(10%)의 실행 시간 감소 효과를 가진다.
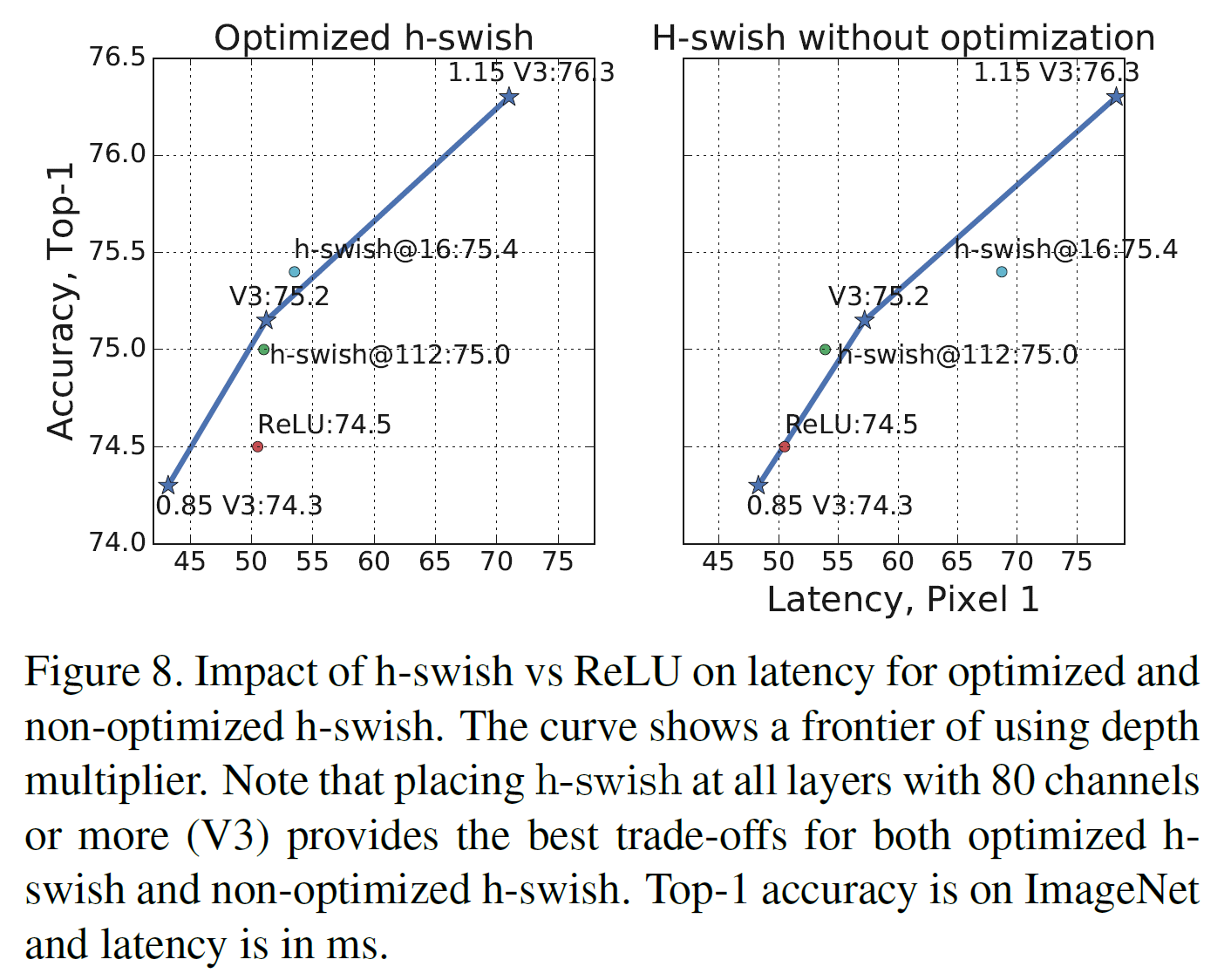
nonlinearity choices와 network width에 기반한 효율적인 frontier를 보여준다. h-swish는 네트워크 중간에 넣는 것이 낫고 ReLU를 확실히 능가한다.
