
Learning to Retrieve Videos by Asking Questions 논문 설명
10 Aug 2022 | Video Retrieval Learning by Asking목차
- Learning to Retrieve Videos by Asking Questions
이 글에서는 Learning to Retrieve Videos by Asking Questions 논문을 간략하게 정리한다.
Learning to Retrieve Videos by Asking Questions
논문 링크: Learning to Retrieve Videos by Asking Questions
- 2022년 6월(Arxiv)
- Avinash Madasu, Junier Oliva, Gedas Bertasius
Abstract
전통적인 text-to-video retrieval은 정적인(static) 환경에서만 진행되어 왔다(첫 query가 주어지고 나면 답을 찾을 때까지 유저와 어떠한 상호작용도 없다). 이는 query가 모호한 경우 적절한 영상을 찾아오는 데 있어 특히 문제될 수 있다. 이 한계를 극복하기 위해 본 논문에서는 Video Retrieval using Dialog(ViReD)를 위한 새로운 framework를 제시하여 유저가 여러 턴에 걸쳐 agent와 상호작용(질문 및 응답)할 수 있게 하여 유저가 정말로 원하는 영상을 찾을 수 있도록 한다.
본 논문에서 제안하는 multimodal question generator는 다음을 사용하여 차후 video retrieval 성능을 높인다:
- 유저와의 상호작용 중 마지막 round 동안 얻은 video 후보들
- 이전의 모든 상호작용에서 얻은 텍스트 대화 history
이를 조합하여 video retrieval과 연관된 시각적/언어적 단서를 찾는다.
또한 질문을 통해 최대한 많은 정보를 얻기 위해 question generator가 더 의미 있는 질문을 생성하도록 Information-Guided Supervision(IGS) 라는 방법을 제안한다.
AVSD 데이터셋에서 제안하는 모델을 평가하여 괜찮은 성능을 얻고 video retrieval에서 효과가 있음을 보인다.
CCS CONCEPTS
Computing methodologies → Visual content-based indexing and retrieval.
KEYWORDS
interactive video retrieval, dialog generation, multi-modal learning
1. Introduction
처음에 query만 하나 던져주고 원하는 video를 찾아오는 것은 query 자체가 정보가 부족하거나 모호할 수 있기 때문에 제약사항이 많다. 그래서 본 논문에서는 단 한번의 query만 받는 것이 아닌 여러 차례 상호작용을 수행하여 좀 더 정확하게 video retrieval task를 수행하는 것을 목표로 한다.
예를 들어 어떤 “요리하는 영상”을 찾는다는 query를 생각해보자. 전통적인 방식으로는 요리 영상이라면 그냥 다 찾아오고 말겠지만 다음과 같이 지속적인 상호작용을 통해:
- Q1: “어떤 요리?”
