
VQ-VAE 2 논문 설명(Generating Diverse High-Fidelity Images with VQ-VAE-2)
26 Nov 2021 | Paper_Review Multimodal VQVAE DeepMind목차
- Generating Diverse High-Fidelity Images with VQ-VAE-2
이 글에서는 2019년 NIPS에 게재된 Generating Diverse High-Fidelity Images with VQ-VAE-2(VQ-VAE2) 논문을 살펴보고자 한다.
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
Generating Diverse High-Fidelity Images with VQ-VAE-2
논문 링크: Generating Diverse High-Fidelity Images with VQ-VAE-2
Github: https://github.com/rosinality/vq-vae-2-pytorch
- 2019년 6월, NIPS 2019
- DeepMind
- Ali Razavi, Aaron van den Oord, Oriol Vinyals
초록(Abstract)
이 논문에서는 VQ-VAE(Vector Quantized Variational AutoEncoder)로 large-scale 이미지 생성 문제를 다루려 한다. 이를 위해 prior를 더욱 강화하여 이전보다 더 일관성, 현실성 있는 이미지를 만들었다. 모델은 단순한 feed-forward encoder와 decoder를 사용하였으며 회귀모델은 오직 latent space 안에서만 쓰여 pixel space에서는 기존보다 더욱 빠른 속도를 갖는다. 최종적으로 GAN과 비슷한 성능을 보이면서도 mode collapsing과 같은 GAN의 고질적인 문제를 겪지 않는 생성 모델을 만들었다.
1. 서론(Introduction)
Deep Generative model은 최근 크게 발전하며 실제와 분간이 힘든 이미지를 생성할 수 있는 수준에 이르렀다. GAN은 minimax 방식을 사용하여 현실적인 이미지를 생성하였지만 실제 세상의 이미지 분포를 그대로 따라가지 못하는 문제가 존재한다. 또한 생성한 이미지를 평가하기도 매우 어려워서 근사하는 방식인 FID 등의 metric으로 평가를 해야 한다.

이와는 대조적으로 likelihood 기반 방식은 NLL을 최적화하며 이는 모델 비교와 아직 보지 못한 일반화 성능을 측정할 수 있게 한다. 또 모델은 학습 셋의 모든 example에 대한 확률을 최대화하므로 분포 문제에서도 자유로운 편이다. 그러나 이 방식 역시 어려운 점이 있는데,
- Pixel space에서의 NLL은 sample의 품질을 측정하기 적합하지 않고
- 다른 model class 사이의 비교하는 데 사용하기도 어렵다.
본 논문에서는 무시해도 되는 정보를 모델링하는 데 드는 노력을 최소화하도록 lossy compression으로부터 얻은 아이디어를 사용한다. 사실 JPEG 압축 방식은 이미지 품질에 영향을 주지 않는 선에서 80%의 용량을 줄일 수 있는 방식이다. 이와 비슷한 아이디어로, 본 논문에서는 이미지를 매우 작은 discrete latent space로 옮겨 저장하는 방식을 취한다. 이는 30배 더 작은 공간을 차지하면서도 decoder가 원래 이미지를 (눈으로 보기에) 거의 비슷하게 복원할 수 있게 한다.
이산표현에서 prior는 PixelCNN + self-attention으로 모델링이 가능하여(PixelSnail), prior로부터 sampling할 때 디코딩된 이미지는 복원 시 고품질과 높은 coherence를 가진다. 인코딩된 이미지는 원본 이미지보다 30배 가량 작고 또 모델의 속도도 빨라서 기존의 생성모델에 비견될 만한 성능을 보인다.
