
OpenAI GPT-2 - Language Models are Unsupervised Multitask Learners(GPT2 논문 설명)
28 Aug 2019 | Paper_Review NLP목차
- OpenAI GPT-2 - Language Models are Unsupervised Multitask Learners
이 글에서는 2019년 2월 Alec Radford 등이 발표한 OpenAI GPT-2: Language Models are Unsupervised Multitask Learners를 살펴보도록 한다.
코드와 논문은 여기에서 볼 수 있지만, 전체버전은 성능이 너무 강력하다는 이유로 공개되지 않았다.
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
OpenAI GPT-2 - Language Models are Unsupervised Multitask Learners
논문 링크: OpenAI GPT-2 - Language Models are Unsupervised Multitask Learners
홈페이지: OpenAI
Tensorflow code: Official Code
초록(Abstract)
질답(QA), 기계번역, 독해, 요약과 같은 자연어처리 과제들은 대개 과제에 특화된 dataset과 지도학습을 통해 이루어졌다. 이 논문에서, 언어모델은 WebText라는 수백만 개의 웹페이지를 모은 새로운 dataset에서 학습될 때 어떤 명시적인 지도 없이 이러한 과제들을 학습하기 시작했음을 보인다. 문서와 질문이 있을 때 대답을 생성하는 언어모델은 CoQA dataset에서 55 F1 score를 달성하였고 이는 127k 이상의 학습데이터 사용 없이 4개 중 3개의 기준시스템을 능가한 것이다.
이 언어모델의 capacity는 zero-shot task transfer의 성공에 필수적이다. 이 논문에서 제시되는 가장 큰 모델 GPT-2는 15억 개의 Transformer parameter를 가지며 zero-shot 환경에서 8개 중 7개에서 state-of-the-art를 달성하였는데 이 큰 모델도 WebText에서 과소적합(underfitting) 현상을 보인다. 모델에서 나온 예는 이러한 개선점을 반영하며 일관성 있는 텍스트 단락을 포함한다. 이러한 발견은 자연적 설명으로부터 과제수행능력을 배우는 언어처리모델을 개발하는 촉망되는 방법을 시사한다.
1. 서론(Introduction)
기계학습 시스템은 큰 dataset과 고용량의 모델, 지도학습 등을 통해 빠르게 발전해왔다. 이러한 방법으로 개발된 모델들은 불안정하며 매우 좁은 범위의 문제에서만 뛰어난 능력을 발휘한다. 그래서 데이터를 수동 분류하는 과정 없이도 더 범용적인 모델을 개발할 필요가 있다.
현재 기계학습체계를 개발하는 주된 방법은 목표 과제에 맞는 dataset을 찾아서, 이를 학습/검증 단계로 나누어 학습 후 IID(independet and identically distributed)로 성능을 측정하는 방법이다. 이는 좁은 범위의 과제에서는 매우 효과적이나 범용적인 이해를 필요로 하는 독해나 다양한 이미지 분류시스템 등의 문제에서는 높은 성능을 내지 못했다.
많은 연구가 단일 영역의 dataset과 단일 과제에만 맞춘 학습에만 치중되었었다. 최근에야 넓은 범위의 dataset과 여러 과제에 대한 GLUE benchmark 등이 제안되기 시작했다.
다중작업 학습(Multitask learning)은 일반성능을 높이는 유망한 방법이지만 아직 초기 연구 단계이다. 최근에는 Learning and Evaluating General Linguistic Intelligence 등의 연구가 성능 향상을 이뤄냈지만, 최근의 기계학습 시스템은 일반화를 위해서는 수십만 개 정도의 학습 샘플을 필요로 하는데 이는 다중작업 학습을 위해서는 그 몇 배가 필요하다는 것을 뜻한다.
가장 성능이 높은 언어처리모델은 사전학습(pre-training)과 지도 세부학습(supervised fine-tuning)의 결합으로 만들어졌다. 이 접근법은 transfer과 더불어 긴 역사를 가졌다.
- 단어벡터를 학습시킨 후 과제특화된(task-specific) 모델구조에 입력으로 넣고
- 순환형 네트워크의 문맥표현이 전이되고
- 최근에는 과제특화된 모델구조는 더 이상 중요하지 않으며 많은 self-attention block만으로 충분하다고 한다.
이러한 방법들은 여전히 지도학습을 필요로 한다. 만약 지도 데이터가 최소한으로 또는 전혀 필요하지 않다면, 일반상식 추론이나 감정분석과 같은 특정 과제들을 수행하는 데 큰 발전이 있을 것이다.