- A1: “지중해식 요리”
- Q2: “육류? 채소류?”
- A2: “채소류”
유저가 더 원할만한 영상을 더 정확하게 찾을 수 있을 것이다.
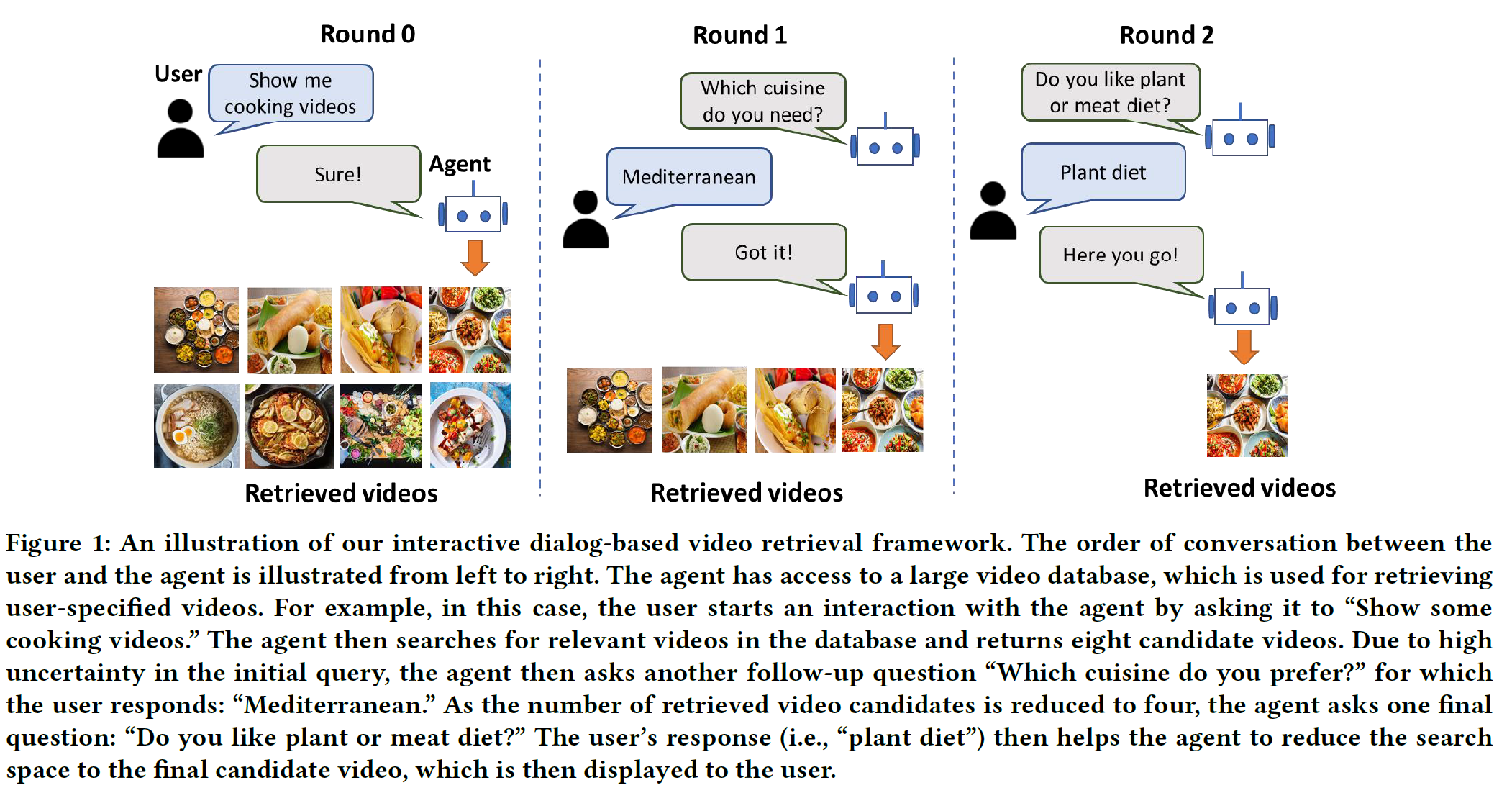
물론 기존에도 상호작용을 포함한 연구들은 있었다. 그러나 보통은 지나치게 많은 round를 (e.g. >5) 요구하는 등의 문제가 있었다. 저자들은 본 연구에서는 2~3번의 상호작용만으로 목적을 달성할 수 있다고 한다. 여기서 초록에서 언급한 Information-Guided Supervision(IGS) 가 중요한 역할을 한다.
2. Related Work
2.1 Multimodal Conversational Agents
특히 image-based visual dialog에서 많은 진척이 있었다. 그러나 대체로 정적인 환경에서 이루어졌다는 단점이 있다.
2.2 Video Question Answering
이미지에 이어 VQA는 영상 또한 다루며 시간적인 정보가 포함되므로 더 도전적인 과제이다. 최근에는 Vx2Text라는 Transformer 기반 multi-modal generative network가 제안되었다.
2.3 Multimodal Video Retrieval
DNN에 기반한 연구, Transformer 기반 모델 등이 제안되어 왔다. 역시 보통은 정적인 환경에서 수행되었다. (계속 본 논문이 상호작용이 있으므로 더 좋다는 주장. 논문에서 필요한 부분이기도 함)
2.4 Interactive Modeling Techniques
- Ishan et al. 의 논문에서는 VQA를 위한 상호작용 학습 framework를 제안하였다. visual question에 대답하기 위한 정보를 oracle에게 능동적으로 요구한다.
- 이미지뿐 아니라 비디오에서도 interactive한 모델들이 video browser showdown (VBS) benchmark를 위해 제안되었다.
- 이러한 연구들은 original search query와 연관된 추가적인 정보를 유저로부터 얻기 위해 interactive한 interfaces를 사용하였다. 이는 attribute-like sketches, temporal context, color, spatial position, cues from the Kinect sensors 등의 정보를 포함한다.
- 이와 비교하여, 본 논문에서 제시하는 대화 기반 video retrieval framework에서 이들 접근법에 대해 상호보완적이다. 특히, 위에 나열한 단서들(sketches 등)과 대화 내용을 결합하는 것은 분명히 video retrieval 정확도를 높여 줄 것이라 믿는다고 저자들은 밝히고 있다.
3. Video Retrieval using Dialog
여기서는 본 논문에서 제시하는 framework인 ViReD를 소개한다.
task의 목표는
- 유저의 initial text query $T$와
- 직전까지 생성된 dialogue history $H_{t-1}$가 주어지면
- 가장 연관성이 높은 $k$개의 영상 $V_1, V_2, …, V_k$ 을 찾는 것
이전 연구들과의 차이점을 간단히 아래 그림에 나타내었다.