2. 배경(Background)
2.1 Vector Quantized Variational AutoEncoder
VQ-VAE는 Variational AutoEncoder와 거의 비슷한 구조를 갖는데, 가장 중요한 차이점은 latent space가 discrete하다는 것이다. 지정된 크기(ex. 512)의 codebook(embedding space)을 유지하면서 이미지의 각 부분을 하나의 embedding의 인덱스에 대응시켜 이미지를 표현한다. Encoder는 입력 $x$에 대해 $x \mapsto E(x)$의 역할을 수행한다. 이 벡터 $E(x)$는 codebook vector $e_k$와의 거리에 기반하여 quantized되며 이는 decoder로 전달된다.
\[\text{Quantize}(E(x)) = \textbf{e}_k \qquad \text{where} \quad k = \argmin_j \Vert E(x) - \textbf{e}_j \Vert\]Decoder는 이미지를 표현한 인덱스를 다시 대응되는 codebook vector로 mapping한다.
VQ-VAE는 다음 식으로 최적화된다.
\[L = \log p(x \vert z_q(x)) + \Vert \text{sg}[z_e(x)]-e \Vert_2^2 + \beta \Vert z_e(x)-\text{sg}[e] \Vert_2^2 , \qquad (3)\]Encoder의 출력과 codebook의 벡터 공간을 일치시키는 것에 대해 두 가지 loss를 포함한다.
- codebook loss: 오직 codebook에만 영향을 준다. 선택된 codebook $\textbf{e}$를 encoder의 출력 $E(x)$에 가까워지도록 한다.
- the commitment loss: encoder의 weight에만 영향을 준다. encoder의 출력이 선택된 codebook 벡터에 가까워지도록 해서 여러 codebook 사이를 자꾸 왔다갔다하지 않도록 하는 역할을 한다.
본 논문에서는 여기에 exponential moving average를 적용시킨다.
3. 방법(Method)
두 단계로 이루어진다.
- 이미지를 discrete latent space로 mapping하기 위해 VQ-VAE를 학습시킨다.
- 모든 데이터를 사용하여 PixelCNN prior를 이 discrete latent space에 fit시킨다.

3.1 Stage 1: Learning Hierarchical Latent Codes
vanilla VQ-VAE와 다른 점은 더 큰 이미지를 다룰 수 있기 위해 vector quantized codes를 계층 구조로 사용한다는 것이다.
