
CGAN(Conditional GAN), C-GAN 논문 설명
19 Mar 2019 | GAN Machine Learning CNN Generative Model Paper_Review목차
- Conditional GAN(CGAN)
- 튜토리얼
- 이후 연구들
이 글에서는 2014년 11월 Mehdi Mirza 등이 발표한 Conditional Generative Adversarial Nets(CGAN)를 살펴보도록 한다.
CGAN은 GAN의 변형 모델이다.
(즉 DCGAN보다는 먼저 나왔다. 하지만 DCGAN이 GAN의 역사에서 제일 중요한 것 중 하나이기 때문에 CGAN을 나중으로 미뤘다.)
CGAN은 GAN과 학습 방법 자체는 별로 다를 것이 없다(D 학습 후 G 학습시키는 것).
GAN의 변형 모델들은 대부분 그 모델 구조를 바꾼 것이다.
CGAN을 도식화한 구조는 다음과 같다. 출처
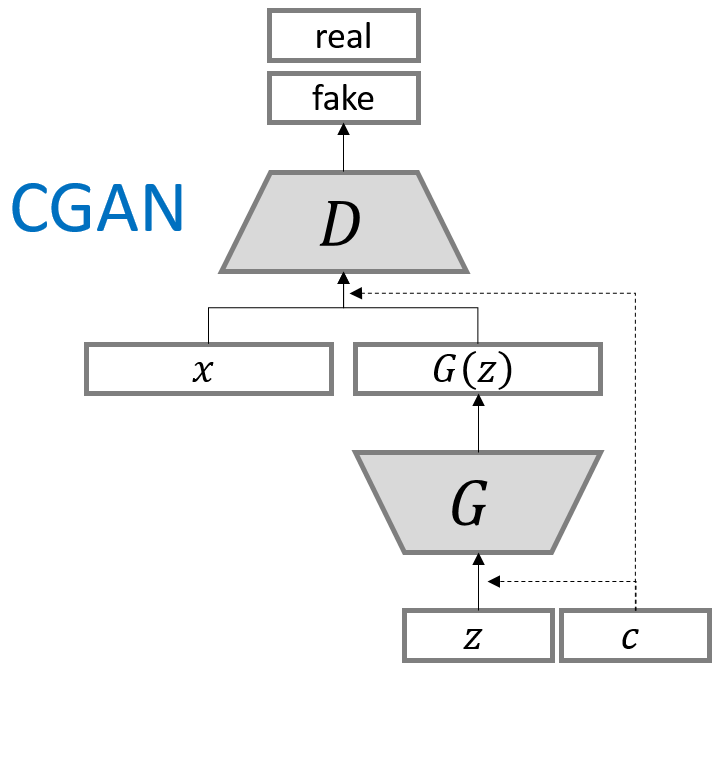
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
Conditional GAN(CGAN)
논문 링크: Conditional GAN
초록(Abstract)
2014년에 나온 논문임을 생각하라.
최근 GAN이 생성모델을 학습시키는 근사한 방법으로 소개되었다. 우리는 이 GAN의 조건부(conditional) 버전, 간단히 $y$ 데이터를 추가하여 만든 적대적 망을 소개하려 한다. 이 CGAN이 class label(숫자 0~9)에 맞는 MNIST 이미지를 생성할 수 있음을 보일 것이다. 또한 이 모델이 multi-modal 모델에 어떻게 사용될지, 또 이미지 태깅에 어떻게 응용 가능할지도 또한 설명할 것이다.
서론(Introduction)
생성 모델을 학습하기 위해, 다루기 힘든 엄청난 확률적 계산의 어려움을 대체하는 GAN이 최근 소개되었다. 적대신경망은 Markov chain이 필요없이 오직 back-propagation만으로 학습이 가능하고, 별다른 추측도 할 필요가 없다.
Unconditional 생성모델에서, 데이터가 생성되는 종류(mode)를 제어할 방법은 없다. 그러나, 추가 정보를 통해 데이터 생성 과정을 제어할 수 있다. 이러한 조건 설정(conditioning)은 class label 등에 기반할 수 있다.
이 논문에서 우리는 conditional 적대신경망을 구현할 것이다. 또 이를 MNIST와 MIR Flickr 데이터셋에 대해 테스트한다.
관련 연구(Related Works)
궁금하면 읽어보자.
