
MobileNetV1 논문 설명(MobileNets - Efficient Convolutional Neural Networks for Mobile Vision Applications 리뷰)
01 Feb 2022 | MobileNet Google목차
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
이 글에서는 Google Inc.에서 발표한 MobileNet V1 논문을 간략하게 정리한다.
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
논문 링크: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Github: https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet_v1.md
- 2017년 4월(Arxiv)
- Google Inc.
- Andrew G. Howard, Menglong Zhu et al.
모바일 기기에서 동작하는 것을 목표로 한, 성능을 별로 희생하지 않으면서도 모델을 크게 경량화하였다.
Abstract
모바일, embedded vision 앱에서 사용되는 것을 목적으로 한 MobileNet이라는 효율적인 모델을 제시한다. Depth-wise separable convolutions라는 구조에 기반하며 2개의 단순한 hyper-parameter를 가진다. 이 2가지는 사용되는 환경에 따라 적절히 선택하여 적당한 크기의 모델을 선택할 수 있게 한다. 수많은 실험을 통해 가장 좋은 성능을 보이는 설정을 찾았으며 타 모델에 비해 성능이 거의 떨어지지 않으면서 모델 크기는 몇 배까지 줄인 모델을 소개한다.
1. Introduction
ConvNet은 computer vision 분야라면 어디서든 사용되었지만(2017년 논문이므로 이 당시에는 vision에 Transformer를 쓰지 않았다.) 모델의 크기가 너무 커지고 가성비가 좋지 않다. 그래서 이 논문에서는 모델의 크기와 성능(low latency)을 적절히 선택할 수 있도록 하는 2개의 hyper-parameter를 갖는 효율적인 모델을 제시한다. 섹션 2에서는 지금까지의 작은 모델을, 섹션 3에서는 MobileNet을 설명한다. 섹션 4에서는 실험을, 5에서는 요약을 서술한다.
2. Prior Work
모델 크기를 줄이는 연구도 많았다. 크게 2가지로 나뉘는데,
- 사전학습된 네트워크를 압축하거나
- 작은 네트워크를 직접 학습하는 방식이다.
이외에도 모델을 잘 압축하거나, 양자화, hashing, pruning 등이 사용되었다.
MobileNet은 기본적으로 작은 모델이지만 latency를 최적화하는 데 초점을 맞춘다. MobileNets은 Depthwise separable convolutions을 사용한다.
3. MobileNet Architecture
MobileNet에서 가장 중요한 부분은 Depthwise Separable Convolution이다.
3.1. Depthwise Separable Convolution
