
Explain Yourself! Leveraging Language Models for Commonsense Reasoning
08 Feb 2020 | Paper_Review NLP목차
- Explain Yourself! Leveraging Language Models for Commonsense Reasoning
이 글에서는 2019년 6월 Nazneen Fatema Fajani 등이 발표한 Explain Yourself! Leveraging Language Models for Commonsense Reasoning 논문을 살펴보도록 한다.
이 논문에서는 CoS-E라는 상식 설명문(Common Sense Explanations)에 관한 데이터셋을 만들어 공개했다. 여기에서 찾아볼 수 있다(논문의 링크로 들어가보면 저장 위치가 바뀌었다고 한다).
중요한 부분만 적을 예정이므로 전체가 궁금하면 원 논문을 찾아 읽어보면 된다.
Explain Yourself! Leveraging Language Models for Commonsense Reasoning
논문 링크: Explain Yourself! Leveraging Language Models for Commonsense Reasoning
Dataset: CoS-E
초록(Abstract)
딥러닝 모델들은 상식추론(Commonsense Reasoning)이 필요한 task에서는 낮은 성능을 보여, 입력에는 당장 나타나지 않는 어떤 정보에 대한 지식이나 추론이 필요하게 하였다. 우리(이 논문의 저자)는 CoS-E(Common Sense Explanations)라 부르는, 1) 일련의 자연어와 2) 강조된 구문 두 가지 형태로 구성된 새로운 데이터셋을 수집했다. CAGE(Commonsense Auto-Generated Explanation) Framework에서 학습 및 추론 단계에서 사용될 수 있는 설명문(explanations)을 자동으로 생성하도록 언어모델을 학습시켰다. CAGE는 상식질답(CommonsenseQA) task에서 10%만큼 State-of-the-art를 뛰어넘었다. 우리는 또한 out-of-domain으로의 전이학습을 포함하여 사람이 그리고 기계가 자동생성한 설명문을 전부 사용하여 DNN에서 상식추론 문제를 연구할 것이라 하였다. 실험결과는 상식추론에 관해 언어모델을 효과적으로 조정(Leverage)할 수 있음을 시사한다.
1. 서론(Introduction)
상식추론(Commonsense Reasoning)은 현대 기계학습 방법에서 도전적인 과제이다. 설명문(Explanations)은 모델이 학습하는 추론을 말로 표현하는 방법이다. 상식질답(Commonsense QA, CQA)는 상식추론 능력을 가진 자연어처리(NLP) 모델을 개발하기 위한 다지선다형 질답 데이터셋이다. 이와 관련해 많은 노력이 있었지만 뚜렷한 발전이 없었다.
이 논문의 저자들은 CQA에 더해 상식추론을 위한 사람의 설명문을 수집했고 이를 CoS-E라 하였다. CoS-E는
- 자유형식의 일련의 자연어(보통 문장)
- 정답을 추론하는 데 중요하다고 사람이 판단한 문장의 일부를 강조한 부분
두 가지 형태로 존재한다. 아래 그림에서 Question과 Choicse(3개)는 CQA dataset의 일부이며, CoS-E는 1) CoS-E 부분의 문장과 2) Question에서 노란색으로 강조된 부분을 포함한다.

Talmor et al. (2019)에서는 Google search를 활용하여 각 질답 당 100개의 snippet으로부터 문맥정보를 추출해내는 것은 ELMo 표현에 self-attention layer를 쓴 모델이자 현재 SOTA(state-of-the-art) 모델인 BiDAF++를 사용해도 CQA에서 정답률을 향상시키지 못한다고 하였다.
이에 반해, 우리는 상식추론에 유용한 설명문(explanations)을 생성하는 사전학습된 모델을 조정하였다. CQA를 위한 설명문을 생성하는 framework로 CAGE(Commonsense Auto-Generated Explanations)를 제안한다. 우리는 상식추론 문제를 두 단계로 나누었다:
- CQA sample과 그에 맞는 CoS-E 설명문을 언어모델에 입력으로 준다. 언어모델은 CQA 질답에 기초하여 CoS-E 설명문을 생성하도록 학습된다.
- 언어모델은 CQA의 학습(training)과 검증(validation) 세트 안에 있는 각 sample에 대해 설명문을 생성하도록 한다. 이 CAGE 설명문은 원래의 질문, 선택지, 언어모델의 출력값에 이어붙여 두 번째 상식추론 모델의 입력으로 들어간다.
이 2단계의 CAGE framework는 기존 최고의 baseline보다 10% 초과 달성한 결과를 얻었으며 그 예측값을 정당화(justify)하는 설명문을 생성하였다. 아래 그림은 이 접근법을 개략적으로 보여준다.
