
DeepFM 논문 리뷰 및 Tensorflow 구현
07 Apr 2020 | Machine_Learning Recommendation System DeepFM목차
- 1. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction 논문 리뷰
- 2. Tensorflow 구현
- Reference
본 글의 전반부에서는 먼저 DeepFM: A Factorization-Machine based Neural Network for CTR Prediction 논문을 리뷰하면서 본 모델에 대해 설명할 것이다. 후반부에서는 Tensorflow를 이용하여 직접 코딩을 하고 학습하는 과정을 소개할 것이다. 논문의 전문은 이곳에서 확인할 수 있다.
1. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction 논문 리뷰
1.0. Abstract
추천 시스템에서 CTR을 최대화하는 것에 있어 사용자의 행동 속에 숨어있는 복잡한 feature interactions들을 학습하는 것은 매우 중요하다. 본 논문에서는 저차원 및 고차원 feature interactions를 모두 강조하면서 end-to-end 학습을 진행하는 모델에 대해 설명할 것이다. 이 DeepFM이라는 모델은 FM과 딥러닝을 결합한 것이다. 최근(2017년 기준) 구글에서 발표한 Wide & Deep model에 비해 피쳐 엔지니어링이 필요 없고, wide하고 deep한 부분에서 공통된 Input을 가진다는 점이 특징적이다.
1.1. Introduction
추천 시스템에서 CTR은 매우 중요하다. 많은 경우에 추천시스템의 목표는 이 클릭 수를 증대하는 것인데, 따라서 CTR 추정값에 근거하여 아이템을 정렬한 뒤 아이템(기사, 영화 등)을 사용자에게 제시할 수 있다. 온라인 광고에서는 수익을 증가시키는 것이 가장 중요하기에, 이 상황에서는 CTR * bid라는 기준 아래 랭킹 전략을 세울 수 있을 것이다. 여기서 bid는 사용자가 아이템을 클릭할 경우 시스템이 수령하는 수입을 의미한다. 어떠한 케이스든, 이 CTR을 정확히 추정하는 것은 매우 중요할 것이다.
CTR 예측에 있어 중요한 포인트는, 사용자의 클릭 행동 속에 숨어 있는 implicit feature interactions(암시적 피쳐 상호작용)를 학습할 줄 알아야 한다는 것이다.
예를 들어 사람들이 식사 시간에 음식 배달을 위한 앱을 다운로드 받는다면, 이 때 앱 카테고리와 시간이라는 요소 사이의 2차 상호작용이 바로 클릭에 대한 신호가 될 수 있다는 것이다. 10대 남자아이가 RPG게임을 좋아한다고 하자, 이 때는 앱 카테고리-사용자의 성별-사용자의 나이라는 3개 요소의 관계가 클릭을 결정하는 요인이 될 수 있다. 즉, 사용자의 클릭 뒤에 숨어있는 이러한 상호작용들은 매우 복잡하여 저/고차원 모두 잘 잡아내는 것이 매우 중요하다.
(중략)
feature representation을 학습하는 방법으로써 Deep Neural Network가 복잡한 feature interactions를 학습하는 잠재력을 갖고 있다고 판단된다. 다만 CNN-based 모델의 경우 이웃한 feature들 사이에 발생하는 상호작용에 의해 편향된 경향을 보이고, RNN-based 모델의 경우 sequential dependency를 갖고 있는 클릭 데이터에 상대적으로 적합한 모습을 보였다. 이후에 FNN, PNN, Wide & Deep 등 여러 모델들이 제안되었다. 본 논문에서는 이러한 모델들의 단점을 보완한 새로운 모델을 제시한다.
1) DeepFM은 피쳐 엔지니어링 없이 end-to-end 학습을 진행할 수 있다. 저차원의 interaction들은 FM 구조를 통해 모델화하고, 고차원의 interaction들은 DNN을 통해 모델화한다.
2) DeepFM은 같은 Input과 Embedding 벡터를 공유하기 때문에 효과적으로 학습을 진행할 수 있다.
