
DCGAN(Deep Convolutional GAN, DCGAN 논문 설명)
17 Mar 2019 | GAN DCGAN Machine Learning CNN Generative Model Paper_Review목차
- 논문(DCGAN)
- 초록(Abstract)
- 서론(Introduction)
- 관련 연구(Related Works)
- 접근법과 모델 아키텍처(Approach and Model Architecture)
- 적대적 학습 상세(Details of Adversarial Training)
- DCGAN의 능력의 경험적 검증(Empirical Validation of DCGANs Capabilities)
- 네트워크 내부 조사 및 시각화(Investigating and Visualizing the Internals of the Networks)
- 결론 및 추후 연구(Conclusions and future work)
- 참고문헌(References)
- 튜토리얼
- 이후 연구들
이 글에서는 2015년 11월 Alec Radford 등이 발표한 DCGAN(Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks)를 살펴보도록 한다.
DCGAN은 GAN의 개선 모델로 GAN과 다른 점은 다음과 같다.
- $D$
- Strided Convolution을 사용한다.
- Batch Normalization을 사용한다. 입력 레이어(첫 번째)에는 사용하지 않는다.
- activation function으로 Leaky ReLU를 사용한다.
- $G$
- Fractional Strided Convolution(Transposed Convolution)을 사용한다.
- Batch Normalization을 사용한다. 출력 레이어(마지막)에는 사용하지 않는다.
- activation function으로 ReLU를 사용하고 마지막 레이어에는 tanh를 사용한다.
참고: 논문에서 deconvolution이라 되어 있는 것은 Transposed 또는 fractional strided convolution을 의미한다. 이 연산은 엄밀히 말해 convolution의 역연산이 아니기 때문에(그 비슷한 것을 의도하긴 했지만) deconvolution은 사실 틀린 표현이다.
