
MobileNetV2 논문 설명(MobileNetsV2 - Inverted Residuals and Linear Bottlenecks 리뷰)
10 Feb 2022 | MobileNet Google목차
- MobileNetsV2: Inverted Residuals and Linear Bottlenecks
이 글에서는 Google Inc.에서 발표한 MobileNet V2 논문을 간략하게 정리한다.
MobileNetsV2: Inverted Residuals and Linear Bottlenecks
논문 링크: MobileNets: Inverted Residuals and Linear Bottlenecks
Github: https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/README.md
- 2018년 1월(Arxiv)
- Google Inc.
- Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen
V1: 모바일 기기에서 동작하는 것을 목표로 한, 성능을 별로 희생하지 않으면서도 모델을 크게 경량화하였다. V2: Inverted Residual, Linear Bottleneck을 도입하여 V1을 업그레이드하였다.
Abstract
- shortcut connection이 얇은 bottleneck layer 사이에 존재하는 inverted residual 구조에 기반한 MobileNet V2를 제안한다.
- 모델의 representational power를 보존하기 위해 narrow layer 안에서는 비선형성을 제거하는 것이 낫다는 것을 발견하였다.
- 본 논문에서 제안하는 접근법은 expressiveness of the transformation으로부터 입출력 도메인을 분리하는 것을 가능하게 한다.
- ImageNet 분류, COCO object detection, VOC image segmentation에서 성능을 측정하여 작은 모델로도 충분히 높은 성능을 기록함을 보인다.
1. Introduction
최근의 모델들은 크기를 상당한 수준으로 키우면서 그 성능도 올라갔지만 메모리나 계산량 역시도 엄청나게 증가하였다. 특히, 모바일 등 작은 기기나 embedded 환경에서는 이러한 모델을 쓰기가 어렵고, 크기가 작은 모델을 개발할 필요가 있다.
이 논문에서는 inverted residual with lienar bottleneck이라는 구조를 제안한다. 이 모듈은 저차원의 압축된 표상(표현)을 받아 먼저 고차원으로 확장한 다음 다시 lightweight depthwise convolution으로 필터링을 거친다. Feature는 이러한 일련의 과정(linear convolution)을 통해 저차원의 표상으로 투영된다.
이는 표준 연산을 통해서 효율적으로 구현이 가능하며 어떤 모델에도 사용할 수 있다. 또 중간 결과로 큰 tensor를 잡는 일도 없어 메모리 사용량을 크게 줄일 수 있다. 이는 작은 기기를 포함하여 많은 곳에서 효율적으로 쓸 수 있음을 뜻한다.
2. Related Work
정확도와 성능(latency) 간의 최적의 균형을 찾는 것은 지난 몇 년간 꽤 핫한 주제였다. 모델의 크기를 키워 성능을 높이고, 비슷한 효과를 가지면서 parameter 수를 줄이는 등 여러 연구가 있어 왔다. 최근에는 유전 알고리즘과 강화학습을 비롯한 여러 최적화 기법도 사용되었으나 이들은 너무 복잡하다는 단점이 있다. 이 논문에서는 더 낫고 더 간결한 방법을 제시하고자 한다.
3. Preliminaries, discussion and intuition
3.1. Depthwise Separable Convolution
MobileNet V1을 참조하면 된다.
3.2. Linear Bottlenecks
$n$개의 layer $L_i$로 구성된 신경망을 고려하자.
- 그러면 실제 이미지 입력에 대해서 각각의 픽셀 및 채널에 대해 $ h_i \times w_i \times d_i $ 크기의 activation이 존재함을 생각할 수 있다.
- 이걸 $d_i$ 차원을 갖는 “pixel”이 $h_i \times w_i$ 개 있다고 생각할 수 있다.
- 대략적으로, 실제 입력 이미지에 대해서, 이러한 layer activation은 “manifold of interest“를 형성한다고 생각할 수 있다.
- 지금까지의 연구들에서는 신경망에서 manifold of interest는 저차원의 subspace로 embedded될 수 있다고 가정해 왔다.
- 즉, 우리가 deep conv layer의 모든 독립적인 $d$-채널 pixel을 볼 때, 이 값들에 인코딩되어 있는 정보는 어떤 manifold 상에 위치하며, 이것은 저차원의 subspace로 보낼 수 있다는 것이다.