이 논문에서는, 위의 두 방향의 연구를 결합하여 전이학습의 더 일반적인 방법의 흐름을 잏는다. 언어모델이 어떤 parameter나 모델구조의 변화 없이도 zero-shot setting 하에서 downstream task를 수행할 수 있음을 보인다. 이 접근법은 언어모델이 zero-shot setting 하에서 넓은 범위의 과제를 수행할 수 있는 가능성을 보이며, 전도유망하고 경쟁력 있으며 과제에 따라서는 state-of-the-art를 달성하였다.
2. 접근법(Approach)
핵심은 언어모델링(language modeling)이다. 언어모델링은 보통 각 원소가 일련의 symbol $(s_1, s_2, …, s_n)$으로 구성된 예제 $(x_1, x_2, …, x_n)$에서 비지도분포 추정을 하는 것으로 정의된다. 언어는 자연적으로 연속된 순서를 가지므로 보통 조건부확률의 곱으로 이루어진 symbol에 따른 합동확률로 구해진다:
\[p(x) = \prod_{i=1}^n p(s_n \vert s_1, ..., s_{n-1})\]이 접근법은 어떤 조건부확률 $p(s_{n-k}, …, s_n \vert s_1, …, s_{n-k-1})$만큼이나 $p(x)$의 다루기 쉬운 샘플링을 가능하게 하였다. 최근에는 이러한 조건부확률을 매우 잘 계산하는 Transformer 등이 만들어졌다.
단일 과제 수행의 학습은 조건부분포 $p(output \vert input)$를 추정하는 확률 framework로 표현될 수 있다. 범용시스템은 여러 다른 과제들을 수행할 수 있어야 하기 때문에 같은 입력이라도 입력뿐 아니라 과제의 종류라는 조건이 들어가야 한다. 따라서 $p(output \vert input, task)$로 표현되어야 한다. 이는 다중학습과 메타학습 환경에서 다양하게 형식을 갖는다.
과제 조건을 다는 것은 모델구조 수준이나 MAML 최적화 framework에서 알고리즘 수준에서 구현되기도 한다. 그러나 McCann에서 나온 것과 같이, 언어는 과제/입력/출력 모두를 일련의 symbol로 명시하는 유연한 방법을 제공한다.
- 예를 들어 번역학습은 (프랑스어로 번역, 영어 텍스트, 프랑스어 텍스트)로 표현된다(translate to french, english text, french text).
- 독해는 (질문에 대답, 문서, 질문, 대답)이다(answer the question, document, question, answer).
McCann은 MQAN이라는 단일 모델로 학습하는 것이 가능했다고 설명하며 이 형식으로 많은 과제를 수행하였다고 한다.
언어모델링은 또한 어떤 symbol이 예측할 출력인지에 대한 명시적인 지도 없이도 McCann의 과제들을 학습할 수 있다. Sequence의 부분집합에 대해서만 평가하더라도 지도목적함수는 비지도목적함수와 같기 때문에, 전역최소값(global minimum)은 비지도학습에서와 지도학습에서 같은 값을 가진다. 즉 비지도목적함수에서 수렴하게 할 수 있다. 예비실험에서, 충분히 큰 언어모델은 이런 toy-ish 환경에서 다중작업 학습이 가능했으나 학습은 명시적 지도학습에서보다 훨씬 느렸다.
대화(dialog) 데이터는 꽤 괜찮은 학습 방법이지만, 상호작용이 필요없는 인터넷 사이트에 존재하는 방대한 양의 데이터가 더 낫다는 판단을 내렸다. 충분한 용량을 가지는 언어모델이라면 데이터 조달 방법과는 관련없이 더 나은 예측을 위한 수행을 시작할 것이라는 추측이 있다. 만약 지금 가능하다면, 아마 현실적으로 비지도 다중작업 학습이 될 것이다.

2.1. Training Dataset
많은 선행연구에서 사용된 dataset은 뉴스와 같이 한 영역에서만 가져온 데이터로 구성되어 있었다. 이 논문에서는 가능한 한 다양한 출처로부터 가져오려고 하였다.
이러한 점에서 촉망받는 것은 Common Crawl과 갈은 web scraping 자료인데, 이 중 많은 양이 이해할 수 없는(unintelligible, 또는 품질이 떨어지는) 데이터라 한다. 따라서 이 논문에서는 단순 크롤링이 아닌 고품질의 데이터를 얻는 다른 방법을 사용하기로 했다.
- 사람에 의해 필터링된 글만을 사용하기로 하였다:
- Reddit에서 3 karma 이상을 받은 글에 포함된 외부링크의 글을 가져왔다.
- 결과적으로 45M개의 링크를 가져왔다.
- Dataset 이름은 WebText라 하였다.
- 텍스트 추출을 위해 Dragnet과 Newspaper 내용추출기를 사용했다.
- 2017년 12월 이후의 글과 위키피디아 글은 제거했으며, 중복제거 등을 거쳐 8M개의 문서, 40GB의 텍스트를 확보하였다.