그래서 나아진 점, 혹은 알아낸 것은?
- (흔히 생각하는 FHD를 넘는 고해상도랑은 거리가 멀지만) 고해상도 이미지를 생성할 수 있게 되었다.
- 거의 대부분의 상황에서 안정적인 학습이 가능하다.
- 단순히 이미지를 기억(overfitting)하는 것이 아님을 보였다.
- convolution의 각 filter는 의미 있는 부분에 대한 정보를 갖고 있다. 논문에서는 침실 데이터를 사용하였는데, 어떤 필터는 창문에 대한 정보를 갖고 있는 식이다. 논문에서는 이를 시각화하여 보여주었다.
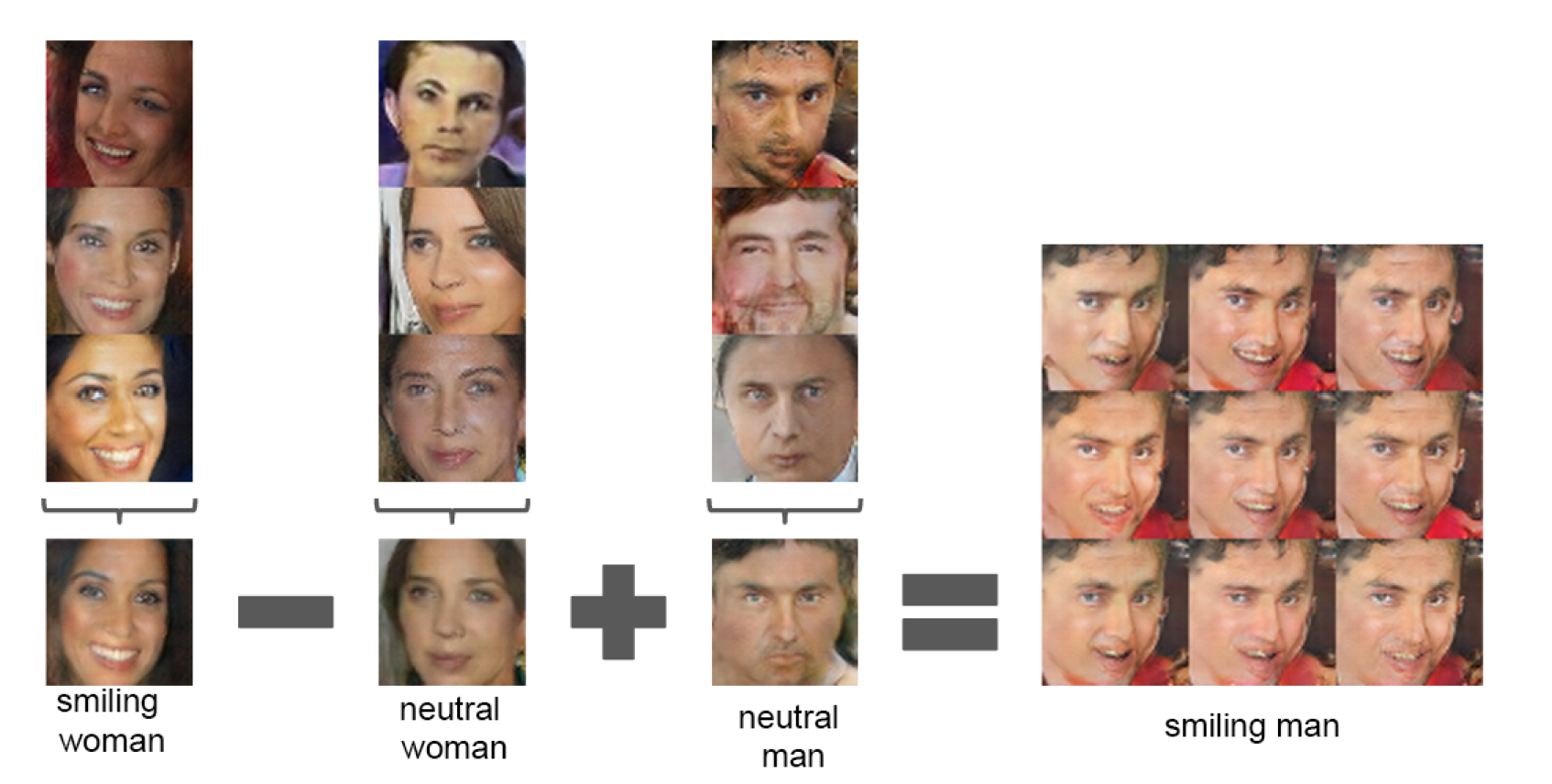
- input인 noise($z$)는 별 의미 없는 값이 아니라, 이것이 생성될 이미지의 특징을 결정하는 벡터이다. 논문에서는,
- 웃는 여자를 생성한 noise $z_1$
- 무표정 여자를 생성한 noise $z_2$
- 무표정 남자를 생성한 noise $z_3$
- $z_4 :=$ $z_1$ - $z_2$ + $z_3$이라 할 때
- $z_4$를 noise로 쓰면 웃는 남자를 생성해낸다.
- 또 왼쪽을 보는 사람과 오른쪽을 보는 사람을 생성한 두 벡터를 interpolating하면 마치 얼굴을 회전시킨 듯한 중간 결과들이 얻어진다.
DCGAN은 GAN과 학습 방법 자체는 별로 다를 것이 없다(D 학습 후 G 학습시키는 것).
참고: $G$로 들어가는 입력 벡터를 뜻하는 noise는 latent variable이라고도 하며, Auto-encoder에서 출력 영상을 만들기 위한 source와 비슷하기에 이 표현도 사용된다.
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
논문(DCGAN)
논문 링크: Deep Convolutional GAN
초록(Abstract)
2015~2016년에 나온 논문임을 생각하라.
최근에는 CNN을 통한 supervised learning 연구가 많이 이루어졌지만 unsupervised learning은 별 주목을 받지 못했다. 우리는 Deep Convolutional GANs를 소개하여 그 간극을 좁히고자 한다. 여러 이미지 데이터셋을 학습시키면서 우리는 DCGAN의 G와 D 모두가 object로부터 유의미한 표현 구조를 찾았음을 보였다. 또, 이를 일반적인(general) 이미지 표현에도 응용해 보았다.
