
Bert4Rec(Sequential Recommendation with BERT) 설명
12 Dec 2021 | Machine_Learning Recommendation System Paper_Review목차
이번 글에서는 BERT 구조를 차용하여 추천 알고리즘을 구성해본 Bert4Rec이란 논문에 대해 다뤄보겠습니다. 논문 원본은 이 곳에서 확인할 수 있습니다. 본 글에서는 핵심적인 부분에 대해서만 살펴보겠습니다.
Bert4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer 설명
1. Background
RNN을 필두로 한 left-to-right unidirectional model은 user behavior sequence를 파악하기에 충분하지 않습니다. 왜냐하면 user의 historical interaction에서 일어난 item 선택 과정에 대해 살펴보면, 여러 이유로 인해 꼭 그 순서 자체가 중요하다고 말할 수 없는 경우가 자주 발생하기 때문입니다. 예를 들어 어떤 user가 토너와 화장솜을 사고 싶다고 할 때 토너를 먼저 구매할 수도 있고, 화장솜을 먼저 구매할 수도 있습니다. 사실 어떤 것이 먼저 오냐는 관점에 따라 크게 중요하지 않은 사실이 될 가능성이 높습니다.
따라서 논문에서는 sequence representations learning을 위해 두 방향 모두에서 context를 통합해야 한다고 이야기합니다. 우리는 이미 BERT 논문을 통해 이러한 방법이 특히 언어 모델에서 매우 잘 작동한다는 사실을 알고 있습니다.
논문 2장에 나온 Related Work에 관해서는 직접 확인하길 바랍니다. 이전에 다룬 내용들이 많아 본 글에서는 생략합니다.
2. Architecture
$u, v$ 를 각각 user, item이라고 할 때 $S_u = [v_1^u, …, v_t^u, …, v_{n_u}^u]$ 는 user $u \in \mathcal{U}$ 가 상호작용한 item 목록, 즉 interaction sequence입니다. 이 때 $v_t^u \in \mathcal{V}$ 는 user $u$ 가 $t$ step에서 상호작용한 item이고 $n_u$ 는 user $u$ 의 interaction sequence의 총 길이입니다.
따라서 user $u$ 가 $n_u+1$ time에서 특정 item $v$ 를 선택할 확률은 아래와 같이 표현할 수 있습니다.
