
BST(Behavior Sequence Transformer for E-commerce Recommendation in Alibaba) 설명
04 Dec 2021 | Machine_Learning Recommendation System Paper_Review목차
이번 글에서는 Alibaba에서 발표한 추천시스템 알고리즘인 BST에 대해 다뤄보도록 하겠습니다. 논문 원본은 이 곳에서 확인할 수 있습니다. 본 글에서는 핵심적인 부분에 대해서만 살펴보겠습니다.
Behavior Sequence Transformer for E-commerce Recommendation in Alibaba 설명
1. Background
Alibaba는 Taobao라고 하는 거대한 쇼핑몰을 갖고 있는데, 본 논문은 이 Taobao에서 발생한 로그의 일부를 효과적으로 활용하여 고객들에게 더 나은 구매경험을 제공하기 위한 방법에 대해 설명하고 있습니다.
예를 들어 어떤 고객이 순서를 갖고 여러 아이템을 클릭했다고 하면 분명 노이즈는 존재하긴 하겠습니다만 이러한 고객의 행동 시퀀스에는 구매행동에 관한 시그널이 존재할 가능성이 높습니다.
Wide & Deep이나 Deep Interest Network에서도 이러한 문제를 풀기 위해 방법을 제시하였지만 여러 한계점이 존재합니다.
본 논문에서는 BST라고 하는 알고리즘을 제시하고 있고, 이 방법론은 기존의 한계를 극복하기 위해 고객의 행동 시퀀스 속에 있는 시그널을 효과적으로 포착/통합하기 위해 설계되었습니다.
2. Architecture
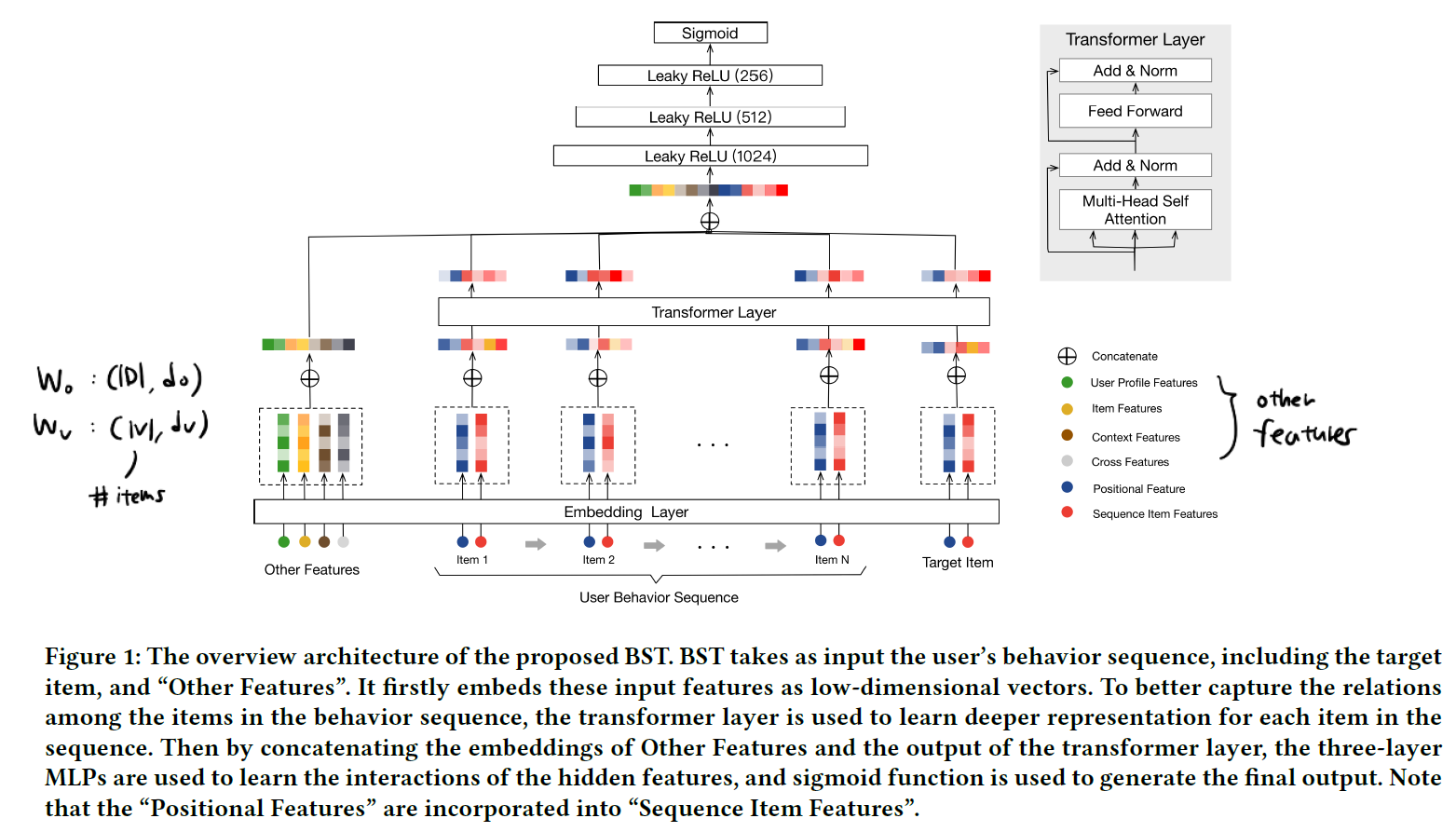
Bert4Rec이나 Transformers4Rec에 비해 복잡한 편은 아니지만, 구조를 잘 들여다보면 생각해볼 부분이 꽤 있습니다. 고객의 행동 시퀀스를 $S(u) = { v_1, v_2, …, v_n }$ 이라고 표기해보겠습니다. 이 때 고객 $u$ 는 총 $n$ 개의 아이템에 대해 클릭을 행했다고 가정하는 것입니다.
고객의 특성, 고객이 만든 feedback(click) sequence, 타겟 아이템의 특성 등을 모델링에서 활용할 수 있을 것입니다. 이러한 특성을 활용하는 데에는 여러가지 방법을 취할 수 있습니다. 이제 상세히 설명하겠지만 BST에서는 각 아이템 사이에서 일어나는 상호작용을 Transformer Layer를 통해 포착하고, 이 결과물을 user feature과 함께 연결하여 최종적으로 downstream task를 푸는 방식으로 추천/예측 알고리즘을 전개해나가고 있습니다.