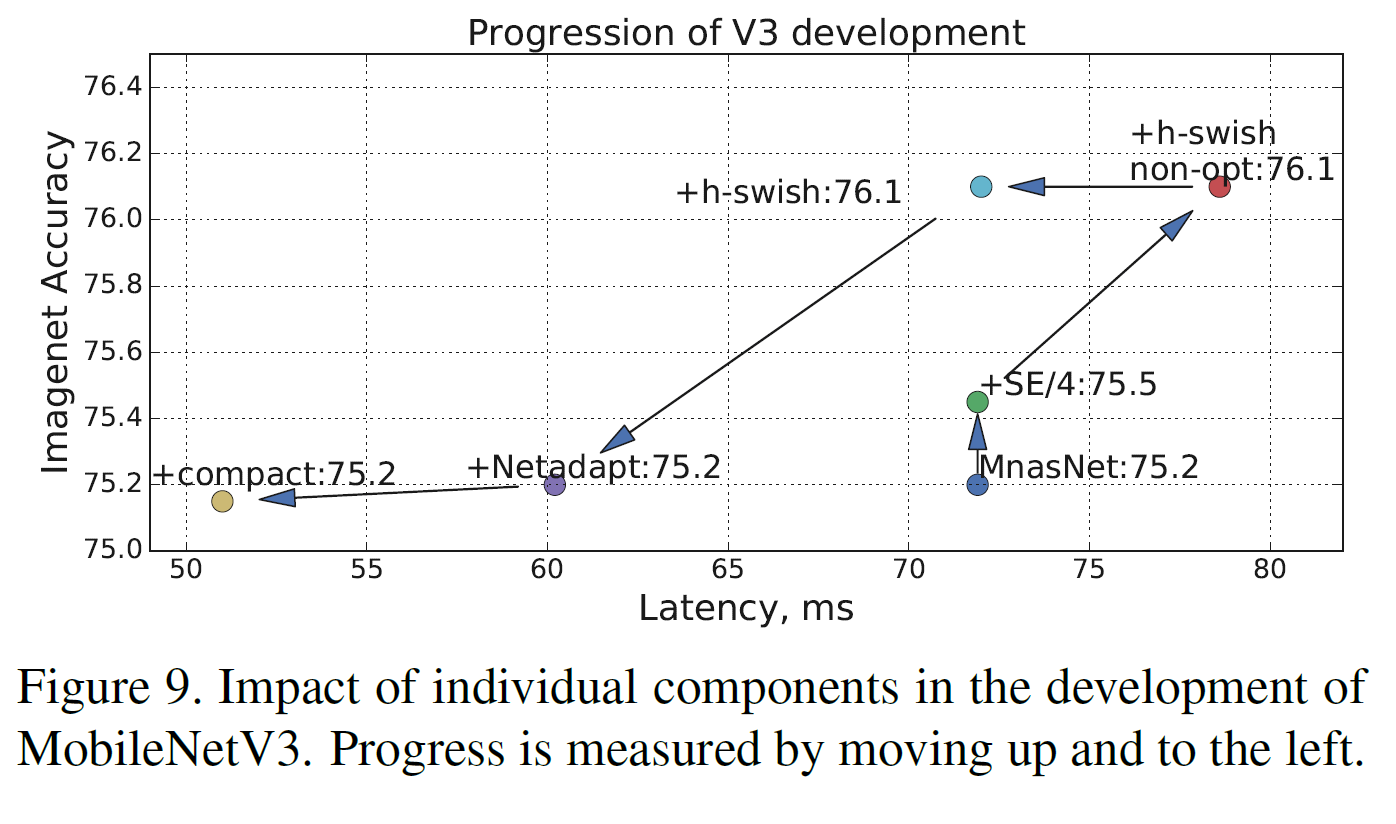
Impact of other components
본문에서 설명한 다른 부분들의 효과를 간략히 보여주고 있다.