서론(Introduction)
GAN은 최대우도(maximum likelihood) 테크닉의 매력적인 대체재이다. 또한 그 학습 방법과 heuristic cost function가 적다는 것 때문에 representation learning에도 훌륭히 잘 쓸 수 있다. 다만 학습이 불안정하고 G가 터무니없는 output을 내뱉을 때가 있다. 그래서 상당히 제한적으로 쓰일 수밖에 없었다.
이 논문에서는, 우리는 다음과 같은 것들을 보일 것이다:
- 거의 대부분의 상황에서 학습이 안정적인 Convolutional GAN을 제안하고 평가한다. 이것이 DCGAN이다.
- D에게 image classification를 시켜봤는데, 거의 state-of-the-art한 결과를 보인다.
- 특정 필터가 특정 object를 그려낸다는 것을 시각화한다.
- G에 들어가는 noise에 산술 연산을 한 결과로 많은 의미있는 이미지를 생성함을 보인다.
관련 연구(Related Works)
궁금하면 읽어보자.
Representation Learning from Unlabeled Data
Unsupervised representation learning은 꽤 잘 연구되었다. 전통적인 접근 방법으로는 clustering(K-means)이 있다.
이미지 쪽에서는 image representation을 학습하기 위한 구조적 clustering, auto-encoder를 학습시키는 것, what/where 분리 구조, image를 간략한 code로 encode하고 다시 이미지로 복원하는 decoder를 포함하는 사다리 구조 등등이 있었다.
Deep belief networks도 구조적 표현방식을 학습하는 데 좋은 성능을 보였다.
Generating Natural Images
이건 두 종류가 있다: parametric과 non-parametric.
database에 존재하는 이미지 찾기 등을 수행하는 non-parametric 모델들은 texture synthesis, super-resolution, in-painting 등에 사용되었다.
Parameteric 모델은 꽤 널리 알려졌지만(MNIST), 성공적인 것은 별로 없다. 대부분 흐린(blurry) 이미지만을 생성해냈다.