- 위키피디아는 다른 dataset에서 흔하고, 학습과 측정 단계에서의 데이터가 겹치는 문제로 인해 분석이 복잡해질 수 있어 제외했다.
2.2. Input Representation
범용언어모델은 어떤 문자열의 확률도 계산할 수 있어야 한다. 현재 대규모 언어모델은 소문자화, 토큰화, 모델링 가능한 문자열이 차지하는 공간을 제한하기 위한 사전외 token과 같은 전처리 과정을 거친다. Unicode 문자열을 UTF-8 형식으로 처리하는 것은 이를 우아하게 만족시키며 byte수준 언어모델은 One Billion Word Benchmark와 같은 대규모 dataset에서 단어수준 언어모델에 뒤떨어진다. WebText에서도 역시 그러한 성능차이를 확인하였다.
Byte Pair Encoding(BPE)는 글자(byte)와 단어의 적당한 중간 단위를 쓴다.
- 이는 자주 나오는 symbol sequence의 단어수준 입력과 자주 나오지 않는 symbol sequence의 글자수준 입력을 적절히 보간(interpolate)한다.
- 그 이름과는 달리 BPE 구현은 byte sequence가 아닌 Unicode code points에서 동작한다. 이러한 구현은 모든 Unicode 문자열을 모델링하기 위해 전체 Unicode symbol의 공간만큼을 필요로 한다.
- multi-symbol token을 추가하기 전 13만 개의 token을 포함하는 기본사전을 필요로 하게 된다. 이는 보통의 3만 2천~6만 4천 token의 사전보다 엄청나게 큰 것이다.
- 이와는 달리 byte수준의 BPE의 사전은 256개만의 token을 포함한다.
- 그러나 BPE를 byte sequence에 직접 적용하는 것은 BPE가 token 사전을 구춘하기 위한 heuristic에 기반한 greedy frequency를 사용하기 때문에 최적이 아니게 된다.
- BPE는 dog의 다양한 형태,
dog.나dog!나dog?등을 가진다.- 이는 한정적인 사전과 모델의 공간을 최적이 아니게 사용하게 된다.
- 이를 피하기 위해 BPE가 어떤 byte sequence로부터도 문자 범주를 넘어 병합하는 것을 막았다.
- 여러 vocab token의 최소부분만을 추가할 때 압축효율성을 크게 증가시키는 공간을 위한 예외를 두었다.
이러한 입력표현은 단어수준 언어모델의 경험적 이점과 문자수준 접근법의 일반성을 결합할 수 있게 한다. 이 논문의 접근법이 어떤 Unicode 문자열에든 확률을 부여할 수 있기 때문에, 이는 이 논문의 모델을 전처리, 토큰화, 사전크기 등과 관련없이 어떤 dataset에서도 평가할 수 있게 만든다.
2.3. Model
Transformer가 기본 구조이며, OpenAI Gpt-1의 구조를 대부분 따른다. 약간의 차이는 있는데,
- Layer 정규화가 pre-activation residual network처럼 각 sub-block의 입력으로 옮겨졌다.
- 추가 layer 정규화가 마지막 self-attention block 이후에 추가되었다.
- 모델 깊이에 따른 residual path의 누적에 관한 부분의 초기화 방법이 변경되었다.
- $N$이 residual layer의 수라 할 때, residual layer의 가중치에 $1 / \sqrt{N}$을 곱했다.
- 사전은 50,257개로 확장되었다.
- 문맥고려범위(context size)가 512~1024개의 token으로 늘어났으며 batch size도 512로 증가했다.
3. 실험(Experiments)
모델은 크기가 각각 다른 4개를 만들어 실험했다. 각 모델의 크기는 다음과 같다.
| Parameters | Layers | d_{model} |
|---|---|---|
| 117M | 12 | 768 |
| 345M | 24 | 1024 |
| 762M | 36 | 1280 |
| 1542M | 48 | 1600 |
가장 작은 모델은 크기가 OpenAI GPT-1와 같고, 두 번째는 BERT와 같다. 가장 큰 모델인 GPT-2는 10배 이상 크다.
각 모델의 learning rate는 WebText의 5%를 떼서 만든 held-out 샘플을 사용하여 수동 조정하였다. 모든 모델은 여전히 WebText에 과소적합(underfitted)되었으며 더 오래 학습시키면 더 높은 성능을 얻을 수 있을 것이다.