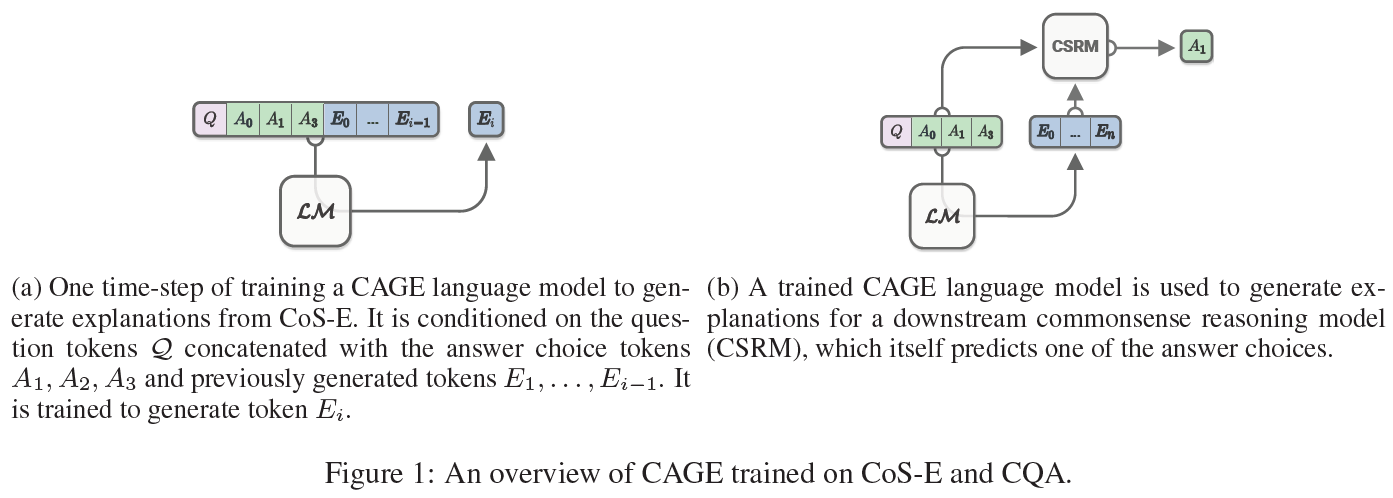
요약하면, 이 논문은 상식추론을 위한 새로운 CoS-E 데이터셋을 소개하였고, CQA v1.0에서 65%의 정답률을 보인 ‘설명문을 자동 생성하는’ CAGE framework를 제안하였다.
참고로, 이 논문이 제출되기 직전 CQA는 v1.11를 공개하였는데, 질문에 대한 선택지가 3개에서 5개로 늘어났다. 더 도전적인(challenging) 과제로 바뀌었다.
2. 배경이론과 관련 연구(Background and Related Work)
논문에 2.1. section이라 소개하진 않았지만 목차를 위해 넣었다.
2.1. Commonsense Reasoning
자연어에 포함된 상황이나 사건의 관계를 예측하도록 요구하는 데이터셋이 최근 몇 개가 소개되어 왔다.
- 여러 타당한 결말 중 가장 올바른 스토리 결말을 선택하는 Story Cloze(혹은 ROC Stories)
- 초기 상황에 기초하여 다음 장면을 예측하는 SWAG(Situations with Adversarial Generations)
이러한 데이터셋에 대해서는 GPT나 BERT이 이미 사람 수준의 성능을 내지만, 대명사가 어떻게 다른 부분과 연관이 되어 있으며 어떻게 세상의 지식과 상호작용을 하는지 등에 관해서는 별로 성공적이지 못했다.
CQA는 9500개의, 질문 + 1개의 정답 + 2개의 헷갈리는 오답으로 구성되어 있는 데이터셋으로 단지 분포상의 편향(biases)에서 정보를 얻기보다는 질문에서 추론하도록 하는 것을 요구하지만, 언어적인 면에서 좋지 않은 쪽으로 편향되어 있음이 발견되었다. 이를테면, 여자와 관련된 부분에서는 부정적인 의미의 문맥이 있다거나 하는.
SOTA 언어모델은 사람에 비해 CQA 데이터셋에서 굉장히 낮은 성능을 보인다. CQA는 모델의 상식추론 능력을 측정하는 benchmark를 제공함에도 정확히 어떤 부분이 모델이 추론을 행하는지는 여전히 불확실하다. CoS-E는 이 benchmark에 더해, 다른 한편으로 모델의 추론능력을 연구, 평가 및 분석할 수 있도록 하는 설명문을 제공한다.
2.2. Natural language explanations
Lei et al.에서는 감정분석 접근법의 타당성을 입증할 수 있는, 어떤 추론 결과를 내기 위해 필요한 구문을 입력에서 강조(선택)하는 방식을 제안했다. 분류데이터를 위한 사람이 만든 자연어 설명문은 의미분석을 학습하기 위해 사용되어왔고 분류기를 학습시키는 데 사용할 수 있는, noisy한 분류 데이터를 생성하였다. 그러나 전이성(interpretability)은 SNLI(Stanford Natural Language Inference)에서 성능저하를 보인다고 한다.