Multi-modal Learning for Image Labelling
굉장히 많은 카테고리를 다룰 수 있는 모델에 관한 문제는 추가 modality에 대한 정보를 다루는 것으로 일부 해결 가능하다. 단어를 vector representation으로 변형하는 것 등이 있다.
input-output 1-1 매칭에만 치중한 문제는 conditional 확률적 생성모델을 사용하는 것이 한 방법이 될 수 있다.
자세한 내용은 원문을 보고 각 논문을 찾아보라. 이미 요약된 부분이라 그냥 건너뛰거나 본문을 보는 것이 더 낫다.
조건부 적대신경망(Conditional Adversarial Nets)
GAN(Genearative Adversarial Nets)
최근 소개된 GAN은 다음 두 부분으로 이루어졌다. 둘 다 non-linear하게 매핑하는 함수일 수 있다.
- 데이터분포를 입력받아 실제에 가깝게 데이터를 생성하는 생성모델 G
- 입력받은 데이터가 진짜 데이터인지 G가 만들어낸 것인지를 판별하는 D
다음 식으로 표현되는 minimax 게임을 G와 D가 진행하게 된다:
\[min_G max_D V(D, G) = \mathbb{E}_{x \sim p_{data}(x)}[log D(x)] + \mathbb{E}_{x \sim p_{z}(z)}[log (1-D(G(z)))]\]수식에 대한 자세한 설명은 GAN을 참고하라.
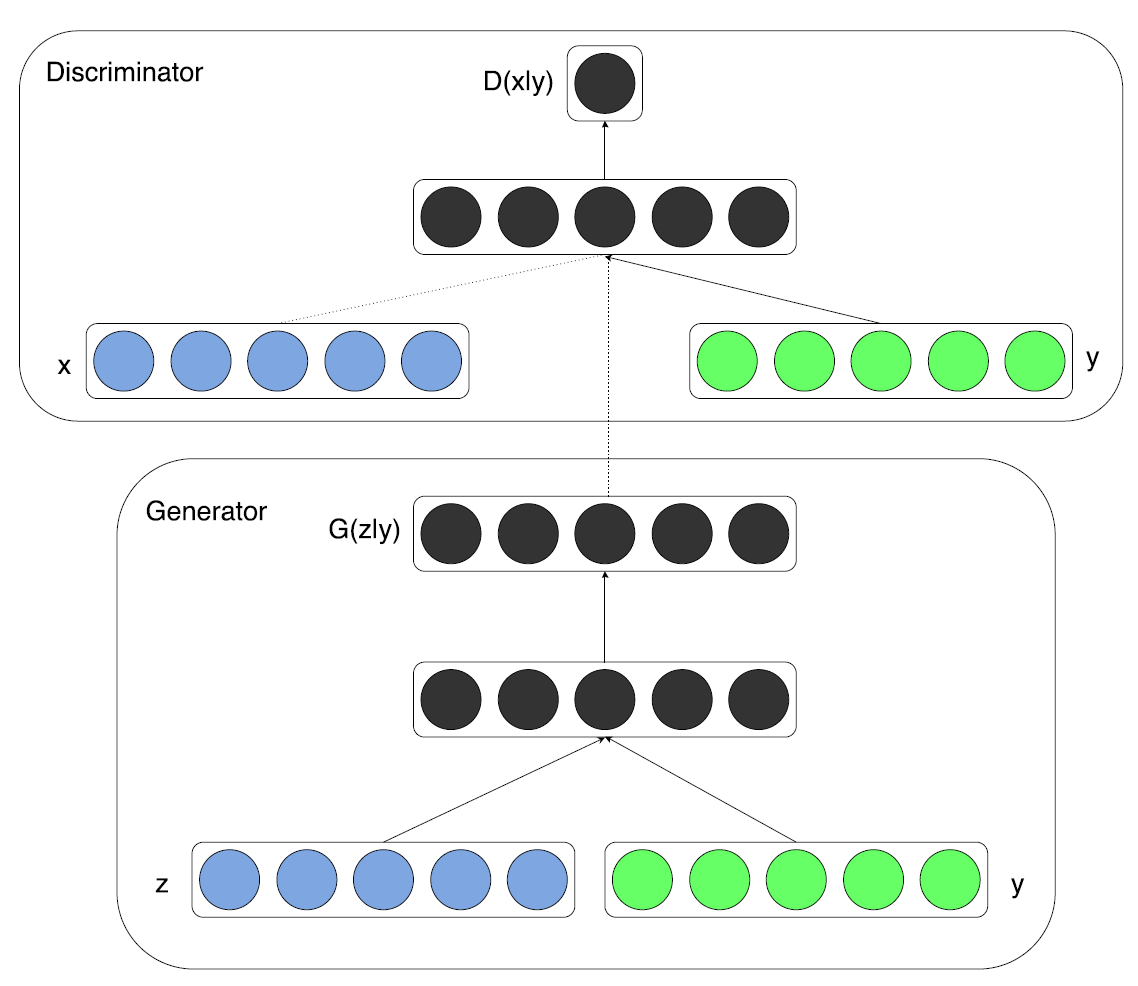
CGAN(Conditional Adversarial Nets)
G와 D가 추가 정보 $y$라는 조건이 붙는다면 조건부 생성모델을 만들 수 있다. $y$는 어떤 보조 정보라도 될 수 있는데, class label이나 다른 modality의 데이터 등이다. 우리는 $y$를 G와 D의 input layer에 추가로 같이 집어넣음으로써 이를 수행할 수 있다.