Factorized convolutions의 한 형태로, 표준 convolution을
- Depthwise convolution(dwConv)과
- Pointwise convolution(pwConv, $1 \times 1$ convolution)
으로 쪼갠 것이다.
dwConv는 각 입력 채널당 1개의 filter를 적용하고, pwConv는 dwConv의 결과를 합치기 위해 $1 \times 1$ conv를 적용한다. 이와 비교해서 표준 conv는 이 2가지 step이 하나로 합쳐져 있는 것이라 보면 된다.
DSConv(depthwise separable convolution)은 이를 2개의 layer로 나누어, filtering을 위한 separate layer, combining을 위핸 separate layer로 구성된다. 이는 모델 크기를 많이 줄일 수 있게 해 준다.
이 과정을 시각화하면 다음과 같다. 각 큐브는 3차원의 필터 모양(혹은 parameter의 개수)을 나타내며, 표준 conv는 딱 봐도 큐브의 부피 합이 커 보이지만 dwConv와 pwconv는 하나 또는 2개의 차원이 1이므로 그 부피가 작다(즉, parameter의 수가 많이 적다).
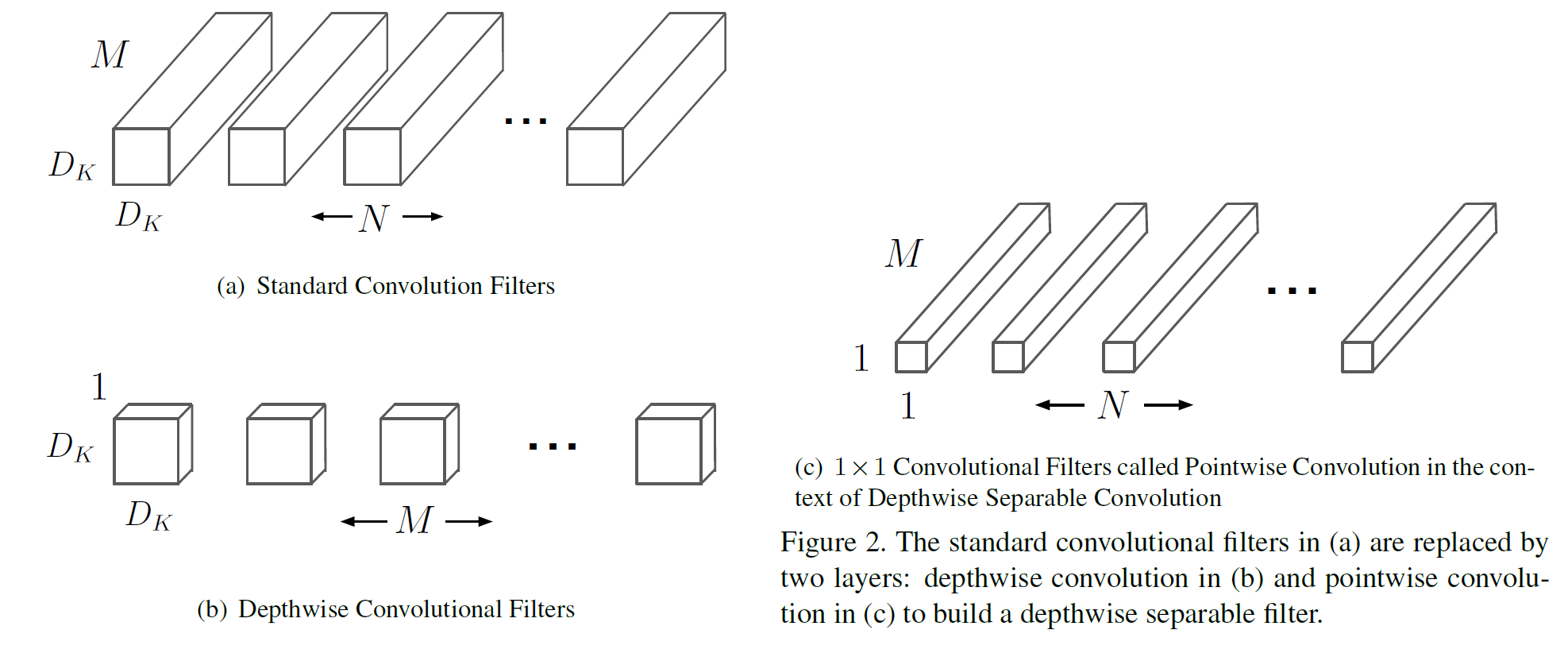
다르게 말해서 3차원적인 계산을 두 방향의 차원으로 먼저 계산한 후 나머지 한 차원을 그 다음에 계산하는 방식이라 생각해도 된다.
표준 conv의 입출력 크기는 다음과 같다.
- 입력 크기: $D_F \times D_F \times M$
- 출력 크기: $D_F \times D_F \times N$
그래서 표준 conv의 필터 개수는 그림 2에서 보듯이 $N$이다.
표준 conv의 연산량은 다음과 같다.
\[D_K^2 \cdot M \cdot N \cdot D_F^2\]- $D_F$: 입력 Feature map의 너비와 높이
- $D_K$: Kernel의 크기
이와 비교해서 DSConv의 연산량은 다음과 같다.
\[D_K^2 \cdot M \cdot D_F^2 + M \cdot N \cdot D_F^2\]연산의 비율은 다음과 같이 계산된다.
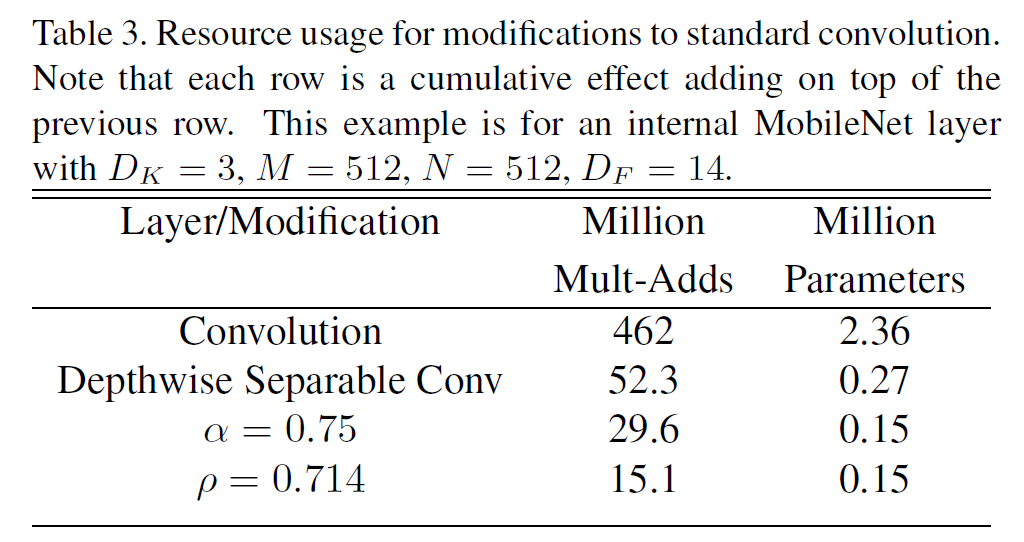
\[\frac{1}{N} + \frac{1}{D_K^2}\]$N$은 보통 큰 편이므로 첫 항은 거의 무시되고, MobileNet에서 $D_K=3$을 사용하므로 연산은 8~9배 가량 줄어든다.
참고로 spatial 차원에서 한 번 더 쪼개는 것은 연산량을 거의 줄여주지 못한다(즉 2+1을 1+1+1로 계산하는 것은 별 의미가 없다).
3.2. Network Structure and Training
표준 Conv와 DSConv layer의 구조를 비교하면 아래 그림과 같다. $1 \times 1$ conv가 pwConv이다.

MobileNet은 맨 처음 layer를 full conv로 쓰는 것을 제외하면 전부 DSConv로 사용한다. dwConv는 표에는 Conv dw라고 표시되어 있다. $1 \times 1$ conv를 수행하는 부분이 pwConv이다.