3.1. Language Modeling
GPT-2는 문자단위(byte level)로 되어 있어 손실이 있는 전처리나 토큰화 등이 필요하지 않으며, 어떤 언더 모델 benchmark에도 사용할 수 있다. 평가는 WebText 언어모델에 따른 dataset의 로그확률을 계산하는 방식으로 통일했다. WebText 언어모델은 일반 분포를 심하게 벗어난 것, 이를테면 대단히 규격화된 텍스트, 분리된 구두점이나 축약형, 섞인 문장에 대해 평가받으며, <UNK>는 WebText에 400억 byte 중 26번밖에 나타나지 않는다.
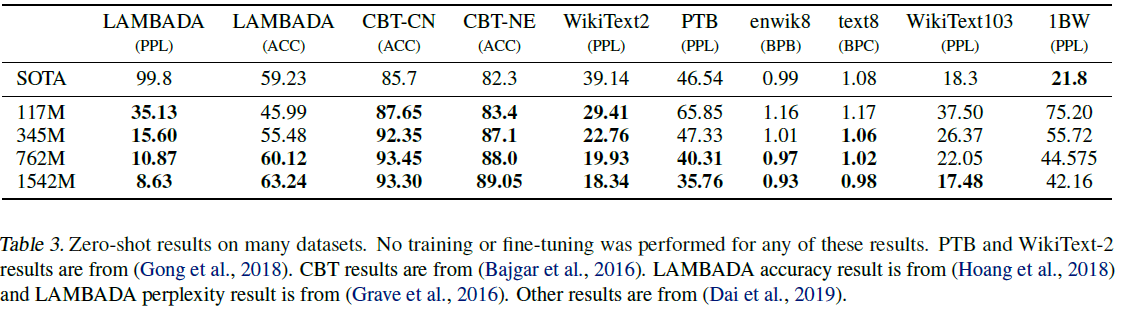
결과는 아래 표에 나와 있으며, 어떤 미세조정도 거치지 않고 zero-shot 환경에서 8개 중 7개에서 state-of-the-art를 달성하였다.
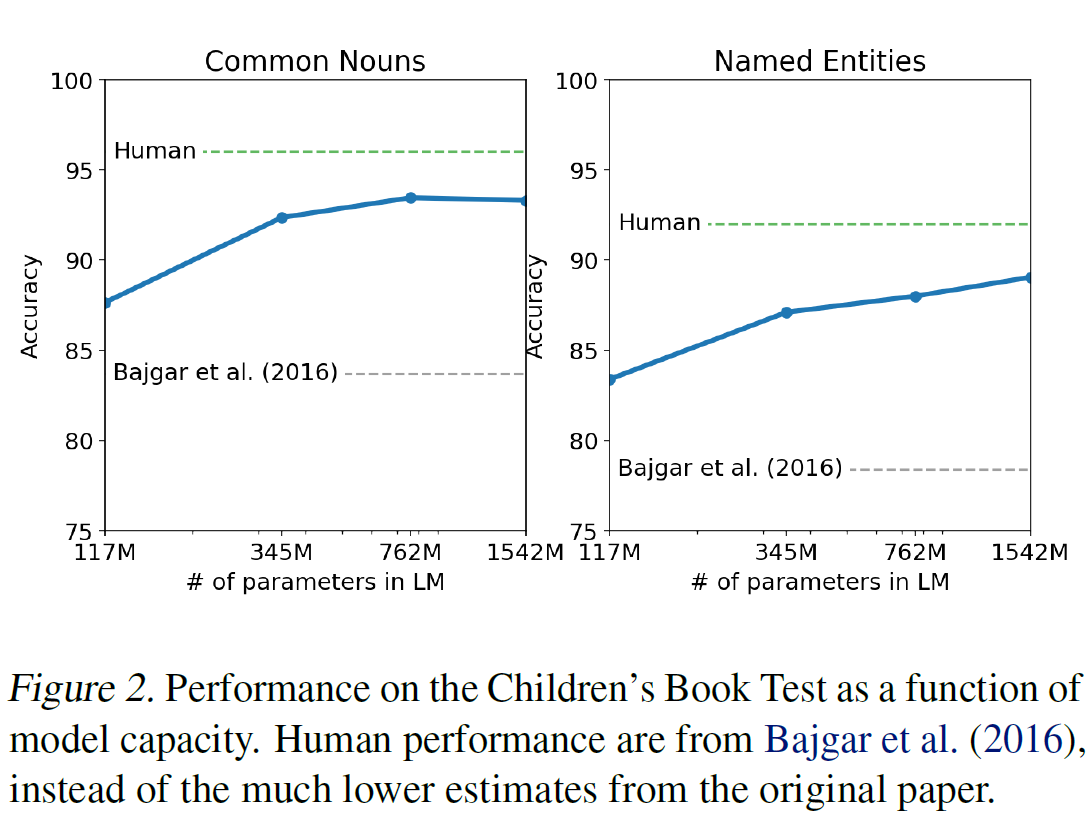
3.2. Children’s Boot Test
품사(고유명사, 명사, 동사, 전치사)에 따른 언어 모델의 성능을 측정하기 위한 dataset이다. 원 논문에 소개된 내용을 따라 각 선택의 확률과 언어모델의 선택에 따른 문장의 나머지 부분에 대한 확률을 계산하고 가장 높은 확률의 선택지를 선택하게 했다. 결과는 89.1% $\to$ 93.3%가 되었다.