G에서는 input noise $p_z(z)$와 $y$가 합쳐진 형태가 된다. 이 적대적 학습 framework는 이 hidden representation이 어떻게 생겼는지에 별 영향을 받지 않는다.
D에서는 $x$와 $y$가 input으로써 들어가게 된다.
좀 전 수식을 conditional 버전으로 바꿔보면,
\[min_G max_D V(D, G) = \mathbb{E}_{x \sim p_{data}(x)}[log D(x|y)] + \mathbb{E}_{x \sim p_{z}(z)}[log (1-D(G(z|y)))]\]참고: D와 G에 들어가는 input이 단지 조건부로 바뀌었다. 실제 들어가는 형태는 합쳐진 형태이다.
실험 결과(Experimental Results)
이미 좋다는 게 알려진 논문의 경우에는 굳이 실험 조건 등을 자세히 볼 필요는 없다. 여기서는 결과만 소개한다.
Unimodal
모델 구조는 다음과 갈다.
- G
- uniform distribution $z$. size=100
- $z$와 $y$는 각각 size 200, 1000짜리 hidden layer(ReLU)로 매핑됨
- 1200짜리 hidden layer로 합쳐짐(ReLU)
- 마지막으로 784차원으로 변환됨(MNIST 이미지는 $28^2$이다)
- D
- $x$는 240 unit과 5 piece짜리 maxout layer, $y$는 50 unit과 5 piece짜리 maxout layer로 매핑됨
- 240 unit, 5 piece짜리 maxout layer로 합쳐진 후 Sigmoid
MNIST로 실험한 결과이다. Log-likelihood 값이 잘 나왔음을 확인할 수 있다.
| Model | MNIST |
|---|---|
| DBN | 138 $\pm $ 2 |
| Stacked CAE | 121 $\pm $ 1.6 |
| Deep GSN | 214 $\pm $ 1.1 |
| Adversarial nets | 225 $\pm $ 2 |
| Conditional adversarial nets | 132 $\pm $ 1.8 |
$y$ 데이터는 각 row별로 0~9까지 들어갔다. 아래는 CGAN을 통해 생성된 이미지이다.

주어지는 조건($y$)에 따라 class가 잘 나뉘는 것은 확인할 수 있다(이미지 품질은 original GAN과 비슷하다).
Multimodal
여러 이미지들에 대해 사람이 직접 넣은 태그와 CGAN이 생성해낸 태그를 비교한 테이블을 가져왔다.