그러나, e-SNLI와는 다르게, CQA를 위한 설명문은 설명-예측 단계로 성능을 향상시킬 수 있다. 또한 VQA에도 사용 가능하며, 자동생성된 것과 사람이 만든 설명문을 함께 사용하는 것이 따로 사용하는 것보다 더 좋은 결과를 내었다.
2.3. Knowledge Transfer in NLP
자연어처리는 Word2Vec이나 GloVe와 같은 사전학습된 단어벡터를 통한 지식의 이전(transfer)에 의존한다. 맥락과 관련된(contextualized) 단어벡터의 사용은 여러 task에서 획기적인 성공을 이뤘다. 이러한 모델들은 적은 수의 parameter만 학습시킬 필요가 있고 따라서 적은 데이터만 갖고 있어도 학습이 가능하다는 장점이 있다. 잘 fine-tuned 된 언어모델은 설명문 생성과 함께 조정될 때 더 효과적이며 언어적으로 상식 정보를 얻어낸다는 점도 실험적으로 증명되었다.
3. Common Sense Explanations(CoS-E)
이 CoS-E 데이터셋은 아마존의 MTurk(Amazon Mechanical Turk)를 통해 수집되었다. CQA 데이터셋은 question token split 과 random split 두 개로 이루어져 있다. CoS-E 데이터셋과 이 논문의 모든 실험은 더 어려운 random split 을 사용하여 진행되었다. CQA v1.11에 대한 CoS-E도 만들었다.
사람들은 질문, 선택지, 정답이 주어지면 “왜 이것이 가장 적절한 답으로 예측되었는가?”라는 질문을 받는다. 그리고
- 주어진 정답이 왜 정답일지를 알려줄 수 있는 부분을 질문에서 선택하며,
- 또한 이 질문 뒤에 숨어 있을 상식적인 내용을 설명하는 자연어 문구를 작성하도록
지시받았다. (참고: 이는 CoS-E 데이터셋의 설명과 일치함.)
그래서 CQA v1.0에 대해 7610(train random split) + 950(dev random split)개의 설명문을, v1.11에 대해 9741 + 1221개의 설명문을 수집하였다. 또한 여기서부터는 질문에서 선택된 부분을 CoS-E-selected, 작성한 자연어 문구(open-ended)는 CoS-E-open-ended 라 한다.
MTurk에서는 사람들의 답변의 품질이 좋다는 것을 보장할 수 없기 때문에, 다음과 같은 처리를 거쳤다:
- 질문에서 아무 것도 선택하지 않거나
- 작성한 설명문이 4단어 이하이면 답변하지 않은 것으로 처리되며
- ‘이 정답은 답이 되는 유일한 것이다’와 같은 답변은 모두 제거하였다.
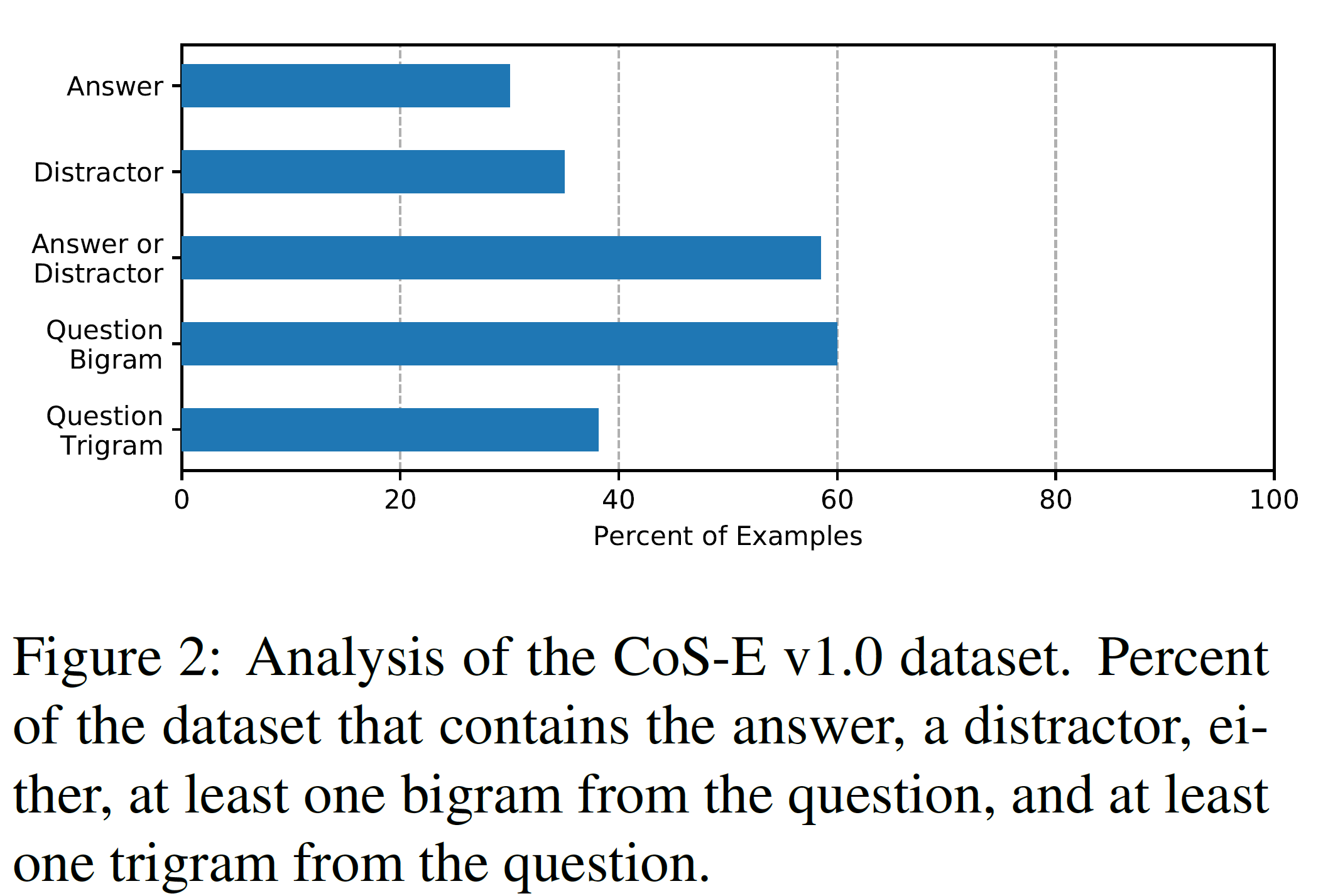
위 그림은 CoS-E v1.0 데이터셋의 분포를 보여준다.
이 논문의 실험에서는 CoS-E를 오직 학습(training) 과정에만 사용하여 SOTA 결과를 얻었으며, CoS-E 데이터셋을 사용한 경우가 그렇지 않은 경우보다 성능이 더 좋다는 것을 실험적으로 보였다.
CoS-E는 crowd-sourcing으로 얻어진 것이기 때문에 noisy할 수는 있지만 그만큼 다양성이 확보되었으며 충분한 품질을 갖고 있는 것으로 보인다고 한다.