3) 본 논문에서 DeepFM은 벤치마크 데이터와 상업용 데이터 모두에서 평가될 것이다.
1.2. Our Approach
$n$개의 instance를 가진 $(\chi, y)$ 학습 데이터셋이 있다고 하자. 이 때 $\chi$는 $m$개의 field를 지니고 있고, $y$는 0과 1의 값을 가진다. (1 = 클릭함)
$\chi$에는 범주형 변수가 있을 수도 있고, 연속형 변수가 있을 수도 있다. 범주형 변수의 경우 원핫인코딩된 벡터로 표현되며, 연속형 변수의 경우 그 값 자체로 표현되거나 이산화되어 원핫인코딩된 벡터로 표현될 수도 있다.
그렇다면 이제 데이터는 $(x, y)$로 표현할 수 있을 것이다. 여기서 $x$는 $[x_{field_1}, x_{field_2}, …, x_{field_m}]$의 구조를 갖게 되며 각각의 $x_{field_j}$는 $\chi$에서의 j번째 field의 벡터 표현을 의미하게 된다. 일반적으로 $x$는 굉장히 고차원이고 희소하다. CTR의 목적은 context가 주어졌을 때 사용자가 특정 어플을 클릭할 확률을 정확히 추정하는 것이다.
1.2.1. DeepFM
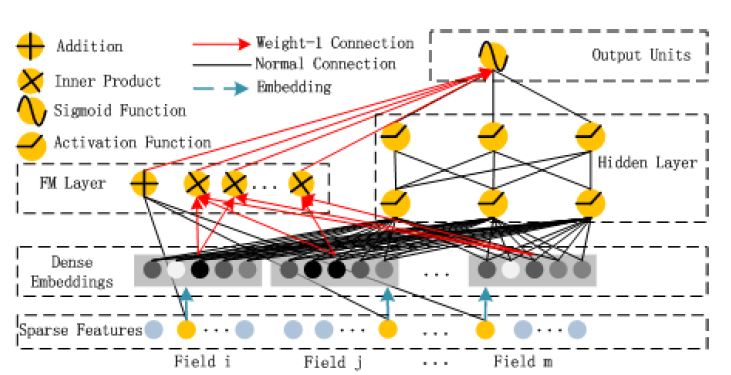
위 그림에서도 확인할 수 있다시피, DeepFM은 2가지 요소로 구성되어 있다. 이 요소들은 같은 Input을 공유한다.
- $i$번재 피쳐에 대해 스칼라 $w_i$: 1차원 importance를 측정함
- latent vector $V_i$: 다른 피쳐들과의 interaction의 영향을 측정
$V_i$의 경우 FM요소에서는 2차원 interaction을 모델화하며, Deep요소에서는 고차원 피쳐 interaction을 모델화한다. 모든 파라미터들은 통합 예측모델에서 함께 학습된다. 즉 모델을 아주 간단히 표현하자면 아래와 같다.
\[\hat{y} = sigmoid(y_{FM} + y_{DNN})\]FM Component
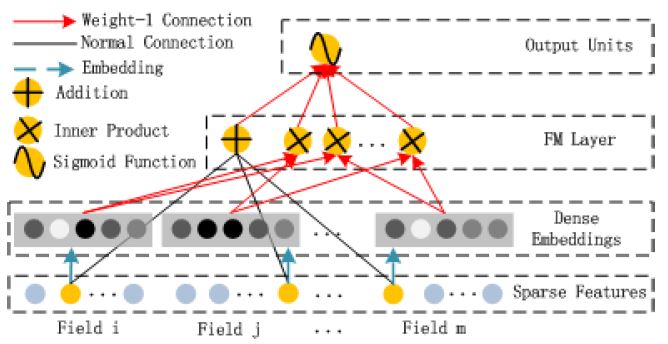
FM요소는 Factorization Machine이다. FM모델에 대한 설명은 이글에서 확인할 수 있다.