이러한 직관을 갖고, MobileNet V1에서는 저차원의 subspace로 보냈다가 다시 복구시키는 bottleneck layer를 적용하여, activation space의 차원을 효과적으로 줄일 수 있었다. 그러나, manifold의 “정보”는 비선형 변환 함수, ReLU와 같은 것이 있기 때문에 일부 소실될 수 있다.

ReLU가 채널을 collapse시킨다면, 해당 채널에서 정보가 손실되는 것은 피할 수 없다. 그러나, 채널이 충분히 많다면, 해당 정보가 다른 채널에서는 살아 있을 수 있다.
요약하면,
- manifold of interest가 ReLU 변환 이후에도 non-zero volume으로 남아 있다면, 그것은 선형 변환에 부합한다.
- ReLU가 입력 manifold에 대해 정보를 완전히 보전하는 경우는, 입력 manifold가 입력 space의 저차원 subspace에 있을 때에만 그렇다.
그래서 결론은, ReLU와 같은 비선형 activation이 없는 layer를 하나 더 추가한다. 이것이 linear bottleneck의 역할을 한다.
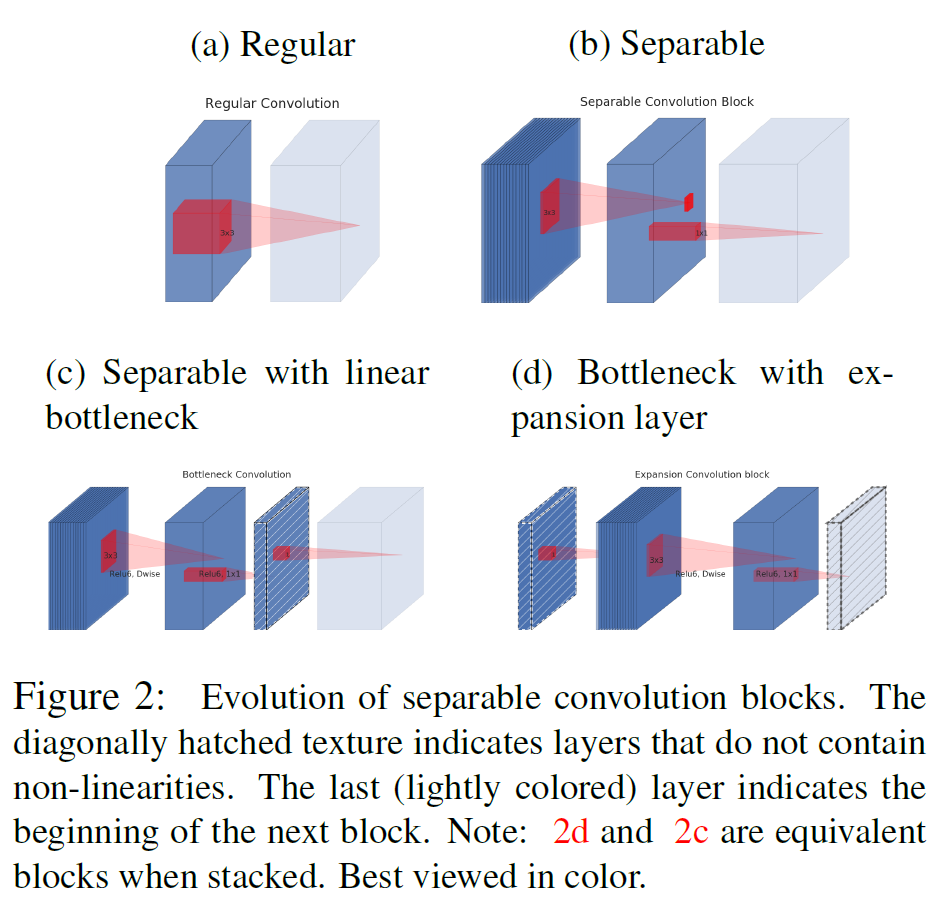
3.3. Inverted residuals
일반적인 residual connection과 반대이다. 즉, 보통은 wide - narrow - wide의 layer가 있고, wide layer끼리 연결을 추가한 방식인데, 이 논문에서는
- narrow - wide - narrow layer가 기본으로 있고
- narrow layer끼리 연결이 되어 있다.