4. 알고리즘(Algorithm)
CAGE(Commonsense Auto-Generated Explanations)를 제안하고 이를 CQA task에 적용한다. CAGE는 언어모델에 의해 생성되었으며 분류모델의 보조 입력으로 사용된다. CQA 데이터셋의 각 샘플은 질문 $q$, 선택지 $c0, c1, c2$, 정답 레이블 $a$로 구성된다. CoS-E 데이터셋은 왜 $a$가 가장 적절한지를 말해주는, 사람이 만든 설명문 $e_h$가 추가된다. CAGE의 출력은 생성한 설명문 $e$가 $e_h$에 가까워지도록 학습하는 언어모델이다.
4.1. Commonsense Auto-Generated Explanations(CAGE)
CAGE를 분류모델에 적용하기 위해, 언어모델(LM)을 CoS-E 데이터셋으로부터 설명문을 생성하도록 fine-tune했다. 이 언어모델은 여러 transformer 레이어로 이루어진, 사전학습된 OpenAI GPT이다.
여기서, 설명문 생성과 관련하여 두 가지 설정:
- 설명 후 예측(explain-and-then-predict(reasoning))
- 예측 후 설명(predict-and-then-explain(rationalization))
으로 진행하였다.
Reasoning
이 방법이 이 논문의 주된 접근법이다. 언어모델은 질문, 선택지, 사람의 설명문으로 fine-tuned 되었으며 실제 정답 label로는 학습되지 않았다. 그래서, 학습하는 동안 입력 문맥(context)은 다음과 같이 정의된다:
$ C_{RE} = “q, c0, c1 \ or\ c2? $ commonsense says
모델은 조건부 언어모델링 목적함수에 따라 설명문 $e$를 생성한다:
\[\sum_i log P (e_i \vert e_{i-k}, ..., e_{i-1}, C_{RE} ; \Theta )\]$k$는 문맥범위(context window)의 크기(이 논문에서는 항상 $ k \ge \vert e \vert $로 전체 설명문이 문맥에 포함됨)이다.
이 방식은 상식 질답 문제의 추론 단계에서 추가 문맥정보를 전달하기 위해 설명문을 자동생성하므로 reasoning 이라 부르기로 하였다.
또한 실험의 완전성을 위해, 추론과 설명의 단계를 바꿔보았는데, 그것이 다음에 설명할 rationalization이다.
Rationalization
언어모델은 post-hoc rationalization을 생성하기 위해 입력과 더불어 예측된 label을 조건으로 한다. 그래서 fine-tuning 단계에서 입력 문맥은 다음과 같다.
$ C_{RE} = “q, c0, c1 \ or\ c2?\ a$ because
목적함수는 reasoning의 것과 유사하지만 모델은 학습 중에도 입력 질문에 대한 실제 정답을 볼 수 있다. 언어모델은 예측 label에 조건을 갖기 때문에 설명문은 상식추론으로 고려될 수 없다. 대신 설명문은 모델이 더 이해 및 해석하기 쉽도록 만드는 rationalization 을 제공한다. 이 접근법은 현 최고의 모델보다 6% 더 높은 성능을 가지며 품질 좋은 설명문을 생성해 낸다.