Deep Component
CTR 예측에 사용되는 Raw 데이터는 일반적으로 매우 희소하고, 고차원이며, 범주형/연속형 변수가 섞여 있고, 일종의 field(성별, 위치, 나이 등)로 그룹화되어 있다는 특징을 지닌다. 따라서 Embedding Layer로 이러한 정보들을 압축하여 저차원의, dense한 실수 벡터를 만들어서 Input을 재가공할 필요가 있다.
아래 그림은 Input Layer에서 Embedding Layer로 이어지는 보조 네트워크를 강조한 부분이다. 여기서 확인해야 할 부분은 2가지이다. 첫 번재는, Input으로 쓰이는 Input field 벡터가 각자 다른 길이를 갖고 있을 수 있기 때문에, 이들의 임베딩은 같은 크기(k)여야 한다는 것이다. 두 번재는, FM 모델에서 latent 벡터로 기능했던 $V$는 본 요소에서는 Input field 벡터를 Embedding 벡터로 압축하기 위해 사용되고 학습되는 네트워크 weight가 된다는 것이다.
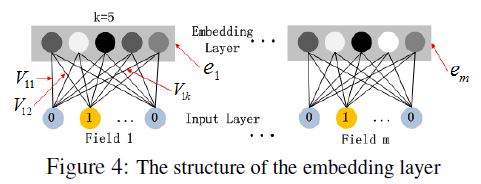
Embedding Layer의 Output은 아래와 같다.
\[a^0 = [e_1, e_2, ..., e_m]\]- $e_i$는 i번재 field의 Embedding
- $m$은 field의 수
$a^{(0)}$는 DNN에 투입되며 forward process는 다음과 같다.
\[a^{(l+1)} = \sigma{(W^{(l)}a^{(l)} + b^{(l)}})\]- $l$: layer의 깊이
이렇게 Dense한 실수 피쳐 벡터가 생성되면 CTR prediction을 위해 최종적으로 sigmoid 함수에 투입되게 된다.
\[y_{DNN} = \sigma{(W^{|H|+1} a^{|H|} + b^{|H| + 1}})\]- $ㅣHㅣ$: hidden layer의 수
- $ \vert H \vert $: hidden layer의 수
1.5. Conclusions
DeepFM은 FM Component와 Deep Component를 함께 학습시킨다. 이러한 방식은 다음과 같은 장점을 지닌다.
1) pre-training이 필요 없다.
2) 저/고차원 feature를 모두 잘 학습한다.
3) feature embedding을 통해 피쳐 엔지니어링이 불필요하다.
실험 결과를 확인하면, DeepFM이 최신 모델들을 압도하고 상당한 효율성을 지닌 것을 알 수 있다.
2. Tensorflow 구현
2.1. 데이터 설명 및 데이터 변환
구현의 핵심은 Parameter인 $w$와 $V$의 shape과 활용 방법에 대해 이해하는 것이다. 사실 구현하는 사람의 입장에서는 논문이 썩 친절하다고 느끼지는 못할 것이다. 다소 애매모호한 표현으로 읽는 사람으로 하여금 혼란을 일으키게 하는 문구나 그림 등도 존재한다. 그럼에도 침착하게 잘 생각해보면, 모델을 구축할 수 있을 것이다.
학습 데이터로는 연봉이 5만 달러를 상회하는지의 여부를 예측하는 데이터를 사용하였고, 여기에서 다운로드 받을 수 있다.
데이터는 48,842개의 Instance로 구성되어 있고, 14개의 Feature를 갖고 있으며, 이 중 6개의 변수가 연속형 변수이다. 당연히 예측 과제는 Binary Classification이다. 0은 연봉 5만 달러 이하를 의미하며, 전체 데이터의 25% 정도를 차지한다. 1은 연봉 5만 달러 초과를 의미한다.