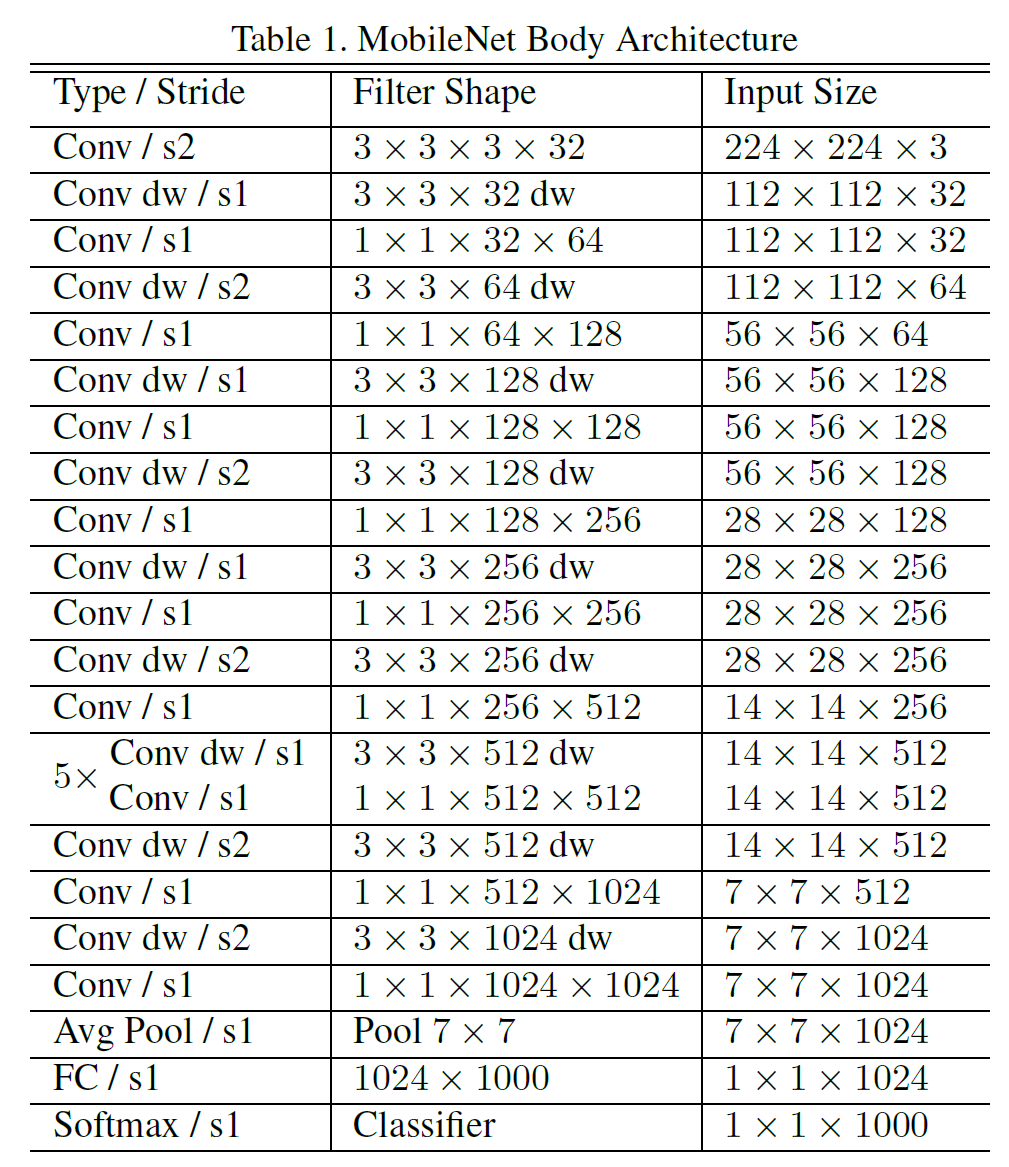
Tensorflow, 그리고 Inception V3와 비슷하게 asynchronous gradient descent를 사용하는 RMSProp로 학습을 진행하였다.
DSConv에는 parameter가 별로 없어서 weight decay는 거의 또는 전혀 사용하지 않는 것이 낫다고 한다.