CAGE에 대해서, 최대길이 20, batch size 36, 10 epoch 동안 학습시겨 가장 좋은 BLEU 점수와 perplexit를 갖는 모델은 선택했다. 학습률(learning rate)는 $1e^{-6}$, 초반 0.002까지 선형적으로 증가하다가(warm-up lr) 0.01만큼 decay되는 방식을 채택했다.
4.2. Commonsense Predictions with Explanations
CoS-E의 사람의 설명문이나 언어모델의 추론 중 하나를 갖고 있을 때 CQA task에 대한 예측모델을 학습시킬 수 있다. 모든 BERT 모델의 입력 샘플의 시작 부분에 들어가는 [CLS] token에 해당하는 최종 상태(final state)를 입력으로 받는 이진 분류기를 추가함으로써 다지선다형 질문 task에 fine-tuning 될 수 있는 BERT를 분류기로 사용하였다. 이를 CQA task에도 적용했는데,
- 데이터셋의 각 샘플에 대해
- BERT를 fine-tuning하기 위한 일련의 세 입력을 구성하고
- 각 입력은 (질문, 구분자
[SEP], 선택지 중 하나)로 구성된다.
- 만약 CoS-E나 CAGE의 설명문을 추가한다면
- 각 입력은 (질문, 구분자
[SEP], 설명문, 구분자[SEP], 선택지 중 하나)로 이루어진다.
- 각 입력은 (질문, 구분자
BERT를 위해 설명문은 한 질문에 대해 같은 입력표현을 공유한다. 선택지에 대해서도 공유하는 것은 약간의 성능저하를 보였다.
4.3. Transfer to out-of-domain datasets
Out-of-domain NLP 데이터셋에 fine-tuning 없이 전이학습을 시키는 것은 낮은 성능을 기록한다고 알려져 있다.