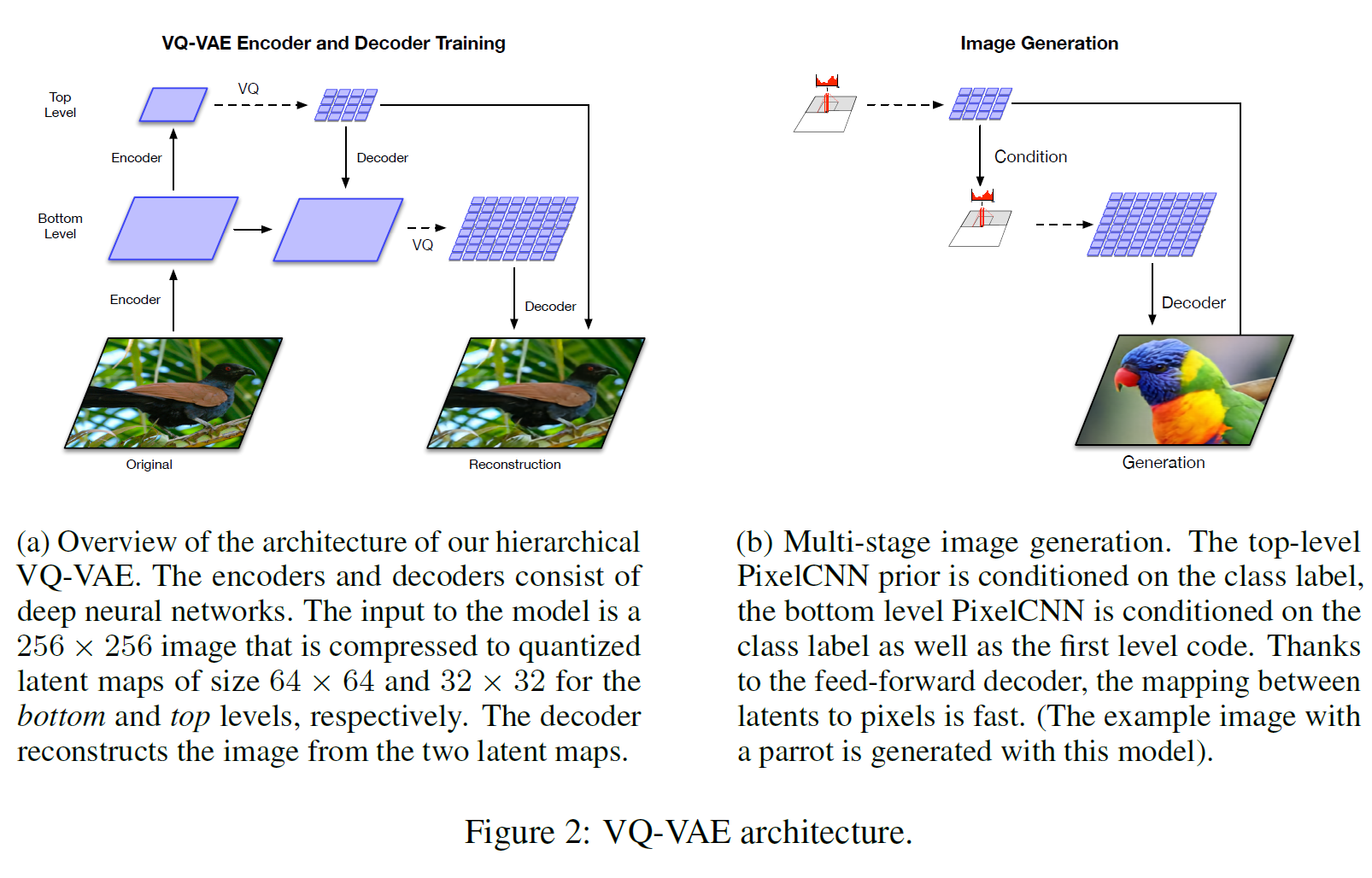
위 그림에서 원본 이미지를 인코딩하여 얻은 bottom latent code는 세부적인 부분을 모델링하고, 이 bottom latent code를 한번 더 인코딩한 Top latent code는 global한 특징을 모델링한다. 여기서 bottom latent code는 top latent code에 의존하는데, 그래야 top latent code가 세부적인 특징까지 혼자 다 모델링하려고 하는 현상이 방지된다(분업한다고 생각하면 된다).
256 x 256 이미지는 bottom level에서 64 x 64로 줄어들고, top level은 32 x 32 크기를 갖는다. Decoder 부분에서는 인코딩된 vector quantized code를 전부 받아서 디코딩을 수행한다. 이는 residual block과 strided transposed convolution으로 수행된다.

3.2 Stage 2: Learning Priors over Latent Codes
이미지 압축 및 stage 1에서 학습한 모델로부터 샘플링을 할 수 있도록 prior를 latent code로 학습시키는 단계이다. Prior를 학습 데이터로 학습시킴으로써 성능을 향상시키고 marginal posterior와 prior 간 괴리를 줄이며, 학습된 prior로부터 샘플링된 latenr variable은 decoder가 학습하는 동안 관찰한 것과 비슷해진다.
이러한 관점에서, prior를 학습된 posterior에 fit하는 과정은 latent variable을 re-encoding함으로써 latenr space를 무손실 압축하는 것으로 볼 수 있다(결과는 Shannon’s entropy에 가깝다). 따라서 학습된 prior의 NLL과 true entropy의 괴리를 줄이고, 더 실제적인 이미지 샘플을 기대할 수 있다.
VQ-VAE framework에서, 이 auxiliary prior는 post-hoc, stage 2에서 PixelCNN과 같은 강력한 회귀모델로 모델링된다.
- Top latent map에서의 prior는 전체 구조를 모델링하는 책임이 있으므로 multi-head self-attention layer를 사용, spatial location 간 상관관계를 얻기 위해 더 큰 receptive field를 사용할 수 있다.
- 이와 대조적으로, bottom level에서의 조건부 prior는 local info를 모델링한다. 여기서는 메모리 문제 때문에 self-attention layer를 쓰는 것은 힘들고, 대신 large conditioning stacks를 사용한다.
