
PinSAGE (Graph Convolutional Neural Networks for Web-Scale Recommender Systems) 설명
21 Feb 2021 | Machine_Learning Recommendation System Paper_Review목차
본 글에서는 2018년에 발표된 Graph Convolutional Neural Networks for Web-Scale Recommender Systems란 논문에 대한 Review를 진행할 것이다. 본 논문은 Graph 구조의 신경망을 Pinterest의 추천 시스템에 어떻게 적용하였는지에 대한 내용을 담고 있으며 이전 글에 설명하였던 GraphSAGE의 후속편으로 이해해도 좋을 것 같다.
Graph Convolutional Neural Networks for Web-Scale Recommender Systems 리뷰
1. Introduction
(전략)
본 논문에서는 굉장히 확장 가능성이 높은 GCN 프레임워크를 소개할 것이고, 이는 Pinterest에서 상용화되었다. PinSAGE라고 이름 붙인 Random-Walk 기반의 GCN은 일반적인 GCN의 적용 사례보다 훨씬 더 큰, 3B Node, 18B Edege 크기의 대형 그래프에 적용되었다. 즉 PinSAGE는 몇몇 주요 인사이트를 활용하여 GCN의 확장 가능성을 크게 개선한 것이라고 볼 수 있다.
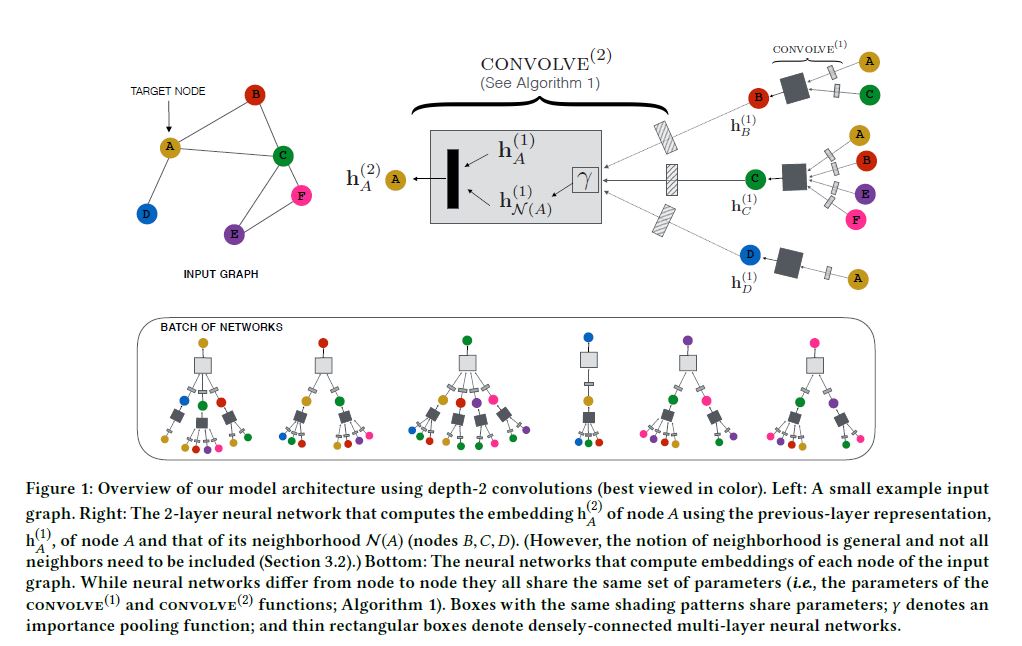
본 알고리즘은 크게 2가지 측면에서 개선이 이루어졌다. 먼저, 펀더멘탈 측면에서 보자.
1) On-the-fly Convolutions
첫 번째로 기존 GCN 알고리즘들이 전체 그래프 라플라시안을 이용하여 변수 행렬을 곱했던 형식을 적용한 것과 달리 PinSAGE은 Node 주변의 이웃들을 Sampling하고 이에 대해 합성곱을 적용한 방식을 사용하였다. 이는 GraphSAGE에서의 방식과 유사하다.