이 논문에서는 CQA에서 SWAG와 Story Cloze Test(둘 모두 CQA같은 다지선다형이다)에 대해서 전이학습을 연구했다. CQA에 fine-tuned된 GPT 언어모델을 SWAG에 대한 설명문을 생성하기 위해 사용하였다. 그리고 이를 통해 BERT 분류기를 학습시켜 두 데이터셋에 평가를 진행했다.
5. 실험 결과(Experimental Results)
모든 모델은 BERT에 기초하며, CoS-E나 CAGE를 쓰지 않을 것이 baseline이 되며, 모든 실험은 CQA dev-random-split에서 수행되었다. 또한 final test split에서도 핵심 모델을 평가하였다.
CoS-E 설명을 사용할수록 성능이 높아짐을 확인할 수 있다.

아직 사람에 비해서는 모든 모델이 한참 못 미치지만, CoS-E와 CAGE를 사용함으로써 성능이 좋아졌다.
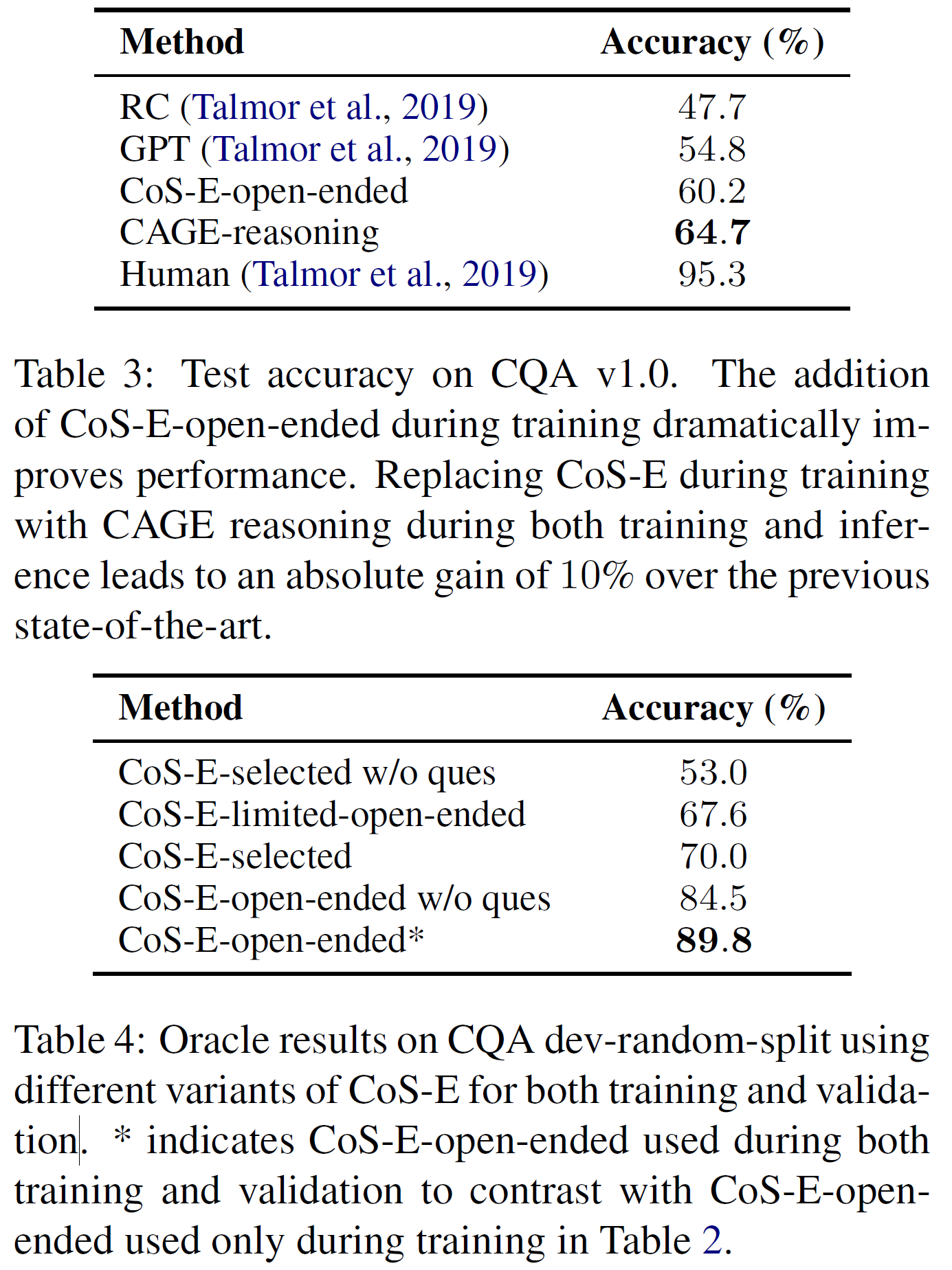
위의 표의 마지막에 있는 89.8%이라는 수치는 설명문을 제공받은 사람은 실제 정답을 갖고 있었기 때문에 공정한 수치는 아니라고 하지만, CoS-E-open-ended를 사용했을 때 얼마만큼 성능을 향상시킬 수 있을지에 대한 상한선을 보여준 것이라 한다. 또한 질문이 없는 상태에서 진행한 실험도 있는데, 질문 없이 어떤 정답이 가장 정답일 것 같은지를 설명문을 보고 판단하는 실험이다.
그리고 open-ended CoS-E의 경우 질문에 이미 있는 쓸모 있는 정보를 알려주는 것을 넘어 중요한 정보를 제공한다는 것을 보여준다.
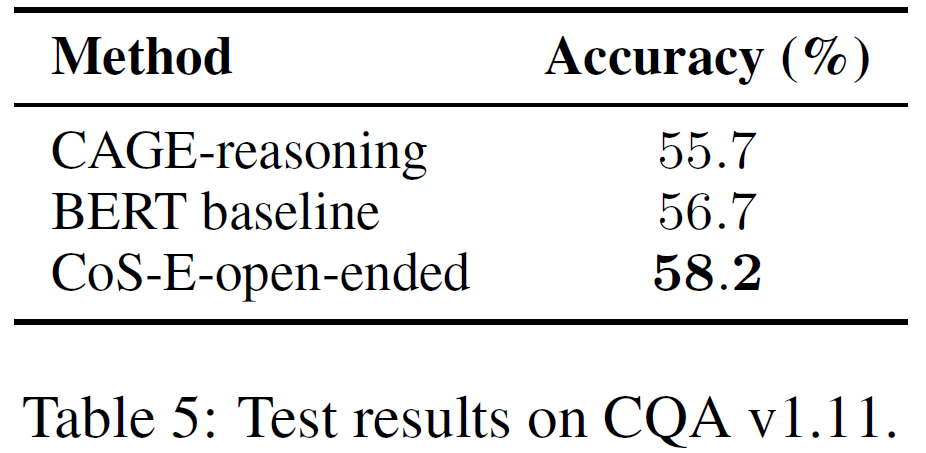
CQA v1.11에 대한 실험도 진행하였고 그 결과는 위 그림에서 볼 수 있다.