앞에서 설명한 데이터를 예로 들어 설명하도록 하겠다. 이 데이터에는 총 14개의 변수가 있다. 이 14개는 곧, field의 개수가 된다. 이 중 범주형 변수를 One-Hot 인코딩을 통해 변환시키면(물론 연속형 변수도 필요에 따라 구간화하여 범주형 변수화해도 된다.) 본 데이터는 총 108개의 칼럼을 갖게 된다. 이 108개는 곧, feature의 개수가 된다. 즉, One-Hot 인코딩을 통해 변환시킨 칼럼의 개수를 feature의 개수로, 인코딩 이전의 데이터의 칼럼의 개수를 field의 개수로 이해하면 쉽다. 논문에서는 임베딩 스킬을 이용하고 있는데, 여기서 Embedding Matrix인 $V$의 칼럼의 개수는 Hyperparameter이다.
본 프로젝트 파일은 다음과 같이 5개의 py파일로 구성되어 있다.
먼저 config파일을 보자. 이 파일에는 칼럼의 목록을 연속형/범주형을 구분하여 저장한 리스트와 Hyperparameter들이 저장되어 있다.
# config.py
ALL_FIELDS = ['age', 'workclass', 'fnlwgt', 'education', 'education-num',
'marital-status', 'occupation', 'relationship', 'race',
'sex', 'capital-gain', 'capital-loss', 'hours-per-week', 'country']
CONT_FIELDS = ['age', 'fnlwgt', 'education-num',
'capital-gain', 'capital-loss', 'hours-per-week']
CAT_FIELDS = list(set(ALL_FIELDS).difference(CONT_FIELDS))
# Hyper-parameters for Experiment
NUM_BIN = 10
BATCH_SIZE = 256
EMBEDDING_SIZE = 5
이제 데이터를 가공할 시간이다. (데이터가 매우 커서 서버에서 데이터를 받아오는 상황이라면, 아래 코드를 pyspark로 짜면 좋을 것이다.) 지금부터 할 작업은 field_index와 field_dict를 만드는 것인데, 쉽게 말해서 아래와 같은 작업을 진행하는 것이다.
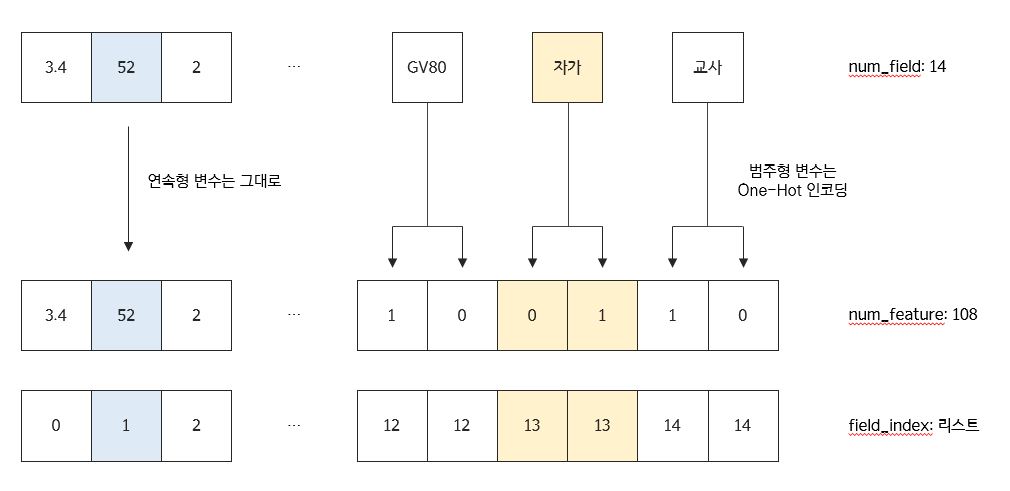
인코딩 이후의 데이터에 대해 각 칼럼이 본래 인코딩 이전에 몇 번째 field에 속했었는지에 대한 정보를 저장한 것이 field_index와 field_dict이다.