\[p(v_{n_u+1}^u = v|S_u)\]아래 그림은 Bert4Rec의 전체 구조와 비교 대상인 RNN의 구조를 도식으로 나타내고 있습니다.
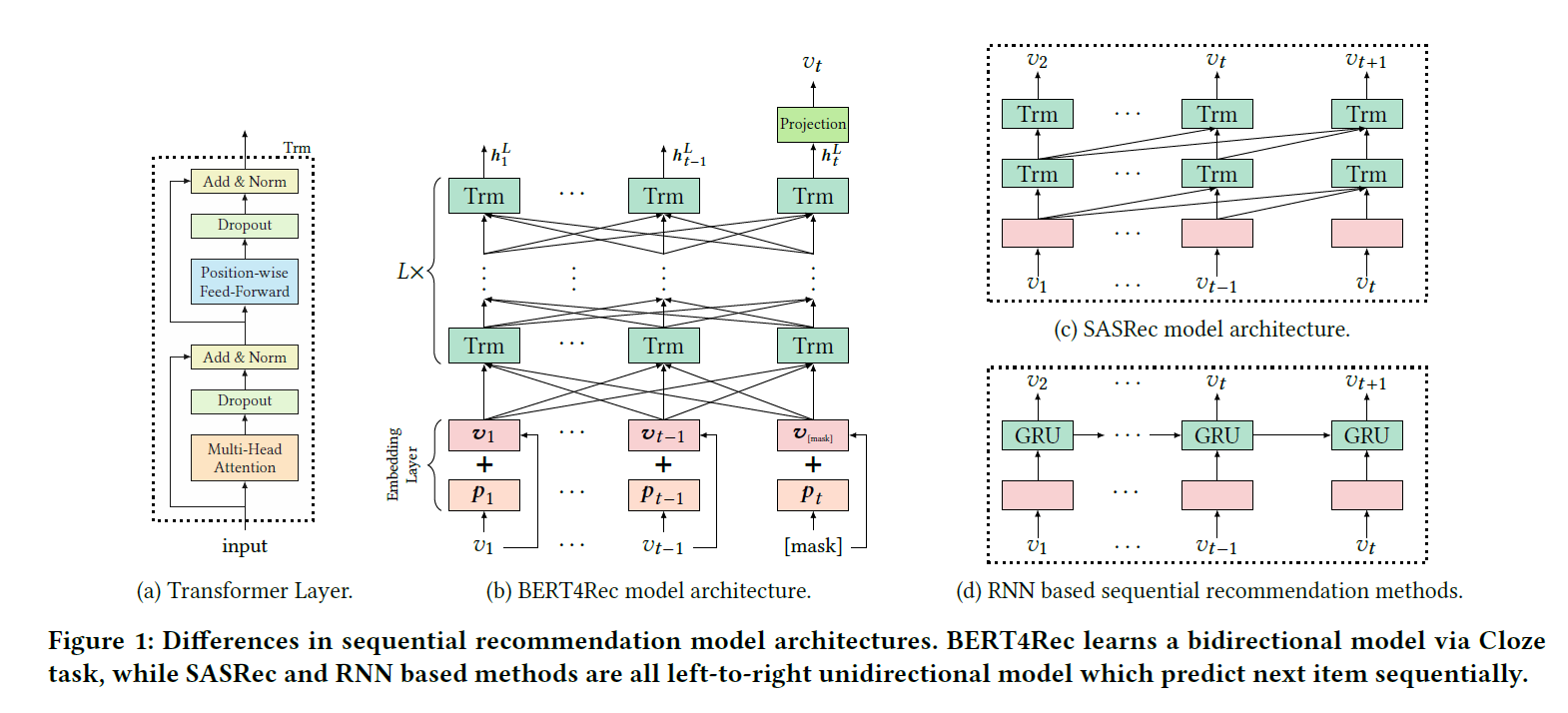
Bert4Rec의 핵심은 stacked된 $L$ 개의 bidirectional Transformer layer입니다. 병렬적으로 이전 layer에 존재하는 모든 position에 있는 정보들을 상호 교환하여 모든 position의 representation을 수정함으로써 학습을 진행합니다. self-attention 메커니즘을 통해 위치/거리 제약 없이 직접적으로 dependency를 포착할 수 있습니다. 이러한 메커니즘은 일종의 global receptive field로 귀결됩니다.
Transformer layer에 대해서는 몇 가지 포인트만 짚고 넘어가겠습니다. 자세한 내용은 원 논문을 참조하시길 바랍니다.
Transformer layer는 multi-head self-attention과 position-wise feed-forward network로 구성됩니다. 후자는 attention sub-layer의 결과물에 대해 적용되는데 이를 통해 여러 dimension 사이에 존재하는 상호작용을 포착하고 비선형성을 강화해줍니다. 본 논문에서는 feed-forward network의 활성화함수로 GELU를 사용하였으니 참고하시길 바랍니다.
이렇게 여러 Transformer layer를 쌓으면 분명 네트워크가 상당히 깊어지기 때문에 residual connection은 필수적으로 들어가게 됩니다. 이 과정을 요약하면 아래와 같습니다.
\[\forall l \in [1, ..., L]\] \[H^l = Trm(H^{l-1}) = LN(A^{l-1} + Dropout(PFFN(A^{l-1})))\] \[A^{l-1} = LN(H^{l-1} + Dropout(MH(H^{l-1})))\]Embedding layer에서는 2가지를 기억하면 됩니다. 일단 positional embedding을 할 때 기존의 transformer와 달리 학습 가능한 방법을 사용했다는 것입니다.
\[h_i^0 = v_i + p_i, p_i \in P, P \in \mathbb{R}^{N, d}\]그리고 만약 길이가 $N$ 을 넘는 sequence가 있다면 마지막 $N$ 개에 대해서만 학습/추론을 진행하였습니다.