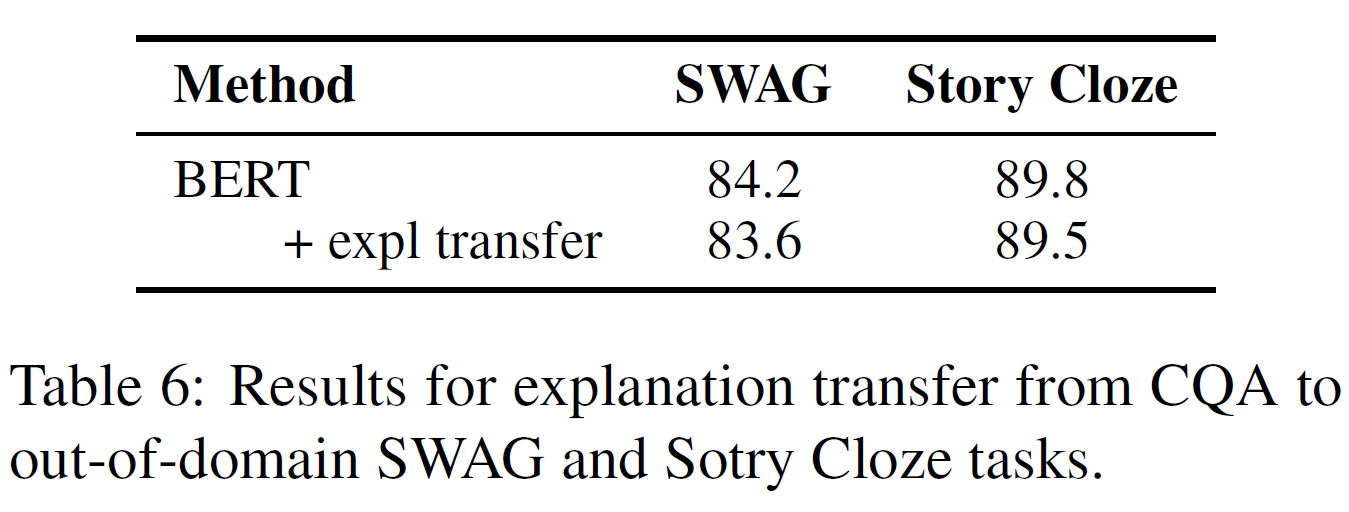
전이학습에 대한 결과는 아래 그림에서 볼 수 있는데, CQA에서 SWAG와 Story Cloze로 전이된 설명문을 추가한 경우 약간의 성능저하가 있음을 보였다.
6. 분석 및 토의(Analysis and Discussion)
CAGE-reasoning은 72%의 성능을 보였는데, CoS-E-open-ended의 모든 정보를 활용한다면 최대 90% 정도까지 성능이 올라갈 수 있음을 보였기 때문에, 추가적인 분석이 더 필요하다.
CAGE-reasoning과 CoS-E-open-ended 간 BLEU 점수는 4.1이며 perplexity는 32를 보였다.
아래 그림은 CQA, CoS-E, CAGE 샘플을 가져온 것인데, CAGE-reason이 일반적으로 CoS-E보다 조금 더 간단한 구성을 보이는데, 이 조금 더 선언적인 부분이 CoS-E-open-ended보다 더 유익한 경우가 있다(실제 단어 차이는 거의 없다). CAGE-reasoning은 43%의 경우에서 선택지 중 적어도 하나를 포함하는데, 모델의 실제 예측 선택지는 21%만이 그러하였다. 이는 답을 직접적으로 가리키는 것보다 더 효과적인 부분이 CAGE-reasoning에 있음을 보여준다.

CAGE-rationalization이 CAGE-reasoning보다 조금 더 나은 것 같기도 하지만, 실제 질문 없이 정답을 추측하는 부분에서는 별 향상이 없다.
CoS-E나 CAGE가 noisy하다고 해도, 모델의 성능이 낮은 것이 이것 때문이라 볼 수는 없다. 만약 CQA의 세 선택지 중 하나를 호도하는 선택지로 일부러 바꾼 경우 모델의 성능은 60%에서 30%로 떨어졌다. 에러의 70%는 호도하는 설명문에 의해 만들어졌고, 그 중 57%는 대신 CoS-E 설명문으로 학습된 모델에 의해 올바르게 정답을 맞췄다. 이는 유익한 설명문의 효과를 보여준다.
CQA v1.11에서는 BERT를 1.5% 차이로 앞섰는데, CQA v1.11에서 잘못 예측한 예시는 아래에서 볼 수 있다. 잘못 예측한 것 중 많은 부분은 생성된 설명문에 맞는 정답을 포함하는 경우가 있었다(dresser drawer과 cleanness 등). 이러한 경우는 관련 있는 정보에 더 집중하도록 하는 명시적인 방법이 필요로 함을 보여준다. 그리고 “forest”와 “compost pile” 같은 의미적으로 비슷한 다른 선택지를 고르는 경우도 빈번했는데, 이는 새로운 CQA 데이터셋에서 설명문을 단지 덧붙이는 것만으로는 충분하지 않음을 보여준다.