- 더 자세한 내용은 알고리즘 3 참조.
Top-level prior는 32 x 32 latent variable을 모델링한다.
- 매 5개의 layer마다 residual gated conv layer + causal multi-headed attention을 추가한다.
- 각 attention matrix, residual block 뒤에 dropout을 추가한다.
- PixelCNN stack에다가 1x1 conv로 구성된 deep residual net을 추가하는 것은 학습 시간이나 메모리 사용량을 별로 늘리지 않으면서 likelihood를 증가시킬 수 있다.
Bottom level에서는 64 x 64 latent variable을 사용한다.
- 앞서 언급했듯 여기서 같은 방식을 사용하면 자원 사용량이 너무 많아지다.
- 그래서 attention layer를 따로 사용하지 않는다.
3.3 Trading off Diversity with Classifier Based Rejection Sampling
GAN과는 다르게 Maximum Likelihood 기반 확률모델은 모든 학습 데이터 분포(+ 모든 mode에 대한 데이터)를 모델링하는 것이 강제된다. 최근 GAN framework 중에서는 다양성과 품질을 trade-off하는 샘플 선택을 자동화하는 과정을 제안하기도 했다.
우리가 생성한 샘플이 실제 data manifold에 더 가까울수록, 그 샘플들이 사전학습된 분류기에 의해 올바른 class label로 분류될 가능성이 더 증가한다는 직관에 기반해서, 이 논문에서는 샘플의 다양성과 품질을 trade-off하는 자동화된 방법을 제안한다. 특히, 분류기가 올바른 class로 분류할 확률에 따라 샘플의 점수를 매기기 위해 ImageNet에서 학습된 분류 network를 사용한다.
4. 관련 연구(Related Works)
- VQ-VAE
- Gated PixelCNN(+self-attention)
- BigGAN: 구조적인 이점, 안정화 방법, TPU로 모델을 scale up하는 것 등으로 FID/Inception score에서 SOTA 모델이다.
5. 실험(Experiments)
256 x 256 ImageNet에서 학습한 모델의 양적/질적 결과를 (BigGAN-deep과) 비교한다.
5.1 Modeling High-Resolution Face Images
데이터 상 매우 긴 범위의 의존성을 잡아내기 위한 방법으로 이 논문에서 제시한 multi-scale 접근법을 평가하기 위해 FFHQ dataset(1024 x 1024)에서 3-level 계층 모델을 학습시킨다. 이 데이터셋은 성별, 인종 등 다양한 domain으로 구성된 7만 개의 고품질 초상화 (사진)으로 구성되어 있다.
초장거리 의존성의 예: 인물 사진의 경우 양쪽 눈이 (거의) 대칭적으로 이루어져 있어야 한다. 이는 수백 pixel 떨어진 곳에서 동일한 색상+ 비슷한 크기 등으로 이미지를 생성해 내야 하는, 장거리 의존성에 대한 이해가 필수이다.



5.2 Quantitative Evaluation
5.2.1 Negative Log-Likelihood and Reconstruction Error
Likelihood 기반 생성모델을 사용하는 핵심 이유 중 하나는 일반화에 대한 성능 평가가 가능하여 over-fitting이 일어나는지를 관찰할 수 있다는 것이다.
일반적으로 사용되는 FID와 Inception score의 경우 일반화 문제를 무시한다.
그래서 NLL(+MSE)로 top & bottom prior에 대한 결과가 아래 표에 있다. 여기서 NLL 값은 같은 사전학습 VQ-VAE를 사용한 경우에만 비교가 유효하다.