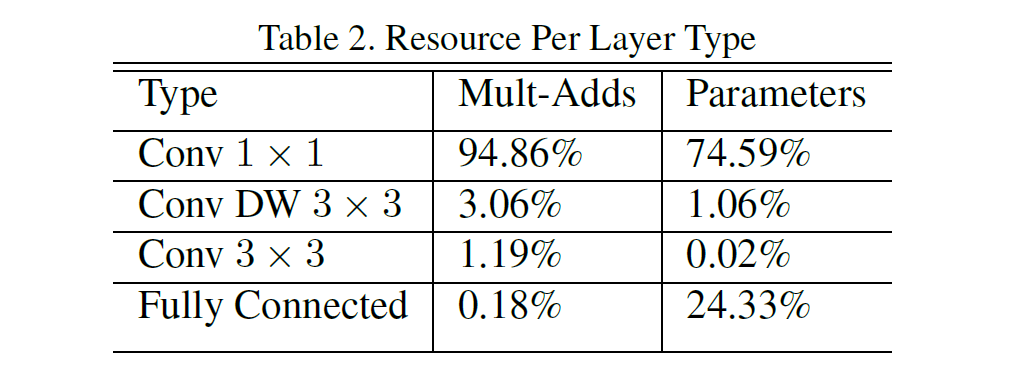
3.3. Width Multiplier: Thinner Models
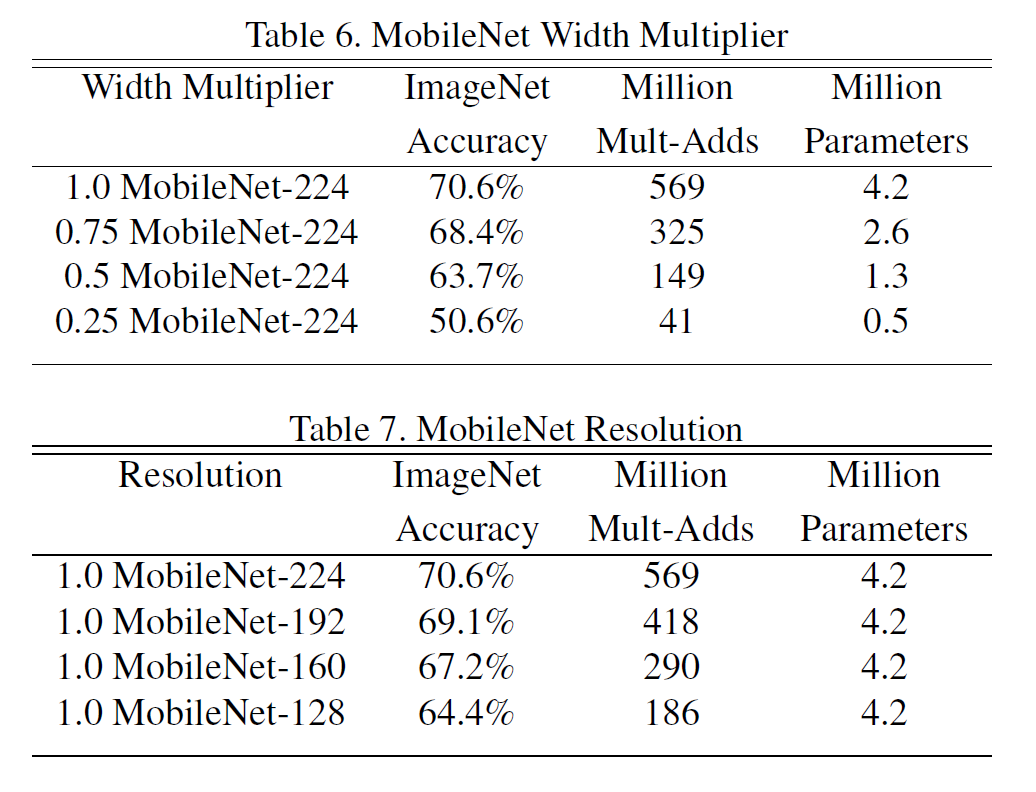
이미 충분히 작지만 더 작고 빠르고 만들어야 하는 경우가 있다. Width multiplier라 부르는 $\alpha$라는 hyper-parameter는 각 layer마다 얼마나 (전체적으로 다) 얇게 만드는지를 결정한다. 입출력 채널 수는 $M, N$에서 $\alpha M, \alpha N$이 된다. $\alpha \in (0, 1]$이고 0.75, 0.5, 0.25등의 값을 쓸 수 있다. $\alpha=1$은 기본 MobileNet이다. 이 $\alpha$를 통해 얼마든지 작은 시스템에도 모델을 집어넣어 사용할 수 있다. 물론 정확도, latency, 크기 사이에는 trade-off가 존재한다.
3.4. Resolution Multiplier: Reduced Representation
두 번째 hyper-parameter는 해상도에 관한 multiplier $\rho$이다. 입력 이미지와 각 레이어의 내부 표현 전부를 이 multiplier를 곱해 줄인다. 이 역시 $\alpha$와 비슷하게 $\rho \in (0, 1]$이고 보통 이미지 해상도를 224, 192, 160, 128 정도로 만들게 한다. 계산량은 $\rho^2$에 비례하여 줄어든다.
4. Experiments
MobileNet을 여러 multiplier 등 여러 세팅을 바꿔가면서 실험한 결과인데, 주로 성능 하락은 크지 않으면서도 모델 크기나 계산량이 줄었음을 보여준다. 혹은 정확도는 낮아도 크기가 많이 작기 때문에 여러 embedded 환경에서 쓸 만하다는 주장을 한다.