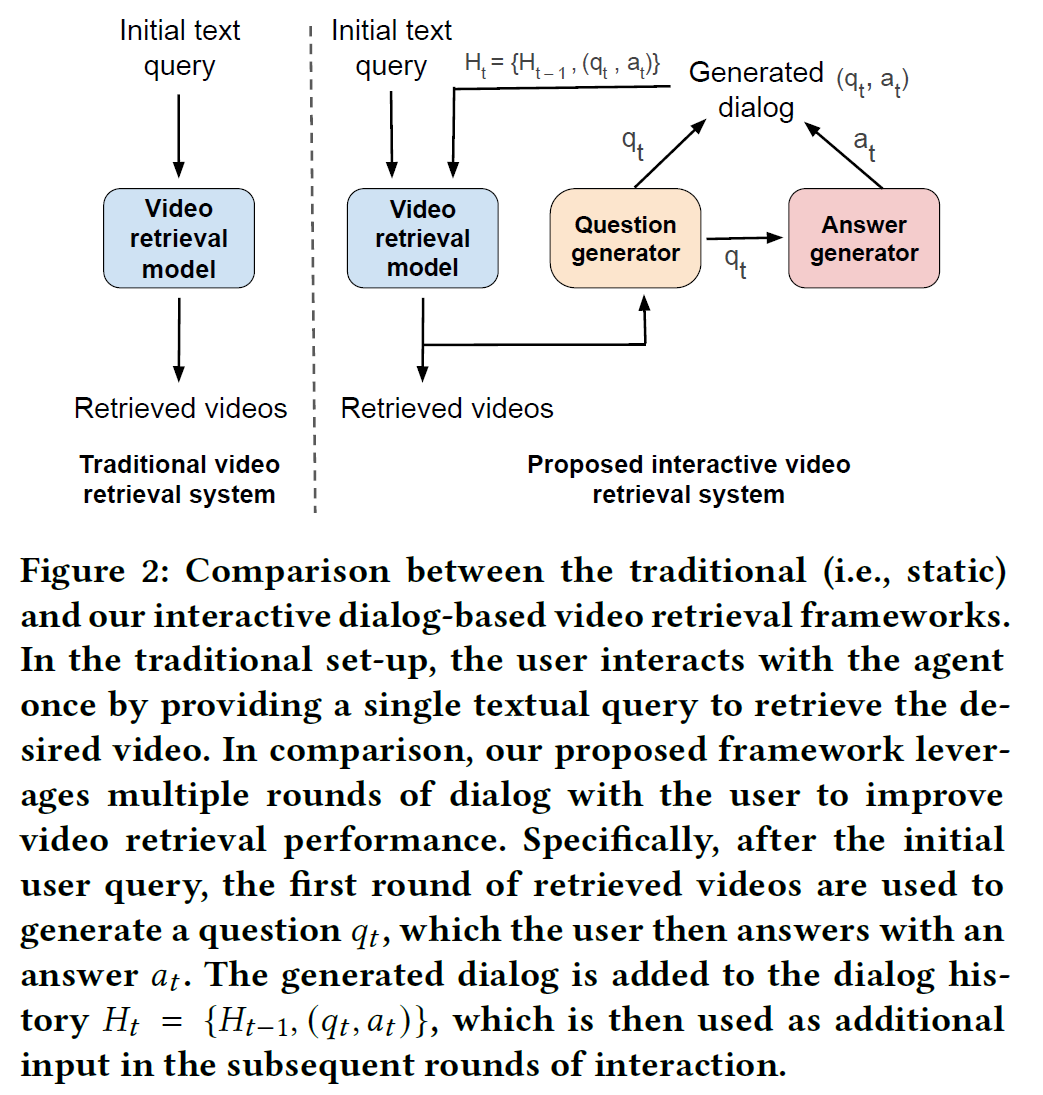
요약하면, video retrieval 모델은 처음 query만 갖고 영상을 찾는 것이 아니라 query와 이전 history를 참조해서 도움이 될 만한 정보를 얻기 위한 질문을 생성하고, 거기에 맞는 답을 생성하고, 이를 여러 차례 반복한 뒤 최종적으로 관련성 있는 영상을 찾는 방식이다.
3.1 Question Generator
Question Generator는 다음 입력을 가지고 있다.
- initial text query $T$
- $t-1$ 시점에 찾아놓은 top $k$의 영상
- 직전까지 생성된 대화 로그(dialogue history) $H_{t-1}$
영상 정보를 매번 처리하긴 힘드니 AVSD 데이터셋에서 학습된 Vid2Sum video caption model을 사용하여 비디오에 대한 요약문을 생성한다. 즉 영상 $V_1, …, V_k$를 요약문 $S_1, …, S_k$로 치환한다.
이들(query, $k$개의 영상 요약문, 대화 로그)을 모두 붙여서 새로운 입력을 얻고,
\[X_q = \text{Concat}(T, S_1, ..., S_k, H_{t-1})\]이를 autoregressive language model인 BART의 생성 모델에 집어넣는다.
\[q_t = \text{BART}_q(X_q)\]3.2 Answer Generation Oracle
사람이 상호작용하며 대답하는 상황을 모방하려 하였다. 여기서 사용하는 방식은 꽤 폭넓게 쓰일 수 있다.
Answer Generator는 다음 입력을 갖고 있다.
- $i$번째 영상 $V_i$
- 이 영상에 대해 Question Generator가 생성한 질문 $q_t$
Question Generator와 비슷하게 Vid2Sum을 사용하여 요약문 $S_i$를 얻고, 이어 붙인 다음 역시 BART에 집어넣는다.
\[X_a = \text{Concat}(S_i, q_t)\] \[a_t = \text{BART}_a(X_a)\]note: BART는 동일한 구조를 갖지만 weights는 다른 question generator와 answer generator, 두 가지 모델이 있다.
이렇게 각 질문 $q$와 대답 $a$를 $t$ round에 걸쳐서 수행하면 dialogue history를 얻을 수 있다.
\[H_t = (\lbrace q_1, a_1 \rbrace, \lbrace q_2, a_2 \rbrace, ..., \lbrace q_t, a_t \rbrace).\]생성된 dialog history $H_t$는 이후 video retrieval framework의 추가 입력으로 들어가게 된다.