이렇게 하는 이유는 narrow에 해당하는 저차원의 layer에는 필요한 정보만 압축된 채로 저장되어 있다고 가정하기 때문이다. 즉 필요한 정보는 narrow에 이미 있기 때문에, skip connection으로 사용해도 정보를 더 깊은 layer까지 전달할 수 있을 것이라고 생각하는 것이다.
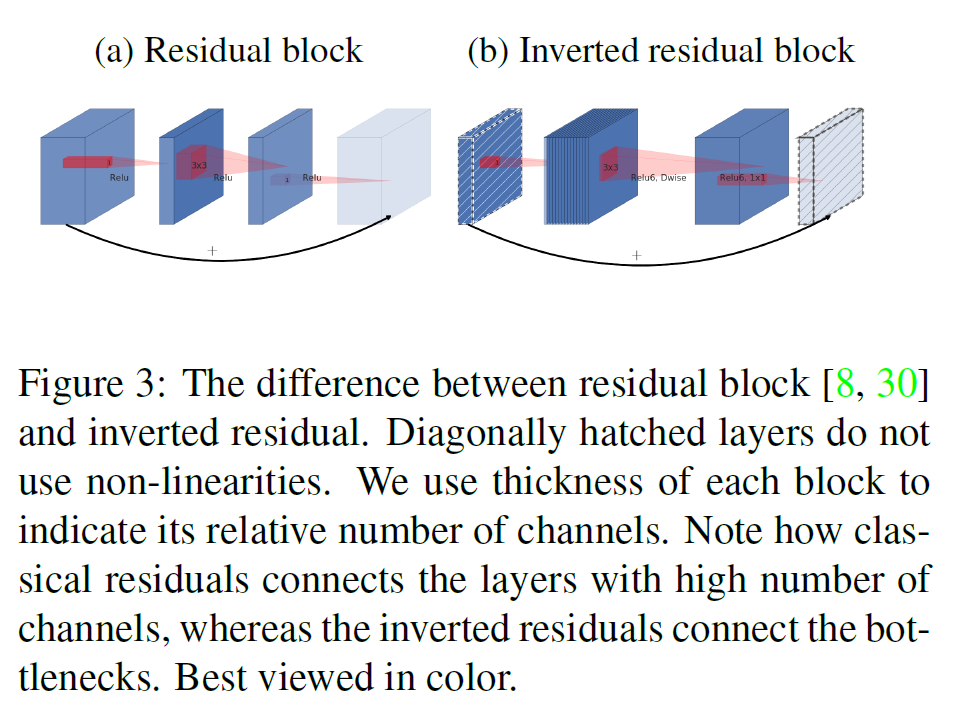
3.4. Information flow interpretation
이 구조가 갖는 흥미로운 특성은 building block(bottleneck layer)의 input/output domains 사이의 자연스러운 분리가 이루어진다는 것이다.
특히, inner layer depth가 0인 경우 다음의 convolution은 shortcut connection 덕분에 항등함수가 된다. expansion ratio가 1보다 작으면 보통의 residual conv block이 되고, 물론, 이 논문에서는 1보다 크다.
이로써 모델의 크기(capacity)와 모델의 표현력을 분리하여 생각할 수 있고, 이는 네트워크의 특성을 이해하는 데 도움을 줄 것이다.
4. Model Architecture
기본 구조는 bottleneck depth-separable convolution with residuals이다. 자세한 구조는 다음 표와 같다.

MobileNet V2는 32개의 filter를 갖는 fully conv layer, 19개의 residual bottleneck layer를 가지며, 활성함수로는 ReLU6을 사용한다.

inverted residual의 확장 비율(expansion ratio)는 모든 실험에서 6으로 고정하였다. 만약 입력 채널 수가 64였다면, 중간의 wide layer에서는 64$\times$6 = 384개의 채널을 갖는다.