GAN이 생성한 것은 noise가 많고 이해하기 어려웠다. Laplcian pyramid extension, recurrent network, deconvolution network 등의 접근은 자연 이미지를 생성하는 데 성공적이었지만 supervised task에 generator를 활용하진 않았다.
Visualizing the Internals of CNNs
Neural Networks의 문제점은 너무 black-box같다는 것이다(참고: 네트워크의 각 필터 등이 정확히 무엇을 의미하는지 사람이 이해할 수가 없다). 다만 각 필터의 의미를 찾으려는 시도는 있었다.
자세한 내용은 원문을 보고 각 논문을 찾아보라.
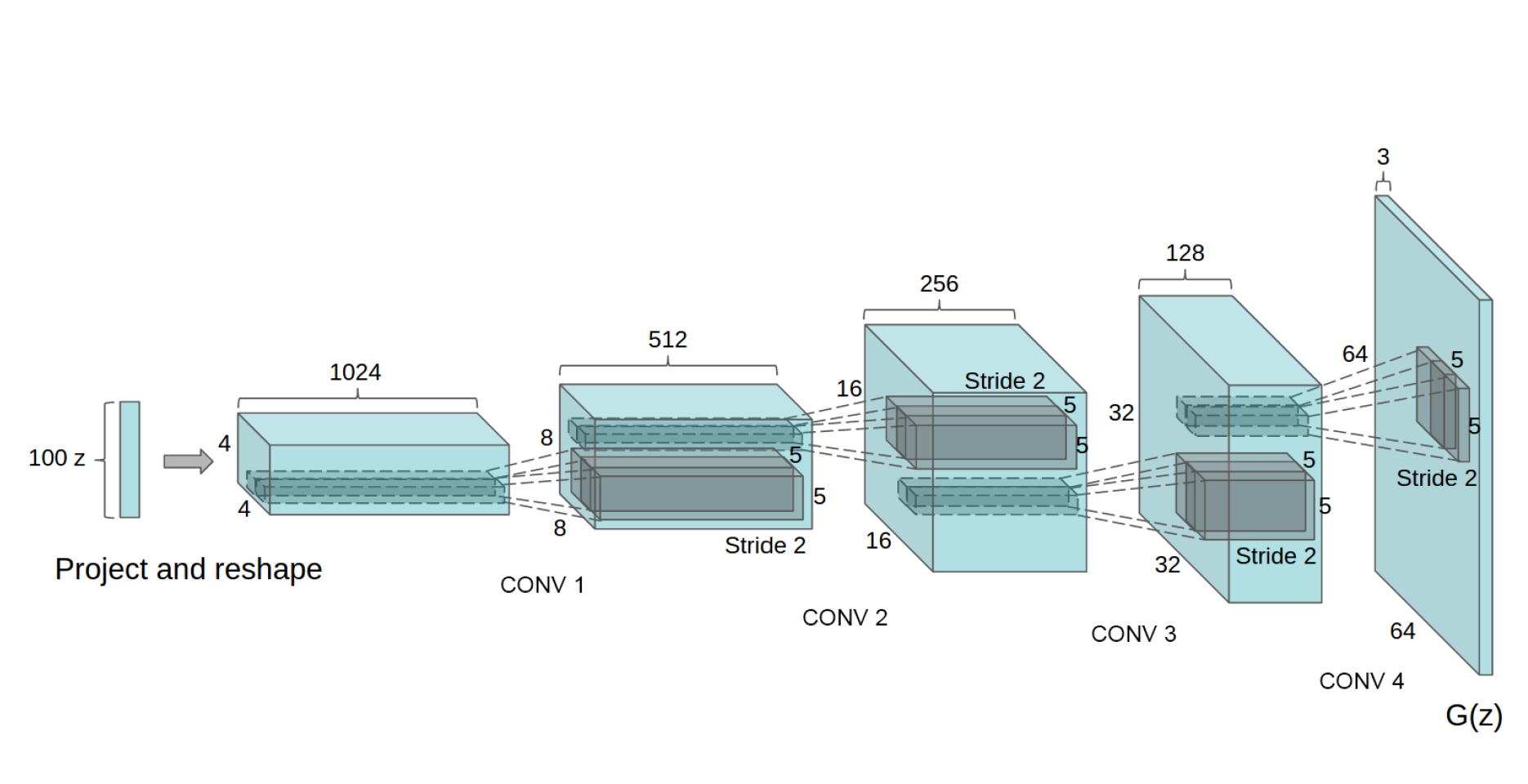
접근법과 모델 아키텍처(Approach and Model Architecture)
GAN에 CNN을 써서 이미지 품질을 높이려는 시도는 지금까지 성공적이지 못했다.
우리는 많은 시도 끝에 다양한 데이터셋에서 안정적인 그리고 더 높은 해상도의 이미지를 생성하는 모델 구조를 찾아내었다.
핵심은 다음 3가지를 CNN 구조에 적용시키는 것이다.
- max-pooling과 같은 미분불가능한 레이어를 strided convolution으로 바꿔 spatial downsampling이 가능하게 한 것이다. 이는 G에 사용된 것이고, D에는 upsampling이 가능하게 바꿨다.
- 요즘 트렌드는 FC(Fully Connected) Layer를 없애고 convolution layer로 바꾸는 것이다.
- Batch Normalization을 사용하여 학습을 안정화시킨다(참고: 2019년 현재 BN은 거의 필수처럼 되어 있다). 이는 weight 초기화가 나쁘게 된 경우와 깊은 모델에서 gradient flow를 도우며, 이는 학습 초기에 잘못된 방향으로 학습이 진행되어 망하는 경우를 막아준다. 그러나 sample이 요동치는 것을 막기 위해 G의 출력 레이어와 D의 input layer에는 넣지 않았다(이건 많은 시도 끝에 알아낸 듯).
G에서는 activation function으로 ReLU를 사용하고 마지막 레이어에는 tanh를 사용한다. Bounded activation(tanh)은 더 빠르게 수렴하고 학습샘플의 분포를 따라갔다. D에는 Leaky ReLU를 사용하여 높은 해상도를 만들 수 있게 하였다. 이는 GAN과 다른 부분이다.