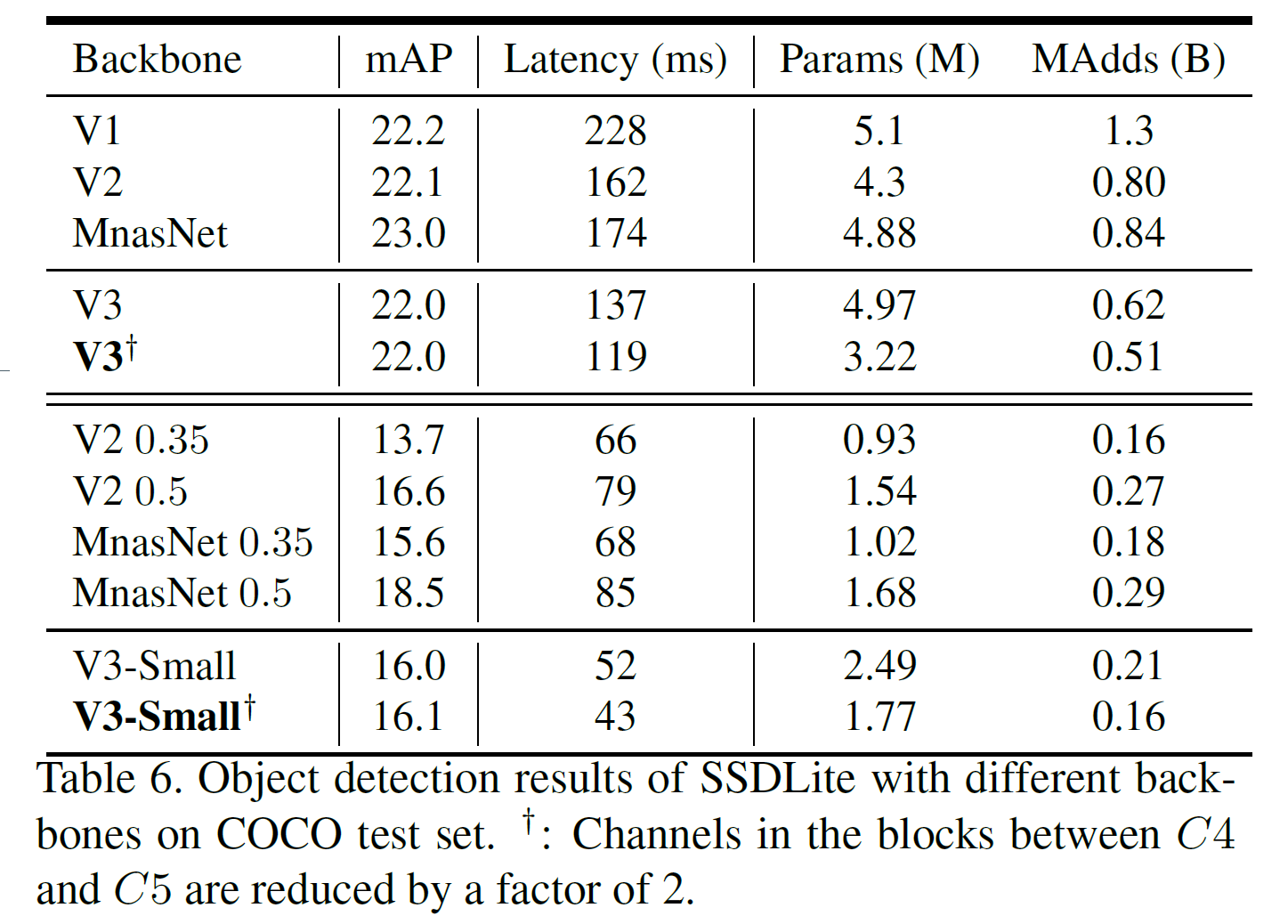
6.3. Detection
COCO 데이터셋에서, SSDLite의 feature extractor를 MobileNetV3로 대체하고 다른 backbone과 비교하였다.
이 논문의 다른 모든 부분에서 그랬듯, 모델의 계산량, latency, 모델 크기 등을 비교하면 된다.