3.3. LAMBADA
텍스트의 장거리 의존성(long-range dependencies)을 평가한다. 간단히 말하면 정확도는 19% $\to$ 52.66%, perplexity는 99.8 $\to$ 8.6으로 향상시켰다.
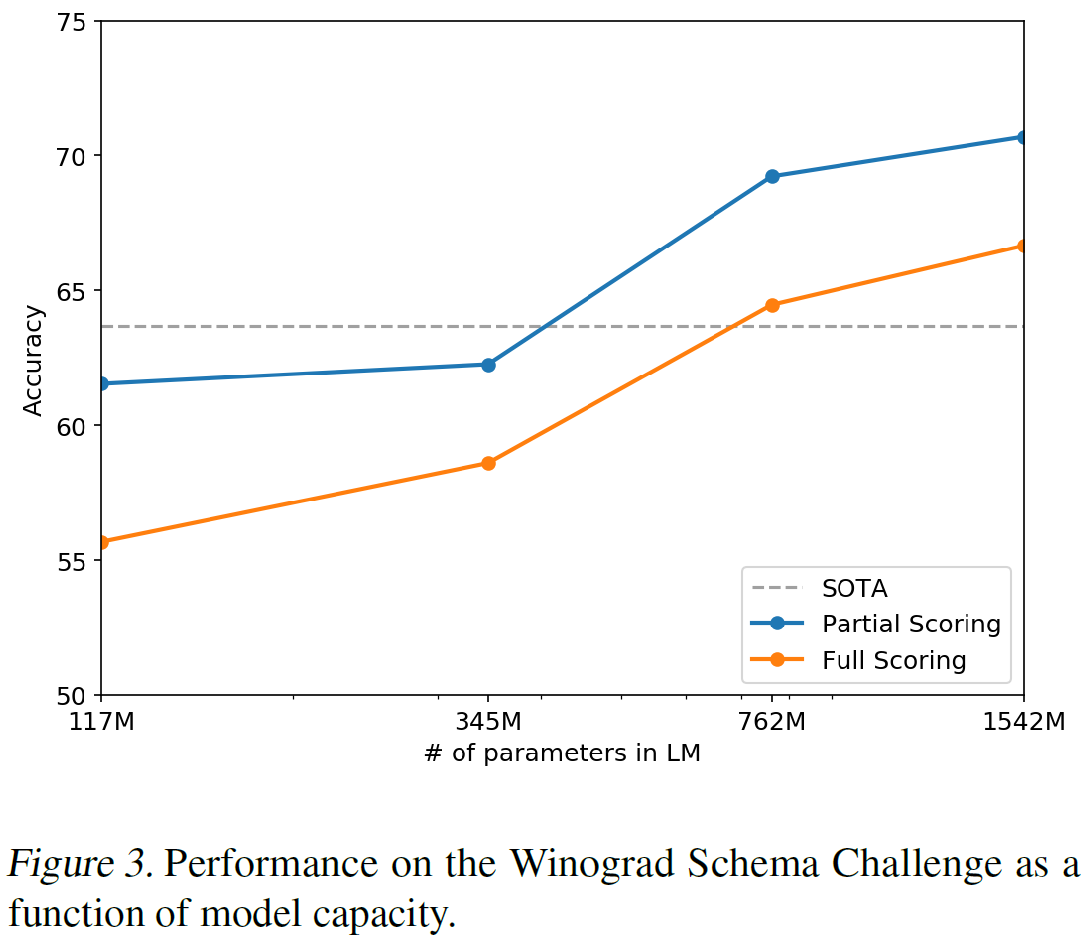
3.4. Winograd Schema Challenge
텍스트에 존재하는 중의성(또는 모호한 부분, ambiguities)을 해석하는 능력을 측정함으로써 일반상식 추론능력을 평가한다. GPT-2는 정확도를 7% 증가시켜 70.70%를 달성했다.
3.5. Reading Comprehension
CoQA(The Conversation Question Answering dataset)을 7개의 분야에서 가져온 문서에서 질문자-답변자의 자연어 대화로 이루어진 dataset이다. CoQA 테스트는 독해능력과 대화에 기반한 모델의 답변능력을 평가한다. GPT-2는 55 F1 score를 달성해 4개 중 3개의 다른 모델을 능가했는데 이는 심지어 주어진 127k 이상의 수동 수집된 질답 쌍으로 학습시키지 않은 것이다. 지도가 포함된 state-of-the-art인 BERT는 89 F1 score에 근접하였다. 그러나 어떤 미세조정 없이 55점을 달성했다는 것은 상당히 고무적인 일이다.