2.1. Embedding Layer
Embedding Layer는 2개로 구분되어 있습니다.
1번째: other features의 embedding layer
2번째: sequence item features의 embedding layer
이 때 sequence item featuers는 고객이 반응한 아이템의 시퀀스를 의미하고, 논문에서는 오직 아이템의 ID와 카테고리만을 사용하고 있습니다. 만약 본인이 해결해야 할 문제에서 아이템의 정보가 부족하고 오직 ID 정도만을 사용할 수 있더라도 이와 같이 접근할 수 있다고 생각하면 될 것 같습니다.
other features로는 user profile features, target item features, context features 등이 있고 쉽게 말해서 위 sequence item features를 제외한 모든 것이라고 보면 됩니다.
| 항목 | 표기 | Shape |
|---|---|---|
| sequence item feature embedding matrix | $\mathbf{W}_v$ | $(\vert V \vert, d_v)$ |
| other feature embedding matrix | $\mathbf{W}_o$ | $(\vert D \vert, d_o)$ |
이 때 $\vert V \vert$ 는 아이템의 수를, $d_o, d_v$는 각각 세팅한 임베딩 dimension을 의미합니다.
$\vert D \vert$ 는 other features의 feature 수 입니다. 그런데 논문에 나온 것처럼 임베딩을 하기 위해서는 사실 모든 other features는 categorical variable이어야 합니다. 따라서 원-핫 인코딩 및 구간화를 통해 모든 변수를 categorical하게 변환하는 과정을 거치거나 아니면 이 대신 간단하게 projection layer를 사용할 수도 있을 것입니다. task의 성격이나 성능 등을 고려하여 설계를 해야될 것으로 보입니다.
sequence item features는 positional embedding 과정을 거치게 됩니다. BST에서는 vanilla transformer에 등장하였던 sin, cos 함수가 아닌 아래와 같은 식으로 시간 순서를 반영합니다.
논문에서는 위와 같이 추천 시간에서 해당 아이템이 클릭된 시간을 뺀 것으로 정의되는데, 이는 Alibaba의 연구 상에서는 이 방법이 더 뛰어났기 때문이라고 합니다. 이 부분은 본인의 task에 맞게 선택적으로 수용하면 될 것 같습니다.