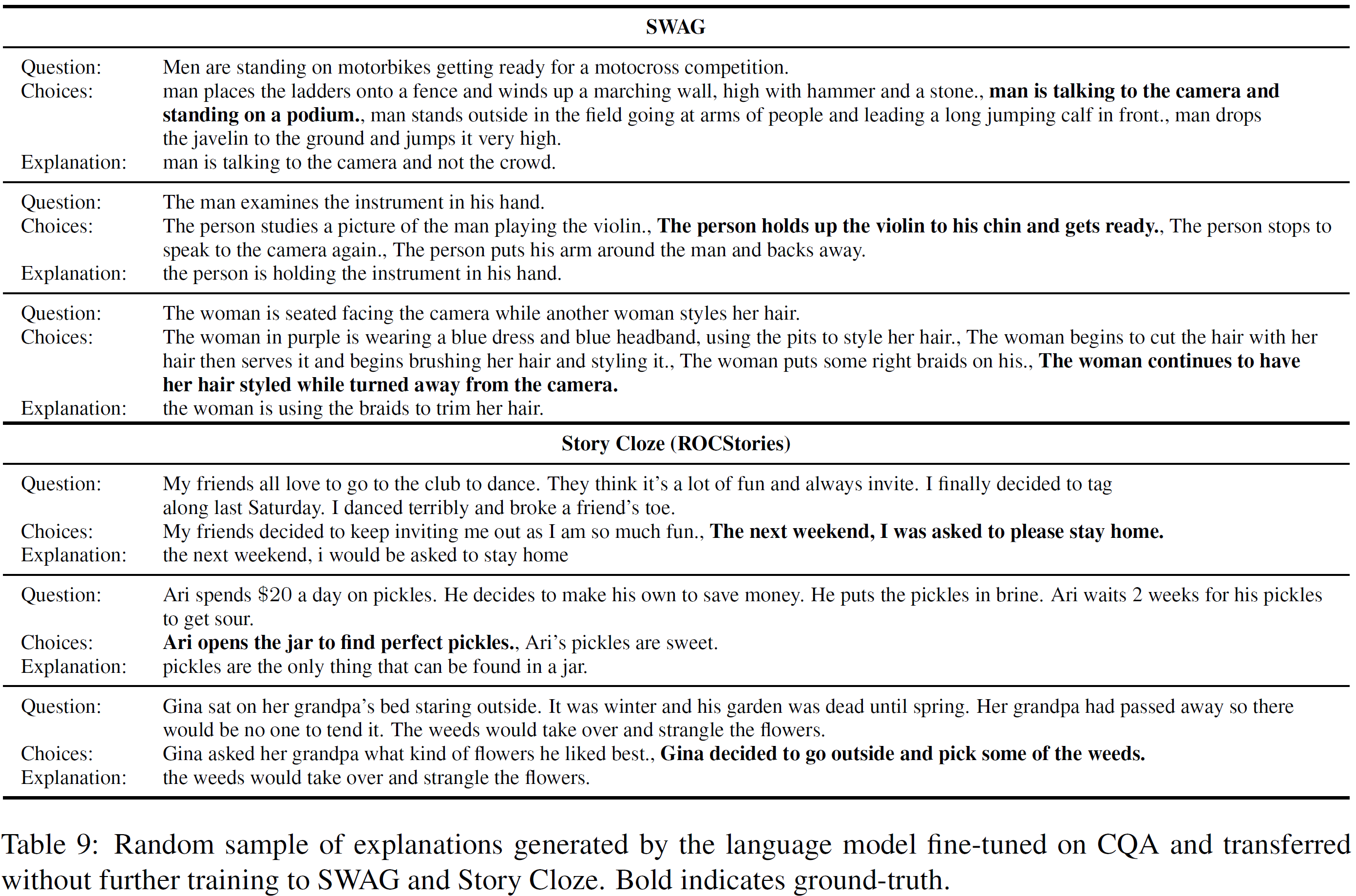
SWAG와 Story Cloze에 맞춰 생성한 설명문은 유익한 정보를 담고 있는 것을 발견했지만, 전이학습에 대한 실험에서 분류기가 이를 제대로 활용하지는 못했다.
7. 결론 및 향후 연구(Conclusion and Future Work)
CoS-E라는 새로운 데이터셋을 제시하였고, CAGE framework를 제안하였으며, 여기서 생성된 설명문(explanations)은 예측을 위해 분류기에서 효율적으로 사용될 수 있었다. 이로써 단지 SOTA를 달성한 것 뿐만 아니라, 이해할 수 있는(interpretable) 상식추론과 관련해 설명문을 연구하는 새로운 길을 열었다.
CAGE는 답을 예측하기 위한 사전 작업으로 설명문을 생성하는 데 집중했는데, 설명문을 통한 언어모델은 정답 예측에 있어 함께 학습될 수도 있다. 이는 더 많은 task에 적용될 수 있을 것이다. 많은 task에 대해 충분한 설명문 데이터셋(CoS-E)가 있으면 다른 task에 대해서도 유용한 설명문을 생성하는 언어모델을 만들 수도 있다.
그리고, 설명문은 편향이 없어야 할 것이다. 예를 들어 CQA에서는 ‘여성’과 ‘부정적인 문맥’의 연관도가 다른 쪽에 비해 더 높았는데, 이러한 편향이 있음은 모델 학습에 있어 분명 고려되어야 한다.
Acknowledgements
언제나 있는 감사의 인사. 그림과 reviewer 등등
Refenrences
논문 참조. 많은 레퍼런스가 있다.