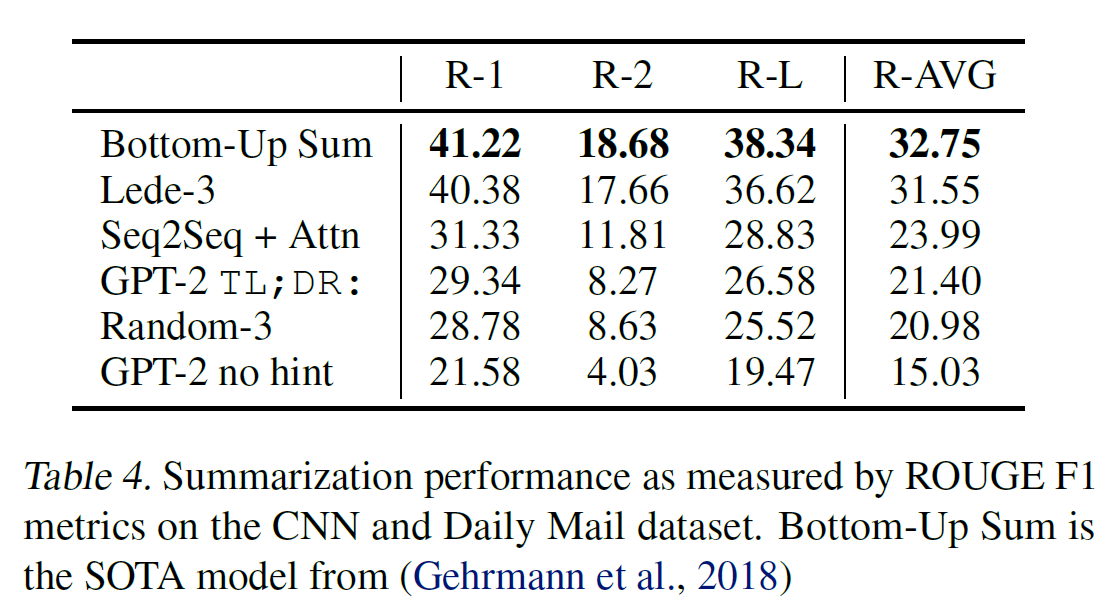
3.6. Summarization
CNN과 Daily Mail dataset으로 요약 능력을 평가했다. 총합 6.4점의 향상을 보였다.
3.7. Translation
번역에서는 예상외로 별로 좋은 결과를 내지 못했다고 한다.
3.8. Question Answering
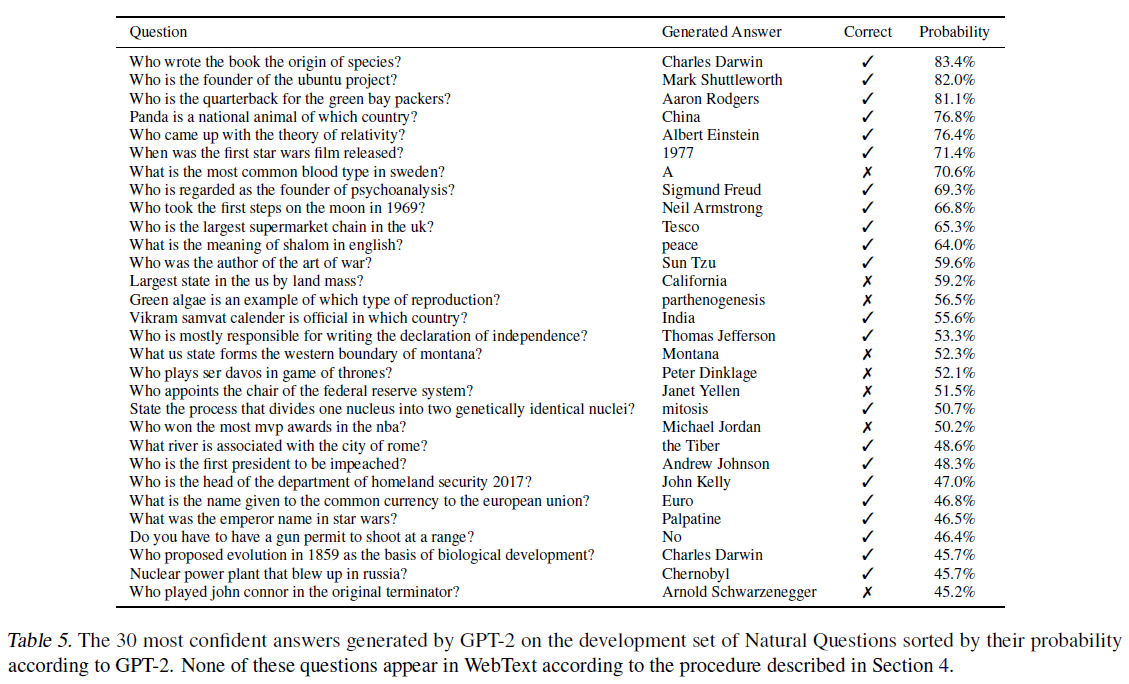
답변한 문장이 ‘완전히 일치하는’ 평가 방법을 썼을 때 GPT-2는 약 4.1%의 정확도를 보여 일반적으로 5.3배의 정확도를 보인다. 그러나 GPT-2가 생성한 30개의 가장 ‘자신있는’ 답변은 아래 그림에 나와 있는데 이는 정보검색과 문서추출 질답을 병행한 열린분야 질답 시스템에 비하면 50%까지 낮은 성능을 보인다.