3.3 Text-to-Video Retrieval Model
VRM(video retrieval model) 은 다음 입력을 받는다.
- initial text query $T$
- 이전 dialog history $H_t$
출력은
- $[T, H_t]$와 각 영상 $V^{(i)}$와의 (정규화된) 유사도를 encode하는 확률분포 $p \in \mathbb{R}^N$
즉
\[p = \text{VRM}(T, H_t)\]$p_i$는 $i$번째 영상 $V^{(i)}$이 입력된 textual query $[T, H_t]$가 얼마나 연관되어 있는지를 나타낸다.
VRM은 2가지 주요 구성요소를 가진다. $\theta$는 학습가능한 parameter이다.
- visual encoder $F(V; \theta_v)$
- textual encoder $G(T, H_t; \theta_t)$
학습하는 동안, 수동으로 labeling된 video retrieval 데이터셋 $\mathcal{X} = \lbrace(V^{(1)}, T^{(1)}, H_t^{(1)}), …, (V^{(N)}, T^{(N)}, H_t^{(N)}))$이 있다고 가정한다. $T^{(i)}, H_t^{(i)}$는 각각 영상 $V^{(i)}$에 대한 text query와 dialog history를 나타낸다.
- visual encoder는 video transformer encoder를 사용하여 visual representation $f^{(i)} = F(V^{(i)}; \theta_v), f^{(i)} \in \mathbb{R}^d$를 얻는다.
- textual encoder는 DistilBERT를 사용하여 textual representation $g^{(i)} = G(T^{(i)}, H_t^{(i)}; \theta_t), g^{(i)} \in \mathbb{R}^d$를 얻는다.
visual과 textual encoder를 같이 학습시키는데, 목적함수는 video-to-text와 text-to-video matching loss의 합을 최소화하는 것을 사용한다.
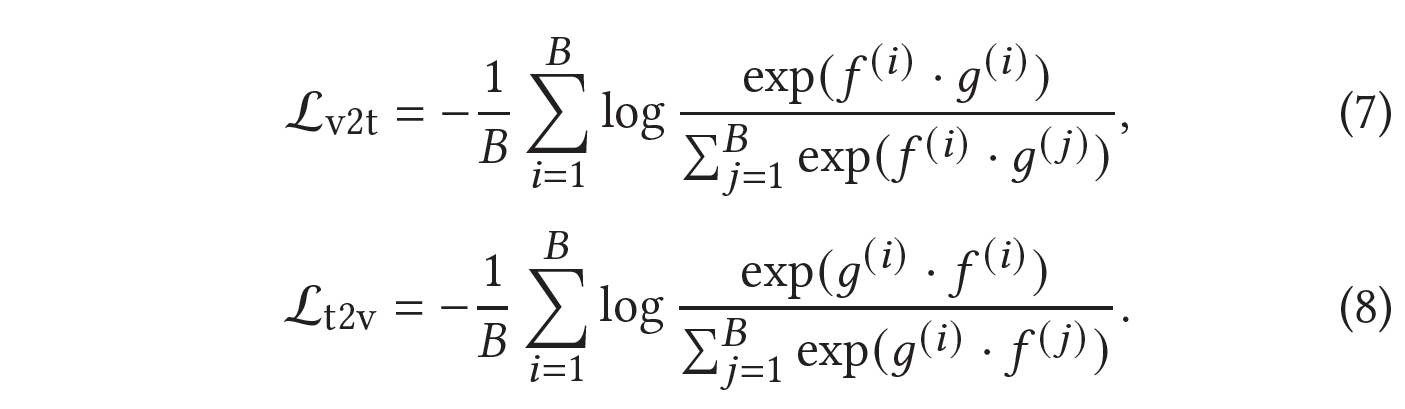
- $B$는 batch size
- $f^{(i)}, g^{(j)}$는 $i$번째 영상, $j$번째 영상에 대한 text embedding을 나타낸다.
여기서 각 batch 내의 text-video($i, i$) 쌍은 positive, 나머지 전부($i, j$)는 negative로 사용하였다.
추론하는 동안에는,
- 학습된 textual encoder로 $g = G(T, H_t; \theta_t), g \in \mathbb{R}^{1 \times d}$를 추출한다.
- $N$개의 모든 영상 $V^{(i)}$에 대해 visual embedding $f^{(i)} = F(V^{(i)}; \theta_v)$를 얻는다.
- visual embedding들을 전부 쌓아서 single feature matrix $Y = [f^{(1)}, …, f^{(N)}],Y \in \mathbb{R}^{N \times d}$를 얻는다.
- single textual embedding $g$와 visual embeddings $Y$를 normalized dot product하여 video retrieval 확률분포 $p \in \mathbb{R}^{1 \times N}$을 계산한다.
즉,
\[p = \text{Softmax}(gY^\top)\]앞으로는 단순하게 나타내기 위해 $p = \text{VRM}(T, H_t)$와 같이 쓴다.