4.1. Model Choices
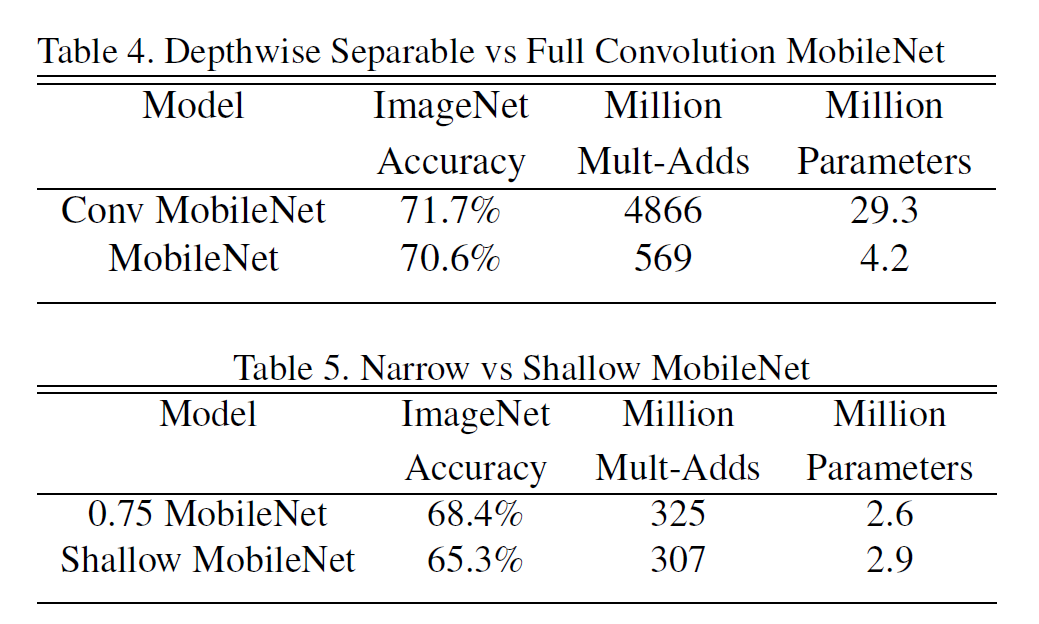
Full conv와 DSConv의 차이는 명확하다. 정확도는 1%p 낮지만, 모델 크기는 7배 이상 작다.
또 Narrow와 Shallow MobileNet을 비교하면 아래와 같다. (깊고 얇은 모델 vs 얕고 두꺼운 모델)
4.2. Model Shrinking Hyperparameters
모델이 작을수록 성능도 떨어지긴 한다.
계산량과 성능 상의 trade-off는 아래처럼 나타난다. 계산량이 지수적으로 늘어나면, 정확도는 거의 선형적으로 늘어난다.
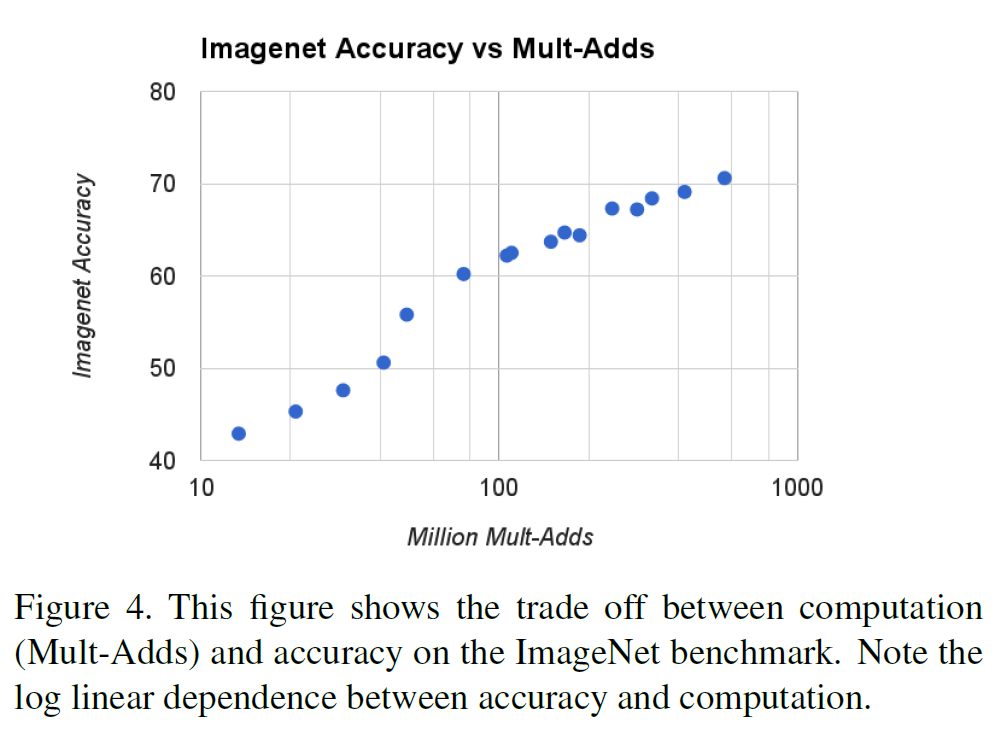
정확도, 계산량, 모델 크기를 종합적으로 비교해보자.