Trade-off hyper parameters
기본 모델은
- multiplier 1
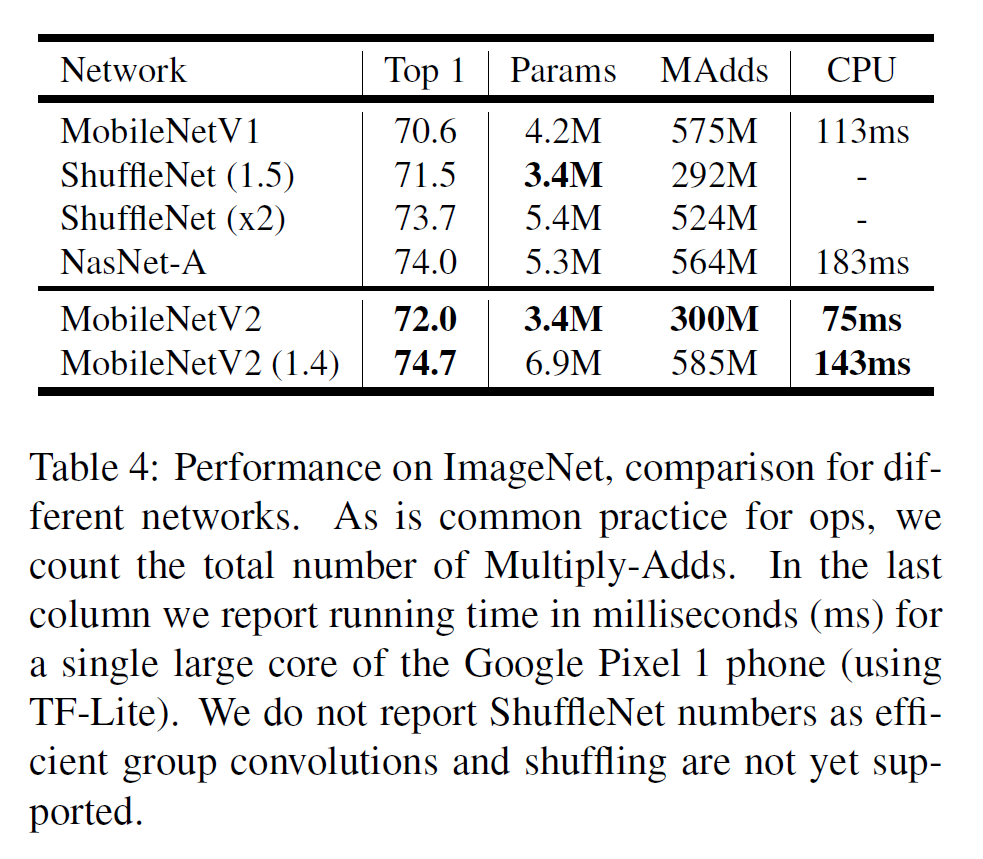
- 224$\times$224의 입력 크기
- 300M개의 multiply-adds(계산량)
- 3.4M개의 parameter
를 갖는다.
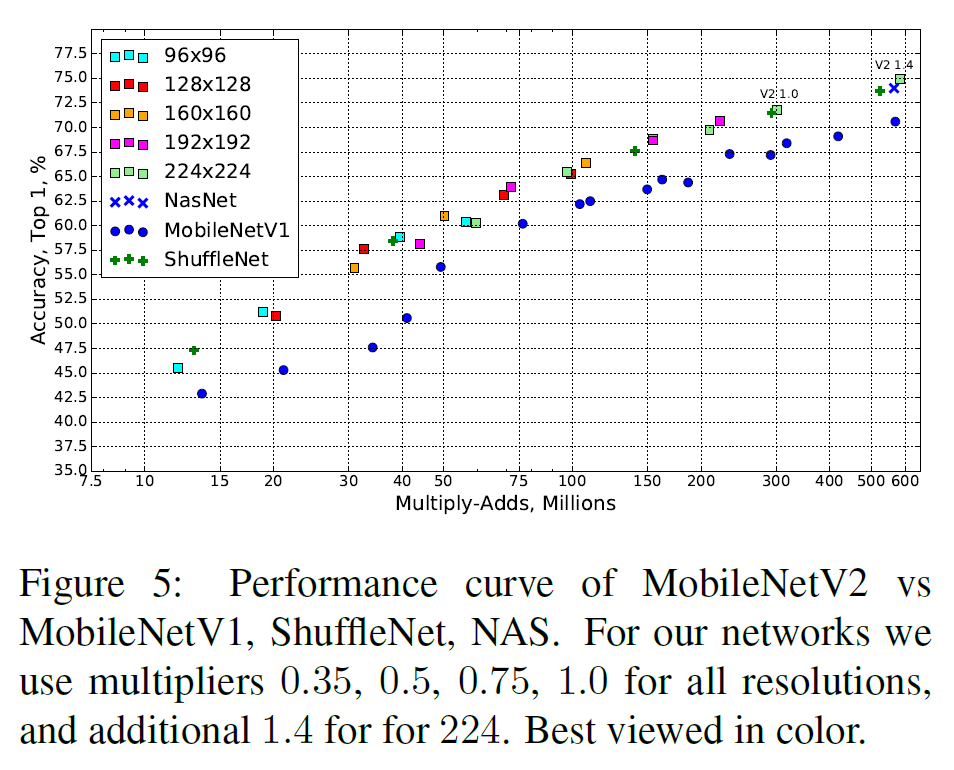
그리고 입력 크기나 multiplier를 달리하면서 모델 크기와 정확도 간 trade-off를 조절할 수 있다.