논문에 명시된 것은 아니지만, 1가지 덧붙이자면 논문 원본의 경우 이렇게 $N$ 개의 item을 산정하고 학습을 진행하기 때문에 inductive inference는 불가능한 상황입니다. 따라서 새롭게 item이 자주 들어오고 나오는 상황에서는 다른 학습 환경이 필요할 것으로 판단됩니다.
$L$ 개의 layer를 통과하고 나면 드디어 최종 결과물을 얻을 수 있게 됩니다.
\[P(v) = softmax(GELU(h_t^L W^P + b^P)E^T + b^O)\]3. Model Learning
학습은 Masked Language Model라고도 알려진 Cloze task를 sequential recommendation에 적용함으로써 진행됩니다. 각 학습 단계에서 input sequence의 모든 item 중 $p$ %를 무작위로 masking하고 주변 context를 통해 masked item의 original ID를 추론하는 것입니다.
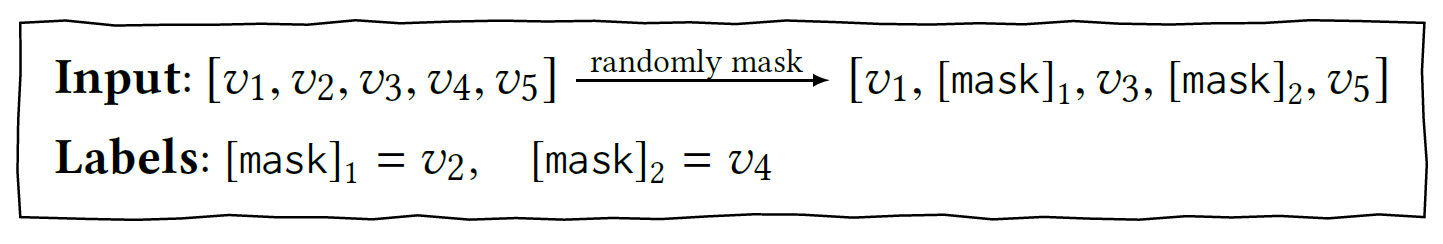
이제 각 masked된 input $\grave{S_u}$ 를 masked target의 negative log-likelihood로 정의할 수 있습니다.
\[\mathcal{L} = \frac{1}{\vert S_u^m \vert} \Sigma_{v_m \in S_u^m} -log P(v_m = v_m^* \vert \grave{S_u})\]이 때 $\grave{S_u}$ 는 user behavior history의 masked version이고, $v_m^*$ 는 masked item $v_m$ 의 true item입니다.
이러한 방식으로 학습 데이터를 구성하게 되면 사실 Bert4Rec은 만약 무작위로 $k$ 개의 item을 masking한다고 했을 때 $\binom{n}{k}$ 개의 sample을 얻을 수 있으므로 더욱 방대하고 다양한 데이터셋을 얻을 수 있을 것입니다.
학습과 달리 테스트 시에는 mask라고 하는 special token을 user behavior sequence의 맨 끝에 놓고 이 token의 final hidden representation에 기반하여 next item을 예측하도록 설정하였습니다.
4. Experiments and Conclusion
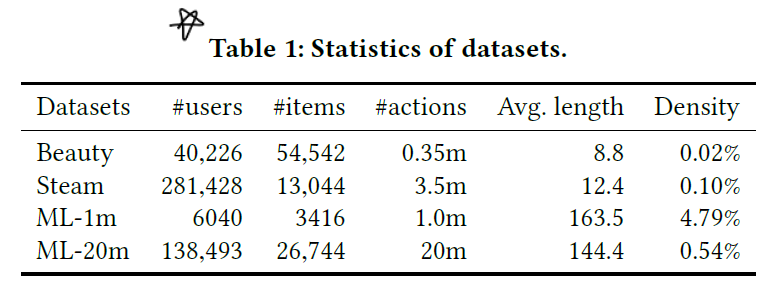
학습 데이터는 아래와 같습니다.