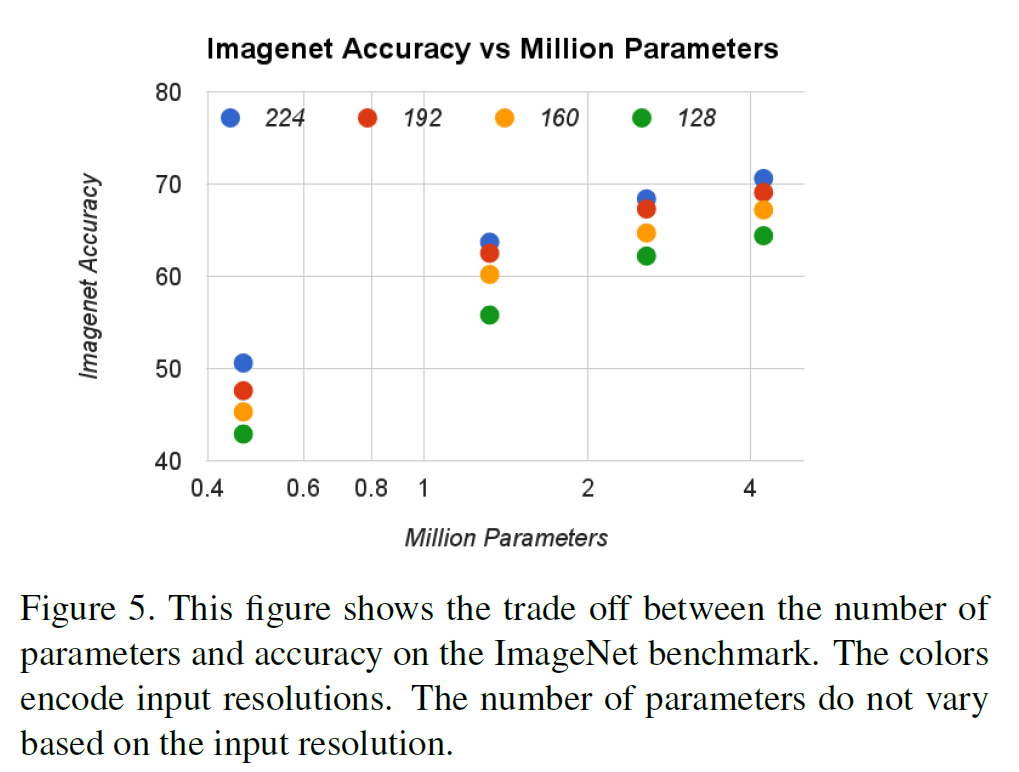
다른 모델(GoogleNet, VGG16 등)과 비교했을 때 MobileNet은 성능은 비슷하면서 계산량과 모델 크기에서 확실한 우위를 점한다.
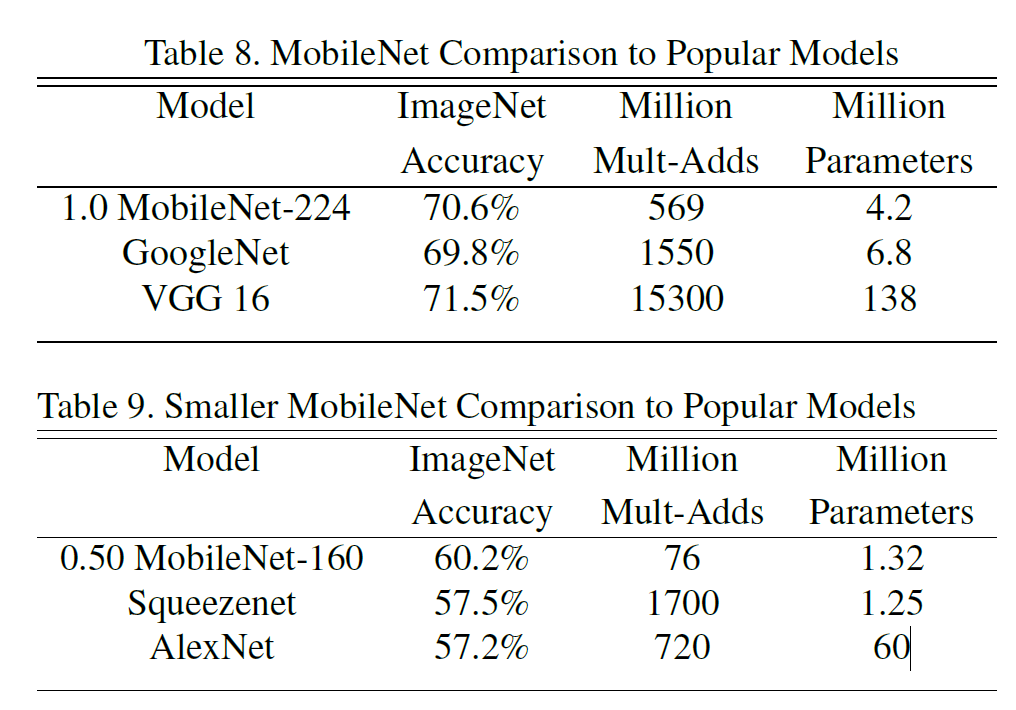
4.3. SFine Grained Recognition
웹에서 얻은 대량이지만 noisy한 데이터를 사용하여 학습한 다음 Stanford Dogs dataset에서 테스트해보았다.