5. Implementation Notes
5.1. Memory efficient inference
Bottleneck Residual Block
메모리 사용량을 분석한 부분인데, 간략하게 결론 내리면 다음과 같다.
- 표 1에 있는 expantion ratio $t$는 2~5 정도로 잡는 것이 메모리 요구량을 크게 줄일 수 있는 방법이라고 한다.
6. Experiments
6.1. ImageNet Classification
RMSPropOptimizer, Tensorflow, weight decay 0.00004, learning rate 0.045, 16 GPU, batch size 96으로 실험하였다.
6.2. Object Detection
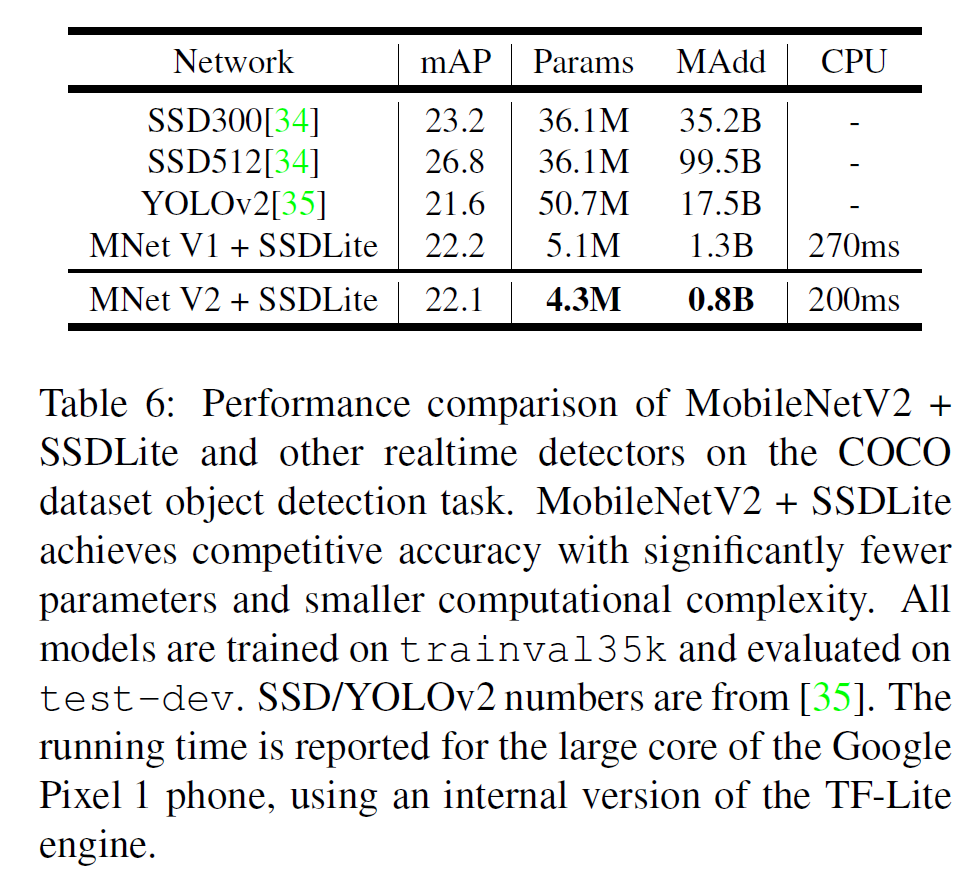
MobileNet와 잘 어울리는, SSDLite라는 것을 소개한다. 이는 기존 SSD의 기본 conv를 separable conv로 바꾼 것이다. 이는 기존보다 계산적인 효율을 높여 준다. 기존 SSD와 비교하여 parameter 수와 계산량을 획기적으로 줄여 준다.