2) Producer-consumer minibatch construction
CPU-bound producer는 효율적으로 Node 주변의 이웃을 추출하고 합성곱에 필요한 변수들을 준비해놓는다. 반면 GPU-bound Tensorflow Model은 미리 정의된 계산 그래프에서 효율적인 Stochastic Gradient Descent를 수행하게 된다.
3) Efficient MapReduce Inference
반복적 연산은 최소화하면서 학습된 모델이 수많은 Node에 대해 임베딩을 빠르게 생성할 수 있도록 하였다.
다음으로는 새로운 학습 테크닉에 대해 간단히 살펴보겠다.
1) Constructing Convolutions via Random Walks
앞서 이웃을 Sampling 한다고 하였는데 단순히 무작위 추출은 효율적이지 못하다. 본 논문에서는 연산 그래프를 추출하기 위해 작은 Random Walk를 활용하는 테크닉을 적용하였다. 각 Node는 Importance Score를 갖고 있고 이는 Pooling/Aggregation 단계에서 활용된다.
2) Importance Pooling
Random Walk 유사성 측정에 기반하여 Aggregation 단계에서 Node Feature의 중요도에 따라 가중치를 부여하는 방식을 적용하여 46%의 성능 향상을 이끌어내었다.
3) Curriculum Training
학습이 지속될 수록 더 어려운 학습셋을 제공하는 방식을 통해 12%의 성능 향상을 이끌어내었다.
PinSAGE는 Pinterest의 여러 추천 task에 활용되었다. 온라인 컨텐츠의 시각적 북마크라고 할 수 있는 Pin을 고객들에게 맞춤식으로 제공하는 것이 대표적이다. 고객들은 이러한 Pin들 중 유사한 것들을 모아 Board를 통해 집합적으로 구성하게 된다. 결국 Pinterest가 제공하는 것은, 2B가 넘는 Pin과 1B가 넘는 Borad로 이루어진, 세계에서 가장 큰 고객 맞춤형 이미지 그래프인 것이다.
2. Related Work
논문을 직접 참고하길 바란다. 한 가지만 언급하자면, PinSAGE은 전체 Graph를 GPU 메모리에 저장할 필요가 없게 만듦으로써 GraphSAGE를 개선하였다.
3. Method
3.1. Problem Setup
Pin과 Board에 대해서는 앞서 설명하였다. Pinterest의 목적은 Pin에 대한 고품질의 Embedding 혹은 Representation을 얻는 것이다. 이를 위해서는 우리는 Pinterest 환경을 이분 그래프 형태로 모델링하였다. 이 때 Node의 종류로는 $I$ (Pin)와 $C$ (Board)가 있을 것이다. 다만 본 논문에서는 $I$ 는 Item의 집합으로 간주하였고, $C$ 는 고객을 정의하는 Context의 집합으로 보았다. 즉 일반적으로 생각하는 User-Item 구조가 아닌 것이다.
Pin(Item)은 어떤 실수 attribute인 $x_u \in \mathbb(R)^d$ 와 관련되어 있는 것으로 가정하였다. 이것은 Raw Feature를 의미하는데 Item에 대한 메타데이터나 컨텐츠 정보를 의미하게 될 것이다.
최종적으로 만들어진 Embedding은 Nearest Neighbor Lookup을 통해 Candidate Generation 형태로 활용되거나 Candidate에 랭킹을 매키는 머신러닝 시스템에서 Feature의 형태로 활용될 것이다.
본 논문에서는 전체 그래프의 Node Set을 $\mathcal{V} = \mathcal{I} \cup \mathcal{C}$ 라 표기할 것이다. 이는 Pin과 Board를 명시적으로 구분하지 않음을 뜻한다. 이러한 Setting은 Pinterest의 시스템 하에서 가능한 것이고, 일반적인 User-Item 추천 시스템에서는 변형이 필요할 것이다.
3.2. Model Architecture
Input Node Feature가 주어지면 그래프 구조를 통해 Node Embedding을 계산하도록 변형&통합하는 신경망을 통과하게 된다.
Node $u$ 에 대해 Embedding $z_u$ 를 얻는 과정은 아래와 같다.

기본적인 전개는 GraphSAGE와 유사하니 생략하고 달라진 부분에 대해서만 정리하도록 하겠다.