5.2.2 Precision - Recall Metric
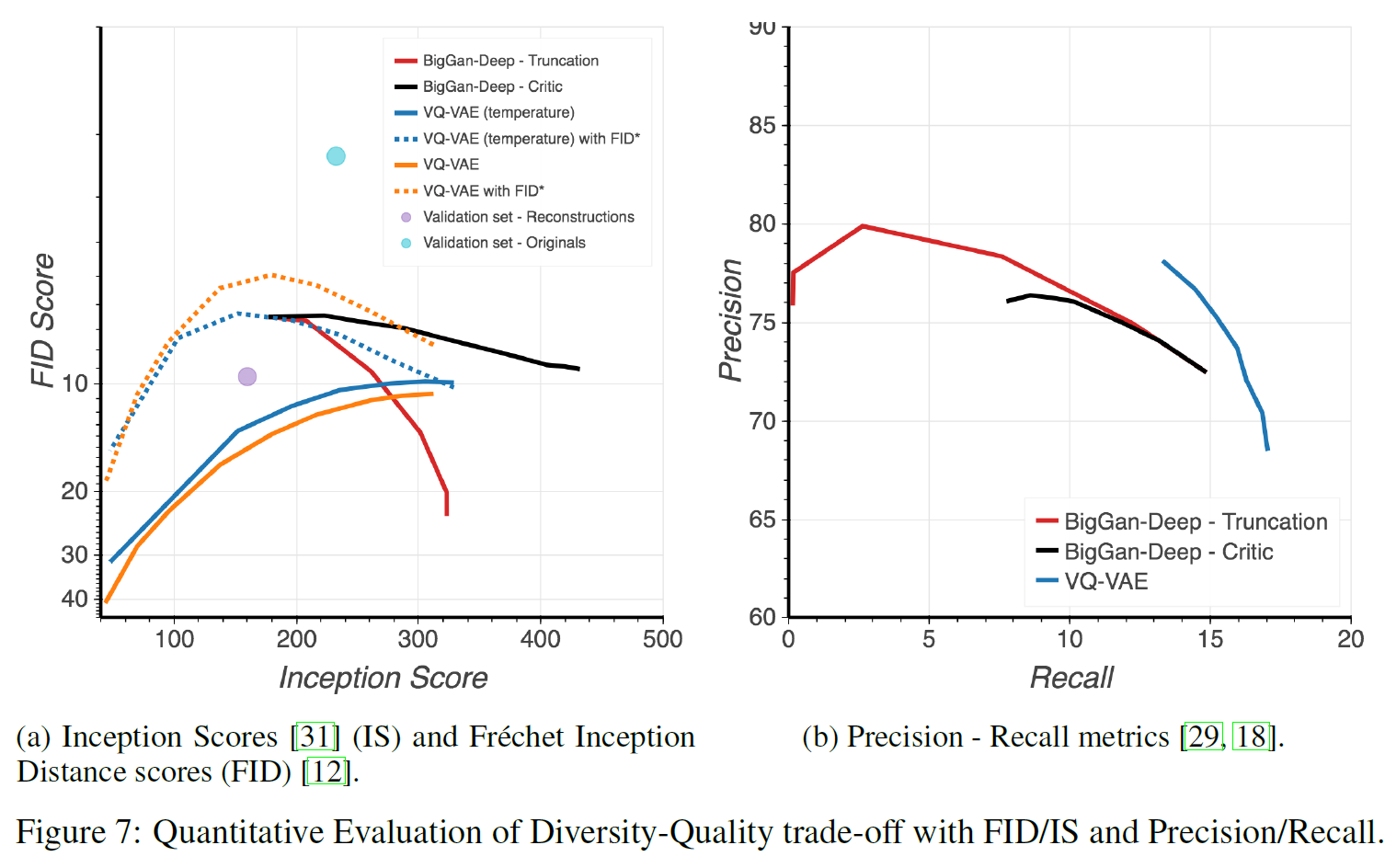
PR metric은 GAN에서 FID와 Inceptino score의 대안으로서 제안되었다. 아래 그림에서 BigGAN-deep와 비교한 결과를 볼 수 있다. Precision은 VQ-VAE가 조금 낮지만, Recall은 더 높다.
5.3 Classification Accuracy Score
최근 제안된 평가방법인 Classificatino Accuracy Score(CAS)로도 비교하였다. 이는 ImageNet 분류기를 후보 모델에서 생성된 샘플에서만 학습하고 test set의 real image에서 분류 정확도를 측정하여 결과적으로 품질과 다양성을 평가할 수 있는 방법이다. 결과는 아래와 같다.