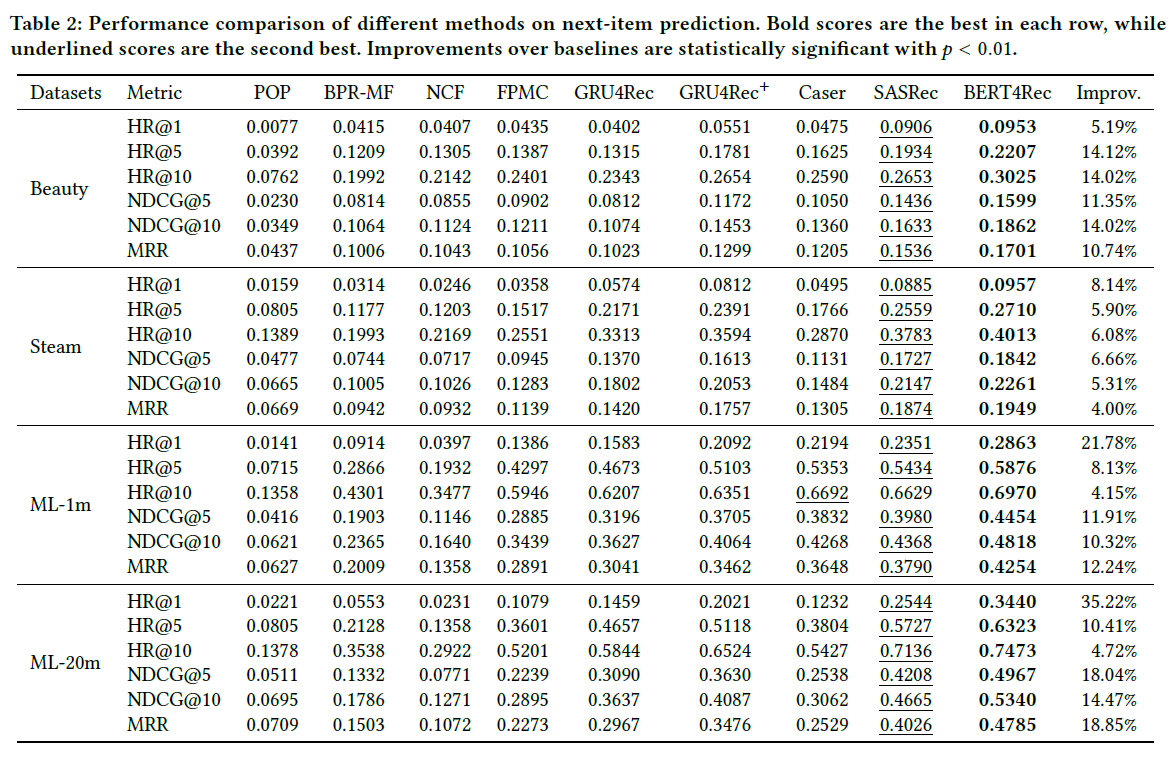
비교 대상 알고리즘, 평가 환경 세팅 등 자세한 내용은 논문 본문을 참조하시길 바랍니다.
논문 후반부에는 attention head에 대한 시각화 자료가 존재하며 hidden vector 차원 및 sequence 길이에 따른 성능 변화에 대한 연구도 포함되어 있어 인사이트를 얻기 좋습니다.
Bert4Rec은 NLP에서 괄목할 만한 성과를 거둔 BERT 구조를 추천 시스템에 적용한 알고리즘입니다. 전체적으로 알고리즘의 component에 대한 설명과 실험 결과에 대해 기술한 부분이 매우 합리적이고 실제 현업에서 적용하기에도 좋은 아이템이라고 판단됩니다. 다만 역시 sequence 형태의 데이터에 기반하였다보니 item 간의 상호작용이 꽤 분명한 task에서 잘 작동할 것으로 예상됩니다.