4. 일반화 vs 암기(Generalization vs Memorization)
최근 연구에서 많이 사용되는 데이터셋 중에는 거의 동일한 이미지를 여럿 포함하는 것이 있는데, 예를 들면 CIFAR-10의 경우 3.3%의 이미지가 train / test 세트에서 겹친다. 이는 기계학습 시스템의 일반화 성능을 과대평가하게 만든다. 이는 성능 측정에 방해 요인이 되기 때문에 데이터셋이 이러한 요인이 없는지 확인하는 것은 중요하다.
그래서 WebText에 대해 8-gram 학습세트 토큰을 포함하는 Bloom 필터를 만들어 테스트해보았고, 결과는 다음과 같다.
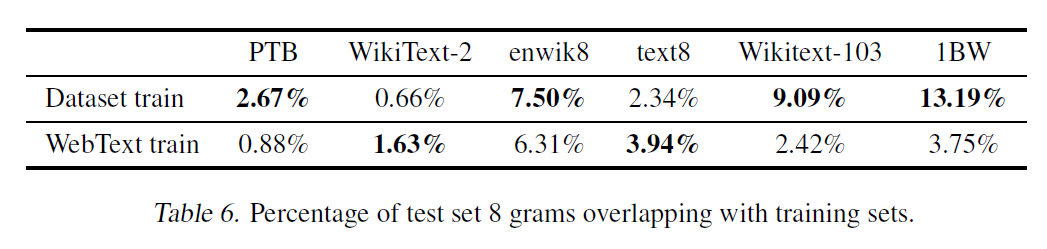
물론 WebText는 써도 괜찮다는 결론이 나왔다. 그런데 다른 데이터셋의 경우에는 생각보다 높은 겹침(overlap) 현상이 나타나는 것을 볼 수 있다.
비슷한 텍스트들이 성능에 어떤 영향을 미치는지 이해하고 정량화하는 것은 중요한 부분이다. 더 나은 데이터중복제거(de-duplication) 기술은 매우 중요하며, 중복제거에 기반한 n-gram overlap을 사용하는 것은 훌륭한 방법이며 이 논문에서는 이를 추천한다.
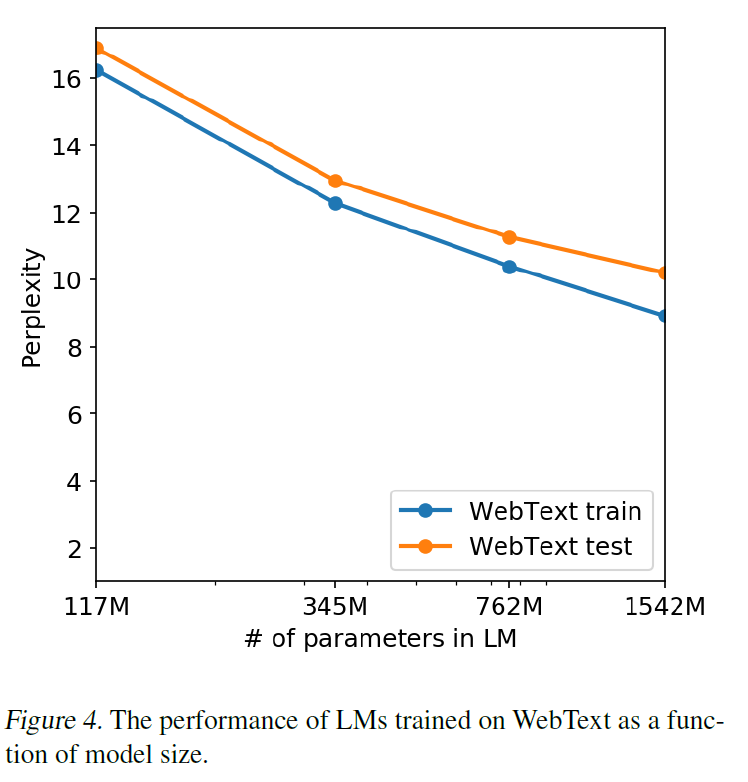
WebText LM의 성능을 결정하는 또 다른 잠재적 방법은 암기(기억, memorization)이 held-out set에 어떤 영향을 미치는지 살펴보는 것이다. train / test set에 대해 성능을 평가한 다음 그림은 그 거대한 GPT-2가 WebText에 대해 여전히 과소적합(underfitted)되었으며 암기에 의한 것이 아님을 보여준다.