적대적 학습 상세(Details of Adversarial Training)
우리는 Large-scale Scene Understanding(LSUN), Imagenet-1k, Faces 데이터셋으로 학습을 진행했다.
- pre-processing은 쓰지 않았고
- size 128인 mini-batch SGD
- (0, 0.02) 정규분포를 따르는 초기화
- Leaky ReLU의 기울기는 0.2
- AdamOptimizer(0.0002, 0.9)
로 했다. AdamOptimizer의 beta1을 0.5로 줄이는 것보다 학습 안정성이 좋았다.
모델 구조는 아래와 같다.
단 1 epoch만 학습시켰을 때의 결과. minibatch SGD를 썼기 때문에 이미지를 기억한다고는 볼 수 없다. 따라서 overfitting 없이 잘 생성하고 있는 것이다.

5 epoch만 학습시켰을 때의 결과. 침대 근처 noise로 볼 때 오히려 underfitting이 일어난 것 같다.

DCGAN의 능력의 경험적 검증(Empirical Validation of DCGANs Capabilities)
Unsupervised representation learning 알고리즘을 평가하는 일반적인 방법은 supervised 데이터셋에 대해 특징 추출을 시킨 뒤 performance를 측정하는 것이다.
검증 요약:
- CIFAR-10 데이터셋에 대해 검증한 결과, 다른 방법들(K-means, Exemplar CNN 등)과 비교하여 정확도가 별 차이가 없었다!(80.6~84.3%, DCGAN은 82.8%)
- StreetView House Numbers dataset(SVHN)은 state-of-the-art 결과를 얻었다.
네트워크 내부 조사 및 시각화(Investigating and Visualizing the Internals of the Networks)
우리는 가장 가까운 학습 데이터 이미지를 찾거나, 최근접 픽셀이나 특징 혹은 log-likelihood metric 같은 방법은 별로이기 때문에 사용하지 않았다.