VQ-VAE의 경우 압축 때문에 high-frequency signal(~noise)이 부족하다.
VQ-VAE reconstruction은 “domain gap”을 좁히고 분류기를 재학습시키지 않고도 더 높은 CAS score를 받았다.
5.3.1 FID and Inception Score
단점이 존재하기는 하지만 GAN을 평가하는 가장 일반적인 방법인 FID와 Inception score로도 평가를 진행하였다. 결과는 위에 있는 그림 7a에서 볼 수 있다.
다양성과 품질을 trade-off하는 방법으로 classifier-based rejection sampling을 사용하였다.
VQ-VAE는 FID와 IS 모두 향상되었다(30 $\rightarrow$ 10). BigGAN-deep에서 rejection sampling은 BigGAN 논문에서 제안된 truncation method보다 낫다.
6. 결론(Conclusion)
VQ-VAE와 강력한 회귀모델을 prior로 사용하여 다양한 고해상도 이미지를 생성하는 간단한 방법을 제시하였다. 계층적 구조의 latent map을 사용하여 SOTA GAN과 비슷한 수준의 이미지 생성 결과를 보여주었고 GAN 방식이 아닌 생성 모델의 한 갈래를 제시했다는 점에서 높이 평가할 만한 논문이다.
참고문헌(References)
논문 참조!
부록 A(Architecture Details and Hyperparameters)
A.1 PixelCNN Prior Networks
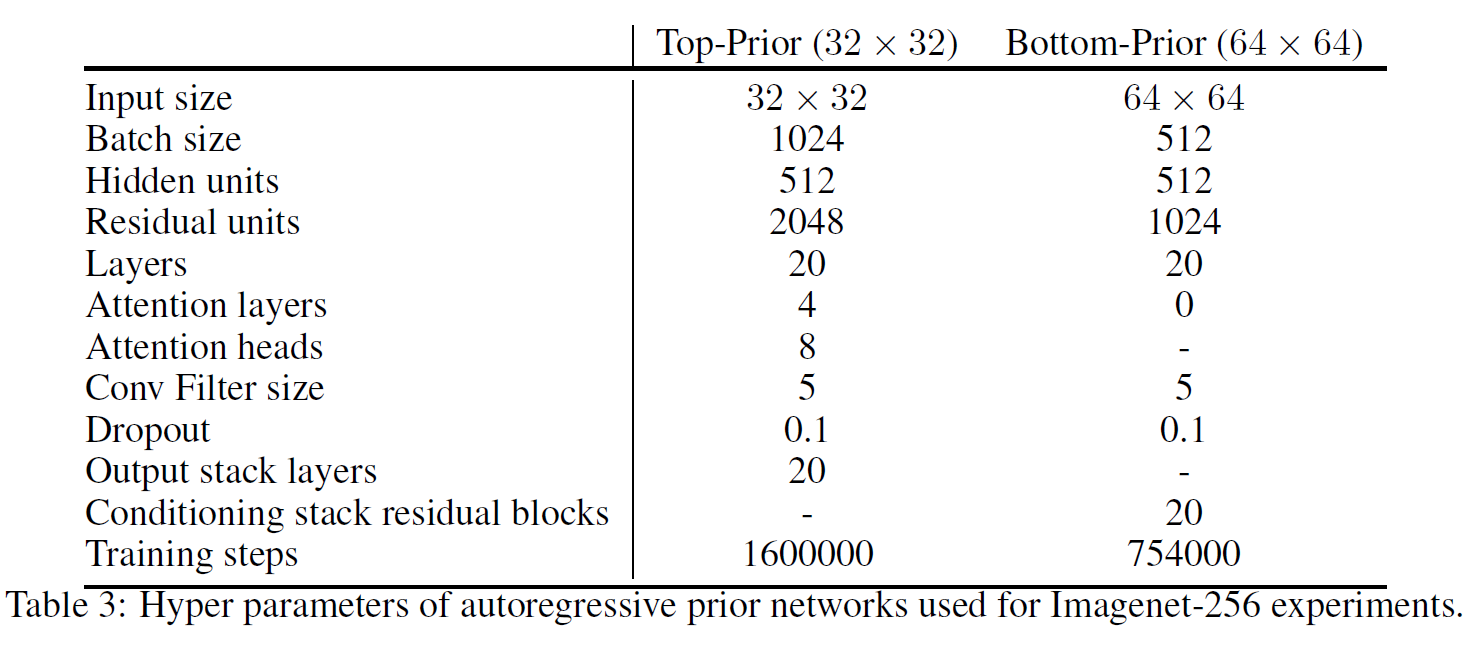
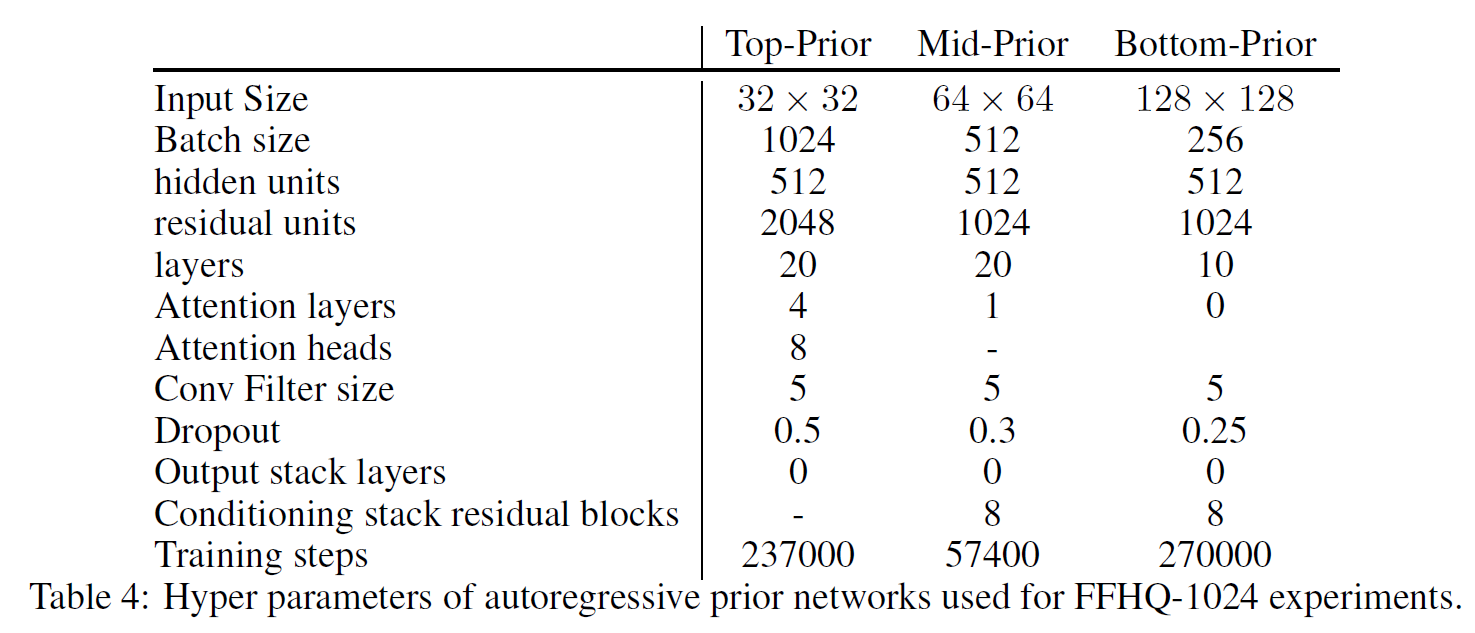
A.2 VQ-VAE Encoder and Decoder

부록 B(Additional Samples)
논문 전체 및 무손실 압축으로 rendering된 결과 등을 추가로 보고 싶다면 아래 링크를 참조하면 된다.
- https://drive.google.com/file/d/1H2nr_Cu7OK18tRemsWn_6o5DGMNYentM/view?usp=sharing