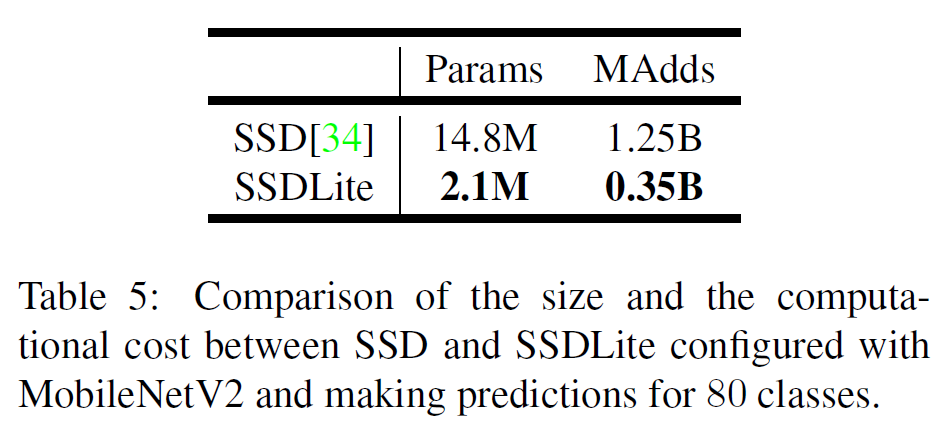
계산량, 성능, 모델 크기 등에서 MNet V2 + SSDLite가 다른 모델을 압도한다.
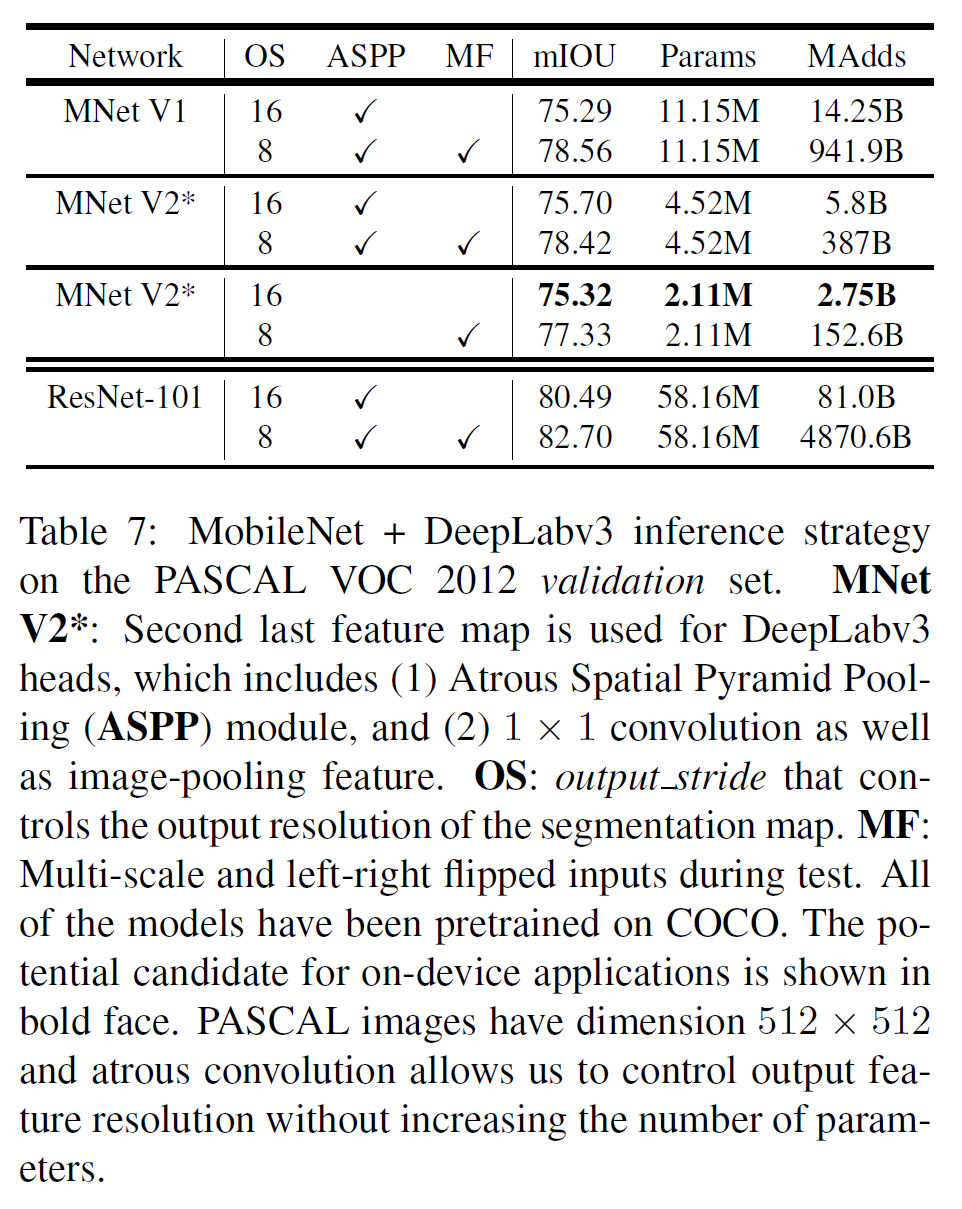
6.3. Semantic Segmentation
여기서는 MobileNet V1, V2를 feature extractor로서 사용하여 DeepLabv3와 같이 사용하여 실험하였다. PASCAL VOC 2012에서, ResNet base 모델에 비해 크게 작고 계산량이 적으며 성능도 괜찮다.
6.4. Ablation study
Inverted residual connection(fig 6a)와 Linear bottleneck(fig 6b)이 있고 없고의 차이를 아래 그림에서 딱 보여준다.