위 과정에서 $\gamma$ 는 원소평균 또는 가중합 함수를 의미한다. $u$ 의 지역 이웃은 $n_u$ 로, $u$ 의 현재 Hidden Representation은 $h_u$ 로 표기한다.
Importance-based Pooling에 대해 설명할 차례이다. 이전 GCN 알고리즘들은 단순히 k-hop 이웃을 확인하였다면, PinSAGE의 경우 이웃을 무작위로 선별하지 않는다. Node $u$ 에 대해 가장 큰 영향을 미치는 $T$ 개의 Sample을 추출하는 방법을 사용할 것이다. 구체적으로, Node $u$ 로부터 시작하여 Random Walk를 수행한 후, 이 Random Walk에서 만나게 되는 Nodes의 만남 횟수를 기록하고 이에 L1 정규화를 적용하게 된다. Node $u$ 의 이웃은 이렇게 기록된 정규화된 방문 횟수가 가장 높은 $T$ 개의 Node들로 정의되게 된다.
이러한 방법은 메모리를 절약하고 중요도를 고려한 이웃을 추출할 수 있다는 장점을 지닌다.
파라미터에 대해 정리해보겠다. 위 알고르짐에서 학습 가능한 파라미터는 $\mathbf{Q, q, W, w}$ 이다. 그리고 이들은 어떤 k번째 Layer이냐에 따라 독립적으로 학습된다. 즉 $\mathbf{Q^{(1)}, Q^{(2)}}$ 가 존재한다는 것이다. 이 또한 GraphSAGE와 같은 설정이다. 각 합성곱 Layer를 통과한 Hidden Representation 벡터의 길이는 $d$ 이며, 최종 임베딩 벡터의 길이 또한 $d$ 이다.
3.3. Model Training
본 논문에서 PinSAGE는 Max-margin Ranking Loss를 통해 학습되었다. 라벨링된 아이템 쌍 집합인 $\mathcal{L}$ 을 갖고 있다고 하자, 이 때 Item 쌍 $(q, i) \in \mathcal{L}$ 은 서로 관련이 있다고 정의된다. 이 때 $q$ 는 query item을 뜻하는데 위와 같은 표기는 Item $i$ 가 query item $q$ 에 좋은 추천이 된다는 뜻이다. 예를 들어 어떤 사람이 $q$ 라는 Item을 과거에 이용한 적이 있다면 이 사람에게 $i$ 라는 Item을 추천해줄 수 있을 것이다.
학습 과정의 목표는 라벨링된 $(q, i) \in \mathcal{L}$ 쌍의 최종 Embedding이 유사한 값을 갖게 만드는 것이다. 이제 학습 과정 상의 주요 포인트들에 대해 알아보자.
Loss Function
Positive Example 사이의 내적 값은 크게 하고, Negative Example 사이의 내적 값은 작게 만드는 것이 이 손실 함수의 기본적인 생각이다. 식은 아래와 같다.
이 때 $P_n(q)$ 는 item $q$ 를 위한 Negative Example의 분포를 의미하며, $\Delta$ 는 Margin Hyper-parameter이다.

Multi-GPU training with large minibathces
각 미니 배치를 같은 크기로 나눈다. 각 GPU는 미니배치의 한 부분씩을 담당하게 되고 같은 파라미터셋으로 연산을 수행한다. 역전파가 수행될 때 모든 GPU에 존재하는 각 파라미터들의 Gradient는 공유되며 동기식 SGD가 수행된다. 배치의 크기는 512 ~ 4096 사이의 숫자를 사용한다.
Producer-consumer minibatch constructions
(전략)
GPU는 모델 계산을, CPU는 Feature를 추출하고 재색인을 수행하며, Negative Sampling의 역할을 맡는다.
Sampling Negative Items
본 논문에서는 한 미니 배치에서 500개의 Negative Item이 공유되도록 설정하였다. 그런데 이 500개를 전체 Item 집합에서 무작위 추출을 통해 뽑는다면, 학습은 너무 쉬울 것이다. 왜냐하면 무작위로 뽑은 500개의 Item과 Query Item과의 내적 값은 Positive Example과의 내적 값에 비해 작을 확률이 매우 크기 때문이다. 따라서 본 논문에서는 다른 방법을 도입하였다.