# Preprocess
import config
from itertools import repeat
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
def get_modified_data(X, all_fields, continuous_fields, categorical_fields, is_bin=False):
field_dict = dict()
field_index = []
X_modified = pd.DataFrame()
for index, col in enumerate(X.columns):
if col not in all_fields:
print("{} not included: Check your column list".format(col))
raise ValueError
if col in continuous_fields:
scaler = MinMaxScaler()
# 연속형 변수도 구간화 할 것인가?
if is_bin:
X_bin = pd.cut(scaler.fit_transform(X[[col]]).reshape(-1, ), config.NUM_BIN, labels=False)
X_bin = pd.Series(X_bin).astype('str')
X_bin_col = pd.get_dummies(X_bin, prefix=col, prefix_sep='-')
field_dict[index] = list(X_bin_col.columns)
field_index.extend(repeat(index, X_bin_col.shape[1]))
X_modified = pd.concat([X_modified, X_bin_col], axis=1)
else:
X_cont_col = pd.DataFrame(scaler.fit_transform(X[[col]]), columns=[col])
field_dict[index] = col
field_index.append(index)
X_modified = pd.concat([X_modified, X_cont_col], axis=1)
if col in categorical_fields:
X_cat_col = pd.get_dummies(X[col], prefix=col, prefix_sep='-')
field_dict[index] = list(X_cat_col.columns)
field_index.extend(repeat(index, X_cat_col.shape[1]))
X_modified = pd.concat([X_modified, X_cat_col], axis=1)
print('Data Prepared...')
print('X shape: {}'.format(X_modified.shape))
print('# of Feature: {}'.format(len(field_index)))
print('# of Field: {}'.format(len(field_dict)))
return field_dict, field_index, X_modified
2.2. 모델 빌드
먼저 FM Component에 대해 살펴보자. call 함수에서 y_fm을 어떤 shape으로 반환할 지는 그 task에 맞게 변환하면 된다. 아래 코드에서는 (None, 2)의 형태로 반환되어 최종적으로 Deep Component의 (None, 2)와 합쳐져 (None, 4)의 최종 Output을 반환하게 되는데, 이 수치는 성능 향상을 위해 변경이 가능하다.
Parameter $w$의 길이는 num_feature(108)이며, Parameter $V$의 shape은 num_field(14), embedding_size(5)이다. 그런데 아래 call 함수에서 보면 알 수 있듯이, 이 $V$행렬은 One-Hot 인코딩된 데이터에 곱해지는 구조이기 때문에 tf.nn.embedding_lookup이라는 함수를 통해 행이 복제된다. 즉, 앞서 생성한 field_index의 정보를 참조하여, 같은 field에서 나온 feature일 경우, 같은 Embedding Row($V$의 Row)를 공유하는 것이다.
new_inputs는 Deep Component의 Input으로 쓰일 개체이다. 코드를 살펴보면, $V$라는 행렬이 FM Component에도 쓰이지만, new_inputs를 만들어내면서 Deep Component에도 영향을 미치는 것을 알 수 있다.