4. Information-Guided Supervision for Question Generation
상호작용 중 질문을 함으로써 최대한 많은 정보를 얻으려는 노력은 반드시 필요하다. 이때 Question Generator는 다음에 대한 이해를 하고 있어야 한다:
- 이미 얻은 정보(e.g. initial query와 dialogue history)
- 유저에게 전달할, 잠재적인 가능성이 있는 영상들에 대한 현재 belief 및 모호성(이는 현재까지 찾아놓은 top $k$개의 후보 영상들을 통해 얻는다)
- 새로운 질문을 통해 얻게 된 잠재적인 정보 획득(e.g. 특정 질문을 함으로써 획득하게 될 것이라고 기대되는 성능 향상)
이를 위해 RL 방법 등이 도입되었으나 본 문제에서 다루는, 취할 수 있는 action이 너무 많고(자유형식 자연어 질문은 무한하다) 얻을 수 있는 피드백은 한정적인(성능이 몇 %나 향상되었는가) 상황에서는 큰 도움이 되지 못한다. 그래서 본 논문에서는 information-guided question generation supervision (IGS) 를 제안한다.
각 영상 $V^{(1)}, i \in \lbrace 1, …, N \rbrace$에 대해서 사람이 만든 QA가 각 $m$개씩 있다고 가정한다.
\[D^{(i)} = \lbrace D_1^{(i)}, ..., D_m^{(i)} \rbrace\]AVSD 데이터셋처럼 각 영상에 대해 독립적으로 데이터가 모아져 있다.
여기서 IGS를 통해 “가장 많은 정보를 얻을 수 있는” 질문을 고르는 과정을 거친다.
$T^{(i)}$를 $V^{(i)}$에 대한 textual initial query라 하자. 그리고 $t$번째 round의 dialogue history $H_t^{(i)}$를 얻은 이후 지금까지 골라 놓은 top-$k$ 영상에 대한 요약문 $S_{t, 1}^{(i)}, …, S_{t, k}^{(i)}$을 얻는다.
여기서, 질문/답변 생성기에서 생성한 $(q, a)$를 $D^{(i)}$에 그대로 넣지 않고, retrieval 성능을 가장 높일 수 있을 만한 qa 쌍을 찾아 history에 추가한다.
즉
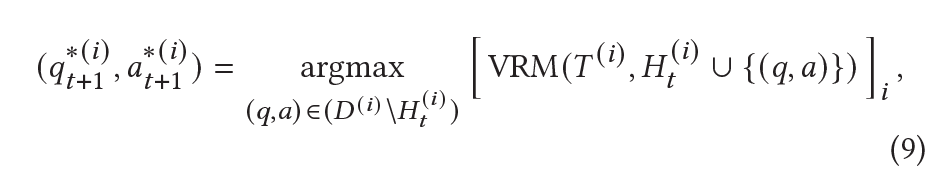
여기서 argmax의 항은 $p_i$와 같다. 이 과정을 통해 얻은 “best question”은 $t+1$번째 round에서 생성할 question의 target이 된다.
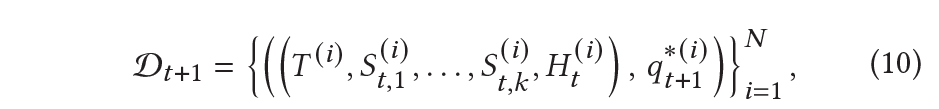
$T, S, H$를 concat해서 $\text{BART}_q$의 입력으로 주게 된다.
target 질문/대답은
\[H_{t+1}^{(i)} = H_t^{(i)} \cup \lbrace(q_{t+1}^{*(i)}, a_{t+1}^{*(i)}) \rbrace\]로 추가되며 $t+2$ round도 비슷하게 진행된다.
여기서 $\mathcal{D}_{t+1} $는
$\mathcal{D}_{t}$에 의존하므로 질문을 생성할 때는 이전 history를 고려하며 생성하게 된다.
즉 각 round마다 이전 기록을 고려하며 가장 informative한 질문을 생성할 수 있게 된다.
또 $\mathcal{D}_1 \cup \mathcal{D}_2 \cup … \cup \mathcal{D}_M $은
question generator($\text{BART}_q$)의 supervised 데이터셋으로 작용한다.
5. Experiments
5.1 Dataset
- AVSD 데이터셋 사용
- 7,985 train, 863 val, 1,000 test video
5.2 Implementation Details
5.2.1 Question Generator
- $\text{BART}_{\text{large}}$ 사용
- 질문 최대 길이 120
- size 10의 beam search
- batch size 32
- 5 epochs
5.2.2 Answer Generator
- $\text{BART}_{\text{large}}$ 사용
- 답변 최대 길이 135
- size 8의 beam search
- batch size 32
- 2 epochs
5.2.3 Video Retrieval Model
- Frozen-in-Time(FiT) codebase 사용
- 20 epochs, batch size 16, early stopping for 10 epochs
- AdamW optimizer($3e^{-5}$)
5.2.4 Vid2Sum Captioning Model
- 5 epochs, 문장 최대길이 25
5.3 Evaluation Metrics
- Recall@k($k = 1, 5, 10$), MedianR, MeanR 사용
- Recall@k는 $k$개의 후보 영상 중 실제 정답 영상이 포함되는지를 가지고 평가함(높을수록 좋다)
- MeanR과 MedianR은 실제 정답 영상이 후보 영상 중 몇 번째에 나타냈는지 평균과 중간값을 내는 것으로 낮을수록 좋다.