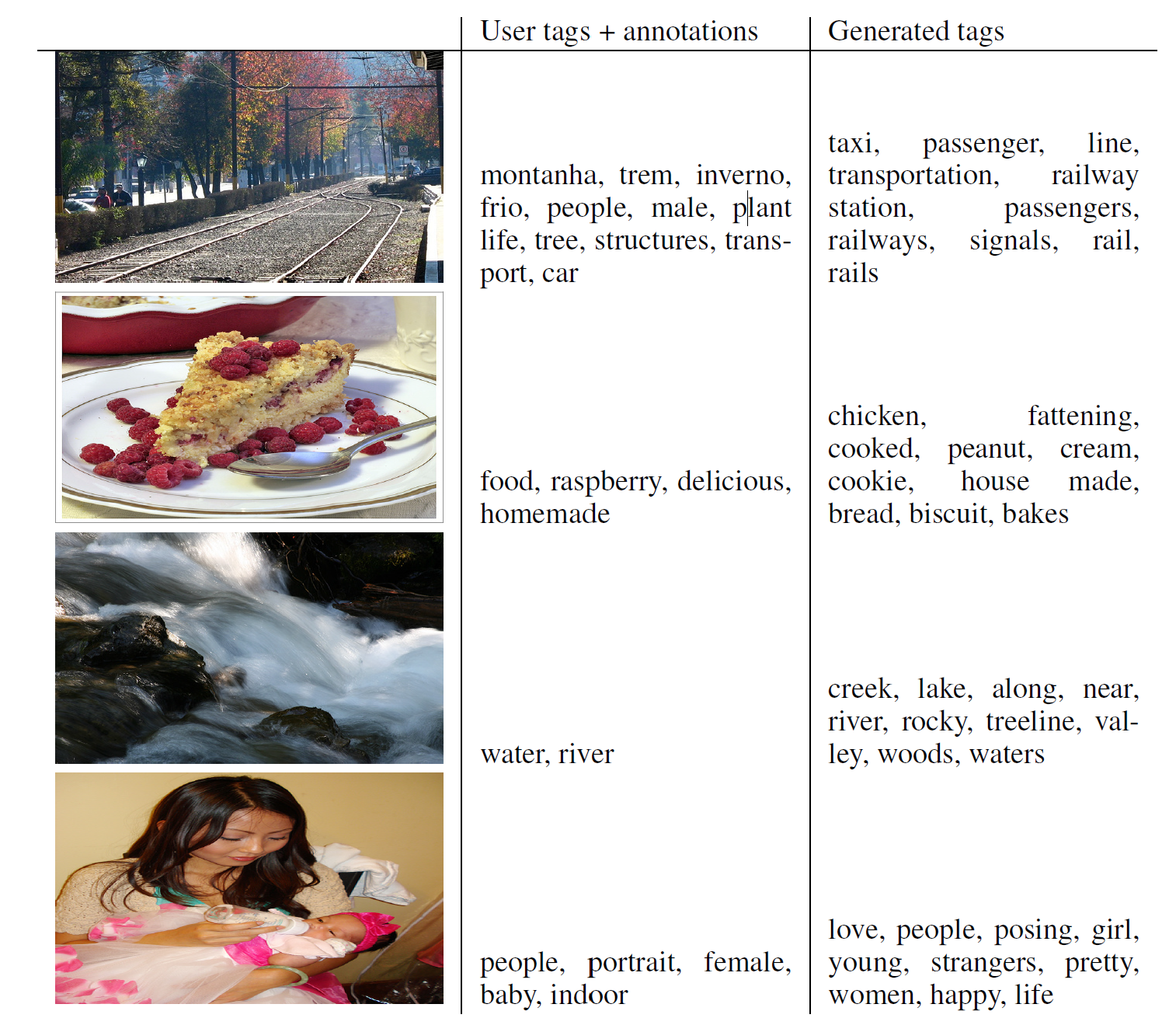
가장 오른쪽 열이 생성된 태그 중 제일 나은 것 10개를 나열한 것인데, 꽤 잘 된 것으로 보인다.
추후 연구(Future work)
이 논문에서 소개된 결과는 서론 정도의 내용이지만, 각각은 조건부 생성모델의 잠재력과 다른 많은 분야로의 응용에 대한 가능성을 보여 준다.
이번 실험에서는 태그를 독립적으로 사용했지만, 한번에 여러 태그를 사용한다면 더 나은 결과를 얻을 수 있을 것이다.
추후 연구의 또 다른 방향은 언어 모델을 배우는 학습계획을 구현하는 것이 있겠다.
Acknowledgments
이 프로젝트는 Pylearn2 framework로 개발되었다.
참고문헌(References)
논문 참조!
튜토리얼
GAN의 핵심 부분을 제외한 부분은 여기를 참고하면 된다.
여기에서 CGAN을 학습시켜볼 수 있다. 해당 repository에는 CGAN뿐 아니라 많은 종류의 GAN이 Pytorch로 구현되어 있으므로 참고하면 좋다.
이후 연구들
GAN 이후로 수많은 발전된 GAN이 연구되어 발표되었다.
많은 GAN들(catGAN, Semi-supervised GAN, LSGAN, WGAN, WGAN_GP, DRAGAN, EBGAN, BEGAN, ACGAN, infoGAN 등)에 대한 설명은 여기, f-GAN에 대한 설명은 여기에서 진행하도록 하겠다.