2.2. Transformer Layer
Transformer Layer는 고객의 행동 시퀀스를 통해 여러 아이템 사이의 관계를 포착하는 역할을 수행합니다.
1번째: self-attention layer
2번째: point-wise feed-forward network
먼저 self-attention layer는 Attention is all you need를 비롯하여 수 많은 논문에서 등장하는 그 형태 그대로입니다.
\[Attention(\mathbf{Q, K, V}) = softmax(\frac{\mathbf{QK}^T}{\sqrt{d}}\mathbf{V})\]이 연산은 아이템 임베딩을 input으로 취하고 이를 linear projection을 통해 3개의 행렬로 변환한 뒤 attention layer로 투입하는 역할을 수행합니다.
\[\mathbf{S} = MH(\mathbf{E}) = concat(head_1, head_2, ..., head_h) \mathbf{W}^H\] \[head_i = Attention(\mathbf{EW}^Q, \mathbf{EW}^K, \mathbf{EW}^V)\]이 때 $\mathbf{W}$ 들은 모두 $(d, d)$ 의 shape을 취하고 있습니다.
point-wise feed-forward network는 이후에 비선형성을 강화하는 역할을 수행합니다.
\[\grave{\mathbf{S}} = LayerNorm(\mathbf{S} + Dropout(MH(\mathbf{S})))\] \[\mathbf{F} = LayerNorm(\grave{\mathbf{S}} + Dropout(LeakyReLU(\grave{\mathbf{S}} \mathbf{W^{1} + b^{1}})\mathbf{W}^{2} + b^2 ))\]여기까지가 이후에 나올 MLP layer 이전의 형태입니다.
2.3. MLP layers and Loss Function
이후 과정은 간단합니다. other features의 결과물과 transformer layer의 결과물을 모두 concat한 뒤 몇 개의 fully connected layer를 거치면 최종 output을 반환하게 됩니다. 손실 함수로는 cross-entropy를 사용하였다고 밝히고 있습니다.
여기까지가 BST의 구조인데, 본인의 task에 맞게 세부 구성을 수정할 수 있습니다. 예를 들어 MLP layer의 input을 결정할 때 논문에서처럼 모두 concat하는 방식을 취할 수도 있지만, SRGNN에서처럼 soft attention을 이용하여 session embedding vector를 만들 수도 있을 것입니다.
결국은 아이템 간의 상호작용을 어떻게 포착할 것인가, 그리고 그 과정이 끝난 아이템 벡터들을 어떻게 통합할 것인가는 연구자/분석가가 편의에 맞게 설정할 수 있는 것입니다.
3. Experiments and Conclusions
논문에서의 실험은 Taobao 앱 데이터를 통해 이루어 졌습니다. 7일치를 학습데이터로 사용하고 마지막 1일을 테스트 데이터로 사용하였다고 합니다. AUC, CTR, Response Time 등을 측정하였고 Adagrad를 통해 gradient descent를 수행하였습니다.
BST가 비교 대상인 WDL, DIN을 outperform하였는데, 이는 Transformer Layer를 통해 고객의 행동 시퀀스에 내재되어 있는 sequential signal을 더욱 잘 포착했기 때문이라고 논문은 서술하고 있습니다.
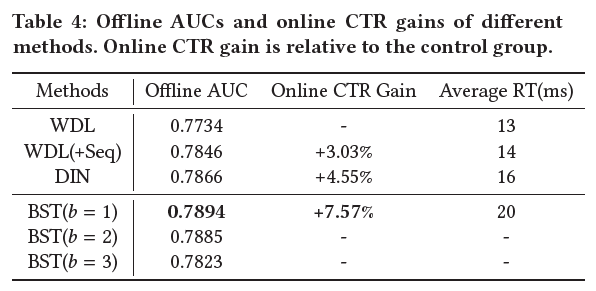

BST의 경우 transformer를 이용한 다른 알고리즘과 마찬가지로 시퀀스에 유의미한 정보가 포함되어 있을 경우 그 효과를 발휘할 수 있을 것으로 기대됩니다. 또한 user feature와 같은 보조적인 정보도 충분히 활용할 수 있다는 장점을 갖습니다.