- 3번씩 실험하여 평균함
5.4 Video Retrieval Baselines
- LSTM
- Frozen-in-Time
- Frozen-in-Time w/ Ground Truth Human Dialog
6. Results and Discussion
6.1 Quantitative Video Retrieval Results
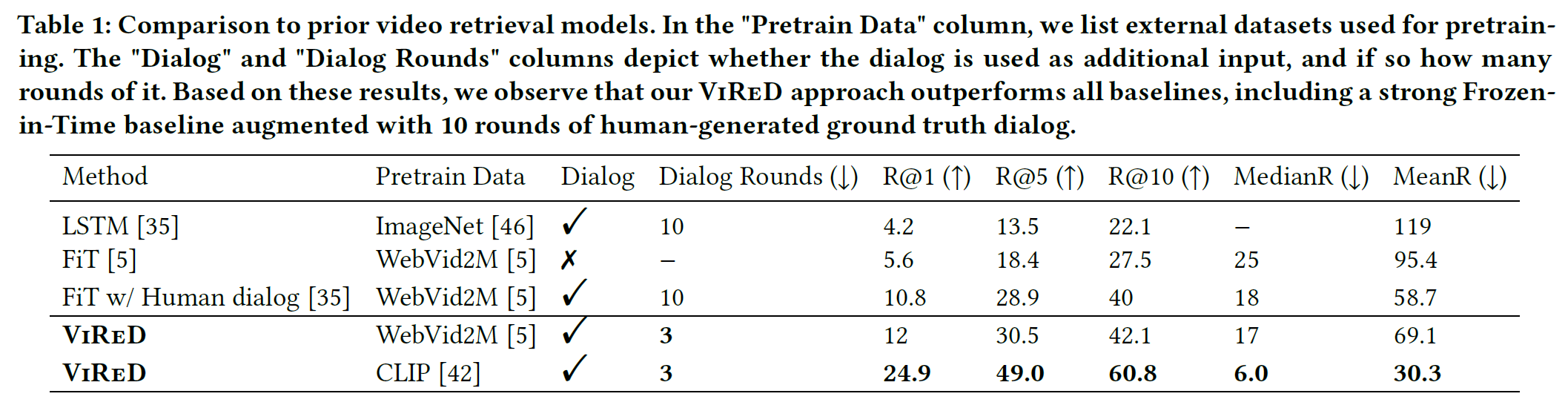
- Pretraining한 FiT가 LSTM을 크게 앞선다.
- Dialog의 존재 유무는 차이가 상당히 크다.
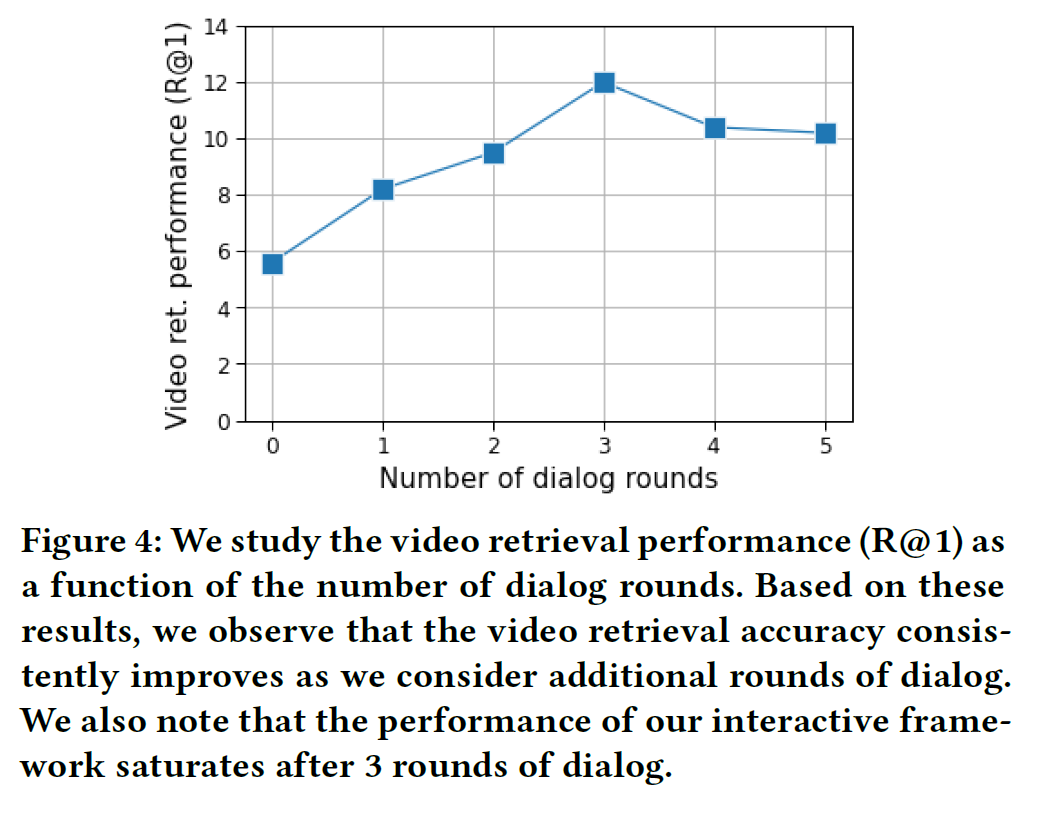
- 몇 턴의 대화(qa)를 사용해야 하는지 실험한 결과 3번이 가장 좋았다. (그래서 표 1에서는 3번으로 실험함)
6.2 Video Question Answering Results