class FM_layer(tf.keras.layers.Layer):
def __init__(self, num_feature, num_field, embedding_size, field_index):
super(FM_layer, self).__init__()
self.embedding_size = embedding_size # k: 임베딩 벡터의 차원(크기)
self.num_feature = num_feature # f: 원래 feature 개수
self.num_field = num_field # m: grouped field 개수
self.field_index = field_index # 인코딩된 X의 칼럼들이 본래 어디 소속이었는지
# Parameters of FM Layer
# w: capture 1st order interactions
# V: capture 2nd order interactions
self.w = tf.Variable(tf.random.normal(shape=[num_feature],
mean=0.0, stddev=1.0), name='w')
self.V = tf.Variable(tf.random.normal(shape=(num_field, embedding_size),
mean=0.0, stddev=0.01), name='V')
def call(self, inputs):
x_batch = tf.reshape(inputs, [-1, self.num_feature, 1])
# Parameter V를 field_index에 맞게 복사하여 num_feature에 맞게 늘림
embeds = tf.nn.embedding_lookup(params=self.V, ids=self.field_index)
# Deep Component에서 쓸 Input
# (batch_size, num_feature, embedding_size)
new_inputs = tf.math.multiply(x_batch, embeds)
# (batch_size, )
linear_terms = tf.reduce_sum(
tf.math.multiply(self.w, inputs), axis=1, keepdims=False)
# (batch_size, )
interactions = 0.5 * tf.subtract(
tf.square(tf.reduce_sum(new_inputs, [1, 2])),
tf.reduce_sum(tf.square(new_inputs), [1, 2])
)
linear_terms = tf.reshape(linear_terms, [-1, 1])
interactions = tf.reshape(interactions, [-1, 1])
y_fm = tf.concat([linear_terms, interactions], 1)
return y_fm, new_inputs
아래는 메인 모델에 대한 코드이다. 성능 향상을 위해 Deep Component를 수정하는 것은 연구자의 자유이다. Task에 따라 가볍게 설계할 수도, 복잡하게 설계할 수도 있을 것이다. 본 코드에서는 Dropout만을 추가하여 다소 가볍게 설계하였다.
import tensorflow as tf
from layers import FM_layer
tf.keras.backend.set_floatx('float32')
class DeepFM(tf.keras.Model):
def __init__(self, num_feature, num_field, embedding_size, field_index):
super(DeepFM, self).__init__()
self.embedding_size = embedding_size # k: 임베딩 벡터의 차원(크기)
self.num_feature = num_feature # f: 원래 feature 개수
self.num_field = num_field # m: grouped field 개수
self.field_index = field_index # 인코딩된 X의 칼럼들이 본래 어디 소속이었는지
self.fm_layer = FM_layer(num_feature, num_field, embedding_size, field_index)
self.layers1 = tf.keras.layers.Dense(units=64, activation='relu')
self.dropout1 = tf.keras.layers.Dropout(rate=0.2)
self.layers2 = tf.keras.layers.Dense(units=16, activation='relu')
self.dropout2 = tf.keras.layers.Dropout(rate=0.2)
self.layers3 = tf.keras.layers.Dense(units=2, activation='relu')
self.final = tf.keras.layers.Dense(units=1, activation='sigmoid')
def __repr__(self):
return "DeepFM Model: #Field: {}, #Feature: {}, ES: {}".format(
self.num_field, self.num_feature, self.embedding_size)
def call(self, inputs):
# 1) FM Component: (num_batch, 2)
y_fm, new_inputs = self.fm_layer(inputs)
# retrieve Dense Vectors: (num_batch, num_feature*embedding_size)
new_inputs = tf.reshape(new_inputs, [-1, self.num_feature*self.embedding_size])
# 2) Deep Component
y_deep = self.layers1(new_inputs)
y_deep = self.dropout1(y_deep)
y_deep = self.layers2(y_deep)
y_deep = self.dropout2(y_deep)
y_deep = self.layers3(y_deep)
# Concatenation
y_pred = tf.concat([y_fm, y_deep], 1)
y_pred = self.final(y_pred)
y_pred = tf.reshape(y_pred, [-1, ])
return y_pred
2.3. 학습
학습 코드는 아래와 같다. 그리 무거운 모델은 아니므로 Autograph는 사용하지 않았다.