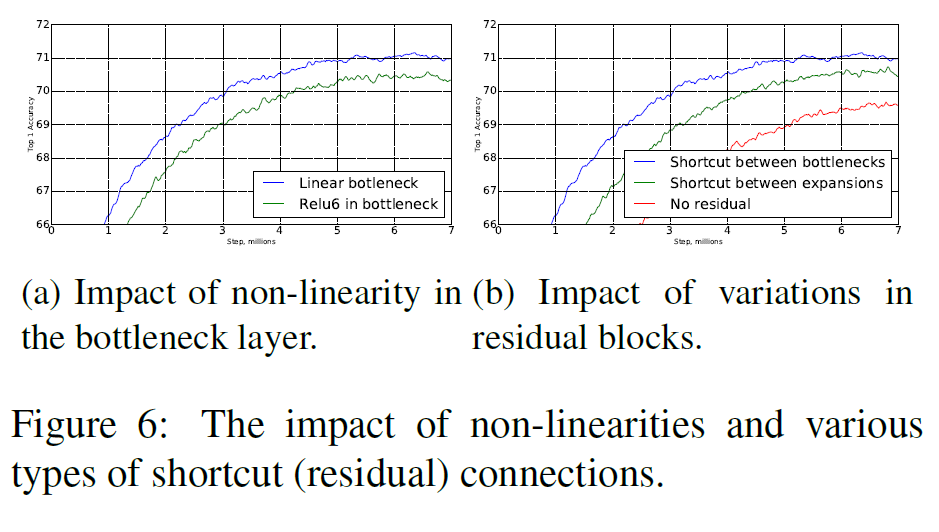
근데 사실 lienar bottleneck 모델은 non-linearaties를 갖는 모델과 비교하여 딱히 강력하다고 할 수 없다. 이는 activation은 bias와 scale 변화에 적절히 동작할 수 있기 때문이다.
그러나 fig 6a에서 보듯 lienar bottleneck은 성능을 향상시켜주며, 이는 비선형성이 저차원 공간에서 정보를 소실시키는 것을 뒷받침한다.
7. Conclusions and future work
메모리 효율(모델 크기), 계산량에서 크게 이점을 가지는 MobileNet V2를 제안하였다. 그러면서도 정확도는 떨어지지 않는 모습을 보여준다.