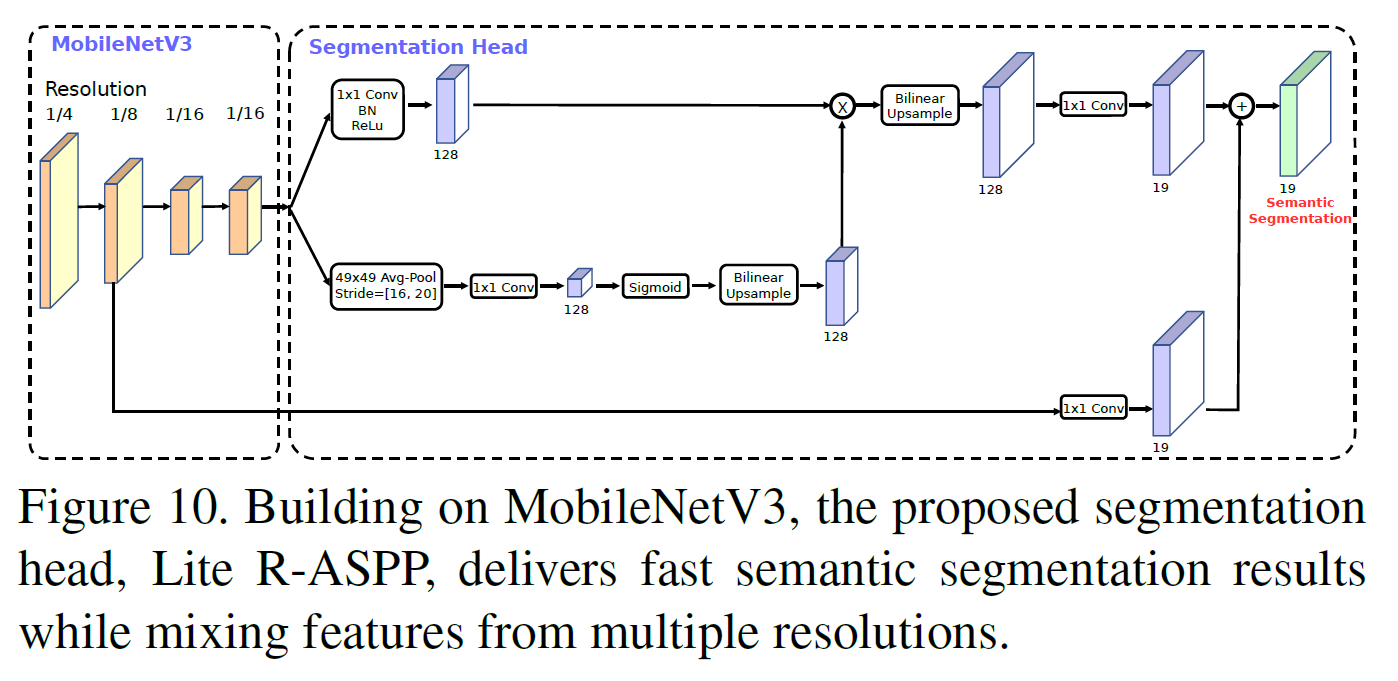
6.4. Semantic Segmentation
구조는 아래와 같다.
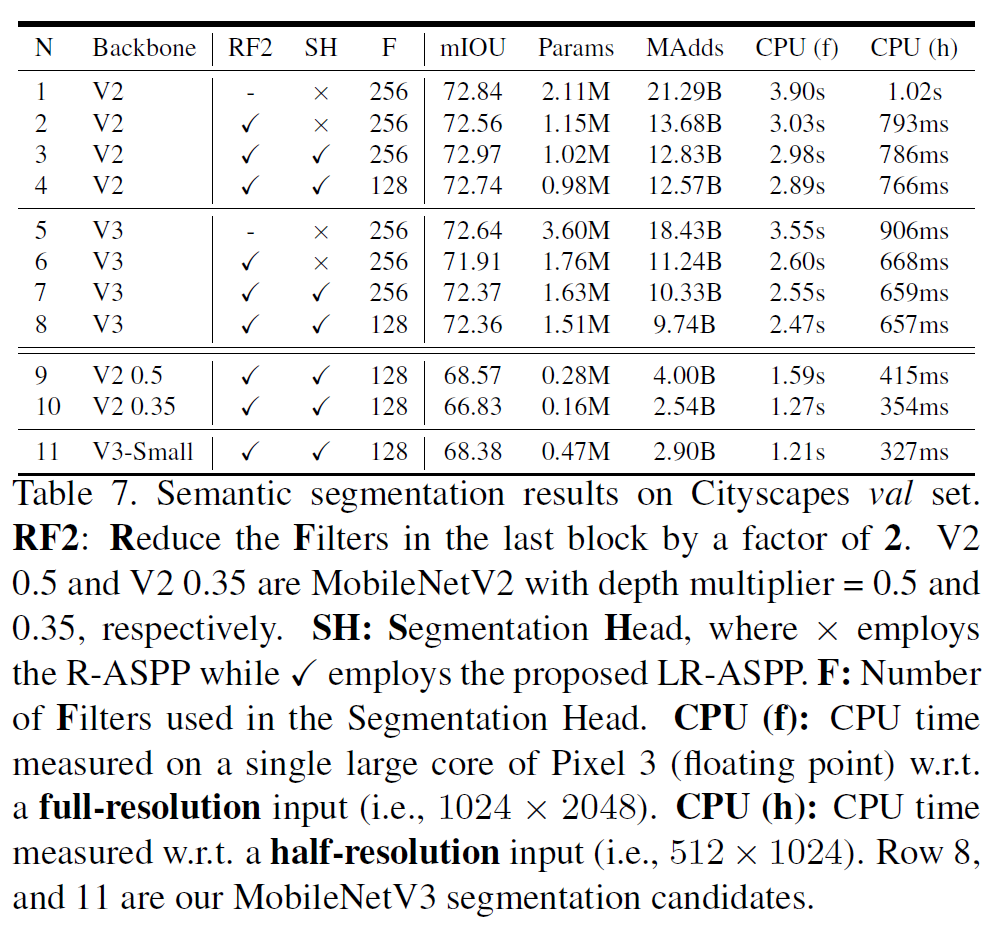
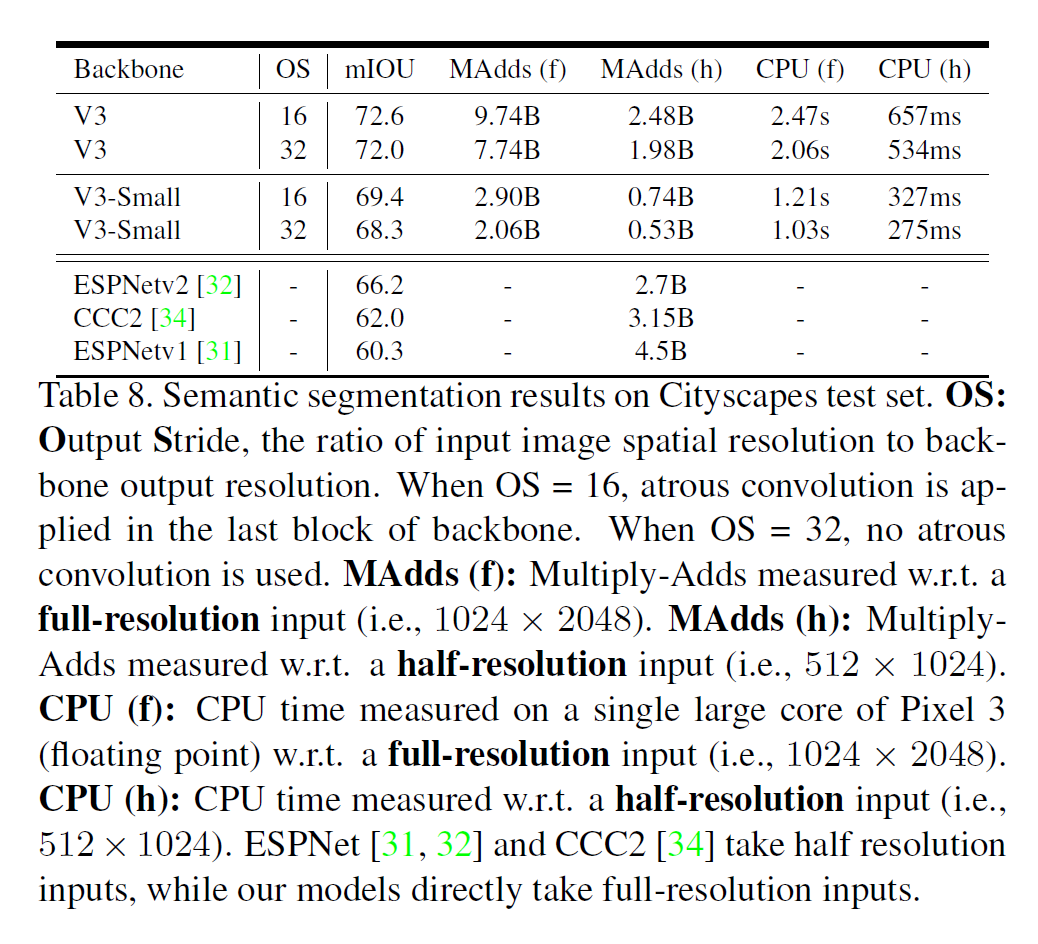
결과도 다른 결과랑 비슷하다.
7. Conclusions and future work
- MobileNetV3-Large, Small 모델을 제안하여 image classification, detection, segmentation에서 SOTA를 달성하였다.
- 특히 모델의 크기가 작고 계산량이 적으며 latency가 낮다.