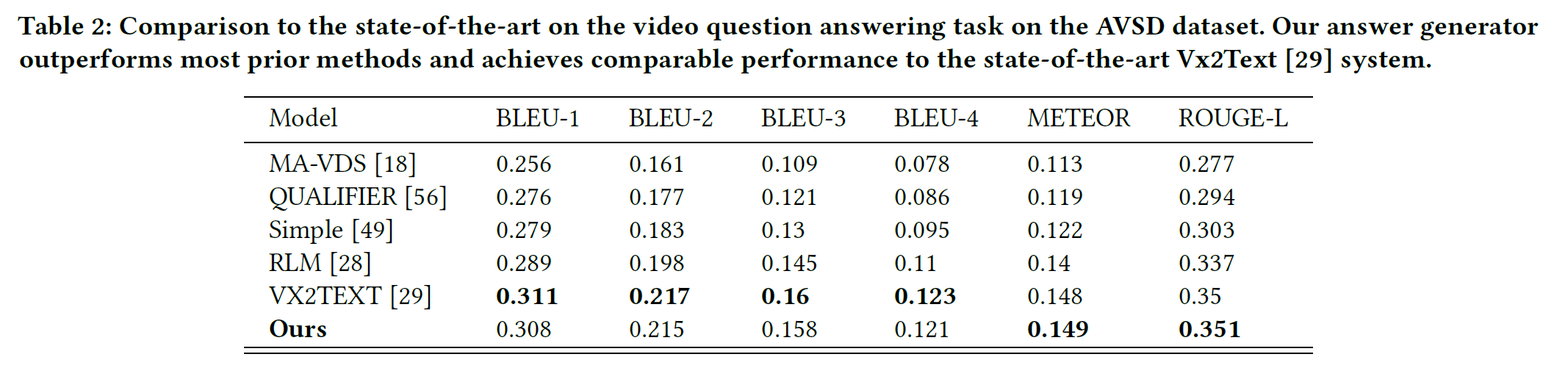
- VX2TEXT와 ViReD가 좋은 성능을 보인다.
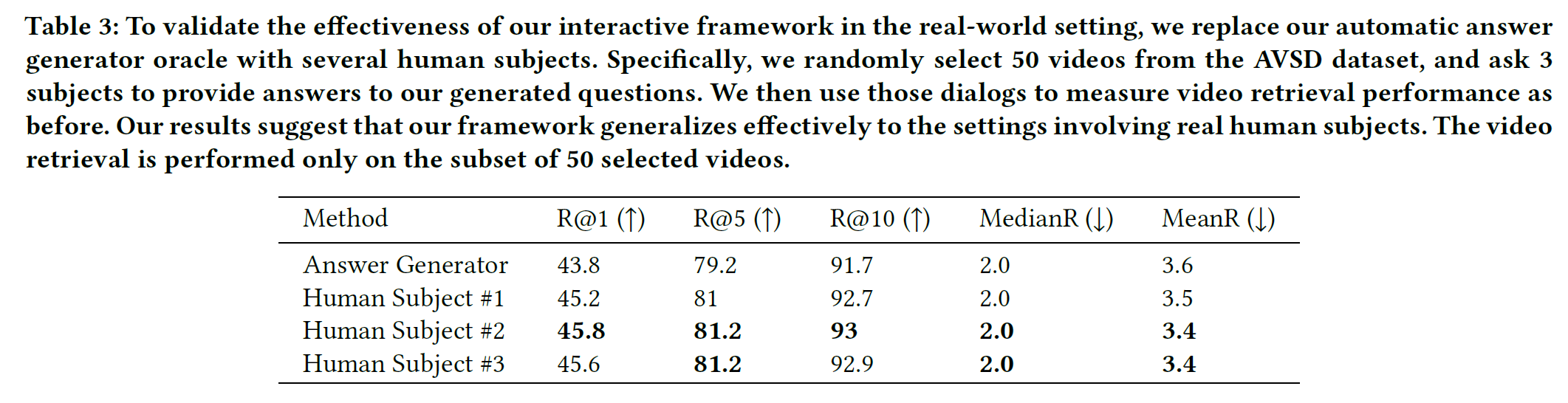
- Question Generator를 Human subject로 대체하였을 때 성능을 아래 표에서 비교하였다. Human subject로 대체하였을 때도 비슷하게 작동한다는 것은 본 논문에서 제안하는 시스템이 실제 상황과 잘 맞으며 신뢰도 있게 작동한다는 것을 의미한다고 한다.
6.3 Ablation Studies
- IGS가 있을 때는 없을 때보다 R1 metric으로 4.3%만큼 좋다.
- Question Gnerator에서 Retrieved Video를 사용한 경우 R1에서 3.9%만큼 향상되었다.