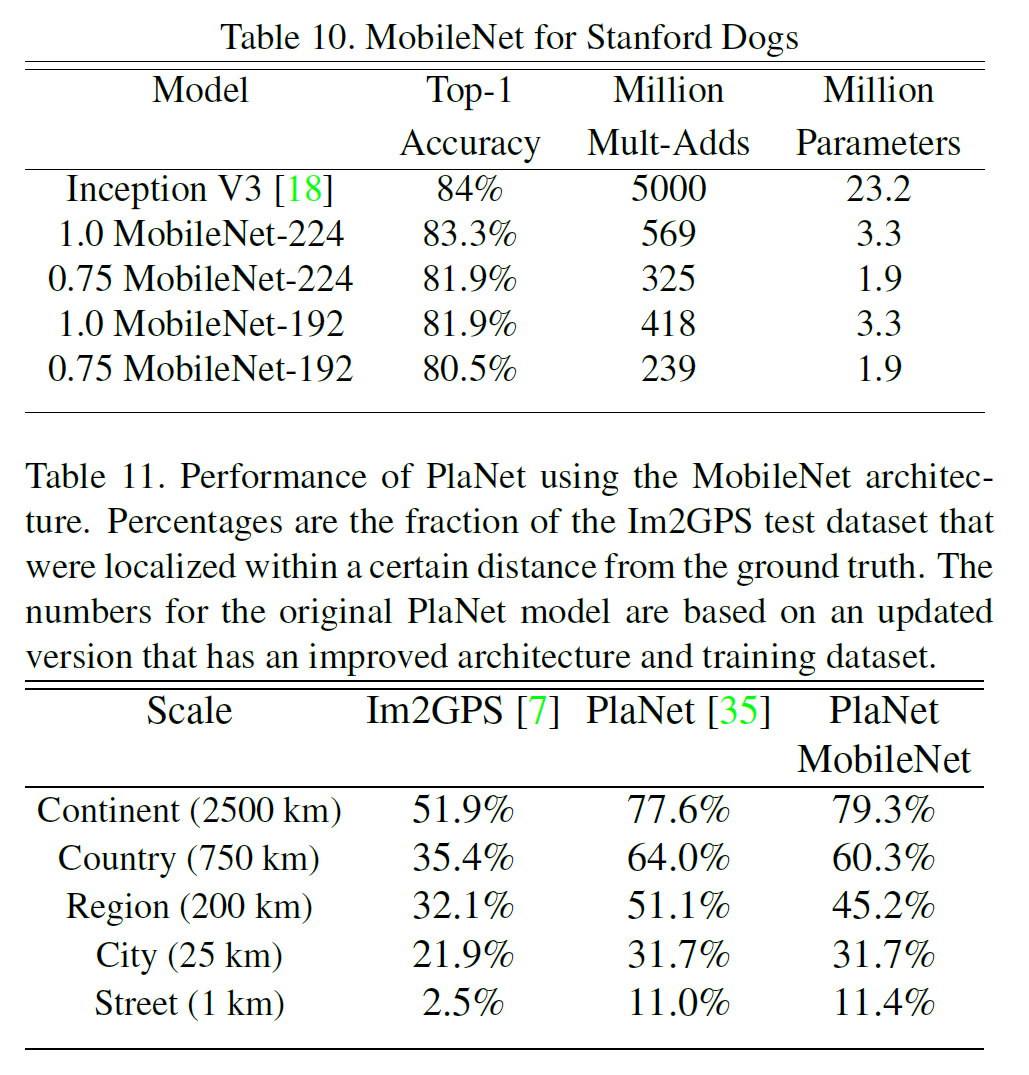
4.4. Large Scale Geolocalizaton
PlaNet을 geo-tagged 사진들로 MobileNet 구조로 재학습시켜 테스트한 결과는 위의 표 11에 나와 있다.
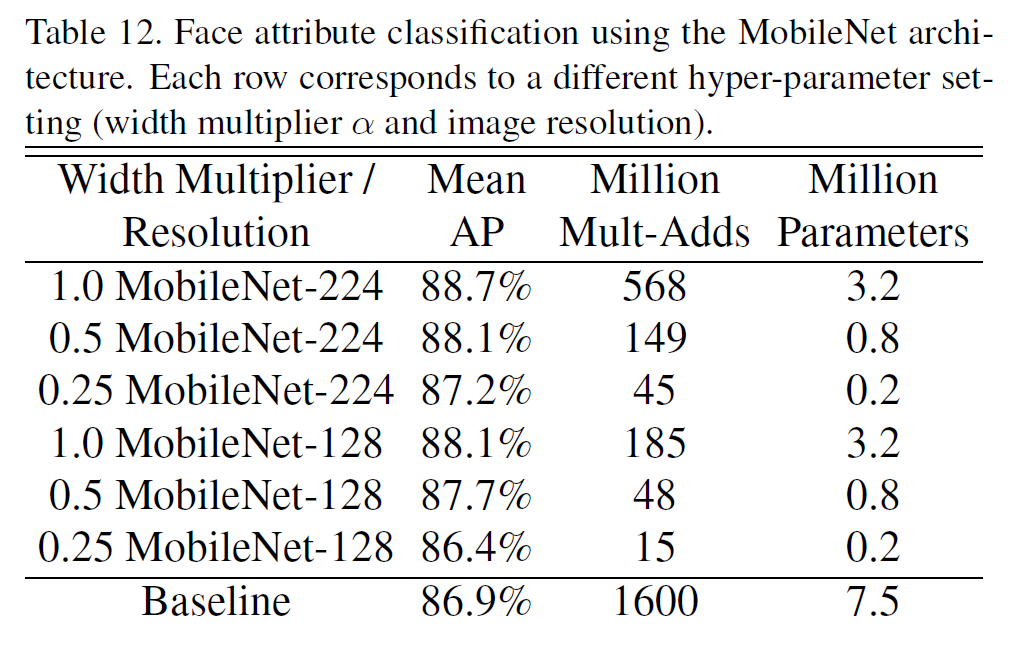
4.5. Face Attributes
MobileNet의 또 다른 쓸모 있는 점은 전혀 또는 거의 알려져 있지 않은(unknown or esoteric) 학습 과정을 가진 큰 모델을 압축할 수 있다는 것이다. MobileNet 구조를 사용하여 얼글 특징 분류기에서 distillation을 수행했는데, 이는 분류기가 GT label 대신에 더 큰 모델의 출력값을 모방하도록 학습하는 방식으로 작동한다. 기본 모델에 비해 최대 99%까지 연산량을 줄이면서도 성능 하락은 별로 없는 것을 볼 수 있다.