각 Positive Training Example에 어려운 Negative Example을 추가하였다. 즉, Query Item과 어느 정도 관련은 있지만 Positive Example 만큼 관련있지는 않은 Item을 추가한 것이다.

이러한 어려운 Negative Example은 Query Item에 대한 개인화된 PageRank Score에 따라 그래프에서 Item에 대한 순위를 매김으로써 생성되며 2000~5000위 사이의 Item을 어려운 Negative Example라고 정의하였다.
이러한 학습 방식을 적용하였을 때, 그렇지 않았을 때에 비하여 2배의 Epoch이 필요하다. 본 논문에서는 수렴을 위해 Curriculumn Training 방식을 도입하였다. 1 Epoch에서는 어려운 Negative Example을 추가하지 않고 학습을 시킨다. 이후에서는 각 Query Item 마다 1개의 어려운 Negative Example을 추가한다. Epoch이 하나씩 지날 수록 이 어려운 Negative Example은 1개씩 더 추가된다.
3.4. Node Embeddings via MapReduce
학습이 끝난 후 Embedding을 생성하는 것도 굉장한 연산량을 요하는 작업이다. 본 논문에서는 이러한 연산을 효율적으로 수행하는 방식을 소개한다. 이 방식은 반복적 연산 없이 모델의 추론을 가능하게 한다. 아래 그림은 Pinterest의 Pin-to-Board 이분 그래프의 데이터 흐름을 잘 나타내고 있다.
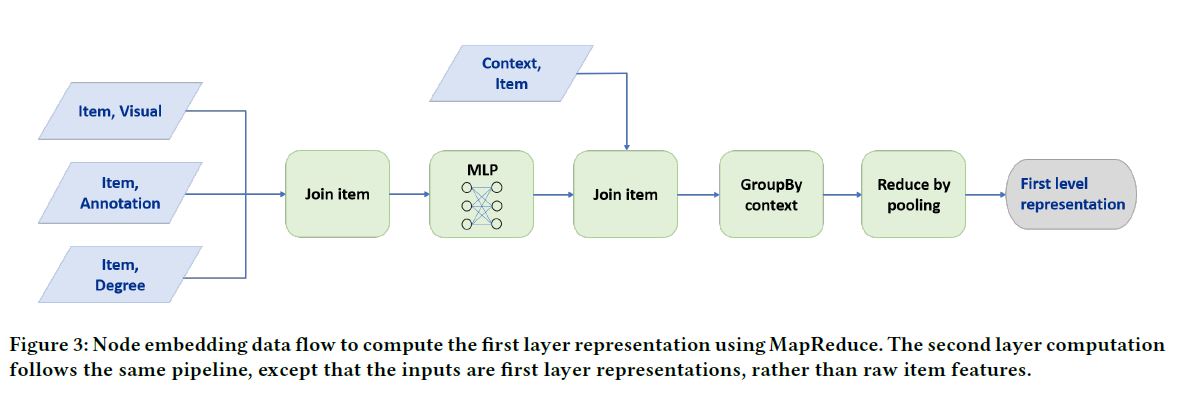
본 논문에서 소개하는 MapReduce 파이프라인은 다음과 같이 2개의 주요 요소를 갖는다.
(1) 하나의 MapReduce는 모든 pin을 Aggregation 연산이 수행되는 저차원 잠재 공간에 투사한다.
(2) 다른 MapReduce는 결과 Representation과 그 Representation이 발생한 Board의 ID를 결합하고, Board Embedding은 Sampling된 이웃의 Feature를 Pooling함으로써 계산된다.
이러한 방식을 도입하면 각 Node의 잠재 벡터는 단 한 번만에 계산되게 된다.
3.5. Efficient Nearest-neighbor Lookups
PinSAGE의 결과물로 형성된 Embedding은 많은 곳에 적용될 수 있지만 가장 직접적인 활용은 바로 이러한 Embedding의 근접 이웃 벡터를 찾아 추천에 활용하는 방법이 될 것이다.
Locality Sensitive Hashing을 통해 근사적인 KNN이 효율적으로 수행될 수 있다. Hash 함수가 계산되고 난 후 Item을 얻는 것은 Weak AND 연산자에 기반한 2단계 retrieval 과정에 의해 실현될 것이다.
4. Experiments
(후략)
References
1) 논문 원본