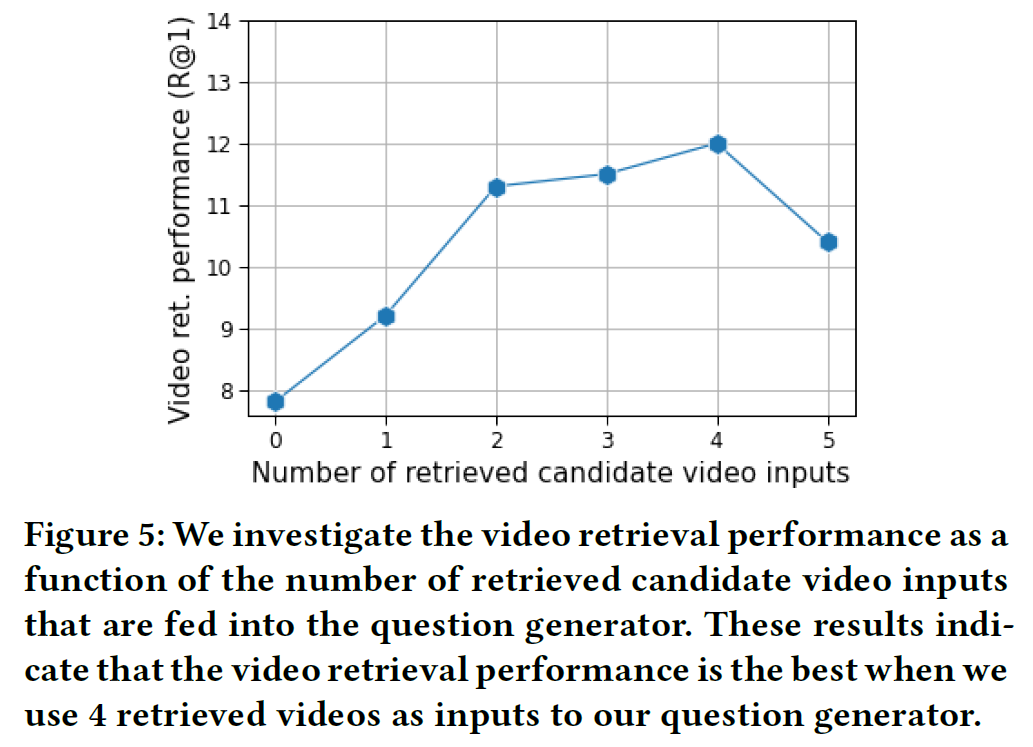
- Question Gnerator에서 Video input은 4개가 적당하다.
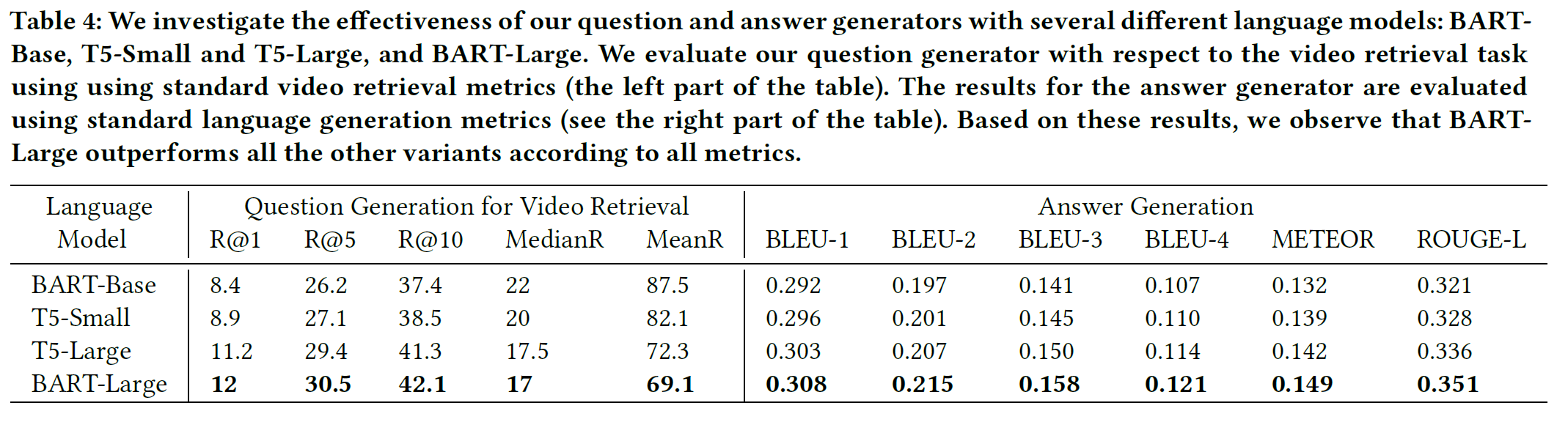
- 언어모델은 BART large가 가장 좋았다.
6.4 Qualitative Results
요건 그림을 살짝 보는 것이 낫다.

각 round별 dialog는 video retrieval 성능을 높이고 있음을 주장하고 있다.
7. Conclusions
- dialog를 사용한 비디오 검색을 위한 대화형 프레임워크인 ViReD를 제안하였다.
- dialog를 사용했을 때가 그렇지 않을 때보다 훨씬 효과적임을 보였다.
요약하면, 이 논문의 방법은
- 개념적으로 간단하고,
- AVSD 데이터셋에 대한 대화형 비디오 검색 작업에 대한 SOTA를 달성하고
- human subject와 같은 실제 환경으로 일반화할 수 있다.
추후 연구는 다른 VL task로도 확장하는 것이다.