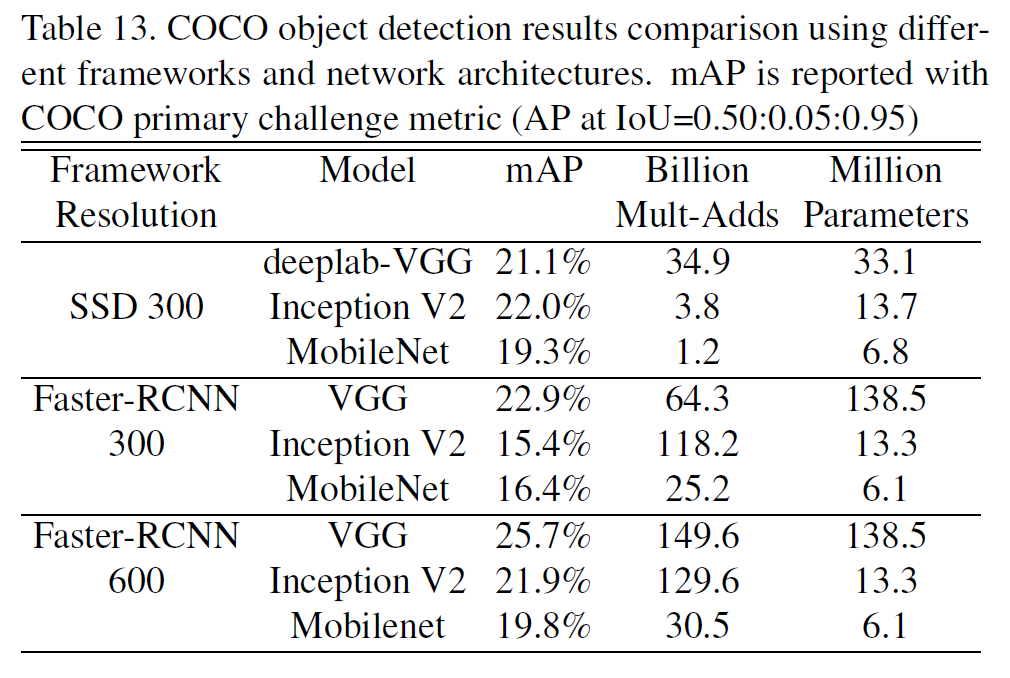
4.6. Object Detection
MobileNet을 물체 인식에도 적용시켜서 Faster-RCNN 등과 비교해 보았다. 이 결과 역시 모델 크기나 연산량에 비해 성능이 좋다는 것을 보여주고 있다.
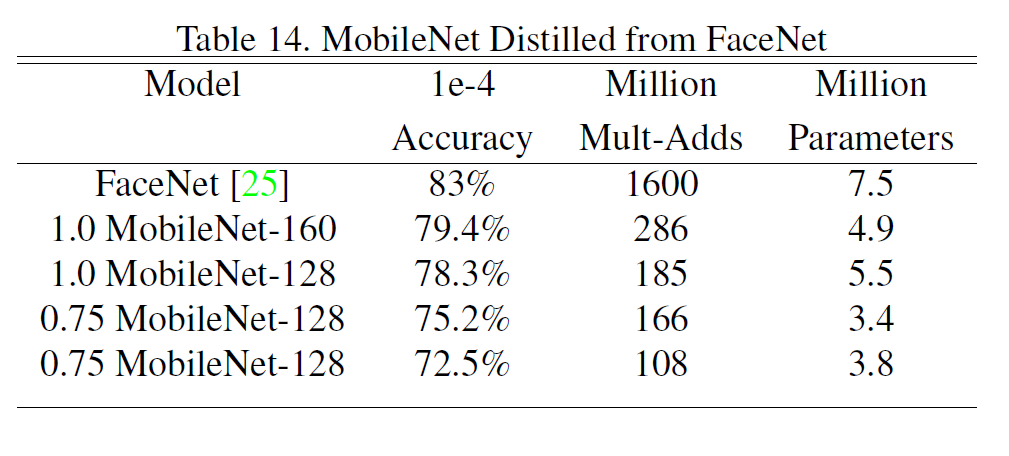
4.7. Face Embeddings
얼굴인식 모델에서 FaceNet은 SOTA 모델인데, 적절히 distillation을 수행한 결과, 성능은 조금 낮으나 연산량을 고려하면 만족할 만한 수준인 것 같다.
5. Conclusion
Depthwise Separable Convolutions을 사용한 경량화된 모델 MobileNet을 제안하였다. 모델 크기나 연산량에 비해 성능은 크게 떨어지지 않고, 시스템의 환경에 따라 적절한 크기의 모델을 선택할 수 있도록 하는 여러 옵션(multiplier)를 제공하였다.