import config
from preprocess import get_modified_data
from DeepFM import DeepFM
import numpy as np
import pandas as pd
from time import perf_counter
import tensorflow as tf
from sklearn.model_selection import train_test_split
from tensorflow.keras.metrics import BinaryAccuracy, AUC
def get_data():
file = pd.read_csv('data/adult.data', header=None)
X = file.loc[:, 0:13]
Y = file.loc[:, 14].map({' <=50K': 0, ' >50K': 1})
X.columns = config.ALL_FIELDS
field_dict, field_index, X_modified = \
get_modified_data(X, config.ALL_FIELDS, config.CONT_FIELDS, config.CAT_FIELDS, False)
X_train, X_test, Y_train, Y_test = train_test_split(X_modified, Y, test_size=0.2, stratify=Y)
train_ds = tf.data.Dataset.from_tensor_slices(
(tf.cast(X_train.values, tf.float32), tf.cast(Y_train, tf.float32))) \
.shuffle(30000).batch(config.BATCH_SIZE)
test_ds = tf.data.Dataset.from_tensor_slices(
(tf.cast(X_test.values, tf.float32), tf.cast(Y_test, tf.float32))) \
.shuffle(10000).batch(config.BATCH_SIZE)
return train_ds, test_ds, field_dict, field_index
# Batch 단위 학습
def train_on_batch(model, optimizer, acc, auc, inputs, targets):
with tf.GradientTape() as tape:
y_pred = model(inputs)
loss = tf.keras.losses.binary_crossentropy(from_logits=False, y_true=targets, y_pred=y_pred)
grads = tape.gradient(target=loss, sources=model.trainable_variables)
# apply_gradients()를 통해 processed gradients를 적용함
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# accuracy & auc
acc.update_state(targets, y_pred)
auc.update_state(targets, y_pred)
return loss
# 반복 학습 함수
def train(epochs):
train_ds, test_ds, field_dict, field_index = get_data()
model = DeepFM(embedding_size=config.EMBEDDING_SIZE, num_feature=len(field_index),
num_field=len(field_dict), field_index=field_index)
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
print("Start Training: Batch Size: {}, Embedding Size: {}".format(config.BATCH_SIZE, config.EMBEDDING_SIZE))
start = perf_counter()
for i in range(epochs):
acc = BinaryAccuracy(threshold=0.5)
auc = AUC()
loss_history = []
for x, y in train_ds:
loss = train_on_batch(model, optimizer, acc, auc, x, y)
loss_history.append(loss)
print("Epoch {:03d}: 누적 Loss: {:.4f}, Acc: {:.4f}, AUC: {:.4f}".format(
i, np.mean(loss_history), acc.result().numpy(), auc.result().numpy()))
test_acc = BinaryAccuracy(threshold=0.5)
test_auc = AUC()
for x, y in test_ds:
y_pred = model(x)
test_acc.update_state(y, y_pred)
test_auc.update_state(y, y_pred)
print("테스트 ACC: {:.4f}, AUC: {:.4f}".format(test_acc.result().numpy(), test_auc.result().numpy()))
print("Batch Size: {}, Embedding Size: {}".format(config.BATCH_SIZE, config.EMBEDDING_SIZE))
print("걸린 시간: {:.3f}".format(perf_counter() - start))
model.save_weights('weights/weights-epoch({})-batch({})-embedding({}).h5'.format(
epochs, config.BATCH_SIZE, config.EMBEDDING_SIZE))
if __name__ == '__main__':
train(epochs=100)
Embedding Size를 변환하면서 진행한 테스트 결과는 아래와 같다. (Epoch: 100)
| Embedding Size | 누적 Loss | Train ACC | Train AUC | Test ACC | Test AUC | 시간 |
|---|---|---|---|---|---|---|
| 10 | 0.3243 | 0.8485 | 0.9038 | 0.8464 | 0.8991 | 4분 0.78초 |
| 9 | 0.3386 | 0.8382 | 0.8954 | 0.8402 | 0.8975 | 4분 3.64초 |
| 8 | 0.3704 | 0.8240 | 0.8729 | 0.8260 | 0.8745 | 4분 2.79초 |
| 7 | 0.3248 | 0.8471 | 0.9033 | 0.8424 | 0.9013 | 4분 0.84초 |
| 6 | 0.3305 | 0.8433 | 0.9001 | 0.8416 | 0.9041 | 4분 1.28초 |
| 5 | 0.3945 | 0.8169 | 0.8512 | 0.8190 | 0.8576 | 4분 8.10초 |
Reference
https://github.com/ChenglongChen/tensorflow-DeepFM