5. 관련 연구(Related Work)
이 논문의 많은 부분은 더 큰 데이터셋으로 학습된 더 큰 언어모델의 성능을 측정하는 데 쓰였다. 다른 많은 연구들도 이와 비슷하다(scaled RNN based LM 등).
iWeb Corpus와 같은 거대한 웹페이지의 텍스트 말뭉치를 필터링하고 구축하는 대안을 제시하거나, 언어문제를 위한 사전학습 방법, 벡터표현, seq2seq 등이 연구되었으며 최근 연구들은 언어모델의 사전학습이 잡담이나 대화 같은 어려운 생성문제에 맞춰 미세조정할 때 도움이 된다는 것을 밝혀내었다.
6. 토의(Discussion)
많은 연구들은 지도/비지도 사전학습 표현에 대한 학습, 이해, 비판적 평가에 관해 연구를 진행해 왔다. 이 논문은 비지도 학습이 아직 연구할 거리가 더 남아 있음을 밝혔다.
GPT-2의 zero-shot 학습 성능은 독해 등에서 좋은 성능을 보였으나 요약과 같은 문제에서는 기본적인 성능만을 보여주었다. 꽤 괜찮긴 해도 실제 사용하기엔 여전히 무리이다.
GPT-2의 성능이 많은 과제에서 괜찮긴 한데, 미세조정을 통한 그 한계가 얼마인지는 분명하지 않다. 그렇지만 이 논문의 저자들은 decaNLP나 GLUE와 갈은 벤치마크에서 미세조정(fine-tuning)할 것을 계획하고 있다고 한다.
또 GPT-2의 학습데이터와 그 크기가 BERT에서 말한 단방향 표현의 비효율성을 극복할 수 있을 만큼 충분한지도 확실치 않다고 한다.
7. 결론(Conclusion)
큰 크기의 언어모델이 충분히 크고 다양한 데이터셋에서 학습된다면 많은 분야와 데이터셋에서 괜찮은 성능을 보여준다. GPT-2의 zero-shot은 8개 중 7개의 주요 언어 과제에서 state-of-the-art를 달성하였다.
모델이 zero-shot으로 다양한 과제에서 잘 수행한다는 것은 대용량의 모델이 외부 지도 없이 충분히 크고 다양한 말뭉치로부터 학습하면 많은 문제를 잘 수행할 가능성을 최대화할 것을 제시한다.
Acknowledgements
언제나 있는 감사의 인사
Refenrences
논문 참조. 많은 레퍼런스가 있다.
Citation
@article{radford2019language,
title={Language Models are Unsupervised Multitask Learners},
author={Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya},
year={2019}
}
8. Appendix A: Samples
8.1. Model capacity
가장 작은 WebText LM과 GPT-2가 본 적 없는(unseen) WebTest 테스트 기사에 대해 생성한 문장들을 비교하여 나열한 것이 표 7~11에 있다. 256개의 단어(token)을 주고 다음 256를 생성하는 것이다. 논문에 따르면 잘 된 것을 골라 가져온 것은 아니라고 한다.
그 중 하나를 가져와 보았다. 기계가 생성한 문장치고 깔끔하다.

8.2. Text Memorization
게티즈버그 연설 유명한 인용문이나 연설 같은 문장이 주어질 때 GPT-2가 (그대로) ‘암기’하는 행동을 보이는 것이 관찰되었다.
이런 현상이 얼마나 일어나는지 보기 위해 test set 기사를 주고 GPT-2가 생성한 문장과 실제 문장의 완성한 것과의 overlap 비율을 비교해 보았다.
결과는 기준보다 그 비율이 낮다고 한다.
8.3. Diversity
표 12는 같은 문장을 주고 나머지를 생성하라 했을 때 얼마나 다양한 문장들을 생성하는지 본 것이다.

8.4. Robustness
표 13은 앞에서 언급 한 유니콘 뉴스 기사를 보여준다. 이 모델이 분포 문맥을 다룰 수는 있지만 이러한 샘플의 품질은 일반적으로 낮다.