생성된 2개의 이미지에 사용된 noise인 $z$를 선형 보간하며 그 보간된 $z$로 이미지를 생성시켜본 결과 한 이미지에서 다른 이미지로 서서히 변해가는 결과를 얻었다(아래 그림). 이미지를 보면 창문 없는 방이 거대한 창문이 있는 방으로 변해 가거나(6th row), TV가 창문으로 변해가는 과정(10th row)을 볼 수 있다.

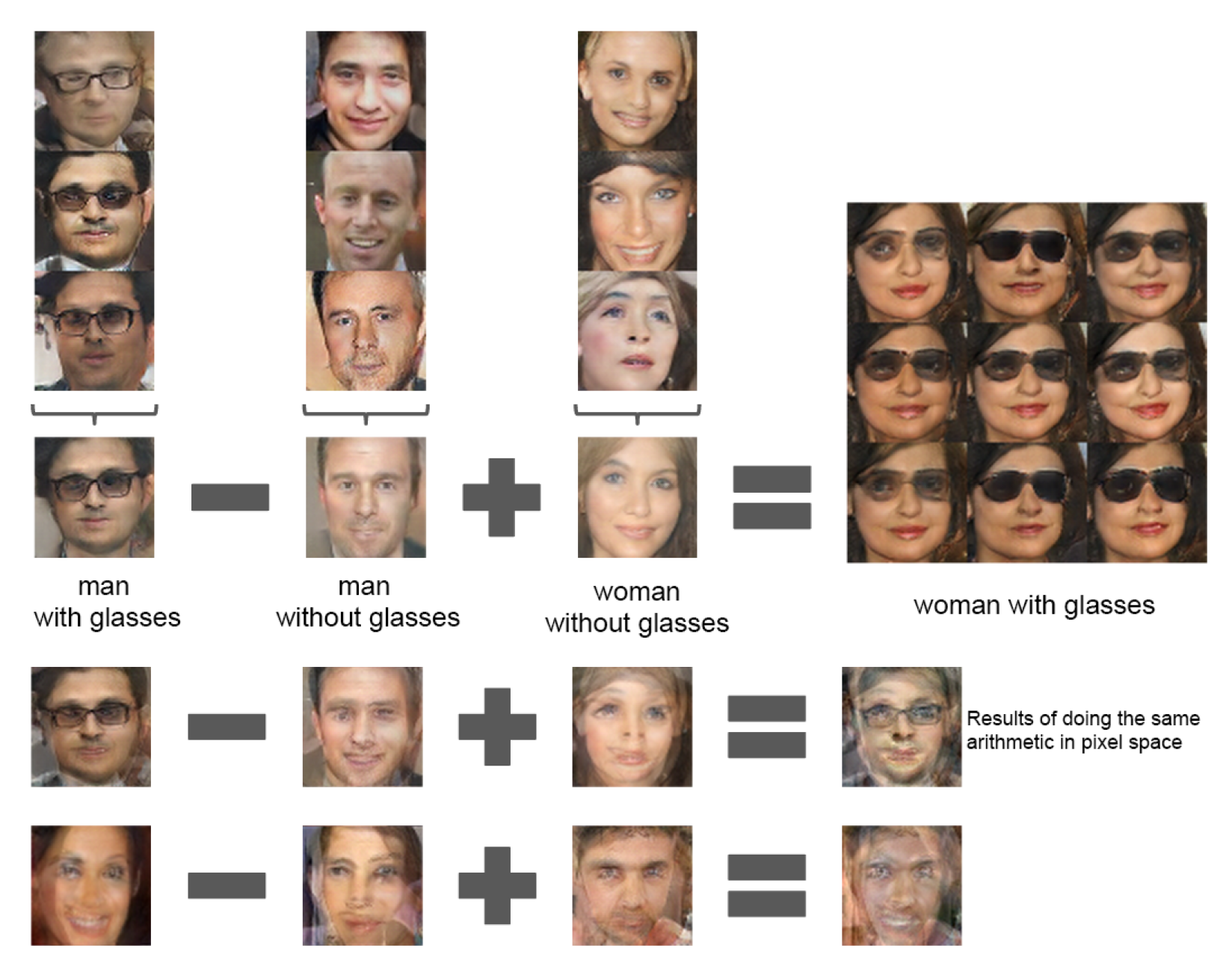
벡터 산술 연산을 통해, vec(웃는 여자) $-$ vec(무표정 여자) $+$ vec(무표정 남자) $=$ vec(웃는 남자) 같은 결과를 얻을 수 있다.
네트워크 내부의 각 필터는 이해할 수 없는 형식이 아닌 특정 object나 특징을 추출하였음을 알 수 있다.

결론 및 추후 연구(Conclusions and future work)
우리는 안정적인 생성모델을 제안하였고 이 적대정 생성모델은 image representation에 탁월함을 보여 주었다. 그러나 아직 오래 학습시킬 시 필터 일부가 요동치는 것 등 모델에 불안정성이 남아 있다.
추후 연구는 이를 안정화하는 방법을 찾는 것이 될 것이다. 또한 이 framework를 영상 또는 음성 등의 다른 domain에도 확장시킬 수도 있다.
Acknowledgments
Ian GoodFellow 등의 연구자와 Nvidia Titan-X GPU에 감사를 표한다.
(광고인줄)
참고문헌(References)
논문 참조!
튜토리얼
공식 튜토리얼
DCGAN이 특별히 중요하기 때문인지 Pytorch 공식 홈페이지에 튜토리얼이 있다.
GAN의 핵심 부분을 제외한 부분은 여기를 참고하면 된다.
https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html
이후 연구들
GAN 이후로 수많은 발전된 GAN이 연구되어 발표되었다. 가장 중요한 것 두 개는 GAN의 학습 불안정성을 많이 개선시킨 DCGAN(Deep Convolutional GAN), 단순 생성이 목적이 아닌 원하는 형태의 이미지를 생성시킬 수 있게 하는 CGAN(Conditional GAN)일 듯 하다.
많은 GAN들(catGAN, Semi-supervised GAN, LSGAN, WGAN, WGAN_GP, DRAGAN, EBGAN, BEGAN, ACGAN, infoGAN 등)에 대한 설명은 여기에서, CGAN에 대한 설명은 다음 글에서 진행하도록 하겠다.